
Kernel development
Brief items
Kernel release status
The current development kernel is 3.16-rc5, released on July 13. Linus said: "Things are looking normal, and as usual, I _wish_ there was a bit less churn going on since it's getting fairly late in the rc cycle, but honestly, it's not like there is anything that really raises any eyebrows here."
Stable updates: 3.15.5, 3.14.12, 3.10.48, and 3.4.98 were released on July 9. The 3.15.6, 3.14.13, 3.10.49, and 3.4.99 updates are in the review process as of this writing; they can be expected on or after July 17.
Quotes of the week
https://www.kickstarter.com/projects/324283889/potato-salad
So in consequence we might turn RT into a crowdfunded nonsense project which serves the purpose of controlling the potato-salad machine to make sure that Zack Danger Brown can deliver all the potato salad people have pledged for.
Linux Foundation Technical Advisory Board election
Elections for five members of the Linux Foundation's Technical Advisory Board wil be held at the 2014 Kernel Summit on August 20. Nominations are being sought now. Incumbent members Chris Mason, James Bottomley, and John Linville are seeking re-election, while Ric Wheeler and Jesse Barnes have decided to step down.
Kernel development news
Anatomy of a system call, part 2
The previous article explored the kernel implementation of system calls (syscalls) in its most vanilla form: a normal syscall, on the most common architecture: x86_64. We complete our look at syscalls with variations on that basic theme, covering other x86 architectures and other syscall mechanisms. We start by exploring the various 32-bit x86 architecture variants, for which a map of the territory involved may be helpful. The map is clickable on the filenames and arrow labels to link to the code referenced:

x86_32 syscall invocation via SYSENTER
The normal invocation of a system call on a 32-bit x86_32 system is closely analogous to the mechanism for x86_64 systems that was described in the previous article. Here, the arch/x86/syscalls/syscall_32.tbl table has an entry for sys_read:
3 i386 read sys_read
This entry indicates that read() for x86_32 has syscall number 3, with entry point sys_read() and an i386 calling convention. The table post-processor will emit a __SYSCALL_I386(3, sys_read, sys_read) macro call into the generated arch/x86/include/generated/asm/syscalls_32.h file. This, in turn, is used to build the syscall table, sys_call_table, as before.
Moving outward, sys_call_table is accessed from the ia32_sysenter_target entry point of arch/x86/kernel/entry_32.S. However, here the SAVE_ALL macro actually pushes a different set of registers (EBX/ECX/EDX/ESI/EDI/EBP rather than RDI/RSI/RDX/R10/R8/R9) onto the stack, reflecting the different syscall ABI convention for this platform.
The location of the ia32_sysenter_target entry point gets written to a model-specific register (MSR) at kernel start (in enable_sep_cpu()); in this case, the MSR in question is MSR_IA32_SYSENTER_EIP (0x176), which is used for handling the SYSENTER instruction.
This shows the invocation path from userspace. The standard modern ABI for how x86_32 programs invoke a system call is to put the system call number (3 for read()) into the EAX register, and the other parameters into specific registers (EBX, ECX, and EDX for the first 3 parameters), then invoke the SYSENTER instruction.
This instruction causes the processor to transition to ring 0 and invoke the code referenced by the MSR_IA32_SYSENTER_EIP model-specific register — namely ia32_sysenter_target. That code pushes the registers onto the (kernel) stack, and calls the function pointer at entry EAX in sys_call_table — namely sys_read(), which is a thin, asmlinkage wrapper for the real implementation in SYSC_read().
x86_32 syscall invocation via INT 0x80
The sys_call_table table is also accessed in arch/x86/kernel/entry_32.S from the system_call assembly entry point. Again, this entry point saves registers to the stack, then uses the EAX register to pick the relevant entry in sys_call_table and call it. This time, the location of the system_call entry point is used by trap_init():
#ifdef CONFIG_X86_32
set_system_trap_gate(SYSCALL_VECTOR, &system_call);
set_bit(SYSCALL_VECTOR, used_vectors);
#endif
This sets up the handler for the SYSCALL_VECTOR trap to be system_call; that is, it sets it up to be the recipient of the venerable INT 0x80 software interrupt method for invoking system calls.
This is the original user-space invocation path for system calls, which is now generally avoided because, on modern processors, it's slower than the instructions that are specifically designed for system call invocation (SYSCALL and SYSENTER).
With this older ABI, programs invoke a system call by putting the system call number into the EAX register, and the other parameters into specific registers (EBX, ECX, and EDX for the first 3 parameters), then invoking the INT 0x80 instruction. This instruction causes the processor to transition to ring 0 and invoke the trap handler for software interrupt 0x80 — namely system_call. The system_call code pushes the registers onto the (kernel) stack, and calls the function pointer at entry EAX in the sys_call_table table — namely sys_read(), the thin, asmlinkage wrapper for the real implementation in SYSC_read(). Much of that should seem familiar, as it is the same as for using SYSENTER.
x86 syscall invocation mechanisms
For reference, the different user-space syscall invocation mechanisms on x86 we've seen so far are as follows:
64-bit programs use the SYSCALL instruction. This instruction was originally introduced by AMD, but was subsequently implemented on Intel 64-bit processors and so is the best choice for cross-platform compatibility.
Modern 32-bit programs use the SYSENTER instruction, which has been present since Intel introduced the IA-32 architecture.
Ancient 32-bit programs use the INT 0x80 instruction to trigger a software interrupt handler, but this is much slower than SYSENTER on modern processors.
x86_32 syscall invocation on x86_64
Now for a more complicated case: what happens if we are running a 32-bit binary on our x86_64 system? From the user-space perspective, nothing is different; in fact, nothing can be different, because the user code being run is exactly the same.
For the SYSENTER case, an x86_64 kernel registers a different function as the handler in the MSR_IA32_SYSENTER_EIP model-specific register. This function has the same name (ia32_sysenter_target) as the x86_32 code but a different definition (in arch/x86/ia32/ia32entry.S). In particular, it pushes the old-style registers but uses a different syscall table, ia32_sys_call_table. This table is built from the 32-bit table of entries; in particular, it will have entry 3 (as used on 32-bit systems), rather than 0 (which is the syscall number for read() on 64-bit systems), mapping to sys_read().
