
LWN.net Weekly Edition for May 5, 2016
In search of a home for Thunderbird
After nearly a decade of trying, Mozilla is finally making the move of formally spinning off ownership of the Thunderbird email client to a third party. The identity of the new owner is still up for debate; Simon Phipps prepared a report [PDF] analyzing several possible options. But Mozilla does seem intent on divesting itself of the project for real this time. Whoever does take over Thunderbird development, though, will likely face a considerable technical challenge, since much of the application is built on frameworks and components that Mozilla will soon stop developing.
Bird versus fox
To say that Mozilla has had a difficult relationship with Thunderbird would be putting things mildly. The first release was in 2003, with version 1.0 following in late 2004. As soon as 2007, though, Mozilla's Mitchell Baker announced that Mozilla wished to rid itself of Thunderbird and find a new home for the project. Instead, Mozilla ended up separating Thunderbird off into a distinct unit (Mozilla Messaging) under the Mozilla Foundation umbrella. It then reabsorbed that unit in 2011, with Baker noting:
But, in July 2012, Mozilla began pulling paid developers from Thunderbird and left its development primarily in the hands of community volunteers, with a few Mozilla employees performing QA and build duties to support the Extended Support Release (ESR) program. At the time, Baker offered this justification:
By 2014, Mozilla had ramped down its involvement to the point where the Thunderbird team lacked any clear leadership, so the developer community voted to establish a Thunderbird Council made up of volunteers.
Most recently, Baker announced in December 2015 that Thunderbird would be formally separated from Mozilla. Phipps was engaged to research the options that he later published in the aforementioned report. In April 2016, Gervase Markham announced that the search for a new home for the project was underway, with Phipps's recommendations serving as a guide.
Lizard tech
For fans of Thunderbird, the repeated back-and-forth from Mozilla leadership can be a source of frustration on its own, but it probably does not help that Mozilla has started multiple other non-browser projects (such as ChatZilla, Raindrop, Grendel, and Firefox Hello) over the years while insisting that Thunderbird was a distraction from Firefox. Although it might seem like Mozilla management displays an inconsistent attitude toward messaging and other non-web application projects, each call for Mozilla to rid itself of Thunderbird has also highlighted the difficulty of maintaining Thunderbird and Firefox in the same engineering and release infrastructure.
In recent years, due in no small part to pressure coming from the rapid release schedule of Google's Chrome, the Firefox development process has shifted considerably. There are new stable releases made approximately every six weeks, and development builds are provided for the next two releases in separate release channels.
In addition, the Firefox codebase itself is changing. The XUL and XPCOM frameworks are on their way out, to be replaced with components and add-ons written in JavaScript. The Gecko rendering engine is also marked for replacement by Servo, and the entire Firefox architecture may be replaced with the multi-process Electrolysis model.
While these changes are exciting news for Firefox, none of them have made their way into Thunderbird. In April, Mozilla's Mark Surman highlighted the divergence issue in a blog post, noting:
Surman also pointed to a new job listing posted by Mozilla for a contractor who would oversee the transition. The posting describes two key responsibilities: to list all significant technical issues facing Thunderbird (including impact assessments) and to compile an outline of the options available to address those issues to move Thunderbird forward.
Former Mozilla developer Daniel Glazman responded to Surman's post on his own blog, with a more blunt assessment of the technical challenges facing Thunderbird developers. He pointed to the job posting's mention of XUL and XPCOM deprecation and said:
- rewrite the whole UI and the whole JS layer with it
- most probably rewrite the whole SMTP/MIME/POP/IMAP/LDAP/... layer
- most probably have a new Add-on layer or, far worse, no more Add-ons
Glazman concluded that it is too soon to select a new host for the Thunderbird project, given that a decision has yet to be made about how to rewrite the application. Furthermore, he pointed out, Mozilla has not yet begun the transition away from XUL and XPCOM in the Firefox codebase. Only when that process starts, he said, will it be possible to assess the complexity of such a move for Thunderbird.
As far as the build infrastructure goes, Markham sent a proposal to the Thunderbird Council in March suggesting a path forward for separating Thunderbird from the Firefox engineering infrastructure. It did not spawn much discussion, but there did not seem to be any objection either.
Out of the nest
For now, Mozilla seems set on finding a new fiscal and organizational sponsor for Thunderbird, with The Document Foundation and the Software Freedom Conservancy (both highlighted in Phipps's report) currently the leading candidates. But the discussion has only just begun on the technical aspects of maintaining and evolving Thunderbird as a standalone application.
Surman contended that the needs of Firefox and Thunderbird are simply too different today for them to be tied to the same codebase and release process. Essentially, the web changes rapidly, while email changes slowly. It is hard to argue with that assertion (setting aside discussions of how email should change), but Thunderbird fans might contend that Mozilla not contributing developer time to the Thunderbird codebase only exacerbates any inherent difference between the browser and email client.
Whether one thinks Mozilla has not adequately supported Thunderbird over the years or has done its level best, the Thunderbird and Firefox projects today are moving in different directions. Given their shared history, it may seem sad to watch them part ways, but perhaps the Thunderbird community can make the most of the opportunity and drive the application forward where Mozilla could (or would) not.
Caravel data visualization
One aspect of the heavily hyped Internet of Things (IoT) that can easily get overlooked is that each of the Things one hooks up to the Internet invariably spews out a near non-stop stream of data. While commercial IoT users—such as utility companies—generally have a well-established grasp of what data interests them and how to process it, the DIY crowd is better served by flexible tools that make exploring and transforming data easy. Airbnb maintains an open-source Python utility called Caravel that provides such tools. There are many alternatives, of course, but Caravel does a good job at ingesting data and smoothly molding it into nice-looking interactive graphs—with a few exceptions.
My own interest in data-visualization tools stems from IoT projects
(namely home-automation and automotive sensors), but Caravel itself is
in no way limited to such uses. Like most contemporary web-based
service providers, Airbnb
![[A Caravel dashboard]](https://static.lwn.net/images/2016/05-caravel-dashboard-sm.png "Caravel dashboard") collects a lot of data about its users and their transactions (in this
case, short-term
housing rentals, renters, and property owners). The company also prides itself on
having a slick-looking web interface, and Caravel reflects that: it
sports modern charts and graphs—no crusty old PNGs with jagged
lines generated by Graphviz here; everything is done in JavaScript.
collects a lot of data about its users and their transactions (in this
case, short-term
housing rentals, renters, and property owners). The company also prides itself on
having a slick-looking web interface, and Caravel reflects that: it
sports modern charts and graphs—no crusty old PNGs with jagged
lines generated by Graphviz here; everything is done in JavaScript.
In a nutshell, what Caravel provides is a connection layer supporting a variety of database types, the tools to configure the metrics of interest for any tables one wishes to explore, and an interactive utility for creating data visualizations. Several dozen visualization options are built in, and all of the charts the user creates can be saved and put into convenient "dashboards" for regular usage.
On top of all that, Caravel's interface is web-based and is almost entirely point-and-click. Perhaps the closest parallel would be to a tool like Orange, where the goal is to mask over the complexities of SQL and statistics. Caravel does not quite walk the user through adding new data sources or defining metrics, but it does take care of as many of the repetitive steps as it can.
For example, when you add a database table to your Caravel
![[Tables in Caravel]](https://static.lwn.net/images/2016/05-caravel-tables-sm.png "Tables in Caravel") work space, there are rows of checkboxes by every field. If you want
to track the minima, maxima, or sums for certain fields, you check
them at load time, and those metrics are automatically available on
the relevant pages of the application from then on. Similar
checkboxes are available for selecting which fields should be used as
categorical groups and which should be available for filtering the
data set.
work space, there are rows of checkboxes by every field. If you want
to track the minima, maxima, or sums for certain fields, you check
them at load time, and those metrics are automatically available on
the relevant pages of the application from then on. Similar
checkboxes are available for selecting which fields should be used as
categorical groups and which should be available for filtering the
data set.
The first public release of Caravel was in September 2015. The most recent is version 0.8.9, from April 2016. The code is hosted at GitHub and packages are also available on the Python Package Index (PyPI). For the moment, only 2.7 is supported. On Linux, installation also requires the development packages for libssl and libffi. When Caravel is installed, one only needs to initialize the database and create an administrator account to get started.
A Caravel instance is multi-user, and the system supports an array
of permissions and access controls. For testing, though, that is not
necessary. Out of the box, the system provides a local web UI and
comes pre-loaded with a demo data set. SQLite support is built in,
and any other database (local or remote) with SQLAlchemy support can be used
![[Databases in Caravel]](https://static.lwn.net/images/2016/05-caravel-db-sm.png "Databases in Caravel") as well. Druid database clusters are also supported, and users
can define a custom schema for any database that requires one. For
those working with large data sets, the good news is that Caravel also
supports a number of open-source caching layers, although none of them
are required. All of these configuration options are presented in the web UI's
"add a database" screen.
as well. Druid database clusters are also supported, and users
can define a custom schema for any database that requires one. For
those working with large data sets, the good news is that Caravel also
supports a number of open-source caching layers, although none of them
are required. All of these configuration options are presented in the web UI's
"add a database" screen.
The birds-eye view of Caravel usage is that the user adds a new database, then selects and adds each table of interest. From then on, working with Caravel is a matter of using the visualization builder to hone in on a chart or graph that presents some meaningful information. The visualizations include everything from line charts to bubble graphs, box plots to directed graphs, and heatmaps to Sankey diagrams. There are also less scientific options, such as word clouds.
A visualization can be saved as a
"slice," and any number of slices can be collected onto the same page
as a "dashboard." Dashboards are updated regularly as the database is
refreshed, so they can be deployed for internal or public
consumption. Finally, although dashboard graphics are interactive
JavaScript (with additional information shown where the mouse hovers),
![[Building visualizations in Caravel]](https://static.lwn.net/images/2016/05-caravel-visualization-sm.png "Building visualizations in Caravel") all charts and graphs can also be exported as image files.
all charts and graphs can also be exported as image files.
This set of features is fairly complete, but one might well ask whether the implementation is up to snuff. For the most part, the answer to that question is yes.
Adding new databases and choosing which tables to use borders on trivial, thanks to the well-optimized add-and-edit pages. There are a few caveats, such as the fact that the user cannot simply add all of the tables of interest from a database at once—each table requires a separate round trip through the "add a table" page. And when Caravel does not like something about a table, it is hard to debug.
For example, Caravel includes special treatment for time-series data; the user can mark any field in a table as being of the datetime type and it will be automatically plugged into various time-series charts in the visualization tool. But Caravel could not make sense out of the timestamps in one example data set I downloaded from datahub.io, and there is no easy way to inspect the data directly, nor does there seem to be any way in the UI to transform the timestamps into an acceptable datetime format. Nor even to see what Caravel thinks is wrong with them.
Clearly, this issue falls under a "you must know your data" warning, which is a fair expectation. But the error reporting that Caravel presents yanks the user right out of the UI, displaying a generic, low-level exception warning and a traceback from the Python interpreter.
And this sometimes happens through no fault of the user, like when
the user selects a new graph type from the drop-down menu in the
![[Exceptions in Caravel]](https://static.lwn.net/images/2016/05-caravel-exception-sm.png "Exceptions in Caravel") visualization builder and the
newly-selected graph takes a different number of parameters. By and
large, the visualization tool is quite handy—the point-and-click
settings and controls are not merely a coat of "UI paint" on the top;
they help the user play around with their data sets to find the
visualization settings that work best. Thus, it is more disappointing
when that friendly interactivity breaks down.
visualization builder and the
newly-selected graph takes a different number of parameters. By and
large, the visualization tool is quite handy—the point-and-click
settings and controls are not merely a coat of "UI paint" on the top;
they help the user play around with their data sets to find the
visualization settings that work best. Thus, it is more disappointing
when that friendly interactivity breaks down.
