
LWN.net Weekly Edition for September 27, 2007
Two free software choices for the Neo phone
In a rather brief period of time, we have gone from having no choice of free software to run on our mobile phones to having two. With the announcement of Qtopia Phone Edition (QPE) for the Neo 1973, two software stacks are available for users to choose from. A choice of GUIs will not be a surprise to Linux users, with GNOME, KDE, and others available on that platform, but it is quite a breath of fresh air in the normally locked-down mobile phone arena.
Also tucked into the Trolltech press release was an announcement that all of QPE was being released under the GPLv2. Prior to that, certain components of QPE – telephony, Digital Rights Management (DRM), and the safe execution environment modules – were only available under a commercial source license. The other choice, OpenMoko, which was reviewed in August, is also available under the GPL (v2 or later). Paralleling the differences between the two major desktop environments for Linux, QPE is based on Trolltech's Qtopia – a Qt derived GUI library – like KDE, whereas OpenMoko is GTK-based, like GNOME.
![[QPE dialer]](https://static.lwn.net/images/qpe/call_sm.png)
QPE is the more mature software of the two, and it shows in the interface. The Neo port of QPE is more responsive and more consistent than the early versions of OpenMoko, which is not surprising as QPE is already in use. There are millions of QPE phones in the hands of customers, mostly in Asia, so QPE has been put through its paces already, while OpenMoko is still under rapid development.
QPE on the Neo suffered from some of the same audio issues – mediocre quality and echo canceling problems – that were found with OpenMoko, which could easily be caused by the hardware or Linux drivers. It is, after all, an early developer release. OpenMoko is still working on the final hardware design for the "mass market" version, scheduled for December, presumably these kinds of issues are high on their list. With additional hardware being added - accelerometers, graphics hardware, and Wi-Fi networking - there is still a great deal to do.
![[QPE main menu]](https://static.lwn.net/images/qpe/mainmenu_sm.png)
The QPE applications are more numerous and offer more functionality than those found on OpenMoko. The current version does suffer from a number of glitches, though, as audio must be enabled manually and the suspend functionality is flaky at best. It does have most of the features that users have come to expect from a mobile phone, which gives it quite a bit of a lead on OpenMoko.
Trolltech has a hardware platform available to developers as well, the Greenphone, but it is more of a reference platform, rather than a consumer-oriented device. Changing the license on the entire QPE platform, while providing the software on a device that developers can actually use as a phone is a good strategic move for Trolltech. It should attract free software developers, resulting in additional software available for their phones.
It is nice to see the OpenMoko and QPE developers play nicely together; much of the infrastructure that OpenMoko put in place is being used by QPE and the two groups have been cooperating to port QPE to the Neo. OpenMoko behaves quite differently from other companies in the embedded device space. They have little interest in lock-in, preferring to build a useful hardware device for which multiple different software stacks can be written. They put together an infrastructure layer based on Linux and invited anyone to join in.
It is quite possible that other software vendors will do just that. Sun had a demo of its JavaFX Mobile phone software running on the Neo in May and has promised to GPL that code at some point. All of these options will allow users to pick an interface that works well for them, taking their data, ringtones, and, in many cases, favorite free applications along with them. Choices are not something that mobile phone users are used to – they are generally stuck with annoying, crippled interfaces forced on them by the manufacturers and carriers. – but it is something they could get used to.
GPL enforcement: waiting for the Monsoon
Some lawsuits begin quietly, others are launched with great fanfare. The Software Freedom Law Center and two BusyBox developers have recently decided to take the latter approach to address a GPL compliance problem. The SFLC's press release reads:
Before getting into the meat of the matter, it is hard to resist quibbling about the details. To that end, one could look at another GPL lawsuit press release, this one from the FSF:
In this case, the judge declined to enforce the GPL in a summary judgment motion, though the ruling acknowledged that MySQL appeared to have the stronger argument. The dispute was eventually settled, with Progress releasing its proprietary MySQL enhancements. It should also be remembered that IBM has brought GPL-violation charges against the SCO Group. So this suit might be the first which is exclusively about GPL enforcement in the US, but it is not the first time that the GPL has been the subject of a suit.
The dispute this time around relates to Monsoon Media's HAVA series of products designed to control and distribute television signals throughout the home. In March, 2007, a HAVA owner started a forum topic by asking if the product contained Linux. Nothing happened until the end of August, when another participant noticed that the firmware image clearly contained a version of BusyBox. On September 5, a Monsoon employee replied:
This person went on to suggest that, by looking inside the HAVA firmware, the forum posters were violating the end user license agreement for that software and that they should desist. The EULA talk did not go very far (it was pointed out that anybody can download the firmware without agreeing to the EULA), but the "project to pull this together" on GPL compliance also did not seem to go very far. Responses to questions on when a release could be expected were vague at best, and often absent entirely. Evidently private communications from the BusyBox developers went unanswered.
So, September 20, the SFLC filed suit on behalf of BusyBox developers Erik Andersen and Rob Landley. The complaint could be a textbook example of a straightforward GPL-violation charge; it complains of copyright infringement and asks for remedies in the form of an injunction against further distribution and monetary damages. The suit appears to have been successful in focusing minds at Monsoon Multimedia; on September 24 the company sent out a press release stating that it was in settlement negotiations and intended to comply with all of the relevant license requirements. The company also posted a comment on LWN stating that it plans to fix the problem:
Thus far, no settlement has been announced. Given that Monsoon has stated its intent to comply with the GPL, the sticking points can only be (1) the timing of the code release, and (2) what else Monsoon might have to do to make the developers happy. Previous GPL-related settlements elsewhere in the world have generally involved compensation for expenses incurred in the enforcement action and, perhaps, a donation to a free software-related project. There is no way to know what the plaintiffs are asking for here, and the final settlement - if and when it happens - may never be made public.
From the outside, this case does not have the look of a deliberate attempt to ignore the GPL. Instead, it looks like a small company which found free software useful in the creation of its product and which put the GPL-compliance part of the job - if it really even understood its obligations in that regard - on the back burner. Anybody who has ever worked in a small operation knows that it can be a long time before anybody has a spare moment to work on perceived low-priority jobs like that. So Monsoon never got around to its source release, even when people started asking questions. It took the filing of a lawsuit to get the company to put some resources into fulfilling its obligations.
It has been suggested that the BusyBox developers acted hastily, given that less than a month passed between the discovery of the problem and the filing of a lawsuit. Unlike some jurisdictions, the U.S. does not require that copyright actions be filed quickly in order to preserve the right to sue. The BusyBox developers might answer that there was nothing else they could do when Monsoon refused to respond to them and that they are generally tired of companies ignoring the license on their code. Whatever their reasons, it seems likely that the BusyBox developers stand a good chance of being taken more seriously the next time they ask a company to comply with the license on their code.
This case may not be the first time that the GPL has found its way into a U.S. court. Its (presumed) quick resolution does suggest that another invariant - that no U.S. court has ever ruled on the validity of the GPL - still holds. Unless the SCO Group somehow manages to continue to exist long enough to push the IBM case through to the end, it appears this situation will not change anytime soon. This is an interesting situation, considering the value of the code licensed under the GPL and how long the GPL has been in use. The conclusion is clear: there are no potential GPL violators out there with enough confidence to try to challenge the GPL in court. The GPL looks well positioned to continue to do the job it was created for all those years ago.
What every programmer should know about memory, Part 1
[Editor's introduction: Ulrich Drepper recently approached us asking if we would be interested in publishing a lengthy document he had written on how memory and software interact. We did not have to look at the text for long to realize that it would be of interest to many LWN readers. Memory usage is often the determining factor in how software performs, but good information on how to avoid memory bottlenecks is hard to find. This series of articles should change that situation.The original document prints out at over 100 pages. We will be splitting it into about seven segments, each run 1-2 weeks after its predecessor. Once the entire series is out, Ulrich will be releasing the full text.
Reformatting the text from the original LaTeX has been a bit of a challenge, but the results, hopefully, will be good. For ease of online reading, Ulrich's footnotes have been placed {inline in the text}. Hyperlinked cross-references (and [bibliography references]) will not be possible until the full series is published.
Many thanks to Ulrich for allowing LWN to publish this material; we hope that it will lead to more memory-efficient software across our systems in the near future.]
1 Introduction
In the early days computers were much simpler. The various components of a system, such as the CPU, memory, mass storage, and network interfaces, were developed together and, as a result, were quite balanced in their performance. For example, the memory and network interfaces were not (much) faster than the CPU at providing data.
This situation changed once the basic structure of computers stabilized and hardware developers concentrated on optimizing individual subsystems. Suddenly the performance of some components of the computer fell significantly behind and bottlenecks developed. This was especially true for mass storage and memory subsystems which, for cost reasons, improved more slowly relative to other components.
The slowness of mass storage has mostly been dealt with using software techniques: operating systems keep most often used (and most likely to be used) data in main memory, which can be accessed at a rate orders of magnitude faster than the hard disk. Cache storage was added to the storage devices themselves, which requires no changes in the operating system to increase performance. {Changes are needed, however, to guarantee data integrity when using storage device caches.} For the purposes of this paper, we will not go into more details of software optimizations for the mass storage access.
Unlike storage subsystems, removing the main memory as a bottleneck has proven much more difficult and almost all solutions require changes to the hardware. Today these changes mainly come in the following forms:
- RAM hardware design (speed and parallelism).
- Memory controller designs.
- CPU caches.
- Direct memory access (DMA) for devices.
For the most part, this document will deal with CPU caches and some effects of memory controller design. In the process of exploring these topics, we will explore DMA and bring it into the larger picture. However, we will start with an overview of the design for today's commodity hardware. This is a prerequisite to understanding the problems and the limitations of efficiently using memory subsystems. We will also learn about, in some detail, the different types of RAM and illustrate why these differences still exist.
This document is in no way all inclusive and final. It is limited to commodity hardware and further limited to a subset of that hardware. Also, many topics will be discussed in just enough detail for the goals of this paper. For such topics, readers are recommended to find more detailed documentation.
When it comes to operating-system-specific details and solutions, the text exclusively describes Linux. At no time will it contain any information about other OSes. The author has no interest in discussing the implications for other OSes. If the reader thinks s/he has to use a different OS they have to go to their vendors and demand they write documents similar to this one.
One last comment before the start. The text contains a number of occurrences of the term “usually” and other, similar qualifiers. The technology discussed here exists in many, many variations in the real world and this paper only addresses the most common, mainstream versions. It is rare that absolute statements can be made about this technology, thus the qualifiers.
1.1 Document Structure
This document is mostly for software developers. It does not go into enough technical details of the hardware to be useful for hardware-oriented readers. But before we can go into the practical information for developers a lot of groundwork must be laid.
To that end, the second section describes random-access memory (RAM) in technical detail. This section's content is nice to know but not absolutely critical to be able to understand the later sections. Appropriate back references to the section are added in places where the content is required so that the anxious reader could skip most of this section at first.
The third section goes into a lot of details of CPU cache behavior. Graphs have been used to keep the text from being as dry as it would otherwise be. This content is essential for an understanding of the rest of the document. Section 4 describes briefly how virtual memory is implemented. This is also required groundwork for the rest.
Section 5 goes into a lot of detail about Non Uniform Memory Access (NUMA) systems.
Section 6 is the central section of this paper. It brings together all the previous sections' information and gives programmers advice on how to write code which performs well in the various situations. The very impatient reader could start with this section and, if necessary, go back to the earlier sections to freshen up the knowledge of the underlying technology.
Section 7 introduces tools which can help the programmer do a better job. Even with a complete understanding of the technology it is far from obvious where in a non-trivial software project the problems are. Some tools are necessary.
In section 8 we finally give an outlook of technology which can be expected in the near future or which might just simply be good to have.
1.2 Reporting Problems
The author intends to update this document for some time. This includes updates made necessary by advances in technology but also to correct mistakes. Readers willing to report problems are encouraged to send email.
1.3 Thanks
I would like to thank Johnray Fuller and especially Jonathan Corbet for taking on part of the daunting task of transforming the author's form of English into something more traditional. Markus Armbruster provided a lot of valuable input on problems and omissions in the text.
1.4 About this Document
The title of this paper is an homage to David Goldberg's classic paper “What Every Computer Scientist Should Know About Floating-Point Arithmetic” [goldberg]. Goldberg's paper is still not widely known, although it should be a prerequisite for anybody daring to touch a keyboard for serious programming.
2 Commodity Hardware Today
Understanding commodity hardware is important because specialized hardware is in retreat. Scaling these days is most often achieved horizontally instead of vertically, meaning today it is more cost-effective to use many smaller, connected commodity computers instead of a few really large and exceptionally fast (and expensive) systems. This is the case because fast and inexpensive network hardware is widely available. There are still situations where the large specialized systems have their place and these systems still provide a business opportunity, but the overall market is dwarfed by the commodity hardware market. Red Hat, as of 2007, expects that for future products, the “standard building blocks” for most data centers will be a computer with up to four sockets, each filled with a quad core CPU that, in the case of Intel CPUs, will be hyper-threaded. {Hyper-threading enables a single processor core to be used for two or more concurrent executions with just a little extra hardware.} This means the standard system in the data center will have up to 64 virtual processors. Bigger machines will be supported, but the quad socket, quad CPU core case is currently thought to be the sweet spot and most optimizations are targeted for such machines.
Large differences exist in the structure of commodity computers. That said, we will cover more than 90% of such hardware by concentrating on the most important differences. Note that these technical details tend to change rapidly, so the reader is advised to take the date of this writing into account.
Over the years the personal computers and smaller servers standardized on a chipset with two parts: the Northbridge and Southbridge. Figure 2.1 shows this structure.
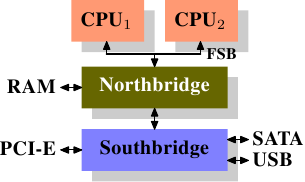
Figure 2.1: Structure with Northbridge and Southbridge
All CPUs (two in the previous example, but there can be more) are connected via a common bus (the Front Side Bus, FSB) to the Northbridge. The Northbridge contains, among other things, the memory controller, and its implementation determines the type of RAM chips used for the computer. Different types of RAM, such as DRAM, Rambus, and SDRAM, require different memory controllers.