For the INT 0x80 case, the trap_init() code on x86_64 instead invokes:
#ifdef CONFIG_IA32_EMULATION
set_system_intr_gate(IA32_SYSCALL_VECTOR, ia32_syscall);
set_bit(IA32_SYSCALL_VECTOR, used_vectors);
#endif
This maps the IA32_SYSCALL_VECTOR (which is still 0x80) to ia32_syscall. This assembly entry point (in arch/x86/ia32/ia32entry.S) uses ia32_sys_call_table rather than the 64-bit sys_call_table.
A more complex example: execve and 32-bit compatibility handling
Now let's look at a system call that involves other complications: execve(). We'll again work outward from the kernel implementation of the system call, and explore the differences from the simpler read() call along the way. Again, a clickable map of the territory we're going to explore might help things along:
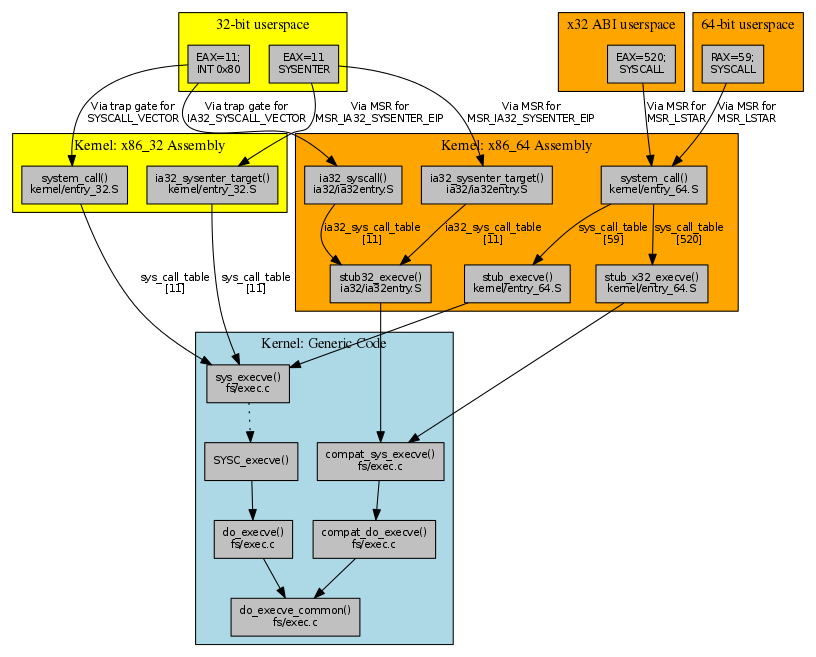
The execve() definition in fs/exec.c looks similar to that for read(), but there is an interesting additional function defined right after it (at least when CONFIG_COMPAT is defined):
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);
}
#ifdef CONFIG_COMPAT
asmlinkage long compat_sys_execve(const char __user * filename,
const compat_uptr_t __user * argv,
const compat_uptr_t __user * envp)
{
return compat_do_execve(getname(filename), argv, envp);
}
#endif
Following the processing path, these two implementations converge on do_execve_common() to perform the real work (sys_execve() → do_execve() → do_execve_common() versus compat_sys_execve() → compat_do_execve() → do_execve_common()), setting up user_arg_ptr structures along the way. These structures hold those syscall arguments that are pointers-to-pointers, together with an indication of whether they come from a 32-bit compatibility ABI; if so, the value being pointed to is a 32-bit user-space address, not a 64-bit value, and the code to copy the argument values from user space needs to allow for that.
So, unlike read(), where the syscall implementation didn't need to distinguish between 32-bit and 64-bit callers because the arguments were pointers-to-values, execve() does need to distinguish, because it has arguments that are pointers-to-pointers. This turns out to be a common theme — other compat_sys_name() entry points are there to cope with pointer-to-pointer arguments (or pointer-to-struct-containing-pointer arguments, for example struct iovec or struct aiocb).
x32 ABI support
The complication of having two variant implementations of execve() spreads outward from the code to the system call tables. For x86_64, the 64-bit table has two distinct entries for execve():
59 64 execve stub_execve
...
520 x32 execve stub_x32_execve
The additional entry in the 64-bit table at syscall number 520 is for x32 ABI programs, which run on x86_64 processors but use 32-bit pointers. As a result of the 64 and x32 ABI indicators, we will end up with stub_execve as entry 59 in sys_call_table, and stub_x32_execve as entry 520.
Although this is our first mention of the x32 ABI, it turns out that our previous read() example did quietly include x32 ABI compatibility. As no pointer-to-pointer address translation was needed, the syscall invocation path (and syscall number) could simply be shared with the 64-bit version.
Both stub_execve and stub_x32_execve are defined in arch/x86/kernel/entry_64.S. These entry points call on sys_execve() and compat_sys_execve(), but also save additional registers (R12-R15, RBX, and RBP) to the kernel stack. Similar stub_* wrappers are also present in arch/x86/kernel/entry_64.S for other syscalls (rt_sigreturn(), clone(), fork(), and vfork()) that may potentially need to restart user-space execution at a different address and/or with a different user stack than when the syscall was invoked.
For x86_32, the 32-bit table has an entry for execve() that's slightly different in format from that for read():
11 i386 execve sys_execve stub32_execve
First of all, this tells us that execve() has syscall number of 11 on 32-bit systems, as compared to number 59 (or 520) on 64-bit systems. More interesting to observe is the presence of an extra field in the 32-bit table, holding a compatibility entry point stub32_execve. For a native 32-bit build of the kernel, this extra field is ignored and the sys_call_table holds sys_execve() as entry 11, as usual.
