
LWN.net Weekly Edition for November 6, 2008
The end of the road for Firefox 2
By some accounts, the Firefox browser is now responsible for a full 20% of web traffic. As the number of Firefox users grows, so does the need for top-quality support; 20% makes for a large number of potential attack points. So it is interesting to note that Mozilla is now planning to end Firefox 2 support in the near future, perhaps before the end of the year. This change could leave a lot of users - and not just Firefox users - in a difficult position.One obvious question to ask would be: have most Firefox users moved on to Firefox 3? Apparently, about two out of three users have made the change, but millions of users have yet to move away from the older browser. The Mozilla project would like to get as many of those users to switch before ending support; that, in turn, requires looking at why they haven't yet upgraded. There seem to be a few prominent reasons beyond sheer inertia:
- Some users have systems which are not supported by Firefox 3.
Many of these, it seems, are running old versions of Windows - 9x or
NT4. In these cases, the operating system itself has long since
ceased to receive support, so it's not entirely clear that continuing
to support the browser does a whole lot of good.
- Others are dependent on extensions which have not been ported to
Firefox 3. While most actively-developed extensions
were ported some time ago, it appears that there are quite a few extensions
which, while still having significant numbers of users, have been
abandoned by their developers. Zack Weinberg has suggested that the project could make an
active effort to find new maintainers for those extensions, or even
fix a few of them itself.
- The Firefox 3 experience is not problem-free for all users; there have been some complaints about printing on some systems, for example. Finding - and fixing - the remaining blockers is clearly an important thing for the Firefox developers to do.
Somehow, ways will probably be found to coax most of these users into moving forward to a newer browser. Beyond doubt, though, some will be left behind, and some of those may learn the hard way what "unsupported" really means. But that will be true no matter how long Firefox 2 is supported; there's never a way to get all users to upgrade. Firefox is not different from any other application in this regard, with the sole exception that its user base is larger than most.
There is another important aspect to this story, though: this decision will affect users well beyond those who use Firefox. The end of Firefox 2 support will also bring an end to support for the Gecko 1.8.1 platform. And this version of Gecko is used by several applications beyond Firefox, including Camino, SeaMonkey, Sunbird, Miro, Instantbird, and Thunderbird. All of these platforms currently use Gecko - the soon-to-be-discontinued version of Gecko - for HTML rendering.
There is a fair amount of concern about Thunderbird in particular. This mail client was recently kicked out of the Mozilla nest to fend for itself. Thunderbird developers are working toward a Thunderbird 3 release (the third alpha release came out in mid-October) which will use a newer version of Gecko. But the 3.0 release is still several months away - some months after the end of Gecko 1.8.1 support. Naturally enough, the Thunderbird developers worry that their current users will be running in an unsupported mode; that does not strike them as the best start for their newly-independent project.
The word from the Mozilla Foundation seems to be that the Gecko platform will continue to be supported, in some minimal fashion, for a while yet. According to Samuel Sidler:
Note that this will mean that browser-specific security and stability bugs will likely be ignored/minused. We'll only be considering bugs that affect Thunderbird 2.0.0.x.
So it seems that Thunderbird should be covered - as long as the people who decide whether bugs are "browser-specific" do their job properly. But experience has shown many times that it can be hard to understand the full implications of a given bug. It would not be all that surprising for one or more "browser-specific" bugs to turn out to be fully exploitable in Thunderbird.
Beyond that, though, applications like SeaMonkey and Camino are browsers. Developers from those projects are, needless to say, concerned that their needs are not being taken into account. They are not attracted by the idea of shipping a browser based on a platform where browser-specific bugs are being ignored. Mozilla developers have tried to reassure these groups that the situation is not as bad as it seems, but how things will work for them is far from clear. The real answer was, perhaps, suggested by Samuel:
In other words, Mozilla would like to outsource the maintenance of this code to the community, and to distributors in particular. The good news is that this is free software, so this kind of extended maintenance is possible as long as the interest is there to do it. Gecko is a non-trivial body of software to maintain, but it should be possible for the various interested projects, along with distributors still shipping this code, to pool their effort and get the job done. In their spare time, perhaps, they can give some thought to how they might avoid getting caught in the same situation when Firefox 3 reaches the end of its supported life.
GFDL 1.3: Wikipedia's exit permit
Wikipedia is one of the preeminent examples of what can be done in an open setting; it has, over the years, accumulated millions of articles - many of them excellent - in a large number of languages. Wikipedia also has a bit of a licensing problem, but it would appear that recent events, including the release of a new license by the Free Software Foundation, offers a way out.Wikipedia is licensed under the GNU Free Documentation License (GFDL). The GFDL has been covered here a number of times; it is, to put it mildly, a controversial document. Its anti-DRM provisions are sufficiently broad that, by some peoples' interpretation, a simple "chmod -r" on a GFDL-licensed file is a violation. But the biggest complaint has to do with the GFDL's notion of "invariant sections." These sections must be propagated unchanged with any copy (or derived work) of the original document. The GFDL itself must also be included with any copies. So a one-page excerpt from the GNU Emacs manual, for example, must be accompanied by several dozen pages of material, including the original GNU Manifesto.
So the GFDL has come to be seen by many as more of a tool for the propagation of FSF propaganda than a license for truly free documentation. Much of the community avoids this license; some groups, such as the Debian Project, see it as non-free. Many projects which still do use the GFDL make a clear point of avoiding (or disallowing outright) the use of cover texts, invariant sections, and other GFDL features. Some projects have dropped the GFDL; in many cases, they have moved to the Creative Commons attribution-sharealike license which retains the copyleft provisions of the GFDL without most of the unwanted baggage.
Members of the Wikipedia project have wanted to move away from the GFDL for some time. They have a problem, though: like the Linux kernel, Wikipedia does not require copyright assignments from its contributors. So any relicensing of Wikipedia content would require the permission of all the contributors. For a project on the scale of Wikipedia, the chances of simply finding all of the contributors - much less getting them to agree on a license change - are about zero. So Wikipedia, it seems, is stuck with its current license.
There is one exception, though. The Wikipedia copyright policy, under which contributions are accepted, reads like this:
The presence of the "or any later version" language allows Wikipedia content to be distributed under the terms of later versions of the GFDL with no need to seek permission from individual contributors. Surprisingly, the Wikimedia Foundation has managed to get the Free Software Foundation to cooperate in the use of the "or any later version" permission to carry out an interesting legal hack.
On November 3, the FSF and the Wikimedia Foundation jointly announced the release of version 1.3 of the GFDL. This announcement came as a surprise to many, who had no idea that a new GFDL 1.x release was in the works. This update does not address any of the well-known complaints against the GFDL. Instead, it added a new section:
The operator of an MMC Site may republish an MMC contained in the site under CC-BY-SA on the same site at any time before August 1, 2009, provided the MMC is eligible for relicensing.
In other words, GFDL-licensed sites like Wikipedia have a special, nine-month window in which they can relicense their content to the Creative Commons attribution-sharealike license. This works because (1) moving to version 1.3 of the license is allowed under the "or any later version" terms, and (2) relicensing to CC-BY-SA is allowed by GFDL 1.3.
Legal codes, like other kinds of code, have a certain tendency to pick up cruft as they are patched over time. In this case, the FSF has added a special, time-limited hack which lets Wikipedia make a graceful exit from the GFDL license regime. This move is surprising to many, who would not have guessed that the FSF would go for it. Lawrence Lessig, who calls the change "enormously important," expresses it this way:
For whatever reason, Stallman and the FSF chose to go along with this change, though not before adding some safeguards. The November 1 cutoff date (which precedes the GFDL 1.3 announcement) is there to prevent troublemakers from posting FSF manuals to Wikipedia in their entirety, and, thus, relicensing them.
Now that Wikipedia has its escape clause, it needs to decide how to respond. The plan would appear to be this:
This proposal will be followed by a "community-wide referendum," with a majority vote deciding whether the new policy will be adopted or not. Expect some interesting discussions over the next month.
This series of events highlights a couple of important points to keep in mind when considering copyright and licensing for a project. There is a certain simplicity and egalitarianism inherent in allowing contributors to retain their copyrights. But it does also limit a project's ability to recover from a suboptimal license choice later on. Licensing inflexibility can be a good thing or a bad thing, depending on your point of view, but it is certainly something which could be kept in mind.
The other thing to be aware of is just how much power the "or any later version" text puts into the hands of the FSF. The license promises that later versions will be "similar in spirit," but the GPLv3 debate made it clear that similarity of spirit is in the eye of the beholder. It is not immediately obvious that allowing text to be relicensed (to a license controlled by a completely different organization) is in the "spirit" of the original GFDL. Your editor suspects that most contributors will be willing to accept this change, but there may be some who feel that their trust was abused.
Finally, it's worth noting that "any later version" includes GFDL 2.0. The discussion draft of this major license upgrade has been available for comments for a full two years now. The FSF has not said anything about when it plans to move forward with the new license, but it seems clear that anybody wanting to comment on this draft would be well advised to do so soon.
Testing Fedora on the OLPC
In preparation for this year's version of the Give One, Get One (G1G1) promotion of the One Laptop Per Child (OLPC) XO, the Fedora OLPC special interest group (SIG) has undertaken a rather large testing effort. With the assistance of 80 mostly-free XOs, the group has been running Fedora 10 on the hardware, trying to shake out Fedora and OLPC bugs. The idea is to help lift some of the burden from the OLPC developers, while also providing some distribution testing focused on areas specific to the OLPC hardware.
G1G1 participants can optionally purchase an SD card pre-loaded with a Fedora 10 live distribution, so that they can run a full Fedora desktop on the XO. Normally, it runs a stripped-down version of Fedora 9 with the Sugar interface as the only desktop available. Part of the Fedora OLPC effort is to help reduce the operating system burden for the OLPC folks. Fedora OLPC liaison (and Red Hat Senior Community Architect) Greg DeKoenigsberg describes where the project is headed:
Back in September, DeKoenigsberg put out a call for folks interested
in testing, with the incentive of a "mostly" free XO. Participants
needed to be willing to buy an SD card to put Fedora on and to spend 20
hours testing Fedora on the XO. There were more volunteers than laptops,
as would be expected, but 80 XOs—most refurbished returns from the
original G1G1 last year—got into the hands of many "experienced
Fedora community members
". The XOs were provided by the OLPC
project through its developer
program.
The testing has already "found and resolved a number of potential
release blockers
", according to DeKoenigsberg. There is an
extensive test
plan that outlines the different testing areas as well as the
methodology of testing and reporting bugs found. In many ways, this is
just a test of Fedora on a new hardware platform, with the focus on things
that set the XO apart: power management, networking, the built-in camera,
display, performance, etc.
But there is more to the SIG than just testing the XO. The task list has a number of different activities that are currently underway. Getting a developer key to each person who chooses the Fedora 10 option in G1G1 is an important piece of the puzzle—the XO security policy will not allow it to boot from SD without it. Various Sugar tasks are high on the list as well.
One of those is the Fedora Sugar spin, a Live CD that allows running the Sugar environment on any computer. So far, there are just a few Sugar "activities"—roughly equivalent to applications for things like web browsing or word processing—available for the spin, but that is another of the tasks that Fedora OLPC will be working on. There is currently a bit of an awkward debate on the fedora-advisory-board mailing list about how "official" the Sugar spin really is—as it missed the deadline for the Fedora 10 freeze—but it would seem that many are in favor of granting it a waiver.
The Fedora OLPC SIG's mission statement—"To provide the OLPC
project with a strong, sustainable, scalable, community-driven base
platform for innovation
"—makes it clear it sees a big role in
assisting OLPC going forward. The testing effort is just one facet of that,
as DeKoenigsberg notes:
The OLPC project is one with great promise. It has suffered at times from the mixed message that it gives regarding free vs. proprietary software, but it could, clearly, be a marvelous example of free software in action. In order for that to happen, though, there will need to be a concerted effort by the free software community to assist. The Fedora OLPC SIG looks to be an excellent step in that direction.
Security
Android's first vulnerability
A company's response to security vulnerabilities is always interesting to watch. Google has the reputation of being fairly cavalier regarding flaws reported in its code; the first security vulnerability reported for the Android mobile phone software appears to follow that pattern. Unfortunately for users of Android phones, though, Google's attitude and relatively slow response might some day lead to an "in the wild" exploit targeting the phones.
The flaw was first reported to Google on October 20 by Independent Security Evaluators (ISE), but was not patched for the G1 phone—the only shipping Android phone—until November 3. Details on the vulnerability are thin, but it affects the web browser and is caused by Google shipping an out-of-date component. Presumably a library or content handler was shipped with a known security flaw that could lead to code execution as the user id which runs the browser.
It should be noted that compromising the browser does not affect the rest of the phone due to Android's security architecture. Unlike the iPhone, separate applications are run as different users, so that phone functionality is isolated from the browser, instant messaging, and other tools. An iPhone compromise in any application can lead to the attacker being able to make phone calls and get access to private data associated with any application; clearly Google made a better choice than Apple.
One interesting recent development, though, is the availability of an application that provides a root-owned telnet daemon. With that running, a simple telnet gets full access to the phone's filesystem. From there, jailbreaking—circumventing the restrictions placed by a carrier on applications—as well as unlocking the phone from a specific carrier are possible. While it is easy to see how that might be useful for the owner of Android, though it opens the phone to rather intrusive attacks, it probably is not what T-Mobile (and other carriers down the road) had in mind.
Google's first response to the vulnerability report was to whine that Charlie Miller, who discovered the flaw, was not being "responsible" by talking about it before a fix was ready. Miller did not disclose details, but did report the existence of—along with some general information about—the flaw. Google's previous reputation regarding vulnerability reporting, as well as how it treated Miller, undoubtedly played a role in his decision.
Perhaps the most galling thing is that the flaw was in a free software component that had been updated prior to the Android release to, at least in part, close that hole. It would seem that the Android team was not paying attention to security flaws reported in the free software components that make up the phone software stack. Hopefully, this particular occurrence will serve as a wake-up call on that front.
Given that the fix was already known, it is a bit puzzling that it would take two weeks for updates to become available. It was the first update made for Android phones in the field, but one hopes the bugs in that process were worked out long ago. Overall, Google's response leaves rather a lot to be desired.
If Google wants security researchers to be more "responsible" in their disclosure, it would be well served by looking at its own behavior. Taking too much time to patch a vulnerability—especially one with a known and presumably already tested fix—is not the way to show the security community that it takes such bugs seriously. Whining about disclosure rarely, if ever, goes anywhere; working in a partnership with folks who find security flaws is much more likely to bear fruit.