There are a couple of troubling technical limitations to mention. First, users must construct any new metrics of interest (other than sample counts, sums, and minima/maxima) by entering raw SQL expressions. Some additional statistical tools would be handy. Perhaps more fundamental is the fact that Caravel cannot join or query multiple tables; all of the visualizations are therefore limited to what information one can extract from a single table.
It might be interesting to pair Caravel with a tool like OpenRefine that specializes in data transformation, but I suspect that for a great many users, what Caravel can do already will serve them well. It handles the database connectivity in the background, putting the emphasis on exploring and manipulating visualizations. The visualizations and dashboards it provides are top-notch by modern standards, but the fact that they are easy for the user to create is Caravel's real advantage.
Security
Replacing /dev/urandom
The kernel's random-number generator (RNG) has seen a great deal of attention over the years; that is appropriate, given that its proper functioning is vital to the security of the system as a whole. During that time, it has acquitted itself well. That said, there are some concerns about the RNG going forward that have led to various patches aimed at improving both randomness and performance. Now there are two patch sets that significantly change the RNG's operation to consider.The first of these comes from Stephan Müller, who has two independent sets of concerns that he is trying to address:
- The randomness (entropy) in the RNG, in the end, comes from sources of
physical entropy in the outside world. In practice, that means the
timing of disk-drive operations, human-input events, and interrupts in
general. But the solid-state drives deployed in current systems are
far more predictable than rotating drives, many systems are deployed
in settings where there are no human-input events at all, and, in any
case, the entropy gained from those events duplicates the entropy from
interrupts in general. The end result, Stephan fears, is that the
current RNG is unable to pick up enough entropy to be truly random,
especially early in the bootstrap process.
- The RNG has shown some scalability problems on large NUMA systems, especially when faced with workloads that consume large amounts of random data from the kernel. There have been various attempts to improve RNG scalability over the last year, but none have been merged to this point.
Stephan tries to address both problems by throwing out much of the current RNG and replacing it with "a new approach"; see this page for a highly detailed explanation of the goals and implementation of this patch set. It starts by trying to increase the amount of useful entropy that can be obtained from the environment, and from interrupt timing in particular. The current RNG assumes that the timing of a specific interrupt carries little entropy — less than one bit. Stephan's patch, instead, accounts a full bit of entropy from each interrupt. Thus, in a sense, this is an accounting change: there is no more entropy flowing into the system than before, but it is being recognized at a higher rate, allowing early-boot users of random data to proceed.
Other sources of entropy are used as well when they are available; these include a hardware RNG attached to the system or built into the CPU itself (though little entropy is credited for the latter source). Earlier versions of the patch used the CPU jitter RNG (also implemented by Stephan) as another source of entropy, but that was removed at the request of RNG maintainer Ted Ts'o, who is not convinced that differences in execution time are a trustworthy source of entropy.
The hope is that interrupt timings, when added to whatever other sources of entropy are available, will be sufficient to quickly fill the entropy pool and allow the generation of truly random numbers. As with current systems, data read from /dev/random will remove entropy directly from that pool and will not complete until sufficient entropy accumulates there to satisfy the request. The actual random numbers are generated by running data from the entropy pool through the SP800-90A deterministic random bit generator (DRBG).
For /dev/urandom, another SP800-90A DRBG is fed from the primary DRBG described above and used to generate pseudo-random data. Every so often (ten minutes at the outset), this secondary generator is reseeded from the primary. On NUMA systems, there is one secondary generator for each node, keeping the random-data generation node-local and increasing scalability.
There has been a certain amount of discussion of Stephan's proposal, which is now in its third iteration, but Ted has said little beyond questioning the use of the CPU jitter technique. Or, at least, that was true until May 2, when he posted a new RNG of his own. Ted's work takes some clear inspiration from Stephan's patches (and from Andi Kleen's scalability work from last year) but it is, nonetheless, a different approach.
Ted's patch, too, gets rid of the separate entropy pool for /dev/urandom; this time, though, it is replaced by the ChaCha20 stream cipher seeded from the random pool. ChaCha20 is deemed to be secure and, it is thought, will perform better than SP800-9A. There is one ChaCha20 instance for each NUMA node, again, hopefully, helping to improve the scalability of the RNG (though Ted makes it clear that he sees this effort as being beyond the call of duty). There is no longer any attempt to track the amount of entropy stored in the (no-longer-existing) /dev/urandom pool, but each ChaCha20 instance is reseeded every five minutes.
When the system is booting, the new RNG will credit each interrupt's timing data with one bit of entropy, as does Stephan's RNG. Once the RNG is initialized with sufficient entropy, though, the RNG switches to the current system, which accounts far less entropy for each interrupt. This policy reflects Ted's unease with assuming that there is much entropy in interrupt timings; the timing of interrupts might be more predictable than one might think, especially on virtualized systems with no direct connection to real hardware.
Stephan's response to this posting has been
gracious: "In general, I have no concerns with this approach
either. And thank you that some of my concerns are addressed.
"
That, along with the fact that Ted is the ultimate decision-maker in this
case, suggests that his patch set is the one that is more likely to make it
into the mainline; it probably will not come down to flipping a coin. It
would be most surprising to see that merging happen for 4.7
— something as sensitive as the RNG needs some review and testing time —
but it could happen not too long thereafter.
Brief items
Security quotes of the week
Linux Kernel BPF JIT Spraying (grsecurity forums)
Over at the grsecurity forums, Brad Spengler writes about a recently released proof of concept attack on the kernel using JIT spraying. "What happened next was the hardening of the BPF interpreter in grsecurity to prevent such future abuse: the previously-abused arbitrary read/write from the interpreter was now restricted only to the interpreter buffer itself, and the previous warn on invalid BPF instructions was turned into a BUG() to terminate execution of the exploit. I also then developed GRKERNSEC_KSTACKOVERFLOW which killed off the stack overflow class of vulns on x64. A short time later, there was work being done upstream to extend the use of BPF in the kernel. This new version was called eBPF and it came with a vastly expanded JIT. I immediately saw problems with this new version and noticed that it would be much more difficult to protect -- verification was being done against a writable buffer and then translated into another writable buffer in the extended BPF language. This new language allowed not just arbitrary read and write, but arbitrary function calling." The protections in the grsecurity kernel will thus prevent this attack. In addition, the newly released RAP feature for grsecurity, which targets the elimination of return-oriented programming (ROP) vulnerabilities in the kernel, will also ensure that "
the fear of JIT spraying goes away completely", he said.
May Android security bulletin
The Android security bulletin for May is available. It lists 40 different CVE numbers addressed by the May over-the-air update; the bulk of those are at a severity level of "high" or above. "Partners were notified about the issues described in the bulletin on April 04, 2016 or earlier. Source code patches for these issues will be released to the Android Open Source Project (AOSP) repository over the next 48 hours. We will revise this bulletin with the AOSP links when they are available. The most severe of these issues is a Critical security vulnerability that could enable remote code execution on an affected device through multiple methods such as email, web browsing, and MMS when processing media files."
New vulnerabilities
botan: side channel attack
| Package(s): | botan1.10 | CVE #(s): | CVE-2015-7827 | ||||||||||||||||||||
| Created: | May 2, 2016 | Updated: | May 4, 2016 | ||||||||||||||||||||
| Description: | From the Debian advisory:
Use constant time PKCS #1 unpadding to avoid possible side channel attack against RSA decryption. | ||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||
botan: insufficient randomness
| Package(s): | botan1.10 | CVE #(s): | CVE-2014-9742 | ||||
| Created: | May 2, 2016 | Updated: | May 4, 2016 | ||||
| Description: | From the Debian LTS advisory:
A bug in Miller-Rabin primality testing was responsible for insufficient randomness. | ||||||
| Alerts: |
| ||||||
chromium-browser: multiple vulnerabilities
| Package(s): | chromium-browser | CVE #(s): | CVE-2016-1660 CVE-2016-1661 CVE-2016-1662 CVE-2016-1663 CVE-2016-1664 CVE-2016-1665 CVE-2016-1666 | ||||||||||||||||||||||||||||||||||||||||
| Created: | May 2, 2016 | Updated: | May 4, 2016 | ||||||||||||||||||||||||||||||||||||||||
| Description: | From the Red Hat advisory:
Multiple flaws were found in the processing of malformed web content. A web page containing malicious content could cause Chromium to crash, execute arbitrary code, or disclose sensitive information when visited by the victim. | ||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||
i7z: denial of service
| Package(s): | i7z | CVE #(s): | |||||
| Created: | April 29, 2016 | Updated: | May 4, 2016 | ||||
| Description: | From the Fedora advisory: i7z-gui: Print_Information_Processor(): i7z_GUI killed by SIGSEGV | ||||||
| Alerts: |
| ||||||
java: three vulnerabilities
| Package(s): | java-1.6.0-ibm | CVE #(s): | CVE-2016-0264 CVE-2016-0363 CVE-2016-0376 | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | May 2, 2016 | Updated: | May 4, 2016 | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | From the Red Hat advisory:
CVE-2016-0264 IBM JDK: buffer overflow vulnerability in the IBM JVM CVE-2016-0363 IBM JDK: insecure use of invoke method in CORBA component, incorrect CVE-2013-3009 fix CVE-2016-0376 IBM JDK: insecure deserialization in CORBA, incorrect CVE-2013-5456 fix | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||
jq: two vulnerabilities
| Package(s): | jq | CVE #(s): | CVE-2015-8863 CVE-2016-4074 | ||||||||||||||||||||||||||||
| Created: | May 4, 2016 | Updated: | December 8, 2016 | ||||||||||||||||||||||||||||
| Description: | From the openSUSE bug report:
CVE-2015-8863: heap buffer overflow in tokenadd() function http://seclists.org/oss-sec/2016/q2/134 CVE-2016-4074: stack exhaustion using jv_dump_term() function http://seclists.org/oss-sec/2016/q2/140 | ||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||
kernel: two vulnerabilities
| Package(s): | kernel | CVE #(s): | CVE-2016-3961 CVE-2016-3955 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | April 28, 2016 | Updated: | May 4, 2016 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | From the Xen advisory:
CVE-2016-3961: Huge (2Mb) pages are generally unavailable to PV guests. Since x86 Linux pvops-based kernels are generally multi purpose, they would normally be built with hugetlbfs support enabled. Use of that functionality by an application in a PV guest would cause an infinite page fault loop, and an OOPS to occur upon an attempt to terminate the hung application. Depending on the guest kernel configuration, the OOPS could result in a kernel crash (guest DoS). From the Red Hat bugzilla entry: CVE-2016-3955: Linux kernel built with the USB over IP(CONFIG_USBIP_*) support is vulnerable to a buffer overflow issue. It could occur while receiving USB/IP packets, when the size value in the packet is greater actual transfer buffer. A user/process could use this flaw to crash the remote host via kernel memory corruption or potentially execute arbitrary code. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
mercurial: code execution
| Package(s): | mercurial | CVE #(s): | CVE-2016-3105 | ||||||||||||||||||||||||||||
| Created: | May 3, 2016 | Updated: | May 18, 2016 | ||||||||||||||||||||||||||||
| Description: | From the Slackware advisory:
This update fixes possible arbitrary code execution when converting Git repos. Mercurial prior to 3.8 allowed arbitrary code execution when using the convert extension on Git repos with hostile names. This could affect automated code conversion services that allow arbitrary repository names. This is a further side-effect of Git CVE-2015-7545. Reported and fixed by Blake Burkhart. | ||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||
minissdpd: denial of service
| Package(s): | minissdpd | CVE #(s): | CVE-2016-3178 CVE-2016-3179 | ||||
| Created: | May 4, 2016 | Updated: | May 4, 2016 | ||||
| Description: | From the Debian LTS advisory:
The minissdpd daemon contains a improper validation of array index vulnerability (CWE-129) when processing requests sent to the Unix socket at /var/run/minissdpd.sock the Unix socket can be accessed by an unprivileged user to send invalid request causes an out-of-bounds memory access that crashes the minissdpd daemon. | ||||||
| Alerts: |
| ||||||
ntp: multiple vulnerabilities
| Package(s): | ntp | CVE #(s): | CVE-2015-8139 CVE-2015-8140 | ||||||||||||||||||||||||||||||||||||||||
| Created: | April 29, 2016 | Updated: | May 4, 2016 | ||||||||||||||||||||||||||||||||||||||||
| Description: | From the SUSE bug reports: CVE-2015-8139: To prevent off-path attackers from impersonating legitimate peers, clients require that the origin timestamp in a received response packet match the transmit timestamp from its last request to a given peer. Under assumption that only the recipient of the request packet will know the value of the transmit timestamp, this prevents an attacker from forging replies. CVE-2015-8140: The ntpq protocol is vulnerable to replay attacks. The sequence number being included under the signature fails to prevent replay attacks for two reasons. Commands that don't require authentication can be used to move the sequence number forward, and NTP doesn't actually care what sequence number is used so a packet can be replayed at any time. If, for example, an attacker can intercept authenticated reconfiguration commands that would. for example, tell ntpd to connect with a server that turns out to be malicious and a subsequent reconfiguration directive removed that malicious server, the attacker could replay the configuration command to re-establish an association to malicious server. | ||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||
ntp: multiple vulnerabilities
| Package(s): | ntp | CVE #(s): | CVE-2016-1551 CVE-2016-1549 CVE-2016-2516 CVE-2016-2517 CVE-2016-2518 CVE-2016-2519 CVE-2016-1547 CVE-2016-1548 CVE-2016-1550 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | May 2, 2016 | Updated: | May 16, 2016 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | From the Slackware advisory:
CVE-2016-1551: Refclock impersonation vulnerability, AKA: refclock-peering CVE-2016-1549: Sybil vulnerability: ephemeral association attack, AKA: ntp-sybil - MITIGATION ONLY CVE-2016-2516: Duplicate IPs on unconfig directives will cause an assertion botch CVE-2016-2517: Remote configuration trustedkey/requestkey values are not properly validated CVE-2016-2518: Crafted addpeer with hmode > 7 causes array wraparound with MATCH_ASSOC CVE-2016-2519: ctl_getitem() return value not always checked CVE-2016-1547: Validate crypto-NAKs, AKA: nak-dos CVE-2016-1548: Interleave-pivot - MITIGATION ONLY CVE-2016-1550: Improve NTP security against buffer comparison timing attacks, authdecrypt-timing, AKA: authdecrypt-timing | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
openssl: multiple vulnerabilities
| Package(s): | openssl | CVE #(s): | CVE-2016-2108 CVE-2016-2107 CVE-2016-2105 CVE-2016-2106 CVE-2016-2109 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | May 3, 2016 | Updated: | June 1, 2016 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | From the Ubuntu advisory:
Huzaifa Sidhpurwala, Hanno Böck, and David Benjamin discovered that OpenSSL incorrectly handled memory when decoding ASN.1 structures. A remote attacker could use this issue to cause OpenSSL to crash, resulting in a denial of service, or possibly execute arbitrary code. (CVE-2016-2108) Juraj Somorovsky discovered that OpenSSL incorrectly performed padding when the connection uses the AES CBC cipher and the server supports AES-NI. A remote attacker could possibly use this issue to perform a padding oracle attack and decrypt traffic. (CVE-2016-2107) Guido Vranken discovered that OpenSSL incorrectly handled large amounts of input data to the EVP_EncodeUpdate() function. A remote attacker could use this issue to cause OpenSSL to crash, resulting in a denial of service, or possibly execute arbitrary code. (CVE-2016-2105) Guido Vranken discovered that OpenSSL incorrectly handled large amounts of input data to the EVP_EncryptUpdate() function. A remote attacker could use this issue to cause OpenSSL to crash, resulting in a denial of service, or possibly execute arbitrary code. (CVE-2016-2106) Brian Carpenter discovered that OpenSSL incorrectly handled memory when ASN.1 data is read from a BIO. A remote attacker could possibly use this issue to cause memory consumption, resulting in a denial of service. (CVE-2016-2109) As a security improvement, this update also modifies OpenSSL behaviour to reject DH key sizes below 1024 bits, preventing a possible downgrade attack. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
openssl: information leak
| Package(s): | lib32-openssl openssl | CVE #(s): | CVE-2016-2176 | ||||||||||||||||||||||||
| Created: | May 4, 2016 | Updated: | May 12, 2016 | ||||||||||||||||||||||||
| Description: | From the Arch Linux advisory:
ASN1 Strings that are over 1024 bytes can cause an overread in applications using the X509_NAME_oneline() function on EBCDIC systems. This could result in arbitrary stack data being returned in the buffer. | ||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||
openvas: cross-site scripting
| Package(s): | openvas | CVE #(s): | CVE-2016-1926 | ||||||||||||||||||||||||||||||||||||||||
| Created: | May 2, 2016 | Updated: | May 9, 2016 | ||||||||||||||||||||||||||||||||||||||||
| Description: | From the Red Hat bugzilla:
It was reported that openvas-gsa is vulnerable to cross-site scripting due to improper handling of parameters of get_aggregate command. If the attacker has access to a session token of the browser session, the cross site scripting can be executed. Affects versions >= 6.0.0 and < 6.0.8. | ||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||
oxide-qt: code execution
| Package(s): | oxide-qt | CVE #(s): | CVE-2016-1578 | ||||
| Created: | April 28, 2016 | Updated: | May 4, 2016 | ||||
| Description: | From the Ubuntu advisory:
A use-after-free was discovered when responding synchronously to permission requests. An attacker could potentially exploit this to cause a denial of service via application crash, or execute arbitrary code with the privileges of the user invoking the program. (CVE-2016-1578) | ||||||
| Alerts: |
| ||||||
php: multiple vulnerabilities
| Package(s): | php | CVE #(s): | CVE-2016-4537 CVE-2016-4538 CVE-2016-4539 CVE-2016-4540 CVE-2016-4541 CVE-2016-4542 CVE-2016-4543 CVE-2016-4544 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | May 2, 2016 | Updated: | May 19, 2016 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | The php package has been updated to version 5.6.21, which fixes several security issues and other bugs. See the upstream ChangeLog for more details. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
php-ZendFramework: multiple vulnerabilities
| Package(s): | php-ZendFramework | CVE #(s): | |||||
| Created: | May 2, 2016 | Updated: | May 4, 2016 | ||||
| Description: | From the Mageia advisory:
The php-ZendFramework package has been updated to version 1.12.18 to fix a potential information disclosure and insufficient entropy vulnerability in the word CAPTCHA (ZF2015-09) and several other functions (ZF2016-01). | ||||||
| Alerts: |
| ||||||
roundcubemail: three vulnerabilities
| Package(s): | roundcubemail | CVE #(s): | CVE-2015-8864 CVE-2016-4068 CVE-2016-4069 | ||||||||||||||||||||||||||||||||
| Created: | May 2, 2016 | Updated: | May 4, 2016 | ||||||||||||||||||||||||||||||||
| Description: | From the Red Hat bugzilla:
(CVE-2015-8864, CVE-2016-4068) Fix XSS issue in SVG images handling (CVE-2016-4069) Protect download urls against CSRF using unique request tokens | ||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||
subversion: multiple vulnerabilities
| Package(s): | subversion | CVE #(s): | CVE-2016-2167 CVE-2016-2168 | ||||||||||||||||||||||||||||||||||||
| Created: | April 29, 2016 | Updated: | June 8, 2016 | ||||||||||||||||||||||||||||||||||||
| Description: | From the Debian advisory:
CVE-2016-2167 - Daniel Shahaf and James McCoy discovered that an implementation error in the authentication against the Cyrus SASL library would permit a remote user to specify a realm string which is a prefix of the expected realm string and potentially allowing a user to authenticate using the wrong realm. CVE-2016-2168 - Ivan Zhakov of VisualSVN discovered a remotely triggerable denial of service vulnerability in the mod_authz_svn module during COPY or MOVE authorization check. An authenticated remote attacker could take advantage of this flaw to cause a denial of service (Subversion server crash) via COPY or MOVE requests with specially crafted header. | ||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||
tardiff: two vulnerabilities
| Package(s): | tardiff | CVE #(s): | CVE-2015-0857 CVE-2015-0858 | ||||||||
| Created: | May 2, 2016 | Updated: | July 28, 2016 | ||||||||
| Description: | From the Debian advisory:
CVE-2015-0857: Rainer Mueller and Florian Weimer discovered that tardiff is prone to shell command injections via shell meta-characters in filenames in tar files or via shell meta-characters in the tar filename itself. CVE-2015-0858: Florian Weimer discovered that tardiff uses predictable temporary directories for unpacking tarballs. A malicious user can use this flaw to overwrite files with permissions of the user running the tardiff command line tool. | ||||||||||
| Alerts: |
| ||||||||||
ubuntu-core-launcher: code execution
| Package(s): | ubuntu-core-launcher | CVE #(s): | CVE-2016-1580 | ||||
| Created: | May 2, 2016 | Updated: | May 4, 2016 | ||||
| Description: | From the Ubuntu advisory:
Zygmunt Krynicki discovered that ubuntu-core-launcher did not properly sanitize its input and contained a logic error when determining the mountpoint of bind mounts when using snaps on Ubuntu classic systems (eg, traditional desktop and server). If a user were tricked into installing a malicious snap with a crafted snap name, an attacker could perform a delayed attack to steal data or execute code within the security context of another snap. This issue did not affect Ubuntu Core systems. | ||||||
| Alerts: |
| ||||||
xen: three vulnerabilities
| Package(s): | xen | CVE #(s): | CVE-2016-4001 CVE-2016-4002 CVE-2016-4037 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | May 2, 2016 | Updated: | May 4, 2016 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | From the Red Hat bugzilla:
CVE-2016-4001: Qemu emulator built with the Luminary Micro Stellaris Ethernet Controller is vulnerable to a buffer overflow issue. It could occur while receiving network packets in stellaris_enet_receive(), if the guest NIC is configured to accept large(MTU) packets. A remote user/process could use this flaw to crash the Qemu process on a host, resulting in DoS. CVE-2016-4002: Qemu emulator built with the MIPSnet controller emulator is vulnerable to a buffer overflow issue. It could occur while receiving network packets in mipsnet_receive(), if the guest NIC is configured to accept large(MTU) packets. A remote user/process could use this flaw to crash Qemu resulting in DoS; OR potentially execute arbitrary code with privileges of the Qemu process on a host. CVE-2016-4037: Qemu emulator built with the USB EHCI emulation support is vulnerable to an infinite loop issue. It occurs during communication between host controller interface(EHCI) and a respective device driver. These two communicate via a split isochronous transfer descriptor list(siTD) and an infinite loop unfolds if there is a closed loop in this list. A privileges used inside guest could use this flaw to consume excessive CPU cycles & resources on the host. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
xerces-j2: denial of service
| Package(s): | xerces-j2 | CVE #(s): | |||||||||
| Created: | May 4, 2016 | Updated: | May 24, 2016 | ||||||||
| Description: | From the openSUSE advisory:
bsc#814241: Fixed possible DoS through very long attribute names | ||||||||||
| Alerts: |
| ||||||||||
Page editor: Jake Edge
Kernel development
Brief items
Kernel release status
The current development kernel is 4.6-rc6, released on May 1. Linus said: "Things continue to be fairly calm, although I'm pretty sure I'll still do an rc7 in this series." As of this prepatch the code name has been changed to "Charred Weasel."
Stable updates: 4.5.3, 4.4.9, and 3.14.68 were released on May 4.
Quotes of the week
Instead, what I'm seeing now is a trend towards forcing existing filesystems to support the requirements and quirks of DAX and pmem, without any focus on pmem native solutions. i.e. I'm hearing "we need major surgery to existing filesystems and block devices to make DAX work" rather than "how do we make this efficient for a pmem native solution rather than being bound to block device semantics"?
