
LWN.net Weekly Edition for October 25, 2007
A potential competitor for GCC: pcc
A C compiler with a long history in the BSD world has recently been imported into the package repositories of the major BSD variants. There are thoughts that it may, perhaps, replace GCC for BSD development some day. A competitor to GCC might be very well received in some parts of the Linux community, as well – grumbling about the compiler, its speed, and the code it generates have been heard for some time.
The Portable C Compiler (pcc) came from Bell Labs in the 1970s and shipped with 4.3BSD-Reno. It was eventually replaced by GCC in 4.4BSD, but it is a much simpler compiler than GCC, while still targeting many architectures. More recently, most of the compiler has been rewritten by Anders Magnusson and others. It will currently compile many of the BSD userspace programs, even linking to libraries compiled with GCC. It is also available in RPM format for Fedora Core 6 and Fedora 7.
Interestingly, pcc has Caldera copyrights as part of its license; well
before they became the SCO Group and sued their way into pariah-dom,
Caldera released "ancient Unices" under a BSD license. pcc is BSD-licensed
as well, which has some obvious attraction for the BSD world, but licensing
is not the primary motivation. The reasons for working on an alternative
compiler are more complex, with OpenBSD leader Theo de Raadt saying that one
of the reasons is
"fighting against an open source monopoly
".
There are several big issues with GCC for the BSDs, but regularly breaking support for architectures that they still use seems to be one of the biggest. The feeling is that GCC concentrates on Linux for x86 and PowerPC to the detriment of other operating systems and CPUs. By having a compiler whose developers are more aligned with the goals of the BSD family, those kinds of problems can be avoided.
The GCC development process can be politicized and difficult for developers – the GNU coding standard can be a real barrier for example. Each new release comes with its set of new features, but with new bugs, especially in the optimizer, that make it difficult to adopt. Supporting multiple GCC versions for a codebase can be an enormous headache. Marc Espie, GCC maintainer for OpenBSD, outlines multiple frustrations with GCC while advocating a new compiler.
The speed of compilation is another area that GCC is criticized for. With each new release, GCC is typically slower, sometimes much slower, in doing its job. Currently pcc is five to ten times faster – a big difference for developers who are constantly recompiling code.
Some of the complaints are reminiscent of those that led to the GCC/ECGS fork, but instead of forking, the BSD folks are investigating an entirely different codebase. Another big barrier to developer involvement in GCC coding is its complexity. GCC is huge and quite daunting to someone who just wants to start hacking on a compiler. It is also difficult to audit for security, one of the hallmarks of the OpenBSD project. pcc is small, easier to understand and audit.
GCC is an important piece of the free software world, it has been for decades and will be for more in the future. It has enabled most of the software we use every day and for that we should be grateful to the GNU project and the GCC developers. It is not without its warts, however; a competitor might just bring about some changes.
pcc is still a long way from supplanting GCC, even in places that would like to see it happen soon. It will be interesting to see – and good for both Linux and the BSDs – if pcc can get to the point of being a viable competitor. Some worry about forks and multiple projects with similar goals (i.e. GNOME and KDE) because they may dilute the efforts of each branch, but that concern has proven to be largely unfounded. Either the technically superior project wins out, or they all coexist more or less happily.
de Raadt is right to be concerned about monopolies, free software or otherwise. Two – or more, see the LLVM project for another option – C compilers can only be good for the free software world. A variety of approaches to both code and project governance allows more participation by more developers. If some day pcc is clearly the superior choice, GCC will change or fade away. That is free software Darwinism at its best.
The state of Mozilla
For those who have not yet seen it, the "Beyond Sustainability" report by Mozilla CEO Mitchell Baker is worth a read. This document provides an overview of the state of the Mozilla project from a few different points of view. Some of the highlights are:
- Mozilla brought in $66.8 million in 2006, while spending less
than $20 million. As a result, Mozilla is putting aside some
nice piles of cash; total assets at the end of 2006 were just over
$74 million.
- Expenditures were mostly on software development ($12 million),
but Mozilla also spent almost $5 million on sales and marketing.
$300,000 was donated to various community efforts, a number which is
expected to grow significantly in 2007.
- Interest in the software remains strong: toward the end of 2006
Mozilla was serving 600,000 Firefox downloads - every day.
- The development community appears to be growing, with "over 1000" people contributing code to Firefox 2. Only 50 of those people are employed by Mozilla. The Mozilla community may not yet be up to the size of the Linux kernel, but it is clearly one of the largest and most active development communities out there.
There are a number of interesting things to ponder in this announcement. Many of them tie back to one core point: 85% of Mozilla's 2006 revenue came from Google. Of the rest, a significant amount was interest earned on Mozilla's money stash. So Google must clearly have a high degree of influence over what goes on at Mozilla Corp. Even if Google sticks to its "don't be evil" mantra, questions will be asked.
A classic example would be the recent decision to push the Thunderbird mail client out of the nest to fend for itself. It does not take too much imagination to see a conflict of interest between promotion of Thunderbird and Google's Gmail service. It would not be surprising if Google did not want its money going to pay for the development of a project which could be seen as competing with its own offerings. The claim is that Google has nothing to do with the decision to spin off Thunderbird, and it could well be true. But there will always be cause to wonder - though the recent addition of IMAP service to Gmail can only serve to lessen any conflict of interest with Thunderbird.
Mitchell's posting talks about the influence Mozilla has had in the restoration of a standards-based Internet. That can only be true; the net (and the world wide web in particular) was clearly going in a proprietary direction before Firefox brought competition back to the browser arena. Your editor, who once relied heavily on the user agent switcher extension, now cannot remember when its use was last required. In this regard, Mozilla has clearly been a beneficial force for the free software community, and for the net as a whole.
That result, perhaps, has been the biggest outcome that Google will have sought from its financing of Mozilla. Google depends on an open net for its business.
The posting also makes this claim:
While getting free software onto all of those Windows desktops must be a good thing, it is not clear how many of them are really learning anything about free software in the process. Meanwhile, there is a steady stream of grumbling about how Mozilla seems to have forgotten Linux in its drive to colonize Windows desktops. Integration with Linux distributions is not always as good as one would like, Mozilla's security update and support policies are not distributor-friendly, the trademark policy is obnoxious, and so on. These issues would not appear to have kept distributors from shipping Firefox or users from running it, though.
One potential issue, as Don Marti pointed out, is that this growing pile of money cannot fail to attract the attention of patent trolls. A body of software as large and complex as Firefox must inevitably violate no end of software patents given the ease with which those patents are obtained in the U.S. There is probably trouble ahead in this regard, though that remains true for much of the commercial free software community in general.
One other future concern is what happens when the current contract with Google expires - next year. Perhaps it will simply be extended and business as normal will continue. Or perhaps Google will conclude that the goal of re-opening the web has succeeded, that Firefox users are highly likely to use Google's services anyway, and that there is no great need to send as much money in that direction. A project which spends over $2 million in administrative overhead cannot handle the loss of a large part of its funding without significant changes.
What a lot of this comes down to is one single subject which was not addressed in this report: if Mozilla is to continue to grow, be sustainable, and be independent in the future, it needs to diversify its income stream. Any business (and Mozilla Corp. is certainly a business) which is dependent on a single customer is in a risky position. Your editor is in no position to say how that diversification should be done - that's Ms. Baker's job. But it is easy to say that the effort which has so spectacularly driven the web toward open standards and free software would be in a better position to drive the next big set of changes if it stood on a wider base.
Memory part 5: What programmers can do
[Editor's note: welcome to part 5 of Ulrich Drepper's "What every programmer should know about memory". This part is the first half of section 6, which discusses what programmers can do to improve the memory performance of their code. Part 1, part 2, part 3, and part 4 remain online for those who have not yet read them.]
6 What Programmers Can Do
After the descriptions in the previous sections it is clear that there are many, many opportunities for programmers to influence a program's performance, positively or negatively. And this is for memory-related operations only. We will proceed in covering the opportunities from the ground up, starting with the lowest levels of physical RAM access and L1 caches, up to and including OS functionality which influences memory handling.
6.1 Bypassing the Cache
When data is produced and not (immediately) consumed again, the fact that memory store operations read a full cache line first and then modify the cached data is detrimental to performance. This operation pushes data out of the caches which might be needed again in favor of data which will not be used soon. This is especially true for large data structures, like matrices, which are filled and then used later. Before the last element of the matrix is filled the sheer size evicts the first elements, making caching of the writes ineffective.
For this and similar situations, processors provide support for non-temporal write operations. Non-temporal in this context means the data will not be reused soon, so there is no reason to cache it. These non-temporal write operations do not read a cache line and then modify it; instead, the new content is directly written to memory.
This might sound expensive but it does not have to be. The processor will try to use write-combining (see Section 3.3.3) to fill entire cache lines. If this succeeds no memory read operation is needed at all. For the x86 and x86-64 architectures a number of intrinsics are provided by gcc:
#include <emmintrin.h> void _mm_stream_si32(int *p, int a); void _mm_stream_si128(int *p, __m128i a); void _mm_stream_pd(double *p, __m128d a); #include <xmmintrin.h> void _mm_stream_pi(__m64 *p, __m64 a); void _mm_stream_ps(float *p, __m128 a); #include <ammintrin.h> void _mm_stream_sd(double *p, __m128d a); void _mm_stream_ss(float *p, __m128 a);
These instructions are used most efficiently if they process large amounts of data in one go. Data is loaded from memory, processed in one or more steps, and then written back to memory. The data “streams” through the processor, hence the names of the intrinsics.
The memory address must be aligned to 8 or 16 bytes respectively. In code using the multimedia extensions it is possible to replace the normal _mm_store_* intrinsics with these non-temporal versions. In the matrix multiplication code in Section 9.1 we do not do this since the written values are reused in a short order of time. This is an example where using the stream instructions is not useful. More on this code in Section 6.2.1.
The processor's write-combining buffer can hold requests for partial writing to a cache line for only so long. It is generally necessary to issue all the instructions which modify a single cache line one after another so that the write-combining can actually take place. An example for how to do this is as follows:
#include <emmintrin.h>
void setbytes(char *p, int c)
{
__m128i i = _mm_set_epi8(c, c, c, c,
c, c, c, c,
c, c, c, c,
c, c, c, c);
_mm_stream_si128((__m128i *)&p[0], i);
_mm_stream_si128((__m128i *)&p[16], i);
_mm_stream_si128((__m128i *)&p[32], i);
_mm_stream_si128((__m128i *)&p[48], i);
}
Assuming the pointer p is appropriately aligned, a call to this function will set all bytes of the addressed cache line to c. The write-combining logic will see the four generated movntdq instructions and only issue the write command for the memory once the last instruction has been executed. To summarize, this code sequence not only avoids reading the cache line before it is written, it also avoids polluting the cache with data which might not be needed soon. This can have huge benefits in certain situations. An example of everyday code using this technique is the memset function in the C runtime, which should use a code sequence like the above for large blocks.
Some architectures provide specialized solutions. The PowerPC architecture defines the dcbz instruction which can be used to clear an entire cache line. The instruction does not really bypass the cache since a cache line is allocated for the result, but no data is read from memory. It is more limited than the non-temporal store instructions since a cache line can only be set to all-zeros and it pollutes the cache (in case the data is non-temporal), but no write-combining logic is needed to achieve the results.
To see the non-temporal instructions in action we will look at a new test which is used to measure writing to a matrix, organized as a two-dimensional array. The compiler lays out the matrix in memory so that the leftmost (first) index addresses the row which has all elements laid out sequentially in memory. The right (second) index addresses the elements in a row. The test program iterates over the matrix in two ways: first by increasing the column number in the inner loop and then by increasing the row index in the inner loop. This means we get the behavior shown in Figure 6.1.
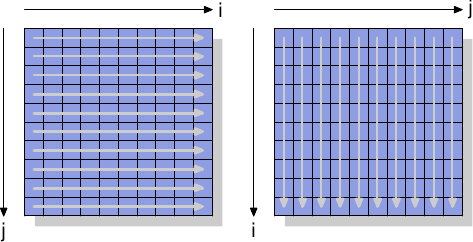
Figure 6.1: Matrix Access Pattern
We measure the time it takes to initialize a 3000×3000 matrix. To see how memory behaves, we use store instructions which do not use the cache. On IA-32 processors the “non-temporal hint” is used for this. For comparison we also measure ordinary store operations. The results can be seen in Table 6.1.
Inner Loop Increment Row Column Normal 0.048s 0.127s Non-Temporal 0.048s 0.160s Table 6.1: Timing Matrix Initialization
For the normal writes which do use the cache we see the expected result: if memory is used sequentially we get a much better result, 0.048s for the whole operation translating to about 750MB/s, compared to the more-or-less random access which takes 0.127s (about 280MB/s). The matrix is large enough that the caches are essentially ineffective.
The part we are mainly interested in here are the writes bypassing the cache. It might be surprising that the sequential access is just as fast here as in the case where the cache is used. The reason for this behavior is that the processor is performing write-combining as explained above. Additionally, the memory ordering rules for non-temporal writes are relaxed: the program needs to explicitly insert memory barriers (sfence instructions for the x86 and x86-64 processors). This means the processor has more freedom to write back the data and thereby using the available bandwidth as well as possible.
In the case of column-wise access in the inner loop the situation is different. The results are significantly slower than in the case of cached accesses (0.16s, about 225MB/s). Here we can see that no write combining is possible and each memory cell must be addressed individually. This requires constantly selecting new rows in the RAM chips with all the associated delays. The result is a 25% worse result than the cached run.
On the read side, processors, until recently, lacked support aside from weak hints using non-temporal access (NTA) prefetch instructions. There is no equivalent to write-combining for reads, which is especially bad for uncacheable memory such as memory-mapped I/O. Intel, with the SSE4.1 extensions, introduced NTA loads. They are implemented using a small number of streaming load buffers; each buffer contains a cache line. The first movntdqa instruction for a given cache line will load a cache line into a buffer, possibly replacing another cache line. Subsequent 16-byte aligned accesses to the same cache line will be serviced from the load buffer at little cost. Unless there are other reasons to do so, the cache line will not be loaded into a cache, thus enabling the loading of large amounts of memory without polluting the caches. The compiler provides an intrinsic for this instruction:
#include <smmintrin.h> __m128i _mm_stream_load_si128 (__m128i *p);
This intrinsic should be used multiple times, with addresses of 16-byte blocks passed as the parameter, until each cache line is read. Only then should the next cache line be started. Since there are a few streaming read buffers it might be possible to read from two memory locations at once.
What we should take away from this experiment is that modern CPUs very nicely optimize uncached write and (more recently) read accesses as long as they are sequential. This knowledge can come in very handy when handling large data structures which are used only once. Second, caches can help to cover up some—but not all—of the costs of random memory access. Random access in this example is 70% slower due to the implementation of RAM access. Until the implementation changes, random accesses should be avoided whenever possible.
In the section about prefetching we will again take a look at the non-temporal flag.
6.2 Cache Access
The most important improvements a programmer can make with respect to caches are those which affect the level 1 cache. We will discuss it first before including the other levels. Obviously, all the optimizations for the level 1 cache also affect the other caches. The theme for all memory access is the same: improve locality (spatial and temporal) and align the code and data.
6.2.1 Optimizing Level 1 Data Cache Access
In section Section 3.3 we have already seen how much the effective use of the L1d cache can improve performance. In this section we will show what kinds of code changes can help to improve that performance. Continuing from the previous section, we first concentrate on optimizations to access memory sequentially. As seen in the numbers of Section 3.3, the processor automatically prefetches data when memory is accessed sequentially.
The example code used is a matrix multiplication. We use two square matrices of 1000×1000 double elements. For those who have forgotten the math, given two matrices A and B with elements aij and bij with 0 ≤ i,j < N the product is
![[formula]](https://static.lwn.net/images/cpumemory/matrixmult.png)
A straight-forward C implementation of this can look like this:
for (i = 0; i < N; ++i)
for (j = 0; j < N; ++j)
for (k = 0; k < N; ++k)
res[i][j] += mul1[i][k] * mul2[k][j];
The two input matrices are mul1 and mul2. The result matrix res is assumed to be initialized to all zeroes. It is a nice and simple implementation. But it should be obvious that we have exactly the problem explained in Figure 6.1. While mul1 is accessed sequentially, the inner loop advances the row number of mul2. That means that mul1 is handled like the left matrix in Figure 6.1 while mul2 is handled like the right matrix. This cannot be good.
There is one possible remedy one can easily try. Since each element in the matrices is accessed multiple times it might be worthwhile to rearrange (“transpose,” in mathematical terms) the second matrix mul2 before using it.
![[formula]](https://static.lwn.net/images/cpumemory/matrixmultT.png)
After the transposition (traditionally indicated by a superscript ‘T’) we now iterate over both matrices sequentially. As far as the C code is concerned, it now looks like this:
double tmp[N][N];
for (i = 0; i < N; ++i)
for (j = 0; j < N; ++j)
tmp[i][j] = mul2[j][i];
for (i = 0; i < N; ++i)
for (j = 0; j < N; ++j)
for (k = 0; k < N; ++k)
res[i][j] += mul1[i][k] * tmp[j][k];
We create a temporary variable to contain the transposed matrix. This requires touching more memory, but this cost is, hopefully, recovered since the 1000 non-sequential accesses per column are more expensive (at least on modern hardware). Time for some performance tests. The results on a Intel Core 2 with 2666MHz clock speed are (in clock cycles):
Original Transposed Cycles 16,765,297,870 3,922,373,010 Relative 100% 23.4%
Through the simple transformation of the matrix we can achieve a 76.6% speed-up! The copy operation is more than made up. The 1000 non-sequential accesses really hurt.
The next question is whether this is the best we can do. We certainly need an alternative method anyway which does not require the additional copy. We will not always have the luxury to be able to perform the copy: the matrix can be too large or the available memory too small.
The search for an alternative implementation should start with a close examination of the math involved and the operations performed by the original implementation. Trivial math knowledge allows us to see that the order in which the additions for each element of the result matrix are performed is irrelevant as long as each addend appears exactly once. {We ignore arithmetic effects here which might change the occurrence of overflows, underflows, or rounding.} This understanding allows us to look for solutions which reorder the additions performed in the inner loop of the original code.