However, for a 64-bit build of the kernel, the IA-32 compatibility code inserts the stub32_execve() entry point into ia32_sys_call_table as entry 11. This entry point is defined in arch/x86/ia32/ia32entry.S as:
PTREGSCALL stub32_execve, compat_sys_execve
The
PTREGSCALL macro
sets up the stub32_execve entry point to call on to compat_sys_execve() (by putting its
address into RAX), and saves additional registers (R12-R15, RBX, and RBP) to
the kernel stack (like stub_execve() above).
gettimeofday(): vDSO
Some system calls just read a small amount of information from the kernel, and for these, the full machinery of a ring transition is a lot of overhead. The vDSO (Virtual Dynamically-linked Shared Object) mechanism speeds up some of these read-only syscalls by mapping the page containing the relevant information (and code to read it) into user space, read-only. In particular, the page is set up in the format of an ELF shared-library, so it can be straightforwardly linked into user programs.
Running ldd on a normal glibc-using binary shows the vDSO as a dependency on linux-vdso.so.1 or linux-gate.so.1 (which ldd obviously can't find a file to back); it also shows up in the memory map of a running process ([vdso] in cat /proc/PID/maps).
Historically, vsyscall was an earlier mechanism to do something similar, which is now deprecated due to security concerns. This older article by Johan Petersson describes how vsyscall's page appears as an ELF object (at a fixed position) to user space.
There's a Linux Journal article that discusses vDSO setup in some detail (although it is now slightly out of date), so we'll just describe the basics here, as applied to the gettimeofday() syscall.
First, gettimeofday() needs to access data. To allow this, the relevant vsyscall_gtod_data structure is exported into a special data section called .vvar_vsyscall_gtod_data. Linker instructions then ensure that this .vvar_vsyscall_gtod_data section is linked into the kernel in the __vvar_page section, and at kernel startup the setup_arch() function calls map_vsyscall() to set up a fixed mapping for that __vvar_page.
The code that provides the core vDSO implementation of gettimeofday() is in __vdso_gettimeofday(). It's marked as notrace to prevent the compiler from ever adding function profiling, and also gets a weak alias as gettimeofday(). To ensure that the resulting page looks like an ELF shared object, the vdso.lds.S file pulls in vdso-layout.lds.S and exports both gettimeofday() and __vdso_gettimeofday() into the page.
To make the vDSO page accessible to a new user-space program, the code in setup_additional_pages() sets the vDSO page location to a random address chosen by vdso_addr() at process start time. Using a random address mitigates the security problems found with the earlier vsyscall implementation, but does mean that the user program needs a way to find the location of the vDSO page. The location is exposed to user space as an ELF auxiliary value: the binary loader for ELF format programs (load_elf_binary()) uses the ARCH_DLINFO macro to set the AT_SYSINFO_EHDR auxiliary value. The user-space program can then find the page using the getauxval() function to retrieve the relevant auxiliary value (although in practice the libc library usually takes care of this under the covers).
For completeness, we should also mention that the vDSO mechanism is used for another important syscall-related feature for 32-bit programs. At boot time, the kernel determines which of the possible x86_32 syscall invocation mechanisms is best, and puts the appropriate implementation wrapper (SYSENTER, INT 0x80, or even SYSCALL for an AMD 64-bit processor) into the __kernel_vsyscall function. User-space programs can then invoke this wrapper and be sure of getting the fastest way into the kernel for their syscalls; see Petersson's article for more details.
ptrace(): syscall tracing
The ptrace() system call is implemented in the normal
manner, but it's particularly relevant here because it can cause system calls of the traced kernel task to behave
differently. Specifically, the PTRACE_SYSCALL request aims to "arrange for the tracee to be stopped
at the next entry to or exit from a system call
".
Requesting PTRACE_SYSCALL causes the TIF_SYSCALL_TRACE thread information flag to be set in thread-specific data (struct thread_info.flags). The effect of this is architecture-specific; we'll describe the x86_64 implementation.
Looking more closely at the assembly for syscall entry (in all of x86_32, x86_64, and ia32) we see a detail that we skipped over previously: if the thread flags have any of the _TIF_WORK_SYSCALL_ENTRY flags (which include TIF_SYSCALL_TRACE) set, the syscall implementation code follows a different path to invoke syscall_trace_enter() instead (x86_32, x86_64, ia32). The syscall_trace_enter() function then performs a variety of different functions that are associated with the various per-thread flag values that were checked for with _TIF_WORK_SYSCALL_ENTRY:
- TIF_SINGLESTEP: single stepping of instructions for ptrace
- TIF_SECCOMP: perform secure computing checks on syscall entry
- TIF_SYSCALL_EMU: perform syscall emulation
- TIF_SYSCALL_TRACE: syscall tracing for ptrace
- TIF_SYSCALL_TRACEPOINT: syscall tracing for ftrace
- TIF_SYSCALL_AUDIT: generation of syscall audit records
Epilogue
System calls have been the standard method for user-space programs to interact with Unix kernels for decades and, consequently, the Linux kernel includes a set of facilities to make it easy to define them and to efficiently use them. Despite the invocation variations across architectures and occasional special cases, system calls also remain a remarkably homogeneous mechanism — this stability and homogeneity allows all sorts of useful tools, from strace to seccomp-bpf, to work in a generic way.
Control groups, part 3: First steps to control
Having spent two articles exploring some background context concerning the grouping of processes and the challenges of hierarchies, we need to gain some understanding of control, and for that we will look at some details of the current (Linux 3.15) cgroups implementation. First on the agenda is how control is exercised in cgroups, then, in later articles, we will look at how hierarchy is used.
Some degree of control existed long before cgroups, of course, with the
"nice" setting to control how much CPU time each process received and
the various limits on memory and other resources that can be
controlled with the setrlimit() system call. However, this control
was always applied to each process individually or, possibly, to each
process in the context of the whole system. As such, those controls don't
really provide any hints on how grouping of processes affects
issues of control.
Cgroup subsystems
The cgroups facility in Linux allows for separate "subsystems" that each independently work with the groupings that cgroups provides. The term "subsystem" is unfortunately very generic. It would be nicer to use the term "resource controller" that is often applied. However, not all "subsystems" are genuinely "controllers", so we will stay with the more general term.