Kernel development news
In pursuit of faster futexes
Futexes, the primitives provided by Linux for fast user-space mutex support, have been explored many times in these pages. They have gained various improvements over the years such as priority inheritance and robustness in the face of processes dying. But it appears that there is still at least one thing they lack: a recent patch set from Thomas Gleixner, along with a revised version, aims to correct the unfortunate fact that they just aren't fast enough.
The claim that futexes are fast (as advertised by the "f" in the name) is primarily based on their behavior when there is no contention on any specific futex. Claiming a futex that no other task holds, or releasing a futex that no other task wants, is extremely quick; the entire operation happens in user space with no involvement from the kernel. The claims that futexes are not fast enough, instead, focus on the contended case: waiting for a busy lock, or sending a wakeup while releasing a lock that others are waiting for. These operations must involve calls into the kernel as sleep/wakeup events and communication between different tasks are involved. It is expected that this case won't be as fast as the uncontended case, but hoped that it can be faster than it is, and particularly that the delays caused can be more predictable. The source of the delays has to do with shared state managed by the kernel.
Futex state: not everything is a file (descriptor)
Traditionally in Unix, most of the state owned by a process is represented by file descriptors, with memory mappings being the main exception. Uniformly using file descriptors provides a number of benefits: the kernel can find the state using a simple array lookup, the file descriptor limit stops processes from inappropriately overusing memory, state can easily be released with a simple close(), and everything can be cleaned up nicely when the process exits.
Futexes do not make use of file descriptors (for general state management) so none of these benefits apply. They use such a tiny amount of kernel space, and then only transiently, that it could be argued that the lack of file descriptors is not a problem. Or at least it could until the discussion around Gleixner's first patch set, where exactly this set of benefits was found to be wanting. While this first attempt has since been discarded in favor of a much simpler approach, exploring it further serves to highlight the key issues and shows what a complete solution might look like.
If we leave priority inheritance out of the picture for simplicity, there are two data structures that the kernel uses to support futexes. struct futex_q is used to represent a task that is waiting on a futex. There is at most one of these for each task and it is only needed while the task is waiting in the futex(FUTEX_WAIT) system call, so it is easily allocated on the stack. This piece of kernel state doesn't require any extra management.
The second data structure is a fixed sized hash table comprising an array of struct futex_hash_bucket; it looks something like this:
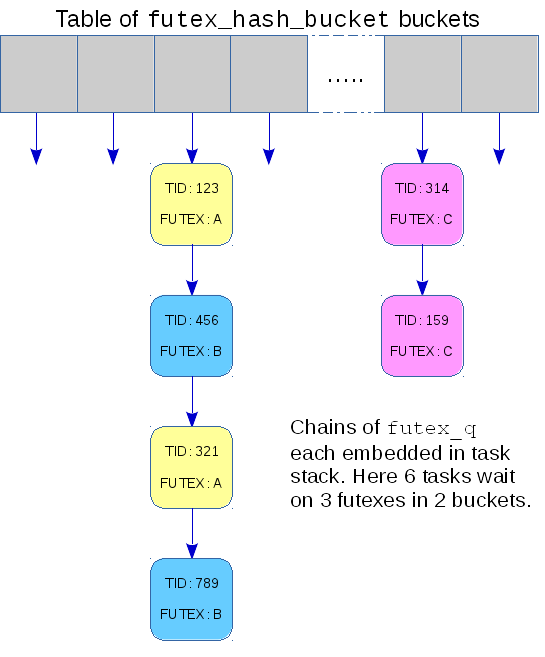
Each bucket has a linked list of futex_q structures representing waiting tasks together with a spinlock and some accounting to manage that list. When a FUTEX_WAIT or FUTEX_WAKE request is made, the address of the futex in question is hashed and the resulting number is used to choose a bucket in the hash table, either to attach the waiting task or to find tasks to wake up.
The performance issues arise when accessing this hash table, and they are issues that would not affect access in a file-descriptor model. First, the "address" of a futex can, in the general case, be either an offset in memory or an offset in a file and, to ensure that the correct calculation is made, the fairly busy mmap_sem semaphore must be claimed. A more significant motivation for the current patches is that a single bucket can be shared by multiple futexes. This makes the process of walking the linked list of futex_q structures to find tasks to wake up non-deterministic since the length could vary depending on the extent of sharing. For realtime workloads determinism is important; those loads would benefit from the hash buckets not being shared.
The single hash table causes a different sort of performance problem that affects NUMA machines. Due to their non-uniform memory architecture, some memory is much faster to access than other memory. Linux normally allocates memory resources needed by a task from the memory that is closest to the CPU that the task is running on, so as to make use of the faster access. Since the hash table is all at one location, the memory will probably be slow for most tasks.
Gleixner, the realtime tree maintainer, reported that these problems
can be measured and that in real world applications the hash
collisions "cause performance or determinism issues
".
This is not a particularly new observation: Darren Hart reported in
a summary of the state of futexes in 2009 that "the futex hash
table is shared across all processes and is protected by spinlocks
which can lead to real overhead, especially on large systems.
"
What does seem to be new is that Gleixner has a proposal to fix the
problems.
Buckets get allocated instead of shared
The core of Gleixner's initial proposal was to replace use of the global table of buckets, shared by all futexes, with dynamically allocated buckets — one for each futex. This was an opt-in change: a task needed to explicitly request an attached futex to get one that has its own private bucket in which waiting tasks are queued.
If we return to the file descriptor model mentioned earlier, kernel state is usually attached via some system call like open(), socket(), or pipe(). These calls create a data structure — a struct file — and return a file descriptor, private to the process, that can be used to access it. Often there will be a common namespace so that two processes can access the same thing: a shared inode might be found by name and referenced by two private files each accessed through file descriptors.
Each of these ideas are present in Gleixner's implementation, though with different names. In place of a file descriptor there is the task-local address of the futex that is purely a memory address, never a file offset. It is hashed for use as a key to a new per-task hash table — the futex_cache. In place of the struct file, the hash table has a futex_cache_slot that contains information about the futex. Unlike most hash tables in the kernel, this one doesn't allow chaining: if a potential collision is ever detected the size of the hash table is doubled.
In place of the shared inode, attached futexes have a shared futex_state structure that contains the global bucket for that futex. Finally, to serve as a namespace, the existing global hash table is used. Each futex_state contains a futex_q that can be linked into that table.
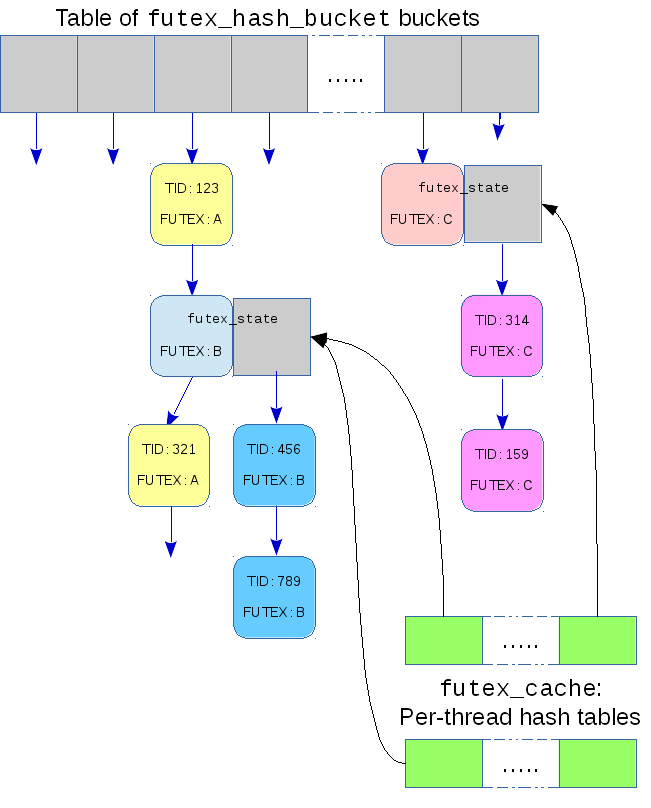
With this infrastructure in place, a task that wants to work with an attached futex must first attach it:
sys_futex(FUTEX_ATTACH | FUTEX_ATTACHED, uaddr, ....);
and can later detach it:
sys_futex(FUTEX_DETACH | FUTEX_ATTACHED, uaddr, ....);
All operations on the attached futex would include the FUTEX_ATTACHED flag to make it clear they expect an attached futex, rather than a normal on-demand futex.
The FUTEX_ATTACH behaves a little like open() and finds or creates a futex_state by performing a lookup in the global hash table, and then attaches it to the task-local futex_cache. All future accesses to that futex will find the futex_state with a lookup in the futex_cache which will be a constant-time lockless access to memory that is probably on the same NUMA node as the task. There is every reason to expect that this would be faster and Gleixner has some numbers to prove it, though he admitted they were a synthetic benchmark rather than a real-world load.
It's always about the interface
The main criticisms that Gleixner's approach received were not that he was re-inventing the file-descriptor model, but that he was changing the interface at all.
Having these faster futexes was not contentious. Requiring, or even allowing, the application programmer to choose between the old and the new behavior is where the problem lies. Linus Torvalds in particular didn't think that programmers would make the right choice, primarily because they wouldn't have the required perspective or the necessary information to make an informed choice. The tradeoffs are really at the system level rather than the application level: large memory systems, particularly NUMA systems, and those designed to support realtime loads would be expected to benefit. Smaller systems or those with no realtime demands are unlikely to notice and could suffer from the extra memory allocations. So while a system-wide configuration might be suitable, a per-futex configuration would not. This seems to mean that futexes would need to automatically attach without requiring an explicit request from the task.
Torvald Riegel supported this conclusion from the different
perspective provided by glibc. When using futexes to implement, for
example, C11 mutexes, "there's no good place to add the
attach/detach calls
" and no way to deduce whether it is worth
attaching at all.
It is worth noting that the new FUTEX_ATTACH interface makes the mistake of conflating two different elements of functionality. A task that issues this request is both asking for the faster implementation and agreeing to be involved in resource management, implicitly stating that it will call FUTEX_DETACH when the futex is no longer needed. Torvalds rejected the first of these as inappropriate and Riegel challenged the second as being hard to work with in practice. This effectively rang the death knell for explicit attachment.
Automatic attachment
Gleixner had already considered automatic attachment but had rejected it because of problems with, to use his list:
- Memory consumption
- Life time issues
- Performance issues due to the necessary allocations
Starting with the lifetime issues, it is fairly clear that the lifetime of the futex_state and futex_cache_slot structures would start when a thread needed to wake or wait on a futex. When the lifetime ends is the interesting question and, while it wasn't discussed, there seem to be two credible options. The easy option is for these structures to remain until the thread(s) using them exits, or at least until the memory containing the futex is unmapped. This could be long after the futex is no longer of interest, and so is wasteful.
The more conservative option would be to keep the structures on some sort of LRU (least-recently used) list and discard the state for old futexes when the total allocated seems too high. As this would introduce a new source of non-determinism in access speed, the approach is likely a non-starter, so wastefulness is the only option.
This brings us to memory consumption. Transitioning from the current implementation to attached futexes changes the kernel memory used per idle futex from zero to something non-zero. This may not be a small change. It is easy to imagine an application embedding a futex in every instance of some object that is allocated and de-allocated in large numbers. Every time such a futex suffers contention, an extra in-kernel data structure would be created. The number of such would probably not grow quickly, but it could just keep on growing. This would particularly put pressure on the futex_cache which could easily become too large to manage.
The performance issues due to extra allocations are not a problem with
explicit attachment for, as Gleixner later clarified:
"Attach/detach is not really critical.
" With implicit
attachment they would happen at first contention which would introduce
new non-determinism. A realtime task working with automatically
attached futexes would probably avoid this by issuing some no-op
operation on a futex just to trigger the attachment at a predictable
time.
All of these problems effectively rule out implicit attachment, meaning that, despite the fact that they remove nearly all the overhead for futex accesses, attached futexes really don't have a future.
