
Kernel development
Brief items
Kernel release status
The current development kernel is 4.6-rc6, released on May 1. Linus said: "Things continue to be fairly calm, although I'm pretty sure I'll still do an rc7 in this series." As of this prepatch the code name has been changed to "Charred Weasel."
Stable updates: 4.5.3, 4.4.9, and 3.14.68 were released on May 4.
Quotes of the week
Instead, what I'm seeing now is a trend towards forcing existing filesystems to support the requirements and quirks of DAX and pmem, without any focus on pmem native solutions. i.e. I'm hearing "we need major surgery to existing filesystems and block devices to make DAX work" rather than "how do we make this efficient for a pmem native solution rather than being bound to block device semantics"?
Kernel development news
In pursuit of faster futexes
Futexes, the primitives provided by Linux for fast user-space mutex support, have been explored many times in these pages. They have gained various improvements over the years such as priority inheritance and robustness in the face of processes dying. But it appears that there is still at least one thing they lack: a recent patch set from Thomas Gleixner, along with a revised version, aims to correct the unfortunate fact that they just aren't fast enough.
The claim that futexes are fast (as advertised by the "f" in the name) is primarily based on their behavior when there is no contention on any specific futex. Claiming a futex that no other task holds, or releasing a futex that no other task wants, is extremely quick; the entire operation happens in user space with no involvement from the kernel. The claims that futexes are not fast enough, instead, focus on the contended case: waiting for a busy lock, or sending a wakeup while releasing a lock that others are waiting for. These operations must involve calls into the kernel as sleep/wakeup events and communication between different tasks are involved. It is expected that this case won't be as fast as the uncontended case, but hoped that it can be faster than it is, and particularly that the delays caused can be more predictable. The source of the delays has to do with shared state managed by the kernel.
Futex state: not everything is a file (descriptor)
Traditionally in Unix, most of the state owned by a process is represented by file descriptors, with memory mappings being the main exception. Uniformly using file descriptors provides a number of benefits: the kernel can find the state using a simple array lookup, the file descriptor limit stops processes from inappropriately overusing memory, state can easily be released with a simple close(), and everything can be cleaned up nicely when the process exits.
Futexes do not make use of file descriptors (for general state management) so none of these benefits apply. They use such a tiny amount of kernel space, and then only transiently, that it could be argued that the lack of file descriptors is not a problem. Or at least it could until the discussion around Gleixner's first patch set, where exactly this set of benefits was found to be wanting. While this first attempt has since been discarded in favor of a much simpler approach, exploring it further serves to highlight the key issues and shows what a complete solution might look like.
If we leave priority inheritance out of the picture for simplicity, there are two data structures that the kernel uses to support futexes. struct futex_q is used to represent a task that is waiting on a futex. There is at most one of these for each task and it is only needed while the task is waiting in the futex(FUTEX_WAIT) system call, so it is easily allocated on the stack. This piece of kernel state doesn't require any extra management.
The second data structure is a fixed sized hash table comprising an array of struct futex_hash_bucket; it looks something like this:
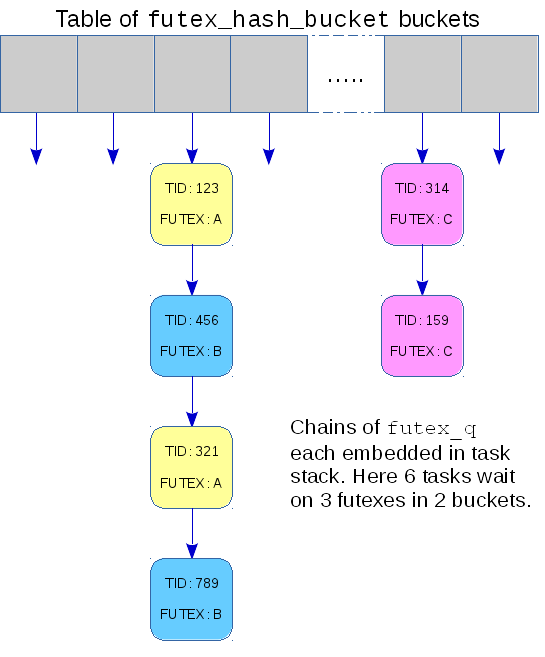
Each bucket has a linked list of futex_q structures representing waiting tasks together with a spinlock and some accounting to manage that list. When a FUTEX_WAIT or FUTEX_WAKE request is made, the address of the futex in question is hashed and the resulting number is used to choose a bucket in the hash table, either to attach the waiting task or to find tasks to wake up.
The performance issues arise when accessing this hash table, and they are issues that would not affect access in a file-descriptor model. First, the "address" of a futex can, in the general case, be either an offset in memory or an offset in a file and, to ensure that the correct calculation is made, the fairly busy mmap_sem semaphore must be claimed. A more significant motivation for the current patches is that a single bucket can be shared by multiple futexes. This makes the process of walking the linked list of futex_q structures to find tasks to wake up non-deterministic since the length could vary depending on the extent of sharing. For realtime workloads determinism is important; those loads would benefit from the hash buckets not being shared.