New vulnerabilities
apache tomcat: restriction bypass
| Package(s): | tomcat5, apache-jakarta-tomcat-connectors | CVE #(s): | CVE-2008-3271 | ||||
| Created: | October 31, 2008 | Updated: | November 5, 2008 | ||||
| Description: | From the CVE entry: Apache Tomcat 5.5.0 and 4.1.0 through 4.1.31 allows remote attackers to bypass an IP address restriction and obtain sensitive information via a request that is processed concurrently with another request but in a different thread, leading to an instance-variable overwrite associated with a "synchronization problem" and lack of thread safety, and related to RemoteFilterValve, RemoteAddrValve, and RemoteHostValve. | ||||||
| Alerts: |
| ||||||
dovecot: negative rights in ACL plugin
| Package(s): | dovecot | CVE #(s): | CVE-2008-4577 | ||||||||||||||||||||||||||||||||
| Created: | October 30, 2008 | Updated: | September 28, 2009 | ||||||||||||||||||||||||||||||||
| Description: | dovecot has a restriction bypass vulnerability. From the
vulnerability database entry:
The ACL plugin in Dovecot before 1.1.4 treats negative access rights as if they are positive access rights, which allows attackers to bypass intended access restrictions. | ||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||
enscript: stack overflows
| Package(s): | enscript | CVE #(s): | CVE-2008-3863 CVE-2008-4306 | ||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | November 4, 2008 | Updated: | December 16, 2008 | ||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | From the Ubuntu alert:
Ulf Härnhammar discovered multiple stack overflows in enscript's handling of special escape arguments. If a user or automated system were tricked into processing a malicious file with the "-e" option enabled, a remote attacker could execute arbitrary code or cause enscript to crash, possibly leading to a denial of service. | ||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||
graphviz: stack-based buffer overflow
| Package(s): | graphviz | CVE #(s): | CVE-2008-4555 | ||||||||||||||||
| Created: | October 31, 2008 | Updated: | December 7, 2009 | ||||||||||||||||
| Description: | From the CVE entry: Stack-based buffer overflow in the push_subg function in parser.y (lib/graph/parser.c) in Graphviz 2.20.2, and possibly earlier versions, allows user-assisted remote attackers to cause a denial of service (memory corruption) or execute arbitrary code via a DOT file with a large number of Agraph_t elements. | ||||||||||||||||||
| Alerts: |
| ||||||||||||||||||
kernel: buffer overflow
| Package(s): | kernel | CVE #(s): | CVE-2008-3496 | ||||
| Created: | November 3, 2008 | Updated: | November 5, 2008 | ||||
| Description: | From the Mandriva advisory: Buffer overflow in format descriptor parsing in the uvc_parse_format function in drivers/media/video/uvc/uvc_driver.c in uvcvideo in the video4linux (V4L) implementation in the Linux kernel before 2.6.26.1 has unknown impact and attack vectors. (CVE-2008-3496) | ||||||
| Alerts: |
| ||||||
kernel: denial of service
| Package(s): | kernel | CVE #(s): | CVE-2006-5755 | ||||||||
| Created: | November 4, 2008 | Updated: | November 5, 2008 | ||||||||
| Description: | From the Red Hat alert:
a flaw was found in the Linux kernel when running on AMD64 systems. During a context switch, EFLAGS were being neither saved nor restored. This could allow a local unprivileged user to cause a denial of service. | ||||||||||
| Alerts: |
| ||||||||||
kernel: denial of service
| Package(s): | kernel | CVE #(s): | CVE-2008-3527 | ||||||||||||||||
| Created: | November 4, 2008 | Updated: | December 16, 2008 | ||||||||||||||||
| Description: | From the Red Hat alert:
Tavis Ormandy reported missing boundary checks in the Virtual Dynamic Shared Objects (vDSO) implementation. This could allow a local unprivileged user to cause a denial of service or escalate privileges. | ||||||||||||||||||
| Alerts: |
| ||||||||||||||||||
kernel: denial of service
| Package(s): | kernel | CVE #(s): | CVE-2007-5907 | ||||||||
| Created: | November 4, 2008 | Updated: | November 5, 2008 | ||||||||
| Description: | From the Red Hat alert:
the Xen implementation did not prevent applications running in a para-virtualized guest from modifying CR4 TSC. This could cause a local denial of service. | ||||||||||
| Alerts: |
| ||||||||||
libgadu: denial of service
| Package(s): | libgadu | CVE #(s): | CVE-2008-4776 | ||||||||||||||||||||||||||||||||||||||||
| Created: | October 31, 2008 | Updated: | December 21, 2010 | ||||||||||||||||||||||||||||||||||||||||
| Description: | From the CVE entry: libgadu before 1.8.2 allows remote servers to cause a denial of service (crash) via a contact description with a large length, which triggers a buffer over-read. | ||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||
libtirpc: denial of service
| Package(s): | libtirpc | CVE #(s): | CVE-2008-4619 | ||||
| Created: | October 30, 2008 | Updated: | November 5, 2008 | ||||
| Description: | libtirpc performs incorrect handling of negative rights in the ACL
plugin. From the
Red Hat Bug description:
The ACL plugin in Dovecot before 1.1.4 treats negative access rights as if they are positive access rights, which allows attackers to bypass intended access restrictions. | ||||||
| Alerts: |
| ||||||
ndiswrapper: buffer overflow
| Package(s): | ndiswrapper | CVE #(s): | CVE-2008-4395 | ||||||||||||||||||||
| Created: | November 5, 2008 | Updated: | March 3, 2009 | ||||||||||||||||||||
| Description: | The out-of-tree ndiswrapper kernel module does not properly handle long ESSIDs, enabling remote code-execution attacks. | ||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||
net-snmp: denial of service
| Package(s): | net-snmp | CVE #(s): | CVE-2008-4309 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | November 3, 2008 | Updated: | July 20, 2009 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | From the Red Hat advisory: A denial-of-service flaw was found in the way Net-SNMP processes SNMP GETBULK requests. A remote attacker who issued a specially-crafted request could cause the snmpd server to crash. (CVE-2008-4309) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
nfs-client: access restriction bypass
| Package(s): | nfs-client | CVE #(s): | CVE-2008-4552 | ||||||||||||||||||||||||||||||||
| Created: | October 30, 2008 | Updated: | September 16, 2009 | ||||||||||||||||||||||||||||||||
| Description: | nfs-client has an access restriction bypass vulnerability.
From the rPath alert:
Previous versions of the nfs-utils package contain a bug that causes NIS netgroup restrictions to be ignored by TCP Wrappers, which may allow remote attackers to bypass intended access restrictions. | ||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||
openoffice.org: multiple vulnerabilities
| Package(s): | openoffice.org | CVE #(s): | CVE-2008-2237 CVE-2008-2238 | ||||||||||||||||||||||||||||||||||||||||
| Created: | October 30, 2008 | Updated: | January 13, 2009 | ||||||||||||||||||||||||||||||||||||||||
| Description: | openoffice.org has two file parser vulnerabilities. From the
Debian alert:
CVE-2008-2237 The SureRun Security team discovered a bug in the WMF file parser that can be triggered by manipulated WMF files and can lead to heap overflows and arbitrary code execution. CVE-2008-2238 An anonymous researcher working with the iDefense discovered a bug in the EMF file parser that can be triggered by manipulated EMF files and can lead to heap overflows and arbitrary code execution. | ||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||
opera: multiple vulnerabilities
| Package(s): | opera | CVE #(s): | CVE-2008-4195 CVE-2008-4196 CVE-2008-4197 CVE-2008-4198 CVE-2008-4199 CVE-2008-4200 CVE-2008-4292 CVE-2008-4694 CVE-2008-4695 CVE-2008-4696 CVE-2008-4697 CVE-2008-4698 CVE-2008-4794 CVE-2008-4795 | ||||
| Created: | November 4, 2008 | Updated: | November 5, 2008 | ||||
| Description: | The Opera browser has multiple vulnerabilities. From the Gentoo alert:
Opera does not restrict the ability of a framed web page to change the address associated with a different frame (CVE-2008-4195). Chris Weber (Casaba Security) discovered a Cross-site scripting vulnerability (CVE-2008-4196). Michael A. Puls II discovered that Opera can produce argument strings that contain uninitialized memory, when processing custom shortcut and menu commands (CVE-2008-4197). Lars Kleinschmidt discovered that Opera, when rendering an HTTP page that has loaded an HTTPS page into a frame, displays a padlock icon and offers a security information dialog reporting a secure connection (CVE-2008-4198). Opera does not prevent use of links from web pages to feed source files on the local disk (CVE-2008-4199). Opera does not ensure that the address field of a news feed represents the feed's actual URL (CVE-2008-4200). Opera does not check the CRL override upon encountering a certificate that lacks a CRL (CVE-2008-4292). Chris (Matasano Security) reported that Opera may crash if it is redirected by a malicious page to a specially crafted address (CVE-2008-4694). Nate McFeters reported that Opera runs Java applets in the context of the local machine, if that applet has been cached and a page can predict the cache path for that applet and load it from the cache (CVE-2008-4695). Roberto Suggi Liverani (Security-Assessment.com) reported that Opera's History Search results does not escape certain constructs correctly, allowing for the injection of scripts into the page (CVE-2008-4696). David Bloom reported that Opera's Fast Forward feature incorrectly executes scripts from a page held in a frame in the outermost page instead of the page the JavaScript URL was located (CVE-2008-4697). David Bloom reported that Opera does not block some scripts when previewing a news feed (CVE-2008-4698). Opera does not correctly sanitize content when certain parameters are passed to Opera's History Search, allowing scripts to be injected into the History Search results page (CVE-2008-4794). Opera's links panel incorrectly causes scripts from a page held in a frame to be executed in the outermost page instead of the page where the URL was located (CVE-2008-4795). | ||||||
| Alerts: |
| ||||||
phpMyAdmin: cross-site scripting
| Package(s): | phpMyAdmin | CVE #(s): | CVE-2008-4775 | ||||||||||||||||||||
| Created: | October 31, 2008 | Updated: | March 19, 2009 | ||||||||||||||||||||
| Description: | From the CVE entry: Cross-site scripting (XSS) vulnerability in pmd_pdf.php in phpMyAdmin 3.0.0, and possibly other versions including 2.11.9.2 and 3.0.1, when register_globals is enabled, allows remote attackers to inject arbitrary web script or HTML via the db parameter, a different vector than CVE-2006-6942 and CVE-2007-5977. | ||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||
samba: denial of service
| Package(s): | samba | CVE #(s): | |||||
| Created: | November 5, 2008 | Updated: | November 5, 2008 | ||||
| Description: | From the rPath advisory: Previous versions of the samba package contain a race condition which may lead to a crash of the winbindd daemon (Denial of Service). | ||||||
| Alerts: |
| ||||||
Page editor: Jonathan Corbet
Kernel development
Brief items
Kernel release status
The current 2.6 development kernel is 2.6.28-rc3, released on November 2. It contains the usual pile of fixes, along with the removal of the (now unused) prepare_write() and commit_write() VFS methods and new drivers for Elantech (EeePC) touchpads, and Intel X38 memory controllers.Also merged was a driver API change; drivers which support FASYNC no longer need to make a final call to fasync_helper() at release time.
As of this writing, a few dozen post-rc3 patches have been merged into the mainline repository. Along with the fixes is a new I/O memory mapping API for graphics drivers; see the separate article below for details.
Kernel development news
Quotes of the week
Linux and object storage devices
The btrfs filesystem is widely regarded as being the long-term future choice for Linux. But what if btrfs is taking the wrong direction, fighting an old war? If the nature of our storage devices changes significantly, our filesystems will have to change as well. A lot of attention has been paid to the increasing prevalence of flash-based devices, but there is another upcoming technology which should be planned for: object storage devices (OSDs). The recent posting of a new filesystem called osdfs provides a good opportunity to look at OSDs and how they might be supported under Linux.The developers of OSDs were driven by the idea that traditional, block-based disk drives offer an overly low-level interface. With contemporary hardware, it should be possible to push more intelligence into storage devices, offloading work from the host while maintaining (or improving) performance and security. So the interface offered by an OSD does not deal in blocks; instead, the OSD provides "objects" to the host system. Most objects will simply be files, but a few other types of objects (partitions, for example) are supported as well. The host manipulates these objects, but need not (and cannot) concern itself with how those objects are implemented within the device.
A file object is identified by two 64-bit numbers. It contains whatever data the creator chooses to put in there; an OSD does not interpret the data in any way. Files also have a collection of attributes and metadata; this includes much of the information stored in an on-disk inode in a traditional filesystem - but without the block layout information, which the OSD hides from the rest of the world. All of the usual operations can be performed on files - reading, writing, appending, truncating, etc. - but, again, the implementation of those operations is handled by the OSD.
One thing that is not handled by the OSD, though, is the creation of a directory hierarchy or the naming of files. It is expected that the host filesystem will use file objects to store its directory structure, providing a suitable interface to the filesystem's users. One could, presumably, also use an OSD as a sort of hardware-implemented object database without a whole lot of high-level code, but that is not where the focus of work with OSDs is now.
[PULL QUOTE: The OSD designers decided to offload another task from the host systems: security. END QUOTE] The OSD protocol [PDF] is a T10-sanctioned extension to the SCSI protocol. It is thus expected that OSD devices will be directly attached to host systems; the protocol has been designed to perform well in that mode. It is also expected, though, that OSDs will be used in network-attached storage environments. For such deployments, the OSD designers decided to offload another task from the host systems: security. To that end, the OSD protocol includes an extensive set of security-related commands. Every operation on an object must be accompanied by a "capability," a cryptographically-signed ticket which names the object and the access rights possessed by the owner of the capability. In the absence of a suitable capability, the drive will deny access.
It is expected that capabilities will be handed out by a security policy daemon running somewhere on the network. That daemon may be in possession of the drive's root key, which allows unrestricted access to the drive, or it may have a separate, partition-level key instead. Either way, it can use that key to sign capabilities given out to processes elsewhere in the system. (Drives also have a "master" key, used primarily to change the root key. Loss of the master key is probably a restore-from-backup sort of event.)
Capabilities last for a while (they include an expiration time) and describe all of the allowed operations. So the act of actually obtaining a capability should be relatively rare; most OSD operations will be performed using a capability which the system already has in hand. That is an important design feature; adding "ask a daemon for a capability" to the filesystem I/O path would not be a performance-enhancing move.
In theory, it should be relatively easy to make a standard Linux filesystem support an OSD. It's mostly a matter of hacking out much of the low-level block layout and inode management code, replacing it with the appropriate object operations. The osdfs filesystem was created in this way; the developers started with ext2. After taking out all the code they no longer needed, the osdfs developers simply added code translating VFS-level requests into operations understood by the OSD. Those requests are then executed by way of the low-level osd-initiator code (which was also recently submitted for consideration). Directories are implemented as simple files containing names and associated object IDs. There is no separate on-disk inode; all of that information is stored as attributes to the file itself. The end result is that the osdfs code is relatively small; it is mostly concerned with remapping VFS operations into OSD operations.
Anybody wanting to test this code may run into one small problem: there are few OSDs to be found in the neighborhood computer store. It would appear that most of the development work so far has been done using OSD simulators. The OSC software OSD is, like osdfs, part of the open-osd project; it implements the OSD protocol over an SQLite database. There is also an OSD simulator hosted at IBM, but it would not appear to be under current development. Simulator-based development and testing may not be as rewarding as having a shiny new device implementing OSD in hardware, but it will help to insure that both the software and the protocol are in good shape by the time such hardware is available.
It should be noted that the success of OSDs is not entirely assured. An OSD takes much of the work normally done in an operating system kernel and shoves it into a hardware firmware blob where it cannot be inspected or fixed. A poor implementation will, at best, not perform well; at worst, the chances of losing data could increase considerably. It may yet prove best to insist that storage devices just concentrate on placing bits where the operating system tells them to and leave the higher-level decisions to higher-level code. Or it may turn out that OSDs are the next step forward in smarter, more capable hardware. Either way, it is an interesting experiment.
See this article at Sun for more information on how OSD works.
Large I/O memory in small address spaces
In the good old days, video graphics drivers ran in user space and the kernel had little to do with video memory. More recently, graphics developers have decisively voted for change and, in the process, moved video memory management into the kernel. So now the kernel must often manipulate video memory directly. And that, as it turns out, is harder than one might expect - at least, on 32-bit machines if the user actually cares about reasonable performance.The problem is that 32-bit machines have a mere 4GB of virtual address space. Linux (usually) splits that space in two; the bottom 3GB are given to user space, while the kernel itself occupies the top 1GB. Splitting the space in this way yields an important advantage: there is no need to adjust the memory management configuration on transitions between kernel and user space, which speeds things up considerably. The down side is that the kernel has to fit in the remaining gigabyte of memory. That would not seem like much of a problem, even with contemporary kernels, but remember one thing: the kernel needs to map physical memory into its address space before it can do anything with it. So the amount of virtual address space given to the kernel limits the amount of physical memory it can manipulate directly.
One other thing that must fit into the kernel's address space is the vmalloc() area - a range of addresses which can be assigned on the fly to create needed mappings in the kernel. When a virtually-contiguous range of memory is allocated with vmalloc(), it is mapped in this range. Another user of this address space is ioremap(), which makes a range of I/O memory available to the kernel.
Device drivers typically need access to I/O memory, so they use ioremap() to map it into the kernel's address space. Graphics adapters are a little different, though, in that they have large I/O memory regions: the entirety of video memory. Contemporary graphics adapters can carry a lot of video memory, to the point that mapping it with ioremap() would require far too much address space, if, indeed, it fits in there at all. So a straight ioremap() is not feasible; life was much easier in the old days when this I/O memory was mapped into user space instead.
The Intel i915 developers, who are the farthest ahead when it comes to kernel-based GPU memory management, ran into this problem first. Their initial solution was to map individual pages as needed with ioremap() (or, strictly, ioremap_wc(), which turns on write combining - see this article for more details), and unmapping them afterward. This solution works, but it's slow. Among other things, an ioremap() operation requires a cross-processor interrupt to be sure that all CPUs know about the address space change. It is a function which was designed to be called infrequently, outside of performance-critical code. Making ioremap() calls a part of most graphical operations is not the way to obtain a satisfactory first-person shooter experience.
The real solution comes in the form of a new mapping API developed by Keith Packard (and subsequently tweaked by Ingo Molnar). It draws heavily on the fact that Linux has had to solve this kind of problem before. Remember that the kernel (on 32-bit systems) only has 1GB of address space to work with; that is the maximum amount of physical memory it can ever have directly mapped at any given time. Any physical memory above that amount is called "high memory"; it is normally not mapped into the kernel's address space. Access to that memory requires an explicit mapping - using kmap() or kmap_atomic() - first. High memory is thus trickier to use, but this trick has enabled 32-bit systems to support far more memory than was once thought possible.