Version two: no more attachment
Gleixner did indeed determine that attachment has no future and came up with an alternate scheme. The last time that futex performance was a problem, the response was to increase the size of the global hash table and enforce an alignment of buckets to cache lines to improve SMP behavior. Gleixner's latest patch set follows the same idea with a bit more sophistication. Rather than increase the single global hash table a "sharding" approach is taken, creating multiple distinct hash tables for multiple distinct sets of futexes.
Futexes can be declared as private, in which case they avoid the mmap_sem semaphore and can be only be used by threads in a single process. The set of private futexes for a given process form the basis for sharding and can, with the new patches, have exclusive access to a per-process hash table of futex buckets. All shared futexes still use the single global hash table. This approach addresses the NUMA issue by having the hash table on the same NUMA node as the process, and addresses the collision issue by dedicating more hash-table space per process. It only helps with private futexes, but these seem to be the style most likely to be used by applications needing predictable performance.
The choice of whether to allocate a per-process hash table is left as a system-wide configuration which is where the tradeoffs can best be assessed. The application is allowed a small role in the choice of when that table is allocated: a new futex command can request immediate allocation and suggest a preferred size. This avoids the non-determinism that would result from the default policy of allocation on first conflict.
It seems likely that this is the end of the story for now. There has been no distaste shown for the latest patch set and Gleixner is confident that it solves his particular problem. There would be no point aiming for a greater level of perfection until another demonstrated concrete need comes along.
Network filesystem topics
Steve French and Michael Adam led a session in the filesystem-only track at the 2016 Linux Storage, Filesystem, and Memory-Management Summit on network filesystems and some of the pain points for them on Linux. One of the main topics was case-insensitive file-name lookups.
French said that doing case-insensitive lookups was a "huge performance issue in Samba". The filesystem won't allow the creation of files with the wrong case, but files created outside of Samba can have mixed case or file names that collide in a case-insensitive comparison. That could lead to deleting the wrong file, for example.
![[Steve French]](https://static.lwn.net/images/2016/lsf-french-sm.jpg "Steve French")
Ric Wheeler suggested that what was really being sought is case-insensitive lookups but preserving the case on file creation. Ted Ts'o said that he has never been interested in handling case-insensitive lookups because Unicode changes the case-folding algorithm with some frequency, which would lead to having to update the kernel code to match that. Al Viro noted that preserving the case can lead to problems in the directory entry (dentry) cache; if both foo.h and FOO.H have been looked up, they will hash to different dentries.
Ts'o said that they would need to hash to the same dentry. Wheeler suggested that the dentry could always be lower case and that the file could have an extended attribute (xattr) that contains the real case-preserved name. That could be implemented by Samba, but there is a problem, as Ts'o pointed out: the Unix side wants to see the file names with the case preserved.
David Howells wondered if the case could simply be folded before the hash is calculated. But the knowledge of case and case insensitivity is not a part of the VFS, Viro said, and the hash is calculated by the filesystems themselves. Ts'o said that currently case insensitivity is not a first-class feature; it is instead just some hacks here and there. If case insensitivity is going to be added to filesystems like ext4, there are some hurdles to clear. For example, there are on-disk hashes in ext4 and he is concerned that changes to the case-folding rules could cause the hash to change, resulting in lost files.
Adam said that handling the case problem is interesting, but there are other problems for network filesystems. He noted that NFS is becoming more like Samba over time. That means that some of the problems that Samba is handling internally will be need to be solved for NFS, as well, though there will be subtle differences between them.
Both the "birth time" attribute for files and rich ACLs were mentioned as areas where
standard access mechanisms are needed, though there are plenty of others.
![[Michael Adam]](https://static.lwn.net/images/2016/lsf-adam-sm.jpg "Michael Adam") The problem is that filesystems provide different ways to get these pieces
of information, such as ioctl() commands or from xattrs. French
said there should be some kind of system call to hide those differences.
The problem is that filesystems provide different ways to get these pieces
of information, such as ioctl() commands or from xattrs. French
said there should be some kind of system call to hide those differences.
The perennially discussed xstat() system call was suggested as that interface, but discussions of xstat() always result in lots of bikeshedding about which attributes it should handle, Viro said. Ts'o said that "people try to do too much" with xstat(). In fact, there was a short session on xstat() later in the day that tried to reduce the scope of the system call with an eye toward getting something merged.
If there are twenty problems that can't be solved for network filesystems and five that can, even getting three of those solved would be a nice start, French said. There are issues for remote DMA (RDMA) and how to manage a direct copy from a device, for example. There are also device characteristics (e.g. whether it is an SSD) that applications want to know. Windows applications want to be able to determine attributes like alignment and seek penalty, but there is no consistent way to get that information. In addition, French said he doesn't want to have to decide whether a filesystem is integrity protected, but wants to query for it in some standard way.
Christoph Hellwig has been suggesting that filesystems move away from xattrs and to standardized filesystem ioctl() commands, French said. Ts'o said that the problem with xattrs is that they have become a kind of ASCII ioctl(); filesystems are parsing and creating xattrs that don't live on disk. At that point, the time for the session expired.
xstat()
The proposed xstat() system call, which is meant to extend the functionality of the stat() call to get additional file-status information, has been discussed quite a bit over the years, but has never been merged. The main impediment seems to be a lot of bikeshedding about how much information—and which specific pieces—will be returned. David Howells led a short filesystem-only discussion on xstat() at the 2016 Linux Storage, Filesystem, and Memory-Management Summit.
Howells presented a long list of possibilities that could be added to the structure for additional file status information to be returned by a call like xstat()—things like larger timestamps, the creation (or birth) time for a file, data version number (for some filesystems), inode generation number, and more. In general, there are more fields, with some that have grown larger, for xstat().
![[David Howells]](https://static.lwn.net/images/2016/lsf-howells-sm.jpg "David Howells")
There is also space at the end of the structure for growth. There are ways for callers to indicate what information they are interested in, as well as ways for the filesystem to indicate which pieces of valid information have been returned.
Howells noted that Dave Chinner wanted more I/O parameters (e.g. preferred read and write sizes, erase block size). There were five to seven different numbers that Chinner wanted, but those could always be added later, he said.
There are also some useful information flags that will be returned. Those will indicate if the file is a kernel file (e.g. in /proc or /sys), if it is compressed (and thus will result in extra latency when accessed), if it is encrypted, or if it is a sparse file. Windows has many of these indications.
But Ted Ts'o complained that there are two different definitions of a compressed file. It could mean that the file is not compressible, because it has already been done, or it could mean that the filesystem has done something clever and a read will return the real file contents. It is important to clearly define what the flag means. The FS_IOC_GETFLAGS ioctl() command did not do so, he said, so he wanted to ensure that the same mistake is not made with xstat().
There are other pieces of information that xstat() could return, Howells said. For example, whether accessing the file will cause an automount action or getting "foreign user ID" information for filesystems that don't have Unix-style UIDs or that have UIDs that do not map to the local system. There are also the Windows file attributes (archive, hidden, read-only, and system) that could be returned.
Ts'o suggested leaving out anything that did not have a clear definition of what it meant. That might help get xstat() merged. Others can be added later, he said.
Howells then described more of the functionality in his current version. There are three modes of operation. The standard mode would work the same way that stat() works today; it would force a sync of the file and retrieve an update from the server (if there is one). The second would be a "sync if we need to" mode; if only certain information that is stored locally is needed, it would simply be returned, but if the information requested required an update from the server (e.g. atime), that will be done. The third, "no sync" mode, means that only local values will be used; "it might be wrong, but it will be fast". For local filesystems, all three modes work the same way.
Jeff Layton asked: "How do we get it in without excessive bikeshedding?" He essentially answered his own question by suggesting that Howells start small and simply add "a few things that people really want". Joel Becker suggested that only parameters with "actual users in some upstream" be supported. That could help trim the list, he said.
Howells said that he asked for comments from various upstreams, but that only Samba had responded. Becker reiterated that whatever went in should be guided by actual users, since it takes work to support adding these bits of information. Howells agreed, noting that leaving extra space and having the masks and flags will leave room for expansion.
As it turns out, Howells posted a new patch set after LSFMM that reintroduces xstat() as the statx() system call.
Stream IDs and I/O hints
I/O hints are a way to try to give storage devices information that will allow them to make better decisions about how to store the data. One of the more recent hints is to have multiple "streams" of data that is associated in some way, which was mentioned in a storage standards update session the previous day. Changho Choi and Martin Petersen led a session at the 2016 Linux Storage, Filesystem, and Memory-Management Summit to flesh out more about streams, stream IDs, and I/O hints in general.
![[Changho Choi]](https://static.lwn.net/images/2016/lsf-choi-sm.jpg "Changho Choi")
Choi said that he is leading the multi-stream specification and software-development work at Samsung. There is no mechanism for storage devices to expose their internal organization to the host, which can lead to inefficient placement of data and inefficient background operations (e.g. garbage collection). Streams are an attempt to provide better collaboration between the host and the device. The host gives hints to the device, which will then place the data in the most efficient way. That leads to better endurance as well as improved and consistent performance and latency, he said.
A stream ID would be associated with operations for data that is expected to have the same lifetime. For example, temporary data, metadata, and user data could be separated into their own streams. The ID would be passed down to the device using the multi-stream interface and the device could put the data in the same erase blocks to avoid copying during garbage collection.
For efficiency, proper mapping of data to streams is essential, Choi said. Keith Packard noted that filesystems try to put writes in logical block address (LBA) order for rotating media and wondered if that was enough of a hint. Choi said that more information was needed. James Bottomley suggested that knowing the size and organization of erase blocks on the device could allow the kernel to lay out the data properly.
But there are already devices shipping with the multi-stream feature, from Samsung and others, Choi said. It is also part of the T10 (SCSI) standard and will be going into T13 (ATA) and NVM Express (NVMe) specifications.
![[Martin Petersen]](https://static.lwn.net/images/2016/lsf-petersen-sm.jpg "Martin Petersen")
Choi suggested exposing an interface for user space that would allow applications to set the stream IDs for writes. But Bottomley asked if there was really a need for a user-space interface. In the past, hints exposed to application developers went largely unused. It would be easier if the stream IDs were all handled by the kernel itself. He was also concerned that there would not be enough stream IDs available, so the kernel would end up using them all; none would be available to offer to user space.
Martin Petersen said that he was not against a user-space interface if one was needed, but suggested that it would be implemented with posix_fadvise() or something like that rather than directly exposing the IDs to user space. Choi thought that applications might have a better idea of the lifetime of their data than the kernel would, however.
At that point, Petersen took over to describe some research he had done on hints: how they are used and which are effective. There are several conduits for hints in the kernel, including posix_fadvise(), ioprio (available using ioprio_set()), the REQ_META flag for metadata, NFS v4.2, SCSI I/O advice hints, and so on. There are tons of different hints available; vendors implement different subsets of them.
So he wanted to try to figure out which hints actually make a difference. He asked internally (at Oracle) and externally about available hints, which resulted in a long list. From that, he pared the list back to hints that actually work. That resulted in half a dozen hints that characterize the data:
- Transaction - filesystem or database journals
- Metadata - filesystem metadata
- Paging - swap
- Realtime - audio/video streaming
- Data - normal application I/O
- Background - backup, data migration, RAID resync, scrubbing
The original streams proposal requires that the block layer request a stream ID from a device by opening a stream. Eventually those streams would need to be closed as well. For NVMe, streams are closely tied to the hardware write channels, which are a scarce resource. The explicit stream open/close is not popular and is difficult to do in some configurations (e.g. multipath).
So Petersen is proposing a combination of hints and streams. Device hints would be set based on knowledge the kernel has about the I/O. The I/O priority would be used to set the background I/O class hint (though it might move to a REQ_BG request flag), other request flags (REQ_META, REQ_JOURNAL, and REQ_SWAP) would set those hints, and posix_fadvise() flags would also set the appropriate hints.