The single hash table causes a different sort of performance problem that affects NUMA machines. Due to their non-uniform memory architecture, some memory is much faster to access than other memory. Linux normally allocates memory resources needed by a task from the memory that is closest to the CPU that the task is running on, so as to make use of the faster access. Since the hash table is all at one location, the memory will probably be slow for most tasks.
Gleixner, the realtime tree maintainer, reported that these problems
can be measured and that in real world applications the hash
collisions "cause performance or determinism issues
".
This is not a particularly new observation: Darren Hart reported in
a summary of the state of futexes in 2009 that "the futex hash
table is shared across all processes and is protected by spinlocks
which can lead to real overhead, especially on large systems.
"
What does seem to be new is that Gleixner has a proposal to fix the
problems.
Buckets get allocated instead of shared
The core of Gleixner's initial proposal was to replace use of the global table of buckets, shared by all futexes, with dynamically allocated buckets — one for each futex. This was an opt-in change: a task needed to explicitly request an attached futex to get one that has its own private bucket in which waiting tasks are queued.
If we return to the file descriptor model mentioned earlier, kernel state is usually attached via some system call like open(), socket(), or pipe(). These calls create a data structure — a struct file — and return a file descriptor, private to the process, that can be used to access it. Often there will be a common namespace so that two processes can access the same thing: a shared inode might be found by name and referenced by two private files each accessed through file descriptors.
Each of these ideas are present in Gleixner's implementation, though with different names. In place of a file descriptor there is the task-local address of the futex that is purely a memory address, never a file offset. It is hashed for use as a key to a new per-task hash table — the futex_cache. In place of the struct file, the hash table has a futex_cache_slot that contains information about the futex. Unlike most hash tables in the kernel, this one doesn't allow chaining: if a potential collision is ever detected the size of the hash table is doubled.
In place of the shared inode, attached futexes have a shared futex_state structure that contains the global bucket for that futex. Finally, to serve as a namespace, the existing global hash table is used. Each futex_state contains a futex_q that can be linked into that table.
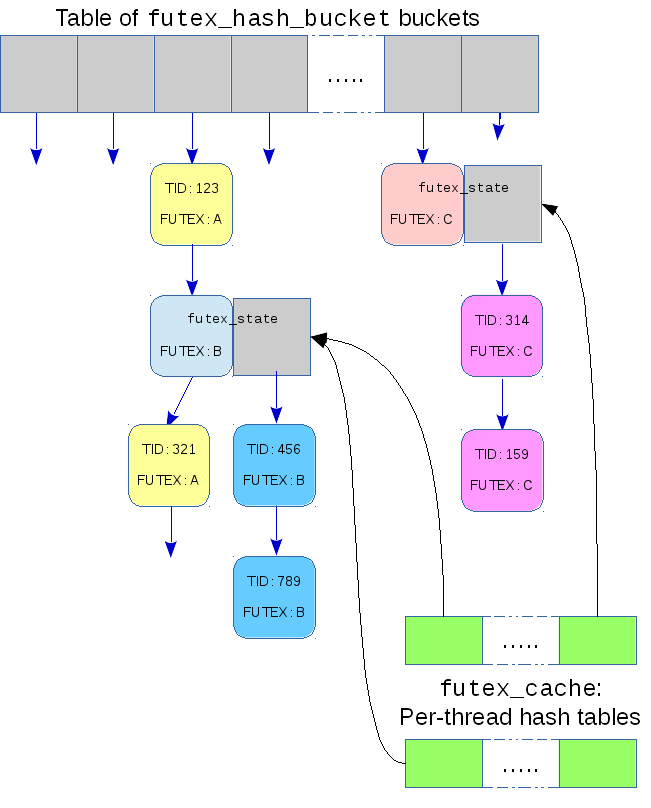
With this infrastructure in place, a task that wants to work with an attached futex must first attach it:
sys_futex(FUTEX_ATTACH | FUTEX_ATTACHED, uaddr, ....);
and can later detach it:
sys_futex(FUTEX_DETACH | FUTEX_ATTACHED, uaddr, ....);
All operations on the attached futex would include the FUTEX_ATTACHED flag to make it clear they expect an attached futex, rather than a normal on-demand futex.
The FUTEX_ATTACH behaves a little like open() and finds or creates a futex_state by performing a lookup in the global hash table, and then attaches it to the task-local futex_cache. All future accesses to that futex will find the futex_state with a lookup in the futex_cache which will be a constant-time lockless access to memory that is probably on the same NUMA node as the task. There is every reason to expect that this would be faster and Gleixner has some numbers to prove it, though he admitted they were a synthetic benchmark rather than a real-world load.
It's always about the interface
The main criticisms that Gleixner's approach received were not that he was re-inventing the file-descriptor model, but that he was changing the interface at all.
Having these faster futexes was not contentious. Requiring, or even allowing, the application programmer to choose between the old and the new behavior is where the problem lies. Linus Torvalds in particular didn't think that programmers would make the right choice, primarily because they wouldn't have the required perspective or the necessary information to make an informed choice. The tradeoffs are really at the system level rather than the application level: large memory systems, particularly NUMA systems, and those designed to support realtime loads would be expected to benefit. Smaller systems or those with no realtime demands are unlikely to notice and could suffer from the extra memory allocations. So while a system-wide configuration might be suitable, a per-futex configuration would not. This seems to mean that futexes would need to automatically attach without requiring an explicit request from the task.