To reach all other system devices, the Northbridge must communicate with the Southbridge. The Southbridge, often referred to as the I/O bridge, handles communication with devices through a variety of different buses. Today the PCI, PCI Express, SATA, and USB buses are of most importance, but PATA, IEEE 1394, serial, and parallel ports are also supported by the Southbridge. Older systems had AGP slots which were attached to the Northbridge. This was done for performance reasons related to insufficiently fast connections between the Northbridge and Southbridge. However, today the PCI-E slots are all connected to the Southbridge.
Such a system structure has a number of noteworthy consequences:
- All data communication from one CPU to another must travel over
the same bus used to communicate with the Northbridge.
- All communication with RAM must pass through the Northbridge.
- The RAM has only a single port.
{We will not discuss multi-port RAM in this document as this
type of RAM is not found in commodity hardware, at least not in places
where the programmer has access to it. It can be found in specialized
hardware such as network routers which depend on utmost speed.}
- Communication between a CPU and a device attached to the
Southbridge is routed through the Northbridge.
A couple of bottlenecks are immediately apparent in this design. One such bottleneck involves access to RAM for devices. In the earliest days of the PC, all communication with devices on either bridge had to pass through the CPU, negatively impacting overall system performance. To work around this problem some devices became capable of direct memory access (DMA). DMA allows devices, with the help of the Northbridge, to store and receive data in RAM directly without the intervention of the CPU (and its inherent performance cost). Today all high-performance devices attached to any of the buses can utilize DMA. While this greatly reduces the workload on the CPU, it also creates contention for the bandwidth of the Northbridge as DMA requests compete with RAM access from the CPUs. This problem, therefore, must to be taken into account.
A second bottleneck involves the bus from the Northbridge to the RAM. The exact details of the bus depend on the memory types deployed. On older systems there is only one bus to all the RAM chips, so parallel access is not possible. Recent RAM types require two separate buses (or channels as they are called for DDR2, see Figure 2.8) which doubles the available bandwidth. The Northbridge interleaves memory access across the channels. More recent memory technologies (FB-DRAM, for instance) add more channels.
With limited bandwidth available, it is important to schedule memory access in ways that minimize delays. As we will see, processors are much faster and must wait to access memory, despite the use of CPU caches. If multiple hyper-threads, cores, or processors access memory at the same time, the wait times for memory access are even longer. This is also true for DMA operations.
There is more to accessing memory than concurrency, however. Access patterns themselves also greatly influence the performance of the memory subsystem, especially with multiple memory channels. Refer to Section 2.2 for more details of RAM access patterns.
On some more expensive systems, the Northbridge does not actually contain the memory controller. Instead the Northbridge can be connected to a number of external memory controllers (in the following example, four of them).
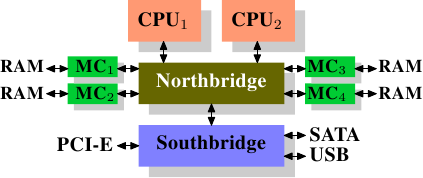
Figure 2.2: Northbridge with External Controllers
The advantage of this architecture is that more than one memory bus exists and therefore total bandwidth increases. This design also supports more memory. Concurrent memory access patterns reduce delays by simultaneously accessing different memory banks. This is especially true when multiple processors are directly connected to the Northbridge, as in Figure 2.2. For such a design, the primary limitation is the internal bandwidth of the Northbridge, which is phenomenal for this architecture (from Intel). {For completeness it should be mentioned that such a memory controller arrangement can be used for other purposes such as “memory RAID” which is useful in combination with hotplug memory.}
Using multiple external memory controllers is not the only way to increase memory bandwidth. One other increasingly popular way is to integrate memory controllers into the CPUs and attach memory to each CPU. This architecture is made popular by SMP systems based on AMD's Opteron processor. Figure 2.3 shows such a system. Intel will have support for the Common System Interface (CSI) starting with the Nehalem processors; this is basically the same approach: an integrated memory controller with the possibility of local memory for each processor.
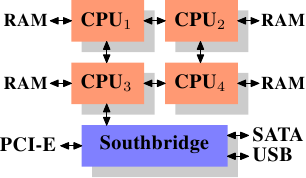
Figure 2.3: Integrated Memory Controller
With an architecture like this there are as many memory banks available as there are processors. On a quad-CPU machine the memory bandwidth is quadrupled without the need for a complicated Northbridge with enormous bandwidth. Having a memory controller integrated into the CPU has some additional advantages; we will not dig deeper into this technology here.
There are disadvantages to this architecture, too. First of all, because the machine still has to make all the memory of the system accessible to all processors, the memory is not uniform anymore (hence the name NUMA - Non-Uniform Memory Architecture - for such an architecture). Local memory (memory attached to a processor) can be accessed with the usual speed. The situation is different when memory attached to another processor is accessed. In this case the interconnects between the processors have to be used. To access memory attached to CPU2 from CPU1 requires communication across one interconnect. When the same CPU accesses memory attached to CPU4 two interconnects have to be crossed.
Each such communication has an associated cost. We talk about “NUMA factors” when we describe the extra time needed to access remote memory. The example architecture in Figure 2.3 has two levels for each CPU: immediately adjacent CPUs and one CPU which is two interconnects away. With more complicated machines the number of levels can grow significantly. There are also machine architectures (for instance IBM's x445 and SGI's Altix series) where there is more than one type of connection. CPUs are organized into nodes; within a node the time to access the memory might be uniform or have only small NUMA factors. The connection between nodes can be very expensive, though, and the NUMA factor can be quite high.
Commodity NUMA machines exist today and will likely play an even greater role in the future. It is expected that, from late 2008 on, every SMP machine will use NUMA. The costs associated with NUMA make it important to recognize when a program is running on a NUMA machine. In Section 5 we will discuss more machine architectures and some technologies the Linux kernel provides for these programs.
Beyond the technical details described in the remainder of this section, there are several additional factors which influence the performance of RAM. They are not controllable by software, which is why they are not covered in this section. The interested reader can learn about some of these factors in Section 2.1. They are really only needed to get a more complete picture of RAM technology and possibly to make better decisions when purchasing computers.
The following two sections discuss hardware details at the gate level and the access protocol between the memory controller and the DRAM chips. Programmers will likely find this information enlightening since these details explain why RAM access works the way it does. It is optional knowledge, though, and the reader anxious to get to topics with more immediate relevance for everyday life can jump ahead to Section 2.2.5.
2.1 RAM Types
There have been many types of RAM over the years and each type varies, sometimes significantly, from the other. The older types are today really only interesting to the historians. We will not explore the details of those. Instead we will concentrate on modern RAM types; we will only scrape the surface, exploring some details which are visible to the kernel or application developer through their performance characteristics.
The first interesting details are centered around the question why there are different types of RAM in the same machine. More specifically, why there are both static RAM (SRAM {In other contexts SRAM might mean “synchronous RAM”.}) and dynamic RAM (DRAM). The former is much faster and provides the same functionality. Why is not all RAM in a machine SRAM? The answer is, as one might expect, cost. SRAM is much more expensive to produce and to use than DRAM. Both these cost factors are important, the second one increasing in importance more and more. To understand these difference we look at the implementation of a bit of storage for both SRAM and DRAM.
In the remainder of this section we will discuss some low-level details of the implementation of RAM. We will keep the level of detail as low as possible. To that end, we will discuss the signals at a “logic level” and not at a level a hardware designer would have to use. That level of detail is unnecessary for our purpose here.
2.1.1 Static RAM
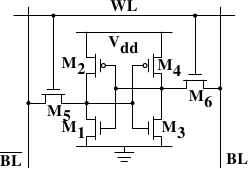
Figure 2.4: 6-T Static RAM
Figure 2.4 shows the structure of a 6 transistor SRAM cell. The core of this cell is formed by the four transistors M1 to M4 which form two cross-coupled inverters. They have two stable states, representing 0 and 1 respectively. The state is stable as long as power on Vdd is available.
If access to the state of the cell is needed the word access line WL is raised. This makes the state of the cell immediately available for reading on BL and BL. If the cell state must be overwritten the BL and BL lines are first set to the desired values and then WL is raised. Since the outside drivers are stronger than the four transistors (M1 through M4) this allows the old state to be overwritten.
See [sramwiki] for a more detailed description of the way the cell works. For the following discussion it is important to note that
- one cell requires six transistors. There are variants with four
transistors but they have disadvantages.
- maintaining the state of the cell requires constant power.
- the cell state is available for reading almost immediately once
the word access line WL is raised. The signal is as rectangular
(changing quickly between the two binary states) as
other transistor-controlled signals.
- the cell state is stable, no refresh cycles are needed.
There are other, slower and less power-hungry, SRAM forms available, but those are not of interest here since we are looking at fast RAM. These slow variants are mainly interesting because they can be more easily used in a system than dynamic RAM because of their simpler interface.
2.1.2 Dynamic RAM
Dynamic RAM is, in its structure, much simpler than static RAM. Figure 2.5 shows the structure of a usual DRAM cell design. All it consists of is one transistor and one capacitor. This huge difference in complexity of course means that it functions very differently than static RAM.
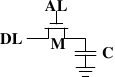
Figure 2.5: 1-T Dynamic RAM
A dynamic RAM cell keeps its state in the capacitor C. The transistor M is used to guard the access to the state. To read the state of the cell the access line AL is raised; this either causes a current to flow on the data line DL or not, depending on the charge in the capacitor. To write to the cell the data line DL is appropriately set and then AL is raised for a time long enough to charge or drain the capacitor.
There are a number of complications with the design of dynamic RAM. The use of a capacitor means that reading the cell discharges the capacitor. The procedure cannot be repeated indefinitely, the capacitor must be recharged at some point. Even worse, to accommodate the huge number of cells (chips with 109 or more cells are now common) the capacity to the capacitor must be low (in the femto-farad range or lower). A fully charged capacitor holds a few 10's of thousands of electrons. Even though the resistance of the capacitor is high (a couple of tera-ohms) it only takes a short time for the capacity to dissipate. This problem is called “leakage”.
This leakage is why a DRAM cell must be constantly refreshed. For most DRAM chips these days this refresh must happen every 64ms. During the refresh cycle no access to the memory is possible. For some workloads this overhead might stall up to 50% of the memory accesses (see [highperfdram]).
A second problem resulting from the tiny charge is that the information read from the cell is not directly usable. The data line must be connected to a sense amplifier which can distinguish between a stored 0 or 1 over the whole range of charges which still have to count as 1.
A third problem is that charging and draining a capacitor is not instantaneous. The signals received by the sense amplifier are not rectangular, so a conservative estimate as to when the output of the cell is usable has to be used. The formulas for charging and discharging a capacitor are
![[Formulas]](https://static.lwn.net/images/cpumemory/capcharge.png)
This means it takes some time (determined by the capacity C and resistance R) for the capacitor to be charged and discharged. It also means that the current which can be detected by the sense amplifiers is not immediately available. Figure 2.6 shows the charge and discharge curves. The X—axis is measured in units of RC (resistance multiplied by capacitance) which is a unit of time.
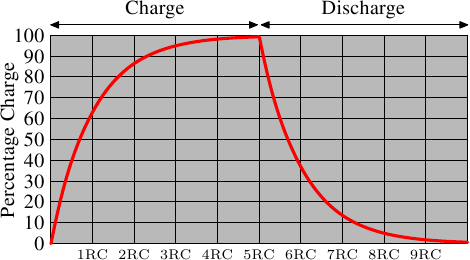
Figure 2.6: Capacitor Charge and Discharge Timing
Unlike the static RAM case where the output is immediately available when the word access line is raised, it will always take a bit of time until the capacitor discharges sufficiently. This delay severely limits how fast DRAM can be.
The simple approach has its advantages, too. The main advantage is size. The chip real estate needed for one DRAM cell is many times smaller than that of an SRAM cell. The SRAM cells also need individual power for the transistors maintaining the state. The structure of the DRAM cell is also simpler and more regular which means packing many of them close together on a die is simpler.
Overall, the (quite dramatic) difference in cost wins. Except in specialized hardware — network routers, for example — we have to live with main memory which is based on DRAM. This has huge implications on the programmer which we will discuss in the remainder of this paper. But first we need to look into a few more details of the actual use of DRAM cells.
2.1.3 DRAM Access
A program selects a memory location using a virtual address. The processor translates this into a physical address and finally the memory controller selects the RAM chip corresponding to that address. To select the individual memory cell on the RAM chip, parts of the physical address are passed on in the form of a number of address lines.
It would be completely impractical to address memory locations individually from the memory controller: 4GB of RAM would require 232 address lines. Instead the address is passed encoded as a binary number using a smaller set of address lines. The address passed to the DRAM chip this way must be demultiplexed first. A demultiplexer with N address lines will have 2N output lines. These output lines can be used to select the memory cell. Using this direct approach is no big problem for chips with small capacities.
But if the number of cells grows this approach is not suitable anymore. A chip with 1Gbit {I hate those SI prefixes. For me a giga-bit will always be 230 and not 109 bits.} capacity would need 30 address lines and 230 select lines. The size of a demultiplexer increases exponentially with the number of input lines when speed is not to be sacrificed. A demultiplexer for 30 address lines needs a whole lot of chip real estate in addition to the complexity (size and time) of the demultiplexer. Even more importantly, transmitting 30 impulses on the address lines synchronously is much harder than transmitting “only” 15 impulses. Fewer lines have to be laid out at exactly the same length or timed appropriately. {Modern DRAM types like DDR3 can automatically adjust the timing but there is a limit as to what can be tolerated.}
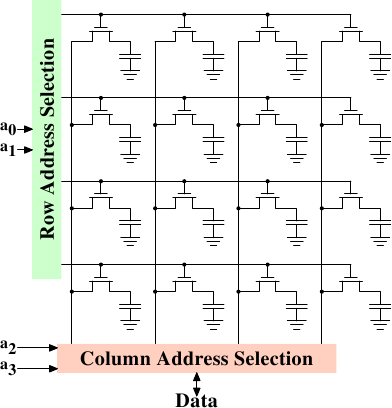
Figure 2.7: Dynamic RAM Schematic
Figure 2.7 shows a DRAM chip at a very high level. The DRAM cells are organized in rows and columns. They could all be aligned in one row but then the DRAM chip would need a huge demultiplexer. With the array approach the design can get by with one demultiplexer and one multiplexer of half the size. {Multiplexers and demultiplexers are equivalent and the multiplexer here needs to work as a demultiplexer when writing. So we will drop the differentiation from now on.} This is a huge saving on all fronts. In the example the address lines a0 and a1 through the row address selection (RAS) demultiplexer select the address lines of a whole row of cells. When reading, the content of all cells is thusly made available to the column address selection (CAS) {The line over the name indicates that the signal is negated} multiplexer. Based on the address lines a2 and a3 the content of one column is then made available to the data pin of the DRAM chip. This happens many times in parallel on a number of DRAM chips to produce a total number of bits corresponding to the width of the data bus.