Stream IDs would be based on files, which would allow sending the file to different devices and getting roughly the same behavior, he said. The proposal would remove the requirement to open and close streams and would provide a common model for all device types, so flash controllers, storage arrays, and shingled magnetic recording (SMR) devices could all make better decisions about data placement. This solution is being proposed to the standards groups as a way to resolve the problems with the existing hints and multi-stream specifications.
Background writeback
The problems with background writeback in Linux have been known for quite some time. Recently, there has been an effort to apply what was learned by network developers solving the bufferbloat problem to the block layer. Jens Axboe led a filesystem and storage track session at the 2016 Linux Storage, Filesystem, and Memory-Management Summit to discuss this work.
The basic problem is that flushing block data from memory to storage
(writeback) can flood the device queues to the point where any other reads and
![[Jens Axboe]](https://static.lwn.net/images/2016/lsf-axboe-sm.jpg "Jens Axboe") writes experience high latency. He has posted several versions of a patch
set to
address the problem and believes it is getting close to its final form.
There are fewer tunables and it all just basically works, he said.
writes experience high latency. He has posted several versions of a patch
set to
address the problem and believes it is getting close to its final form.
There are fewer tunables and it all just basically works, he said.
The queues are managed on the device side in ways that are "very loosely based on CoDel" from the networking code. The queues will be monitored and write requests will be throttled when the queues get too large. He thought about dropping writes instead (as CoDel does with network packets), but decided "people would be unhappy" with that approach.
The problem is largely solved at this point. Both read and write latencies are improved, but there is still some tweaking needed to make it work better. The algorithm is such that if the device is fast enough, it "just stays out of the way". It also narrows in on the right queue size quickly and if there are no reads contending for the queues, it "does nothing at all". He did note that he had not yet run the "crazy Chinner test case" again.
Ted Ts'o asked about the interaction with the I/O controller for control groups that is trying to do proportional I/O. Axboe said he was not particularly concerned about that. Controllers for each control group will need to be aware of each other, but it should all "probably be fine".
David Howells asked about writeback that is going to multiple devices. Axboe said that still needs work. Someone else asked about background reads, which Axboe said could be added. Nothing is inherently blocking that, but the work still needs to be done.
Multipage bio_vecs
In the block layer, larger I/O operations tend to be more efficient, but current kernels limit how large those operations can be. The bio_vec structure, which describes the buffer for an I/O operation, can only store a single page of tuples (of page, offset, and length) to describe the I/O buffer. There have been efforts over the years to allow multiple pages of array entries, so that even larger I/O operations can be held in a single bio_vec. Ming Lei led a session at the 2016 Linux Storage, Filesystem, and Memory-Management Summit to discuss patches to support bio_vec structures with multiple pages for the arrays.
Multipage bio_vec structures would consist of multiple, physically
contiguous
pages that could hold a larger array. It is the correct
thing to do, Lei said. It will save memory as there will be fewer
bio_vec structures needed and it will increase the transfer size
![[Ming Lei]](https://static.lwn.net/images/2016/lsf-lei-sm.jpg "Ming Lei") for each
struct bio (which contains a pointer to a bio_vec).
Currently, the single-page nature of a bio_vec means that only one
megabyte of I/O can be contained in a single bio_vec; adding
support for multiple pages will remove that limit.
for each
struct bio (which contains a pointer to a bio_vec).
Currently, the single-page nature of a bio_vec means that only one
megabyte of I/O can be contained in a single bio_vec; adding
support for multiple pages will remove that limit.
Jens Axboe agreed that there are benefits to larger bio_vec arrays, but was concerned about requesters getting physically contiguous pages. That would have to be done when the bio is created. Lei said that it is not hard to figure out how many pages will be needed before creating the bio, though.
All of the "magic" is in the bio_vec and bio iterators, one developer in the audience said. So there would be a need to introduce new helpers to iterate over the multipage bio_vec. The new name for the helper would require that all callers change, which would provide a good opportunity to review all of the users of the helpers, Christoph Hellwig said.
The patches also clean up direct access to some fields in bio structures: bi_vcnt, which tracks the number of entries in the bio_vec array, and the pointer to the bio_vec itself (bi_io_vec).
Axboe was concerned about handling all of the different special cases. There need to be "some real wins" in the patch set, since the memory savings are not all that huge. He is "not completely sold on why multipage is needed".
Hellwig agreed that the memory savings were not particularly significant, but that there is CPU time wasted in iterating over the segments. At various levels of the storage stack, the kernel has to iterate over the bio and bio_vec structures that make up I/O requests, so consolidating that information will save CPU time. There are also many needed cleanups in the patches, he said, so those should be picked up; "then, hopefully, we can get to the multipage bio_vecs".
Axboe said that the patches have been posted, but are not all destined for 4.7. He will queue up some of the preparatory patches, but the rest "need some time to digest".
Exposing extent information to user space
In a short, filesystem-only session at the 2016 Linux Storage, Filesystem, and Memory-Management Summit, Josef Bacik led a discussion on exposing information on extents, which are contiguous ranges of blocks allocated for a file (or files) by the filesystem, to user space. That could be done either by extending the FIEMAP ioctl() command or by coming up with a new interface. Bacik said that he was standing in for Mark Fasheh, who was unable to attend the session.
![[Josef Bacik]](https://static.lwn.net/images/2016/lsf-bacik-sm.jpg "Josef Bacik")
FIEMAP just reports whether an extent is shared or not, but there are some applications that want to know which inodes are sharing the extents. There are reserved 64-bit fields in struct fiemap_extent that could be used to report the inode numbers, Bacik said. He asked if that seemed like a reasonable approach.
Ric Wheeler wondered if there was really a need for applications to unwind all of this information. He asked: "Is there a backup application that will use this?" Jeff Mahoney responded that there is someone requesting the functionality.
Darrick Wong said that as part of his reverse mapping and reflink() work for XFS he has an interface that will allow applications to retrieve that kind of information. You can pass a range of physical block numbers to the reverse-map ioctl() and get back a list of objects (e.g. inodes) that think they own those blocks, he said.
Bacik said that sounded like the right interface: "Let's use that." Wong said that he would post some patches once he returned home from the summit.
DAX on BTT
In the final plenary session of the 2016 Linux Storage, Filesystem, and Memory-Management Summit, much of the team that works on the DAX direct-access mechanism led a discussion on how DAX should interact with the block translation table (BTT)—a mechanism aimed at making persistent memory have the atomic sector-write properties that users expect from block devices. Dan Williams took the role of ringleader, but Matthew Wilcox, Vishal Verma, and Ross Zwisler were also on-stage to participate.
Williams noted that Microsoft has adopted DAX for persistent memory and is even calling it DAX. Wilcox said that it was an indication that Microsoft is "listening to customers; they've changed".
![[Matthew Wilcox, Vishal Verma, Ross Zwisler, and Dan Williams]](https://static.lwn.net/images/2016/lsf-daxbtt-sm.jpg "Matthew Wilcox, Vishal Verma, Ross Zwisler, & Dan Williams")
BTT is a way to put block-layer-like semantics onto persistent memory, which handles writes at a cache-line granularity (i.e. 64 bytes), so that 512-byte (sector) writes are atomic. This eliminates the problem of "sector tearing", where a power or other failure causes a partial write to a sector resulting in a mixture of old and new data—a situation that applications (or filesystems) are probably not prepared to handle. Microsoft supports DAX on both BTT and non-BTT block devices, while Linux only supports it for non-BTT devices. Williams asked: "should we follow them [Microsoft] down that rabbit hole?"
The problem is that BTT is meant to fix a problem where persistent memory is treated like a block device, which is not what DAX is aimed at. Using BTT only for filesystem metadata might be one approach, Zwisler said. But Ric Wheeler noted that filesystems already put a lot of work into checksumming metadata, so using BTT for that would make things much slower for little or no gain.
Jeff Moyer pointed out that sector tearing can happen on block devices like SSDs, which is not what users expect. Joel Becker suggested that something like the SCSI atomic write command could be used by filesystems or applications that are concerned about torn sectors. That command guarantees that the sector is either written in full or not at all. There is no way to "magically save applications from torn sectors" unless they take some kind of precaution, he said.
There is a bit of a "hidden agenda" in supporting BTT, though, Williams said. Currently, the drivers are not aware of when DAX mappings are established and torn down, but that would change for BTT support. Wilcox said he has a patch series that addresses some parts of that by making the radix tree the source for that information.
task_diag and statx()
The interfaces supported by Linux to provide access to information about processes and files have literally been around for decades. One might think that, by this time, they would have reached a state of relative perfection. But things are not so perfect that developers are deterred from working on alternatives; the motivating factor in the two cases studied here is the same: reducing the cost of getting information out of the kernel while increasing the range of information that is available.
task_diag
There is no system call in Linux that provides information about running processes; instead, that information can be found in the /proc filesystem. Each process is represented by a directory under /proc; that directory contains a directory tree of its own with files providing information on just about every aspect of the process's existence. A quick look at the /proc hierarchy for a running bash instance reveals 279 files in 40 different directories. Whether one wants to know about control-group membership, resource usage, memory mappings, environment variables, open files, namespaces, out-of-memory-killer policies, or more, there is a file somewhere in that tree with the requisite information.
There are a lot of advantages to /proc, starting with the way it implements the classic Unix "everything is a file" approach. The information is readable as plain text, making it accessible from the command line or shell scripts. To a great extent, the interface is self-documenting, though some parts are more obvious than others. The contents of the stat file, for example, require an outside guide to be intelligible.
There are some downsides to this approach too, though. Accessing a file in /proc requires a minimum of three system calls — open(), read(), and close() — and that is after the file has been located in the directory hierarchy. Getting a range of information can require reading several files, with the system-call count multiplied accordingly. Some /proc files are expensive to read, and much of the resulting data may not be of interest to the reading process. There has been, to put it charitably, no unifying vision guiding the design of the /proc hierarchy, so each file there must be approached as a new parsing problem. It all adds up to a slow and cumbersome interface for applications that need significant amounts of information about multiple processes.
A possible solution comes in the form of the task_diag patch set from Andrey Vagin; it adds a binary interface allowing the extraction of lots of process information from the kernel using a single request. The starting point is a file called /proc/task-diag, which an interested process must open. That process then uses the netlink protocol to send a message describing the desired information, which can then be read back from the same file.
The request for information is contained within this structure:
struct task_diag_pid {
__u64 show_flags;
__u64 dump_strategy;
__u32 pid;
};
The dump_strategy field tells the kernel which processes are of interest. Its value can be one of TASK_DIAG_DUMP_ONE (information about the single process identified by pid), TASK_DIAG_DUMP_THREAD (get information about all threads of pid), TASK_DIAG_DUMP_CHILDREN (all children of pid), TASK_DIAG_DUMP_ALL (all processes in the system) or TASK_DIAG_DUMP_ALL_THREADS (all threads in the system).
The show_flags field, instead, describes which information is to be returned for each process. With TASK_DIAG_SHOW_BASE, the "base" information will be returned:
struct task_diag_base {
__u32 tgid;
__u32 pid;
__u32 ppid;
__u32 tpid;
__u32 sid;
__u32 pgid;
__u8 state;
char comm[TASK_DIAG_COMM_LEN];
};
Other possible flags include TASK_DIAG_SHOW_CREDS to get credential information, TASK_SHOW_VMA and TASK_SHOW_VMA_STAT for information on memory mappings, TASK_DIAG_SHOW_STAT for resource-usage statistics, and TASK_DIAG_SHOW_STATM for memory-usage statistics. If this interface is merged into the mainline, other options will surely follow.
The patches have been through a few rounds of review. Presumably something along these lines will eventually be merged, but it is not clear that the level of review required to safely add a new major kernel API has happened. There is also no man page for this feature yet. So it would not be surprising if a few more iterations were required before this one is declared to be ready.
statx()
Information about files in Linux, as with all Unix-like systems, comes via the stat() system call and its variants. Developers have chafed against its limitations for a long time. This system call, being enshrined in the POSIX standard, cannot be extended to return more information. It will likely return information that the calling process doesn't need — a wasted effort that can, for some information and filesystems, be expensive. And so on. For these reasons, an extended stat() system call has been a topic of discussion for many years.