Torvald Riegel supported this conclusion from the different
perspective provided by glibc. When using futexes to implement, for
example, C11 mutexes, "there's no good place to add the
attach/detach calls
" and no way to deduce whether it is worth
attaching at all.
It is worth noting that the new FUTEX_ATTACH interface makes the mistake of conflating two different elements of functionality. A task that issues this request is both asking for the faster implementation and agreeing to be involved in resource management, implicitly stating that it will call FUTEX_DETACH when the futex is no longer needed. Torvalds rejected the first of these as inappropriate and Riegel challenged the second as being hard to work with in practice. This effectively rang the death knell for explicit attachment.
Automatic attachment
Gleixner had already considered automatic attachment but had rejected it because of problems with, to use his list:
- Memory consumption
- Life time issues
- Performance issues due to the necessary allocations
Starting with the lifetime issues, it is fairly clear that the lifetime of the futex_state and futex_cache_slot structures would start when a thread needed to wake or wait on a futex. When the lifetime ends is the interesting question and, while it wasn't discussed, there seem to be two credible options. The easy option is for these structures to remain until the thread(s) using them exits, or at least until the memory containing the futex is unmapped. This could be long after the futex is no longer of interest, and so is wasteful.
The more conservative option would be to keep the structures on some sort of LRU (least-recently used) list and discard the state for old futexes when the total allocated seems too high. As this would introduce a new source of non-determinism in access speed, the approach is likely a non-starter, so wastefulness is the only option.
This brings us to memory consumption. Transitioning from the current implementation to attached futexes changes the kernel memory used per idle futex from zero to something non-zero. This may not be a small change. It is easy to imagine an application embedding a futex in every instance of some object that is allocated and de-allocated in large numbers. Every time such a futex suffers contention, an extra in-kernel data structure would be created. The number of such would probably not grow quickly, but it could just keep on growing. This would particularly put pressure on the futex_cache which could easily become too large to manage.
The performance issues due to extra allocations are not a problem with
explicit attachment for, as Gleixner later clarified:
"Attach/detach is not really critical.
" With implicit
attachment they would happen at first contention which would introduce
new non-determinism. A realtime task working with automatically
attached futexes would probably avoid this by issuing some no-op
operation on a futex just to trigger the attachment at a predictable
time.
All of these problems effectively rule out implicit attachment, meaning that, despite the fact that they remove nearly all the overhead for futex accesses, attached futexes really don't have a future.
Version two: no more attachment
Gleixner did indeed determine that attachment has no future and came up with an alternate scheme. The last time that futex performance was a problem, the response was to increase the size of the global hash table and enforce an alignment of buckets to cache lines to improve SMP behavior. Gleixner's latest patch set follows the same idea with a bit more sophistication. Rather than increase the single global hash table a "sharding" approach is taken, creating multiple distinct hash tables for multiple distinct sets of futexes.
Futexes can be declared as private, in which case they avoid the mmap_sem semaphore and can be only be used by threads in a single process. The set of private futexes for a given process form the basis for sharding and can, with the new patches, have exclusive access to a per-process hash table of futex buckets. All shared futexes still use the single global hash table. This approach addresses the NUMA issue by having the hash table on the same NUMA node as the process, and addresses the collision issue by dedicating more hash-table space per process. It only helps with private futexes, but these seem to be the style most likely to be used by applications needing predictable performance.
The choice of whether to allocate a per-process hash table is left as a system-wide configuration which is where the tradeoffs can best be assessed. The application is allowed a small role in the choice of when that table is allocated: a new futex command can request immediate allocation and suggest a preferred size. This avoids the non-determinism that would result from the default policy of allocation on first conflict.
It seems likely that this is the end of the story for now. There has been no distaste shown for the latest patch set and Gleixner is confident that it solves his particular problem. There would be no point aiming for a greater level of perfection until another demonstrated concrete need comes along.
Network filesystem topics
Steve French and Michael Adam led a session in the filesystem-only track at the 2016 Linux Storage, Filesystem, and Memory-Management Summit on network filesystems and some of the pain points for them on Linux. One of the main topics was case-insensitive file-name lookups.
French said that doing case-insensitive lookups was a "huge performance issue in Samba". The filesystem won't allow the creation of files with the wrong case, but files created outside of Samba can have mixed case or file names that collide in a case-insensitive comparison. That could lead to deleting the wrong file, for example.
![[Steve French]](https://static.lwn.net/images/2016/lsf-french-sm.jpg "Steve French")
Ric Wheeler suggested that what was really being sought is case-insensitive lookups but preserving the case on file creation. Ted Ts'o said that he has never been interested in handling case-insensitive lookups because Unicode changes the case-folding algorithm with some frequency, which would lead to having to update the kernel code to match that. Al Viro noted that preserving the case can lead to problems in the directory entry (dentry) cache; if both foo.h and FOO.H have been looked up, they will hash to different dentries.