The new mapping API draws more than inspiration from the treatment of high memory - it uses much of the same mechanism as well. A driver which needs to map a large I/O area sets up the mapping with a call to:
struct io_mapping *io_mapping_create_wc(unsigned long base,
unsigned long size);
This function returns the struct io_mapping pointer, but it does not actually map any of the I/O memory into the kernel's address space. That must be done a page at a time with a call to one of:
void *io_mapping_map_atomic_wc(struct io_mapping *mapping,
unsigned long offset);
void *io_mapping_map_wc(struct io_mapping *mapping, unsigned long offset);
Either function will return a kernel-space pointer which is mapped to the page at the given offset. The atomic form is essentially a kmap_atomic() call - it uses the KM_USER0 slot, which is a good thing for developers to know about. It is, by far, the faster of the two, but it requires that the mapping be held by atomic code, and only one page at a time can be mapped in this way. Code which might sleep must use io_mapping_map_wc(), which currently falls back to the old ioremap_wc() implementation.
Mapped pages should be unmapped when no longer needed, of course:
void io_mapping_unmap_atomic(void *vaddr);
void io_mapping_unmap(void *vaddr);
There are some interesting aspects to this implementation. One is that struct io_mapping is never actually defined anywhere. The code need not remember anything except the base address, so the return value from io_mapping_create_wc() is just the base pointer which was passed in. The other is that all of this structure is really only needed on 32-bit systems; a 64-bit processor has no trouble finding enough address space to map video memory. So, on 64-bit systems, io_mapping_create_wc() just maps the entire region with ioremap_wc(); the individual page operations are no-ops.
Keith reports that, with this change, Quake 3 (used for testing purposes only, of course) runs 18 times faster. The far more serious Dave Airlie tested with glxgears and got an increase from 85 frames/second to 380. This is a big enough improvement that they would like to see this code go into 2.6.28, which will contain the GEM memory manager code. Linus responds:
As a result, this code has been merged into the mainline and will appear in 2.6.28-rc4.
Hierarchical RCU
Introduction
Read-copy update (RCU) is a synchronization mechanism that was added to the Linux kernel in October of 2002. RCU improves scalability by allowing readers to execute concurrently with writers. In contrast, conventional locking primitives require that readers wait for ongoing writers and vice versa. RCU ensures coherence for read accesses by maintaining multiple versions of data structures and ensuring that they are not freed until all pre-existing read-side critical sections complete. RCU relies on efficient and scalable mechanisms for publishing and reading new versions of an object, and also for deferring the collection of old versions. These mechanisms distribute the work among read and update paths in such a way as to make read paths extremely fast. In some cases (non-preemptable kernels), RCU's read-side primitives have zero overhead.
Although Classic RCU's read-side primitives enjoy excellent performance and scalability, the update-side primitives which determine when pre-existing read-side critical sections have finished, were designed with only a few tens of CPUs in mind. Their scalability is limited by a global lock that must be acquired by each CPU at least once during each grace period. Although Classic RCU actually scales to a couple of hundred CPUs, and can be tweaked to scale to roughly a thousand CPUs (but at the expense of extending grace periods), emerging multicore systems will require it to scale better.
In addition, Classic RCU has a sub-optimal dynticks interface, with the result that Classic RCU will wake up every CPU at least once per grace period. To see the problem with this, consider a 16-CPU system that is sufficiently lightly loaded that it is keeping only four CPUs busy. In a perfect world, the remaining twelve CPUs could be put into deep sleep mode in order to conserve energy. Unfortunately, if the four busy CPUs are frequently performing RCU updates, those twelve idle CPUs will be awakened frequently, wasting significant energy. Thus, any major change to Classic RCU should also leave sleeping CPUs lie.
Both the existing and the proposed implementation have have Classic RCU semantics and identical APIs, however, the old implementation will be called “classic RCU” and the new implementation will be called “tree RCU”.
- Review of RCU Fundamentals
- Brief Overview of Classic RCU Implementation
- RCU Desiderata
- Towards a More Scalable RCU Implementation
- Towards a Greener RCU Implementation
- State Machine
- Use Cases
- Testing
These sections are followed by concluding remarks and the answers to the Quick Quizzes.
Review of RCU Fundamentals
In its most basic form, RCU is a way of waiting for things to finish. Of course, there are a great many other ways of waiting for things to finish, including reference counts, reader-writer locks, events, and so on. The great advantage of RCU is that it can wait for each of (say) 20,000 different things without having to explicitly track each and every one of them, and without having to worry about the performance degradation, scalability limitations, complex deadlock scenarios, and memory-leak hazards that are inherent in schemes using explicit tracking.
In RCU's case, the things waited on are called
"RCU read-side critical sections".
An RCU read-side critical section starts with an
rcu_read_lock() primitive, and ends with a corresponding
rcu_read_unlock() primitive.
RCU read-side critical sections can be nested, and may contain pretty
much any code, as long as that code does not explicitly block or sleep
(although a special form of RCU called
"SRCU"
does permit general sleeping in SRCU read-side critical sections).
If you abide by these conventions, you can use RCU to wait for any
desired piece of code to complete.
RCU accomplishes this feat by indirectly determining when these other things have finished, as has been described elsewhere for Classic RCU and realtime RCU.
In particular, as shown in the following figure, RCU is a way of waiting for pre-existing RCU read-side critical sections to completely finish, including memory operations executed by those critical sections.
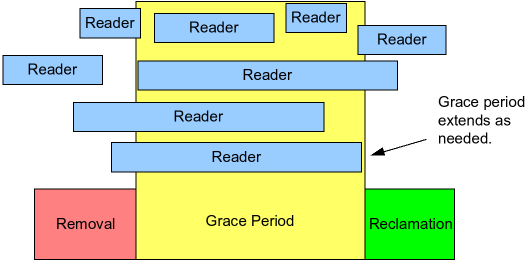
However, note that RCU read-side critical sections that begin after the beginning of a given grace period can and will extend beyond the end of that grace period.
The following section gives a very high-level view of how the Classic RCU implementation operates.
Brief Overview of Classic RCU Implementation
The key concept behind the Classic RCU implementation is that Classic RCU read-side critical sections are confined to kernel code and are not permitted to block. This means that any time a given CPU is seen either blocking, in the idle loop, or exiting the kernel, we know that all RCU read-side critical sections that were previously running on that CPU must have completed. Such states are called “quiescent states”, and after each CPU has passed through at least one quiescent state, the RCU grace period ends.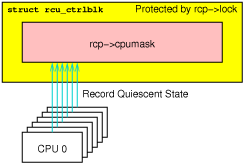
Classic RCU's most important data structure is the rcu_ctrlblk
structure, which contains the ->cpumask field, which contains
one bit per CPU.
Each CPU's bit is set to one at the beginning of each grace period,
and each CPU must clear its bit after it passes through a quiescent
state.
Because multiple CPUs might want to clear their bits concurrently,
which would corrupt the ->cpumask field, a
->lock
spinlock is used to protect ->cpumask, preventing any
such corruption.
Unfortunately, this spinlock can also suffer extreme contention if there
are more than a few hundred CPUs, which might soon become quite common
if multicore trends continue.
Worse yet, the fact that all CPUs must clear their own bit means
that CPUs are not permitted to sleep through a grace period, which limits
Linux's ability to conserve power.
The next section lays out what we need from a new non-real-time RCU implementation.
RCU Desiderata
The list of RCU desiderata called out at LCA2005 for real-time RCU is a very good start:- Deferred destruction, so that an RCU grace period cannot end until all pre-existing RCU read-side critical sections have completed.
- Reliable, so that RCU supports 24x7 operation for years at a time.
- Callable from irq handlers.
- Contained memory footprint, so that mechanisms exist to expedite grace periods if there are too many callbacks. (This is weakened from the LCA2005 list.)
- Independent of memory blocks, so that RCU can work with any conceivable memory allocator.
- Synchronization-free read side, so that only normal non-atomic instructions operating on CPU- or task-local memory are permitted. (This is strengthened from the LCA2005 list.)
- Unconditional read-to-write upgrade, which is used in several places in the Linux kernel where the update-side lock is acquired within the RCU read-side critical section.
- Compatible API.
Because this is not to be a real-time RCU, the requirement for preemptable RCU read-side critical sections can be dropped. However, we need to add a few more requirements to account for changes over the past few years:
- Scalability with extremely low internal-to-RCU lock contention. RCU must support at least 1,024 CPUs gracefully, and preferably at least 4,096.
- Energy conservation: RCU must be able to avoid awakening low-power-state dynticks-idle CPUs, but still determine when the current grace period ends. This has been implemented in real-time RCU, but needs serious simplification.
- RCU read-side critical sections must be permitted in NMI
handlers as well as irq handlers. Note that preemptable RCU
was able to avoid this requirement due to a separately
implemented
synchronize_sched(). - RCU must operate gracefully in face of repeated CPU-hotplug operations. This is simply carrying forward a requirement met by both classic and real-time.
- It must be possible to wait for all previously registered
RCU callbacks to complete, though this is already provided
in the form of
rcu_barrier(). - Detecting CPUs that are failing to respond is desirable, to assist diagnosis both of RCU and of various infinite loop bugs and hardware failures that can prevent RCU grace periods from ending.
- Extreme expediting of RCU grace periods is desirable, so that an RCU grace period can be forced to complete within a few hundred microseconds of the last relevant RCU read-side critical second completing. However, such an operation would be expected to incur severe CPU overhead, and would be primarily useful when carrying out a long sequence of operations that each needed to wait for an RCU grace period.
The most pressing of the new requirements is the first one, scalability. The next section therefore describes how to make order-of-magnitude reductions in contention on RCU's internal locks.
Towards a More Scalable RCU Implementation
One effective way to reduce lock contention is to create a hierarchy,
as shown in the following figure.
Here, each of the four rcu_node structures has its own lock,
so that only CPUs 0 and 1 will acquire the lower left
rcu_node's lock, only CPUs 2 and 3 will acquire the
lower middle rcu_node's lock, and only CPUs 4 and 5
will acquire the lower right rcu_node's lock.
During any given grace period,
only one of the CPUs accessing each of the lower rcu_node
structures will access the upper rcu_node, namely, the
last of each pair of CPUs to record a quiescent state for the corresponding
grace period.
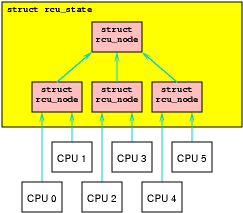
This results in a significant reduction in lock contention:
instead of six CPUs contending for a single lock each grace period,
we have only three for the upper rcu_node's lock
(a reduction of 50%) and only
two for each of the lower rcu_nodes' locks (a reduction
of 67%).
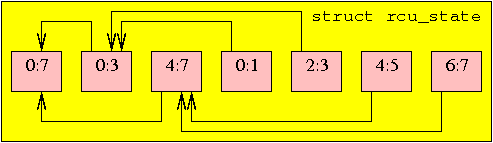
The tree of rcu_node structures is embedded into
a linear array in the rcu_state structure,
with the root of the tree in element zero, as shown below for an eight-CPU
system with a three-level hierarchy.
The arrows link a given rcu_node structure to its parent.
Each rcu_node indicates the range of CPUs covered,
so that the root node covers all of the CPUs, each node in the second
level covers half of the CPUs, and each node in the leaf level covering
a pair of CPUs.
This array is allocated statically at compile time based on the value
of NR_CPUS.
The following sequence of six figures shows how grace periods are detected.
In the first figure, no CPU has yet passed through a quiescent state,
as indicated by the red rectangles.
Suppose that all six CPUs simultaneously try to tell RCU that they have
passed through a quiescent state.
Only one of each pair will be able to acquire the lock on the
corresponding lower rcu_node, and so the second figure
shows the result if the lucky CPUs are numbers 0, 3, and 5, as indicated
by the green rectangles.
Once these lucky CPUs have finished, then the other CPUs will acquire
the lock, as shown in the third figure.
Each of these CPUs will see that they are the last in their group,
and therefore all three will attempt to move to the upper
rcu_node.
Only one at a time can acquire the upper rcu_node structure's
lock, and the fourth, fifth, and sixth figures show the sequence of
states assuming that CPU 1, CPU 2, and CPU 4 acquire
the lock in that order.
The sixth and final figure in the group shows that all CPUs have passed
through a quiescent state, so that the grace period has ended.
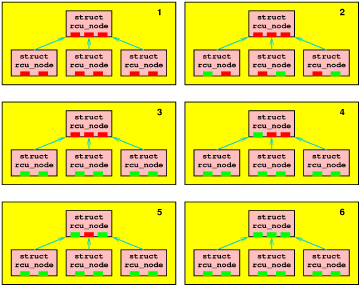
In the above sequence, there were never more than three CPUs
contending for any one lock, in happy contrast to Classic RCU,
where all six CPUs might contend.
However, even more dramatic reductions in lock contention are
possible with larger numbers of CPUs.
Consider a hierarchy of rcu_node structures, with
64 lower structures and 64*64=4,096 CPUs, as shown in the following figure.
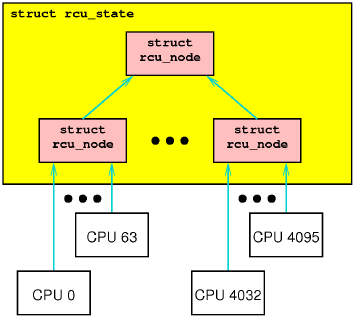
Here each of the lower rcu_node structures' locks
are acquired by 64 CPUs, a 64-times reduction from the 4,096 CPUs
that would acquire Classic RCU's single global lock.
Similarly, during a given grace period, only one CPU from each of
the lower rcu_node structures will acquire the
upper rcu_node structure's lock, which is again
a 64x reduction from the contention level that would be experienced
by Classic RCU running on a 4,096-CPU system.
Quick Quiz 1: Wait a minute! With all those new locks, how do you avoid deadlock?
Quick Quiz 2: Why stop at a 64-times reduction? Why not go for a few orders of magnitude instead?
Quick Quiz 3: But I don't care about McKenney's lame excuses in the answer to Quick Quiz 2!!! I want to get the number of CPUs contending on a single lock down to something reasonable, like sixteen or so!!!
The implementation maintains some per-CPU data, such as lists of
RCU callbacks, organized into rcu_data structures.
In addition, rcu (as in call_rcu()) and
rcu_bh (as in call_rcu_bh()) each maintain their own
hierarchy, as shown in the following figure.
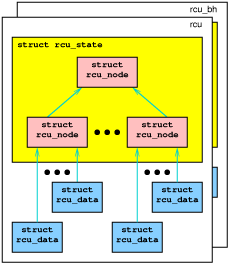
Quick Quiz 4: OK, so what is the story with the colors?
The next section discusses energy conservation.
Towards a Greener RCU Implementation
As noted earlier, an important goal of this effort is to leave sleeping CPUs lie in order to promote energy conservation. In contrast, classic RCU will happily awaken each and every sleeping CPU at least once per grace period in some cases, which is suboptimal in the case where a small number of CPUs are busy doing RCU updates and the majority of the CPUs are mostly idle. This situation occurs frequently in systems sized for peak loads, and we need to be able to accommodate it gracefully. Furthermore, we need to fix a long-standing bug in Classic RCU where a dynticks-idle CPU servicing an interrupt containing a long-running RCU read-side critical section will fail to prevent an RCU grace period from ending.
Quick Quiz 5: Given such an egregious bug, why does Linux run at all?
This is accomplished by requiring that all CPUs manipulate counters
located in a per-CPU rcu_dynticks structure.
Loosely speaking, these counters have even-numbered values when the
corresponding CPU is in dynticks idle mode, and have odd-numbered values
otherwise.
RCU thus needs to wait for quiescent states only for those CPUs whose
rcu_dynticks counters are odd, and need not wake up sleeping
CPUs, whose counters will be even.
As shown in the following diagram, each per-CPU rcu_dynticks
is shared by the “rcu” and “rcu_bh” implementations.

The following section presents a high-level view of the RCU state machine.
State Machine
At a sufficiently high level, Linux-kernel RCU implementations can be thought of as high-level state machines as shown in the following schematic:
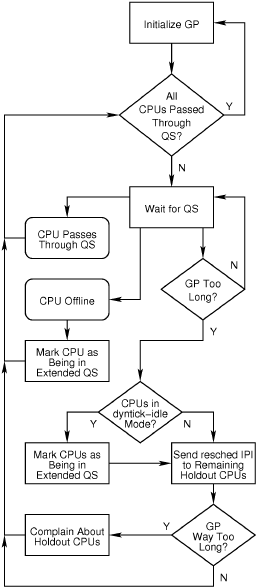
The common-case path through this state machine on a busy system
goes through the two uppermost loops, initializing at the
beginning of each grace period (GP),
waiting for quiescent states (QS), and noting when each CPU passes through
its first quiescent state for a given grace period.