Now let us examine the actual problem in the execution of the original code. The order in which the elements of mul2 are accessed is: (0,0), (1,0), …, (N-1,0), (0,1), (1,1), …. The elements (0,0) and (0,1) are in the same cache line but, by the time the inner loop completes one round, this cache line has long been evicted. For this example, each round of the inner loop requires, for each of the three matrices, 1000 cache lines (with 64 bytes for the Core 2 processor). This adds up to much more than the 32k of L1d available.
But what if we handle two iterations of the middle loop together while executing the inner loop? In this case we use two double values from the cache line which is guaranteed to be in L1d. We cut the L1d miss rate in half. That is certainly an improvement, but, depending on the cache line size, it still might not be as good as we can get it. The Core 2 processor has a L1d cache line size of 64 bytes. The actual value can be queried using
sysconf (_SC_LEVEL1_DCACHE_LINESIZE)
at runtime or using the getconf utility from the command line so that the program can be compiled for a specific cache line size. With sizeof(double) being 8 this means that, to fully utilize the cache line, we should unroll the middle loop 8 times. Continuing this thought, to effectively use the res matrix as well, i.e., to write 8 results at the same time, we should unroll the outer loop 8 times as well. We assume here cache lines of size 64 but the code works also well on systems with 32-byte cache lines since both cache lines are also 100% utilized. In general it is best to hardcode cache line sizes at compile time by using the getconf utility as in:
gcc -DCLS=$(getconf LEVEL1_DCACHE_LINESIZE) ...
If the binaries are supposed to be generic, the largest cache line size should be used. With very small L1ds this might mean that not all the data fits into the cache but such processors are not suitable for high-performance programs anyway. The code we arrive at looks something like this:
#define SM (CLS / sizeof (double))
for (i = 0; i < N; i += SM)
for (j = 0; j < N; j += SM)
for (k = 0; k < N; k += SM)
for (i2 = 0, rres = &res[i][j],
rmul1 = &mul1[i][k]; i2 < SM;
++i2, rres += N, rmul1 += N)
for (k2 = 0, rmul2 = &mul2[k][j];
k2 < SM; ++k2, rmul2 += N)
for (j2 = 0; j2 < SM; ++j2)
rres[j2] += rmul1[k2] * rmul2[j2];
This looks quite scary. To some extent it is but only because it incorporates some tricks. The most visible change is that we now have six nested loops. The outer loops iterate with intervals of SM (the cache line size divided by sizeof(double)). This divides the multiplication in several smaller problems which can be handled with more cache locality. The inner loops iterate over the missing indexes of the outer loops. There are, once again, three loops. The only tricky part here is that the k2 and j2 loops are in a different order. This is done since, in the actual computation, only one expression depends on k2 but two depend on j2.
The rest of the complication here results from the fact that gcc is not very smart when it comes to optimizing array indexing. The introduction of the additional variables rres, rmul1, and rmul2 optimizes the code by pulling common expressions out of the inner loops, as far down as possible. The default aliasing rules of the C and C++ languages do not help the compiler making these decisions (unless restrict is used, all pointer accesses are potential sources of aliasing). This is why Fortran is still a preferred language for numeric programming: it makes writing fast code easier. {In theory the restrict keyword introduced into the C language in the 1999 revision should solve the problem. Compilers have not caught up yet, though. The reason is mainly that too much incorrect code exists which would mislead the compiler and cause it to generate incorrect object code.}
How all this work pays off can be seen in Table 6.2.
Original Transposed Sub-Matrix Vectorized Cycles 16,765,297,870 3,922,373,010 2,895,041,480 1,588,711,750 Relative 100% 23.4% 17.3% 9.47% Table 6.2: Matrix Multiplication Timing
By avoiding the copying we gain another 6.1% of performance. Plus, we do not need any additional memory. The input matrices can be arbitrarily large as long as the result matrix fits into memory as well. This is a requirement for a general solution which we have now achieved.
There is one more column in Table 6.2 which has not been explained. Most modern processors nowadays include special support for vectorization. Often branded as multi-media extensions, these special instructions allow processing of 2, 4, 8, or more values at the same time. These are often SIMD (Single Instruction, Multiple Data) operations, augmented by others to get the data in the right form. The SSE2 instructions provided by Intel processors can handle two double values in one operation. The instruction reference manual lists the intrinsic functions which provide access to these SSE2 instructions. If these intrinsics are used the program runs another 7.3% (relative to the original) faster. The result is a program which runs in 10% of the time of the original code. Translated into numbers which people recognize, we went from 318 MFLOPS to 3.35 GFLOPS. Since we are here only interested in memory effects here, the program code is pushed out into Section 9.1.
It should be noted that, in the last version of the code, we still have some cache problems with mul2; prefetching still will not work. But this cannot be solved without transposing the matrix. Maybe the cache prefetching units will get smarter to recognize the patterns, then no additional change would be needed. 3.19 GFLOPS on a 2.66 GHz processor with single-threaded code is not bad, though.
What we optimized in the example of the matrix multiplication is the use of the loaded cache lines. All bytes of a cache line are always used. We just made sure they are used before the cache line is evacuated. This is certainly a special case.
It is much more common to have data structures which fill one or more cache lines where the program uses only a few members at any one time. In Figure 3.11 we have already seen the effects of large structure sizes if only few members are used.

Figure 6.2: Spreading Over Multiple Cache Lines
Figure 6.2 shows the results of yet another set of benchmarks performed using the by now well-known program. This time two values of the same list element are added. In one case, both elements are in the same cache line; in the other case, one element is in the first cache line of the list element and the second is in the last cache line. The graph shows the slowdown we are experiencing.
Unsurprisingly, in all cases there are no negative effects if the working set fits into L1d. Once L1d is no longer sufficient, penalties are paid by using two cache lines in the process instead of one. The red line shows the data when the list is laid out sequentially in memory. We see the usual two step patterns: about 17% penalty when the L2 cache is sufficient and about 27% penalty when the main memory has to be used.
In the case of random memory accesses the relative data looks a bit different. The slowdown for working sets which fit into L2 is between 25% and 35%. Beyond that it goes down to about 10%. This is not because the penalties get smaller but, instead, because the actual memory accesses get disproportionally more costly. The data also shows that, in some cases, the distance between the elements does matter. The Random 4 CLs curve shows higher penalties because the first and fourth cache lines are used.
An easy way to see the layout of a data structure compared to cache lines is to use the pahole program (see [dwarves]). This program examines the data structures defined in a binary. Take a program containing this definition:
struct foo {
int a;
long fill[7];
int b;
};
Compiled on a 64-bit machine, the output of pahole contains (among other things) the information shown in Figure 6.3.
struct foo { int a; /* 0 4 */ /* XXX 4 bytes hole, try to pack */ long int fill[7]; /* 8 56 */ /* --- cacheline 1 boundary (64 bytes) --- */ int b; /* 64 4 */ }; /* size: 72, cachelines: 2 */ /* sum members: 64, holes: 1, sum holes: 4 */ /* padding: 4 */ /* last cacheline: 8 bytes */Figure 6.3: Output of pahole Run
This output tells us a lot. First, it shows that the data structure uses up more than one cache line. The tool assumes the currently-used processor's cache line size, but this value can be overridden using a command line parameter. Especially in cases where the size of the structure is barely over the limit of a cache line, and many objects of this type are allocated, it makes sense to seek a way to compress that structure. Maybe a few elements can have a smaller type, or maybe some fields are actually flags which can be represented using individual bits.
In the case of the example the compression is easy and it is hinted at by the program. The output shows that there is a hole of four bytes after the first element. This hole is caused by the alignment requirement of the structure and the fill element. It is easy to see that the element b, which has a size of four bytes (indicated by the 4 at the end of the line), fits perfectly into the gap. The result in this case is that the gap no longer exists and that the data structure fits onto one cache line. The pahole tool can perform this optimization itself. If the —reorganize parameter is used and the structure name is added at the end of the command line the output of the tool is the optimized structure and the cache line use. Besides moving elements to fill gaps, the tool can also optimize bit fields and combine padding and holes. For more details see [dwarves].
Having a hole which is just large enough for the trailing element is, of course, the ideal situation. For this optimization to be useful it is required that the object itself is aligned to a cache line. We get to that in a bit.
The pahole output also makes it easier to determine whether elements have to be reordered so that those elements which are used together are also stored together. Using the pahole tool, it is easily possible to determine which elements are in the same cache line and when, instead, the elements have to be reshuffled to achieve that. This is not an automatic process but the tool can help quite a bit.
The position of the individual structure elements and the way they are used is important, too. As we have seen in Section 3.5.2 the performance of code with the critical word late in the cache line is worse. This means a programmer should always follow the following two rules:
-
Always move the structure element which is most likely to be the critical word to the beginning of the structure.
-
When accessing the data structures, and the order of access is not dictated by the situation, access the elements in the order in which they are defined in the structure.
For small structures, this means that the programmer should arrange the elements in the order in which they are likely accessed. This must be handled in a flexible way to allow the other optimizations, such as filling holes, to be applied as well. For bigger data structures each cache line-sized block should be arranged to follow the rules.
Reordering elements is not worth the time it takes, though, if the object itself is not aligned. The alignment of an object is determined by the alignment requirement of the data type. Each fundamental type has its own alignment requirement. For structured types the largest alignment requirement of any of its elements determines the alignment of the structure. This is almost always smaller than the cache line size. This means even if the members of a structure are lined up to fit into the same cache line an allocated object might not have an alignment matching the cache line size. There are two ways to ensure that the object has the alignment which was used when designing the layout of the structure:
- the object can be allocated with an explicit alignment
requirement. For dynamic allocation a call to malloc would
only allocate the object with an alignment matching that of the most
demanding standard type (usually long double). It is possible
to use posix_memalign, though, to request higher alignments.
#include <stdlib.h> int posix_memalign(void **memptr, size_t align, size_t size);The function stores the pointer to the newly-allocated memory in the pointer variable pointed to by memptr. The memory block is size bytes in size and is aligned on a align-byte boundary.
For objects allocated by the compiler (in .data, .bss, etc, and on the stack) a variable attribute can be used:
struct strtype variable __attribute((aligned(64)));In this case the variable is aligned at a 64 byte boundary regardless of the alignment requirement of the strtype structure. This works for global variables as well as automatic variables.
This method does not work for arrays, though. Only the first element of the array would be aligned unless the size of each array element is a multiple of the alignment value. It also means that every single variable must be annotated appropriately. The use of posix_memalign is also not entirely free since the alignment requirements usually lead to fragmentation and/or higher memory consumption.
- the alignment requirement of a type can be changed using a type
attribute:
struct strtype { ...members... } __attribute((aligned(64)));This will cause the compiler to allocate all objects with the appropriate alignment, including arrays. The programmer has to take care of requesting the appropriate alignment for dynamically allocated objects, though. Here once again posix_memalign must be used. It is easy enough to use the alignof operator gcc provides and pass the value as the second parameter to posix_memalign.
The multimedia extensions previously mentioned in this section almost always require that the memory accesses are aligned. I.e., for 16 byte memory accesses the address is supposed to be 16 byte aligned. The x86 and x86-64 processors have special variants of the memory operations which can handle unaligned accesses but these are slower. This hard alignment requirement is nothing new for most RISC architectures which require full alignment for all memory accesses. Even if an architecture supports unaligned accesses this is sometimes slower than using appropriate alignment, especially if the misalignment causes a load or store to use two cache lines instead of one.
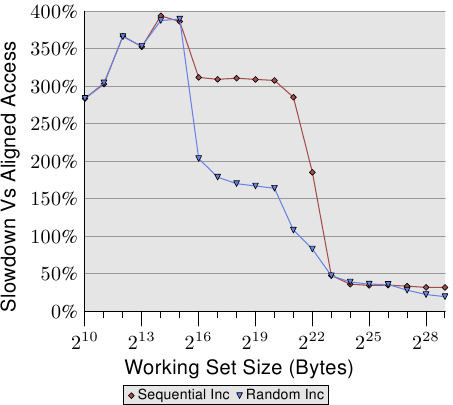
Figure 6.4: Overhead of Unaligned Accesses
Figure 6.4 shows the effects of unaligned memory accesses. The now well-known tests which increment a data element while visiting memory (sequentially or randomly) are measured, once with aligned list elements and once with deliberately misaligned elements. The graph shows the slowdown the program incurs because of the unaligned accesses. The effects are more dramatic for the sequential access case than for the random case because, in the latter case, the costs of unaligned accesses are partially hidden by the generally higher costs of the memory access. In the sequential case, for working set sizes which do fit into the L2 cache, the slowdown is about 300%. This can be explained by the reduced effectiveness of the L1 cache. Some increment operations now touch two cache lines, and beginning work on a list element now often requires reading of two cache lines. The connection between L1 and L2 is simply too congested.
For very large working set sizes, the effects of the unaligned access are still 20% to 30%—which is a lot given that the aligned access time for those sizes is long. This graph should show that alignment must be taken seriously. Even if the architecture supports unaligned accesses, this must not be taken as “they are as good as aligned accesses”.
There is some fallout from these alignment requirements, though. If an automatic variable has an alignment requirement, the compiler has to ensure that it is met in all situations. This is not trivial since the compiler has no control over the call sites and the way they handle the stack. This problem can be handled in two ways:
- The generated code actively aligns the stack, inserting gaps if
necessary. This requires code to check for alignment, create
alignment, and later undo the alignment.
- Require that all callers have the stack aligned.
All of the commonly used application binary interfaces (ABIs) follow the second route. Programs will likely fail if a caller violates the rule and alignment is needed in the callee. Keeping alignment intact does not come for free, though.
The size of a stack frame used in a function is not necessarily a multiple of the alignment. This means padding is needed if other functions are called from this stack frame. The big difference is that the stack frame size is, in most cases, known to the compiler and, therefore, it knows how to adjust the stack pointer to ensure alignment for any function which is called from that stack frame. In fact, most compilers will simply round the stack frame size up and be done with it.
This simple way to handle alignment is not possible if variable length arrays (VLAs) or alloca are used. In that case, the total size of the stack frame is only known at runtime. Active alignment control might be needed in this case, making the generated code (slightly) slower.
On some architectures, only the multimedia extensions require strict alignment; stacks on those architectures are always minimally aligned for the normal data types, usually 4 or 8 byte alignment for 32- and 64-bit architectures respectively. On these systems, enforcing the alignment incurs unnecessary costs. That means that, in this case, we might want to get rid of the strict alignment requirement if we know that it is never depended upon. Tail functions (those which call no other functions) which do no multimedia operations do not need alignment. Neither do functions which only call functions which need no alignment. If a large enough set of functions can be identified, a program might want to relax the alignment requirement. For x86 binaries gcc has support for relaxed stack alignment requirements:
-mpreferred-stack-boundary=2
If this option is given a value of N, the stack alignment requirement will be set to 2N bytes. So, if a value of 2 is used, the stack alignment requirement is reduced from the default (which is 16 bytes) to just 4 bytes. In most cases this means no additional alignment operation is needed since normal stack push and pop operations work on four-byte boundaries anyway. This machine-specific option can help to reduce code size and also improve execution speed. But it cannot be applied for many other architectures. Even for x86-64 it is generally not applicable since the x86-64 ABI requires that floating-point parameters are passed in an SSE register and the SSE instructions require full 16 byte alignment. Nevertheless, whenever the option is usable it can make a noticeable difference.
Efficient placement of structure elements and alignment are not the only aspects of data structures which influence cache efficiency. If an array of structures is used, the entire structure definition affects performance. Remember the results in Figure 3.11: in this case we had increasing amounts of unused data in the elements of the array. The result was that prefetching was increasingly less effective and the program, for large data sets, became less efficient.
For large working sets it is important to use the available cache as well as possible. To achieve this, it might be necessary to rearrange data structures. While it is easier for the programmer to put all the data which conceptually belongs together in the same data structure, this might not be the best approach for maximum performance. Assume we have a data structure as follows:
struct order {
double price;
bool paid;
const char *buyer[5];
long buyer_id;
};
Further assume that these records are stored in a big array and that a frequently-run job adds up the expected payments of all the outstanding bills. In this scenario, the memory used for the buyer and buyer_id fields is unnecessarily loaded into the caches. Judging from the data in Figure 3.11 the program will perform up to 5 times worse than it could.
It is much better to split the order data structure in two, storing the first two fields in one structure and the other fields elsewhere. This change certainly increases the complexity of the program, but the performance gains might justify this cost.
Finally, let's consider another cache use optimization which, while also applying to the other caches, is primarily felt in the L1d access. As seen in Figure 3.8 an increased associativity of the cache benefits normal operation. The larger the cache, the higher the associativity usually is. The L1d cache is too large to be fully associative but not large enough to have the same associativity as L2 caches. This can be a problem if many of the objects in the working set fall into the same cache set. If this leads to evictions due to overuse of a set, the program can experience delays even though much of the cache is unused. These cache misses are sometimes called conflict misses. Since the L1d addressing uses virtual addresses, this is actually something the programmer can have control over. If variables which are used together are also stored together the likelihood of them falling into the same set is minimized. Figure 6.5 shows how quickly the problem can hit.
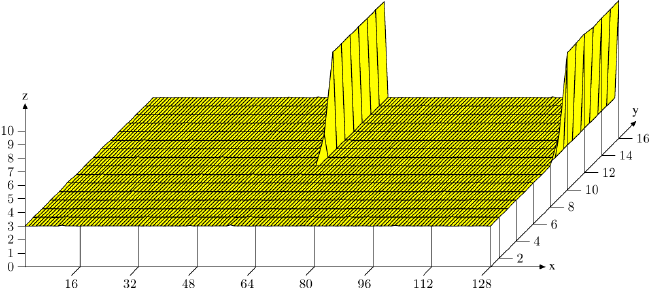
Figure 6.5: Cache Associativity Effects
In the figure, the now familiar Follow {The test was performed on a 32-bit machine, hence NPAD=15 means one 64-byte cache line per list element.} with NPAD=15 test is measured with a special setup. The X–axis is the distance between two list elements, measured in empty list elements. In other words, a distance of 2 means that the next element's address is 128 bytes after the previous one. All elements are laid out in the virtual address space with the same distance. The Y–axis shows the total length of the list. Only one to 16 elements are used, meaning that the total working set size is 64 to 1024 bytes. The z–axis shows the average number of cycles needed to traverse each list element.