Ts'o said that they would need to hash to the same dentry. Wheeler suggested that the dentry could always be lower case and that the file could have an extended attribute (xattr) that contains the real case-preserved name. That could be implemented by Samba, but there is a problem, as Ts'o pointed out: the Unix side wants to see the file names with the case preserved.
David Howells wondered if the case could simply be folded before the hash is calculated. But the knowledge of case and case insensitivity is not a part of the VFS, Viro said, and the hash is calculated by the filesystems themselves. Ts'o said that currently case insensitivity is not a first-class feature; it is instead just some hacks here and there. If case insensitivity is going to be added to filesystems like ext4, there are some hurdles to clear. For example, there are on-disk hashes in ext4 and he is concerned that changes to the case-folding rules could cause the hash to change, resulting in lost files.
Adam said that handling the case problem is interesting, but there are other problems for network filesystems. He noted that NFS is becoming more like Samba over time. That means that some of the problems that Samba is handling internally will be need to be solved for NFS, as well, though there will be subtle differences between them.
Both the "birth time" attribute for files and rich ACLs were mentioned as areas where
standard access mechanisms are needed, though there are plenty of others.
![[Michael Adam]](https://static.lwn.net/images/2016/lsf-adam-sm.jpg "Michael Adam") The problem is that filesystems provide different ways to get these pieces
of information, such as ioctl() commands or from xattrs. French
said there should be some kind of system call to hide those differences.
The problem is that filesystems provide different ways to get these pieces
of information, such as ioctl() commands or from xattrs. French
said there should be some kind of system call to hide those differences.
The perennially discussed xstat() system call was suggested as that interface, but discussions of xstat() always result in lots of bikeshedding about which attributes it should handle, Viro said. Ts'o said that "people try to do too much" with xstat(). In fact, there was a short session on xstat() later in the day that tried to reduce the scope of the system call with an eye toward getting something merged.
If there are twenty problems that can't be solved for network filesystems and five that can, even getting three of those solved would be a nice start, French said. There are issues for remote DMA (RDMA) and how to manage a direct copy from a device, for example. There are also device characteristics (e.g. whether it is an SSD) that applications want to know. Windows applications want to be able to determine attributes like alignment and seek penalty, but there is no consistent way to get that information. In addition, French said he doesn't want to have to decide whether a filesystem is integrity protected, but wants to query for it in some standard way.
Christoph Hellwig has been suggesting that filesystems move away from xattrs and to standardized filesystem ioctl() commands, French said. Ts'o said that the problem with xattrs is that they have become a kind of ASCII ioctl(); filesystems are parsing and creating xattrs that don't live on disk. At that point, the time for the session expired.
xstat()
The proposed xstat() system call, which is meant to extend the functionality of the stat() call to get additional file-status information, has been discussed quite a bit over the years, but has never been merged. The main impediment seems to be a lot of bikeshedding about how much information—and which specific pieces—will be returned. David Howells led a short filesystem-only discussion on xstat() at the 2016 Linux Storage, Filesystem, and Memory-Management Summit.
Howells presented a long list of possibilities that could be added to the structure for additional file status information to be returned by a call like xstat()—things like larger timestamps, the creation (or birth) time for a file, data version number (for some filesystems), inode generation number, and more. In general, there are more fields, with some that have grown larger, for xstat().
![[David Howells]](https://static.lwn.net/images/2016/lsf-howells-sm.jpg "David Howells")
There is also space at the end of the structure for growth. There are ways for callers to indicate what information they are interested in, as well as ways for the filesystem to indicate which pieces of valid information have been returned.
Howells noted that Dave Chinner wanted more I/O parameters (e.g. preferred read and write sizes, erase block size). There were five to seven different numbers that Chinner wanted, but those could always be added later, he said.
There are also some useful information flags that will be returned. Those will indicate if the file is a kernel file (e.g. in /proc or /sys), if it is compressed (and thus will result in extra latency when accessed), if it is encrypted, or if it is a sparse file. Windows has many of these indications.
But Ted Ts'o complained that there are two different definitions of a compressed file. It could mean that the file is not compressible, because it has already been done, or it could mean that the filesystem has done something clever and a read will return the real file contents. It is important to clearly define what the flag means. The FS_IOC_GETFLAGS ioctl() command did not do so, he said, so he wanted to ensure that the same mistake is not made with xstat().
There are other pieces of information that xstat() could return, Howells said. For example, whether accessing the file will cause an automount action or getting "foreign user ID" information for filesystems that don't have Unix-style UIDs or that have UIDs that do not map to the local system. There are also the Windows file attributes (archive, hidden, read-only, and system) that could be returned.
Ts'o suggested leaving out anything that did not have a clear definition of what it meant. That might help get xstat() merged. Others can be added later, he said.
Howells then described more of the functionality in his current version. There are three modes of operation. The standard mode would work the same way that stat() works today; it would force a sync of the file and retrieve an update from the server (if there is one). The second would be a "sync if we need to" mode; if only certain information that is stored locally is needed, it would simply be returned, but if the information requested required an update from the server (e.g. atime), that will be done. The third, "no sync" mode, means that only local values will be used; "it might be wrong, but it will be fast". For local filesystems, all three modes work the same way.