In Linux 3.15, there are twelve distinct subsystems which, together, can provide some useful insights into a number of issues surrounding cgroups. We will look at them roughly in order of increasing complexity; not the complexity of what is controlled, but of how the groups and, particularly, the hierarchy of groups, is involved in that control. Slightly over half will be discussed in this article with the remainder relegated to a subsequent article.
Before detailing our first seven, a quick sketch of what a subsystem can do will be helpful. Each subsystem can:
- store some arbitrary state data in each cgroup
- present a number of attribute files for each cgroup in the cgroup filesystem that can be used to view or modify this state data, or any other state details
- accept or reject a request to attach a process to a given cgroup
- accept or reject a request to create a new group as a child of an existing one
- be notified when any process in some cgroup forks or exits
Naturally, a subsystem can also interact with processes and other kernel internals in arbitrary ways in order to implement the desired result. These are just the common interfaces for interacting with the process group infrastructure.
A simple debugging aid
The debug subsystem is one of those that does not "control" anything, nor does it remove bugs (unfortunately). It does not attach extra data to any cgroup, never rejects an "attach" or "create" request, and doesn't care about forking or exiting.
The sole effect of enabling this subsystem is to make a number of internal details of individual groups, or of the cgroup system as a whole, visible via virtual files within the cgroup filesystem. Details include things like the current reference count on some data structures and the settings of some internal flags. These details are only likely to be at all interesting to someone working on the cgroups infrastructure itself.
Identity — the first step to control
It was Robert Heinlein who first exposed me to the idea that
requiring people to carry identity cards is sometimes a first step toward
controlling them. While doing this to control people may be
unwelcome, providing clear identification for controlling processes can be
quite practical and useful. This is primarily what the net_cl and
net_prio cgroup subsystems are concerned with.
Both of these subsystems associate a small identifying number with
each cgroup which is then copied to any socket created by a process in
that group. net_prio uses the sequence number that the cgroups core provides each
group with (cgroup->id) and stores this in the
sk_cgrp_prioidx attribute. This
is unique for each cgroup.
net_cl allows an identifying number to be explicitly given to each
cgroup, and stores it in the sk_classid attribute. This is
not necessarily unique
for each cgroup.
These two different group identifiers are used for three different
tasks.
-
The
sk_classidset bynet_clcan be used withiptablesto selectively filter packets based on which cgroup owns the originating socket. -
The
sk_classidcan also be used for packet classification during network scheduling. The packet classifier can make decisions based on the cgroup and other details, and these decisions can affect various scheduling details, including setting the priority of each message. -
The
sk_cgrp_prioidxis used purely to set the priority of network packets, so when used it overrides the priority set with theSO_PRIORITYsocket option or by any other means. A similar effect could be achieved usingsk_classidand the packet classifier. However, according to the commit that introduced thenet_priosubsystem, the packet classifier isn't always sufficient, particularly for data center bridging (DCB) enabled systems.
Having two different subsystems controlling sockets in three different ways, with some overlap, seems odd, though it is a little familiar from the overlap we saw with process groups previously. Whether subsystems should be of lighter weight, so it is cheap to have more (one per control element), or whether they should be more powerful, so just one can be used for all elements, is not yet clear. We will come across more overlap in later subsystems and maybe that will help clarify the issues.
For the moment, the important issue remaining is how these subsystems interact with the hierarchical nature of cgroups. The answer is that, for the most part, they don't.
Both the class ID set for net_cl and the (per-device) priorities set
for net_prio apply just to that cgroup and any sockets associated
with processes in that cgroup. They do not automatically apply to
sockets in processes in child cgroups. So, for these subsystems,
recursive membership in a group is not relevant, only immediate
membership.
This limitation is partially offset by the fact that newly created groups inherit important values from their parent. So if, for example, a particular network priority is set for all groups in some subtree of the cgroup hierarchy, then that priority will continue to apply to all groups in that subtree, even if new groups are created. In many practical cases, this is probably sufficient to achieve a useful result.
This near-disregard for hierarchy makes the cgroups tree look, from the perspective of these subsystems, more like an organizational hierarchy than a classification hierarchy (as discussed in the hierarchies article) — subgroups are not really sub-classifications, just somewhere convenient that is nearby.
Other subsystems provide more focus on hierarchy in various ways;
three worth contrasting are devices, freezer, and perf_event.
Ways of working with hierarchy
One of the challenges of big-picture thinking about cgroups is that the individual use cases can be enormously different and place different demands on the underlying infrastructure. These next three subsystems all make use of the hierarchical arrangement of cgroups, but differ in the details of how control flows from the configuration of a cgroup to the effect on a process.
devices
The devices subsystem imposes mandatory access control for some or
all accesses to device-special files (i.e. block devices and character
devices). Each group can either allow or deny all accesses by
default, and then have a list of exceptions where access is denied or
allowed, respectively.
The code for updating the exception list ensures that a child never has more permission than its parent, either by rejecting a change that the parent doesn't allow or by propagating changes to children. This means that when it comes time to perform a permission check, only the default and exceptions in one group need to checked. There is no need to walk up the tree checking that ancestors allow the access too, as any rules imposed by ancestors are already present in each group.
There is a clear trade-off here, where the task of updating the permissions is made more complex in order to keep the task of testing permissions simple. As the former will normally happen much less often than the latter, this is a sensible trade-off.
The devices subsystem serves as a mid-point in the range of options
for this trade-off. Configuration in any cgroup is pushed down to all
children, all the way down to the leaves of the hierarchy, but no further.
Individual processes still need to refer back to the relevant cgroup
when they need to make an access decision.
freezer
The freezer subsystem has completely different needs, so it
settles
on a different point in the range. This subsystem presents a
"freezer.state" file in each cgroup to which can be written
"FROZEN" or
"THAWED". This is a little bit like sending SIGSTOP or SIGCONT to
one of the process groups that we met in the first article in that
the whole group of processes is stopped or restarted. However, most of
the remaining details differ.