The result shown in the figure should not be surprising. If few elements are used, all the data fits into L1d and the access time is only 3 cycles per list element. The same is true for almost all arrangements of the list elements: the virtual addresses are nicely mapped to L1d slots with almost no conflicts. There are two (in this graph) special distance values for which the situation is different. If the distance is a multiple of 4096 bytes (i.e., distance of 64 elements) and the length of the list is greater than eight, the average number of cycles per list element increases dramatically. In these situations all entries are in the same set and, once the list length is greater than the associativity, entries are flushed from L1d and have to be re-read from L2 the next round. This results in the cost of about 10 cycles per list element.
With this graph we can determine that the processor used has an L1d cache with associativity 8 and a total size of 32kB. That means that the test could, if necessary, be used to determine these values. The same effects can be measured for the L2 cache but, here, it is more complex since the L2 cache is indexed using physical addresses and it is much larger.
For programmers this means that associativity is something worth paying attention to. Laying out data at boundaries that are powers of two happens often enough in the real world, but this is exactly the situation which can easily lead to the above effects and degraded performance. Unaligned accesses can increase the probability of conflict misses since each access might require an additional cache line.

Figure 6.6: Bank Address of L1d on AMD
If this optimization is performed, another related optimization is possible, too. AMD's processors, at least, implement the L1d as several individual banks. The L1d can receive two data words per cycle but only if both words are stored in different banks or in a bank with the same index. The bank address is encoded in the low bits of the virtual address as shown in Figure 6.6. If variables which are used together are also stored together the likelihood that they are in different banks or the same bank with the same index is high.
6.2.2 Optimizing Level 1 Instruction Cache Access
Preparing code for good L1i use needs similar techniques as good L1d use. The problem is, though, that the programmer usually does not directly influence the way L1i is used unless s/he writes code in assembler. If compilers are used, programmers can indirectly determine the L1i use by guiding the compiler to create a better code layout.
Code has the advantage that it is linear between jumps. In these periods the processor can prefetch memory efficiently. Jumps disturb this nice picture because
- the jump target might not be statically determined;
- and even if it is static the memory fetch might take a long time
if it misses all caches.
These problems create stalls in execution with a possibly severe impact on performance. This is why today's processors invest heavily in branch prediction (BP). Highly specialized BP units try to determine the target of a jump as far ahead of the jump as possible so that the processor can initiate loading the instructions at the new location into the cache. They use static and dynamic rules and are increasingly good at determining patterns in execution.
Getting data into the cache as soon as possible is even more important for the instruction cache. As mentioned in Section 3.1, instructions have to be decoded before they can be executed and, to speed this up (important on x86 and x86-64), instructions are actually cached in the decoded form, not in the byte/word form read from memory.
To achieve the best L1i use programmers should look out for at least the following aspects of code generation:
- reduce the code footprint as much as possible. This has to be
balanced with optimizations like loop unrolling and inlining.
- code execution should be linear without
bubbles. {Bubbles describe graphically the holes in the
execution in the pipeline of a processor which appear when the
execution has to wait for resources. For more details the reader
is referred to literature on processor design.}
- aligning code when it makes sense.
We will now look at some compiler techniques available to help with optimizing programs according to these aspects.
Compilers have options to enable levels of optimization; specific optimizations can also be individually enabled. Many of the optimizations enabled at high optimization levels (-O2 and -O3 for gcc) deal with loop optimizations and function inlining. In general, these are good optimizations. If the code which is optimized in these ways accounts for a significant part of the total execution time of the program, overall performance can be improved. Inlining of functions, in particular, allows the compiler to optimize larger chunks of code at a time which, in turn, enables the generation of machine code which better exploits the processor's pipeline architecture. The handling of both code and data (through dead code elimination or value range propagation, and others) works better when larger parts of the program can be considered as a single unit.
A larger code size means higher pressure on the L1i (and also L2 and higher level) caches. This can lead to less performance. Smaller code can be faster. Fortunately gcc has an optimization option to specify this. If -Os is used the compiler will optimize for code size. Optimizations which are known to increase the code size are disabled. Using this option often produces surprising results. Especially if the compiler cannot really take advantage of loop unrolling and inlining, this option is a big win.
Inlining can be controlled individually as well. The compiler has heuristics and limits which guide inlining; these limits can be controlled by the programmer. The -finline-limit option specifies how large a function must be to be considered too large for inlining. If a function is called in multiple places, inlining it in all of them would cause an explosion in the code size. But there is more. Assume a function inlcand is called in two functions f1 and f2. The functions f1 and f2 are themselves called in sequence.
With inlining Without inlining Table 6.3: Inlining Vs Not
Table 6.3 shows how the generated code could look like in the cases of no inline and inlining in both functions. If the function inlcand is inlined in both f1 and f2 the total size of the generated code is:
size f1 + size f2 + 2 × size inlcand
If no inlining happens, the total size is smaller by size inlcand. This is how much more L1i and L2 cache is needed if f1 and f2 are called shortly after one another. Plus: if inlcand is not inlined, the code might still be in L1i and it will not have to be decoded again. Plus: the branch prediction unit might do a better job of predicting jumps since it has already seen the code. If the compiler default for the upper limit on the size of inlined functions is not the best for the program, it should be lowered.
There are cases, though, when inlining always makes sense. If a function is only called once it might as well be inlined. This gives the compiler the opportunity to perform more optimizations (like value range propagation, which might significantly improve the code). That inlining might be thwarted by the selection limits. gcc has, for cases like this, an option to specify that a function is always inlined. Adding the always_inline function attribute instructs the compiler to do exactly what the name suggests.
In the same context, if a function should never be inlined despite being small enough, the noinline function attribute can be used. Using this attribute makes sense even for small functions if they are called often from different places. If the L1i content can be reused and the overall footprint is reduced this often makes up for the additional cost of the extra function call. Branch prediction units are pretty good these days. If inlining can lead to more aggressive optimizations things look different. This is something which must be decided on a case-by-case basis.
The always_inline attribute works well if the inline code is always used. But what if this is not the case? What if the inlined function is called only occasionally:
void fct(void) {
... code block A ...
if (condition)
inlfct()
... code block C ...
}
The code generated for such a code sequence in general matches the structure of the sources. That means first comes the code block A, then a conditional jump which, if the condition evaluates to false, jumps forward. The code generated for the inlined inlfct comes next, and finally the code block C. This looks all reasonable but it has a problem.
If the condition is frequently false, the execution is not linear. There is a big chunk of unused code in the middle which not only pollutes the L1i due to prefetching, it also can cause problems with branch prediction. If the branch prediction is wrong the conditional expression can be very inefficient.
This is a general problem and not specific to inlining functions. Whenever conditional execution is used and it is lopsided (i.e., the expression far more often leads to one result than the other) there is the potential for false static branch prediction and thus bubbles in the pipeline. This can be prevented by telling the compiler to move the less often executed code out of the main code path. In that case the conditional branch generated for an if statement would jump to a place out of the order as can be seen in the following figure.
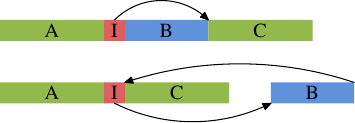
The upper parts represents the simple code layout. If the area B, e.g. generated from the inlined function inlfct above, is often not executed because the conditional I jumps over it, the prefetching of the processor will pull in cache lines containing block B which are rarely used. Using block reordering this can be changed, with a result that can be seen in the lower part of the figure. The often-executed code is linear in memory while the rarely-executed code is moved somewhere where it does not hurt prefetching and L1i efficiency.
gcc provides two methods to achieve this. First, the compiler can take profiling output into account while recompiling code and lay out the code blocks according to the profile. We will see how this works in Section 7. The second method is through explicit branch prediction. gcc recognizes __builtin_expect:
long __builtin_expect(long EXP, long C);
This construct tells the compiler that the expression EXP most likely will have the value C. The return value is EXP. __builtin_expect is meant to be used in an conditional expression. In almost all cases will it be used in the context of boolean expressions in which case it is much more convenient to define two helper macros:
#define unlikely(expr) __builtin_expect(!!(expr), 0) #define likely(expr) __builtin_expect(!!(expr), 1)
These macros can then be used as in
if (likely(a > 1))
If the programmer makes use of these macros and then uses the -freorder-blocks optimization option gcc will reorder blocks as in the figure above. This option is enabled with -O2 but disabled for -Os. There is another option to reorder block (-freorder-blocks-and-partition) but it has limited usefulness because it does not work with exception handling.
There is another big advantage of small loops, at least on certain processors. The Intel Core 2 front end has a special feature called Loop Stream Detector (LSD). If a loop has no more than 18 instructions (none of which is a call to a subroutine), requires only up to 4 decoder fetches of 16 bytes, has at most 4 branch instructions, and is executed more than 64 times, than the loop is sometimes locked in the instruction queue and therefore more quickly available when the loop is used again. This applies, for instance, to small inner loops which are entered many times through an outer loop. Even without such specialized hardware compact loops have advantages.
Inlining is not the only aspect of optimization with respect to L1i. Another aspect is alignment, just as for data. There are obvious differences: code is a mostly linear blob which cannot be placed arbitrarily in the address space and it cannot be influenced directly by the programmer as the compiler generates the code. There are some aspects which the programmer can control, though.
Aligning each single instruction does not make any sense. The goal is to have the instruction stream be sequential. So alignment only makes sense in strategic places. To decide where to add alignments it is necessary to understand what the advantages can be. Having an instruction at the beginning of a cache line {For some processors cache lines are not the atomic blocks for instructions. The Intel Core 2 front end issues 16 byte blocks to the decoder. They are appropriately aligned and so no issued block can span a cache line boundary. Aligning at the beginning of a cache line still has advantages since it optimizes the positive effects of prefetching.} means that the prefetch of the cache line is maximized. For instructions this also means the decoder is more effective. It is easy to see that, if an instruction at the end of a cache line is executed, the processor has to get ready to read a new cache line and decode the instructions. There are things which can go wrong (such as cache line misses), meaning that an instruction at the end of the cache line is, on average, not as effectively executed as one at the beginning.
Combine this with the follow-up deduction that the problem is most severe if control was just transferred to the instruction in question (and hence prefetching is not effective) and we arrive at our final conclusion where alignment of code is most useful:
- at the beginning of functions;
- at the beginning of basic blocks which are reached only through
jumps;
- to some extent, at the beginning of loops.
In the first two cases the alignment comes at little cost. Execution proceeds at a new location and, if we choose it to be at the beginning of a cache line, we optimize prefetching and decoding. {For instruction decoding processors often use a smaller unit than cache lines, 16 bytes in case of x86 and x86-64.} The compiler accomplishes this alignment through the insertion of a series of no-op instructions to fill the gap created by aligning the code. This “dead code” takes a little space but does not normally hurt performance.
The third case is slightly different: aligning beginning of each loop might create performance problems. The problem is that beginning of a loop often follows other code sequentially. If the circumstances are not very lucky there will be a gap between the previous instruction and the aligned beginning of the loop. Unlike in the previous two cases, this gap cannot be completely dead. After execution of the previous instruction the first instruction in the loop must be executed. This means that, following the previous instruction, there either must be a number of no-op instructions to fill the gap or there must be an unconditional jump to the beginning of the loop. Neither possibility is free. Especially if the loop itself is not executed often, the no-ops or the jump might cost more than one saves by aligning the loop.
There are three ways the programmer can influence the alignment of code. Obviously, if the code is written in assembler the function and all instructions in it can be explicitly aligned. The assembler provides for all architectures the .align pseudo-op to do that. For high-level languages the compiler must be told about alignment requirements. Unlike for data types and variables this is not possible in the source code. Instead a compiler option is used:
-falign-functions=N
This option instructs the compiler to align all functions to the next power-of-two boundary greater than N. That means a gap of up to N bytes is created. For small functions using a large value for N is a waste. Equally for code which is executed only rarely. The latter can happen a lot in libraries which can contain both popular and not-so-popular interfaces. A wise choice of the option value can speed things up or save memory by avoiding alignment. All alignment is turned off by using one as the value of N or by using the -fno-align-functions option.
The alignment for the second case above—beginning of basic blocks which are not reached sequentially—can be controlled with a different option:
-falign-jumps=N
All the other details are equivalent, the same warning about waste of memory applies.
The third case also has its own option:
-falign-loops=N
Yet again, the same details and warnings apply. Except that here, as explained before, alignment comes at a runtime cost since either no-ops or a jump instruction has to be executed if the aligned address is reached sequentially.
gcc knows about one more option for controlling alignment which is mentioned here only for completeness. -falign-labels aligns every single label in the code (basically the beginning of each basic block). This, in all but a few exceptional cases, slows down the code and therefore should not be used.
6.2.3 Optimizing Level 2 and Higher Cache Access
Everything said about optimizations for using level 1 cache also applies to level 2 and higher cache accesses. There are two additional aspects of last level caches:
- cache misses are always very expensive. While L1 misses
(hopefully) frequently hit L2 and higher cache, thus limiting the
penalties, there is obviously no fallback for the last level cache.
- L2 caches and higher are often shared by multiple cores and/or
hyper-threads. The effective cache size available to each execution
unit is therefore usually less than the total cache size.
To avoid the high costs of cache misses, the working set size should be matched to the cache size. If data is only needed once this obviously is not necessary since the cache would be ineffective anyway. We are talking about workloads where the data set is needed more than once. In such a case the use of a working set which is too large to fit into the cache will create large amounts of cache misses which, even with prefetching being performed successfully, will slow down the program.
A program has to perform its job even if the data set is too large. It is the programmer's job to do the work in a way which minimizes cache misses. For last-level caches this is possible—just as for L1 caches—by working on the job in smaller pieces. This is very similar to the optimized matrix multiplication on Table 6.2. One difference, though, is that, for last level caches, the data blocks which are be worked on can be bigger. The code becomes yet more complicated if L1 optimizations are needed, too. Imagine a matrix multiplication where the data sets—the two input matrices and the output matrix—do not fit into the last level cache together. In this case it might be appropriate to optimize the L1 and last level cache accesses at the same time.
The L1 cache line size is usually constant over many processor generations; even if it is not, the differences will be small. It is no big problem to just assume the larger size. On processors with smaller cache sizes two or more cache lines will then be used instead of one. In any case, it is reasonable to hardcode the cache line size and optimize the code for it.
For higher level caches this is not the case if the program is supposed to be generic. The sizes of those caches can vary widely. Factors of eight or more are not uncommon. It is not possible to assume the larger cache size as a default since this would mean the code performs poorly on all machines except those with the biggest cache. The opposite choice is bad too: assuming the smallest cache means throwing away 87% of the cache or more. This is bad; as we can see from Figure 3.14 using large caches can have a huge impact on the program's speed.
What this means is that the code must dynamically adjust itself to the cache line size. This is an optimization specific to the program. All we can say here is that the programmer should compute the program's requirements correctly. Not only are the data sets themselves needed, the higher level caches are also used for other purposes; for example, all the executed instructions are loaded from cache. If library functions are used this cache usage might add up to a significant amount. Those library functions might also need data of their own which further reduces the available memory.
Once we have a formula for the memory requirement we can compare it with the cache size. As mentioned before, the cache might be shared with multiple other cores. Currently {There definitely will sometime soon be a better way!} the only way to get correct information without hardcoding knowledge is through the /sys filesystem. In Table 5.2 we have seen the what the kernel publishes about the hardware. A program has to find the directory:
/sys/devices/system/cpu/cpu*/cache
for the last level cache. This can be recognized by the highest numeric value in the level file in that directory. When the directory is identified the program should read the content of the size file in that directory and divide the numeric value by the number of bits set in the bitmask in the file shared_cpu_map.
The value which is computed this way is a safe lower limit. Sometimes a program knows a bit more about the behavior of other threads or processes. If those threads are scheduled on a core or hyper-thread sharing the cache, and the cache usage is known to not exhaust its fraction of the total cache size, then the computed limit might be too low to be optimal. Whether more than the fair share should be used really depends on the situation. The programmer has to make a choice or has to allow the user to make a decision.
6.2.4 Optimizing TLB Usage
There are two kinds of optimization of TLB usage. The first optimization is to reduce the number of pages a program has to use. This automatically results in fewer TLB misses. The second optimization is to make the TLB lookup cheaper by reducing the number higher level directory tables which must be allocated. Fewer tables means less memory usage which can result is higher cache hit rates for the directory lookup.
The first optimization is closely related to the minimization of page faults. We will cover that topic in detail in Section 7.5. While page faults usually are a one-time cost, TLB misses are a perpetual penalty given that the TLB cache is usually small and it is flushed frequently. Page faults are orders of magnitude more expensive than TLB misses but, if a program is running long enough and certain parts of the program are executed frequently enough, TLB misses can outweigh even page fault costs. It is therefore important to regard page optimization not only from the perspective of page faults but also from the TLB miss perspective. The difference is that, while page fault optimizations only require page-wide grouping of the code and data, TLB optimization requires that, at any point in time, as few TLB entries are in use as possible.
The second TLB optimization is even harder to control. The number of page directories which have to be used depends on the distribution of the address ranges used in the virtual address space of the process. Widely varying locations in the address space mean more directories. A complication is that Address Space Layout Randomization (ASLR) leads to exactly these situations. The load addresses of stack, DSOs, heap, and possibly executable are randomized at runtime to prevent attackers of the machine from guessing the addresses of functions or variables.
For maximum performance ASLR certainly should be turned off. The costs of the extra directories is low enough, though, to make this step unnecessary in all but a few extreme cases. One possible optimization the kernel could at any time perform is to ensure that a single mapping does not cross the address space boundary between two directories. This would limit ASLR in a minimal fashion but not enough to substantially weaken it.