On such a system, quiescent states will occur on each context switch,
or, for CPUs that are either idle or executing user-mode code, each
scheduling-clock interrupt.
CPU-hotplug events will take the state machine through the
“CPU Offline” box, while the presence of “holdout”
CPUs that fail to pass through quiescent states quickly enough will exercise
the path through the “Send resched IPIs to Holdout CPUs” box.
RCU implementations that avoid unnecessarily awakening dyntick-idle
CPUs will mark those CPUs as being in an extended quiescent state,
taking the “Y” branch out of the “CPUs in dyntick-idle
Mode?” decision diamond (but note that CPUs in dyntick-idle mode
will not be sent resched IPIs).
Finally, if CONFIG_RCU_CPU_STALL_DETECTOR is enabled,
truly excessive delays in reaching quiescent states will exercise the
“Complain About Holdout CPUs” path.
The events in the above state schematic interact with different data structures, as shown below:
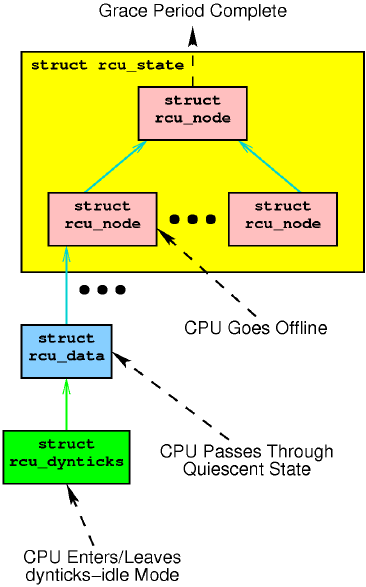
However, the state schematic does not directly translate into C code for any of the RCU implementations. Instead, these implementations are coded as an event-driven system within the kernel. Therefore, the following section describes some “use cases”, or ways in which the RCU algorithm traverses the above state schematic as well as the relevant data structures.
Use Cases
This section gives an overview of several “use cases” within the RCU implementation, listing the data structures touched and the functions invoked. The use cases are as follows:
- Start a new grace period.
- Pass through a quiescent state.
- Announce a quiescent state to RCU.
- Enter and leave dynticks idle mode.
- Interrupt from dynticks idle mode.
- NMI from dynticks idle mode.
- Note that a CPU is in dynticks idle mode.
- Offline a CPU.
- Online a CPU.
- Detect a too-long grace period.
Each of these use cases is described in the following sections.
Start a New Grace Period
The rcu_start_gp() function starts a new grace period.
This function is invoked when a CPU having callbacks waiting for a
grace period notices that no grace period is in progress.
The rcu_start_gp() function updates state in
the rcu_state and rcu_data structures
to note the newly started grace period,
acquires the ->onoff lock (and disables irqs) to exclude
any concurrent CPU-hotplug operations,
sets the
bits in all of the rcu_node structures to indicate
that all CPUs (including this one) must pass through a quiescent
state,
and finally
releases the ->onoff lock.
The bit-setting operation is carried out in two phases.
First, the non-leaf rcu_node structures' bits are set without
holding any additional locks, and then finally each leaf rcu_node
structure's bits are set in turn while holding that structure's
->lock.
Quick Quiz 6: But what happens if a CPU tries to report going through a quiescent state (by clearing its bit) before the bit-setting CPU has finished?
Quick Quiz 7: And what happens if all CPUs try to report going through a quiescent state before the bit-setting CPU has finished, thus ending the new grace period before it starts?
Pass Through a Quiescent State
The rcu and rcu_bh flavors of RCU have different sets of quiescent
states.
Quiescent states for rcu are context switch, idle (either dynticks or
the idle loop), and user-mode execution, while quiescent states for
rcu_bh are any code outside of softirq with interrupts enabled.
Note that an quiescent state for rcu is also a quiescent state
for rcu_bh.
Quiescent states for rcu are recorded by invoking rcu_qsctr_inc(),
while quiescent states for rcu_bh are recorded by invoking
rcu_bh_qsctr_inc().
These two functions record their state in the current CPU's
rcu_data structure.
These functions are invoked from the scheduler, from
__do_softirq(), and from rcu_check_callbacks().
This latter function is invoked from the scheduling-clock interrupt,
and analyzes state to determine whether this interrupt occurred within
a quiescent state, invoking rcu_qsctr_inc() and/or
rcu_bh_qsctr_inc(), as appropriate.
It also raises RCU_SOFTIRQ, which results in
rcu_process_callbacks() being invoked on the current
CPU at some later time from softirq context.
Announce a Quiescent State to RCU
The afore-mentioned rcu_process_callbacks() function
has several duties:
- Determining when to take measures to end an over-long grace period
(via
force_quiescent_state()). - Taking appropriate action when some other CPU detected the end of
a grace period (via
rcu_process_gp_end()). “Appropriate action“ includes advancing this CPU's callbacks and recording the new grace period. This same function updates state in response to some other CPU starting a new grace period. - Reporting the current CPU's quiescent states to the core RCU
mechanism (via
rcu_check_quiescent_state(), which in turn invokescpu_quiet()). This of course might mark the end of the current grace period. - Starting a new grace period if there is no grace period in progress
and this CPU has RCU callbacks still waiting for a grace period
(via
cpu_needs_another_gp()andrcu_start_gp()). - Invoking any of this CPU's callbacks whose grace period has ended
(via
rcu_do_batch()).
These interactions are carefully orchestrated in order to avoid buggy behavior such as reporting a quiescent state from the previous grace period against the current grace period.
Enter and Leave Dynticks Idle Mode
The scheduler invokes rcu_enter_nohz() to
enter dynticks-idle mode, and invokes rcu_exit_nohz()
to exit it.
The rcu_enter_nohz() function increments a per-CPU
dynticks_nesting variable and
also a per-CPU dynticks counter, the latter of which which must
then have an even-numbered value.
The rcu_exit_nohz() function decrements this same
per-CPU dynticks_nesting variable,
and again increments the per-CPU dynticks
counter, the latter of which must then have an odd-numbered value.
The dynticks counter can be sampled by other CPUs.
If the value is even, the first CPU is in an extended quiescent state.
Similarly, if the counter value changes during a given grace period,
the first CPU must have been in an extended quiescent state at some
point during the grace period.
However, there is another dynticks_nmi per-CPU variable
that must also be sampled, as will be discussed below.
Interrupt from Dynticks Idle Mode
Interrupts from dynticks idle mode are handled by
rcu_irq_enter() and rcu_irq_exit().
The rcu_irq_enter() function increments the
per-CPU dynticks_nesting variable, and, if the prior
value was zero, also increments the dynticks
per-CPU variable (which must then have an odd-numbered value).
The rcu_irq_exit() function decrements the
per-CPU dynticks_nesting variable, and, if the new
value is zero, also increments the dynticks
per-CPU variable (which must then have an even-numbered value).
Note that entering an irq handler exits dynticks idle mode and vice versa. This enter/exit anti-correspondence can cause much confusion. You have been warned.
NMI from Dynticks Idle Mode
NMIs from dynticks idle mode are handled by rcu_nmi_enter()
and rcu_nmi_exit().
These functions both increment the dynticks_nmi counter,
but only if the aforementioned dynticks counter is even.
In other words, NMI's refrain from manipulating the
dynticks_nmi counter if the NMI occurred in non-dynticks-idle
mode or within an interrupt handler.
The only difference between these two functions is the error checks,
as rcu_nmi_enter() must leave the dynticks_nmi
counter with an odd value, and rcu_nmi_exit() must leave
this counter with an even value.
Note That a CPU is in Dynticks Idle Mode
The force_quiescent_state() function implements a
two-phase state machine.
In the first phase (RCU_SAVE_DYNTICK), the
dyntick_save_progress_counter() function scans the CPUs that
have not yet reported a quiescent state, recording their per-CPU
dynticks and dynticks_nmi counters.
If these counters both have even-numbered values, then the corresponding
CPU is in dynticks-idle state, which is therefore noted as an extended
quiescent state (reported via cpu_quiet_msk()).
In the second phase (RCU_FORCE_QS), the
rcu_implicit_dynticks_qs() function again scans the CPUs
that have not yet reported a quiescent state (either explicitly or
implicitly during the RCU_SAVE_DYNTICK phase), again checking the
per-CPU dynticks and dynticks_nmi counters.
If each of these has either changed in value or is now even, then
the corresponding CPU has either passed through or is now in dynticks
idle, which as before is noted as an extended quiescent state.
If rcu_implicit_dynticks_qs() finds that a given CPU
has neither been in dynticks idle mode nor reported a quiescent state,
it invokes rcu_implicit_offline_qs(), which checks to see
if that CPU is offline, which is also reported as an extended quiescent
state.
If the CPU is online, then rcu_implicit_offline_qs() sends
it a reschedule IPI in an attempt to remind it of its duty to report
a quiescent state to RCU.
Note that force_quiescent_state() does not directly
invoke either dyntick_save_progress_counter() or
rcu_implicit_dynticks_qs(), instead passing these functions
to an intervening rcu_process_dyntick() function that
abstracts out the common code involved in scanning the CPUs and reporting
extended quiescent states.
Quick Quiz 8: And what happens if one CPU comes out of dyntick-idle mode and then passed through a quiescent state just as another CPU notices that the first CPU was in dyntick-idle mode? Couldn't they both attempt to report a quiescent state at the same time, resulting in confusion?
Quick Quiz 9: But what if all the CPUs end up in dyntick-idle mode? Wouldn't that prevent the current RCU grace period from ever ending?
Quick Quiz 10:
Given that force_quiescent_state() is a two-phase state
machine, don't we have double the scheduling latency due to scanning
all the CPUs?
Offline a CPU
CPU-offline events cause rcu_cpu_notify() to invoke
rcu_offline_cpu(), which in turn invokes
__rcu_offline_cpu() on both the rcu and the rcu_bh
instances of the data structures.
This function clears the outgoing CPU's bits so that future grace
periods will not expect this CPU to announce quiescent states,
and further invokes cpu_quiet() in order to announce
the offline-induced extended quiescent state.
This work is performed with the global ->onofflock
held in order to prevent interference with concurrent grace-period
initialization.
Quick Quiz 11:
But the other reason to hold ->onofflock is to prevent
multiple concurrent online/offline operations, right?
Online a CPU
CPU-online events cause rcu_cpu_notify() to invoke
rcu_online_cpu(), which initializes the incoming CPU's
dynticks state, and then invokes rcu_init_percpu_data()
to initialize the incoming CPU's rcu_data structure,
and also to set this CPU's bits (again protected by
the global ->onofflock) so that future grace periods
will wait for a quiescent state from this CPU.
Finally, rcu_online_cpu()
sets up the RCU softirq vector for this CPU.
Quick Quiz 12:
Given all these acquisitions of the global ->onofflock, won't there
be horrible lock contention when running with thousands of CPUs?
Detect a Too-Long Grace Period
When the CONFIG_RCU_CPU_STALL_DETECTOR kernel parameter
is specified, the record_gp_stall_check_time() function
records the time and also a timestamp set three seconds into the future.
If the current grace period still has not ended by that time, the
check_cpu_stall() function will check for the culprit,
invoking print_cpu_stall() if the current CPU is the
holdout, or print_other_cpu_stall() if it is some other CPU.
A two-jiffies offset helps ensure that CPUs report on themselves
when possible, taking advantage of the fact that a CPU can normally
do a better job of tracing its own stack than it can tracing some other
CPU's stack.
Testing
RCU is fundamental synchronization code, so any failure of RCU results in random, difficult-to-debug memory corruption. It is therefore extremely important that RCU be highly reliable. Some of this reliability stems from careful design, but at the end of the day we must also rely on heavy stress testing, otherwise known as torture.
Fortunately, although there has been some debate as to exactly what populations are covered by the provisions of the Geneva Convention, it is still the case that it does not apply to software. Therefore, it is still legal to torture your software. In fact, it is strongly encouraged, because if you don't torture your software, it will end up torturing you by crashing at the most inconvenient times imaginable.
Therefore, we torture RCU quite vigorously using the rcutorture module.
However, it is not sufficient to torture the common-case uses of RCU.
It is also necessary to torture it in unusual situations, for example,
when concurrently onlining and offlining CPUs and when CPUs are concurrently
entering and exiting dynticks idle mode.
I use a
script to online and offline CPUs,
and use the test_no_idle_hz module parameter to rcutorture
to stress-test dynticks idle mode.
Just to be fully paranoid, I sometimes run a kernbench workload in parallel
as well.
Ten hours of this sort of torture on a 128-way machine seems sufficient
to shake out most bugs.
Even this is not the complete story. As Alexey Dobriyan and Nick Piggin demonstrated in early 2008, it is also necessary to torture RCU with all relevant combinations of kernel parameters. The relevant kernel parameters may be identified using yet another script, and are as follows:
-
CONFIG_CLASSIC_RCU: Classic RCU. -
CONFIG_PREEMPT_RCU: Preemptable (real-time) RCU. -
CONFIG_TREE_RCU: Classic RCU for huge SMP systems. -
CONFIG_RCU_FANOUT: Number of children for eachrcu_node. -
CONFIG_RCU_FANOUT_EXACT: Balance thercu_nodetree. -
CONFIG_HOTPLUG_CPU: Allow CPUs to be offlined and onlined. -
CONFIG_NO_HZ: Enable dyntick-idle mode. -
CONFIG_SMP: Enable multi-CPU operation. -
CONFIG_RCU_CPU_STALL_DETECTOR: Enable RCU to detect when CPUs go on extended quiescent-state vacations. -
CONFIG_RCU_TRACE: Generate RCU trace files in debugfs.
We ignore the CONFIG_DEBUG_LOCK_ALLOC configuration
variable under the perhaps-naive assumption that hierarchical RCU
could not have broken lockdep.
There are still 10 configuration variables, which would result in
1,024 combinations if they were independent boolean variables.
Fortunately the first three are mutually exclusive, which reduces
the number of combinations down to 384, but CONFIG_RCU_FANOUT
can take on values from 2 to 64, increasing the number of combinations
to 12,096.
This is an infeasible number of combinations.
One key observation is that only CONFIG_NO_HZ
and CONFIG_PREEMPT can be expected to have changed behavior
if either CONFIG_CLASSIC_RCU or
CONFIG_PREEMPT_RCU are in effect, as only these portions
of the two pre-existing RCU implementations were changed during this effort.
This cuts out almost two thirds of the possible combinations.
Furthermore, not all of the possible values of
CONFIG_RCU_FANOUT produce significantly different results,
in fact only a few cases really need to be tested separately:
- Single-node “tree”.
- Two-level balanced tree.
- Three-level balanced tree.
- Autobalanced tree, where
CONFIG_RCU_FANOUTspecifies an unbalanced tree, but such that it is auto-balanced in absence ofCONFIG_RCU_FANOUT_EXACT. - Unbalanced tree.
Looking further, CONFIG_HOTPLUG_CPU makes sense only
given CONFIG_SMP, and CONFIG_RCU_CPU_STALL_DETECTOR
is independent, and really only needs to be tested once (though someone
even more paranoid than am I might decide to test it both with
and without CONFIG_SMP).
Similarly, CONFIG_RCU_TRACE need only be tested once,
but the truly paranoid (such as myself) will choose to run it both with
and without CONFIG_NO_HZ.
This allows us to obtain excellent coverage of RCU with only 15
test cases.