For writing, the new cell value is put on the data bus and, when the cell is selected using the RAS and CAS, it is stored in the cell. A pretty straightforward design. There are in reality — obviously — many more complications. There need to be specifications for how much delay there is after the signal before the data will be available on the data bus for reading. The capacitors do not unload instantaneously, as described in the previous section. The signal from the cells is so weak that it needs to be amplified. For writing it must be specified how long the data must be available on the bus after the RAS and CAS is done to successfully store the new value in the cell (again, capacitors do not fill or drain instantaneously). These timing constants are crucial for the performance of the DRAM chip. We will talk about this in the next section.
A secondary scalability problem is that having 30 address lines connected to every RAM chip is not feasible either. Pins of a chip are a precious resources. It is “bad” enough that the data must be transferred as much as possible in parallel (e.g., in 64 bit batches). The memory controller must be able to address each RAM module (collection of RAM chips). If parallel access to multiple RAM modules is required for performance reasons and each RAM module requires its own set of 30 or more address lines, then the memory controller needs to have, for 8 RAM modules, a whopping 240+ pins only for the address handling.
To counter these secondary scalability problems DRAM chips have, for a long time, multiplexed the address itself. That means the address is transferred in two parts. The first part consisting of address bits a0 and a1 in the example in Figure 2.7) select the row. This selection remains active until revoked. Then the second part, address bits a2 and a3, select the column. The crucial difference is that only two external address lines are needed. A few more lines are needed to indicate when the RAS and CAS signals are available but this is a small price to pay for cutting the number of address lines in half. This address multiplexing brings its own set of problems, though. We will discuss them in Section 2.2.
2.1.4 Conclusions
Do not worry if the details in this section are a bit overwhelming. The important things to take away from this section are:
- there are reasons why not all memory is SRAM
- memory cells need to be individually selected to be used
- the number of address lines is directly responsible for the cost
of the memory controller, motherboards, DRAM module, and DRAM chip
- it takes a while before the results of the read or write
operation are available
The following section will go into more details about the actual process of accessing DRAM memory. We are not going into more details of accessing SRAM, which is usually directly addressed. This happens for speed and because the SRAM memory is limited in size. SRAM is currently used in CPU caches and on-die where the connections are small and fully under control of the CPU designer. CPU caches are a topic which we discuss later but all we need to know is that SRAM cells have a certain maximum speed which depends on the effort spent on the SRAM. The speed can vary from only slightly slower than the CPU core to one or two orders of magnitude slower.
2.2 DRAM Access Technical Details
In the section introducing DRAM we saw that DRAM chips multiplex the addresses in order to save resources. We also saw that accessing DRAM cells takes time since the capacitors in those cells do not discharge instantaneously to produce a stable signal; we also saw that DRAM cells must be refreshed. Now it is time to put this all together and see how all these factors determine how the DRAM access has to happen.
We will concentrate on current technology; we will not discuss asynchronous DRAM and its variants as they are simply not relevant anymore. Readers interested in this topic are referred to [highperfdram] and [arstechtwo]. We will also not talk about Rambus DRAM (RDRAM) even though the technology is not obsolete. It is just not widely used for system memory. We will concentrate exclusively on Synchronous DRAM (SDRAM) and its successors Double Data Rate DRAM (DDR).
Synchronous DRAM, as the name suggests, works relative to a time source. The memory controller provides a clock, the frequency of which determines the speed of the Front Side Bus (FSB) — the memory controller interface used by the DRAM chips. As of this writing, frequencies of 800MHz, 1,066MHz, or even 1,333MHz are available with higher frequencies (1,600MHz) being announced for the next generation. This does not mean the frequency used on the bus is actually this high. Instead, today's buses are double- or quad-pumped, meaning that data is transported two or four times per cycle. Higher numbers sell so the manufacturers like to advertise a quad-pumped 200MHz bus as an “effective” 800MHz bus.
For SDRAM today each data transfer consists of 64 bits — 8 bytes. The transfer rate of the FSB is therefore 8 bytes multiplied by the effective bus frequency (6.4GB/s for the quad-pumped 200MHz bus). That sounds like a lot but it is the burst speed, the maximum speed which will never be surpassed. As we will see now the protocol for talking to the RAM modules has a lot of downtime when no data can be transmitted. It is exactly this downtime which we must understand and minimize to achieve the best performance.
2.2.1 Read Access Protocol
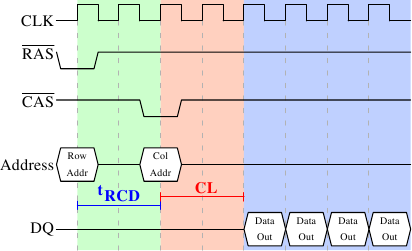
Figure 2.8: SDRAM Read Access Timing
Figure 2.8 shows the activity on some of the connectors of a DRAM module which happens in three differently colored phases. As usual, time flows from left to right. A lot of details are left out. Here we only talk about the bus clock, RAS and CAS signals, and the address and data buses. A read cycle begins with the memory controller making the row address available on the address bus and lowering the RAS signal. All signals are read on the rising edge of the clock (CLK) so it does not matter if the signal is not completely square as long as it is stable at the time it is read. Setting the row address causes the RAM chip to start latching the addressed row.
The CAS signal can be sent after tRCD (RAS-to-CAS Delay) clock cycles. The column address is then transmitted by making it available on the address bus and lowering the CAS line. Here we can see how the two parts of the address (more or less halves, nothing else makes sense) can be transmitted over the same address bus.
Now the addressing is complete and the data can be transmitted. The RAM chip needs some time to prepare for this. The delay is usually called CAS Latency (CL). In Figure 2.8 the CAS latency is 2. It can be higher or lower, depending on the quality of the memory controller, motherboard, and DRAM module. The latency can also have half values. With CL=2.5 the first data would be available at the first falling flank in the blue area.
With all this preparation to get to the data it would be wasteful to only transfer one data word. This is why DRAM modules allow the memory controller to specify how much data is to be transmitted. Often the choice is between 2, 4, or 8 words. This allows filling entire lines in the caches without a new RAS/CAS sequence. It is also possible for the memory controller to send a new CAS signal without resetting the row selection. In this way, consecutive memory addresses can be read from or written to significantly faster because the RAS signal does not have to be sent and the row does not have to be deactivated (see below). Keeping the row “open” is something the memory controller has to decide. Speculatively leaving it open all the time has disadvantages with real-world applications (see [highperfdram]). Sending new CAS signals is only subject to the Command Rate of the RAM module (usually specified as Tx, where x is a value like 1 or 2; it will be 1 for high-performance DRAM modules which accept new commands every cycle).
In this example the SDRAM spits out one word per cycle. This is what the first generation does. DDR is able to transmit two words per cycle. This cuts down on the transfer time but does not change the latency. In principle, DDR2 works the same although in practice it looks different. There is no need to go into the details here. It is sufficient to note that DDR2 can be made faster, cheaper, more reliable, and is more energy efficient (see [ddrtwo] for more information).
2.2.2 Precharge and Activation
Figure 2.8 does not cover the whole cycle. It only shows parts of the full cycle of accessing DRAM. Before a new RAS signal can be sent the currently latched row must be deactivated and the new row must be precharged. We can concentrate here on the case where this is done with an explicit command. There are improvements to the protocol which, in some situations, allows this extra step to be avoided. The delays introduced by precharging still affect the operation, though.
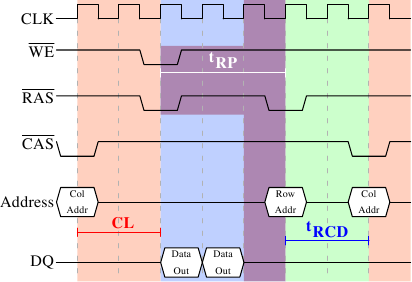
Figure 2.9: SDRAM Precharge and Activation
Figure 2.9 shows the activity starting from one CAS signal to the CAS signal for another row. The data requested with the first CAS signal is available as before, after CL cycles. In the example two words are requested which, on a simple SDRAM, takes two cycles to transmit. Alternatively, imagine four words on a DDR chip.
Even on DRAM modules with a command rate of one the precharge command cannot be issued right away. It is necessary to wait as long as it takes to transmit the data. In this case it takes two cycles. This happens to be the same as CL but that is just a coincidence. The precharge signal has no dedicated line; instead, some implementations issue it by lowering the Write Enable (WE) and RAS line simultaneously. This combination has no useful meaning by itself (see [micronddr] for encoding details).
Once the precharge command is issued it takes tRP (Row Precharge time) cycles until the row can be selected. In Figure 2.9 much of the time (indicated by the purplish color) overlaps with the memory transfer (light blue). This is good! But tRP is larger than the transfer time and so the next RAS signal is stalled for one cycle.
If we were to continue the timeline in the diagram we would find that the next data transfer happens 5 cycles after the previous one stops. This means the data bus is only in use two cycles out of seven. Multiply this with the FSB speed and the theoretical 6.4GB/s for a 800MHz bus become 1.8GB/s. That is bad and must be avoided. The techniques described in Section 6 help to raise this number. But the programmer usually has to do her share.
There is one more timing value for a SDRAM module which we have not discussed. In Figure 2.9 the precharge command was only limited by the data transfer time. Another constraint is that an SDRAM module needs time after a RAS signal before it can precharge another row (denoted as tRAS). This number is usually pretty high, in the order of two or three times the tRP value. This is a problem if, after a RAS signal, only one CAS signal follows and the data transfer is finished in a few cycles. Assume that in Figure 2.9 the initial CAS signal was preceded directly by a RAS signal and that tRAS is 8 cycles. Then the precharge command would have to be delayed by one additional cycle since the sum of tRCD, CL, and tRP (since it is larger than the data transfer time) is only 7 cycles.
DDR modules are often described using a special notation: w-x-y-z-T. For instance: 2-3-2-8-T1. This means:
w 2 CAS Latency (CL) x 3 RAS-to-CAS delay (tRCD) y 2 RAS Precharge (tRP) z 8 Active to Precharge delay (tRAS) T T1 Command Rate
There are numerous other timing constants which affect the way commands can be issued and are handled. Those five constants are in practice sufficient to determine the performance of the module, though.
It is sometimes useful to know this information for the computers in use to be able to interpret certain measurements. It is definitely useful to know these details when buying computers since they, along with the FSB and SDRAM module speed, are among the most important factors determining a computer's speed.
The very adventurous reader could also try to tweak a system. Sometimes the BIOS allows changing some or all these values. SDRAM modules have programmable registers where these values can be set. Usually the BIOS picks the best default value. If the quality of the RAM module is high it might be possible to reduce the one or the other latency without affecting the stability of the computer. Numerous overclocking websites all around the Internet provide ample of documentation for doing this. Do it at your own risk, though and do not say you have not been warned.
2.2.3 Recharging
A mostly-overlooked topic when it comes to DRAM access is recharging. As explained in Section 2.1.2, DRAM cells must constantly be refreshed. This does not happen completely transparently for the rest of the system. At times when a row {Rows are the granularity this happens with despite what [highperfdram] and other literature says (see [micronddr]).} is recharged no access is possible. The study in [highperfdram] found that “[s]urprisingly, DRAM refresh organization can affect performance dramatically”.
Each DRAM cell must be refreshed every 64ms according to the JEDEC specification. If a DRAM array has 8,192 rows this means the memory controller has to issue a refresh command on average every 7.8125µs (refresh commands can be queued so in practice the maximum interval between two requests can be higher). It is the memory controller's responsibility to schedule the refresh commands. The DRAM module keeps track of the address of the last refreshed row and automatically increases the address counter for each new request.
There is really not much the programmer can do about the refresh and the points in time when the commands are issued. But it is important to keep this part to the DRAM life cycle in mind when interpreting measurements. If a critical word has to be retrieved from a row which currently is being refreshed the processor could be stalled for quite a long time. How long each refresh takes depends on the DRAM module.
2.2.4 Memory Types
It is worth spending some time on the current and soon-to-be current memory types in use. We will start with SDR (Single Data Rate) SDRAMs since they are the basis of the DDR (Double Data Rate) SDRAMs. SDRs were pretty simple. The memory cells and the data transfer rate were identical.
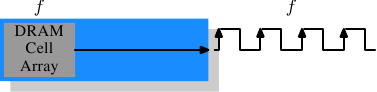
Figure 2.10: SDR SDRAM Operation
In Figure 2.10 the DRAM cell array can output the memory content at the same rate it can be transported over the memory bus. If the DRAM cell array can operate at 100MHz, the data transfer rate of the bus is thus 100Mb/s. The frequency f for all components is the same. Increasing the throughput of the DRAM chip is expensive since the energy consumption rises with the frequency. With a huge number of array cells this is prohibitively expensive. {Power = Dynamic Capacity × Voltage2 × Frequency.} In reality it is even more of a problem since increasing the frequency usually also requires increasing the voltage to maintain stability of the system. DDR SDRAM (called DDR1 retroactively) manages to improve the throughput without increasing any of the involved frequencies.
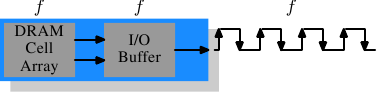
Figure 2.11: DDR1 SDRAM Operation
The difference between SDR and DDR1 is, as can be seen in Figure 2.11 and guessed from the name, that twice the amount of data is transported per cycle. I.e., the DDR1 chip transports data on the rising and falling edge. This is sometimes called a “double-pumped” bus. To make this possible without increasing the frequency of the cell array a buffer has to be introduced. This buffer holds two bits per data line. This in turn requires that, in the cell array in Figure 2.7, the data bus consists of two lines. Implementing this is trivial: one only has the use the same column address for two DRAM cells and access them in parallel. The changes to the cell array to implement this are also minimal.