The only way a programmer is directly affected by this is when an address space region is explicitly requested. This happens when using mmap with MAP_FIXED. Allocating new a address space region this way is very dangerous and hardly ever done. It is possible, though, and, if it is used, the programmer should know about the boundaries of the last level page directory and select the requested address appropriately.
6.3 Prefetching
The purpose of prefetching is to hide the latency of a memory access. The command pipeline and out-of-order (OOO) execution capabilities of today's processors can hide some latency but, at best, only for accesses which hit the caches. To cover the latency of main memory accesses, the command queue would have to be incredibly long. Some processors without OOO try to compensate by increasing the number of cores, but this is a bad trade unless all the code in use is parallelized.
Prefetching can further help to hide latency. The processor performs prefetching on its own, triggered by certain events (hardware prefetching) or explicitly requested by the program (software prefetching).
6.3.1 Hardware Prefetching
The trigger for hardware prefetching is usually a sequence of two or more cache misses in a certain pattern. These cache misses can be to succeeding or preceding cache lines. In old implementations only cache misses to adjacent cache lines are recognized. With contemporary hardware, strides are recognized as well, meaning that skipping a fixed number of cache lines is recognized as a pattern and handled appropriately.
It would be bad for performance if every single cache miss triggered a hardware prefetch. Random memory accesses, for instance to global variables, are quite common and the resulting prefetches would mostly waste FSB bandwidth. This is why, to kickstart prefetching, at least two cache misses are needed. Processors today all expect there to be more than one stream of memory accesses. The processor tries to automatically assign each cache miss to such a stream and, if the threshold is reached, start hardware prefetching. CPUs today can keep track of eight to sixteen separate streams for the higher level caches.
The units responsible for the pattern recognition are associated with the respective cache. There can be a prefetch unit for the L1d and L1i caches. There is most probably a prefetch unit for the L2 cache and higher. The L2 and higher prefetch unit is shared with all the other cores and hyper-threads using the same cache. The number of eight to sixteen separate streams therefore is quickly reduced.
Prefetching has one big weakness: it cannot cross page boundaries. The reason should be obvious when one realizes that the CPUs support demand paging. If the prefetcher were allowed to cross page boundaries, the access might trigger an OS event to make the page available. This by itself can be bad, especially for performance. What is worse is that the prefetcher does not know about the semantics of the program or the OS itself. It might therefore prefetch pages which, in real life, never would be requested. That means the prefetcher would run past the end of the memory region the processor accessed in a recognizable pattern before. This is not only possible, it is very likely. If the processor, as a side effect of a prefetch, triggered a request for such a page the OS might even be completely thrown off its tracks if such a request could never otherwise happen.
It is therefore important to realize that, regardless of how good the prefetcher is at predicting the pattern, the program will experience cache misses at page boundaries unless it explicitly prefetches or reads from the new page. This is another reason to optimize the layout of data as described in Section 6.2 to minimize cache pollution by keeping unrelated data out.
Because of this page limitation the processors do not have terribly sophisticated logic to recognize prefetch patterns. With the still predominant 4k page size there is only so much which makes sense. The address range in which strides are recognized has been increased over the years, but it probably does not make much sense to go beyond the 512 byte window which is often used today. Currently prefetch units do not recognize non-linear access patterns. It is more likely than not that such patterns are truly random or, at least, sufficiently non-repeating that it makes no sense to try recognizing them.
If hardware prefetching is accidentally triggered there is only so much one can do. One possibility is to try to detect this problem and change the data and/or code layout a bit. This is likely to prove hard. There might be special localized solutions like using the ud2 instruction {Or non-instruction. It is the recommended undefined opcode.} on x86 and x86-64 processors. This instruction, which cannot be executed itself, is used after an indirect jump instruction; it is used as a signal to the instruction fetcher that the processor should not waste efforts decoding the following memory since the execution will continue at a different location. This is a very special situation, though. In most cases one has to live with this problem.
It is possible to completely or partially disable hardware prefetching for the entire processor. On Intel processors an Model Specific Register (MSR) is used for this (IA32_MISC_ENABLE, bit 9 on many processors; bit 19 disables only the adjacent cache line prefetch). This, in most cases, has to happen in the kernel since it is a privileged operation. If profiling shows that an important application running on a system suffers from bandwidth exhaustion and premature cache evictions due to hardware prefetches, using this MSR is a possibility.
6.3.2 Software Prefetching
The advantage of hardware prefetching is that programs do not have to be adjusted. The drawbacks, as just described, are that the access patterns must be trivial and that prefetching cannot happen across page boundaries. For these reasons we now have more possibilities, software prefetching the most important of them. Software prefetching does require modification of the source code by inserting special instructions. Some compilers support pragmas to more or less automatically insert prefetch instructions. On x86 and x86-64 Intel's convention for compiler intrinsics to insert these special instructions is generally used:
#include <xmmintrin.h>
enum _mm_hint
{
_MM_HINT_T0 = 3,
_MM_HINT_T1 = 2,
_MM_HINT_T2 = 1,
_MM_HINT_NTA = 0
};
void _mm_prefetch(void *p,
enum _mm_hint h);
Programs can use the _mm_prefetch intrinsic on any pointer in the program. Most processors (certainly all x86 and x86-64 processors) ignore errors resulting from invalid pointers which make the life of the programmer significantly easier. If the passed pointer references valid memory, though, the prefetch unit will be instructed to load the data into cache and, if necessary, evict other data. Unnecessary prefetches should definitely be avoided since this might reduce the effectiveness of the caches and it consumes memory bandwidth (possibly for two cache lines in case the evicted cache line is dirty).
The different hints to be used with the _mm_prefetch intrinsic are implementation defined. That means each processor version can implement them (slightly) differently. What can generally be said is that _MM_HINT_T0 fetches data to all levels of the cache for inclusive caches and to the lowest level cache for exclusive caches. If the data item is in a higher level cache it is loaded into L1d. The _MM_HINT_T1 hint pulls the data into L2 and not into L1d. If there is an L3 cache the _MM_HINT_T2 hints can do something similar for it. These are details, though, which are weakly specified and need to be verified for the actual processor in use. In general, if the data is to be used right away using _MM_HINT_T0 is the right thing to do. Of course this requires that the L1d cache size is large enough to hold all the prefetched data. If the size of the immediately used working set is too large, prefetching everything into L1d is a bad idea and the other two hints should be used.
The fourth hint, _MM_HINT_NTA, is special in that it allows telling the processor to treat the prefetched cache line specially. NTA stands for non-temporal aligned which we already explained in Section 6.1. The program tells the processor that polluting caches with this data should be avoided as much as possible since the data is only used for a short time. The processor can therefore, upon loading, avoid reading the data into the lower level caches for inclusive cache implementations. When the data is evicted from L1d the data need not be pushed into L2 or higher but, instead, can be written directly to memory. There might be other tricks the processor designers can deploy if this hint is given. The programmer must be careful using this hint: if the immediate working set size is too large and forces eviction of a cache line loaded with the NTA hint, reloading from memory will occur.
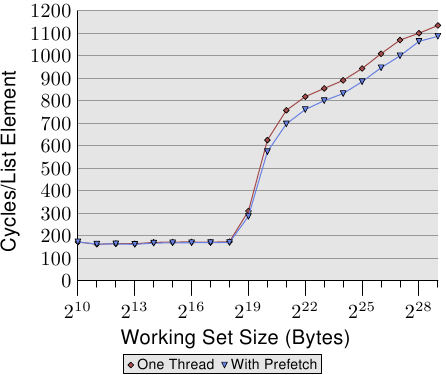
Figure 6.7: Average with Prefetch, NPAD=31
Figure 6.7 shows the results of a test using the now familiar pointer chasing framework. The list is randomized. The difference to previous test is that the program actually spends some time at each list node (about 160 cycles). As we learned from the data in Figure 3.15, the program's performance suffers badly as soon as the working set size is larger than the last-level cache.
We can now try to improve the situation by issuing prefetch requests ahead of the computation. I.e., in each round of the loop we prefetch a new element. The distance between the prefetched node in the list and the node which is currently worked on must be carefully chosen. Given that each node is processed in 160 cycles and that we have to prefetch two cache lines (NPAD=31), a distance of five list elements is enough.
The results in Figure 6.7 show that the prefetch does indeed help. As long as the working set size does not exceed the size of the last level cache (the machine has 512kB = 219B of L2) the numbers are identical. The prefetch instructions do not add a measurable extra burden. As soon as the L2 size is exceeded the prefetching saves between 50 to 60 cycles, up to 8%. The use of prefetch cannot hide all the penalties but it does help a bit.
AMD implements, in their family 10h of the Opteron line, another instruction: prefetchw. This instruction has so far no equivalent on the Intel side and is not available through intrinsics. The prefetchw instruction prefetches the cache line into L1 just like the other prefetch instructions. The difference is that the cache line is immediately put into 'M' state. This will be a disadvantage if no write to the cache line follows later. If there are one or more writes, they will be accelerated since the writes do not have to change the cache state—that already happened when the cache line was prefetched.
Prefetching can have bigger advantages than the meager 8% we achieved here. But it is notoriously hard to do right, especially if the same binary is supposed to perform well on a variety of machines. The performance counters provided by the CPU can help the programmer analyze prefetches. Events which can be counted and sampled include hardware prefetches, software prefetches, useful software prefetches, cache misses at the various levels, and more. In Section 7.1 we will introduce a number of these events. All these counters are machine specific.
When analyzing programs one should first look at the cache misses. When a large source of cache misses is located one should try to add a prefetch instruction for the problematic memory accesses. This should be done in one place at a time. The result of each modification should be checked by observing the performance counters measuring useful prefetch instructions. If those counters do not increase the prefetch might be wrong, it is not given enough time to load from memory, or the prefetch evicts memory from the cache which is still needed.
gcc today is able to emit prefetch instructions automatically in one situation. If a loop is iterating over an array the following option can be used:
-fprefetch-loop-arrays
The compiler will figure out whether prefetching makes sense and, if so, how far ahead it should look. For small arrays this can be a disadvantage and, if the size of the array is not known at compile time, the results might be worse. The gcc manual warns that the benefits highly depend on the form of the code and that in some situation the code might actually run slower. Programmers have to use this option carefully.
6.3.3 Special Kind of Prefetch: Speculation
The OOO execution capability of a processor allows moving instructions around if they do not conflict with each other. For instance (using this time IA-64 for the example):
st8 [r4] = 12 add r5 = r6, r7;; st8 [r18] = r5
This code sequence stores 12 at the address specified by register r4, adds the content of registers r6 and r7 and stores it in register r5. Finally it stores the sum at the address specified by register r18. The point here is that the add instruction can be executed before—or at the same time as—the first st8 instruction since there is no data dependency. But what happens if one of the addends has to be loaded?
st8 [r4] = 12 ld8 r6 = [r8];; add r5 = r6, r7;; st8 [r18] = r5
The extra ld8 instruction loads the value from the address specified by the register r8. There is an obvious data dependency between this load instruction and the following add instruction (this is the reason for the ;; after the instruction, thanks for asking). What is critical here is that the new ld8 instruction—unlike the add instruction—cannot be moved in front of the first st8. The processor cannot determine quickly enough during the instruction decoding whether the store and load conflict, i.e., whether r4 and r8 might have same value. If they do have the same value, the st8 instruction would determine the value loaded into r6. What is worse, the ld8 might also bring with it a large latency in case the load misses the caches. The IA-64 architecture supports speculative loads for this case:
ld8.a r6 = [r8];; [... other instructions ...] st8 [r4] = 12 ld8.c.clr r6 = [r8];; add r5 = r6, r7;; st8 [r18] = r5
The new ld8.a and ld8.c.clr instructions belong together and replace the ld8 instruction in the previous code sequence. The ld8.a instruction is the speculative load. The value cannot be used directly but the processor can start the work. At the time when the ld8.c.clr instruction is reached the content might have been loaded already (given there is a sufficient number of instructions in the gap). The arguments for this instruction must match that for the ld8.a instruction. If the preceding st8 instruction does not overwrite the value (i.e., r4 and r8 are the same), nothing has to be done. The speculative load does its job and the latency of the load is hidden. If the store and load do conflict the ld8.c.clr reloads the value from memory and we end up with the semantics of a normal ld8 instruction.
Speculative loads are not (yet?) widely used. But as the example shows it is a very simple yet effective way to hide latencies. Prefetching is basically equivalent and, for processors with fewer registers, speculative loads probably do not make much sense. Speculative loads have the (sometimes big) advantage of loading the value directly into the register and not into the cache line where it might be evicted again (for instance, when the thread is descheduled). If speculation is available it should be used.
6.3.4 Helper Threads
When one tries to use software prefetching one often runs into problems with the complexity of the code. If the code has to iterate over a data structure (a list in our case) one has to implement two independent iterations in the same loop: the normal iteration doing the work and the second iteration, which looks ahead, to use prefetching. This easily gets complex enough that mistakes are likely.
Furthermore, it is necessary to determine how far to look ahead. Too little and the memory will not be loaded in time. Too far and the just loaded data might have been evicted again. Another problem is that prefetch instructions, although they do not block and wait for the memory to be loaded, take time. The instruction has to be decoded, which might be noticeable if the decoder is too busy, for instance, due to well written/generated code. Finally, the code size of the loop is increased. This decreases the L1i efficiency. If one tries to avoid parts of this cost by issuing multiple prefetch requests in a row (in case the second load does not depend on the result of the first) one runs into problems with the number of outstanding prefetch requests.
An alternative approach is to perform the normal operation and the prefetch completely separately. This can happen using two normal threads. The threads must obviously be scheduled so that the prefetch thread is populating a cache accessed by both threads. There are two special solutions worth mentioning:
- Use hyper-threads (see Figure 3.22) on the
same core. In this case the prefetch can go into L2 (or even L1d).
- Use “dumber” threads than SMT threads which can do
nothing but prefetch and other simple operations. This is an option
processor manufacturers might explore.
The use of hyper-threads is particularly intriguing. As we have seen on Figure 3.22, the sharing of caches is a problem if the hyper-threads execute independent code. If, instead, one thread is used as a prefetch helper thread this is not a problem. To the contrary, it is the desired effect since the lowest level cache is preloaded. Furthermore, since the prefetch thread is mostly idle or waiting for memory, the normal operation of the other hyper-thread is not disturbed much if it does not have to access main memory itself. The latter is exactly what the prefetch helper thread prevents.
The only tricky part is to ensure that the helper thread is not running too far ahead. It must not completely pollute the cache so that the oldest prefetched values are evicted again. On Linux, synchronization is easily done using the futex system call [futexes] or, at a little bit higher cost, using the POSIX thread synchronization primitives.
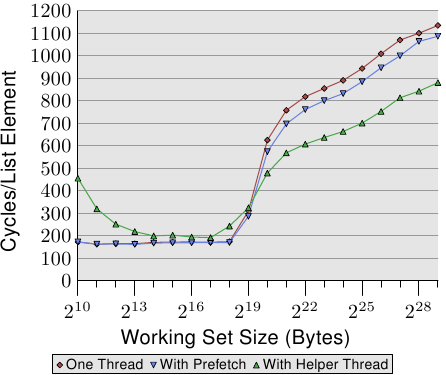
Figure 6.8: Average with Helper Thread, NPAD=31
The benefits of the approach can be seen in Figure 6.8. This is the same test as in Figure 6.7 only with the additional result added. The new test creates an additional helper thread which runs about 100 list entries ahead and reads (not only prefetches) all the cache lines of each list element. In this case we have two cache lines per list element (NPAD=31 on a 32-bit machine with 64 byte cache line size).
The two threads are scheduled on two hyper-threads of the same core. The test machine has only one core but the results should be about the same if there is more than one core. The affinity functions, which we will introduce in Section 6.4.3, are used to tie the threads down to the appropriate hyper-thread.
To determine which two (or more) processors the OS knows are hyper-threads, the NUMA_cpu_level_mask interface from libNUMA can be used (see Section 12).
#include <libNUMA.h>
ssize_t NUMA_cpu_level_mask(size_t destsize,
cpu_set_t *dest,
size_t srcsize,
const cpu_set_t*src,
unsigned int level);
This interface can be used to determine the hierarchy of CPUs as they are connected through caches and memory. Of interest here is level 1 which corresponds to hyper-threads. To schedule two threads on two hyper-threads the libNUMA functions can be used (error handling dropped for brevity):
cpu_set_t self;
NUMA_cpu_self_current_mask(sizeof(self),
&self);
cpu_set_t hts;
NUMA_cpu_level_mask(sizeof(hts), &hts,
sizeof(self), &self, 1);
CPU_XOR(&hts, &hts, &self);
After this code is executed we have two CPU bit sets. self can be used to set the affinity of the current thread and the mask in hts can be used to set the affinity of the helper thread. This should ideally happen before the thread is created. In Section 6.4.3 we will introduce the interface to set the affinity. If there is no hyper-thread available the NUMA_cpu_level_mask function will return 1. This can be used as a sign to avoid this optimization.
The result of this benchmark might be surprising (or maybe not). If the working set fits into L2, the overhead of the helper thread reduces the performance by between 10% and 60% (ignore the smallest working set sizes again, the noise is too high). This should be expected since, if all the data is already in the L2 cache, the prefetch helper thread only uses system resources without contributing to the execution.
Once the L2 size is exhausted the picture changes, though. The prefetch helper thread helps to reduce the runtime by about 25%. We still see a rising curve simply because the prefetches cannot be processed fast enough. The arithmetic operations performed by the main thread and the memory load operations of the helper thread do complement each other, though. The resource collisions are minimal which causes this synergistic effect.