All test cases specify the following configuration parameters in order
to run rcutorture and so that CONFIG_HOTPLUG_CPU=n actually
takes effect:
CONFIG_RCU_TORTURE_TEST=m CONFIG_MODULE_UNLOAD=y CONFIG_SUSPEND=n CONFIG_HIBERNATION=n
The 15 test cases are as follows:
- Force single-node “tree” for small systems:
CONFIG_NR_CPUS=8 CONFIG_RCU_FANOUT=8 CONFIG_RCU_FANOUT_EXACT=n CONFIG_RCU_TRACE=y
- Force two-level tree for large systems:
CONFIG_NR_CPUS=8 CONFIG_RCU_FANOUT=4 CONFIG_RCU_FANOUT_EXACT=n CONFIG_RCU_TRACE=n
- Force three-level tree for huge systems:
CONFIG_NR_CPUS=8 CONFIG_RCU_FANOUT=2 CONFIG_RCU_FANOUT_EXACT=n CONFIG_RCU_TRACE=y
- Test autobalancing to a balanced tree:
CONFIG_NR_CPUS=8 CONFIG_RCU_FANOUT=6 CONFIG_RCU_FANOUT_EXACT=n CONFIG_RCU_TRACE=y
- Test unbalanced tree:
CONFIG_NR_CPUS=8 CONFIG_RCU_FANOUT=6 CONFIG_RCU_FANOUT_EXACT=y CONFIG_RCU_CPU_STALL_DETECTOR=y CONFIG_RCU_TRACE=y
- Disable CPU-stall detection:
CONFIG_SMP=y CONFIG_NO_HZ=y CONFIG_RCU_CPU_STALL_DETECTOR=n CONFIG_HOTPLUG_CPU=y CONFIG_RCU_TRACE=y
- Disable CPU-stall detection and dyntick idle mode:
CONFIG_SMP=y CONFIG_NO_HZ=n CONFIG_RCU_CPU_STALL_DETECTOR=n CONFIG_HOTPLUG_CPU=y CONFIG_RCU_TRACE=y
- Disable CPU-stall detection and CPU hotplug:
CONFIG_SMP=y CONFIG_NO_HZ=y CONFIG_RCU_CPU_STALL_DETECTOR=n CONFIG_HOTPLUG_CPU=n CONFIG_RCU_TRACE=y
- Disable CPU-stall detection, dyntick idle mode, and CPU hotplug:
CONFIG_SMP=y CONFIG_NO_HZ=n CONFIG_RCU_CPU_STALL_DETECTOR=n CONFIG_HOTPLUG_CPU=n CONFIG_RCU_TRACE=y
- Disable SMP, CPU-stall detection, dyntick idle mode, and CPU hotplug:
CONFIG_SMP=n CONFIG_NO_HZ=n CONFIG_RCU_CPU_STALL_DETECTOR=n CONFIG_HOTPLUG_CPU=n CONFIG_RCU_TRACE=y
This combination located a number of compiler warnings.
- Disable SMP and CPU hotplug:
CONFIG_SMP=n CONFIG_NO_HZ=n CONFIG_RCU_CPU_STALL_DETECTOR=n CONFIG_HOTPLUG_CPU=n CONFIG_RCU_TRACE=y
- Test Classic RCU with dynticks idle but without preemption:
CONFIG_NO_HZ=y CONFIG_PREEMPT=n CONFIG_RCU_TRACE=y
- Test Classic RCU with preemption but without dynticks idle:
CONFIG_NO_HZ=n CONFIG_PREEMPT=y CONFIG_RCU_TRACE=y
- Test Preemptable RCU with dynticks idle:
CONFIG_NO_HZ=y CONFIG_PREEMPT=y CONFIG_RCU_TRACE=y
- Test Preemptable RCU without dynticks idle:
CONFIG_NO_HZ=n CONFIG_PREEMPT=y CONFIG_RCU_TRACE=y
For a large change that affects RCU core code, one should run
rcutorture for each of the above combinations, and concurrently
with CPU offlining and onlining for cases with
CONFIG_HOTPLUG_CPU.
For small changes, it may suffice to run kernbench in each case.
Of course, if the change is confined to a particular subset of
the configuration parameters, it may be possible to reduce the
number of test cases.
Torturing software: the Geneva Convention does not (yet) prohibit it, and I strongly recommend it!!!
Conclusion
This hierarchical implementation of RCU reduces lock contention, avoids unnecessarily awakening dyntick-idle sleeping CPUs, while helping to debug Linux's hotplug-CPU code paths. This implementation is designed to handle single systems with thousands of CPUs, and on 64-bit systems has an architectural limitation of a quarter million CPUs, a limit I expect to be sufficient for at least the next few years.
This RCU implementation of course has some limitations:
- The
force_quiescent_state()can scan the full set of CPUs with irqs disabled. This would be fatal in a real-time implementation of RCU, so if hierarchy ever needs to be introduced to preemptable RCU, some other approach will be required. It is possible that it will be problematic on 4,096-CPU systems, but actual testing on such systems is required to prove this one way or the other.On busy systems, the
force_quiescent_state()scan would not be expected to happen, as CPUs should pass through quiescent states within three jiffies of the start of a quiescent state. On semi-busy systems, only the CPUs in dynticks-idle mode throughout would need to be scanned. In some cases, for example when a dynticks-idle CPU is handling an interrupt during a scan, subsequent scans are required. However, each such scan is performed separately, so scheduling latency is degraded by the overhead of only one such scan.If this scan proves problematic, one straightforward solution would be to do the scan incrementally. This would increase code complexity slightly and would also increase the time required to end a grace period, but would nonetheless be a likely solution.
- The
rcu_nodehierarchy is created at compile time, and is therefore sized for the worst-caseNR_CPUSnumber of CPUs. However, even for 4,096 CPUs, thercu_nodehierarchy consumes only 65 cache lines on a 64-bit machine (and just you try accommodating 4,096 CPUs on a 32-bit machine!). Of course, a kernel built withNR_CPUS=4096running on a 16-CPU machine would use a two-level tree when a single-node tree would work just fine. Although this configuration would incur added locking overhead, this does not affect hot-path read-side code, so should not be a problem in practice. - This patch does increase kernel text and data somewhat:
the old Classic RCU implementation consumes 1,757 bytes of
kernel text and 456 bytes of kernel data for a total of 2,213 bytes,
while the new hierarchical RCU implementation consumes 4,006
bytes of kernel text and 624 bytes of kernel data for a total
of 4,630 bytes on a
NR_CPUS=4system. This is a non-problem even for most embedded systems, which often come with hundreds of megabytes of main memory. However, if this is a problem for tiny embedded systems, it may be necessary to provide both “scale up” and “scale down” implementations of RCU.
This hierarchical RCU implementation should nevertheless be a vast improvement over Classic RCU for machines with hundreds of CPUs. After all, Classic RCU was designed for systems with only 16-32 CPUs.
At some point, it may be necessary to also apply hierarchy to the preemptable RCU implementation. This will be challenging due to the modular arithmetic used on the per-CPU counter pairs, but should be doable.
Acknowledgements
I am indebted to Manfred Spraul for ideas, review comments, bugs spotted, as well as some good healthy competition, to Josh Triplett, Ingo Molnar, Peter Zijlstra, Mathieu Desnoyers, Lai Jiangshan, Andi Kleen, Andy Whitcroft, Gautham Shenoy, and Andrew Morton for review comments, and to Thomas Gleixner for much help with timer issues. I am thankful to Jon M. Tollefson, Tim Pepper, Andrew Theurer, Jose R. Santos, Andy Whitcroft, Darrick Wong, Nishanth Aravamudan, Anton Blanchard, and Nathan Lynch for keeping machines alive despite my (ab)use for this project. We all owe thanks to Peter Zijlstra, Gautham Shenoy, Lai Jiangshan, and Manfred Spraul for helping (in some cases unwittingly) render this document at least partially human readable. Finally, I am grateful to Kathy Bennett for her support of this effort.
This work represents the view of the authors and does not necessarily represent the view of IBM.
Linux is a registered trademark of Linus Torvalds.
Other company, product, and service names may be trademarks or service marks of others.
Answers to Quick Quizzes
Quick Quiz 1: Wait a minute! With all those new locks, how do you avoid deadlock?
Answer:
Deadlock is avoided by never holding more than one of the
rcu_node structures' locks at a given time.
This algorithm uses two more locks, one to prevent CPU hotplug operations
from running concurrently with grace-period advancement
(onofflock) and another
to permit only one CPU at a time from forcing a quiescent state
to end quickly (fqslock).
These are subject to a locking hierarchy, so that
fqslock must be acquired before
onofflock, which in turn must be acquired before
any of the rcu_node structures' locks.
Also, as a practical matter, refusing to ever hold more than
one of the rcu_node locks means that it is unnecessary
to track which ones are held.
Such tracking would be painful as well as unnecessary.
Quick Quiz 2: Why stop at a 64-times reduction? Why not go for a few orders of magnitude instead?
Answer: RCU works with no problems on systems with a few hundred CPUs, so allowing 64 CPUs to contend on a single lock leaves plenty of headroom. Keep in mind that these locks are acquired quite rarely, as each CPU will check in about one time per grace period, and grace periods extend for milliseconds.
Quick Quiz 3: But I don't care about McKenney's lame excuses in the answer to Quick Quiz 2!!! I want to get the number of CPUs contending on a single lock down to something reasonable, like sixteen or so!!!
Answer:
OK, have it your way, then!!!
Set CONFIG_RCU_FANOUT=16 and (for NR_CPUS=4096)
you will get a
three-level hierarchy with with 256 rcu_node structures
at the lowest level, 16 rcu_node structures as intermediate
nodes, and a single root-level rcu_node.
The penalty you will pay is that more rcu_node structures
will need to be scanned when checking to see which CPUs need help
completing their quiescent states (256 instead of only 64).
Quick Quiz 4: OK, so what is the story with the colors?
Answer:
Data structures analogous to rcu_state (including
rcu_ctrlblk) are yellow,
those containing the bitmaps used to determine when CPUs have checked
in are pink,
and the per-CPU rcu_data structures are blue.
Later on, we will see that data structures used to conserve energy
(such as rcu_dynticks) will be green.
Quick Quiz 5: Given such an egregious bug, why does Linux run at all?
Answer: Because the Linux kernel contains device drivers that are (relatively) well behaved. Few if any of them spin in RCU read-side critical sections for the many milliseconds that would be required to provoke this bug. The bug nevertheless does need to be fixed, and this variant of RCU does fix it.
Quick Quiz 6: But what happens if a CPU tries to report going through a quiescent state (by clearing its bit) before the bit-setting CPU has finished?
Answer: There are three cases to consider here:
- A CPU corresponding to a non-yet-initialized leaf
rcu_nodestructure tries to report a quiescent state. This CPU will see its bit already cleared, so will give up on reporting its quiescent state. Some later quiescent state will serve for the new grace period. - A CPU corresponding to a leaf
rcu_nodestructure that is currently being initialized tries to report a quiescent state. This CPU will see that thercu_nodestructure's->lockis held, so will spin until it is released. But once the lock is released, thercu_nodestructure will have been initialized, reducing to the following case. - A CPU corresponding to a leaf
rcu_nodethat has already been initialized tries to report a quiescent state. This CPU will find its bit set, and will therefore clear it. If it is the last CPU for that leaf node, it will move up to the next level of the hierarchy. However, this CPU cannot possibly be the last CPU in the system to report a quiescent state, given that the CPU doing the initialization cannot yet have checked in.
So, in all three cases, the potential race is resolved correctly.
Quick Quiz 7: And what happens if all CPUs try to report going through a quiescent state before the bit-setting CPU has finished, thus ending the new grace period before it starts?
Answer: The bit-setting CPU cannot pass through a quiescent state during initialization, as it has irqs disabled. Its bits therefore remain non-zero, preventing the grace period from ending until the data structure has been fully initialized.
Quick Quiz 8: And what happens if one CPU comes out of dyntick-idle mode and then passed through a quiescent state just as another CPU notices that the first CPU was in dyntick-idle mode? Couldn't they both attempt to report a quiescent state at the same time, resulting in confusion?
Answer:
They will both attempt to acquire the lock on the same leaf
rcu_node structure.
The first one to acquire the lock will report the quiescent state
and clear the appropriate bit, and the second one to acquire the
lock will see that this bit has already been cleared.
Quick Quiz 9: But what if all the CPUs end up in dyntick-idle mode? Wouldn't that prevent the current RCU grace period from ever ending?
Answer: Indeed it will! However, CPUs that have RCU callbacks are not permitted to enter dyntick-idle mode, so the only way that all the CPUs could possibly end up in dyntick-idle mode would be if there were absolutely no RCU callbacks in the system. And if there are no RCU callbacks in the system, then there is no need for the RCU grace period to end. In fact, there is no need for the RCU grace period to even start.
RCU will restart if some irq handler does a call_rcu(),
which will cause an RCU callback to appear on the corresponding CPU,
which will force that CPU out of dyntick-idle mode, which will in turn
permit the current RCU grace period to come to an end.
Quick Quiz 10:
Given that force_quiescent_state() is a two-phase state
machine, don't we have double the scheduling latency due to scanning
all the CPUs?
Answer: Ah, but the two phases will not execute back-to-back on the same CPU. Therefore, the scheduling-latency hit of the two-phase algorithm is no different than that of a single-phase algorithm. If the scheduling latency becomes a problem, one approach would be to recode the state machine to scan the CPUs incrementally. But first show me a problem in the real world, then I will consider fixing it!
Quick Quiz 11:
But the other reason to hold ->onofflock is to prevent
multiple concurrent online/offline operations, right?
Answer:
Actually, no!
The CPU-hotplug code's synchronization design prevents multiple
concurrent CPU online/offline operations, so only one CPU online/offline
operation can be executing at any given time.
Therefore, the only purpose of ->onofflock is to prevent a CPU
online or offline operation from running concurrently with grace-period
initialization.
Quick Quiz 12:
Given all these acquisitions of the global ->onofflock,
won't there
be horrible lock contention when running with thousands of CPUs?
Answer: Actually, there can be only three acquisitions of this lock per grace period, and each grace period lasts many milliseconds. One of the acquisitions is by the CPU initializing for the current grace period, and the other two onlining and offlining some CPU. These latter two cannot run concurrently due to the CPU-hotplug locking, so at most two CPUs can be contending for this lock at any given time.
Lock contention on ->onofflock should therefore
be no problem, even on systems with thousands of CPUs.
Patches and updates
Kernel trees
Architecture-specific
Core kernel code
Development tools
Device drivers
Documentation
Filesystems and block I/O
Memory management
Networking
Security-related
Virtualization and containers
Benchmarks and bugs
Miscellaneous
Page editor: Jonathan Corbet
Distributions
News and Editorials
Interview with the openSUSE board
The openSUSE project recently welcomed the first community elected board. The previous board was appointed by Novell. The new board consists of both Novell employees and non-Novell members of the community. From the Non-Novell side of the community Pascal Bleser and Bryen Yunashko were elected, and from the Novell side Henne Vogelsang and Federico Mena-Quintero were elected. Novell appointed Michael Löffler as chairman of the board. We asked the new board a few questions and are pleased to present their responses.LWN: There was some discussion in the mailing lists prior to the election about the definition of a member. The current definition says: "openSUSE Members" are specifically distinguished contributors who have brought a continued and substantial contribution to the openSUSE project."
Do you agree with this definition? What is your definition of "continued and substantial"?
LWN: Does Novell adequately support openSUSE? Should Novell do more to support the project?
LWN: Does Novell exert too much control over the project? Where are the areas where Novell could allow more community control?
There are still a few areas where we're still at the beginning of opening up (actually rather at the point of starting to think about ways to do that properly), such as having non-Novell employees co-maintain core distribution packages or the openSUSE reference guide. As said, it's in flux, and certain things take time, but Novell definitely hasn't been standing in the way, quite the contrary. And while Novell ultimately has the most resources in certain or even most areas of the project, especially in building the distribution and providing security maintenance during the openSUSE release lifetime, there is always room for discussion.
One notable example was the thread about whether KDE 3 should be removed from openSUSE 11.1, as KDE 4 is where almost all KDE developers put their efforts in. At first, Novell's product management position was to drop KDE 3 because it would mean supporting it for 2 years. But the discussion lead to a compromise, as many believe that KDE 4 wasn't quite ready enough. In the end, openSUSE 11.1 will still have KDE 3, but KDE 3 will be dropped in 11.2. The KDE3 maintenance during the lifetime of openSUSE 11.1 will be taken care of by Novell employees. So, again, while Novell commits most of the resources, the opinion of the community is important to them, for obvious reasons.
LWN: Is the current board, with 5 members (2 Novell + 3 non), a good size and does it achieve the right balance of corporate vs. community?
I can also imagine that at some point, that differentiation between Novell employee and non-Novell employee Board position shall be removed. Remember that it is our first elected Board. We take some decision and define some processes because we believe that they offer a good balance. Actually, the idea behind that separation was to make sure that there were two seats occupied by non-Novell employees (and not less).
We understand that this is a controversial topic. But you shouldn't get too theoretical while reflecting upon it. It is very tempting but this is a total non-issue in reality. We are not trying to find the best theoretical possibility to govern a project. We are hackers that try to get things done.
LWN: In the openSUSE election members were able to name another contributor (non-member) to be a voter. Would you like to see this continue in future elections? Do you know if there were many non-members who voted in this election?
LWN: How do regular users get more involved? How can they contribute to both the technical work and the decision making?