Jeff Layton asked: "How do we get it in without excessive bikeshedding?" He essentially answered his own question by suggesting that Howells start small and simply add "a few things that people really want". Joel Becker suggested that only parameters with "actual users in some upstream" be supported. That could help trim the list, he said.
Howells said that he asked for comments from various upstreams, but that only Samba had responded. Becker reiterated that whatever went in should be guided by actual users, since it takes work to support adding these bits of information. Howells agreed, noting that leaving extra space and having the masks and flags will leave room for expansion.
As it turns out, Howells posted a new patch set after LSFMM that reintroduces xstat() as the statx() system call.
Stream IDs and I/O hints
I/O hints are a way to try to give storage devices information that will allow them to make better decisions about how to store the data. One of the more recent hints is to have multiple "streams" of data that is associated in some way, which was mentioned in a storage standards update session the previous day. Changho Choi and Martin Petersen led a session at the 2016 Linux Storage, Filesystem, and Memory-Management Summit to flesh out more about streams, stream IDs, and I/O hints in general.
![[Changho Choi]](https://static.lwn.net/images/2016/lsf-choi-sm.jpg "Changho Choi")
Choi said that he is leading the multi-stream specification and software-development work at Samsung. There is no mechanism for storage devices to expose their internal organization to the host, which can lead to inefficient placement of data and inefficient background operations (e.g. garbage collection). Streams are an attempt to provide better collaboration between the host and the device. The host gives hints to the device, which will then place the data in the most efficient way. That leads to better endurance as well as improved and consistent performance and latency, he said.
A stream ID would be associated with operations for data that is expected to have the same lifetime. For example, temporary data, metadata, and user data could be separated into their own streams. The ID would be passed down to the device using the multi-stream interface and the device could put the data in the same erase blocks to avoid copying during garbage collection.
For efficiency, proper mapping of data to streams is essential, Choi said. Keith Packard noted that filesystems try to put writes in logical block address (LBA) order for rotating media and wondered if that was enough of a hint. Choi said that more information was needed. James Bottomley suggested that knowing the size and organization of erase blocks on the device could allow the kernel to lay out the data properly.
But there are already devices shipping with the multi-stream feature, from Samsung and others, Choi said. It is also part of the T10 (SCSI) standard and will be going into T13 (ATA) and NVM Express (NVMe) specifications.
![[Martin Petersen]](https://static.lwn.net/images/2016/lsf-petersen-sm.jpg "Martin Petersen")
Choi suggested exposing an interface for user space that would allow applications to set the stream IDs for writes. But Bottomley asked if there was really a need for a user-space interface. In the past, hints exposed to application developers went largely unused. It would be easier if the stream IDs were all handled by the kernel itself. He was also concerned that there would not be enough stream IDs available, so the kernel would end up using them all; none would be available to offer to user space.
Martin Petersen said that he was not against a user-space interface if one was needed, but suggested that it would be implemented with posix_fadvise() or something like that rather than directly exposing the IDs to user space. Choi thought that applications might have a better idea of the lifetime of their data than the kernel would, however.
At that point, Petersen took over to describe some research he had done on hints: how they are used and which are effective. There are several conduits for hints in the kernel, including posix_fadvise(), ioprio (available using ioprio_set()), the REQ_META flag for metadata, NFS v4.2, SCSI I/O advice hints, and so on. There are tons of different hints available; vendors implement different subsets of them.
So he wanted to try to figure out which hints actually make a difference. He asked internally (at Oracle) and externally about available hints, which resulted in a long list. From that, he pared the list back to hints that actually work. That resulted in half a dozen hints that characterize the data:
- Transaction - filesystem or database journals
- Metadata - filesystem metadata
- Paging - swap
- Realtime - audio/video streaming
- Data - normal application I/O
- Background - backup, data migration, RAID resync, scrubbing
The original streams proposal requires that the block layer request a stream ID from a device by opening a stream. Eventually those streams would need to be closed as well. For NVMe, streams are closely tied to the hardware write channels, which are a scarce resource. The explicit stream open/close is not popular and is difficult to do in some configurations (e.g. multipath).
So Petersen is proposing a combination of hints and streams. Device hints would be set based on knowledge the kernel has about the I/O. The I/O priority would be used to set the background I/O class hint (though it might move to a REQ_BG request flag), other request flags (REQ_META, REQ_JOURNAL, and REQ_SWAP) would set those hints, and posix_fadvise() flags would also set the appropriate hints.
Stream IDs would be based on files, which would allow sending the file to different devices and getting roughly the same behavior, he said. The proposal would remove the requirement to open and close streams and would provide a common model for all device types, so flash controllers, storage arrays, and shingled magnetic recording (SMR) devices could all make better decisions about data placement. This solution is being proposed to the standards groups as a way to resolve the problems with the existing hints and multi-stream specifications.
Background writeback
The problems with background writeback in Linux have been known for quite some time. Recently, there has been an effort to apply what was learned by network developers solving the bufferbloat problem to the block layer. Jens Axboe led a filesystem and storage track session at the 2016 Linux Storage, Filesystem, and Memory-Management Summit to discuss this work.