The results of this test should be transferable to many other situations. Hyper-threads, often not useful due to cache pollution, shine in these situations and should be taken advantage of. The sys file system allows a program to find the thread siblings (see the thread_siblings column in Table 5.3). Once this information is available the program just has to define the affinity of the threads and then run the loop in two modes: normal operation and prefetching. The amount of memory prefetched should depend on the size of the shared cache. In this example the L2 size is relevant and the program can query the size using
sysconf(_SC_LEVEL2_CACHE_SIZE)
Whether or not the progress of the helper thread must be restricted depends on the program. In general it is best to make sure there is some synchronization since scheduling details could otherwise cause significant performance degradations.
6.3.5 Direct Cache Access
One sources of cache misses in a modern OS is the handling of incoming data traffic. Modern hardware, like Network Interface Cards (NICs) and disk controllers, has the ability to write the received or read data directly into memory without involving the CPU. This is crucial for the performance of the devices we have today, but it also causes problems. Assume an incoming packet from a network: the OS has to decide how to handle it by looking at the header of the packet. The NIC places the packet into memory and then notifies the processor about the arrival. The processor has no chance to prefetch the data since it does not know when the data will arrive, and maybe not even where exactly it will be stored. The result is a cache miss when reading the header.
Intel has added technology in their chipsets and CPUs to alleviate this problem [directcacheaccess]. The idea is to populate the cache of the CPU which will be notified about the incoming packet with the packet's data. The payload of the packet is not critical here, this data will, in general, be handled by higher-level functions, either in the kernel or at user level. The packet header is used to make decisions about the way the packet has to be handled and so this data is needed immediately.
The network I/O hardware already has DMA to write the packet. That means it communicates directly with the memory controller which potentially is integrated in the Northbridge. Another side of the memory controller is the interface to the processors through the FSB (assuming the memory controller is not integrated into the CPU itself).
The idea behind Direct Cache Access (DCA) is to extend the protocol between the NIC and the memory controller. In Figure 6.9 the first figure shows the beginning of the DMA transfer in a regular machine with North- and Southbridge.
DMA Initiated DMA and DCA Executed Figure 6.9: Direct Cache Access
The NIC is connected to (or is part of) the Southbridge. It initiates the DMA access but provides the new information about the packet header which should be pushed into the processor's cache.
The traditional behavior would be, in step two, to simply complete the DMA transfer with the connection to the memory. For the DMA transfers with the DCA flag set the Northbridge additionally sends the data on the FSB with a special, new DCA flag. The processor always snoops the FSB and, if it recognizes the DCA flag, it tries to load the data directed to the processor into the lowest cache. The DCA flag is, in fact, a hint; the processor can freely ignore it. After the DMA transfer is finished the processor is signaled.
The OS, when processing the packet, first has to determine what kind of packet it is. If the DCA hint is not ignored, the loads the OS has to perform to identify the packet most likely hit the cache. Multiply this saving of hundreds of cycles per packet with tens of thousands of packets which can be processed per second, and the savings add up to very significant numbers, especially when it comes to latency.
Without the integration of I/O hardware (NIC in this case), chipset, and CPUs such an optimization is not possible. It is therefore necessary to make sure to select the platform wisely if this technology is needed.
Security
Preventing brute force ssh attacks
Repeatedly trying to log in via ssh using multiple username/password pairs, is a common attack against systems; it works often enough that relatively unsophisticated attackers ("script kiddies") continue to try to exploit it. As with most internet threats, this one, known as a brute force ssh attack, rises and falls in popularity; it currently seems to be on the upswing. There are a number of techniques that can be used to reduce the effectiveness of this attack, starting with the most obvious: pick good passwords.
These attacks cannot succeed, in any sensible length of time, if the passwords on all the accounts are well-chosen, long, and contain a mix of numbers, upper and lower case, and punctuation. Bruce Schneier has good advice on choosing a password based on his research into passwords and guessing algorithms. But it is difficult to ensure that all passwords on a system conform or that some new guessing scheme doesn't happen to randomly hit upon the same password a user chose. Because of that, other evasive measures are often used.
One of the drawbacks to being subjected to a brute force attack is the bandwidth and processing power needed to deal with the log in attempts, even if unsuccessful. A simple way to avoid that, at least for most unsophisticated attackers, is to simply run the ssh server at a port other than 22. Legitimate users can be told what port to use, while unsophisticated attackers will not find a server to connect to. An attacker using Nmap, or a similar port scanning tool, will find the ssh server pretty quickly, though.
In a similar vein, port knocking hides the server by only enabling it after getting a certain sequence of connection requests. For example, a server could wait until it got a connection to port 1037, followed by connections to 42 and 6666, in quick succession from the same IP address, before it would open up port 22 (or some other port to combine with the above) for ssh traffic. After a timeout of a minute or so, the port would be closed down again.
Both port knocking and changing the port rely on "security through obscurity," which is no defense against a determined attacker, but may be just fine to convince a script kiddie to move on to an easier target. Anyone who has access to the traffic bound for the server, though, will be able to spot ssh to a non-standard port as well as port knocking. To repel more sophisticated attackers, who may be targeting specific hosts, rather than trawling, other techniques can be used.
An effective countermeasure against repeated connections is to ban the offending IP address for some period of time. There are several mechanisms to do this, one of the most straightforward is to use iptables to limit the number of ssh connections per minute to some small number. If a host exceeds that limit, its IP address is not allowed to make ssh connections for another minute. This slows down the traffic rather severely, but does have some drawbacks: iptables cannot distinguish between successful and unsuccessful log ins, so a fourth log in attempt would fail even if the previous three had been successful.
Other tools, such as Fail2ban, monitor the ssh server log file to determine if there are too many failures, based on configurable criteria, from a given host and then modify firewall or tcp_wrapper rules to stop the offending host from connecting for some period of time. All of the techniques that ban IP addresses are effective against hosts that are used again and again. It is not inconceivable that a botnet could be used to do a distributed brute force attack which, depending on how many hosts were available and the timeouts on the server, might be very effective.
Perhaps the most secure solution of all is eliminating passwords entirely, as long as the other endpoints are reasonably secured. The ssh server can be configured to not allow password authentication, only accepting connections from users that have their public key stored in the authorized_keys file. An attacker that gets access to the corresponding private key will have an easy entry to the host system, so this technique must be used carefully.
Brute force attacks against ssh are more annoying than they are dangerous generally, but they can lead to intrusions. An intrusion of even a regular user account is only a privilege escalation bug away from being a complete takeover of the system. It makes sense to monitor log files periodically to determine if your host is being attacked and to take appropriate countermeasures.
(For more details, see this article at the samhain labs website.)
New vulnerabilities
dhcp: buffer overflow
| Package(s): | dhcp | CVE #(s): | CVE-2007-5365 | ||||||||||||||||||||
| Created: | October 18, 2007 | Updated: | October 30, 2007 | ||||||||||||||||||||
| Description: | The DHCP server has a buffer overflow vulnerability. DHCP does not correctly allocate space for network replies. This can be used by a malicious DHCP client to create a buffer overflow and possibly execute arbitrary code on the server machine. | ||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||
drupal: multiple vulnerabilities
| Package(s): | drupal | CVE #(s): | CVE-2007-5593 CVE-2007-5594 CVE-2007-5595 CVE-2007-5596 CVE-2007-5597 | ||||||||||||
| Created: | October 24, 2007 | Updated: | December 7, 2007 | ||||||||||||
| Description: | From the Fedora advisory:
- Upgrade to 5.3, fixes: - HTTP response splitting. - Arbitrary code execution. - Cross-site scripting. - Cross-site request forgery. - Access bypass. | ||||||||||||||
| Alerts: |
| ||||||||||||||
flac: arbitrary code execution
| Package(s): | flac | CVE #(s): | CVE-2007-4619 | ||||||||||||||||||||||||||||||||
| Created: | October 22, 2007 | Updated: | January 21, 2008 | ||||||||||||||||||||||||||||||||
| Description: | From the Red Hat advisory:
A security flaw was found in the way flac processed audio data. An attacker could create a carefully crafted FLAC audio file in such a way that it could cause an application linked with flac libraries to crash or execute arbitrary code when it was opened. (CVE-2007-4619) | ||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||
gnome-screensaver: keyboard lock bypass
| Package(s): | gnome-screensaver | CVE #(s): | CVE-2007-3920 | ||||||||||||||||||||||||
| Created: | October 24, 2007 | Updated: | October 15, 2009 | ||||||||||||||||||||||||
| Description: | From the Ubuntu advisory:
Jens Askengren discovered that gnome-screensaver became confused when running under Compiz, and could lose keyboard lock focus. A local attacker could exploit this to bypass the user's locked screen saver. | ||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||
libpng: several vulnerabilities
| Package(s): | libpng | CVE #(s): | CVE-2007-5266 CVE-2007-5267 CVE-2007-5268 CVE-2007-5269 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | October 19, 2007 | Updated: | March 23, 2009 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | Certain chunk handlers in libpng before 1.0.29 and 1.2.x before 1.2.21
allow remote attackers to cause a denial of service (crash) via crafted (1)
pCAL (png_handle_pCAL), (2) sCAL (png_handle_sCAL), (3) tEXt
(png_push_read_tEXt), (4) iTXt (png_handle_iTXt), and (5) ztXT
(png_handle_ztXt) chunking in PNG images, which trigger out-of-bounds read
operations. (CVE-2007-5269)
pngrtran.c in libpng before 1.0.29 and 1.2.x before 1.2.21 use (1) logical instead of bitwise operations and (2) incorrect comparisons, which might allow remote attackers to cause a denial of service (crash) via a crafted PNG image. (CVE-2007-5268) Off-by-one error in ICC profile chunk handling in the png_set_iCCP function in pngset.c in libpng before 1.2.22 beta1 allows remote attackers to cause a denial of service (crash) via a crafted PNG image, due to an incorrect fix for CVE-2007-5266. (CVE-2007-5267) Off-by-one error in ICC profile chunk handling in the png_set_iCCP function in pngset.c in libpng before 1.0.29 beta1 and 1.2.x before 1.2.21 beta1 allows remote attackers to cause a denial of service (crash) via a crafted PNG image that prevents a name field from being NULL terminated. (CVE-2007-5266) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
nagios-plugins: buffer overflow
| Package(s): | nagios-plugins | CVE #(s): | CVE-2007-5198 | ||||||||||||||||||||||||||||||||
| Created: | October 23, 2007 | Updated: | April 17, 2008 | ||||||||||||||||||||||||||||||||
| Description: | Buffer overflow in the redir function in check_http.c in Nagios Plugins before 1.4.10 allows remote web servers to execute arbitrary code via long Location header responses (redirects). | ||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||
openssl: off-by-one error
| Package(s): | openssl | CVE #(s): | CVE-2007-4995 | ||||||||||||||||||||
| Created: | October 23, 2007 | Updated: | May 13, 2008 | ||||||||||||||||||||
| Description: | Off-by-one error in the DTLS implementation in OpenSSL 0.9.8 before 0.9.8f and 0.9.7 allows remote attackers to execute arbitrary code via unspecified vectors. | ||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||
php: multiple vulnerabilities
| Package(s): | php | CVE #(s): | CVE-2007-3799 CVE-2007-3998 CVE-2007-4659 CVE-2007-4658 CVE-2007-4670 CVE-2007-4661 | ||||||||||||||||||||||||||||||||||||||||
| Created: | October 23, 2007 | Updated: | May 19, 2008 | ||||||||||||||||||||||||||||||||||||||||
| Description: | From the Red Hat advisory:
Various integer overflow flaws were found in the PHP gd extension. A script that could be forced to resize images from an untrusted source could possibly allow a remote attacker to execute arbitrary code as the apache user. (CVE-2007-3996) A previous security update introduced a bug into PHP session cookie handling. This could allow an attacker to stop a victim from viewing a vulnerable web site if the victim has first visited a malicious web page under the control of the attacker, and that page can set a cookie for the vulnerable web site. (CVE-2007-4670) A flaw was found in the PHP money_format function. If a remote attacker was able to pass arbitrary data to the money_format function this could possibly result in an information leak or denial of service. Note that is is unusual for a PHP script to pass user-supplied data to the money_format function. (CVE-2007-4658) A flaw was found in the PHP wordwrap function. If a remote attacker was able to pass arbitrary data to the wordwrap function this could possibly result in a denial of service. (CVE-2007-3998) A bug was found in PHP session cookie handling. This could allow an attacker to create a cross-site cookie insertion attack if a victim follows an untrusted carefully-crafted URL. (CVE-2007-3799) A flaw was found in handling of dynamic changes to global variables. A script which used certain functions which change global variables could be forced to enable the register_globals configuration option, possibly resulting in global variable injection. (CVE-2007-4659) An integer overflow flaw was found in the PHP chunk_split function. If a remote attacker was able to pass arbitrary data to the third argument of chunk_split they could possibly execute arbitrary code as the apache user. Note that it is unusual for a PHP script to use the chunk_split function with a user-supplied third argument. (CVE-2007-4661) | ||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||
reprepro: authentication bypass
| Package(s): | reprepro | CVE #(s): | CVE-2007-4739 | ||||
| Created: | October 24, 2007 | Updated: | October 24, 2007 | ||||
| Description: | From the Debian advisory:
It was discovered that reprepro, a tool to create a repository of Debian packages, when updating from a remote site only checks for the validity of known signatures, and thus does not reject packages with only unknown signatures. This allows an attacker to bypass this authentication mechanism. | ||||||
| Alerts: |
| ||||||
tikiwiki: arbitrary code execution
| Package(s): | tikiwiki | CVE #(s): | CVE-2007-5423 | ||||||||
| Created: | October 22, 2007 | Updated: | November 15, 2007 | ||||||||
| Description: | From the Gentoo advisory:
An attacker could execute arbitrary code with the rights of the user running the web server by passing a specially crafted parameter string to the tiki-graph_formula.php file. | ||||||||||
| Alerts: |
| ||||||||||
tramp: insecure tmpfile creation
| Package(s): | tramp | CVE #(s): | CVE-2007-5377 | ||||
| Created: | October 22, 2007 | Updated: | October 24, 2007 | ||||
| Description: | From the Gentoo advisory:
A local attacker could create symbolic links in the directory where the temporary files are written, pointing to a valid file somewhere on the filesystem that is writable by the user running TRAMP. When TRAMP writes the temporary file, the target valid file would then be overwritten with the contents of the TRAMP temporary file. | ||||||
| Alerts: |
| ||||||
xscreensaver, tempest: screen lock bypass
| Package(s): | xscreensaver, tempest | CVE #(s): | CVE-2007-5585 | ||||||||||||||||||||
| Created: | October 24, 2007 | Updated: | November 6, 2007 | ||||||||||||||||||||
| Description: | From the Fedora advisory:
A bug was reported that xscreensaver unlocking password dialog crashes randomly. It is found this problem occurs when GL hack is launched without gl helper binary installed. | ||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||
xulrunner, firefox, thunderbird: multiple vulnerabilities
| Package(s): | xulrunner, firefox, thunderbird | CVE #(s): | CVE-2007-1095 CVE-2007-2292 CVE-2007-3511 CVE-2007-5334 CVE-2007-5337 CVE-2007-5338 CVE-2007-5339 CVE-2007-5340 CVE-2006-2894 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | October 22, 2007 | Updated: | May 12, 2008 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | From the Debian advisory:
CVE-2007-1095: Michal Zalewski discovered that the unload event handler had access to the address of the next page to be loaded, which could allow information disclosure or spoofing. CVE-2007-2292: Stefano Di Paola discovered that insufficient validation of user names used in Digest authentication on a web site allows HTTP response splitting attacks. CVE-2007-3511: It was discovered that insecure focus handling of the file upload control can lead to information disclosure. This is a variant of CVE-2006-2894. CVE-2007-5334: Eli Friedman discovered that web pages written in Xul markup can hide the titlebar of windows, which can lead to spoofing attacks. CVE-2007-5337: Georgi Guninski discovered the insecure handling of smb:// and sftp:// URI schemes may lead to information disclosure. This vulnerability is only exploitable if Gnome-VFS support is present on the system. CVE-2007-5338: "moz_bug_r_a4" discovered that the protection scheme offered by XPCNativeWrappers could be bypassed, which might allow privilege escalation. CVE-2007-5339: L. David Baron, Boris Zbarsky, Georgi Guninski, Paul Nickerson, Olli Pettay, Jesse Ruderman, Vladimir Sukhoy, Daniel Veditz, and Martijn Wargers discovered crashes in the layout engine, which might allow the execution of arbitrary code. CVE-2007-5340: Igor Bukanov, Eli Friedman, and Jesse Ruderman discovered crashes in the Javascript engine, which might allow the execution of arbitrary code. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
zoph: missing input sanitizing
| Package(s): | zoph | CVE #(s): | CVE-2007-3905 | ||||||||
| Created: | October 19, 2007 | Updated: | October 25, 2007 | ||||||||
| Description: | It was discovered that zoph, a web based photo management system, performs insufficient input sanitizing, which allows SQL injection. | ||||||||||
| Alerts: |
| ||||||||||
Page editor: Jake Edge
Kernel development
Brief items
Kernel release status
The current 2.6 prepatch is 2.6.24-rc1, released by Linus on October 23. As Linus noted when tagging the release:
See the article below for this week's update on what was merged before the window closed. There's also the short-form changelog for a list of patches or the long changelog for all the details.
As of this writing, no patches have been merged into the mainline git repository since the -rc1 release. There have also been no -mm releases over the last week.
For older kernels: 2.6.20.21 was released on October 17 with a few dozen patches including a couple of security fixes. 2.6.16.56-rc1 came out on October 20; it has a dozen or so patches, again with a couple of security fixes.
Kernel development news
Quotes of the week
And partly to send the signal that rather than beavering away on new features all the time, we should also be spending some (more) time testing, reviewing and bugfixing the current and soon-to-be-current code.