To contribute to our documentation go and help organizing and authoring in our Wiki. To help to translate the openSUSE distribution into your language join one of our various translation teams and translate strings to your native language.
To contribute to the distribution use the openSUSE Build service. And those are just the four main entrances into our project. You can have it as specialized as helping openSUSE HAM users to transmit via radio, spinning your own version of openSUSE for educational use or create artwork to be included in the distribution. The same holds true for decision making. All of the different areas make their own decisions. So to influence decisions you go there, participate and voice your opinion.
Decisions that concern the overall project are always discussed at the opensuse-project mailing list or are a topic in the bi-weekly opensuse-project meeting. So you just go there and do the same. It is really as simple as that.
Users can become members through advocacy, promoting openSUSE regularly at local events, getting online and providing support to new users in IRC and the forums. It's really not that difficult to become a member and you don't have to be a technical genius to become a member.
LWN: Do you see areas of collaboration with other distributions either currently or in the future?
While openSUSE is definitely a brilliant distribution in many regards and while we have a healthy community that consists of great people, we still have a lot to do, and so do the other distribution projects. They're not less good nor less deserving, we all have our strengths and weaknesses, so we should work together to make Linux and FOSS a better experience to everyone. If you're feeling at home with another distribution, great, contribute there! And if you think you'd like to contribute to our distribution or to our community, you are definitely welcome here too. And if you believe there are domains where we can work together, please get in touch with us at board -AT- opensuse.org.
Editor's note: We would like to thank the openSUSE Board for taking the time to answer our questions. Readers may notice that not all board members have answered every question. This was their choice and not due to any censorship on our part.
New Releases
Fedora 10 preview release
The Fedora 10 preview release is now available. "Doesn't it smell yummy? We know you can't resist, and we don't want you to. We want everyone in the Fedora community to take an early sample and tell us what you find. The recipe is pretty good, but now is the time to make it perfect." This is the last testing release for this cycle. See the release notes for an overview of what Fedora 10 brings.
Announcing Fedora Sugar Spin!
Fedora has a Sugar Spin available, which incorporates the Sugar Desktop Environment on a Fedora Live CD. "So, what is this in specific? With this spin, you'll be able to run Sugar, which is developed by Sugarlabs and the desktop environment used on the OLPC, directly from a Live CD!"
OpenBSD 4.4 released, Nov 1. Enjoy!
The OpenBSD project has announced the official release of OpenBSD 4.4. Click below for a list of new features, new platform support and more.openSUSE 11.1 Beta 4 Now Available
The openSUSE Project has announced the availability of openSUSE 11.1 beta 4. "This release includes a number of important bugfixes since the last beta, as well as a few new bugs that need to be squashed before the final release. Read on for details about this release and how to get involved with testing."
With the release of openSUSE 11.1 Beta4 comes a call for feature testing.
Red Hat Delivers Red Hat Enterprise Linux 5.3 Beta
Red Hat has released the Beta of Red Hat Enterprise Linux 5.3. This version has kernel-2.6.18-120.el5 and includes versions for x86, x86/64, Itanium, IBM POWER and System z. The Beta runs until January 6, 2009.
The CentOS community has issued
a call for testing of this release. "So if we can improve the
testing during the RHEL Beta program, everyone in the CentOS community
directly benefits from that as well. Therefore it makes a lot of sense to
encourage the large CentOS community to take part in the RHEL Beta program
and help with improving the next CentOS releases.
"
Tin Hat Linux 20081025 released
A new release of Tin Hat Linux is out, with bugs/security fixes.Ubuntu 8.10 has been released
Ubuntu 8.10 "Intrepid Ibex" has been released. "The Ubuntu team is pleased to announce Ubuntu 8.10 Desktop and Server, continuing Ubuntu's tradition of integrating the latest and greatest open source technologies into a high-quality, easy-to-use Linux distribution."
Distribution News
Fedora
RPM Fusion is now Available
The RPM Fusion project has announced the availability of its repositories of Fedora and Red Hat compatible software. "RPM Fusion is a project started by the Dribble, Freshrpms and Livna teams. It aims to bring together many packagers from various 3rd party repositories and build a single add-on repository for Fedora and Red Hat Enterprise Linux. We hope to attract new Fedora packagers and hope that other 3rd party repositories will join us." Click below for the full announcement.
Announcing Fedora IRC Classroom Sessions
The #fedora-classroom irc channel (on irc.freenode.net) will be open soon for some classroom sessions. "These sessions are intended to be short (30min to an hour) sessions on the IRC network where you can learn about a specific Fedora related topic." Check the schedule to see what topics will be offered.
Fedora Board Recap
Click below for a brief recap of the October 28, 2008 meeting of the Fedora Board. Topics include Trademark guidelines, Fedora Sugar Spin, Upcoming Elections, and FUDCon Fedora 11.FESCo Meeting Summary for 2008-10-29
Click below for a summary of the Fedora Engineering Steering Committee meeting for October 29, 2008. Topics include features, elections and comps.
SUSE Linux and openSUSE
Advance discontinuation notice of Service Pack 1 of SUSE Linux Enterprise 10
SUSE Security has announced that the maintenance, security and L3 support for Service Pack 1 of the SUSE Linux Enterprise 10 line of products will end November 30, 2008. "We recommend strongly that customers upgrade now to Service Pack 2 of SUSE Linux Enterprise 10."
Ubuntu family
The Ubuntu "Jaunty Jackalope" cycle begins
The Ubuntu Project has started the development cycle leading up to the 9.04 release, currently planned for April 23. "We do not recommend that users upgrade to Jaunty at this time; it is likely to be in very considerable flux until the initial round of merges is complete. As ever, any developers wishing to take the plunge at this early stage should ensure that they are comfortable with recovering from anything up to complete system failure."
Distribution Newsletters
DistroWatch Weekly, Issue 277
The DistroWatch Weekly for November 3, 2008 is out. "It was the Ubuntu week, with much of the Linux-related coverage on many web sites dominated by the brand new "Intrepid Ibex", the project's latest. A plethora of reviews followed almost instantly, but some subtle hardware issues and lack of real breakthrough features have left some of the users and reviewers unimpressed. In other news, Fedora has unveiled Plymouth, a new flicker-free boot process, Sabayon has hinted at a large number of never-seen-before features for the upcoming 4.0 release, Yellow Dog Linux has launched a beta testing period for its forthcoming version 6.1, and NetBSD is about to branch version 5.0 with some unexpected improvements. Also in this week's issue - Ubuntu has published a draft release schedule for "Jaunty Jackalope" or Ubuntu 9.04. Finally, we are pleased to announce that the recipient of the October 2008 DistroWatch.com donation is GoblinX, a slick Slackware-based live CD made in Brazil."
Echo Monthly News - Issue 3
The Echo Monthly News for October 2008 is out, covering the news about Fedora's Echo Theme. Topics include new icons, new templates, Echo Won't Be F10's Default Icon Theme, Icon Check Script and Echo Future.Fedora Weekly News #150
The Fedora Weekly News for November 2, 2008 is out. "In this week's issue, featured content includes announcements on a new Fedora Sugar Spin, and development freeze for Fedora 10. The Translation beat this week features an interview with Fedora Translation project member Diego Zacarao (Rasther). In Developments, details on resume from suspend problems with Intel i945s, details on "[a] gigantic multi-thread flamewar consum[ing] many list participants" over moving X from VT7 to VT1 and POSIX file capabilities for Fedora 11. The Artwork beat features discussion of new wallpaper extras, and final fixes for the Fedora 10 Solar backgrounds. The Security Advisory beat rounds out this issue and updates us with fixes released in the last week for Fedora 8 and 9."
OpenSUSE Weekly News/44
This issue of the OpenSUSE Weekly News looks at Less then 50 days to openSUSE 11.1, Results of the 1st openSUSE Board Election, Ben Kevan: fslint - Take control about your Filesystem, OpenOffice.org 3.0 final, counter.opensuse.org updated, and more.Ubuntu Weekly Newsletter #115
The Ubuntu Weekly Newsletter for November 1, 2008 covers: Ubuntu 8.10 released, Ubuntu 8.10: significant new features, UDSJaunty, Ubuntu Open Week, New Contributing Developer, Dustin Kirkland interview #2, Ubuntu Brainstorm 8.10 report, SFD in Tunisia, Launchpad EPIC, Over 6 million Forum posts and counting, Ubuntu Sighting, Full Circle Magazine #18, New TurnKey Linux release, Release week for Ubuntu and CohesiveFT, and much more.
Distribution meetings
Ubuntu Open Week!
Ubuntu Open Week starts next Monday, November 3. "Ubuntu Open Week is a week of IRC tuition and Q+A sessions all about getting involved in the rock-and-roll world that is the Ubuntu community. We organise this week for the beginning of a new release cycle to help new contributors get involved. Thanks to Jorge for helping to get the week together and for everyone who is helping to run sessions. Its going to be a fun week!" Tune into #ubuntu-classroom on Freenode to join in the fun.
Newsletters and articles of interest
A Closer Look At Red Hat's Plymouth (Phoronix)
Phoronix takes a look at Plymouth, a flicker-free boot process previewing in Fedora 10. "Plymouth has an extensive API that allows artists and programmers to develop graphically rich Plymouth plug-ins. Plymouth is, however, compiled into the system's initial RAM disk (initrd) so there are some limitations. Plug-ins though can rely on loading PNG images as libpng is linked to Plymouth. The plug-ins currently available through the project's git repository currently include details, fade-in, pulser, solar, spinfinity, and text. These plug-ins are also packaged in RPM form on Fedora 10. The Fedora 10 RPMs include plymouth (the main graphical boot package), plymouth-devel (the libraries and headers), plymouth-gdm-hooks (provides integrated with GDM), plymouth-libs (the Plymouth libraries), plymouth-plugin-fade-in, plymouth-plugin-label, plymouth-plugin-pulser, plymouth-plugin-solar, plymouth-plugin-spinfinity, plymouth-scripts (scripts to assist in configuring Plymouth), plymouth-text-and-details-only (intended for those not interested in a rich boot experience), and plymouth-utils (utilities related to Plymouth)."
GSoC Mentor Summit wrap-up
Joe "Zonker" Brockmeir reports on the Google Summer of Code Mentor's Summit. "Overall, I think the FOSS community in general, and distros in particular, are pretty good at being willing to communicate and work together -- the fall-down comes in when a contributor from Project A doesn't know who to contact with Project B. (Hint: Start with the project leader or community manager if you don't know who to start with_) One of the larger discussions was -- how do projects get picked for GSoC and how do projects get passed over."
Distribution reviews
Ubuntu 8.10 Charges Up the Mountain (Linux Journal)
Linux Journal takes a look at the final release of Ubuntu 8.10 "Intrepid Ibex". "Among Intrepid's shiny new packages are upgrades to core portions of the operating system including the kernel itself, which has been updated to the 2.6.27 release. The latest version of X.Org, 7.4, which appeared in September after months of repeated delays, is included, and boasts improved hot-plugging for keyboards, mice, and other input peripherals, a failsafe mechanism to provide better troubleshooting for startup glitches, and for many users, the end of the xorg.conf configuration file."
Kubuntu 8.10 Brings KDE 4 to the Masses (KDE.News)
KDE.News takes a quick look at Kubuntu 8.10 with KDE 4.1. "The Kubuntu developers have been hard at work, integrating this major new version into a completed desktop. The settings and artwork have been kept close to KDE's defaults to ensure the best face of our favourite desktop shines through."
Page editor: Rebecca Sobol
Development
Linux Connectivity for the Wii Remote
Linux has had support for numerous hand-held infrared remote control devices for many years through the Linux Infra Red Controller (LIRC) drivers. There has been recent work to include LIRC in the kernel. The Nintendo Wii Remote is a more sophisticated remote control that was developed for the Wii game platform, it is accessible through a collection of Linux tools called CWiid. Wikipedia describes the Wii Remote:
The Wiimote hardware capabilities (photo) include:
{kind=link}
- Two-way wireless Bluetooth connectivity to the host.
- A screen-mounted Sensor Bar with multiple IR light sources and a 5 meter range.
- A built-in IR camera with distance and rotation sensing capabilities.
- A three axis accelerometer for detecting hand motions.
- Six general purpose remote control pushbuttons labeled A, -, Home, +, 1 and 2.
- An up-down-left-right four-way pushbutton.
- A power switch.
- Four remote controlled LEDs.
- A built-in speaker for providing audio effects.
- A "rumble" device for producing vibrations.
- Built-in non volatile memory with space for user data.
- A hardware expansion port.
- Powered by two AA cells, can use rechargeable types.
CWiid was written by L. Donnie Smith and has been released under the GPLv2. The project has been around since March, 2007 and is currently at version 0.6.00. The libcwiid API document explains the CWiid software interface.
There are currently at least twelve programs using CWiid. Some of the highlights include control of DMX lighting systems with Wiimote Control, 3D display of chemical structures using the Avogadro molecular editor, the WiiOSC control device for music programs and a newly released prototype Wiimote Control for the Ardour multi-track audio editor. Although the Wiimote control is ideal for use in games, there don't appear to be any such developments under Linux at this point.
One of the more interesting uses of the Wiimote includes Head Tracking for an immersive 3D experience, based on the work of Johnny Chung Lee. This approach to 3D visualization produces full-color displays, unlike the the old-fashioned 3D movie technology that uses glasses with red and green lenses. Other 3D technologies require expensive LCD shutters that tend to produce a lot of flicker. The head tracking 3D technology would be well suited for use by the physically disabled.
New Wiimote devices can be purchased for $40 or less. Many of them exist on the used markets, thanks to the popularity of the Wii platform. If your favorite application could benefit from a two-way wireless remote control device with a wide variety of features, the Wiimote looks like a good choice.
System Applications
Clusters and Grids
JPPF: version 1.6 released (SourceForge)
Version 1.6 of JPPF, the Java Parallel Processing Framework, has been announced. "JPPF is an open source Grid Computing platform written in Java that makes it easy to run applications in parallel, and speed up their execution by orders of magnitude. Write once, deploy once, execute everywhere! The JPPF Team brings new features and bug fixes in this version."
Version 6.1.3 of the UNICORE server and UCC is available (SourceForge)
Version 6.1.3 of the UNICORE server and UCC have been announced. "UNICORE is a modern, Web services and WS-RF based, OGSA-compliant, standards-conform, ready-to-run Grid technology implemented in Java. UNICORE makes distributed computing, data, network, and software resources available in a seamless and secure way."
Database Software
cx_Oracle 4.4.1 released
Version 4.4.1 of cx_Oracle has been announced, a number of new features have been added. "cx_Oracle is a Python extension module that allows access to Oracle and conforms to the Python database API 2.0 specifications with a few exceptions."
IMDbPY 3.8 released
Version 3.8 of IMDbPY has been announced. "IMDbPY is a Python package useful to retrieve and manage the data of the IMDb movie database about movies, people, characters and companies. With this release, it's possible to access the data in the sql database using both the SQLObject and SQLAlchemy ORMs. Many bugs were also fixed."
phpMyAdmin: Security fix: 3.0.1.1 and 2.11.9.3 (SourceForge)
Versions 3.0.1.1 and 2.11.9.3 of phpMyAdmin have been announced. "phpMyAdmin is a tool written in PHP intended to handle the administration of MySQL over the Web. Currently it can create and drop databases, create/drop/alter tables, delete/edit/add fields, execute any SQL statement, manage keys on fields. Welcome to phpMyAdmin versions 2.11.9.3 and 3.0.1.1 which fix a security problem."
PostgreSQL Weekly News
The November 2, 2008 edition of the PostgreSQL Weekly News is online with the latest PostgreSQL DBMS articles and resources.
Networking Tools
ZABBIX: 1.6.1 released (SourceForge)
Version 1.6.1 of ZABBIX has been announced, some new capabilities have been added. "ZABBIX is an enterprise-class open source distributed monitoring solution designed to monitor and track performance and availability of network servers, devices and other IT resources. It supports distributed and WEB monitoring, auto-discovery, and more."
Security
Announcing ClamAV 0.94.1
Version 0.94.1 of ClamAV, a virus scanner, has been announced. "ClamAV 0.94.1 fixes some issues that were found in previous releases and includes one new feature, "Malware Statistics Gathering." This is an optional feature that allows ClamAV users optionally to submit statistics to us about what they detect in the field. We will then use these data to determine what types of malware are the most detected in the field and in what geographic area they are. It will also allow us to publish summary data on www.clamav.net where our users will be able to monitor the latest threats. You can help us by enabling SubmitDetectionStats in freshclam.conf."
sqlmap 0.6.2 has been released
Version 0.6.2 of sqlmap has been announced, it includes major bug fixes. "sqlmap is an automatic SQL injection tool developed in Python. Its goal is to detect and take advantage of SQL injection vulnerabilities on web applications."