Back in 2010, David Howells proposed a xstat() call that addressed a number of these problems, but that proposal got bogged down in discussion without being merged. Six years later, David is back with a new version of this patch. Time will tell if he is more successful this time around.
The new system call is now called statx(); the proposed interface is:
int statx(int dfd, const char *filename, unsigned atflag, unsigned mask, struct statx *buffer);
The file of interest is identified by filename; that file is expected to be found in or underneath the directory indicated by the file descriptor passed in dfd. If dfd is AT_FDCWD, the filename is interpreted relative to the current working directory. If filename is null, information about the file represented by dfd is returned instead.
The atflag parameter modifies how the information is collected. If it is AT_SYMLINK_NOFOLLOW and filename is a symbolic link, information is returned about the link itself. Other atflag values include AT_NO_AUTOMOUNT to prevent filesystems from being automatically mounted by the request, AT_FORCE_ATTR_SYNC to force a network filesystem to update attributes from the server before returning the information, and AT_NO_ATTR_SYNC to avoid updating from the server, even at the cost of returning approximate information. That last option can speed things up considerably when querying information about files on remote filesystems.
The mask parameter, instead, specifies which information the caller is looking for. The current patch set has fifteen options, varying from STATX_MODE (to get the permission bits) to STATX_GEN to get the current inode generation number (on filesystems that have such a concept). That mask appears again in the returned structure to indicate which fields are valid; that structure looks like:
struct statx {
__u32 st_mask; /* What results were written [uncond] */
__u32 st_information; /* Information about the file [uncond] */
__u32 st_blksize; /* Preferred general I/O size [uncond] */
__u32 st_nlink; /* Number of hard links */
__u32 st_gen; /* Inode generation number */
__u32 st_uid; /* User ID of owner */
__u32 st_gid; /* Group ID of owner */
__u16 st_mode; /* File mode */
__u16 __spare0[1];
__u64 st_ino; /* Inode number */
__u64 st_size; /* File size */
__u64 st_blocks; /* Number of 512-byte blocks allocated */
__u64 st_version; /* Data version number */
__s64 st_atime_s; /* Last access time */
__s64 st_btime_s; /* File creation time */
__s64 st_ctime_s; /* Last attribute change time */
__s64 st_mtime_s; /* Last data modification time */
__s32 st_atime_ns; /* Last access time (ns part) */
__s32 st_btime_ns; /* File creation time (ns part) */
__s32 st_ctime_ns; /* Last attribute change time (ns part) */
__s32 st_mtime_ns; /* Last data modification time (ns part) */
__u32 st_rdev_major; /* Device ID of special file */
__u32 st_rdev_minor;
__u32 st_dev_major; /* ID of device containing file [uncond] */
__u32 st_dev_minor;
__u64 __spare1[16]; /* Spare space for future expansion */
};
Many of those fields match those found in the classic struct stat
or are close to them. Times have been split into separate second and
nanosecond fields, enabling both high-precision timestamps and year-2038
compliance. The __spare1 array at the end is meant to
allow other types of data to be added in the future. Finally,
st_information gives general information about the file, including
whether it's encrypted, whether it's a kernel-generated file, or whether
it's stored on a remote server.
The only response to this patch set, as of this writing, came from Jeff Layton, who suggested "I
think we really ought to resist excessive bikeshedding this time
around
". If the other developers accept that advice, then it's
possible that an enhanced stat() interface might just get into the
kernel sometime this year. Nobody will be able to complain that this
particular change has been rushed.
Patches and updates
Kernel trees
Architecture-specific
Core kernel code
Device drivers
Device driver infrastructure
Networking
Security-related
Miscellaneous
Page editor: Jonathan Corbet
Distributions
Fedora's Node.js problem
Aligning distribution and major package schedules is often something of a tricky balancing act. Fedora is currently doing some of that; it is trying to figure out what to with its Node.js package for Fedora 24. Node.js 5.10 is currently packaged for Fedora 24, but that release will only be supported until mid-year, which would mean that Fedora developers would have to backport security fixes for as long as a year. But the most recent release (6.0) came out on April 26 and may not yet support all of the other dependent packages, which puts Fedora somewhere between a rock and a hard place.
Current Node.js package maintainer Stephen Gallagher posted a message about the problem on the
release day for Node.js 6.0. That release is a "significant ABI-breaking release,
which means there is no guarantee that existing modules will work with it
at all
", he said. That release is slated to become the next
long-term support release in October—on paper, that would make it a good
choice for Fedora 24, since it will be supported until 2019. But
Fedora 24 is nearly out the
door, with a final freeze scheduled for the end of May and the
release in mid-June. So, any change, especially one that could break all
of the packages dependent on Node.js, is worrisome—at best.
Currently, Fedora 24 has Node.js 5.x, but that will be unsupported by the Node.js developers relatively soon. One option would be to stick with that, but once Fedora 24 is released, the project's policy of disallowing major ABI changes in a stable release would mean that Fedora has to pick up the maintenance burden. Gallagher put it this way:
Another option might be to fall back to Node.js 4.x, which was
released in October 2015 and will be
supported until well after the end of life for Fedora 24, but that is not
without potential problems as well. Any of the dependent packages that
have started using features from 5.x may not work. It all adds up to no
"particularly good options
", he said.
No one in the resulting thread seemed to like the "stick with 5.x" option.
There was some talk of just abandoning 5.x and moving to 6.x sometime
around October, but that would require Fedora Engineering Steering
Committee (FESCo) approval and would set something of a bad precedent. But
"drago01" thought that concerns about
upgrading the package during the release cycle were based on a misunderstanding
of the update
policy, which says that it is possible to upgrade when an
upstream stops
supporting a release if backporting fixes "would be
impractical
". The definition of "practical" is up to the packager
and FESCo.
Gallagher pointed out that the policy is likely changing, however:
Tom Hughes noted that there actually might not be any problem falling back to 4.x, since most packages try to support both 4.x and 5.x. Gallagher confirmed that by querying the package repository:
I don't love the idea of regressing the versions post-Beta, but it's starting to look like the least-risky approach.
The beta release of Fedora 24 is targeted for May 10, so the regression to 4.x would happen after that. But if the repository metadata is accurate, there should be few repercussions to making the switch. Gallagher announced that plan on April 28 and asked Node.js users to test with the new package he had built.
There was also some discussion of which Node.js branches should be used in the future. Hughes asked if it would ever make sense to use versions without long-term support given Fedora's thirteen-month support cycle. Gallagher replied that it turns out those releases are generally only supported for nine months or so, which means that Fedora should always ship the long-term support releases. That seems to be the plan moving forward.
In the end, it would seem that it will be a fairly painless transition, even if it looked like there were only ugly choices at the start. As part of its general philosophy, Fedora targets the newest releases of packages, which is presumably why Node.js 5.x got picked up in the first place. But the burden of maintaining an unsupported release, especially for an internet-facing package like Node.js, is quite large. Better to distribute an older version than to risk exposing Fedora Node.js users to the vulnerabilities that will undoubtedly be uncovered during the life of Fedora 24.
Brief items
Devuan Jessie beta released
The Devuan community has finally gotten a beta release out for testing. "Debian GNU+Linux [sic] is a fork of Debian without systemd, on its way to become much more than that. This Beta release marks an important milestone towards the sustainability and the continuation of Devuan as an universal base distribution."
The Linux Embedded Development Environment launches
The Linux Embedded Development Environment (or LEDE) project, a fork (or "spinoff") of OpenWrt, has announced its existence. "We are building an embedded Linux distribution that makes it easy for developers, system administrators or other Linux enthusiasts to build and customize software for embedded devices, especially wireless routers. [...] Members of the project already include a significant share of the most active members of the OpenWrt community. We intend to bring new life to Embedded Linux development by creating a community with a strong focus on transparency, collaboration and decentralisation." The new project lives at lede-project.org. (Thanks to Mattias Mattsson).
Newsletters and articles of interest
Distribution newsletters
- DistroWatch Weekly, Issue 659 (May 2)
- Lunar Linux weekly news (April 29)
- Ubuntu Kernel Team weekly newsletter (May 3)
- Ubuntu Weekly Newsletter, Issue 463 (May 1)
Ubuntu 16.04 Review: What’s New for Desktop Users (Linux.com)
Linux.com reviews Ubuntu 16.04 LTS on the desktop, including Snaps, a new way of packaging and delivering applications. "Snaps also offer relatively more security because each app is sandboxed -- although there is still some room for improvement. But, like any other new technology, it will get better with time. In regard to privacy and security, I should mention that Unity previously was heavily criticized for integrating online ads and services with Dash. It was seen a privacy leak. Ubuntu 16.04, however, comes the latest version of Unity for the desktop -- that's 7.4 -- which disables online search or ads as the default."
Page editor: Rebecca Sobol
Development
Sandboxing for the unprivileged with bubblewrap
Sandboxing a Linux application is a task often associated with server-side containers that are exposed to the Internet at large. One wants a database server or web application to be contained, for instance, so that if something goes awry, that does not harm the entire host operating system. But work progresses on sandboxing desktop applications, too. On that front, Alex Larsson and others from the GNOME community have recently started working on a new "user-level" sandboxing utility called bubblewrap. The tool can be used by unprivileged users to run an application in a sandboxed environment, so that it cannot access OS resources and is similarly restricted from accessing the user's home directory.
Much of the effort (or, at least, the highly publicized effort) that has gone into application-level sandboxing in recent years has been driven by the needs of those deploying containers at large scale—in particular, by projects like Docker and Kubernetes that are most popular for web applications. But the desire to isolate a process from the surrounding OS is also relevant to people running desktop Linux distributions.
Ubuntu's snap system and GNOME's xdg-app both incorporate measures to isolate an application process (via mechanisms like control groups and namespaces). But both of those frameworks provide quite a bit more than the sandbox itself. For instance, they define runtime environments that the sandboxed process can depend on for system services and they provide a way to package an application with its dependencies included.
Furthermore, as Larsson explained in an April 29 blog post, container-management tools themselves are generally designed for system administrators and, thus, run as a privileged user. That makes such tools a potential cause for security concern, as granting users access to them means trusting those users with considerable administrative privileges (and, in the case of security bugs, can lead to privilege escalations). In addition, there are several scenarios beyond container orchestration in which sandboxing a process is a wise idea. Development builds of software could be sandboxed to isolate them from the OS, for example, or a sandbox could be used to limit an application's privileges in some specific manner. In short, a sandboxing utility that unprivileged users could employ to isolate a process would find numerous uses.
In response to all of these issues, Larsson and the other xdg-app developers started the bubblewrap project in February. Bubblewrap's internals originated in Colin Walters's linux-user-chroot, which was then ported into xdg-app as a helper application. But the helper was tied in directly to xdg-app in several places. It assumed, for instance, that the sandboxed process would be mounted on top of an xdg-app runtime. The standalone version is more generic, and builds substantially over what linux-user-chroot was capable of.
The bubblewrap README notes that user namespaces could also be used to let unprivileged users do application sandboxing by allowing those users to run an existing container-management tool in their own user namespace. But it points to the ongoing concerns about the security of user namespaces as a rationale for the new project.
As is, bubblewrap provides only a subset of the functionality that user namespaces could allow. In particular, it does not provide control over iptables, which the README says could prevent vulnerabilities like CVE-2016-3135.
Bubblewrap works by creating an empty mount namespace with the root on a temporary filesystem that will be destroyed after the sandboxed process exits. Using switches, the user can construct the desired filesystem environment within the mount namespace by bind-mounting the desired directories from the host system.