The SDR DRAMs were known simply by their frequency (e.g., PC100 for 100MHz SDR). To make DDR1 DRAM sound better the marketers had to come up with a new scheme since the frequency did not change. They came with a name which contains the transfer rate in bytes a DDR module (they have 64-bit busses) can sustain:
100MHz × 64bit × 2 = 1,600MB/s
Hence a DDR module with 100MHz frequency is called PC1600. With 1600 > 100 all marketing requirements are fulfilled; it sounds much better although the improvement is really only a factor of two. {I will take the factor of two but I do not have to like the inflated numbers.}
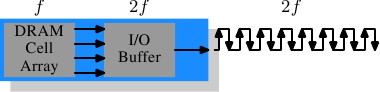
Figure 2.12: DDR2 SDRAM Operation
To get even more out of the memory technology DDR2 includes a bit more innovation. The most obvious change that can be seen in Figure 2.12 is the doubling of the frequency of the bus. Doubling the frequency means doubling the bandwidth. Since this doubling of the frequency is not economical for the cell array it is now required that the I/O buffer gets four bits in each clock cycle which it then can send on the bus. This means the changes to the DDR2 modules consist of making only the I/O buffer component of the DIMM capable of running at higher speeds. This is certainly possible and will not require measurably more energy, it is just one tiny component and not the whole module. The names the marketers came up with for DDR2 are similar to the DDR1 names only in the computation of the value the factor of two is replaced by four (we now have a quad-pumped bus). Figure 2.13 shows the names of the modules in use today.
Array
Freq.Bus
Freq.Data
RateName
(Rate)Name
(FSB)133MHz 266MHz 4,256MB/s PC2-4200 DDR2-533 166MHz 333MHz 5,312MB/s PC2-5300 DDR2-667 200MHz 400MHz 6,400MB/s PC2-6400 DDR2-800 250MHz 500MHz 8,000MB/s PC2-8000 DDR2-1000 266MHz 533MHz 8,512MB/s PC2-8500 DDR2-1066 Figure 2.13: DDR2 Module Names
There is one more twist to the naming. The FSB speed used by CPU, motherboard, and DRAM module is specified by using the effective frequency. I.e., it factors in the transmission on both flanks of the clock cycle and thereby inflates the number. So, a 133MHz module with a 266MHz bus has an FSB “frequency” of 533MHz.
The specification for DDR3 (the real one, not the fake GDDR3 used in graphics cards) calls for more changes along the lines of the transition to DDR2. The voltage will be reduced from 1.8V for DDR2 to 1.5V for DDR3. Since the power consumption equation is calculated using the square of the voltage this alone brings a 30% improvement. Add to this a reduction in die size plus other electrical advances and DDR3 can manage, at the same frequency, to get by with half the power consumption. Alternatively, with higher frequencies, the same power envelope can be hit. Or with double the capacity the same heat emission can be achieved.
The cell array of DDR3 modules will run at a quarter of the speed of the external bus which requires an 8 bit I/O buffer, up from 4 bits for DDR2. See Figure 2.14 for the schematics.
Figure 2.14: DDR3 SDRAM Operation
Initially DDR3 modules will likely have slightly higher CAS latencies just because the DDR2 technology is more mature. This would cause DDR3 to be useful only at frequencies which are higher than those which can be achieved with DDR2, and, even then, mostly when bandwidth is more important than latency. There is already talk about 1.3V modules which can achieve the same CAS latency as DDR2. In any case, the possibility of achieving higher speeds because of faster buses will outweigh the increased latency.
One possible problem with DDR3 is that, for 1,600Mb/s transfer rate or higher, the number of modules per channel may be reduced to just one. In earlier versions this requirement held for all frequencies, so one can hope that the requirement will at some point be lifted for all frequencies. Otherwise the capacity of systems will be severely limited.
Figure 2.15 shows the names of the expected DDR3 modules. JEDEC agreed so far on the first four types. Given that Intel's 45nm processors have an FSB speed of 1,600Mb/s, the 1,866Mb/s is needed for the overclocking market. We will likely see more of this towards the end of the DDR3 lifecycle.
Array
Freq.Bus
Freq.Data
RateName
(Rate)Name
(FSB)100MHz 400MHz 6,400MB/s PC3-6400 DDR3-800 133MHz 533MHz 8,512MB/s PC3-8500 DDR3-1066 166MHz 667MHz 10,667MB/s PC3-10667 DDR3-1333 200MHz 800MHz 12,800MB/s PC3-12800 DDR3-1600 233MHz 933MHz 14,933MB/s PC3-14900 DDR3-1866 Figure 2.15: DDR3 Module Names
All DDR memory has one problem: the increased bus frequency makes it hard to create parallel data busses. A DDR2 module has 240 pins. All connections to data and address pins must be routed so that they have approximately the same length. Even more of a problem is that, if more than one DDR module is to be daisy-chained on the same bus, the signals get more and more distorted for each additional module. The DDR2 specification allow only two modules per bus (aka channel), the DDR3 specification only one module for high frequencies. With 240 pins per channel a single Northbridge cannot reasonably drive more than two channels. The alternative is to have external memory controllers (as in Figure 2.2) but this is expensive.
What this means is that commodity motherboards are restricted to hold at most four DDR2 or DDR3 modules. This restriction severely limits the amount of memory a system can have. Even old 32-bit IA-32 processors can handle 64GB of RAM and memory demand even for home use is growing, so something has to be done.
One answer is to add memory controllers into each processor as explained in Section 2. AMD does it with the Opteron line and Intel will do it with their CSI technology. This will help as long as the reasonable amount of memory a processor is able to use can be connected to a single processor. In some situations this is not the case and this setup will introduce a NUMA architecture and its negative effects. For some situations another solution is needed.
Intel's answer to this problem for big server machines, at least for the next years, is called Fully Buffered DRAM (FB-DRAM). The FB-DRAM modules use the same components as today's DDR2 modules which makes them relatively cheap to produce. The difference is in the connection with the memory controller. Instead of a parallel data bus FB-DRAM utilizes a serial bus (Rambus DRAM had this back when, too, and SATA is the successor of PATA, as is PCI Express for PCI/AGP). The serial bus can be driven at a much higher frequency, reverting the negative impact of the serialization and even increasing the bandwidth. The main effects of using a serial bus are
- more modules per channel can be used.
- more channels per Northbridge/memory controller can be used.
- the serial bus is designed to be fully-duplex (two lines).
An FB-DRAM module has only 69 pins, compared with the 240 for DDR2. Daisy chaining FB-DRAM modules is much easier since the electrical effects of the bus can be handled much better. The FB-DRAM specification allows up to 8 DRAM modules per channel.
Compared with the connectivity requirements of a dual-channel Northbridge it is now possible to drive 6 channels of FB-DRAM with fewer pins: 2×240 pins versus 6×69 pins. The routing for each channel is much simpler which could also help reducing the cost of the motherboards.
Fully duplex parallel busses are prohibitively expensive for the traditional DRAM modules, duplicating all those lines is too costly. With serial lines (even if they are differential, as FB-DRAM requires) this is not the case and so the serial bus is designed to be fully duplexed, which means, in some situations, that the bandwidth is theoretically doubled alone by this. But it is not the only place where parallelism is used for bandwidth increase. Since an FB-DRAM controller can run up to six channels at the same time the bandwidth can be increased even for systems with smaller amounts of RAM by using FB-DRAM. Where a DDR2 system with four modules has two channels, the same capacity can handled via four channels using an ordinary FB-DRAM controller. The actual bandwidth of the serial bus depends on the type of DDR2 (or DDR3) chips used on the FB-DRAM module.
We can summarize the advantages like this:
DDR2 FB-DRAM Pins 240 69 Channels 2 6 DIMMs/Channel 2 8 Max Memory 16GB 192GB Throughput ~10GB/s ~40GB/s
There are a few drawbacks to FB-DRAMs if multiple DIMMs on one channel are used. The signal is delayed—albeit minimally—at each DIMM in the chain, which means the latency increases. But for the same amount of memory with the same frequency FB-DRAM can always be faster than DDR2 and DDR3 since only one DIMM per channel is needed; for large memory systems DDR simply has no answer using commodity components.
2.2.5 Conclusions
This section should have shown that accessing DRAM is not an arbitrarily fast process. At least not fast compared with the speed the processor is running and with which it can access registers and cache. It is important to keep in mind the differences between CPU and memory frequencies. An Intel Core 2 processor running at 2.933GHz and a 1.066GHz FSB have a clock ratio of 11:1 (note: the 1.066GHz bus is quad-pumped). Each stall of one cycle on the memory bus means a stall of 11 cycles for the processor. For most machines the actual DRAMs used are slower, thusly increasing the delay. Keep these numbers in mind when we are talking about stalls in the upcoming sections.
The timing charts for the read command have shown that DRAM modules are capable of high sustained data rates. Entire DRAM rows could be transported without a single stall. The data bus could be kept occupied 100%. For DDR modules this means two 64-bit words transferred each cycle. With DDR2-800 modules and two channels this means a rate of 12.8GB/s.
But, unless designed this way, DRAM access is not always sequential. Non-continuous memory regions are used which means precharging and new RAS signals are needed. This is when things slow down and when the DRAM modules need help. The sooner the precharging can happen and the RAS signal sent the smaller the penalty when the row is actually used.
Hardware and software prefetching (see Section 6.3) can be used to create more overlap in the timing and reduce the stall. Prefetching also helps shift memory operations in time so that there is less contention at later times, right before the data is actually needed. This is a frequent problem when the data produced in one round has to be stored and the data required for the next round has to be read. By shifting the read in time, the write and read operations do not have to be issued at basically the same time.
2.3 Other Main Memory Users
Beside the CPUs there are other system components which can access the main memory. High-performance cards such as network and mass-storage controllers cannot afford to pipe all the data they need or provide through the CPU. Instead, they read or write the data directly from/to the main memory (Direct Memory Access, DMA). In Figure 2.1 we can see that the cards can talk through the South- and Northbridge directly with the memory. Other buses, like USB, also require FSB bandwidth—even though they do not use DMA—since the Southbridge is connected to the Northbridge through the FSB, too.
While DMA is certainly beneficial, it means that there is more competition for the FSB bandwidth. In times with high DMA traffic the CPU might stall more than usual while waiting for data from the main memory. There are ways around this given the right hardware. With an architecture as in Figure 2.3 one can make sure the computation uses memory on nodes which are not affected by DMA. It is also possible to attach a Southbridge to each node, equally distributing the load on the FSB of all the nodes. There are a myriad of possibilities. In Section 6 we will introduce techniques and programming interfaces which help achieving the improvements which are possible in software.
Finally it should be mentioned that some cheap systems have graphics systems without separate, dedicated video RAM. Those systems use parts of the main memory as video RAM. Since access to the video RAM is frequent (for a 1024x768 display with 16 bpp at 60Hz we are talking 94MB/s) and system memory, unlike RAM on graphics cards, does not have two ports this can substantially influence the systems performance and especially the latency. It is best to ignore such systems when performance is a priority. They are more trouble than they are worth. People buying those machines know they will not get the best performance.
- Part 2 (CPU caches)
- Part 3 (Virtual memory)
- Part 4 (NUMA systems)
- Part 5 (What programmers can do - cache optimization)
- Part 6 (What programmers can do - multi-threaded optimizations)
- Part 7 (Memory performance tools)
- Part 8 (Future technologies)
- Part 9 (Appendices and bibliography)
Security
Bandit: multi-protocol identity management
The Novell-sponsored Bandit project is a relatively new entry into the somewhat crowded digital identity space. Bandit is trying to unify the disparate protocols and mechanisms for authentication into a consistent view for users and applications. This would allow a user to be independent of the underlying authentication method used, while allowing them full control over what information is released to a site requesting personal information.
One of the more annoying "features" of the web is the necessity of signing up with various sites, often using the same information (name, email address, mailing address, etc.). Once that is done, users need to remember their password at each site, which often means taking a very insecure shortcut by using the same one everywhere. Even a quick correction or pointer added into a comment thread will often require creating an account and logging in, definitely a barrier to quick and easy internet discourse. LWN is as "guilty" as most other sites, as there is no other simple solution to reducing comment spam.
The idea behind Bandit, and the other identity management systems, is to provide a means for users to manage this information, present it to sites they wish to use, without retyping their full name and contact information all over the place. It can also store more sensitive information, credit card numbers and the like. Unlike other, centralized schemes, the user information can be stored locally, with external servers used to validate a connection between an identity and the credentials presented.
Where Bandit is different is that it intends to try and encompass various other free authentication mechanisms and interoperate with them. In some ways it is like a web browser, in that it incorporates multiple different protocols (http, ftp, local file access, etc.) into a single view for the user. Bandit extends the browser by providing a plug-in for Firefox that communicates with their DigitalMe identity manager.
DigitalMe will do the heavy lifting of keeping track of the identities, where and how they are stored, as well as how to communicate that to the requesting site (aka relying party). The Firefox plug-in will present the stored identities to the user allowing them to choose one. It will also display the information requested by the relying party and allow the user to select which they will allow to be sent, keeping the user firmly in control.
An auditing framework is also part of Bandit, to allow companies to ensure that the identities are used in compliance with regulations or company standards. One of the use cases described for Bandit is for a company with identity cards that their employees use to log in to their systems. All of the identity information for those users would be stored by the company, rather than the employee, which would allow the company to recover them when an employee leaves. The identities would correspond to various company-run services as well as vendor or customer systems that are used by the employee.
Because it incorporates so many different standards and protocols, Bandit is even more of an alphabet soup than other identity systems. It is difficult to see, yet, whether it lives up to its grand vision. The project has released some code, but DigitalMe is currently only packaged for SuSE Linux distributions. But it is all free software, mostly licensed under the LGPL and certainly has some interesting ideas.