The basic problem is that flushing block data from memory to storage
(writeback) can flood the device queues to the point where any other reads and
![[Jens Axboe]](https://static.lwn.net/images/2016/lsf-axboe-sm.jpg "Jens Axboe") writes experience high latency. He has posted several versions of a patch
set to
address the problem and believes it is getting close to its final form.
There are fewer tunables and it all just basically works, he said.
writes experience high latency. He has posted several versions of a patch
set to
address the problem and believes it is getting close to its final form.
There are fewer tunables and it all just basically works, he said.
The queues are managed on the device side in ways that are "very loosely based on CoDel" from the networking code. The queues will be monitored and write requests will be throttled when the queues get too large. He thought about dropping writes instead (as CoDel does with network packets), but decided "people would be unhappy" with that approach.
The problem is largely solved at this point. Both read and write latencies are improved, but there is still some tweaking needed to make it work better. The algorithm is such that if the device is fast enough, it "just stays out of the way". It also narrows in on the right queue size quickly and if there are no reads contending for the queues, it "does nothing at all". He did note that he had not yet run the "crazy Chinner test case" again.
Ted Ts'o asked about the interaction with the I/O controller for control groups that is trying to do proportional I/O. Axboe said he was not particularly concerned about that. Controllers for each control group will need to be aware of each other, but it should all "probably be fine".
David Howells asked about writeback that is going to multiple devices. Axboe said that still needs work. Someone else asked about background reads, which Axboe said could be added. Nothing is inherently blocking that, but the work still needs to be done.
Multipage bio_vecs
In the block layer, larger I/O operations tend to be more efficient, but current kernels limit how large those operations can be. The bio_vec structure, which describes the buffer for an I/O operation, can only store a single page of tuples (of page, offset, and length) to describe the I/O buffer. There have been efforts over the years to allow multiple pages of array entries, so that even larger I/O operations can be held in a single bio_vec. Ming Lei led a session at the 2016 Linux Storage, Filesystem, and Memory-Management Summit to discuss patches to support bio_vec structures with multiple pages for the arrays.
Multipage bio_vec structures would consist of multiple, physically
contiguous
pages that could hold a larger array. It is the correct
thing to do, Lei said. It will save memory as there will be fewer
bio_vec structures needed and it will increase the transfer size
![[Ming Lei]](https://static.lwn.net/images/2016/lsf-lei-sm.jpg "Ming Lei") for each
struct bio (which contains a pointer to a bio_vec).
Currently, the single-page nature of a bio_vec means that only one
megabyte of I/O can be contained in a single bio_vec; adding
support for multiple pages will remove that limit.
for each
struct bio (which contains a pointer to a bio_vec).
Currently, the single-page nature of a bio_vec means that only one
megabyte of I/O can be contained in a single bio_vec; adding
support for multiple pages will remove that limit.
Jens Axboe agreed that there are benefits to larger bio_vec arrays, but was concerned about requesters getting physically contiguous pages. That would have to be done when the bio is created. Lei said that it is not hard to figure out how many pages will be needed before creating the bio, though.
All of the "magic" is in the bio_vec and bio iterators, one developer in the audience said. So there would be a need to introduce new helpers to iterate over the multipage bio_vec. The new name for the helper would require that all callers change, which would provide a good opportunity to review all of the users of the helpers, Christoph Hellwig said.
The patches also clean up direct access to some fields in bio structures: bi_vcnt, which tracks the number of entries in the bio_vec array, and the pointer to the bio_vec itself (bi_io_vec).
Axboe was concerned about handling all of the different special cases. There need to be "some real wins" in the patch set, since the memory savings are not all that huge. He is "not completely sold on why multipage is needed".
Hellwig agreed that the memory savings were not particularly significant, but that there is CPU time wasted in iterating over the segments. At various levels of the storage stack, the kernel has to iterate over the bio and bio_vec structures that make up I/O requests, so consolidating that information will save CPU time. There are also many needed cleanups in the patches, he said, so those should be picked up; "then, hopefully, we can get to the multipage bio_vecs".
Axboe said that the patches have been posted, but are not all destined for 4.7. He will queue up some of the preparatory patches, but the rest "need some time to digest".
Exposing extent information to user space
In a short, filesystem-only session at the 2016 Linux Storage, Filesystem, and Memory-Management Summit, Josef Bacik led a discussion on exposing information on extents, which are contiguous ranges of blocks allocated for a file (or files) by the filesystem, to user space. That could be done either by extending the FIEMAP ioctl() command or by coming up with a new interface. Bacik said that he was standing in for Mark Fasheh, who was unable to attend the session.
![[Josef Bacik]](https://static.lwn.net/images/2016/lsf-bacik-sm.jpg "Josef Bacik")
FIEMAP just reports whether an extent is shared or not, but there are some applications that want to know which inodes are sharing the extents. There are reserved 64-bit fields in struct fiemap_extent that could be used to report the inode numbers, Bacik said. He asked if that seemed like a reasonable approach.
Ric Wheeler wondered if there was really a need for applications to unwind all of this information. He asked: "Is there a backup application that will use this?" Jeff Mahoney responded that there is someone requesting the functionality.