New maintainers for the x86 architecture
At the kernel summit in September, Andi Kleen, the maintainer of the i386 and x86_64 architecture code, stated that he would not maintain that code if it was merged into the unified x86 architecture. He appears to have not changed his mind on that score; a patch merged for 2.6.24 states that the x86 maintainers will be Thomas Gleixner, Ingo Molnar, and H. Peter Anvin. The x86 code is clearly in good hands, but it is sad to see Andi bow out; we owe him a lot of thanks for maintaining the architectures that most of us use for so long.Merged for 2.6.24, part 2
The 2.6.24 merge window has now closed; more than 7000 changesets were merged before 2.6.24-rc1 was released. The bulk of the new features for 2.6.24 were described last week. Here's a summary of patches merged since then, starting with user-visible changes:
- There are new drivers for Marvell Libertas 8385/6 wireless chips,
Freescale 3.0Gbps SATA controllers, Fujitsu laptops (LCD brightness in
particular), and TI AR7 watchdog devices.
- Another set of old Open Sound System drivers has been removed from the
kernel.
- The "uninitialized block groups" feature has been merged into the
ext4 filesystem. UBG helps to speed filesystem checks by keeping
track of which parts of a disk partition have never been used, and,
thus, do not require checking.
- As was discussed back in
August, the binary sysctl() interface has been marked
deprecated, and the code for many of the sysctl targets (much of which
appears to not have worked for some time) has been removed. There is
a new checker which looks for problematic sysctl definitions;
according to Eric Biederman, "
As best as I can determine all of the several hundred errors spewed on boot up now are legitimate.
" - The semantics of the CAP_SETPCAP capability have been
changed. In previous kernels, this capability gave a process the
ability to bestow new capabilities upon another process; now, instead,
it allows a process to set capabilities within its own "inherited"
mask.
- Process CPU time accounting (via taskstats) has been augmented with
information allowing CPU usage time to be scaled by CPU frequency.
- The Control Groups (formerly process containers) patch
set has been merged. Control groups will allow the CFS group
scheduling feature to be used; it will also be the control mechanism
used for containers in general.
- Process ID namespaces have been added; this feature lets container
implementations create a different view of the list of processes on
the system for every container.
- The kernel markers patch
set has been merged.
- The CIFS filesystem now has access control list (ACL) support.
- The old, unmaintained Fibre Channel support code has been removed.
Changes visible to kernel developers include:
- The process of merging the i386 and x86_64 architectures continues,
with many files having been merged by the time the window closed.
This job is far from complete, though. For the curious, this message from Ingo Molnar talks a bit
about what is going on there. "
The x86 architecture is the most common Linux architecture after all - and users care much more about having a working kernel than they care about cleanups and unifications.... This cannot be realistically finished in v2.6.24, without upsetting the codebase.
" - The paravirt_ops structure has been split into several smaller, more
specialized operations vectors. These include pv_init_ops
(boot-time operations), pv_time_ops (for time-related
operations), pv_cpu_ops (privileged instructions),
pv_irq_ops (interrupt handling), pv_mmu_ops (page
table management), and a few others.
- There are some new bit operations which have been added:
int test_and_set_bit_lock(unsigned long nr, unsigned long *addr); void clear_bit_unlock(unsigned long nr, unsigned long *addr); void __clear_bit_unlock(unsigned long nr, unsigned long *addr);These operations are intended to be used in the creation of single-bit locks; they work without the need for any additional memory barriers.
- There is a new KERN_CONT priority level for
printk(). It is, in fact, empty; it is meant to serve as a
marker for printk() calls which continue a previous (not
terminated with a newline) printed line.
- The watchdog device drivers have been moved to a new home at
drivers/watchdog.
- A notifier mechanism for console events has been added; this feature
is aimed at accessibility tools (like Speakup) which need to know when
something has changed on the console display.
- The filesystem export operations, used to make filesystems available
over protocols like NFS, have been reworked. Two new methods
(fh_to_dentry() and fh_to_parent()) replace the old
get_dentry() interface. There is a new structure (struct
fid) used to describe file handles. This work is aimed at making
the export interface easier to use and (eventually) supporting 64-bit
inode numbers.
- The virtio patches - providing an infrastructure for I/O into and out of virtualized guests - have been merged.
Now the stabilization period begins.
Various topics, all related to interrupts
An interrupt handler is the portion of a device driver which is charged with responding to interrupts from the hardware; at a minimum it should shut the hardware up and initiate any processing which needs to be performed. When your editor worked on the second edition of Linux Device Drivers, the prototype for interrupt handlers looked like this:
void handler(int irq, void *dev_id, struct pt_regs *regs);
The kernel development process is not particularly kind to book authors who, as a rule, prefer to see the ink dry on their creations before the text becomes obsolete. True to form, the handler prototype has changed a couple of times since LDD2, with the result that the 2.6.23 version looks like:
irqreturn_t handler(int irq, void *dev_id);
Along the way, interrupt handlers gained a return type (used to tell the kernel whether an interrupt was actually processed or not) and lost the processor registers argument. One would think that this interface (along with those who attempt to document it) had suffered enough, but, it seems, there will be no rest in the near future.
In particular, Jeff Garzik has proposed that the irq argument be removed from the interrupt handler prototype. There are very few interrupt handlers which actually use that argument currently. And, as it turns out, most of the remaining handlers do not actually need it; they are often using the interrupt number to identify the interrupting device, but the dev_id pointer already exists for just that purpose. Still, getting this patch into the kernel would require a significant amount of work, since every in-tree interrupt handler will have to be audited and fixed up.
So Jeff is taking it slowly; this is not a patch set which is aimed at
being merged for 2.6.24. Before it goes in, there is room for a lot of
useful work cleaning up the current use of the irq argument in
drivers, all of which would ease the eventual transition to the new call.
Handlers which really need the IRQ number can call the new
get_irqfunc_irq() function. But, says
Jeff, "I am finding a ton of bugs in each get_irqfunc_irq()
driver, so I would rather patiently sift through them, and push fixes and
cleanups upstream.
" Quite a few interrupt handler fixes resulting
from this work have already been posted.
Eric Biederman worries that converting all of the drivers could be a challenge; he has posted a proposal which would create two different interrupt registration and handler interfaces, allowing drivers which really need the IRQ number to continue to receive it. Jeff is confident that the extra structure will not be necessary, though. Thomas Gleixner, instead, would like to see the patches merged immediately, but it is almost certain that this patch set will be given one more development cycle to mature before going into the mainline.
Alexey Dobriyan, meanwhile, would like to fix up the interrupt-safe spinlock interface. Most code which requires a spinlock in the presence of interrupts calls:
void spin_lock_irqsave(spinlock_t *lock, unsigned long flags);
The flags variable is used by the (architecture-specific) code to save any interrupt state which may be needed when spin_unlock_irqrestore() is called. The problem with this interface is that it is not particularly type-safe. Developers have been known to use an int type instead of unsigned long; that usage will generate no errors and it will work fine on the x86 architecture. It will, however, fail in ugly ways on some other architectures.
So Alexey would like to turn flags into a new type (irq_flags_t). This type would initially be defined to be unsigned long, so the change would not break compilation. It would be annotated, though, so that the sparse utility could point out all of the places where spin_lock_irqsave() is called with an incorrect type. In the more distant future, when the changeover is complete, architecture maintainers would be able to redefine the type to whatever works best on their systems, be it a structure or a single byte.
Andrew Morton had a mixed response to the patch:
However I'd prefer that we have some really good reason for introducing irq_flags_t now. Simply so that I don't needlessly spend the next two years wrestling with literally thousands of convert-to-irq_flags_t patches and having to type "please use irq_flags_t here" in hundreds of patch reviews.
As an alternative, it was suggested that most calls of spin_lock_irqsave() should be changed to spin_lock_irq() instead. The latter version disables interrupts without saving the previous state; the accompanying spin_unlock_irq() call will then unconditionally re-enable interrupts. Those functions can be made to work, but only if it is known that interrupts will not have already been disabled when spin_lock_irq() is called. Otherwise the spin_unlock_irq() call risks enabling interrupts when some other part of the kernel expects them to still be disabled. The resulting random behavior is generally seen as undesirable by most computer users. So, in other words, spin_lock_irqsave() is a safer interface, which is why there is not a great deal of support for removing it. The prospect of well-intentioned kernel janitors changing code to spin_lock_irq() without really understanding the broader context is just too scary.
Finally, there was a discussion involving synchronize_irq() which illustrates just how hard it can be to get a handle on race conditions on multiprocessor systems. This function:
void synchronize_irq(unsigned int irq);
is intended to help coordinate actions between a driver's interrupt and non-interrupt code. At its core, it is a simple loop:
while (desc->status & IRQ_INPROGRESS)
cpu_relax();
In other words, synchronize_irq() will busy-wait until it is known that no handlers are running for the given interrupt. The idea is that any interrupt handler which might have been running before the call to synchronize_irq() will have completed when that function returns. The typical usage pattern is something like this:
some_important_flag = a_new_value;
synchronize_irq();
/* Code which depends on IRQ handler seeing a_new_value here */
With code like this, after the synchronize_irq() call, any interrupt handler will be guaranteed to see a_new_value - or so people think.
The problem is that contemporary processors will happily reorder memory operations to avoid pipeline stalls and improve performance; the what every programmer should know about memory series currently being serialized by LWN describes these issues in detail. What is relevant here is that the change to some_important_flag might be reordered (delayed) such that it does not become visible to other processors on the system until sometime after synchronize_irq() returns. During the window when the change is not visible, the promise of synchronize_irq() is not kept - an interrupt handler could run and see the old value, possibly creating mayhem as a result. That is the sort of obscure, one-in-a-billion race condition which keeps kernel hackers up at night.
Actually, kernel hacking and coffee keep kernel hackers up at night, but your editor's point should be clear.
Benjamin Herrenschmidt, upon finding this race, attempted to fix it with a memory barrier. After some discussion, though, it became clear that the memory barrier was not sufficient. Barriers can affect the order in which operations become visible, but they cannot, in the absence of corresponding barriers on another processor, guarantee that a specific change becomes visible to that processor at any given time. That sort of guarantee requires the use of a locked operation which forces synchronization between processors - the sort of operation which is typically used to implement spinlocks.
So the real solution appears to be this patch by Linus Torvalds and Herbert Xu. The while loop shown above persists in the new version, and it continues to run with no locks held - holding the interrupt descriptor lock when the interrupt subsystem may want it could lead to deadlocks. But, once it appears that no handlers are running, the descriptor lock is acquired and the status is checked one more time. If no handlers are running, the synchronize operation is complete; otherwise the code goes back to busy-waiting. The acquisition of the descriptor lock guarantees that memory barriers will have been executed on both sides of any potential race condition; that, in turn, will force the ordering of the memory operations. So, with this change in place, synchronize_irq() will truly synchronize with IRQ handlers and one more difficult race condition will have been eliminated.
LSM: loadable or static?
The ever-contentious Linux Security Modules (LSM) API is being debated once again on linux-kernel, not its removal, which Linus Torvalds came down firmly against, but whether it should allow security modules to be loaded dynamically. As part of 2.6.24, Torvalds merged a patch to convert LSM into a static interface, but has indicated a willingness to revert it. The key sticking point is whether there are real security modules that require the ability to be runtime-loaded.
A complaint by Thomas Fricaccia about the change caused Torvalds to put out a call for folks using module loading with their LSM code. The patch could be reverted if there are "real-world" uses for that ability. Torvalds again questions the sanity of security developers, but is clearly looking for someone to step up:
Jan Engelhardt responded with information about his MultiAdmin module, which allows multiple root users on a system, each with their own UID. This allows separate tracking of file ownership, resource usage and the like for each administrator. MultiAdmin also allows for the creation of sub-administrators who can perform some root activities for processes and files owned by a subset of users. The use case he cites is for professors being allowed to administer their students' accounts without getting full root privileges.
James Morris, who proposed the static LSM change, responded that MultiAdmin seemed to qualify as a real-world use under Torvalds's criteria. Though it is not clear that MultiAdmin requires a loadable interface, it does use it. The venerable root_plug security module – which only allows root processes to start if a particular USB device is plugged in – also implements loading and unloading. In both cases, configuration could be done via sysfs parameters with an enable flag to turn them on or off.
To some extent, for the examples offered so far, loading is a convenience for administrators, but the major users for unloading are developers. Crispin Cowan sums it up:
Other justifications for leaving the LSM loadable interface in the kernel have been less compelling. It is hard to imagine that the US Sarbanes-Oxley regulation would allow loading security modules into a running kernel, but not allow the kernel to be rebuilt as Fricaccia suggested. Inserting proprietary security modules that are provided from the vendor in a binary-only form seems foolhardy – this kind of potential abuse is the kind of hole Morris's patch was meant to close – but could be seen as a reason to allow LSM loading.
A compromise may have been found in a patch posted by Arjan van de Ven, which converts LSM to be either static or loadable depending on a compile-time kernel option. A consensus seems to be building that this is a reasonable approach, allowing distributions and users to decide for themselves whether they will allow security modules to be loaded. As of this writing, Torvalds has not weighed back in with a decision and the newly released 2.6.24-rc1 kernel has the static patch.
Dynamic loading of security modules is a potential source of problems – what better place for a rootkit to hide? – but there are valid reasons that someone might want to use it. Linux strives to be open to many uses, including some that the kernel hackers might find distasteful; dynamic security modules would seem to be one of those uses.
Patches and updates
Kernel trees
Core kernel code
Development tools
Device drivers
Documentation
Filesystems and block I/O
Networking
Security-related
Miscellaneous
Page editor: Jonathan Corbet
Distributions
News and Editorials
Unbreakable Linux vs. Unfakeable Linux
It was just about a year ago that Oracle announced its Unbreakable Linux offering. There was considerable speculation (here and here) on Oracle's motives for offering support for a Linux distribution that was essentially recompiled Red Hat Enterprise Linux. Red Hat countered this campaign with its own Unfakeable Linux campaign. The move seemed to many to be designed to undercut Red Hat's business. Oddly, to me at least, there was very little speculation about where Oracle would get their Linux sources if they did manage to impact Red Hat's business.
Fast forward one year, Linux-Watch
takes a look at how Unbreakable Linux is diverging from its parent, mostly
through the addition of packages such as the Oracle
Call Interface (OCI8) database driver for PHP and Yast (Yet Another Setup
Tool). These additions leave the original source code
untouched. Linux-Watch quotes Oracle Vice President of Linux Engineering
Wim Coekaerts: ""Oracle Enterprise Linux is compatible with RHEL and
what we do is provide a great support service on top of either or both. We
didn't launch a Linux distribution business; we started a Linux support
program. I think we have made that very clear many times."
"
CentOS contributor Dag Wieers doesn't
agree that Unbreakable Linux is still compatible with Unfakeable Linux
(RHEL). "Another well-hidden fact of Oracle's promotional buzz is
that you cannot both be compatible with RHEL, and provide bugfixes and
improvements. Either you make changes, or you stay compatible with the
original. So whatever Oracle stated was self-contradictory. All the
articles at the time failed to mention that, riding on Oracle's
wave.
"
Dag also notes (in a comment below the post) that "YaST does not
work on top of the OS, it cuts into most of the sysadmin tasks and often
breaks config-files that have been handcrafted. YaST actually requires that
start-up scripts and /etc/sysconfig-files are heavily modified.
"
Perhaps Oracle is introducing some incompatibility, but if Oracle's Unbreakable Linux diverges too much from the Unfakeable RHEL, Oracle loses. Oracle is not in the Linux Distribution business, nor does it want to be. Oracle does need a dependable platform that works well with its database products and Red Hat provides that platform. Oracle's Linux customers may not always know if a problem they have is in Oracle's database or somewhere in the OS. Why should they need to know that? One call to Oracle puts that problem in Oracle's lap, where it belongs. Oracle's Linux business is firmly tied to Red Hat's business now, and Oracle will suffer if Red Hat falters.
New Releases
Ubuntu 7.10 "Gutsy Gibbon" released
Ubuntu 7.10, Gutsy Gibbon, has been released. Gutsy contains many new packages including X.org 7.3, GNOME 2.20, the newly merged Compiz/Beryl and lots more. More information can be found by clicking below.Damn Small Linux 4.0 released
Damn Small Linux 4.0 has been released. The announcement contains a change log which notes an upgraded kernel from 2.4.26 to 2.4.31, new support modules: cloop, unionfs, ndiswrapper, fuse, and madwifi in support of kernel change and much more.
Distribution News
Mandriva Linux
The Mandriva Club is now open to all Linux users for free
The new Mandriva Club has been announced. "The Mandriva Club offers content and services for Mandriva Linux users, including: * a news feed with community articles and interviews * a knowledge base, with tips & tricks and a special zone for Linux newcomers * the RPM farm service for an easy access to online application packages and repositories * Bittorrent downloads with access to the final versions a few days before the release for early seeders * the official documentation * a personal blog service for community members * a nice e-cards service for the holiday season * access to a complete e-training program, with 25 free training modules * access to the Mandriva Expert support platform * an HCL database."
New Distributions
elpicx
elpicx is a live DVD Linux system that will help you prepare for the exams of the Linux Professional Institute Certification Program LPIC. elpicx 1.1 Dual-Boot-DVD (based on Knoppix 5.1.1 and CentOS 4.3) is the current version. Supported languages are German and English.
Distribution Newsletters
Fedora Weekly News Issue 106
The Fedora Weekly News for October 15, 2007 contains Ask Fedora, some Planet Fedora articles, marketing discussions, developments, the Fedora Board Recap, open fonts, and much more.Ubuntu Weekly News: Issue #62
Ubuntu Weekly News #62 is out, covering the release of Gutsy, the Ubuntu Developer Summit, Dell shipping Gutsy on desktops and laptops, and much more. Click below to read the issue.DistroWatch Weekly, Issue 225
The DistroWatch Weekly for October 22, 2007 is out. "It is dedicated to the recently released Mandriva Linux 2008, with a first look review at Mandriva's latest release, an interview with the company's Director of Engineering, and a brief note comparing the new releases from the traditional European Linux power houses - Mandriva and openSUSE. In the news section, Canonical releases impressive "Gutsy Gibbon", Fedora mulls development changes, KDE reaches its third beta, and Slackware updates Current branch. Finally, for those of you who enjoy the DistroWatch Page Hit Ranking statistics, don't miss the Site News section, which summarises a brief experiment that took place on the web site last week. It's a bumper issue, so get yourself a cup of coffee and enjoy the read!"