Web Site Development
Apache 2.2.10 released
Version 2.2.10 of the Apache web server has been announced. "This version of Apache is principally a bug and security fix release. The following potential security flaws are addressed: * CVE-2008-2939 (cve.mitre.org) mod_proxy_ftp: Prevent XSS attacks when using wildcards in the path of the FTP URL. Discovered by Marc Bevand of Rapid7. We consider this release to be the best version of Apache available, and encourage users of all prior versions to upgrade."
Django 1.0.1 beta is available
Version 1.0.1 beta of the Django web platform has been announced. "Following the previously-announced schedule, today the Django team has released Django 1.0.1 beta 1; this is a preview of the upcoming Django 1.0.1 release, which consists solely of bugfixes and other improvements to the Django 1.0 codebase. This package also follows our policy of maintaining compatibility in the 1.0 release series."
dotCMS: 1.6.5 Released (SourceForge)
Version 1.6.5 of dotCMS has been announced. "dotCMS bridges the gap between php CMSes and J2ee solutions. Included: clustering support, structured content, granular permissions, WYSIWYG editing, events management, e-communications tools. Please visit http://dotcms.org. dotCMS, Inc. is pleased to announce that dotCMS 1.6.5 is available for download. Weve worked hard to make dotCMS 1.6.5 faster, more robust, more feature rich and easier to use. The new 1.6.5 version includes almost 300 improvements and fixes."
Midgard 8.09.2 released
Version 8.09.2 of the Midgard web development platform has been announced. "The Midgard Project has released the second maintenance release of Midgard 8.09 Ragnaroek LTS. Ragnaroek LTS is a Long Term Support version of the free software content management framework. The 8.09.2 release focuses on major performance improvements and ease of upgrade from earlier Midgard 1.8 installations. It is the first maintenance release in the Ragnaroek series that combines both Midgard and MidCOM."
Desktop Applications
Audio Applications
Amarok 2.0 beta 3 released
Version 2.0 beta 3 of the Amarok music player has been announced. "This release is yet another significant step towards the final version. Beta 3 fixes a number of serious bugs and enhances many parts of the application. Some parts underwent significant rewrites in order to fix some deeply rooted problems. All in all, Amarok 2 is now a much more polished application."
Ataksak - Beta 3 of Amarok 2.0 released (KDE.News)
KDE.News briefly looks at Amarok 2.0 beta 3. "The Amarok team announces the third beta release of Amarok 2.0, codename Ataksak. It includes a database importer for users of Amarok 1.4, who want to keep their statistics and ratings, as well as a lot of bugfixes and improvements. The playlist, statusbar and Last.fm integration got a major overhaul and are a lot more stable and polished now."
New features come to Ardour
The Ardour multi-track audio editor recently acquired some new capabilities. Prototype Wiimote Control software has been added: "After languishing for months in the horror of hardware construction and the herding of cats, long-time Ardour developer Sampo Savolainen jumped back in to working on his favorite DAW and added support for the Wiimote as a remote control this past weekend. You just need working bluetooth support on your computer, the right library, and of course a Wiimote."
Also,
MIDI Clock Sync Comes To Ardour 3.0:
"Although Ardour 3.0 is not yet ready for serious testing, it is the subject of some cool development work. Hans Baier just added support for MIDI Clock sync, which means that Ardour's transport can now slave to you MIDI sequencing hardware/software without relying on more sophisticated (and better, but less widely used) protocols like MIDI Machine Control or MIDI Time Code.
"
Desktop Environments
GNOME Software Announcements
The following new GNOME software has been announced this week:- at-spi 1.25.1 (bug fixes)
- bug-buddy 2.25.1 (new features and bug fixes)
- Cheese 2.25.1 (bug fixes and translation work)
- Deskbar-Applet 2.25.1 (bug fixes and translation work)
- Eye of GNOME 2.25.1 (bug fixes, code cleanup and translation work)
- GCalctool 5.25.1 (bug fixes and translation work)
- gnome-applets 2.25.1 (new features, bug fixes and code cleanup)
- The Gnome Chemistry Utils 0.10.0 (new features)
- GNOME DVB daemon 0.1.0 (initial release)
- gnome-games 2.24.1.1 (bug fixes and translation work)
- Gnome Games 2.25.1 (bug fixes, code cleanup and translation work)
- gnome-keyring 2.25.1 (code cleanup and translation work)
- gnome-settings-daemon 2.25.1 (new features, bug fixes and code cleanup)
- GObject-Introspection 0.6.0 (new features and bug fixes)
- GOK 2.25.1 (bug fixes and translation work)
- Gtk2-Perl 2.25.1 (new features and bug fixes)
- gtk-engines 2.17.0 (new features and bug fixes)
- libgee 0.1.4 (Update for Vala 0.3.3)
- mousetweaks 2.25.1 (new features, bug fixes and translation work)
- Orca 2.25.1 (bug fixes and translation work)
- Papywizard 1.2. (new features and translation work)
- PyPoppler 0.10.0 (new features)
- RSS-GLib - 0.2.0 (initial release)
- Seahorse 2.25.1 (code cleanup and translation work)
- seahorse-plugins 2.25.1 (code cleanup)
- Vala 0.5.1 (new features and bug fixes)
KDE 4.1.3 released
Version 4.1.3 of KDE has been announced. "KDE Community Improves Desktop with KDE 4.1.3 Codenamed "Change". KDE Community Ships Third Translation and Service Release of the 4.1 Free Desktop, Containing Numerous Bugfixes, Performance Improvements and Translation Updates."
KDE Software Announcements
The following new KDE software has been announced this week:- digiKam 0.10.0-beta5 (new features and bug fixes)
- Gimper 1.2 (new features and bug fixes)
- kipi-plugins 0.2.0-beta3 (new features and bug fixes)
- PySMSsend 1.39 (new features and bug fixes)
- QTGZManager Beta4 (new features and bug fixes)
- skrooge 0.1.0 (initial release)
- TreeLine 1.2.1 (bug fixes)
- Xt7-Player 0.7.9 (new features and bug fixes)
Xfce 4.4.3 released
Version 4.4.3 of Xfce, a light weight desktop environment, has been announced. "Just because we're gearing up to release 4.6.0, it doesn't mean we've forgotten the 4.4 branch. A bunch of bug fixes had accumulated since 4.4.2, so we have a new release for you."
Announcing xpra 0.0.5 - 'screen for X'
Version 0.0.5 of xpra has been announced, it includes bug fixes. "Xpra is 'screen for X' -- it allows you to run X programs, usually on a remote host, direct their display to your local machine, and then to disconnect from these programs and reconnect from the same or another machine, without losing any state. It is licensed under the GPLv2+."
Xorg Software Announcements
The following new Xorg software has been announced this week:- libdrm 2.4.1 (bug fixes)
- libpciaccess 0.10.5 (bug fixes)
- xf86-input-evdev 2.0.99.3 (new features and bug fixes)
- xserver 1.5.3 (new features and bug fixes)
Desktop Publishing
StorYBook: Version 2.1.6 released (SourceForge)
Version 2.1.6 of StorYBook has been announced, it adds some new capabilities and a Finnish translation. "Are you novelist, writer or author? StorYBook is a scene-based software for all creative writers that helps to organize your story. StorYBook assists you in structuring your book."
Financial Applications
SQL-Ledger 2.8.18 announced
Version 2.8.18 of SQL-Ledger, a web-based accounting system, has been announced. The What's New document summarized the changes: "workaround for Bizarre copy error caused by perl 5.10, lock order if it has been converted to an invoice, added user name and email for statements, fixed parts history order and added payment method variable for invoices."
Fonts and Images
Linux Libertine 4.1.8 released
Version 4.1.8 of the Linux Libertine font set has been announced, numerous improvements have been added.
Games
Cyphesis 0.5.17 released (WorldForge)
The WorldForge virtual world project has announced the release of Cyphesis 0.5.17, a server for WorldForge games. "Major changes in this version: Terrain modifiers are now fully supported. A new persistence backend has been written and is in testing. Properties have been re-written to be way more efficient. Internal metrics and monitors are now exposed using http. Registration with the metaserver is now much more reliable. Simulation is now jittered to make CPU load much smoother. Lots of bugs have been fixed."
libwfut 0.2.1 released (WorldForge)
The WorldForge virtual world project has announced the release of libwfut 0.2.1. "WFUT is a content distribution system initially intended to provide media updates for WorldForge clients. libwfut is a C++ implementation of the client side functionality. This release allows downloads to be aborted, contains some sample python front-ends and fixes a few small bugs. This version will also use a systemwide installation of tinyxml if available."
Sprite2d: New Release 0.8.0 (SourceForge)
Version 0.8.0 of Sprite2d has been announced. Sprite2d is: "A Java framework for writing sprite based games (turn-based, card, and arcade games.) Provides: Sprite management, rendering (Java2d or OpenGL), Collision Detection, Sprite widgets (buttons etc...), visual editor for layout of game widgets. We have released a new version of Sprite2d. This is another large change that includes: Event Containers, Font Creator, and new Demo called Slide Puzzle."
WOMBAT 0.4.0 and 0.4.1 released (WorldForge)
The WorldForge virtual world project has announced the release of WOMBAT 0.4.0 and 0.4.1, the WorldForge Open Media Browser/Artist Tool. "New features in these versions include: * Completely revamped look and feel * Support for users and roles * Actions that change the servers data * Custom icons that reflect the content of the media, if possible * New stock icons from the Tango project * Display total number of files under a directory to simplify browsing"
Graphics
Cairo release 1.8.2 now available
Version 1.8.2 of the Cairo graphics library has been announced. "This is the first update to cairo's stable 1.8 series and contains a large number of bug fixes. It is being released just over one month since cairo 1.8.0. This release consists primarily of bug fixes, but there is one notable new feature, (the ability to build cairo without an external font backend), and there are a few optimizations as well."
GUI Packages
New Qt Creator IDE from Qt Software (KDE.News)
KDE.News takes a look at a new IDE for Qt. "News emerged recently that Qt Software (formerly Trolltech) were working on their first IDE for Qt, code named Project Greenhouse. Today saw the release of the first technical preview under the name Qt Creator. The initial release is binary only, and under the terms of the Qt preview license, but the final release will be released with source code under a GPL compatible license. The initial release is available for Linux, Mac OS X and MS Windows."
Multimedia
Elisa Media Center 0.5.17 released
Version 0.5.17 of Elisa Media Center has been announced. "This release brings its usual lot of bug fixes and important performance improvements. A complete list of the new features and bugs fixed by this release is available at: https://bugs.launchpad.net/elisa/+milestone/0.5.17"
Office Suites
Announcing OpenOffice.org 2.4.2
Version 2.4.2 of OpenOffice.org has been announced. "The OpenOffice.org Community is pleased to announce the release of OpenOffice.org 2.4.2, a minor update of OpenOffice.org 2.4.1 released in June 2008."
OpenOffice.org Newsletter
The October, 2008 edition of the OpenOffice.org Newsletter is out with the latest OO.o office suite articles and events.
Video Applications
Theora 1.0 released
The 1.0 release of the Theora video codec is finally available. "A number of leading multimedia web groups already support Theora. Upcoming releases of Mozilla Firefox, the world's most popular open source browser, will support Theora natively, as will releases of the multi-platform Opera browser. Top-10 website Wikipedia uses Theora for all of its video."
Languages and Tools
C
Get to know GCC 4 (IBM developerWorks)
M. Tim Jones explores GCC 4 in an IBM developerWorks article. "In the last few years, the GNU Compiler Collection (GCC) has undergone a major transition from GCC version 3 to version 4. With GCC 4 comes a new optimization framework (and new intermediate code representation), new target and language support, and a variety of new attributes and options. Get to know the major new features and their benefits."
GCC 4.3.3 Status Report
The November 3, 2008 edition of the GCC 4.3.3 Status Report has been published. "The GCC 4.3 branch is open for regression and documentation fixes. The number of P1s grew a little bit, so the 4.3.3 release will need to be delayed by a few days until they are resolved or downgraded. Out of the 5 P1s, 2 were already fixed on the trunk and I'll just need to retest them in 4.3, one had a patch posted but no progress after patch review, one needs reghunt and analysis, one is currently assigned. Once all the P1s are resolved, 4.3.3 rc will be prepared."
GCC 4.4.0 Status Report
The November 1, 2008 edition of the GCC 4.4.0 Status Report has been published. "The two months of Stage 3 have ended and the trunk is now in regression and documentation fixes only mode. At this point bugfixing should concentrate on getting the list of serious regressions down to a level that makes GCC 4.4 ready to release. As an exception to this we will still have the old register allocator removed before we branch for the GCC 4.4.0 release."
Python
Jython 2.5 Beta 0 released
Version 2.5 Beta0 of Jython, an implementation of Python in Java, has been announced. "Jython 2.5 Beta0 is the beginning of a code cooling period where the number of new features should significantly slow as we concentrate on solidifying Jython 2.5 for an eventual release. There are still a number of features that we will squeeze in (like jythonc). This is a beta release so be careful."
Tcl/Tk
Tcl-URL! - weekly Tcl news and links
The October 31, 2008 edition of the Tcl-URL! is online with new Tcl/Tk articles and resources.
Build Tools
64 Studio Platform Development Kit 0.9.7 released
Version 0.9.7 of the 64 Studio Platform Development Kit has been announced, it includes a bug fix and a new inst-timeout option. "The 64 Studio Platform Development Kit (PDK) is a Free Software tool that we use to automate the production and maintenance of several different projects. PDK is a kind of version control system for distributions, allowing us to create and manage many different custom products based on Debian and Ubuntu sources."
Editors
PHP mode for Emacs: 1.5.0 released (SourceForge)
Version 1.5.0 of PHP mode for Emacs has been announced. The software is: "An Emacs major mode for editing PHP code. Features: Syntax coloring and indenting; Documentation browse and search functions; Support for Imenu and SpeedBar; Customization options A new version of PHP mode for Emacs is released. Version 1.5.0 is the follow-up to the major improvements unveiled for PHP mode in January. There are no major new features in this release, but many bug fixes."
Version Control
Gitbuilder 0.2.0 is released
Gitbuilder 0.2.0 has been announced. "I'd like to announce the new v0.2.0 release of gitbuilder, an auto-bisecting autobuilder tool for git-based projects. The new version incorporates several suggestions from end users..."
Page editor: Forrest Cook
Linux in the news
Recommended Reading
Gettys: Time to lead on the desktop
Jim Gettys, one of the original X Window System programmers (among many other things) has put up a lengthy call to the community to take the lead in the design of desktop software. "Our fundamental advantage we have is the ability to experiment and modify all areas of the stack; from hardware, to the window system, though toolkits to applications. Just as compositing has allowed a thousand flowers to bloom (most of which stink, but we've picked some that smell pretty sweet) in eye candy, accessibility and in other areas, compositing and other modern free software technologies can be used in new an unexpected ways. We are able to perform experiments, and have a large audience to test the experiments radically faster than commercial software."
Ibex design: user switching, presence and session termination (Here Be Dragons)
Mark Shuttleworth discusses recent work done on Ubuntu 8.10. "With Intrepid on track to hit the wires today I thought Id blog a little on the process we followed in designing the new user switcher, presence manager and session management experience, and lessons learned along the way. Ted has been blogging about the work he did, and its been mentioned in a couple of different forums (briefly earning the memorable title the new hotness), but since its one of the first pieces of work to go through the user experience design process within Canonical I thought it would be interesting to write it up."
Linux Adoption
Linux: The Joe Sixpack Strategy (ZDNet)
Jason Perlow suggests some Linux adoption strategies in a ZDNet blog. "To get Joe Sixpack to switch to Linux, hes going to need an easy way to move from his existing XP OS to his end-state, with all of his important data his Office files, his emails, his contacts, MP3 files, digital photos and what have you, so a foolproof migration process is going to have to be designed. According to my fantasy scenario, Ubuntu and Google join forces and Google provides a freely downloadable program that installs on the client Windows PC, sets the user up with an online Google account, and sucks out all the office files, email and other critical data, backing it up to the cloud, which would be automatically restored to the target Linux install."
Legal
Diebold faces GPL infringement lawsuit over voting machines (ars technica)
Ars technica covers the GPL infringement suit against Diebold for its use of Ghostscript in its voting machines. "Evidence of Diebold's Ghostscript use first emerged last year when electronic voting machine critic Jim March was conducting analysis of Pima County voting irregularities. He brought a technical question to the Ghostscript mailing list relating to his investigation and mentioned in passing that Diebold's use of Ghostscript could potentially fall afoul of the GPL. This view was shared by Ghostscript developer Ralph Giles, who referred the matter to the Artifex business staff so that it could evaluate the legal implications."