Darrick Wong said that as part of his reverse mapping and reflink() work for XFS he has an interface that will allow applications to retrieve that kind of information. You can pass a range of physical block numbers to the reverse-map ioctl() and get back a list of objects (e.g. inodes) that think they own those blocks, he said.
Bacik said that sounded like the right interface: "Let's use that." Wong said that he would post some patches once he returned home from the summit.
DAX on BTT
In the final plenary session of the 2016 Linux Storage, Filesystem, and Memory-Management Summit, much of the team that works on the DAX direct-access mechanism led a discussion on how DAX should interact with the block translation table (BTT)—a mechanism aimed at making persistent memory have the atomic sector-write properties that users expect from block devices. Dan Williams took the role of ringleader, but Matthew Wilcox, Vishal Verma, and Ross Zwisler were also on-stage to participate.
Williams noted that Microsoft has adopted DAX for persistent memory and is even calling it DAX. Wilcox said that it was an indication that Microsoft is "listening to customers; they've changed".
![[Matthew Wilcox, Vishal Verma, Ross Zwisler, and Dan Williams]](https://static.lwn.net/images/2016/lsf-daxbtt-sm.jpg "Matthew Wilcox, Vishal Verma, Ross Zwisler, & Dan Williams")
BTT is a way to put block-layer-like semantics onto persistent memory, which handles writes at a cache-line granularity (i.e. 64 bytes), so that 512-byte (sector) writes are atomic. This eliminates the problem of "sector tearing", where a power or other failure causes a partial write to a sector resulting in a mixture of old and new data—a situation that applications (or filesystems) are probably not prepared to handle. Microsoft supports DAX on both BTT and non-BTT block devices, while Linux only supports it for non-BTT devices. Williams asked: "should we follow them [Microsoft] down that rabbit hole?"
The problem is that BTT is meant to fix a problem where persistent memory is treated like a block device, which is not what DAX is aimed at. Using BTT only for filesystem metadata might be one approach, Zwisler said. But Ric Wheeler noted that filesystems already put a lot of work into checksumming metadata, so using BTT for that would make things much slower for little or no gain.
Jeff Moyer pointed out that sector tearing can happen on block devices like SSDs, which is not what users expect. Joel Becker suggested that something like the SCSI atomic write command could be used by filesystems or applications that are concerned about torn sectors. That command guarantees that the sector is either written in full or not at all. There is no way to "magically save applications from torn sectors" unless they take some kind of precaution, he said.
There is a bit of a "hidden agenda" in supporting BTT, though, Williams said. Currently, the drivers are not aware of when DAX mappings are established and torn down, but that would change for BTT support. Wilcox said he has a patch series that addresses some parts of that by making the radix tree the source for that information.
task_diag and statx()
The interfaces supported by Linux to provide access to information about processes and files have literally been around for decades. One might think that, by this time, they would have reached a state of relative perfection. But things are not so perfect that developers are deterred from working on alternatives; the motivating factor in the two cases studied here is the same: reducing the cost of getting information out of the kernel while increasing the range of information that is available.
task_diag
There is no system call in Linux that provides information about running processes; instead, that information can be found in the /proc filesystem. Each process is represented by a directory under /proc; that directory contains a directory tree of its own with files providing information on just about every aspect of the process's existence. A quick look at the /proc hierarchy for a running bash instance reveals 279 files in 40 different directories. Whether one wants to know about control-group membership, resource usage, memory mappings, environment variables, open files, namespaces, out-of-memory-killer policies, or more, there is a file somewhere in that tree with the requisite information.
There are a lot of advantages to /proc, starting with the way it implements the classic Unix "everything is a file" approach. The information is readable as plain text, making it accessible from the command line or shell scripts. To a great extent, the interface is self-documenting, though some parts are more obvious than others. The contents of the stat file, for example, require an outside guide to be intelligible.
There are some downsides to this approach too, though. Accessing a file in /proc requires a minimum of three system calls — open(), read(), and close() — and that is after the file has been located in the directory hierarchy. Getting a range of information can require reading several files, with the system-call count multiplied accordingly. Some /proc files are expensive to read, and much of the resulting data may not be of interest to the reading process. There has been, to put it charitably, no unifying vision guiding the design of the /proc hierarchy, so each file there must be approached as a new parsing problem. It all adds up to a slow and cumbersome interface for applications that need significant amounts of information about multiple processes.
A possible solution comes in the form of the task_diag patch set from Andrey Vagin; it adds a binary interface allowing the extraction of lots of process information from the kernel using a single request. The starting point is a file called /proc/task-diag, which an interested process must open. That process then uses the netlink protocol to send a message describing the desired information, which can then be read back from the same file.
The request for information is contained within this structure:
struct task_diag_pid {
__u64 show_flags;
__u64 dump_strategy;
__u32 pid;
};
The dump_strategy field tells the kernel which processes are of interest. Its value can be one of TASK_DIAG_DUMP_ONE (information about the single process identified by pid), TASK_DIAG_DUMP_THREAD (get information about all threads of pid), TASK_DIAG_DUMP_CHILDREN (all children of pid), TASK_DIAG_DUMP_ALL (all processes in the system) or TASK_DIAG_DUMP_ALL_THREADS (all threads in the system).