Windows has its own idea of identity management, CardSpace, that Bandit can also interoperate with in some fashion. Novell is demonstrating the technology and its interoperability with CardSpace at the Digital ID World conference this week. In conjunction with the conference, Novell is also promoting a "Control Your Identity" campaign that is encouraging users to get Bandit cards.
Like much of the work in this area, Bandit shows a lot of promise, but in order for it, or any other identity management framework, to succeed, there must be user interest. Plenty of complaints are heard about identity handling and the need to sign on seemingly everywhere on the web, but so far, no solution has really made a lot of headway. Because it intends to incorporate most of the solutions out there, Bandit may have a better chance than most.
New vulnerabilities
bugzilla: unauthorized account creation
| Package(s): | bugzilla | CVE #(s): | CVE-2007-5038 | ||||
| Created: | September 25, 2007 | Updated: | September 26, 2007 | ||||
| Description: | The offer_account_by_email function in User.pm in the WebService for Bugzilla before 3.0.2, and 3.1.x before 3.1.2, does not check the value of the createemailregexp parameter, which allows remote attackers to bypass intended restrictions on account creation. | ||||||
| Alerts: |
| ||||||
elinks: remote data sniffing
| Package(s): | elinks | CVE #(s): | CVE-2007-5034 | ||||||||||||||||||||||||
| Created: | September 25, 2007 | Updated: | October 9, 2007 | ||||||||||||||||||||||||
| Description: | ELinks before 0.11.3, when sending a POST request for an https URL, appends the body and content headers of the POST request to the CONNECT request in cleartext, which allows remote attackers to sniff sensitive data that would have been protected by TLS. NOTE: this issue only occurs when a proxy is defined for https. | ||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||
fuse: incorrect file access permissions
| Package(s): | fuse | CVE #(s): | |||||
| Created: | September 26, 2007 | Updated: | September 26, 2007 | ||||
| Description: | It was discovered that members of the group fuse can get access to devices which they normally should not have access to. For ntfs-3g mounts, this was because /sbin/mount.ntfs-3g was setuid root. This update fixes /sbin/mount.ntfs-3g so that it is no longer has the setuid bit enabled. The fuse package is also being updated to correct an error in the previous testing package which incorrectly changed the permissions on /dev/fuse. | ||||||
| Alerts: |
| ||||||
httpd: denial of service, cross-site scripting
| Package(s): | apache httpd | CVE #(s): | CVE-2007-3847 CVE-2007-4465 | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | September 25, 2007 | Updated: | February 15, 2008 | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | A flaw was found in the mod_proxy module. On sites where a reverse proxy is
configured, a remote attacker could send a carefully crafted request that
would cause the Apache child process handling that request to crash. On
sites where a forward proxy is configured, an attacker could cause a
similar crash if a user could be persuaded to visit a malicious site using
the proxy. This could lead to a denial of service if using a threaded
Multi-Processing Module. (CVE-2007-3847)
A flaw was found in the mod_autoindex module. On sites where directory listings are used, and the AddDefaultCharset directive has been removed from the configuration, a cross-site-scripting attack may be possible against browsers which do not correctly derive the response character set following the rules in RFC 2616. (CVE-2007-4465) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||
JRockit: multiple vulnerabilities
| Package(s): | jrockit-jdk-bin | CVE #(s): | CVE-2007-2788 CVE-2007-4381 CVE-2007-3716 CVE-2007-2789 CVE-2007-3004 CVE-2007-3005 CVE-2007-3503 CVE-2007-3698 CVE-2007-3922 | ||||||||||||||||||||||||||||
| Created: | September 24, 2007 | Updated: | June 24, 2008 | ||||||||||||||||||||||||||||
| Description: | An integer overflow vulnerability exists in the embedded ICC profile image parser (CVE-2007-2788), an unspecified vulnerability exists in the font parsing implementation (CVE-2007-4381), and an error exists when processing XSLT stylesheets contained in XSLT Transforms in XML signatures (CVE-2007-3716), among other vulnerabilities. | ||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||
kdebase: kdm passwordless login vulnerability
| Package(s): | kdebase kdm | CVE #(s): | CVE-2007-4569 | ||||||||||||||||||||||||||||||||
| Created: | September 21, 2007 | Updated: | November 13, 2007 | ||||||||||||||||||||||||||||||||
| Description: | According to this KDE advisory KDM can be tricked into performing a password-less login even for accounts with a password set under certain circumstances, namely autologin to be configured and "shutdown with password" enabled. KDE versions 3.3.0 up to including 3.5.7 are vulnerable. | ||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||
kernel: out-of-bounds access
| Package(s): | kernel | CVE #(s): | CVE-2007-4573 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | September 25, 2007 | Updated: | December 6, 2010 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | The IA32 system call emulation functionality in Linux kernel 2.4.x and 2.6.x before 2.6.22.7, when running on the x86_64 architecture, does not zero extend the eax register after the 32bit entry path to ptrace is used, which might allow local users to gain privileges by triggering an out-of-bounds access to the system call table using the %RAX register. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
libsndfile: heap-based buffer overflow
| Package(s): | libsndfile | CVE #(s): | CVE-2007-4974 | ||||||||||||||||||||||||
| Created: | September 25, 2007 | Updated: | January 9, 2008 | ||||||||||||||||||||||||
| Description: | Heap-based buffer overflow in libsndfile 1.0.17 and earlier might allow remote attackers to execute arbitrary code via a FLAC file with crafted PCM data containing a block with a size that exceeds the previous block size. | ||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||
postgresql: several vulnerabilities
| Package(s): | postgresql | CVE #(s): | CVE-2007-3278 CVE-2007-3279 CVE-2007-3280 | ||||||||||||||||||||||||||||||||
| Created: | September 25, 2007 | Updated: | February 1, 2008 | ||||||||||||||||||||||||||||||||
| Description: | PostgreSQL 8.1 and probably later and earlier versions, when local trust
authentication is enabled and the Database Link library (dblink) is
installed, allows remote attackers to access arbitrary accounts and execute
arbitrary SQL queries via a dblink host parameter that proxies the
connection from 127.0.0.1. (CVE-2007-3278)
PostgreSQL 8.1 and probably later and earlier versions, when the PL/pgSQL (plpgsql) language has been created, grants certain plpgsql privileges to the PUBLIC domain, which allows remote attackers to create and execute functions, as demonstrated by functions that perform local brute-force password guessing attacks, which may evade intrusion detection. (CVE-2007-3279) The Database Link library (dblink) in PostgreSQL 8.1 implements functions via CREATE statements that map to arbitrary libraries based on the C programming language, which allows remote authenticated superusers to map and execute a function from any library, as demonstrated by using the system function in libc.so.6 to gain shell access. (CVE-2007-3280) | ||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||
t1lib: buffer overflow
| Package(s): | t1lib | CVE #(s): | CVE-2007-4033 | ||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | September 20, 2007 | Updated: | February 12, 2008 | ||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | T1lib, an enhanced rasterizer for X11 Type 1 fonts, does not properly perform bounds checking. An attacker can send specially crafted input to applications linked against the library in order to create a buffer overflow, resulting in a denial of service or the execution of arbitrary code. | ||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||
tomcat: multiple vulnerabilities
| Package(s): | tomcat | CVE #(s): | CVE-2007-3382 CVE-2007-3385 CVE-2007-3386 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | September 26, 2007 | Updated: | September 13, 2010 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | Tomcat was found treating single quote characters -- ' -- as delimiters in
cookies. This could allow remote attackers to obtain sensitive information,
such as session IDs, for session hijacking attacks (CVE-2007-3382).
It was reported Tomcat did not properly handle the following character sequence in a cookie: \" (a backslash followed by a double-quote). It was possible remote attackers could use this failure to obtain sensitive information, such as session IDs, for session hijacking attacks (CVE-2007-3385). A cross-site scripting (XSS) vulnerability existed in the Host Manager Servlet. This allowed remote attackers to inject arbitrary HTML and web script via crafted requests (CVE-2007-3386). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Page editor: Jake Edge
Kernel development
Brief items
Kernel release status
The current 2.6 prepatch is 2.6.23-rc8, released on September 24. It contains a relatively small number of fixes, and Linus is confident that the final release is getting close. "Of course, me feeling happy is usually immediately followed by some nasty person finding new problems, but I'll just ignore that and enjoy the feeling anyway, however fleeting it may be."
As of this writing, about 50 post-rc8 patches have gone into the mainline repository.
The current -mm tree is 2.6.23-rc8-mm1. Recent changes to -mm include some ext4 enhancements, support for read-only bind mounts, some kdump improvements, and a rework of the NFS export code.
The current stable 2.6 kernel is 2.6.22.9, released on September 26. It contains a few dozen fixes for problems throughout the kernel. 2.6.22.8, released on September 24, contains a single security fix for a privilege escalation vulnerability in the sound subsystem. 2.6.22.7, released on the 21st, is also a single-fix update; this one addresses an x86_64-only privilege escalation problem. There is a larger 2.6.22 update in the works which should be released shortly.
For older kernels: 2.6.20.20, released on September 23, fixes the x86_64 vulnerability and one other bug. The 2.6.16 series returned on September 25 with 2.6.16.54-rc1, which contains a fair number of fixes. 2.4.35.3 (September 23) also has the x86_64 fix and a couple of others.
Kernel development news
Quotes of the week
MadWifi developers move to ath5k
The developers for the MadWifi project have announced their intention to move away from their current Atheros driver (which contains a binary-only component) and, instead, work on the development of the free ath5k driver. "To underline our decision and commitment to ath5k we now declare MadWifi 'legacy.'. In the long run ath5k will replace the MadWifi driver. For the time being MadWifi will still be supported, bugs will get fixed and HAL updates will be applied where possible. But it becomes unlikely that we'll see new features or go through major changes on that codebase."
Reviving linux-tiny
An announcement of the revival of linux-tiny, a set of patches aimed at reducing the footprint of the kernel, mainly for the embedded world, has led to a number of linux-kernel threads. The conversations range from the proper place for linux-tiny to reside to the removal of the enormous number of printk() strings in the kernel. They provide an interesting glimpse into the kernel development process.
The linux-tiny project was started
by Matt Mackall in December 2003 with the aim to "collect patches that
reduce kernel disk and memory footprint as well as tools for working
on small systems.
" LWN covered
the announcement at the time and tried out the patches more than
a year ago. Many of the linux-tiny features have found their way into the
mainline, but quite a few still remain outside.
The Consumer Electronics Linux Forum (CELF) is behind the effort to revive the project, with Tim Bird, architecture group chair, announcing the plan, including a new maintainer, Michael Opdenacker. The first step has been mostly completed, bringing the patches forward from the 2.6.14 kernel to 2.6.22. A status page has been established to track the progress of updating the patches, but it is clear that moving them into the mainline, rather than maintaining them as patches, is a big motivation behind the revival.
Andrew Morton immediately volunteered to manage the linux-tiny patches in an answer to the revival message:
Reactions were quite favorable, with the maintainer, Opdenacker responding:
I'm finishing a sequence of crazy weeks and I will have time to send you patches one by one next week, starting with the easiest ones.
The full patchset will live in a separate repository as the individual patches are being worked on for inclusion, but it is clear that no one wants to continuously maintain and out-of-tree patchset for a long time. The cost of ensuring that the patches do not bitrot is large and their inclusion in the mainline will get them in the hands of more developers.
From there, more detailed discussion of how to structure the patches - and tiny features in general - ensued. A separate discussion also came about regarding printk() and the large amounts of memory it consumes with all of its static strings. printk() has long been seen as an area that could be improved to reduce the memory footprint of the kernel.
All sorts of kernel messages are printed to logfiles or the console via printk(); there are something on the order of 60,000 calls in 2.6. There can be a severity level associated with a specific call, which provides a primitive syslog-style categorization of the messages. Unfortunately, in the mainline, those calls are either present, with all the associated memory for the strings, or completely absent, compiled out via a config option. It is rather difficult to diagnose problems without at least some printk() information, but keeping all of the data in can increase the size of the kernel 5-10%.
Rob Landley started things off with a way to make it possible to only compile in messages based on their severity level. An embedded developer could remove KERN_NOTICE, KERN_DEBUG and similar low severity messages while keeping the more critical messages:
Landley's suggestion has a drawback in that it would require a flag day for printk() or the creation of a new function that implemented his suggestion with relevant changes trickling into the kernel over time. In the meantime, small-system developers would still be looking for ways to get the messages they want, while removing the others from the code. There was also discussion of using separate calls for each severity level, where pr_info(), or some similar name, would produce messages with that level. The preprocessor could then be used to remove those that a developer is not interested in.
The discussion led Vegard Nossum to put together an RFC for a new kernel-message logging API. He starts with requirements that the API be backwards-compatible with the existing printk() usage, with the output format being extensible at either compile or run time. The RFC also tries to handle the case of multiple printk() calls to emit what is essentially a single message, but it seems like an over-engineered solution to what should be a fairly straightforward problem.
Another contender, one that is already part of the linux-tiny patchset, is Tim Bird's DoPrintk patch. This allows developers to selectively choose source code files for which printk() will be enabled, removing it from the rest of the code and resulting kernel image. While not allowing fine-grained selection of messages based on severity, it does put more control into the hands of developers.
It is too early to say which, if any, printk() changes are coming down the pike. There does seem to be a lot of interest in helping small systems reduce their kernel footprint without sacrificing all diagnostic messages. printk() is claimed to be one of the lowest hanging fruit for significant kernel size reduction, which would seem to make it a likely candidate for change.
The new timerfd() API
The timerfd() system call was added in the 2.6.22 kernel. The core idea behind timerfd() - allowing a process to associate a file descriptor with timer events - is not controversial, but the implementation of this idea did, belatedly, raise a few eyebrows. In particular, Michael Kerrisk pointed out that timerfd() was inconsistent with (and less powerful than) the existing timer-related system calls, and, besides, the 2.6.22 version did not even work as advertised. After a fair amount of discussion, it became clear that the issues with this system call would not be worked out in the 2.6.23 time frame. So the 2.6.23-rc7 prepatch disabled timerfd() altogether in an attempt to prevent application developers from using an API which is going to change.Prompted by all of this, Davide Libenzi (the creator of the original timerfd() system call) has posted a proposal for a revised timerfd() API. The single system call has turned into three different calls with a few new features.