In order to implement the freezing or thawing of processes, the
freezer subsystem walks down the cgroup hierarchy, much like the
devices subsystem, marking all descendant groups as frozen or
thawed. Then it must go one step further. Processes do not regularly
check if their cgroup has been frozen, so freezer must walk beyond
all the descendant cgroups to all the member processes and explicitly
move them to the freezer or move them out again. Freezing is arranged
by sending a virtual signal to each process, since the signal handling
code does check if the cgroup has been marked as frozen and acts
accordingly. In order to make sure that no process escapes the
freeze, freezer requests notification when a process
forks, so it can catch newly created processes — it is the only
subsystem that does this.
So the freezer occupies one extreme of the hierarchy management
spectrum by forcing configuration all the way down the hierarchy and
into the processes. perf_event occupies the other extreme.
perf_event
The perf facility collects various performance data for some
set of processes. This set can be all processes on the system, all
that are owned by a particular user, all that descended from some
particular parent, or, using the perf_event cgroup subsystem, all
that are within some particular cgroup. The perf_event cgroup
subsystem interprets
"within" in a fully hierarchical sense — unlike net_cl which also
tests group membership but does so based on an ID number that may be
shared by some but not all groups in a subtree.
To perform this hierarchical "within a group" test, perf_event uses
the cgroup_is_descendant() function which simply walks up the
->parent links until it finds a match or the root.
While this is not an overly expensive exercise, particularly if the
hierarchy isn't very deep, it is certainly more expensive than simply
comparing two numbers. The developers of the networking code are
famous for being quite sensitive to added performance costs,
particularly if these costs could apply to every packet. So it is not
surprising that the networking code does not use
cgroup_is_descendant().
The ideal, of course, would be a mechanism for testing membership that was both fully hierarchical and also highly efficient. Such a mechanism is left as an exercise for the reader.
For perf, we can see that configuration is never pushed down the
hierarchy at all. Whenever a control decision is needed (i.e. should this event
be counted?), the code
walks up the tree from a process to find the answer.
If we look back to net_cl and net_perf and ask exactly how they
fit into this spectrum that contrasts pushing configuration down from cgroups
with processes reaching up to receive control, they are most like
devices. Processes do refer back to a single cgroup when
creating a socket, but don't proceed up the hierarchy. Their distinction
is that the pushing-down of
configuration is left up to user space rather than being imposed by
the kernel.
cpuset: where it all began
The final cgroup subsystem to examine for this installment is cpuset,
which was the first one to be added to Linux. In fact, the
cpuset mechanism for controlling process groups predates the more
generic cgroups implementation. One reminder of this is that there is
a distinct cpuset virtual filesystem type that is equivalent to the
cgroup virtual filesystem when configured with the
cpuset subsystem. This subsystem doesn't really introduce anything new, but it does
serve to emphasize some aspects we have already seen.
The
cpuset cgroup subsystem is useful on any machine with multiple CPUs, and particularly
on NUMA machines, which feature multiple nodes and, often, wildly different speeds
for access within and between nodes. Like net_cl,
cpuset provides two distinct, but related, controls.
It identifies a set of processors on which each process in a group may
run, and it also identifies a set of memory nodes from which processes
in a group can allocate memory. While these sets may often be the
same, the implementation keeps them completely separate; enforcing
the sets involves two completely different approaches. This is most
obvious when moving a process from one cgroup to another. If the set
of allowed processors is different, the process can trivially be placed
on the run queue for a new processor on which it is permitted. If the
set of allowed memory nodes has changed, then migrating all the memory
across from one node to another is far from trivial (consequently this
migration is optional).
Similar to the device subsystem, cpuset propagates any changes
made to a parent into all descendants when appropriate. Unlike
device, where the cgroup contained the authoritative control
information, each process has its own CPU set that the scheduler
inspects. Once changes are imposed on descendant groups, cpuset
must take the same final step as freezer and impose the new settings
on individual processes. Exactly why cpuset doesn't request
notification of forks, while freezer does, will have to remain a mystery.
Combined with this, cpuset will sometimes also walk up the
hierarchy looking for an appropriate parent. One such case is when a
process finds itself in a cgroup that has no working CPU in its
set, possibly due to a CPU being taken offline. Another is when a
high-priority memory allocation finds that all nodes in the
mems_allowed set have exhausted their free memory. In both these
cases, some borrowing of resources that are granted to ancestor nodes
can be used to get out of a tight spot.
Both of these cases could conceivably be handled by maintaining an
up-to-date set of "emergency" processors and memory nodes in each cgroup. It is likely that the complexity of keeping this extra
information current outweighs the occasional cost of having to
search up the tree to find a needed resource. We saw before that some
subsystems will propagate configuration down the tree while others
will search for permission up the tree. Here we see that cpuset
does both, each as appropriate to a particular need.
The story so far
These seven cgroup subsystems have something in common that separates them from the five we will look at in the next article, and this difference relates to accounting. For the most part, these seven cgroup subsystems do not maintain any accounting, but provide whatever service they provide with reference only to the current instant and without reference to any recent history.
perf_event doesn't quite fit this description as it does record some
performance data for each group of processes, though this data is
never used to impose control. There is still a very clear difference
between the accounting performed by perf_event and that performed by
the other five subsystems, but we will need to wait until next time to
clarify that difference.
Despite that commonality, there is substantial variety:
- Some actually impose control (
devices,freezer,cpuset), while others provide identification to enable separate control (net_cl,net_prio) and still others aren't involved in control at all (debug,perf_event). - Some (
devices) impose control by requiring the core kernel code to check with the cgroup subsystem for every access, while others (cpuset,net_cl) impose settings on kernel objects (threads, sockets) and the relevant kernel subsystems take it from there. - Some handle hierarchy by walking down the tree imposing on children, some by walking up the tree checking on parents, some do both and some do neither.
There is not much among these details that relates directly to the various issues we found in hierarchies last time, though the emphasis on using cgroups to identify processes perhaps suggests that classification rather than an organization is expected.