The show_flags field, instead, describes which information is to be returned for each process. With TASK_DIAG_SHOW_BASE, the "base" information will be returned:
struct task_diag_base {
__u32 tgid;
__u32 pid;
__u32 ppid;
__u32 tpid;
__u32 sid;
__u32 pgid;
__u8 state;
char comm[TASK_DIAG_COMM_LEN];
};
Other possible flags include TASK_DIAG_SHOW_CREDS to get credential information, TASK_SHOW_VMA and TASK_SHOW_VMA_STAT for information on memory mappings, TASK_DIAG_SHOW_STAT for resource-usage statistics, and TASK_DIAG_SHOW_STATM for memory-usage statistics. If this interface is merged into the mainline, other options will surely follow.
The patches have been through a few rounds of review. Presumably something along these lines will eventually be merged, but it is not clear that the level of review required to safely add a new major kernel API has happened. There is also no man page for this feature yet. So it would not be surprising if a few more iterations were required before this one is declared to be ready.
statx()
Information about files in Linux, as with all Unix-like systems, comes via the stat() system call and its variants. Developers have chafed against its limitations for a long time. This system call, being enshrined in the POSIX standard, cannot be extended to return more information. It will likely return information that the calling process doesn't need — a wasted effort that can, for some information and filesystems, be expensive. And so on. For these reasons, an extended stat() system call has been a topic of discussion for many years.
Back in 2010, David Howells proposed a xstat() call that addressed a number of these problems, but that proposal got bogged down in discussion without being merged. Six years later, David is back with a new version of this patch. Time will tell if he is more successful this time around.
The new system call is now called statx(); the proposed interface is:
int statx(int dfd, const char *filename, unsigned atflag, unsigned mask, struct statx *buffer);
The file of interest is identified by filename; that file is expected to be found in or underneath the directory indicated by the file descriptor passed in dfd. If dfd is AT_FDCWD, the filename is interpreted relative to the current working directory. If filename is null, information about the file represented by dfd is returned instead.
The atflag parameter modifies how the information is collected. If it is AT_SYMLINK_NOFOLLOW and filename is a symbolic link, information is returned about the link itself. Other atflag values include AT_NO_AUTOMOUNT to prevent filesystems from being automatically mounted by the request, AT_FORCE_ATTR_SYNC to force a network filesystem to update attributes from the server before returning the information, and AT_NO_ATTR_SYNC to avoid updating from the server, even at the cost of returning approximate information. That last option can speed things up considerably when querying information about files on remote filesystems.
The mask parameter, instead, specifies which information the caller is looking for. The current patch set has fifteen options, varying from STATX_MODE (to get the permission bits) to STATX_GEN to get the current inode generation number (on filesystems that have such a concept). That mask appears again in the returned structure to indicate which fields are valid; that structure looks like:
struct statx {
__u32 st_mask; /* What results were written [uncond] */
__u32 st_information; /* Information about the file [uncond] */
__u32 st_blksize; /* Preferred general I/O size [uncond] */
__u32 st_nlink; /* Number of hard links */
__u32 st_gen; /* Inode generation number */
__u32 st_uid; /* User ID of owner */
__u32 st_gid; /* Group ID of owner */
__u16 st_mode; /* File mode */
__u16 __spare0[1];
__u64 st_ino; /* Inode number */
__u64 st_size; /* File size */
__u64 st_blocks; /* Number of 512-byte blocks allocated */
__u64 st_version; /* Data version number */
__s64 st_atime_s; /* Last access time */
__s64 st_btime_s; /* File creation time */
__s64 st_ctime_s; /* Last attribute change time */
__s64 st_mtime_s; /* Last data modification time */
__s32 st_atime_ns; /* Last access time (ns part) */
__s32 st_btime_ns; /* File creation time (ns part) */
__s32 st_ctime_ns; /* Last attribute change time (ns part) */
__s32 st_mtime_ns; /* Last data modification time (ns part) */
__u32 st_rdev_major; /* Device ID of special file */
__u32 st_rdev_minor;
__u32 st_dev_major; /* ID of device containing file [uncond] */
__u32 st_dev_minor;
__u64 __spare1[16]; /* Spare space for future expansion */
};
Many of those fields match those found in the classic struct stat
or are close to them. Times have been split into separate second and
nanosecond fields, enabling both high-precision timestamps and year-2038
compliance. The __spare1 array at the end is meant to
allow other types of data to be added in the future. Finally,
st_information gives general information about the file, including
whether it's encrypted, whether it's a kernel-generated file, or whether
it's stored on a remote server.
The only response to this patch set, as of this writing, came from Jeff Layton, who suggested "I
think we really ought to resist excessive bikeshedding this time
around
". If the other developers accept that advice, then it's
possible that an enhanced stat() interface might just get into the
kernel sometime this year. Nobody will be able to complain that this
particular change has been rushed.
Patches and updates
Kernel trees
Architecture-specific
Core kernel code
Device drivers
Device driver infrastructure
Networking
Security-related
Miscellaneous
Page editor: Jonathan Corbet
Next page:
Distributions>>