Distribution meetings
FOSDEM call for talks for the Debian devroom
Debian will have a devroom at FOSDEM 2008, February 23-24, 2008 in Brussels, Belgium. "Since that's "only" about four months from now, I'm hereby calling for talks. As usual, the deadline is "when my schedule is full", and talks that have a subject matter which involves Debian and which are appropriate for FOSDEM, given its somewhat technical background, will be accepted on a first come, first serve basis."
Newsletters and articles of interest
Yellow Dog Linux - PS3 user featured in Wired Magazine
Terra Soft has pointed out this Wired article about the work of Yellow Dog Linux user and HPC Consortium member Dr. Gaurav Khanna. "As the architect of this research, Dr. Gaurav Khanna is employing his so-called "gravity grid" of PS3s to help measure these theoretical gravity waves -- ripples in space-time that travel at the speed of light -- that Einstein's Theory of Relativity predicted would emerge when such an event takes place."
Interviews
Interview with Chitlesh Goorah on Fedora Electronics Lab
Chitlesh Goorah talks about the Fedora Electronics Lab. "At the very beginning, there was neither the intention for a Fedora Electronic Lab nor its spin. During my post-graduate studies in Micro-Nano Electronic Engineering, I needed VLSI simulation tools. I started packaging the VLSI simulation tools for Fedora, which I needed for my studies. Then MirjamWaeckerlin and my lecturers in Strasbourg, France, encouraged the concept of introducing Application-Specific Integrated Circuit (ASIC) Design Flows on Fedora, so that they can recommend to other students or use those tools themselves."
Distribution reviews
Battle of the Titans: Mandriva 2008 vs openSUSE 10.3 (TuxMachines)
TuxMachines compares Mandriva 2008.0 and openSUSE 10.3. "I've followed development of openSUSE and Mandriva fairly closely over the years, albeit a bit closer of openSUSE. I write about how nice they both are. I pick out the new features and test basic functionality. I see what's included and what makes up the base system. I like them both. But a visitor and contributor here at tuxmachines asked which would be better for his laptop and that gave me the idea to compare these large multi-CD Titans of Linux development. In the blue corner weighing in at 4.3 GB, Mandriva 2008.0. In the green corner weighing in at 4.2 GB, openSUSE 10.3."
What's New in Ubuntu 7.10? (O'ReillyNet)
Brian DeLacey reviews Ubuntu 7.10, a.k.a. Gutsy Gibbon, on O'Reilly's ONLamp site. "Ubuntu 7.10 adds highly attractive user interface elements with the inclusion of Compiz Fusion technology. This is instantly cool demo-ware. If you want to get a sense of what this functionality can do, visit Google Video and you will find impressively choreographed demonstrations by virtuosos of Compiz Fusion demonstrating their jazz of "Advanced Desktop Effects." Not only do these interface improvements look nice, but they can also help you productively manage multiple desktops and workspaces with numerous 3D effects. These have been wish list items for some time, and they have finally arrived. These effects require newer video cards for you to get the full benefit, but they degrade gracefully on older hardware lacking the required graphics horsepower."
'Vixta' Linux distro mimics Vista's look and feel (apc)
apc reviews Vixta, a Fedora-based distribution that is modeled after Windows Vista. "I don't know if Linus Torvalds has nightmares about Linux turning into Windows but some people definitely do. Linux Doesn't Need to Look Like Windows has been a popular and oft-visited article about Vixta on reddit since last week. It had spurred about 100 comments going back and forth about the merit of Vixta's user interface design and whether Linux should look like Windows."
Page editor: Rebecca Sobol
Development
The GIMP project releases version 2.4
The GIMP is a popular desktop application that compares favorably with the commercial Adobe Photoshop product:
Version 2.4 of The GIMP was announced this week, the informative project history page shows that this is the first major release in a long time. Version 2.2 was announced in December, 2004. The initial release of the software dates back to 1995.
The GIMP version 2.4 release notes list some of the new capabilities, here is a summary of the main changes:
- The menus have been changed to improve the user experience.
- The on screen status information has been improved.
- Image window status bars add hints for learning shortcuts and features.
- The GIMP now features a new default icon theme which supports the Tango Icon Theme Guidelines.
- A new top-level color menu has been added.
- The Selection Tools have been rewritten for easier learnability, resizing is now possible.
- A new assisted Foreground Select Tool has been added.
- A new Align Tool allows a list of layers, paths or guides to be aligned or distributed.
- The Crop Tool has been enhanced to behave more like other GIMP tools, it no longer performs move operations.
- A new Perspective Clone Tool allows cloning of image sections onto a perspective plane.
- A new brush size slider allows parametric and bitmap brush sizes to be scaled.
- The color picker can now sample colors outside of the GIMP windows.
- Improvements to the zooming system fix problems with the display of thin lines.
- The fullscreen editing mode now allows all of the tools to be hidden.
- A new Color Management system is in place for improving color consistency between the screen and printer output.
- The Printing system uses new gtk+ printing API improvements for better user control.
- A print preview image is now available.
- A new auto-magic filter has been added for easier red eye removal.
- A new Scheme interpreter has been added.
- A new preview widget for plug-ins has been added.
- The performance of various plug-ins have been improved.
- It is now possible for plug-ins to add top level menu entries.
- There is now support for the Photoshop ABR brush file format.
- Support for JPEG EXIF metadata has been improved.
- JPEG quality has been improved by normalizing compression parameters.
To sum it all up, version 2.4 of the GIMP adds a lot of usability improvements, simplifies common digital photography editing tasks and improves a lot of power-user capabilities. For further reading, Red Hat Magazine has published a review of a beta release of GIMP 2.4 with lots of screenshots.
The GIMP tutorials have a lot of useful information for learning the software. Source code and packages are available for download here.
System Applications
Database Software
Firebird 2.1 Beta 2 released
Version 2.1 Beta 2 of the Firebird DBMS has been announced. "This is the second Beta build of the Firebird version 2.1 series. It is for FIELD TESTING ONLY and should not be put into production systems."
Postgres Weekly News
The October 22, 2007 edition of the Postgres Weekly News is online with the latest PostgreSQL DBMS articles and resources.SQLAlchemy 0.4.0 released
Version 0.4.0 of SQLAlchemy, the Python SQL Toolkit and Object Relational Mapper, has been announced. "The first production release of 0.4 is now available. After six separate beta releases, the final 0.4 represents the hard work of many contributors with over a hundred new fixes and improvements after the the initial 0.4 beta1 release. 0.4 overall represents the largest overhaul SQLAlchemy has had yet, with its most refined and feature-filled ORM, SQL expression, and transactional APIs ever, all new documentation, a rewritten compiler, massive refactorings and speed refinements to the execution system and ORM, and more support for more databases, including experimental support for Sybase and MS Access."
Networking Tools
NagVis: 1.1.1 and 1.2b1 released (SourceForge)
Versions 1.1.1 and 1.2b1 of NagVis have been announced. "NagVis is a visualization addon for the well known network managment system Nagios. NagVis can be used to visualize Nagios Data, e.g. to display IT processes like a mail system or a network infrastructure. Today we release two new versions of NagVis. The first is a Bugfix release for the stable 1.1, it has the version number 1.1.1. The second release is the first beta release of our current developement version 1.2, it's version number is 1.2b1." Version 1.2b2 was also announced this week, it features bug fixes and new capabilities.
Web Site Development
Two new versions of mnoGoSearch
Two new versions of mnoGoSearch, a web site search engine, have been announced. For more details, see the changelog files for version 3.2.43 and version 3.3.5.
Miscellaneous
Paragent released as open-source software
Paragent, LLC has announced the first open-source release of its Paragent cross-platform desktop management software. "Paragent is a web-based tool for IT administrators that provides a unified service for hardware and software inventory, alerting, remote desktop and help desk. Paragent delivers these tools in an easy-to-use interface, with one-click access, and site-wide built-in advanced search capabilities. Paragent is a combination of applications, including Lisp-based servers collecting data, C++ agents on the client machines, and Java tools for the remote desktop component."
Desktop Applications
Animation Software
Initial release of the prefuse visualization toolkit (SourceForge)
The initial release of the prefuse visualization toolkit has been announced. The software is described as: "A Java-based toolkit for building interactive information visualization applications. Prefuse supports a rich set of features for data modeling, visualization, animation, and interaction. Flare is a new prefuse-based toolkit for ActionScript 3 and the Flash Player, intended for creating visualizations that more seamlessly embed into the web."
Audio Applications
Vamp plugin SDK v1.1b now available
Version 1.1b of Vamp plugin SDK has been released. "Vamp is a plugin API for audio analysis and feature extraction plugins written in C or C++. Its SDK features an easy-to-use set of C++ classes for plugin and host developers, a reference host implementation, example plugins, and documentation. It is supported across Linux, OS/X and Windows. Version 1.1b is a minor update with a small number of build and bug fixes."
Business Applications
Pentaho Open BI Suite 1.6 GA released (SourceForge)
Version 1.6 GA of Pentaho Open BI Suite has been announced. Pentaho is: "A complete business intelligence platform that includes reporting, analysis (OLAP), dashboards, data mining and data integration (ETL). Use it as a full suite or as individual components that are accessible via web services. Ranked #1 in open source BI. Pentaho Corp., creator of the world's most popular open source business intelligence (BI) suite, announces delivery of Pentaho Open BI Suite 1.6. The new release provides general availability of major new enhancements including an enterprise BI metadata layer that streamlines use of BI data as well as a thin-client reporting interface enabling business users to create their own ad hoc queries and reports."
Desktop Environments
GNOME 2.20.1 released
Version 2.20.1 of the GNOME desktop has been released. "This is the first update to GNOME 2.20.0. The update fixes all known and unknown crashers, even for those modules which haven't released a new version (AKA gnome-terminal). The next development release contains all crashers ported from 2.20. The release team wants your tarballs on November 10 23:59 UTC, although you could release your tarball earlier as well."
GARNOME 2.20.1 released
Version 2.20.1 of GARNOME, the bleeding edge version of the GNOME desktop, is out. "This is the second release of the current stable GNOME branch, and the first bug-fixing release ironing out yet-more bugs, hopefully adding yet-more stability, and ships with the latest and greatest stable releases. As usual it includes updates and fixes after the official GNOME freeze, together with a host of third-party GNOME packages, Bindings and the Mono(tm) Platform."
GNOME Software Announcements
The following new GNOME software has been announced this week:- goocanvasmm 0.3.0 (code cleanup)
- Sysprof Linux Profiler 1.0.9 (unspecified)
- Tinymail pre-release 0.0.3 (new features, bug fixes and documentation work)
KDE 4.0 Beta 3 Released
The beta 3 release of KDE 4.0 has been announced. "The KDE Community is happy to release the third Beta for KDE 4.0. This Beta is aimed at further polishing of the KDE codebase and also marks the freeze of the KDE Development Platform. We are joined in this release by the KOffice project which releases its 4th alpha release, bringing many improvements in OpenDocument support, a KChart Flake shape and much more to those willing to test. Since the last Beta, most of KDE has been frozen for new features, instead receiving the necessary polish and bugfixing."
KDE Commit-Digest (KDE.News)
The October 21, 2007 edition of the KDE Commit-Digest has been announced. The content summary says: "Fortune-teller and Keyboard Layout applets for Plasma, KNewsTicker resurrected for KDE 4.0 as a Plasmoid. Rewrite of <canvas> tag support in KHTML. Various new language syntax highlighting in Kate. Internal database storage work in Digikam. More playlist handling work, and support for Magnatune "streaming membership" in Amarok 2. OpenDocument loading of charts in KChart for KOffice 2..."
KDE Software Announcements
The following new KDE software has been announced this week:- GradeL 0.8.13 (unspecified)
- indywikia 0.8.3 (unspecified)
- KGtk 0.9.3 (bug fixes and translation work)
- Kisa 0.43 (new features and bug fixes)
- KSquirrel 0.7.2 (new features and bug fixes)
- Kvkbd 0.4.7 (new feature)
- lnkMusic 0.2.21 (new features and bug fixes)
- Merge Konsole Windows 0.00 (initial release)
- Piklab 0.15.0 (new features and bug fixes)
- Qosmic 1.1 (new features and bug fixes)
- Snippits 0.5 (bug fixes)
- StarDict 3 3.0.1 (unspecified)
- TCgui 0.93 (unspecified)
- TorK 0.21 (new features and bug fixes)
- WineRar 0.52b (translation work)
- xmppstatusbot 0.3 (new feature and bug fix)
- Zhu3D 3.0.9 (new features)
Xorg Software Announcements
The following new Xorg software has been announced this week:- xf86-video-nv 2.1.6 (bug fixes and code cleanup)
Electronics
GNU Radio 3.1.0 released
Stable version 3.1.0 of GNU Radio, an interface to an open software programmable radio system, is out. "While 3.1.0 is based on the current development trunk that many are familiar with, it has been a full year since the last stable branch was cleaved from the trunk. The changes between then and now are many and varied".
pcb 20070912 announced
Version 20070912 of PCB, a printed circuit CAD application, has been announced. "This release represents nearly 200 commits and as such this summary clearly is not complete."
Music Applications
Q version 7.8 released
Version 7.8 of Q, a GPLed, modern-style functional programming language with good library support for multimedia and computer music applications, has been released. "I've just released Q 7.8 which sports some important bugfixes and some nice new features. The most important addition probably is that Q now has a complete Qt interface. You can find the sources and a ready-made RPM for Linux (which contains almost everything surrounding Q, including the interfaces to Faust, MidiShare, Pd and SuperCollider and the multimedia examples) on the Q download page".
Office Suites
OxygenOffice Professional 2.3.0 released (SourceForge)
Version 2.3.0 of OxygenOffice Professional has been announced. "OxygenOffice Professional (was: OpenOffice.org Premium) is an enhanced version of OpenOffice.org what is a multi-platform office productivity suite. OxygenOffice Professional contains more extras like templates, cliparts, samples, fonts and VBA support. The OxygenOffice Professional Team is proudly anounce the latest and greatest version of OxygenOffice Professional."
Web Browsers
Mitchell Baker: Beyond Sustainability
Mitchell Baker has posted a sort of annual report on the state of the Mozilla project. Mozilla brought in almost $67 million last year, while spending less than $20 million. "Tens of thousands of people are involved in the Mozilla project. Over 1,000 people contributed code to Firefox 2. Mozilla employed around 50 of those people. In 2006, approximately 10,000 people downloaded nightly builds every day; this number continues to grow. Sixteen thousand people reported bugs or potential issues in our bug-tracking system; something like a thousand comments a day were added to the issue-tracker."
Mozilla Links Newsletter
The October 18, 2007 edition of the Mozilla Links Newsletter is online, take a look for the latest news about the Mozilla browser and related projects.
Miscellaneous
Introducing Stepic: Python Steganography in Images (domnit.org)
domnit.org presents an introduction to Stepic. "Steganography is the hiding of data within other data. Stepic is my new Python module and command line tool for hiding arbitrary data within images by slightly modifying the colors. These modifications are generally imperceptible to humans, but are machine detectable."
Steve.Museum: Tagger 2.0 released (SourceForge)
Version 2.0 of Tagger from Steve.Museum has been announced. ""Steve is a collaborative research project exploring the potential for user-generated descriptions of the subjects of works of art to improve access to museum collections and encourage engagement with cultural content."
Languages and Tools
Caml
Caml Weekly News
The October 23, 2007 edition of the Caml Weekly News is out with new Caml language articles.
JSP
JSLoader: Version 1.0.0 released (SourceForge)
Version 1.0.0 of JSLoader has been announced. "JSLoader is a dead-simple, non-intrusive "Javascript-on-demand" packaging convention which helps developers and the internet community rapidly develop and prototype applications without the headache of figuring out the witches' brew of files that need to be copied, included, etc."
Python
Python-URL! - weekly Python news and links
The October 22, 2007 edition of the Python-URL! is online with a new collection of Python article links.
Tcl/Tk
Tcl-URL! - weekly Tcl news and links
The October 18, 2007 edition of the Tcl-URL! is online with new Tcl/Tk articles and resources.Tcl-URL! - weekly Tcl news and links
The October 23, 2007 edition of the Tcl-URL! is online with new Tcl/Tk articles and resources.
XML
XForms Thick Clients (O'Reilly)
Jack Cox works with XForms on O'Reilly. "Jack Cox explains an approach to building XForms client applications that work in a disconnected environment."
IDEs
Emonic: 0.3 released (SourceForge)
Version 0.3 of Emonic has been announced. "Emonic (Eclipse-Mono-Integration) is a Eclipse-Plugin for C#. It provides color-highlighting, outline, word-completion and build mechanism via Ant or Nant. Tested on Linux and Windows with Mono and the Win-.net-framework. With the just published version 0.3 the project reaches beta status. Many new features including quick outline, a improved icon-set, better parsing of the source code and improved build process are implemented. With the new version the license of the plugin changes from cpl to epl."
Version Control
Mercurial 0.9.5 released
Version 0.9.5 of Mercurial a source control management system, has been announced. This release adds new features and extensions and includes a number of bug fixes.
Page editor: Forrest Cook
Linux in the news
Recommended Reading
What does the Linux desktop really need? (Linux Magazine)
Joe "Zonker" Brockmeier analyzes areas where the Linux desktop could improve in a Linux Magazine article. "On the one hand, you can easily argue that Linux doesn't lack for applications -- and, to a certain extent, that's true. Scour Freshmeat for a few minutes, and you'll find a gazillion and one apps for Linux. Many of which are useful, actively maintained, and at a point in development where they're ready for production use. But, the question is whether users can find the applications that they need to do their job. In some cases, Linux apps just aren't up to the task just yet. In particular, I've noticed a few areas where you're not likely to find suitable tools on the Linux desktop."
13 reasons why Linux should be on your desktop (DesktopLinux)
DesktopLinux has a guest column with thirteen reasons Linux should be on your desktop. "Vista is a Wagner Opera that is usually late to start, takes too long to finish, and is spoilt by floorboards creaking under the weight of the cast. Mac OS X Leopard, meanwhile, is the late show in an exclusive nightclub where the drinks are always too expensive. In contrast, the Linux desktop is the free show in the park across the street -- it imposes some discomforts on the audience, but provides plenty of entertainment."