One connection that does appear is that, as these subsystems do not
depend on accounting, they do not demand a strong hierarchy. If there
is a need to use net_prio to set the priority for a number of
cgroups and they don't all have a common parent, that need not be a
problem. The same priorities can simply be set on each group that
needs them. It would even be fairly easy to automate this if some rule
could be given to identify which groups required the setting. We have
already seen that net_prio and net_cl require consistent initial
settings to behave as you might expect, and this simply extends that
requirement a little.
So, for these subsystems at least, there is a small leaning toward wanting a classification hierarchy, but no particular desire for multiple hierarchies.
Looking further back to the issues that process groupings raised, we see there continue to be blurred lines of demarcation, with different subsystems providing similar services, and distinct services being combined in the same subsystem. We also see that naming of groups is important, but apparently not trivial, as we potentially have two different numeric identifiers for each cgroup.
Of course we haven't finished yet. Next time we will look at the
remaining subsystems: cpu, cpuacct, blkio, memory, and
hugetlb, to see what they can teach us, and what sort of
hierarchies might best suit them.
Filesystem notification, part 2: A deeper investigation of inotify
In the first article in this series, we briefly looked at the original Linux filesystem notification API, dnotify, and noted a number of its limitations. We then turned our attention to its successor, inotify, and saw how the design of the newer API addressed various problems with the dnotify API while providing a number of other benefits as well. At first glance, inotify seems to provide a complete solution for the task of creating an application that reliably monitors the state of a filesystem. However, we are about to see that this isn't quite the case.
So, now we dig deeper into the use of inotify, looking at how the API can be used to create an application that monitors the dynamic state of a directory tree. Our goals are, on the one hand, to demonstrate how inotify can be used to robustly achieve this task and, on the other hand, to discover some of the challenges inherent in the task, and thereby discover some of the limitations of inotify.
Our application, inotify_dtree.c, serves as a proof-of-concept, rather than performing any practical task. It is invoked with a command of the following form:
./inotify_dtree <directory> <directory>...
The goal of the application is to robustly and accurately maintain an internal representation ("a cache") of the dynamically changing set of subdirectories under each of the directories named in its command line. This is somewhat similar to the task of programs such as GUI file managers, which must present the user with an accurate representation of (some part of) a filesystem tree.
In addition to caching the state of the directory trees, the program also provides a command-line interface that allows the user to do such things as dumping the contents of the cache and triggering a consistency check of the cache against the current state of the directory trees.
In order to keep the program to a manageable size, we make a number of simplifications:
- The application caches only the subdirectories under a directory tree. Other types of files are ignored. Caching other file types is reasonably straightforward, but we focus on monitoring subdirectories because they are the most challenging part of the problem.
- For each directory, the only information we cache is the directory name and the corresponding watch descriptor. In a real-world application, we might want to cache other information as well, such as file ownership, permissions, and last modification time.
- The cache data structure is simply a list (a dynamically allocated array of structures that is resized as needed). The list is searched linearly by pathname or watch descriptor. This allows a simple implementation, at the expense of efficiency. In a real-world application, we might instead elect to use a tree data structure whose form matches the directory tree.
Even with these simplifications, we will see that programming with inotify presents a number of challenges.
Challenge 1: recursively monitoring a directory tree
Inotify does not perform recursive monitoring of directories. If we monitor the directory mydir, then we will receive events for the directory itself and for its immediate children, but not for children of subdirectories.
Therefore, in order to monitor an entire directory tree, we must create a watch for each subdirectory in the tree. This requires a recursive process whereby, for each directory, we create a watch and scan for subdirectories that should also be watched. The fun starts when we consider some of the possible race conditions. For example, suppose that we handle the tasks in the following order:
- We scan mydir, adding watches for the subdirectories that we find.
- We add a watch for mydir.
Suppose that between these two steps, a new subdirectory, mydir/new, is created (or a directory is renamed into mydir). No watch will be created for that directory, since, on the one hand, it was created after the scan of subdirectories, and, on the other hand, it will not generate an event for inotify, because it was created before a watch was added for the directory mydir.
The solution is to ensure that we perform the above steps in the reverse order, first creating a watch for the parent directory, and then scanning for subdirectories. If a new subdirectory is created between these two steps, then it might both generate an inotify event and be caught by the scanning step, which may result in a watch being created twice for the subdirectory. However, with careful programming, this is harmless, since repeated inotify_add_watch() calls for the same filesystem object will generate the same watch descriptor number.
There are other race conditions to consider as well. For example, during the scanning step we may find a subdirectory and attempt to add a watch for it, only for the inotify_add_watch() call to fail because the directory has already been deleted or renamed. The correct approach in such cases is to silently ignore the error.
The standard nftw() library function can assist with the task of creating a watch list for an entire directory tree. nftw() performs a traversal (preorder by default) of all of the files in a directory, calling a user-defined function once for each file. Among the arguments supplied to that function are the pathname of the file being visited and a stat structure containing attributes of that file, including the file type.
Here's an edited version of our function that is called by nftw() as it recursively traverses a directory tree that we want to add to the cache:
static int
traverseTree(const char *pathname, const struct stat *sb, int tflag,
struct FTW *ftwbuf)
{
int wd, slot, flags;
if (! S_ISDIR(sb->st_mode))
return 0; /* Ignore nondirectory files */
flags = IN_CREATE | IN_MOVED_FROM | IN_MOVED_TO | IN_DELETE_SELF;
if (isRootDirPath(pathname))
flags |= IN_MOVE_SELF;
wd = inotify_add_watch(ifd, pathname, flags | IN_ONLYDIR);
A few points in the above code warrant explanation. The S_ISDIR() check allows us to skip non-directory files. We initialize the inotify_add_watch() flags argument with the set of flags that are relevant for monitoring the creation, renaming, and deletion of directories.
Our isRootDirPath() function returns true if the given path is one of those supplied on the command line. For these directories, we are interested in events that rename the directories themselves, so we include the IN_MOVE_SELF flag. When an IN_MOVE_SELF event is processed, the program ceases monitoring the corresponding directory and all of its subdirectories.