On the simple end of the spectrum,
bwrap --bind /some/chroot / foo.sh
will essentially create a traditional chroot jail. The final argument (here, foo.sh) is simply the executable to be started in the sandbox. But the configuration supported by bubblewrap can be substantially more complex. So, for instance, the example shown in the README:
bwrap --ro-bind /usr /usr \
--dir /tmp \
--proc /proc \
--dev /dev \
--ro-bind /etc/resolv.conf /etc/resolv.conf \
--symlink usr/lib /lib \
--symlink usr/lib64 /lib64 \
--symlink usr/bin /bin \
--symlink usr/sbin /sbin \
--chdir / \
--unshare-pid \
--unshare-net \
--dir /run/user/$(id -u) \
--setenv XDG_RUNTIME_DIR "/run/user/`id -u`" \
/bin/sh
creates a read-only bind mount from the host system for /usr and for /etc/resolv.conf, but creates its own /tmp, /proc, and /dev directories by using the --dir switch.
The --unshare-pid switch creates a PID namespace in the sandbox and --unshare-net creates a network namespace. The other options currently supported are IPC namespaces, user namespaces (including specifying a custom UID and GID), and UTS namespaces.
Apart from specifying the UID and GID, no options are provided for the namespace switches. The sandbox isolates the executable from the host filesystem, IPC mechanism, and the network. In addition, the --seccomp file_descriptor switch can be used to load a set of seccomp rules for the sandbox.
Bubblewrap has now replaced the earlier helper application in xdg-app and is available for the rpm-ostree packaging system. The bubblewrap page notes, however, that it could also be useful in existing server-oriented container environments. Whether that idea catches on or not remains to be seen; in the meantime, bubblewrap provides an interesting extension of Linux's sandboxing capabilities into the unprivileged-user space.
Brief items
Quote of the week
De Maré: Mercurial 3.7 and 3.8
Mercurial revision-control system developer Mathias De Maré summarizes the changes in the 3.7 and 3.8 releases. "Mercurial 3.7 had a major focus on performance. This is — to a large degree — due to large users like Facebook and Mozilla working on both performance and scalability."
WebExtensions in Firefox 48
At the Mozilla blog, Andy McKay announces
that the browser maker has officially declared WebExtensions ready to
use for add-on development. "With the release of Firefox 48, we feel WebExtensions are
in a stable state. We recommend developers start to use the
WebExtensions API for their add-on development.
" The
WebExtensions support released for Firefox 48 includes improvements to
the "alarms,
bookmarks,
downloads,
notifications,
webNavigation,
webRequest,
windows
and tabs
"
APIs, support for a new Content Security Policy that limits where
resources can be loaded from, and support in Firefox for Android. LWN
looked at the WebExtensions API in December.
Newsletters and articles
Development newsletters from the past week
- What's cooking in git.git (April 29)
- What's cooking in git.git (May 3)
- OCaml Weekly News (May 3)
- Perl Weekly (May 2)
- PostgreSQL Weekly News (May 1)
- Python Weekly (April 28)
- Ruby Weekly (April 28)
- This Week in Rust (May 2)
- Tahoe-LAFS Weekly News (May 3)
- Wikimedia Tech News (May 2)
A guide to inline assembly code in GCC
The "linux-insides" series of articles has gained an overview of inline assembly in GCC. "I've decided to write this to consolidate my knowledge related to inline assembly here. As inline assembly statements are quite common in the Linux kernel and we may see them in linux-insides parts sometimes, I thought that it would be useful if we would have a special part which contains descriptions of the more important aspects of inline assembly. Of course you may find comprehensive information about inline assembly in the official documentation, but I like the rules all in one place."
Page editor: Nathan Willis
Announcements
Brief items
The ACM 2015 technical awards
The Association for Computing Machinery has announced the recipients of its 2015 technical awards. They are Brent Walters, Michael Luby, Eric Horvitz, and: "Richard Stallman, recipient of the ACM Software System Award for the development and leadership of GCC (GNU Compiler Collection), which has enabled extensive software and hardware innovation, and has been a lynchpin of the free software movement."
X.Org votes to join SPI
The results of the X.Org election are in. There were two things up for a vote: four seats on the board of directors and amending the bylaws to join Software in the Public Interest (SPI). Unlike last year's election, this year's vote met the required 2/3 approval to join SPI (61 voters out of 65 members, with 54 voting "Yes", 4 "No", and 3 "Abstain"). In addition, Egbert Eich, Alex Deucher, Keith Packard, and Bryce Harrington were elected to the board.
Articles of interest
FSFE Newsletter - May 2016
This edition of the Free Software Foundation Europe newsletter covers EU jeopardises its goals in standardisation with FRAND licensing, European Commission vs Google Android, and much more.
New Books
Humble Book Bundle: Hacking, presented by No Starch Press
No Starch Press and Humble Bundle present the "Humble Book Bundle: Hacking". "The bundle includes a selection of the company's finest--such as worldwide best seller "Hacking: The Art of Exploitation"; classics like "Hacking the Xbox"; and more recent best sellers like "Automate the Boring Stuff with Python," "Black Hat Python," and "Practical Malware Analysis." This bundle is a true bargain--valued at over US $350--and with Humble Bundle's pay-what-you-want model, customers can pay whatever price they think is fair."
Calls for Presentations
DebConf16 Call for Proposals deadline extended
The call for proposals deadline for DebConf has been extended until May 15. DebConf will be held July 2-9 in Cape Town, South Africa.EuroPython 2016: Extra Hot Topics - Call for Proposals
There will be a second call for proposals for EuroPython open only June 4-12. This call is strictly reserved for hot topics, emerging technologies, brand new developments in software & hardware, and recent results in research and science. EuroPython will take place July 17-24 in Bilbao, Spain.Tracing Summit 2016 Call for Presentations
There will be a Tracing Summit on October 12 in Berlin, Germany, co-located with the Embedded Linux Conference. "The Tracing Summit is organized by the Linux Foundation Diagnostic and Monitoring Workgroup (http://diamon.org). This event focuses on the tracing area, gathering people involved in development and end-users of tracing tools as well as trace analysis tools. The main target of this Tracing Summit is to provide room for discussion between people in the various areas that benefit from tracing, namely parallel, distributed and/or real-time systems, as well as kernel development." The call for proposals ends July 15.
CFP Deadlines: May 5, 2016 to July 4, 2016
The following listing of CFP deadlines is taken from the LWN.net CFP Calendar.
| Deadline | Event Dates | Event | Location |
|---|---|---|---|
| May 6 | October 26 October 27 |
All Things Open | Raleigh, NC, USA |
| May 6 | July 13 July 15 |
LinuxCon Japan | Tokyo, Japan |
| May 8 | August 12 August 16 |
PyCon Australia 2016 | Melbourne, Australia |
| May 15 | July 2 July 9 |
DebConf16 | Cape Town, South Africa |
| May 15 | September 1 September 8 |
QtCon 2016 | Berlin, Germany |
| May 15 | June 11 June 12 |
Linuxwochen Linz | Linz, Austria |
| May 16 | October 31 November 2 |
O’Reilly Security Conference | New York, NY, USA |
| May 23 | October 17 October 19 |
O'Reilly Open Source Convention | London, UK |
| May 23 | August 20 August 21 |
FrOSCon - Free and Open Source Software Conference | Sankt-Augustin, Germany |
| May 24 | August 18 August 21 |
Camp++ 0x7e0 | Komárom, Hungary |
| May 24 | November 9 November 11 |
O’Reilly Security Conference EU | Amsterdam, Netherlands |
| May 25 | October 5 October 7 |
International Workshop on OpenMP | Nara, Japan |
| May 29 | September 20 September 23 |
PyCon JP 2016 | Tokyo, Japan |
| May 30 | September 13 September 16 |
PostgresOpen 2016 | Dallas, TX, USA |
| June 3 | June 24 June 25 |
French Perl Workshop 2016 | Paris, France |
| June 4 | July 30 July 31 |
PyOhio | Columbus, OH, USA |
| June 5 | September 26 September 27 |
Open Source Backup Conference | Cologne, Germany |
| June 5 | September 9 September 10 |
RustConf 2016 | Portland, OR, USA |
| June 10 | August 25 August 26 |
Linux Security Summit 2016 | Toronto, Canada |
| June 11 | October 3 October 5 |
OpenMP Conference | Nara, Japan |
| June 15 | September 8 September 9 |
First OpenPGP conference | Cologne, Germany |
| June 15 | November 16 November 17 |
Paris Open Source Summit | Paris, France |
| June 20 | September 9 September 11 |
Kiwi PyCon 2016 | Dunedin, New Zealand |
| June 22 | September 19 September 23 |
Libre Application Summit | Portland, OR, USA |
| June 26 | October 11 October 13 |
Embedded Linux Conference Europe | Berlin, Germany |
| June 30 | November 29 December 2 |
Open Source Monitoring Conference | Nürnberg, Germany |
If the CFP deadline for your event does not appear here, please tell us about it.
Upcoming Events
Early LinuxCon + ContainerCon keynotes announced
The Linux Foundation has announced the lineup of early keynote speakers for LinuxCon and ContainerCon. Speakers include Cory Doctorow, Margaret Heffernan, Ainissa Ramirez, and Linus Torvalds. LinuxCon and ContainerCon will take place August 22-24 in Toronto, Canada.Events: May 5, 2016 to July 4, 2016
The following event listing is taken from the LWN.net Calendar.
| Date(s) | Event | Location |
|---|---|---|
| May 1 June 29 |
Open Source Innovation Spring | Paris, France |
| May 2 May 5 |
FOSS4G North America | Raleigh, NC, USA |
| May 9 May 13 |
ApacheCon North America | Vancouver, Canada |
| May 10 May 12 |
Samba eXPerience 2016 | Berlin, Germany |
| May 14 May 15 |
Open Source Conference Albania | Tirana, Albania |
| May 14 May 15 |
Community Leadership Summit 2016 | Austin, TX, USA |
| May 16 May 19 |
OSCON 2016 | Austin, TX, USA |
| May 17 May 21 |
PGCon - PostgreSQL Conference for Users and Developers | Ottawa, Canada |
| May 24 May 25 |
Cloud Foundry Summit | Santa Clara, CA, USA |
| May 26 | NLUUG - Spring conference 2016 | Bunnik, The Netherlands |
| May 28 June 5 |
PyCon 2016 | Portland, OR, USA |
| June 1 June 2 |
Apache MesosCon | Denver, CO, USA |
| June 4 June 5 |
Coliberator 2016 | Bucharest, Romania |
| June 11 | TÜBIX 2016 | Tübingen, Germany |
| June 11 June 12 |
Linuxwochen Linz | Linz, Austria |
| June 14 June 15 |
PyData Paris 2016 | Paris, France |
| June 19 June 21 |
DockerCon | Seattle, WA, USA |
| June 20 June 23 |
OPNFV Summit | Berlin, Germany |
| June 21 June 22 |
Deutsche OpenStack Tage | Köln, Deutschland |
| June 21 June 24 |
Open Source Bridge | Portland, OR, USA |
| June 21 June 25 |
Third Julia Conference | Cambridge, MA, USA |
| June 21 June 28 |
Wikimania | Esino Lario, Italy |
| June 22 June 26 |
openSUSE Conference 2016 | Nürnberg, Germany |
| June 22 June 24 |
USENIX Annual Technical Conference | Denver, CO, USA |
| June 23 July 1 |
DebCamp | Cape Town, South Africa |
| June 24 June 25 |
Hong Kong Open Source Conference 2016 | Hong Kong, Hong Kong |
| June 24 June 25 |
devopsdays Silicon Valley 2016 | Mountain View, CA, USA |
| June 24 | Swiss PostgreSQL Day | Rapperswil, Switzerland |
| June 24 June 25 |
French Perl Workshop 2016 | Paris, France |
| June 27 July 1 |
Hack in Paris | Paris, France |
| June 27 July 1 |
12th Netfilter Workshop | Amsterdam, Netherlands |
| July 2 July 9 |
DebConf16 | Cape Town, South Africa |
If your event does not appear here, please tell us about it.
Page editor: Rebecca Sobol