EU patent board to decide whether to allow software patents (ars technica)
Ars technica reports on an upcoming decision affecting the patentability of software in the European Union. "Although EU patent law expressly excludes patenting software as such, it does allow patents to be granted for computer-implemented inventions. There are, however, many unanswered questions about the distinction between software methods and computer-implemented inventions. In practice, the EPO has historically granted patent applications in some cases for software methods that are viewed as legitimate technical innovations rather than business innovations. The EPO illustrates the difference by saying that a patent on a software method for improving signal strength between mobile phones is likely to be valid, but a patent on Internet auction systems is probably not."
Status of FSFE's legal dept: FTF (Fellowship of FSFE)
Ciarán O'Riordan takes a look inside the legal department of the Free Software Foundation Europe. "Inside FSFE, we talk a lot about our legal department, the FTF. I was in the Zurich office a while ago with the FTF's coordinator, Shane Coughlan, and took the opportunity to gather some info for anyone interested."
Bilski: What It Means, Part 1 (Groklaw)
Groklaw analyzes the Bilski decision with an eye toward its effects on free software. "As you no doubt recall, Red Hat argued in its amicus brief that abstract ideas are not patentable. That argument won out. But Red Hat also argued that abstract ideas are not patentable *just because there is a computer involved*. The court didn't go that far. In a way, it found the opposite, that a machine has to be involved. But what it said was that as far as software is concerned, future cases will have to decide exactly where the line is."
Court Greatly Limits Software And Business Method Patents (Techdirt)
Techdirt reports on a new US Federal Appeals Court ruling regarding software patents. "The summary is that the court has said that there's a two-pronged test to determine whether a software of business method process patent is valid: (1) it is tied to a particular machine or apparatus, or (2) it transforms a particular article into a different state or thing. In other words, pure software or business method patents that are neither tied to a specific machine nor change something into a different state are not patentable. That means a significant number of software and business method patents are about to disappear, freeing up many industries to be much more innovative -- at a time when that's desperately needed."
Interviews
How Linux Supports More Devices Than Any Other OS, Ever (O'Reilly)
O'Reilly has an interview with kernel hacker Greg Kroah-Hartman. In it, they cover topics like Linux device support, the kernel development process, and the ever (un)popular binary-only device drivers. "The ease of writing drivers; Linux drivers are at normally one-third smaller than Windows drivers or other operating system drivers. We have all the examples there, so it's trivial to write a new one if you have new hardware, usually because you can copy the code and go. We maintain them for forever, so the old ones don't disappear and we run on every single processor out there. I mean Linux is 80% of the world's top 500 super computers right now and we're also the number one embedded operating system today."
Resources
AlgoScore - Music By The Numbers (Linux Journal)
Dave Phillips discovers AlgoScore, a Csound-based program for sound and music composition. "AlgoScore is not a "graphical composition" environment, i.e., the sound is not created by the graphics per se. AlgoScore supplies graphic objects, but their ultimate content and shapes result from Csound and/or Nasal code (a Nasal interpreter is included with the package). Thus, unlike other programs that simplify Csound, AlgoScore requires some knowledge of computer programming. Fortunately Csound and Nasal are relatively simple languages to learn, and even a little familiarity will take you a long way into the possibilities of AlgoScore."
Reduce your PC's power consumption through smart activity monitors (IBM developerWorks)
Nathan Harrington discusses power saving with smart activity monitors on IBM developerWorks. "Advanced Configuration and Power Interface (ACPI) and the power configuration systems built into modern computers provide a wide range of options for reducing overall power consumption. Linux and its associated user space programs have many of the tools necessary to master your PC power consumption in a variety of contexts. Much of the current documentation focuses on modifying your kernel parameters and hdparm settings to reduce unnecessary disk activity. In addition, extensive documentation is available for changing your processor settings to maximize the benefits of dynamic frequency scaling based on your current power source. This article provides tools and code to build on these power-saving measures by monitoring your application-usage patterns. Use the techniques presented here to change your power settings based on the application in focus, user activity, and general system performance."
Miscellaneous
Intel, Taiwan teaming up on mobile Linux development lab (Ars Technica)
Ryan Paul covers Taiwan's participation in Moblin. "Intel's open source Linux-based mobile platform initiative got a big boost this month from Linux distributors and new contributors that are joining to participate in the effort. The project, which is called Moblin, aims to assemble a Linux stack that is optimized for mobile Internet devices, subnotebooks, and integrated car computing systems that are designed to use Intel's Atom processor. The latest organization to join the ranks of Moblin supporters is Taiwan's Ministry of Economic Affairs (MOEA), which will be working with Intel to establish a Moblin development facility. Intel is also investing in VMAX, a mobile carrier in Taiwan that plans to roll out a WiMAX network."
Hostile takeover of Open Source Project TWiki
In a blog posting, Michale Daum covers a hostile takeover of the TWiki project. "Yesterday, 2008-10-27: 21:00 GMT, just a minute before the regular TWiki release meeting, the company TWIKI.NET announced unilaterally that the best for the TWiki.org project would be for them to take over governance. With it comes a complete lock down of the community site. From that minute on, all long-time contributors have lost access to their code. Counter-reaction: the community has left the building, leaving TWIKI.NET without a contributing community. Question: is it a sensible move for a venture capital firm that depends on a healthy Open Source community to lock it out?" (Thanks to Francesco Lovergine and Rahul Sundaram).
What's up with the GNOME Linux Desktop? (InternetNews.com)
InternetNews.com reports on the development and funding of GNOME 3, which should come out in 2009 or 2010. "It takes money and it takes new ideas to build a better desktop, both of which are being raised by the open source GNOME Foundation. GNOME is one of the most popular Linux desktop GUIs and is included in nearly every Linux distribution. The GNOME Foundation is now getting the official support of both Motorola and Google as sponsors and members of the GNOME Board of Advisors. The new advisors come as GNOME continues to expand the mobile Linux footprint as well as gear up for the next big thing GNOME 3.0."
Page editor: Forrest Cook
Announcements
Non-Commercial announcements
Free Documentation License 1.3
The Free Software Foundation has announced the release of version 1.3 of the GNU Free Documentation License. The big change would appear to be a clause allowing FDL-licensed text to be relicensed to the Creative Commons attribution-sharealike license. "This new permission has been added at the request of the Wikimedia Foundation, which oversees the Wikipedia project. The same terms are available to any public wiki that uses materials available under the new license. The Wikimedia Foundation will now initiate a process of community discussion and voting to determine whether or not to use CC-BY-SA 3.0 as the license for Wikipedia."
Motorola and Google join the GNOME Foundation Advisory Board
Motorola and Google have joined the GNOME Foundation Advisory Board. "We excited to announce today that Motorola and Google are joining the GNOME Foundation as sponsors and advisory board members. With these new additions to its advisory board, the GNOME Foundation continues to strengthen its industry support and shows that the support for free and open source software is growing - especially in the mobile space with technologies like GNOME Mobile."
Knuth: no more checks for bug reports
Donald Knuth pioneered the idea of bounties for bug reports many years ago. He has now announced, in classic Knuthian style, that he can no longer write checks for these reports because he's tired of being ripped off. "It turns out that only 9 of the first 275 checks that I've sent out since the beginning of 2006 have actually been cashed. The others have apparently been cached. So this change in policy will probably not affect too many people. On the other hand, I don't like to renege on promises, so I shall do my best to find a suitable way to send money to anyone who really prefers legal tender."
Commercial announcements
OXID eSales goes Open Source
OXID eSales has announced the release of its eSales product OXID eShop PE4 under the GPLv3 license. "The new Community Edition, OXID eShop CE, will offer the identical software to the latest release of OXID's proprietary professional edition, OXID PE 4.0, providing a fully functional out-of-the-box software solution for companies looking to build an online shop. The Community Edition is available for free download immediately under the GNU Public License version three (GPLv3)."
Zenoss to demonstrate open-source network monitoring solutions at LISA '08
Zenoss has announced plans to demonstrate their latest offerings at the LISA Conference in San Diego, CA on November 12-13, 2008. "Zenoss will be releasing their latest enterprise management and monitoring solutions featuring new capabilities for monitoring J2EE applications, Windows server, and native VMware instances. This latest version was developed in conjunction with the Zenoss open source community who provided product input, beta testing, and over 30 Zenoss extensions. In addition to showcasing its solutions during the show, Zenoss will also conduct its third annual Open Source Systems Management Survey."
New Books
Enterprise Rails - New from O'Reilly
O'Reilly has published the book Enterprise Rails by Dan Chak.Web Security Testing Cookbook--New from O'Reilly
O'Reilly has published the book Web Security Testing Cookbook by Paco Hope and Ben Walther.
Resources
Linux Gazette #156 is out!
Issue #156 of Linux Gazette has been published. Topics this time include: A (not so) short overview of the Geographic Information System GRASS, Writing Network Device Drivers for Linux, Installing and configuring root-access sandboxes in a running Linux system, The Red Hat Linux Boot Process, and lots more. Click below for the full announcement.White Paper: rPath Puts Adoption Model in the Cloud
rPath has published a white paper entitled The Pragmatist's Guide to Cloud Computing (registration required). ""Virtualization and cloud computing have a transformative impact on the cost and efficiency of software delivery and consumption, which makes investments in these areas of even greater importance during a down economy," said Jake Sorofman, VP of marketing for rPath. "But despite its importance, the path to cloud remains elusive for many organizations. rPath developed the Cloud Computing Adoption Model to propose what we believe is a useful incremental approach to cloud adoption, while also stimulating a public conversation about patterns and practices that can help us all become smarter about virtualization and cloud initiatives.""
Contests and Awards
2008 OpenVAS contest winners announced
Three winners have been selected for the OpenVAS Contest. "The 2008 OpenVAS Contest took place from August 23rd to October 15th, 2008. With 5 nominees who contributed a large number of improvements to the OpenVAS framework and extended the Open Source Network Vulnerability Testing, it was a great success. During the contest duration the number of OpenVAS Network Vulnerability Tests (NVTs) increased dramatically: from 3750 NVTs up to 5736 NVTs (an overall increase of over 50%). The most significant number of NVTs, which deliver full support for Gentoo and FreeBSD local security checks, were contributed by Thomas Reinke who deserves special thanks for his continuing support of OpenVAS."
The first official Python coin has been released in the Netherlands
Stani, author of Stani's Python Editor, has won a competition for a commemorative coin design. "I am pleased to announce that I won the competition for the next 5 euro commemorative coin with the theme 'Netherlands and Architecture'. The design of the coin was totally developed with python. I used PIL for raster image manipulation and pyCairo for generating vector graphics." See: How to make money with free software... for photos and more information on the effort.
Education and Certification
Free Web Seminars from MontaVista and Freescale (MarketWatch)
MarketWatch notes that MontaVista and Freescale will hold free web seminars on November 18. "MontaVista(R) Software, Inc., the leader in embedded Linux(R) commercialization, announces registration for two free web seminars on improving embedded Linux Startup time, presented with Freescale(TM) Semiconductor, OpenSystems Media and Christopher Hallinan, author of Embedded Linux Primer, the number one-selling book on embedded Linux. The web seminars will provide strategies for improving embedded Linux startup time and present techniques that help design engineers to reduce boot time while preserving the base functionality required of most embedded Linux systems."
Meeting Minutes
Perl 6 Design Minutes (use Perl)
The minutes from the October 29, 2008 Perl 6 Design Meeting have been published. "The Perl 6 design team met by phone on 29 October 2008. Larry, Allison, Patrick, Jerry, Will, Jesse, Nicholas, and chromatic attended."
Calls for Presentations
DC BSDCon 2009 Call for Papers
A call for papers has gone out for DC BSDCon 2009. The event takes place in Washington, D.C. on February 4-5, 2009, papers are due by December 1.Call for papers for GCC Research Opportunities Workshop GROW'09
A Call for papers has gone out for the GCC Research Opportunities Workshop, GROW'09. The event takes place on January 25-28, 2009 in Paphos, Cyprus, the deadline has been extended to November 21.Camp KDE 2009: Call For Presentations Deadline (KDE.News)
KDE.News has announced The Call For Presentations deadline for Camp KDE 2009. "The Call For Presentations deadline for Camp KDE 2009 will be Friday, November 21. Due to the compressed planning of this event, deliberation will be held over the weekend and selected presentations will be announced on Monday, November 24 so that travel decisions can be made." Camp KDE takes place on January 17-23, 2009 in Negril, Jamaica.
Upcoming Events
O'Reilly Money:Tech conference opens registration
Registration is open for the 2009 O'Reilly Money:Tech conference. "Registration has opened for Money:Tech 2009, February 4-6, 2009, in New York City, and program chairs Paul Kedrosky and Rob Passarella have announced the program. Money:Tech 2009 is the preeminent conference for investment professionals examining the impact technology has on trading, finance, and investing. Money:Tech 2009 will showcase tools, techniques, and technologies; provide a forum for leading-edge viewpoints; and deliver a first look at industry trends that will have merged into the mainstream by next year."
O'Reilly Tools of Change for Publishing Conference opens registration
Registration is open for the 2009 O'Reilly Tools of Change for Publishing Conference. "Registration has opened for the O'Reilly Tools of Change for Publishing Conference, taking place February 9-11, 2009, at the Marriot Marquis Times Square in New York City. Program Chair Andrew Savikas and co-Chair Mac Slocum have announced the program, which investigates the emerging trends in digital publishing through keynotes, sessions, tutorials, panels, and other events designed to surpass the high expectations inspired by the sold-out TOC 2008."
POC2008 conference, South Korea
POC2008 has been announced. "The 3rd international hacking and security conference "POC2008" by hackers will be held in Seoul, Korea on November 13 ~ 14."
Events: November 13, 2008 to January 12, 2009
The following event listing is taken from the LWN.net Calendar.
| Date(s) | Event | Location |
|---|---|---|
| November 10 November 14 |
Python Bootcamp with Dave Beazley | Atlanta, GA, USA |
| November 11 November 14 |
DeepSec IDSC 2008 | Vienna, Austria |
| November 12 November 14 |
php|works 2008 | Atlanta, GA, USA |
| November 12 November 13 |
PacSec Applied Security Conference | Tokyo, Japan |
| November 13 November 14 |
International Hacking and Security Conference | Seoul, Korea |
| November 14 November 16 |
OpenSQL Camp 2008 | Charlottesville, VA, USA |
| November 16 November 20 |
Middle East IT Security Conference | Dubai, UAE |
| November 19 November 20 |
Linux Foundation Japan Symposium | Tokyo, Japan |
| November 20 November 21 |
FreedomHEC Taipei 2008 | Taipei, Taiwan |
| November 22 | The phpnw08 conference | Manchester, UK |
| November 22 | PGDay Rio de la Plata | Buenos Aires, Argentina |
| November 22 | Mandriva 2009 Installfest | Everywhere, World |
| November 25 November 29 |
FOSS.IN 2008 | Bangalore, India |
| November 25 November 30 |
make art 2008 | Poitiers, France |
| November 28 | Informazione geografica aperta e libera | Pontedera (PI), Italy |
| November 28 November 29 |
WhyFLOSS La Plata - Argentina | La Plata, Argentina |
| November 29 | LinuxDay in Vorarlberg (Deutschland, Schweiz, Liechtenstein und Österreich) | Dornbirn, Austria |
| December 1 | First Nuxeo Developer Day | Paris, France |
| December 1 December 2 |
Open World Forum | Paris, France |
| December 2 December 5 |
Open Source Developers' Conference 2008 | Sydney, NSW, Australia |
| December 4 December 7 |
PIKSEL08 - code dreams | Bergen, Norway |
| December 5 December 6 |
FOSSCamp | Mountain View, CA, USA |
| December 5 December 13 |
International Joint Conferences on Computer, Information, and Systems Sciences, and Engineering | Online |
| December 7 December 12 |
Computer Measurement Group Conference 2008 | Las Vegas, NV, USA |
| December 8 December 12 |
Ubuntu Developer Summit | Mountain View, CA, USA |
| December 8 | Forum PHP Paris 2008 | Paris, France |
| December 10 December 11 |
First Workshop on I/O Virtualization | San Diego, CA, USA |
| December 13 | NLLGG meeting/BSD Community Day | Utrecht, The Netherlands |
| December 27 December 30 |
Chaos Communication Congress | Berlin, Germany |
| January 8 January 11 |
Consumer Electronics Show | Las Vegas, NV, USA |
| January 9 January 11 |
Fedora User and Developer Conference | Boston, USA |
If your event does not appear here, please tell us about it.
Page editor: Forrest Cook