The IN_ONLYDIR flag causes inotify_add_watch() to check that the monitored file is a directory. Although we already checked (via the S_ISDIR() macro) that pathname is a directory, there is a chance that in the meantime the directory was deleted and a regular file with the same name was created. In other words, IN_ONLYDIR provides us with a race-free way of ensuring that a monitored object is a directory.
The remainder of the function handles the consequences of the various race conditions described earlier, and then caches the new watch descriptor and pathname:
if (wd == -1) {
/* By the time we come to create a watch, the directory might
already have been deleted or renamed, in which case we'll get
an ENOENT error. In that case, we log the error, but
carry on execution. Other errors are unexpected, and if we
hit them, we give up. */
logMessage(VB_BASIC, "inotify_add_watch: %s: %s\n",
pathname, strerror(errno));
if (errno == ENOENT)
return 0;
else
exit(EXIT_FAILURE);
}
if (findWatch(wd) > 0) {
/* This watch descriptor is already in the cache;
nothing more to do. */
logMessage(VB_BASIC, "WD %d already in cache (%s)\n", wd, pathname);
return 0;
}
slot = addWatchToCache(wd, pathname);
return 0;
}
Challenge 2: handling overflow events
Queueing inotify events until they are read requires kernel memory. Therefore, the kernel imposes a per-queue limit on the number of events that can be queued. (The various inotify limits are exposed, and can, with privilege, be modified via /proc files, as described in the inotify(7) man page.) When this queue limit is reached, the kernel adds an inotify overflow event (IN_Q_OVERFLOW) to the event queue and then discards further events until the application has drained some events from the queue.
This behavior has a number of implications. First of all, it means that when an overflow situation occurs, the application loses information about filesystem events. Or, to put things another way, inotify can't be used to produce a completely accurate log of filesystem activity.
Overflow events also have implications for applications such as our example application. Once an overflow occurs, the cache state in our application is no longer synchronized with the filesystem state. Furthermore, even if we drain the inotify event queue so that future events can be queued, we are likely to encounter problems because some of those events will likely be inconsistent with the now-out-of-sync cache. In this circumstance, there is only one thing to do: close the inotify file descriptor, discard the existing cache, open a new inotify file descriptor and then repopulate the cache and re-create all of our watch descriptors by rescanning the monitored directories. This may take some time, if we are monitoring a large number of directories. These steps are handled in the reinitialize() function of our example application.
Although the inotify queue limit can be raised in order to make overflow events less likely, there nevertheless always remains a risk that the limit will be hit in an application. Therefore, all inotify applications must be written to properly handle overflow events.
In passing, it's worth noting that unexpected corner cases or program bugs also may cause an application cache to become inconsistent with the state of the filesystem. A robust application should allow for this possibility: if such inconsistencies are detected, it is probably necessary to take the same steps as for the queue overflow case.
Challenge 3: handling rename events
As noted in our previous article, inotify provides much better support than dnotify for monitoring rename events. When a filesystem object is renamed, two events are generated: an IN_MOVED_FROM event for the source directory from which the file is moved, and an IN_MOVED_TO for the target directory to which the file is moved. Those events are only generated for directories that are being watched, so an application will only get both if it is monitoring both the source and destination. The name fields of these two events provide the old and new names of the file. The two events will have the same (unique) value in their cookie field, which provides an application with the means to connect them.
![[Directory tree example for inotify]](https://static.lwn.net/images/2014/inotify_dir_example.png) Rename events present a number of challenges. One of these is
that, depending how we cache pathnames, a rename event may affect
multiple items in the cache. For example, in our application, each
item in the cache consists of a watch descriptor plus the complete
pathname string corresponding to that watch descriptor. Suppose
that we had a subtree containing the directories shown in the
diagram to the right.
Rename events present a number of challenges. One of these is
that, depending how we cache pathnames, a rename event may affect
multiple items in the cache. For example, in our application, each
item in the cache consists of a watch descriptor plus the complete
pathname string corresponding to that watch descriptor. Suppose
that we had a subtree containing the directories shown in the
diagram to the right.
If the directory abc was renamed to def under directory xyz, then three pathname strings inside our cache would need to be modified (so, for example, mydir/abc/man would become mydir/xyz/def/man).
More sophisticated cache designs may mitigate or eliminate this problem. For example, if the cache employs a tree data structure that mirrors the structure of the directory tree, and each node contains just the filename (rather than the full pathname) of the corresponding filesystem object, then only a single cache object would be affected by a rename (it would be relocated inside the tree structure, and its pathname string would be modified).
Rename events present other, more serious challenges, however. First, it's important to note that the IN_MOVED_FROM and IN_MOVED_TO events are generated only if, respectively, the source and target directories are each in the set being monitored by our inotify file descriptor. If only the target directory is in the set, then we will receive only an IN_MOVED_TO event. This can be dealt with straightforwardly: it is the same as the case of (recursively) adding a complete subtree to the set of watch subtrees.
On the other hand, if only the source directory is in the monitored set, then only an IN_MOVED_FROM event is generated. Notionally, this can be treated like a deletion event: for all of the monitored objects in the renamed subtree, we destroy each of the corresponding objects in our cache and destroy each of the watch descriptors using inotify_rm_watch().
However, there is a problem: when we receive an IN_MOVED_FROM event, we do not yet know if there will be a following IN_MOVED_TO event. In other words, we do not yet know whether to treat this as a deletion event or as a "true rename" event. And it gets worse. If there are multiple processes generating events in the monitored trees, then there is no guarantee that, for a true rename event, the IN_MOVED_FROM and IN_MOVED_TO events will be returned as consecutive items in the buffer of events returned when reading from the inotify file descriptor; other events may be returned between the pair. The upshot is that when we encounter an IN_MOVED_FROM event, we need to do some measure of forward searching to see if there is a corresponding IN_MOVED_TO event.