Under the new API, an application wanting to create a file descriptor for timer events would make a call to:
int timerfd_create(int clockid);
Where clockid describes which clock should be used; it will be either CLOCK_MONOTONIC or CLOCK_REALTIME. The return value will, if all goes well, be the requested file descriptor.
A timer event can be requested with:
int timerfd_settime(int fd, int flags, const struct itimerspec *timer,
struct itimerspec *previous);
Here, fd is a file descriptor obtained from timerfd_create(), and timer gives the desired expiration time (and re-arming interval value, if desired). This time is normally a relative time, but if the timer sets the TFD_TIMER_ABSTIME bit in flags, it will be interpreted as an absolute time instead. If previous is not NULL, the pointed-to structure will be filled with the previous value of the timer. This ability to obtain the previous value is one of the features which was lacking in the original timerfd() implementation.
That implementation also had no way for an application to simply ask what the current value of the timer was. The new API provides a function for querying a timer non-destructively:
int timerfd_gettime(int fd, struct itimerspec *timer);
This system call will store the current expiration time (if any) associated with fd into timer.
The read() interface is essentially unchanged. A process which reads on a timer file descriptor will block if the timer has not yet expired. It will then read a 64-bit integer value indicating how many times the timer has expired since it was last read. A timer file descriptor can be passed to poll(), allowing timers to be handled in an applications main event loop.
Responses to the new API proposal have been muted at best; hopefully this silence means that developers are happy with the new system calls. The alternative is that this iteration of timerfd() will not be reviewed any more extensively than its predecessor was. As things stand, the new set of system calls looks likely to be merged for 2.6.24.
Credential records
Every Linux process carries with it a set of credentials which describe its privileges within the system. Credentials include the user ID, group membership, capabilities, security context, and more. These credentials are currently stored in the task_struct structure associated with each process; an operation which changes credentials does so by operating directly on the task_struct structure. This approach has worked for many years, but it occasionally shows its age.In particular, the current scheme makes life hard for kernel code which needs to adopt a different set of credentials for a limited time. In an attempt to remedy that situation, David Howells has posted a patch which significantly changes the handling of process credentials. The result is a more complex system, but also a system which is more flexible, and, with luck, more secure.
The core idea behind this patch is that all process credentials (attributes which describe how a process can operate on other objects) should be pulled out of the task structure into a separate structure of their own. The result is struct cred, which holds the effective filesystem user and group IDs, the list of group memberships, the effective capabilities, the process keyrings, a generic pointer for security modules, and some housekeeping information. The result is quite a bit of code churn as every access to the old credential information is changed to look into the new cred structure instead.
That churn is complicated by the fact that quite a bit of the credential information has not really moved to the cred structure; instead it is mirrored there. One of the fundamental rules for how struct cred works is that the structure can only be changed by the process it describes. So anything in the structure which can be changed by somebody else - capabilities and keyrings, for example - remain in the task_struct structure and are copied into the cred structure as needed. "As needed," for all practical purposes, means anytime those credentials are to be checked. So most system calls get decorated with this extra bit of code:
result = update_current_cred();
if (result < 0)
return result;
The next rule says that the cred structure can never be altered once it has been attached to a task. Instead, a read-copy-update technique must be used, wherein the cred structure is copied, the new copy is changed, then the pointer from the task_struct structure is set to the new structure. The old one, which is reference counted, persists while it is in use and is eventually disposed of via RCU.
There is a whole set of utility functions for dealing with credentials, a few of which are:
struct cred *get_current_cred();
void put_cred(struct cred *cred);
A call to get_current_cred() takes a reference to the current process's cred structure and returns a pointer to that structure. put_cred() releases a reference.
A change to a credentials structure usually involves a set of calls to:
struct cred *dup_cred(const struct cred *cred);
void set_current_cred(struct cred *cred);
The current credentials can be copied with dup_cred(); the duplicate, once modified, can be made current with set_current_cred(). A set of new hooks has been added to allow security modules to participate in the duplication and setting of credentials.
So far, this infrastructure may seem like a bunch of extra work with the gain yet to be explained. The direction that David is going with this change can be seen with this new function:
struct cred *get_kernel_cred(const char *service,
struct task_struct *daemon);
The purpose of this function is to create a new credentials structure with the requisite privileges for the given service. The daemon pointer indicates a current process which should be used as the source for the new credentials - essentially, the new cred structure will enable its holder to act as if it were the daemon process. The current security module gets a chance to change how those credentials are set up; in fact, the interpretation of the "service" string is only done in security modules. In the absence of a security module, get_kernel_cred() will just duplicate the credentials held by daemon.
This capability is used in a new version of David's venerable FS-Cache (formerly cachefs) patch set. FS-Cache implements a local cache for network-based filesystems; the locally-stored cache will, naturally, have all of the security concerns as the remote filesystem. There is a daemon which does a certain amount of the cache management work, but other accesses to the cache are performed by FS-Cache code running in the context of a process which is working with files on the remote filesystem. Using the above function, the FS-Cache code is able to empower any process to work with the privileges of the daemon process for just as long as is needed to get the filesystem work done.
The end result is that security policies can be carried further into the kernel than before. In the FS-Cache case, kernel code doing caching work always operates under the effective capabilities of the cache management daemon. So any protections, SELinux policies, etc. which apply to the daemon will also apply when FS-Cache work is being done in a different context. This should result in a more secure system overall.
The credential work is still in a relatively early state with a fair amount of work yet to be done. It will be quite a big patch by the time the required changes are made throughout the kernel. So this is not a 2.6.24 candidate. The work is progressing, though, so it will likely be knocking on the mainline door at some point.
Patches and updates
Kernel trees
Core kernel code
Development tools
Device drivers
Documentation
Filesystems and block I/O
Memory management
Networking
Security-related
Virtualization and containers
Miscellaneous
Page editor: Jonathan Corbet
Distributions
News and Editorials
Multimedia with dyne:bolic 2.5
Multimedia creation is one area where free software still lags behind proprietary software. The dyne:bolic GNU/Linux distribution does a pretty good job of filling in that gap, and the recently announced 2.5 release has narrowed it further.Dyne:bolic is easy to use and comes as a live CD full of software for multimedia production, all of it Free Software. Simply copying the /dyne directory from the CD to the users hard disk will install the distribution, without destroying the existing OS. Artists are often not technically inclined, so dyne:bolic strives to make it easy for them to get creating without having to understand the technical aspects of hardware detection and operating systems.
Denis "Jaromil" Rojo is the creator of Rasta Software and dyne:bolic:
while ( love & passion ) {
for( fight = 0 ; rights < freedom ; rights++ )
fight = standup( rights );
free( babylon );
}
Jaromil has been joined by an international community of artists, teachers and developers, all of whom help to adapt dyne:bolic to a variety of uses. The core code, bug tracking, and developers lounge can be found at dyne.org. This core is an important part of dyne:bolic, of course, but the additional applications make it a full-featured distribution. Dyne:bolic includes MuSE for streaming audio, FreeJ for realtime video manipulation, and HasciiCam which makes it possible to have live ascii video on the web.
This version of dyne:bolic also has updated versions of Ardour2, Gimp, Audacity, Nicotine+, Pidgin, Ktorrent, Rox and toolkit libraries such as Gtk, Cairo and Wx. New software in this release includes Ekiga, Guarddog and Wireshark plus all the GtkPython and WxPython libraries. Text console usage has been enhanced by a fully functional mail setup with Mutt, Msmtp, Fetchmail, Procmail and Spamassassin. There's also the text based presentation tool TPP and the Rtorrent download client. A graphical desktop repair button and a mount utility for SSH accounts are also new in this release.
As if all this wouldn't be enough, the dyne:bolic community is
blossoming several specialized modules, developed by and for musicians
and media artists ___ _ _
____ ___ _ _ http://lab.dyne.org/DyneModules
New Releases
Foresight Linux 1.4.0 released
Foresight Linux has announced the release of version 1.4.0. The release announcement has more information: "Foresight Linux is a Linux distribution for your desktop that features a rolling release schedule that always keeps your desktop up to date; a revolutionary package manager, Conary; the latest GNOME desktop environment and an innovative set of excellent, up to date packages. Foresight is proud to be the first distribution to ship with GNOME 2.20 and be the basis for the GNOME Live Media available at http://torrents.gnome.org. Foresight Linux 1.4 features the latest GNOME mentioned above, including updates to Evolution Email and Calendar, Tomboy Notes, Power Manager, Epiphany Web Browser the GNOME Image Viewer, Eye of GNOME and more."
Mandriva Linux 2008 RC2 released
Mandriva Linux 2008 RC2 'Kepler' has been released. New features since the release of RC1 include the final release of GNOME 2.20, the inclusion of the new 8.41.7 version of ATI's proprietary driver in the non-free repository to support Radeon HD cards, significant kernel updates that improve support for certain ATA controllers and many audio chipsets, some new features in the urpmi and rpmdrake package management tools, and over 500 bug fixes since RC1.Announcing openSUSE 10.3 RC1
The first release candidate of openSUSE 10.3 is out. Click below to see the recent changes, most annoying bugs, the call for testing and download information. The second release candidate will not be distributed to mirror sites, but live CD images will be available.PC-BSD 1.4 Released
The PC-BSD team has announced the release of PC-BSD 1.4. PC-BSD 1.4 is based on FreeBSD 6-STABLE and includes X.org 7.2, KDE 3.5.7, Compiz-Fusion 0.5.2 and more.Ubuntu's Launchpad 1.1.9 released
Launchpad is the suite of tools used to develop Ubuntu and siblings. Click below to see what's new in version 1.1.9.
Distribution News
New dpkg in Debian experimental
A new version of dpkg is in Debian's experimental branch. "So please test this version. While rewriting/improving dpkg-shlibdeps I dealt with all the outstanding bugs and I made it a bit more strict. Most notably, packages which generate the warning "unable to find dependency information for shared library" will FTBFS. You'll find a list at the end of this mail."
First CFV for Debian Constitutional amendment: reduce the length of DPL election process
A call for votes has gone out on a Constitutional amendment that would reduce the length of the Debian Project Leader election process.Cast your vote for the Fedora 8 Codename!
Those who have a Fedora Account are asked to vote for the Fedora 8 codename before October 5.Mandriva simplifies its new range of products: Mandriva Linux 2008
Mandriva describes the various flavors of Mandriva Linux 2008 that will be available once this version is finalized.Advance notice of discontinuation of SUSE Linux 10.0
SUSE Security has announced that SUSE Linux 10.0 will be discontinued soon. "Having provided security-relevant fixes for more than two years, vulnerabilities found in SUSE Linux 10.0 after November 15th 2007 will not be fixed any more for this product. We expect to release the last updates around November 30th 2007." SUSE Linux 10.0 is not SUSE Linux Enterprise Server 10. The Enterprise Server has a longer support cycle.
2007 Google Summer of Code in Ubuntu - project results
The 2007 Google Summer of Code is over, and most projects mentored by Ubuntu were successfully completed. This code will find its way into forthcoming Ubuntu releases.Ubuntu September 2007 Team Reports
Various Ubuntu teams have made gutsy progress reports. Reports have been included from the Desktop Team, Kernel Team, Kubuntu, MOTU (Masters of The Universe), Mythbuntu, Screencast Team, Server Team, Ubuntu-IRC, Ubuntu Women, and US LoCo Teams Project.
Distribution Newsletters
Gentoo Weekly Newsletter
The Gentoo Weekly Newsletter for September 17, 2007 looks at GWN seeking writers, forums upgrade, GUIs project, Developer of the Week (cla), and several other topics.Ubuntu Weekly News: Issue #58
The Ubuntu Weekly Newsletter for September 22, 2007 covers the Gutsy Gibbon 7.10 beta release, new MOTU members, new Launchpad release, Software Freedom Day organized by the Ubuntu Nicaragua Team, and much more.DistroWatch Weekly, Issue 221
The DistroWatch Weekly for September 24, 2007 is out. "GNOME 2.20 is finally here and we can soon look forward to a range of releases from all the major distributions incorporating the new version into their products; Mandriva Linux 2008 is expected later this week, but openSUSE 10.3 won't be far behind. In other news: Fedora introduces a new desktop theme called Nodoka, Mandriva simplifies its product range before the upcoming release of version 2008, and Ian Murdock reveals some details about Project Indiana, Sun Microsystems' new Solaris-based desktop distribution. The featured story in this week's issue looks at the security and bug fix infrastructure in today's leading distributions, while those readers who were curious about DistroWatch's recent migration from FreeBSD to Debian GNU/Linux will find the answer in the "Site News" section."
Newsletters and articles of interest
Fedora 8 Nodoka Theme
Jonathan Roberts talks with Martin Sourada, creator of the Nodoka theme. "For a while now, Clearlooks has been the default theme in Fedora; in fact, for a long time, Clearlooks has been the default theme in a number of distros thanks to its place as Gnome's default. Aiming to give Fedora its own distinct and modern appearance is Nodoka: based on its own theme engine it's extremely fast, and when seen in combination with the rest of the artwork for Fedora 8 is beautiful."
Distribution reviews
KateOS - Getting Better with Age (TuxMachines)
TuxMachines reviews KateOS 3.6. "KateOS 3.6 was released a few days ago. Since KateOS has always been one of my favorite distributions and since I haven't looked at it recently, I decided to take it for a test run on my HP Pavillion laptop. It always supported the hardware on my desktop, so I was interested to see how it would fare with wireless ethernet and powersaving features. There are two versions available: a full 2.4 GB DVD and a 700 MB live CD. I chose the 700 MB live CD."
The best desktop Linux for Windows users: Xandros 4 (DesktopLinux)
DesktopLinux begins a series on the "best Linux desktop" with a look at the best system for a Windows user. "What's the best desktop Linux? For me, it's SimplyMEPIS 6.5, soon to be replaced by 7.0. But this is both a dumb question and a dumb answer. The real question is: What's the best desktop operating system for you?"
Page editor: Rebecca Sobol
Development
Run Linux apps on other platforms with LINA
LINA is an interoperability product that is being developed by Lina Software:
![[LINA]](https://static.lwn.net/images/ns/LINA.png)
The LINA FAQ explains some of the project details. LINA has been in development for four years and there are several patents pending on the LINA technology. In addition:
- LINA is written in C and C++ and uses some Python build tools.