Trade Shows and Conferences
Firebird Conference coverage
Photos and Blog entries from the 2007 Firebird DBMS conference have been posted. "The 2007 Firebird Conference convened from October 18-20 in Hamburg, Germany."
Companies
EU Win Over Microsoft Gives Ball To Linux -- Can It Run With It? (InformationWeek)
InformationWeek takes a look at Microsoft's decision to stop appealing the European Union's antitrust ruling along with the impact of that decision on Linux and free software. "Proclaiming victory, the European Commission on Monday said Microsoft has agreed to make interoperability information available to open source developers for a one-time payment of 10,000 Euros (about $14,000 U.S.). Microsoft also dropped its previous demand that developers licensing such information also pay hefty sums to license related patents as well. For developers that choose to license the patents (it's now optional), Microsoft has reduced royalty fees from 5.95% to 0.4%."
Novell Offers Channel Linux Bundle (Linux-Watch)
Linux-Watch reports on the latest Linux software Bundle from Novell. "Novell Open Workgroup Suite Small Business Edition, a SUSE Linux-based desktop-to-server solution tailored to meet the needs of small businesses, combines the flexibility and cost efficiency of open-source software with the support of Novell and its partners. The suite provides small businesses with productivity tools and a networking infrastructure at a fraction of the cost of alternative, proprietary-only software bundles such as Windows Small Business Server 2003 R2. The suite includes not just the server software, but five copies of SLED (SUSE Linux Enterprise Desktop) 10 Service Pack 1."
RIP Linux "Greenphone" (LinuxDevices)
LinuxDevices reports that Trolltech is discontinuing its Greenphone hardware platform in favor of other available platforms, including the Neo1973 OpenMoko phone. "Schilling said Trolltech will continue to support the Greenphone and Neo1973, while extending its family of supported development hardware platforms to encompass a variety of device types. He hinted that a WiFi-enabled hardware design of some kind might be next in line -- no surprise given Trolltech's success with VoIP phones. He noted that 'the Neo1973 does not have WiFi, and that has been a major criticism.'"
Linux Projects' Best Kept Secret (TuxMachines)
TuxMachines takes a look at Webpath Technologies, the parent company of On-Disk.com. "There are a total of 42 developers earning money at On-Disk.com. Some of the projects being supported include Wolvix Linux, Ark Linux, Frugalware Linux, SymphonyOS, Berry Linux, Zenwalk Linux, Goblinx, Feather Linux, PCLinuxOS, and dynebolic. Karlie Robinson, of Webpath Technologies, states, "And some of our projects aren't Distros at all. Projects like Glest (Open Source Turn-based game), Smart Technology for Smarter Business (tutorials for commercial office software), Ray Larabie/Typodermic (Fonts) to name a few." They also participate in Fedora Sponsorships and other disc donations."
Legal
Getting Inventive With Software Patents (Linux Journal)
Glyn Moody looks at the Open Invention Network. "The Open Invention Network (OIN) is a company set up in 2005 with investments from IBM, NEC, Novell, Philips, Red Hat and Sony. It has a war-chest of tens of millions of dollars (it won't give an exact figure) that enables it to buy software patents on the open market for the defence of the GNU/Linux ecosystem, which it does in a very novel way. OIN's growing collection of patents is available royalty-free to any company, institution or individual -- provided that the latter agrees not to assert its own patents against GNU/Linux, defined very broadly."
Microsoft Posts the New License Terms for Interoperability in the EU Agreement (Groklaw)
Groklaw examines Microsoft's posted license terms in the EU. "But it does mean, whether the EU Commission realizes it yet or not that Microsoft's number one competitor, Linux, is completely unable to be interoperable with Microsoft's patented code. I'm curious as to how that is helpful to the public who wish to have a choice."
Interviews
KDE and Distributions: ALT Linux Interview (KDE.News)
KDE.News interviews the developers of the ALT Linux distribution. "ALT Linux started with tailoring of Mandrake Linux for the Russian market. However, it soon became evident that full-fledged technical support and more extensive customization were impossible without having a package repository and establishing the distribution development cycle of our own. That is why we created Sisyphus, which is now one of world's 5 largest Linux-based Free Software repositories."
Interview with Mark Taylor, Pres. of UK Open Source Consortium, by Sean Daly (Groklaw)
Sean Daly talks with Mark Taylor, president of the UK Open Source Consortium about a variety of topics. Mark Taylor on Canonical: "Canonical are incredibly strong supporters of free software and speak about it on issues relating to the community and relating to the emerging industry, so people like Mark [Shuttleworth] get involved in the debate about software patents, and Canonical have made it very, very clear that, as a distribution, they will not be doing a deal with Microsoft, for example. They already speak strongly on issues affecting the industry, and it was really just a natural match. A number of the OSC member companies have done some public-sector work, some public-sector business here in the UK, so it was just natural for them to get involved. They are also very much involved in our iPlayer campaign as well."
Reviews
Product Review - The EmperorLinux Wasp CF-19 (Linux Journal)
Linux Journal reviews a rugged, Linux-powered notebook from EmperorLinux. "In this space, we're reviewing a laptop from Emperor's line of rugged laptops, the Wasp CF-19, which is the Linux edition of the Panasonic ToughBook CF-19. The Wasp, at 10.4", is the smallest of the ToughBooks; the larger 13.3" Tarantula and 15.4" Scarab (love those names, Emperor!) are also available from Emperor but not reviewed here."
GIMP 2.4 preview (Red Hat Magazine)
Red Hat Magazine has a screenshot-heavy preview of GIMP 2.4. "Color management was introduced in this version. You can use ICC color profiles, load and adjust them, get your image on screen looking exactly as it was produced by your camera or scanner, and have the final results printed just as they look on screen. GIMP will even make use of the color profiles embedded in images."
Publishing High-Quality Documents with Kile (LinuxWorld)
LinuxWorld reviews Kile, a front end for TeX and LaTeX. "Discerning typesetters have long relied on Tex and LaTeX for impeccable-looking documents. Now they have a front-end that works under Linux and BSD and brings control of the compilers and related utilities under the comprehensive graphical user interface. Authors and editors who use Kile can get increased productivity in the document creation business. This article will highlight some of Kile's key features which make it so attractive to newcomers to LaTeX."
Miscellaneous
How Linux Is Testing The Limits Of Open Source Development (InformationWeek)
InformationWeek has a lengthy article on the kernel development process. "Yet Torvalds can't let off the gas, for two reasons. First, Linux can't afford to fall behind technically, or it'll lose ever-demanding business users. The new kernel, for example, has hooks to take advantage of the latest virtualization capabilities embedded in Intel and Advanced Micro Devices processors. Second, Linux needs to feed its developer community. New features keep coders from getting bored and moving on to other projects, and they attract new talent as coders age or drop out of the process."
ExploitMe: Free Firefox Plug-Ins Test Web Apps (Dark Reading)
Dark Reading covers
the upcoming release of free Firefox plug-ins that test common web
application vulnerabilities. As with most security tools, they could be
used for good or ill. "The ExploitMe tools -- which are in
currently in beta form -- include SQL Inject-Me, which lets you right-click
on an HTML field in your Firefox browser and inject it with SQL injection
payloads, and XSS-Me, which works the same way, but with XSS. The tools
developers also plan to release Web services exploit tools as well.
"
Page editor: Forrest Cook
Announcements
Non-Commercial announcements
FFII: EU tells open source to start paying MS patent tax
Here's a press release from FFII on the recent agreement between the European Union and Microsoft. "Neelie Kroes European Commissioner for Competition and Microsoft agreed that the royalties payable for the interoperability information will be 10,000 Euros, and that Microsoft can use its EPO software patents to charge 0.4 percent of all the sales of its competitors. The FFII says that these conditions effectively exclude open source competitors and add costs for all who wish to communicate with Microsoft products."
Commercial announcements
ACCESS Connect Ecosystem Partner Program announces new members
ACCESS CO., LTD. has announced seven new partners to the ACCESS Connect Ecosystem partner program. "ACCESS CO., LTD., a global provider of advanced software technologies to the mobile and beyond-PC markets, today reinforced its commitment to strengthening cooperation among mobile industry players with the addition of seven new partners to its ACCESS(TM) Connect Ecosystem (ACE) partner program. The ACE partner program is designed to create an ecosystem of world-class partners that will unleash the potential of the digital life generation by driving development and adoption of new mobile converged technologies and solutions. In the short eight months since its creation, the program has rapidly grown to include 73 members."
Collaborative Software partners with CollabNet
Collaborative Software Initiative has announced a partnership with CollabNet. "Collaborative Software Initiative (CSI), which introduces a market-changing process that applies open source methodologies to business communities facing common IT challenges, today announced it is partnering with CollabNet, the leading provider of collaborative software development solutions for distributed organizations. CSI will use CollabNet's development platform to facilitate collaboration among its customers to share the cost of meeting the same compliance, regulatory and public service requirements."
Everex and Koolu announce partnership
Everex has announced a partnership with Koolu. "Everex, a world leader in the design and production of personal computers and Koolu, an organization renowned for their thin client devices and key members of the FOSS community, today announced a business alliance to further develop and promote open source, eco-friendly computing products for the mass market. "Everex is thrilled to be working with a high caliber company like Koolu," states John Lin, general manager at Everex. "With their expertise in software and service and our prowess in delivering mainstream computing products, we feel confident in furthering our many shared initiatives.""
Message Partners announces Email archival solutions
Message Partners has announced a new Email archival solution for Linux servers. "Our email archive solution is suitable for compliance and data mining applications and offers extremely fast search and retrieval of email databases with many millions of records. Our solution integrates a number of leading open source technology components such as MySQL, Sphinx and others, but MPP is the heart of our solution. Our total email compliance solution offers email archival, content filtering, message stamping, surveillance, attachment controls and more. Our solution is not only compatible with Postfix, Sendmail and QMail, but can also archive MS Exchange and other Window's based systems."
Turbolinux does the Microsoft deal
Microsoft has announced that Turbolinux is the latest to sign a "collaboration" deal which includes, of course, "intellectual property assurance." "Delivering value requires a vision for how to design mixed-source solutions that tackle clear customer priorities and a framework for sharing intellectual property. When strong Microsoft customers are evaluating Linux, we want them to see Turbolinux as the distribution that works best with their existing Microsoft investments."
N810 device program opens
Nokia has announced a program to get its new N810 tablet into the hands of people who can make it better for a reduced price. "The call is addressed not only to open source programmers, but also to designers, documentation writers, community supporters, maemo evangelists, bloggers..." Up to 500 devices will be made available (for €99) under this program.
PIKA extends appliance offering to Linux community
Pika Technologies Inc. has announced PIKA Warp for Linux. "PIKA Technologies Inc., a developer of media-processing hardware and software, today announced the release of its Appliance for Linux, the second member of PIKA Warp, its new Appliance family. It provides Linux computer telephony (CT) application developers with a smaller-sized and lower-cost alternative to traditional off-the-shelf computers and plug-in board network connectivity."
RedCannon Security adds secure OpenOffice access
RedCannon Security has announced KeyPoint Alchemy with support for OpenOffice.org. "RedCannon Security, a trusted provider of centrally managed, secure mobile-access solutions for the enterprise, today announced direct support for OpenOffice applications through KeyPoint enabled USB flash drives. The combined solution empowers mobile workers by allowing OpenOffice applications to be pushed to any USB stick, while ensuring through its KeyPoint solutions that only "trusted" or "locked-down" versions of OpenOffice applications are used."
Schwartz: ZFS Puts Net App Viability at Risk?
Sun CEO Jonathan Schwartz reveals Sun's plans in the Network Appliance patent suit. "In addition to seeking the removal of their products from the marketplace, we will be going after sizable monetary damages. And I am committing that Sun will donate half of those proceeds to the leading institutions promoting free software and patent reform (in specific, The Software Freedom Law Center and the Peer to Patent initiative), and to the legal defense of free software innovators. We will continue to fund the aggressive reexamination of spurious patents used against the community (which we've been doing behind the scenes on behalf of several open source innovators). Whatever's left over will fuel a venture fund fostering innovation in the free software community."
Announcing the LAPP Virtual Appliance
Virtual Appliance has announced a easy to install system with PostgreSQL, phpPgAdmin, Apache and Zeroconf. "This virtual appliance the easiest and fastest way to get PostgreSQL running. In addition to our usual Virtual Appliance features, this server includes... Our LAPP Virtual Appliance is a complete LAPP solution, is based on Ubuntu and is only 130MB to download for a full Ubuntu 7.04 Server Edition installation."
New Books
GIS for Web Developers--New from Pragmatic Bookshelf
Pragmatic Bookshelf has published the book GIS for Web Developers by Scott Davis.iPod: The Missing Manual, 6th Edition--New from O'Reilly Media
O'Reilly has published the book iPod: The Missing Manual, 6th Edition by J.D. Biersdorfer with David Pogue.Rapid GUI Programming with Python and Qt - new from Prentice Hall
Prentice Hall has published the book Rapid GUI Programming with Python and Qt: The Definitive Guide to PyQt Programming by Mark Summerfield.sendmail, 4th Edition--New from O'Reilly Media
O'Reilly has published the book sendmail, 4th Edition by Bryan Costales, George Jansen, Claus Aßmann, and Gregory Shapiro.Tomcat: The Definitive Guide, 2nd Edition--New from O'Reilly Media
O'Reilly has published the book Tomcat: The Definitive Guide, 2nd Edition by Jason Brittain and Ian F. Darwin.The Unofficial LEGO MINDSTORMS NXT Inventor's Guide--New from No Starch Press
No Starch Press has published the book The Unofficial LEGO MINDSTORMS NXT Inventor's Guide by David J. Perdue.
Upcoming Events
Brian Behlendorf to launch Alfresco Community Event
Alfresco Software, Inc. has announced the keynote speaker for the Alfresco North American Community Conference. "Alfresco Software, Inc., the first and leading provider of open source enterprise content management solutions, today announced that open source guru Brian Behlendorf will be keynote speaker at the inaugural Alfresco North American Community Conference in New York, on Wednesday, November 7, 2007. His presentation, "The Threat of Microsoft SharePoint to Open Source," will take place at 10 a.m. ET."
Events: November 1, 2007 to December 31, 2007
The following event listing is taken from the LWN.net Calendar.
| Date(s) | Event | Location |
|---|---|---|
| October 28 November 2 |
Ubuntu Developer Summit | Cambridge, Massachusetts, USA |
| October 29 November 1 |
Fall VON Conference and Expo | Boston, MA, USA |
| October 31 November 1 |
LinuxWorld Conference & Expo | Utrecht, Netherlands |
| November 1 November 2 |
The Linux Foundation Japan Symposium | Tokyo, Japan |
| November 2 | 5th ACM Workshop on Recurring Malcode | Alexandria, VA, USA |
| November 2 November 3 |
Embedded Linux Conference, Europe | Linz, Austria |
| November 2 November 4 |
Real-Time Linux Workshop | Linz, Austria |
| November 3 | Linux-Info-Tag Dresden | Dresden, Germany |
| November 5 November 9 |
Python Bootcamp with Dave Beazley | Atlanta, USA |
| November 7 | NLUUG 25th anniversary conference | Beurs van Berlage, Amsterdam, The Netherlands |
| November 7 | Alfresco North American Community Conference 2007 | New York, NY, USA |
| November 8 November 9 |
Blog World Expo | Las Vegas, NV, USA |
| November 10 November 11 |
Linuxtage | Essen, NRW, Germany |
| November 11 November 17 |
Large Installation System Administration Conference | Dallas, TX, USA |
| November 12 November 16 |
Ruby on Rails Bootcamp with Charles B. Quinn | Atlanta, USA |
| November 12 November 15 |
OWASP & WASC AppSec 2007 Conference | San Jose, USA |
| November 12 November 16 |
ApacheCon US 2007 | Atlanta, GA, USA |
| November 13 November 14 |
IV Latin American Free Software Conference | Foz do Iguacu, Brazil |
| November 15 November 18 |
Piksel07 | Bergen, Norway |
| November 15 | Alfresco European Community Conference | Paris, France |
| November 16 November 18 |
aKademy-es 2007 | Zaragoza, Spain |
| November 20 November 23 |
DeepSec ISDC 2007 | Vienna, Austria |
| November 22 November 23 |
Conferencia Rails Hispana | Madrid, Spain |
| November 24 | LinuxDay in Vorarlberg (Deutschland, Schweiz, Liechtenstein und Österreich) | Dornbirn, Austria |
| November 26 November 29 |
Open Source Developers' Conference | Brisbane, Australia |
| November 28 November 30 |
Mono Summit 2007 | Madrid, Spain |
| November 29 November 30 |
PacSec 2007 | Tokyo, Japan |
| December 1 | Django Worldwide Sprint | Online, World |
| December 1 | London Perl Workshop 2007 | London, UK |
| December 4 December 8 |
FOSS.IN 2007 | Bangalore, India |
| December 7 December 8 |
Free Software Conference Scandinavia | Gotherburg, Sweden |
| December 7 December 8 |
PGCon Brazil | Sao Paulo, Brazil |
| December 10 | Paris on Rails (2nd Edition) | Paris, France |
| December 11 December 12 |
3rd DoD Open Conference: Deployment of Open Technologies and Architectures within Military Systems | Vienna, VA, USA |
| December 15 December 22 |
Unix Meeting 2007 | IRC, Worldwide |
| December 27 December 30 |
24th Chaos Communication Congress | Berlin, Germany |
If your event does not appear here, please tell us about it.
Audio and Video programs
The debut of Tim Blechmann's re-reading album
Tim Blechmann has released a downloadable audio work entitled re-reading under the Free Software Series label. "Debut album from the PD master Tim Blechmann (now living in Vienna). Many programmers try to show off the possibilities of their programs, instead Tim achieves the most focus and rigorous contemporary electronic music that I heard since Dion Workman."
Page editor: Forrest Cook