At this point, one might ask: rather than going to the effort of detecting whether there is an event pair, why not simply always treat IN_MOVED_FROM as a deletion event and IN_MOVED_TO as a creation event? This approach simplifies the programming in some respects, but it has some costs. If this is a true rename event, then we will waste effort in deleting items from our cache and destroying watch descriptors only to immediately repopulate the cache with the same filesystem objects and re-create a new set of watch descriptors. If the subtree that is being renamed is large, this may be rather expensive. Furthermore, when the watches are re-created they will use different watch descriptors. This means that there may be a series of events ahead in the inotify queue that contain watch descriptors that no longer exist. The simplest thing to do with these events is to discard them.
Because of the problems described in the previous paragraph, it is usually worth going to some effort to detect whether there is an IN_MOVED_TO that matches the IN_MOVED_FROM. The only question is: how much effort do we make? It turns out that even on a busy filesystem where multiple processes are generating events, the two events are almost always consecutive. So, a simple approach when encountering IN_MOVED_FROM is to check whether the very next event is IN_MOVED_TO, in which case this can be treated as a true rename, otherwise the IN_MOVED_FROM can be treated as a deletion event. Occasionally, we will fail to detect true renames because the events are not consecutive, in which case we fall back to the situation described in the preceding paragraph.
However, even when performing this simplified detection of IN_MOVED_FROM+IN_MOVED_TO pairs, some care is required. A read() from an inotify descriptor will (given a sufficiently large buffer) return multiple events if they are available. This means that, generally, if there is a true rename operation, the IN_MOVED_FROM and IN_MOVED_TO events will be read in the same buffer. However, it may happen that only the IN_MOVED_FROM can fit at the end of the buffer returned by one read() and the IN_MOVED_TO event is fetched by the next read(). The application should deal with this possibility.
It is also possible, of course, that there is no following IN_MOVED_TO, and indeed there might not (for the moment) be any more events at all. Furthermore, from the point of view of user space, the IN_MOVED_FROM+IN_MOVED_TO pair that is generated by a rename is not inserted atomically into the event queue: this means that having read an IN_MOVED_FROM from the queue, the following IN_MOVED_TO may not yet be available if we try to immediately fetch it with a nonblocking read(). Therefore, the second read() that tries to fetch the possibly following IN_MOVED_TO event must be performed with a (small) timeout.
The processInotifyEvents() function in our example application provides one example of how to do this. It employs a 2-millisecond timeout for the second read(), which was found to be sufficient to catch around 99.8% of the true renames even when the monitored directory tree was subject to a high level of rename activity.
For the purposes of testing, I created a test program, rand_dtree.c, that randomly performs either subdirectory creations, subdirectory deletions, or subdirectory renames at a specified location. During testing, I simultaneously ran ten instances of the program in rename mode against a directory tree that contained approximately 200 subdirectories.
A similar timeout technique is used in the inotify-kernel.c source file of the GIO library in GLib, where a 0.5 millisecond timeout is used. In my tests, this was sufficient to detect true renames with only 95% accuracy.
Challenge 4: using pathnames for notifications
When an event is generated for an object inside a monitored directory, inotify produces an event containing the name of the file. This is more information than given to us by dnotify. However, notification via pathname has some difficulties. The problem is that pathnames exist independently of filesystem objects. (One must also bear in mind that a filesystem object may have multiple pathnames, since a file can have multiple hard links.) Thus, by the time we read a notification that contains a filename, that filename may already have been deleted or renamed. Applications must be designed to handle this possibility.
![[Two files that link to the same inode]](https://static.lwn.net/images/2014/inotify_links.png)
Notification via pathname also produces some other oddities. Suppose that a filesystem object has two links, one inside a directory (mydir/abc) that we are monitoring for all possible events via inotify, and another link inside a directory (mydir/xyz) that we are not monitoring, as shown in the diagram to the right.
If the inode 5139 is opened via the link mydir/abc/x1, then an event will be generated. On the other hand, if it is opened via mydir/xyz/x2, no event is generated. More generally, inotify events are generated for files only when they occur via pathnames that are in the monitored set. This behavior is not the consequence of a kernel limitation, but rather is a limitation of the notification method. In some circumstances, notifying the application about an event that occurred via one pathname using a different pathname would be confusing. For example, suppose that the pathname mydir/xyz/x2 was deleted, how should an IN_DELETE event for mydir/abc/x1 be interpreted? A similar question can be asked about rename events. To avoid these sorts of confusions, inotify only notifies events that occur via pathnames in the monitored set.
Other limitations of the inotify API
In addition to the various challenges dealt with by our example application, there are several other limitations of the inotify API that an application may encounter:
- Event notifications do not include information about the process that generated the event. Nevertheless, it would sometimes be useful to have the process ID and user ID of the triggering process. One particularly notable case is that if a monitoring application itself touches files inside the monitored directories, then it may also generate events, but it has no way (for example, a PID) to distinguish those events from events generated by other processes.
- Inotify does not provide any gatekeeping functionality. That is to say, inotify only informs us about filesystem activity; it provides no way to block filesystem actions by other processes. This type of functionality is needed by antivirus software and some types of user-space file servers, for example.
- Inotify reports only events that a user-space program triggers through the filesystem API. This constitutes a fairly serious limitation of the API. For example, it means that inotify does not inform us of events on monitored objects via a remote filesystem (e.g. NFS) operation. Likewise, no events are generated for virtual filesystems such as /proc. Furthermore, events are not generated for file accesses and modifications that may occur via file mappings created using mmap(). To discover changes that occur via these mechanisms, an application must revert to polling the filesystem using stat() and readdir().
Inotify improves on dnotify in many respects. However, a number of limitations of the API mean that reliably monitoring filesystem events still presents quite a challenge. In the next article in this series, we will consider the fanotify API, which, although more restricted than inotify in its range of applications, addresses some of the limitations of inotify.
Patches and updates
Kernel trees
Architecture-specific
Build system
Core kernel code
Development tools
Device drivers
Device driver infrastructure
Filesystems and block I/O
Janitorial
Memory management
Networking
Security-related
Miscellaneous
Page editor: Jonathan Corbet
Next page:
Distributions>>