- LINA currently runs on Fedora7, OpenSUSE 10.2, Ubuntu 7.04, Mac OS X v. , Windows Vista, Windows XP and Windows 2003.
- Plans to support Solaris and OpenBSD are underway.
- Command line and web applications can be run on LINA.
- GUI applications that use the LINA library are supported.
- Plans are underway for support of GUI applications that use Qt and GTK+.
- Supported languages include C and C++ with plans to add Perl, Python and Ruby.
- LINA packages consist of Linux binaries packed into a .zip file.
- LINA applications currently have a 2X performance hit, that should improve with time.
- The LINA platform is approximately 75MB in size.
- LINA does not currently support 3D graphics acceleration or X11 over SSL.
- Lina Software is offering support for LINA.
See the LINA technology description for more information on the project.
Lina Software recently announced the release of LINA (starting with version 0.7.0) under the GPLv2 license:
The LINA source code is available for download here, the build instructions explain how to compile the software. Some LINA screenshots show the software in action.
If you have some simple Linux command line applications that you need to run across numerous platforms, LINA may be a solution that is worth further investigation.
System Applications
Audio Projects
Rivendell 0.9.82 released
Version 0.9.82 of Rivendell, a radio station automation system, is out with new functionality.
Clusters and Grids
Allmydata-Tahoe 0.6 announced
Version 0.6 of Allmydata-Tahoe, a secure, decentralized storage grid, has been announced. This release includes new features, improved performance and bug fixes.
Database Software
MySQL Toolkit version 896 released (SourceForge)
Version 896 of MySQL Toolkit has been announced. "This toolkit contains essential command-line utilities for MySQL, such as a table checksum tool and query profiler. It provides missing features such as checking slaves for data consistency, with emphasis on quality and scriptability. This release of MySQL Toolkit adds a new tool, fixes some minor bugs and adds new functionality (especially the ability to run as a daemon) to several of the tools."
PostgreSQL Weekly News
The September 24, 2007 edition of the PostgreSQL Weekly News is online with the latest PostgreSQL DBMS articles and resources.
Printing
Common UNIX Printing System 1.3.2 announced
Version 1.3.2 of CUPS, the Common UNIX Printing System, has been announced. "CUPS 1.3.2 replaces the invalid 1.3.1 release tarballs and fixes some scheduler and printing issues."
Miscellaneous
OpenHPI 2.10 released (SourceForge)
Version 2.10 of OpenHPI is available. "Open HPI is an open source implementation of the SA Forum's Hardware Platform Interface (HPI). HPI provides an abstracted interface to managing computer hardware, typically for chassis and rack based servers."
Desktop Applications
Audio Applications
Amarok's Summer of Code Review (KDE.News)
KDE.News looks at the Google Summer of Code contributions to the Amarok music player application. "This year, Amarok had two summer of code projects under the KDE umbrella. Both of these projects have finished while remaining in continued development and were extremely successful. Read on to learn about two innovative additions to the Amarok project."
Snd-ls 0.9.8.3 released
Version 0.9.8.3 of Snd-ls, a distribution of the sound editor SND, is out with the following fix: "Screwed up the rt_readin_tag fix by adding the wrong file. Big thanks to "edu" for reporting the problem so quickly."
BitTorrent Applications
Azureus 3.0.3.0 released (SourceForge)
Version 3.0.3.0 of Azureus, a cross-platform bittorrent client, has been announced. "Azureus 3.0.3.0 brings the version numbering back into line and should reduce confusion over which 2.x version maps to which 3.x version. Existing 2.x users will get the classic UI, while new and existing 3.x users will get the Vuze client UI, with the option to switch back to the 2.x UI if you choose."
Desktop Environments
GNOME Software Announcements
The following new GNOME software has been announced this week:- gtk-engines 2.12.1 (bug fix)
- Sabayon 2.20.1 (bug fix)
KDE Software Announcements
The following new KDE software has been announced this week:- eMule Collection handler 0.1 (initial release)
- gbxgol 0.0.68 (unspecified)
- kooldock 0.4.7 (new features and bug fixes)
- kReiSSy 0.1.0a (initial release)
- KSquirrel 0.7.1try5 (new features and bug fixes)
- Leave Message clone from gnome-2.20 0.1 (unspecified)
- Parley 0.9.0 (unspecified)
- Perl Audio Converter 4.0.0beta2 (new features and bug fixes)
- QtiPlot 0.9 (new features and bug fixes)
- rospell 2007.01 (new features and translation work)
- Smb4K 0.8.5 (build fix and documentation work)
- sqliteman 1.0.1 and 20070925 (bug fixes)
- Tellico 1.2.14 (new features and bug fixes)
Xorg Software Announcements
The following new Xorg software has been announced this week:- xf86-video-ati 6.7.193 (new features and bug fixes)
- xf86-video-nv 2.1.5 (bug fix)
Electronics
GNU Radio Companion 0.69 released
Version 0.69 of GNU Radio Companion (GRC), a GUI front-end for the GNU Radio software programmable radio platform, is out. "GRC and gnuradio have been through many changes these past few months; especially, the adoption of hier2, which has temporarily broken GRC a few times. With the gnuradio trunk stabilized, and 3.1 com[]ing up, a GRC release has been long overdue."
PCB development snapshot 20070912 announced
Development snapshot 20070912 of PCB, an interactive printed circuit board editor for the X11 window system, has been announced. "This release represents nearly 200 commits and as such this summary clearly is not complete."
Financial Applications
Buddi 2.9.3.0 released (SourceForge)
Version 2.9.3.0 of Buddi has been announced "Buddi is a simple budgeting program targeted for users with little or no financial background. It allows users to set up accounts and categories, record transactions, check spending habits, etc. I am pleased to announce the release of Buddi 2.9.3.0. This is the first release in the 3.0 Development branch which is recommended for production use. I have converted my finances to this new version, and I greatly appreciate all those who are able and willing to help me test it."
Fonts and Images
Font rasterization techniques
The Anti-Grain Geometry project has an article on font rendering, covering Linux, Mac, and Windows techniques. It looks at various ways to make text look better on a monitor, including sub-pixel rendering, hinting, and gamma correction. "The Windows way of text rendering is bad, the Linux way is much worse. In all Linux systems I've seen they use FreeType by David Turner, Robert Wilhelm, and Werner Lemberg. It is a great library, really, but the way of using it is not so good." (thanks to Michael Kofler)
Games
FreeCol 0.7.2 released (SourceForge)
Version 0.7.2 of FreeCol has been announced. "FreeCol is an open version of the turn based strategy game Colonization. We have now released version 0.7.2 of FreeCol: - The game can now switch between fullscreen and windowed mode. - The application window can be resized. - Zooming on the mapboard has been implemented"
Instant Messaging
Zimbra Collaboration Suite 4.5.7 released (SourceForge)
Version 4.5.7 of the Zimbra Collaboration Suite has been released. "Zimbra is an open source server and client technology for next-generation enterprise messaging and collaboration. Zimbra delivers innovation for both the administrator and the end-user as well as compatibility with exis[t]ing infrastructure and applications. ZCS 4.5.7 contains 160 fixed issues."
Multimedia
Mpeg4ip 1.6 released (SourceForge)
Version 1.6 of Mpeg4ip, a cross-platform MPEG and IETF standards-based system for encoding, streaming, and playing audio and video, has been announced. "This will be my last release of mpeg4ip; I am changing jobs and can no longer contribute to this project. I will be able to answer questions about it in the forums and email list, but will not be able to actively make changes or maintain it."
Music Applications
horgand 1.12 released
Version 1.12 of horgand, an organ synthesizer, is out with a lot of new capabilities and some bug fixes.
News Readers
Liferea 1.4.3 released (SourceForge)
Stable version 1.4.3 of Liferea, a news aggregator for news feeds and weblogs, has been announced. "While this release fixes several functional issues it also fixes a grave feed update bug that causes continuous feed updates in v1.4.2b when your global default feed update interval was set to zero."
Video Applications
Theora 1.0beta1 released
After several years of development, the first beta release for Ogg Theora 1.0 - a free video codec - is now available. Now all we have to do is to get some content in the Theora format.
Miscellaneous
Sweet Home 3D 1.1 released (SourceForge)
Stable version 1.1 of Sweet Home 3D has been announced. "Sweet Home 3D is an interior design Java application for quickly choosing and placing furniture on a house 2D plan drawn by the end-user, with a final 3D preview."
Languages and Tools
Caml
Caml Weekly News
The September 25, 2007 edition of the Caml Weekly News is out with new Caml language articles.
Haskell
Haskell Weekly News
The September 23, 2007 edition of the Haskell Weekly News is online. This week brings a ridiculous number of new libraries and tools for Haskell programming, and the appearance of half a dozen new user groups, on several continents.
Perl
PDF Processing with Perl (O'Reilly)
Detlef Groth discusses PDF Processing with Perl on O'Reilly. "Adobe's PDF is a well-established format for transferring pixel-perfect documents. It's not nearly as malleable as plain text, but several CPAN modules make creating, manipulating, and reusing PDFs much easier. Detlef Groth demonstrates how to use PDF::Reuse."
Python
Python-URL! - weekly Python news and links
The September 24, 2007 edition of the Python-URL! is online with a new collection of Python article links.
Ruby
Behavior Driven Development Using Ruby (Part 3) (O'ReillyNet)
O'Reilly has published part three of the Behavior Driven Development Using Ruby series. "Gregory Brown has been testing the heck out of his dots and lines game! In the last portion of his dive into behavior driven development, he looks at custom matchers and introduces us to RCov, a coverage visualizer."
Tcl/Tk
Tcl-URL! - weekly Tcl news and links
The September 24, 2007 edition of the Tcl-URL! is online with new Tcl/Tk articles and resources.
Build Tools
JPlate: Parser 0.2 released (SourceForge)
Version 0.2 of the Parser for JPlate has been announced. "JPlate is a framework/toolkit to build applications - think of it as the template for application development. If for some reason releases are not happening in a timely fashion please examine the Subversion repository as you may find more there. This releases fixes documentation, adds a new parser (colon delimited values) and moved some files around to be in more logical locations."
Version Control
GIT 1.5.3.2 announced
Version 1.5.3.2 of GIT, a distributed version control system, is available. This is a maintenance release with numerous bug fixes.
Page editor: Forrest Cook
Linux in the news
Recommended Reading
Defending Openness (Linux Journal)
Glyn Moody looks at challenges to open access and open data. "What this shows is that however many battles are won, the war against closed, proprietary approaches goes on. Open source and open standards have made huge strides, but in other areas - open access and open data, for example - the fight is only beginning. If you want to track what's happening here the best place to go is Peter Suber's Open Access News. This will not only keep you completely up to date on the latest developments in the open access and open data worlds (with a fair amount of related open source stuff thrown in for good measure), but it will also highlight all the important campaigns and petitions that need your help. As recent events in the open source and open standards world have shown, individuals can make a real difference."
Printing Trends in Linux (O'ReillyNet)
Andy Oram covers efforts by the Linux Foundation's Open Printing Working Group on O'Reilly. "Printing has been a notoriously difficult capability to configure in Linux, but work by the Open Printing Working Group is designed to change that. Andy Oram has been examining what we can expect in the future from this initiative, which includes distribution-independent drivers."
Looking for Algae--the Next Voyage (Linux Journal)
Jon maddog Hall spent the winter in Brazil before setting sail in a search for algae. "How does [algae] fit in with computing? Most of the readers of Linux Journal have at least one computer in their houses. I lost count of my own computer stock at about 15, and some of them are real electrical power-eaters. A lot of them have really dangerous chemicals in them, like lead and acidic materials. Fortunately, over time, power requirements per CPU and graphics cycles have gone down, as have costs for the hardware. Manufacturers, either through legislation or social and civic concern, have moved to making their systems from more environmentally-friendly components."
The SCO Problem
Snowed By SCO (Forbes)
As SCO fades away, some of the pro-SCO journalists are being asked some hard questions. Here is the closest thing we'll get to an answer from Dan Lyons on Forbes. "This time, I figured I should at least give SCO the benefit of the doubt. I flew to Utah and interviewed their managers. I attended a SCO conference in Las Vegas and did more interviews. They told me all sorts of things, like they'd found a 'smoking gun' that proved IBM was guilty, and that they were preparing to sue big Hollywood companies that use Linux server farms to make movies. I reported what they said. Turns out I was getting played. They never produced a smoking gun. They never sued any Hollywood company."
SCO, Linux and Rob Enderle: A Conclusion (TG Daily)
For anybody who has wanted to see Rob Enderle explain himself with regard to SCO, TG Daily has that explanation at great length. "I thought I'd run into the cover up of the century. I was even told, as the senior research fellow, I was not allowed to talk about Linux anymore and I was lectured by the Head of Research on how I should have written the column who, upon actually reading it, agreed I had done everything he had just lectured me to do. He concluded that he must be thinking of another column I had written (this was my first column and there was no 'other' column). I saw this as a clear ethics problem and resigned the next day, focused like a laser on the Linux supporters I then viewed as criminals. And if they were criminals, than SCO must be the victim, right? Well, that was my thought back then."
Linux Adoption
Russian OS to be installed in every school (CNews)
Russia plans to install a Linux-derived "Russian OS" in every school in that country, as reported by CNews. Pilot programs are to start in three regions in 2008, with 2009 being targeted for a full rollout. "The main aim of the given work is to reduce dependence on foreign commercial software and provide education institutions with the possibility to choose whether to pay for commercial items or to use the software, provided by the government."
Legal
Microsoft's secretive standards orgs in Former Yugoslavia (LinuxWorld)
Ivan Jelic, a member of the Free Software Foundation Europe, looks at which European countries voted for the OpenXML format as a standard. "Romania and Bulgaria, members of European Union, together with Bosnia and Herzegovina, Croatia and Serbia, gave a green light for Microsoft's format, with comments from Bulgaria. In this story, we take a look at the decision processes and reactions in those countries."
Interviews
Want to meet four men who dared to fight MS -- and won? (Groklaw)
Groklaw features an interview with Georg Greve, Jeremy Allison, Volker Lendecke and Carlo Piana on the recent EU Commission's antitrust ruling against Microsoft. "Sean Daly: Now, tell me a little bit more about the "blue bubble" because I wasn't present at the hearings, but in the hallway, coming out of the hearings, I kept hearing about this blue bubble bursting. What's going on here? Georg Greve: Well, the blue bubble was a theory that Microsoft invented in order to justify that it had kept parts of the protocol secret. They said that there's a difference between the internal protocols and the external protocols, if you want to describe them like that. They said that certain protocols that are so secret that they are in this blue bubble, because they had visualized this with a blue bubble, that this could never be shared without actually sharing source code, without sharing how the program exactly works."
Resources
Building a community around your open source project (Red Hat Magazine)
Red Hat Magazine has some
nice ideas about building a community around an open source
project. "If you have an open source project, most likely you are a
designer/developer and not a marketer. Marketing is part of the job though
(sorry!), but it doesn't have to take a lot of effort. For starters, think
of the related mailing lists you are active on. If you aren't active on any
mailing lists, start! Open source lives through free exchange of email. If
you see a problem posted that might be solved by your software, it's
perfectly acceptable to mention your app. Other projects may exist as
alternatives to your own, and you want to respect them, as you want to also
respect other users on the lists. Help, but don't advertise.
"
Reviews
GNOME 2.20 arrives on Linux desktops (DesktopLinux)
DesktopLinux takes a look at GNOME 2.20, with screenshots. "The first major update of GNOME, version 2.20, has arrived almost two and a half years after GNOME 2.10, its last big step forward. GNOME 2.20 boasts not just improvements to the desktop itself, but multiple significant improvements to GNOME's applications as well."
MontaVista readies new Linux mobile phone OS (LinuxDevices)
LinuxDevices.com looks at MontaVista's Mobilinux 5.0, an upcoming distribution aimed at mobile phone use. "'Typical' phones based on Mobilinux 5.0 are said to be capable of booting in under five seconds, and placing calls within 10. Boot times are reduced through XIP (execute-in-place) technology that runs applications directly from flash, without first instantiating them in RAM. Application startup times are reduced by prelinking, including to glibc."
Miscellaneous
My Fabulous Geek Career (O'ReillyNet)
Carla Schroder, author of the Linux Cookbook pens this installment in the Women in Technology series. "[You] definitely need a thick skin in the FOSS world. It's a self-selected group, so it's chock-full of mavericks, the socially-inept, just plain trolls, and all manner of folks who don't understand the importance of courtesy and respect. But these are not representative of the excellent people who really do things. The best FOSS people are polite and pleasant. I do not believe that anyone is so invaluable and indispensable that they can be excused from common courtesy. The world itself is full of mean people, and there is no remedy other than learning how to deal with it. Girls are still often raised to be passive doormats, and they are not taught how to set and achieve goals, or that they are even worthy of going after what they really want. There are no shortcuts; all we can do is dig in, do our best, and not allow the naysayers to derail us."
Page editor: Forrest Cook
Announcements
Non-Commercial announcements
SFLC files first U.S. GPL violation lawsuit
The Software Freedom Law Center has filed a GPL violation lawsuit. "The Software Freedom Law Center (SFLC) today announced that it has filed the first ever U.S. copyright infringement lawsuit based on a violation of the GNU General Public License (GPL) on behalf of its clients, two principal developers of BusyBox, against Monsoon Multimedia, Inc. BusyBox is a lightweight set of standard Unix utilities commonly used in embedded systems and is open source software licensed under GPL version 2."
Monsoon Multimedia gives in on GPL
Monsoon Multimedia, which was just the subject of a GPL-violation complaint from the Busybox project, has announced its intent to comply with the requirements of the Busybox license. "Monsoon is in settlement negotiations with BusyBox to resolve the matter and intends to fully comply with all open-source software license requirements. Monsoon will make modified BusyBox source code publicly available on the company web-site at http://www.myhava.com in the coming weeks."
Commercial announcements
Autodesk releases coordinate system software
Autodesk, Inc. has announced plans to release some coordinate system and map projection technology under an open-source license. "The software, acquired from Mentor Software and its founder Norm Olsen, will help users to more easily support geographic coordinate conversions and allow accurate and precise geospatial analysis. The announcement was made today at the annual Free and Open Source Software for Geospatial (FOSS4G) conference in Victoria, British Columbia, Canada, where geospatial open source developers and users join to learn, present and network."
Holonyx launches reseller partner program for Linux support
Holonyx Inc. has announced its Partner Program to provide Linux support and open source software support to Value Added Resellers and System Integrators. This program will allow Holonyx Partners to expand the technology solutions they offer to their customers by implementing fully supported open source solutions in their customer accounts.OLPC starts "Give 1 Get 1" program
The One Laptop Per Child project is starting a new program for people interested in getting the XO laptop for their children. The Give 1 Get 1 promotion, starting November 12, allows people to buy an XO for someone they know while sending one to a student in a developing country, all for $399. "While children are by nature eager for knowledge, many countries have little resources to devote to education – sometimes less than $20 a year per child. Imagine the potential that could be unlocked by giving every child in the world the tools they need to learn, no matter who they are, no matter where they live, no matter how little they may have."
OpenLogic launches OpenLogic Exchange
OpenLogic, Inc. has announced the launch of the OpenLogic Exchange web site. "OpenLogic, Inc., a provider of enterprise open source software solutions encompassing hundreds of open source packages, today announced the launch of OpenLogic Exchange (OLEX) -- a free web site where companies can find, research, and download certified, enterprise-ready open source packages."
Purple Labs raises $14.5 million of venture capital
Purple Labs, a supplier of embedded Linux solutions for the wireless industry, has announced that it secured $14.5 Million in an initial round of venture capital funding.Qumranet de-cloaks
Qumranet, the company behind the KVM virtualization subsystem which quickly found its way into the mainline kernel last year, has finally unveiled its business plans. The press release is available in PDF format. "Solid ICE enables enterprises to host desktops in KVM virtual machines on servers in the corporate data center, and allows users to connect to them via a remote protocol called SPICE. The benefits for IT include centralized provisioning, management, policy enforcement and compliance for desktops. In addition, due to the KVM and SPICE combination, Solid ICE delivers a superior end-user experience, especially with respect to graphics and multimedia."
SiteScape unifies workspaces and workflow
SiteScape, Inc. has announced that its ICEcoreT Open Source project and ICEcoreT Enterprise collaboration software suite will be available starting October 20, 2007. ICEcore is a fully integrated Open Source collaboration suite, licensed under the OSI-certified Common Public Attribution License (CPAL).
New Books
The Essential Blender--New from No Starch Press
No Starch Press has published the book The Essential Blender by members of the Blender community.Fonts and Encodings--New from O'Reilly Media
O'Reilly has published the book Fonts & Encodings by Yannis Haralambous, translated by P. Scott Horne.
Education and Certification
LPI offers discounted exams at Ohio LinuxFest
The Linux Professional Institute will be offering discounted LPIC-1, LPIC-2 and Ubuntu Certified Professional exams at the Ohio LinuxFest 2007 in Columbus, Ohio on Sunday, September 30, 2007.
Calls for Presentations
FOSS.IN Call for Participation announced
FOSS.IN, the Free and Open Source software conference in India has put out their Call for Participation. This is the seventh FOSS.IN and will be held in Bangalore December 4-8, 2007. The conference starts with two "Project Days" dedicated to individual free software projects, followed by three days of the main conference. "The main objective of FOSS.IN is to promote involvement in FOSS projects, so presentations about actual contribution to FOSS projects would be of primary importance."
LCA 2008 Virtualisation Miniconf CFP
A call for presentations has gone out for the LCA 2008 Virtualisation Miniconf. The event takes place on January 28, 2008 in Melbourne, Australia, submissions are due by October 7.
Upcoming Events
Tim O'Reilly to Keynote Graphing Social Patterns
Tim O'Reilly will present a keynote at Graphing Social Patterns, the event will be held on October 7-9, 2007 in San Jose, California. "Chaired and produced by Dave McClure, Graphing Social Patterns is the premier conference covering Facebook business and technology issues. and related social networking platforms."
Events: October 4, 2007 to December 3, 2007
The following event listing is taken from the LWN.net Calendar.
| Date(s) | Event | Location |
|---|---|---|
| October 3 October 5 |
Apache Cocoon Get Together | Rome, Italy |
| October 6 October 7 |
Wineconf 2007 | Zurich, Switzerland |
| October 6 October 8 |
GNOME Boston Summit | Boston, MA, USA |
| October 7 October 9 |
Graphing Social Patterns | San Jose, CA, USA |
| October 8 October 10 |
VISION 2007 Embedded Linux Developer Conference | Santa Clara, USA |
| October 8 | Embedded Linux Bootcamp for Beginners | Santa Clara, CA, USA |
| October 9 October 10 |
Profoss | Brussels, Belgium |
| October 10 October 12 |
Plone Conference 2007 | Naples, Italy |
| October 12 | Legal Summit for Software Freedom | New York, NY, USA |
| October 13 October 14 |
T-DOSE 2007 (Technical Dutch Open Source Event) | Eindhoven, The Netherlands |
| October 13 | The Ontario Linux Fest Conference | Toronto, Canada |
| October 13 | Aka Linux Kernel Developer Conference | Beijing, China |
| October 16 | Databases and the Web | London, England |
| October 17 October 19 |
2007 WebGUI Users Conference | Madison, WI, USA |
| October 17 October 19 |
Web 2.0 Summit | San Francisco, CA, USA |
| October 18 October 20 |
HackLu 2007 | Kirchberg, Luxembourg |
| October 19 October 21 |
ToorCon 9 | San Diego, CA, USA |
| October 20 October 21 |
Ubucon.de | Krefeld (Köln), Germany |
| October 20 | PostgreSQL Conference Fall 2007 | Portland, OR, USA |
| October 20 | ./freedom & opensource day - PERU | Lima, PERU |
| October 21 October 25 |
OOPSLA 2007 | Montreal, Canada |
| October 21 October 26 |
Colorado Software Summit | Keystone, CO, USA |
| October 22 October 26 |
OpenGL Bootcamp with Rocco Bowling | Atlanta, GA, USA |
| October 22 October 23 |
She's Geeky - A Women's Tech (un)Conference | Mountain View, CA, USA |
| October 23 October 25 |
Open aLANtejo 07 - CNSL07 | Évora, Portugal |
| October 23 October 26 |
Black Hat Japan | Tokyo, Japan |
| October 25 October 26 |
FSOSS 2007 - Free Software and Open Source Symposium | Toronto, Canada |
| October 27 October 28 |
FOSSCamp 2007 | Cambridge, MA, USA |
| October 27 | Linux Day Italy | many cities around country, Italy |
| October 28 November 2 |
Ubuntu Developer Summit | Cambridge, Massachusetts, USA |
| October 29 | 3rd International Workshop on Storage Security and Survivability | Alexandria, VA, USA |
| October 29 November 1 |
Fall VON Conference and Expo | Boston, MA, USA |
| October 30 October 31 |
BCS'07 | Jakarta, Indonesia |
| October 31 November 1 |
LinuxWorld Conference & Expo | Utrecht, Netherlands |
| November 1 November 2 |
The Linux Foundation Japan Symposium | Tokyo, Japan |
| November 2 | 5th ACM Workshop on Recurring Malcode | Alexandria, VA, USA |
| November 2 November 3 |
Embedded Linux Conference, Europe | Linz, Austria |
| November 2 November 4 |
Real-Time Linux Workshop | Linz, Austria |
| November 3 | Linux-Info-Tag Dresden | Dresden, Germany |
| November 5 November 9 |
Python Bootcamp with Dave Beazley | Atlanta, USA |
| November 7 | NLUUG 25th anniversary conference | Beurs van Berlage, Amsterdam, The Netherlands |
| November 7 | Alfresco North American Community Conference 2007 | New York, NY, USA |
| November 8 November 9 |
Blog World Expo | Las Vegas, NV, USA |
| November 10 November 11 |
Linuxtage | Essen, NRW, Germany |
| November 11 November 17 |
Large Installation System Administration Conference | Dallas, TX, USA |
| November 12 November 16 |
Ruby on Rails Bootcamp with Charles B. Quinn | Atlanta, USA |
| November 12 November 15 |
OWASP & WASC AppSec 2007 Conference | San Jose, USA |
| November 12 November 16 |
ApacheCon US 2007 | Atlanta, GA, USA |
| November 13 November 14 |
IV Latin American Free Software Conference | Foz do Iguacu, Brazil |
| November 15 November 18 |
Piksel07 | Bergen, Norway |
| November 15 | Alfresco European Community Conference | Paris, France |
| November 16 November 18 |
aKademy-es 2007 | Zaragoza, Spain |
| November 20 November 23 |
DeepSec ISDC 2007 | Vienna, Austria |
| November 22 November 23 |
Conferencia Rails Hispana | Madrid, Spain |
| November 24 | LinuxDay in Vorarlberg (Deutschland, Schweiz, Liechtenstein und Österreich) | Dornbirn, Austria |
| November 26 November 29 |
Open Source Developers' Conference | Brisbane, Australia |
| November 28 November 30 |
Mono Summit 2007 | Madrid, Spain |
| November 29 November 30 |
PacSec 2007 | Tokyo, Japan |
| December 1 | Django Worldwide Sprint | Online, World |
| December 1 | London Perl Workshop 2007 | London, UK |
If your event does not appear here, please tell us about it.
Event Reports
RailsConf Europe gathers Rails enthusiasts
O'Reilly has sent out an event report for RailsConf Europe. "RailsConf Europe, which took place 17-19 September, was a global melting pot for Rails developers, industry luminaries, Ruby hackers, web-based entrepreneurs, and IT managers. The conference brought attendees from as far away as Peru, Iceland, and South Africa, giving further evidence that Ruby on Rails is truly a global movement. Held over three days at the Maritim Pro Arte Hotel in Berlin, the conference was co-presented by Ruby Central, Inc. and O'Reilly Media, Inc."
Web sites
LessWatts.org launches
Intel has launched LessWatts.org, a site dedicated to reducing power consumption by Linux systems. "LessWatts is about creating a community around saving power on Linux, bringing developers, users, and sysadmins together to share software, optimizations, and tips and tricks."
Page editor: Forrest Cook