
Measuring and improving buffered I/O
There are two types of file I/O on Linux, buffered I/O, which goes through the page cache, and direct I/O, which goes directly to the storage device. The performance of buffered I/O was reported to be a lot worse than direct I/O, especially for one specific test, in Luis Chamberlain's topic proposal for a session at the 2024 Linux Storage, Filesystem, Memory Management, and BPF Summit. The proposal resulted in a lengthy mailing-list discussion, which also came up in Paul McKenney's RCU session the next day; Chamberlain led a combined storage and filesystem session to discuss those results with an eye toward improving buffered I/O performance.
Testing goals
He began by outlining his goals with the testing, which were to measure the limits of the page cache and to find ways that page-cache performance could be improved. In order to improve the performance, it needs to be measured; in particular, there needs to be a way to avoid introducing performance regressions as part of the work. He has done a lot of testing of the page cache, but there is a need to try to distinguish between normal and pathological use cases.
Based on the tests that he has done, and a suggestion for a "normal" test case from Chris Mason, he wondered if it seemed reasonable to try to achieve throughput parity between buffered and direct I/O on a six-drive, RAID 0 configuration. Dave Chinner said "absolutely not"; he does not think it is possible to get parity between the two types of I/O in that configuration. Chamberlain suggested that the summit would be a good place to work out what the right tools, tests, and configurations would be to try to measure and improve page-cache performance (thus, buffered I/O performance).
The pathological test case that he presented in the topic proposal is the one that got the most attention. On a well-resourced system, he reported 86GB/s writes for direct I/O and only 7GB/s writes using buffered I/O. That is a huge difference; he wondered whether it was acceptable or is something that should be investigated and, perhaps, fixed.
Chamberlain said that there were some other outcomes from the thread. Matthew Wilcox reported a problem with 64-byte random reads, which resulted in a patch from Linus Torvalds; Kent Overstreet did some preliminary testing and found that it provided a 25% performance improvement. Torvalds was not interested in pushing the patch any further, but Chamberlain said he is testing it some more to see that it does not crash.
He described a few other things that came up in the thread, some of which were addressed with patches. But the results from the pathological case seem to be unexpected; what should be done about that?
These kinds of discussions are always about tradeoffs, Ted Ts'o said; you trade some amount of safety, which you may not care about depending on the workload, for improvement on a microbenchmark. There may or may not be user-space applications that actually care about the operations measured in the microbenchmark, as well. For example, he does not know of any real-world application that needs to be able to do 64-byte random reads.
It takes work to determine if these things make a difference to real-world applications, he continued, and more work to ensure that whatever changes are being considered do not break other applications and make things worse. There is a philosophical question that needs to be answered about whether it even makes sense to spend the time to investigate any given problem.
He contrasted the problems being discussed with the torn-write problem, which has a clear and obvious benefit for database performance if it gets solved; whether that is also true about providing high-performance for 64-byte I/O is unclear to him. In the absence of a customer, "is it worth it?" But Wilcox said that the 64-byte-read problem came from a real (and large) Linux-using customer.
Ts'o's point is valid, Chamberlain said, but his goal in the session was not to come up with areas to address; he wanted to raise some of the questions that arose from his testing.
Not unexpected
Chinner said that the numbers from the pathological test were not unexpected. Part of the problem is that buffered I/O has a single writeback thread per filesystem, so that I/O cannot go any faster than that. The writeback thread is CPU-bound; "it is not that the page cache is slow, it is cleaning the page cache that's slow", he said. There are hacks to get around that limitation somewhat, but what needs to be looked at is some way to parallelize cleaning the page cache. That could be multiple writeback threads, using writethrough instead, or some other mechanism; the architecture of the page cache is not scalable for the cleanup part. Writethrough means that writes go into the page cache, but are also written to storage immediately.
Chamberlain wondered if there was general agreement with Chinner in the room. Wilcox said that he did not disagree, but that how the scaling is to be done is an interesting question. For example, a single huge file that needs writeback to be done in multiple places will be harder to scale than dealing with multiple small or medium-size files that need writeback.
Chinner said that much of the CPU time in writeback is spent scanning the page cache looking for pages that need to be written, which does not really change based on the size of the files. There are some filesystem-specific considerations as well, but a pure-overwrite workload will have higher writeback rates because the amount of scanning needed is less; at that point it runs into contention for the LRU lock. Adding more threads into that mix will not help at all and may make things worse.
One of the workloads that Chinner runs frequently simulates an untar operation with lots of files, each of which gets created, 4KB is written to it, and it gets closed. XFS gets stuck at around 50K files/s (roughly 200MB/s) on a device that can normally handle 7-8GB/s; the limitation is the single writeback thread. The rate goes way up (to 600K files/s or 2.4GB/s) if he does a flush when the file is closed, which simulates a writethrough mechanism. The writeback problem for this workload is trivially parallelizable, but that is not always true. The key problem is how to get the data out of the page cache and to the disk as efficiently as possible.
Jan Kara said that it would be difficult to add more writeback threads because there are assumptions that there is only one at various levels. He and Chinner discussed ways to do so, though it sounds like there would be quite a bit of work. Part of the reason it has not really been investigated, perhaps, is that SSDs are so fast that there is less of a push to optimize these kinds of things, Ts'o said. Getting a, say, 20% benefit on an untar-and-build workload, which already runs quickly, is not all that compelling.
There may be opportunities to simply turn off writeback on certain classes of devices, since writethrough performs so much better on high-end SSDs, Ts'o said. Chamberlain wondered if switching to writethrough would help solve the buffered I/O atomic-write problem; Chinner said that it could. With that, the session ran out of time, though there was talk of picking it back up at BoF session later in the summit.
| Index entries for this article | |
|---|---|
| Kernel | Buffered I/O |
| Conference | Storage, Filesystem, Memory-Management and BPF Summit/2024 |
Posted Jun 5, 2024 21:43 UTC (Wed)
by willy (subscriber, #9762)
[Link] (2 responses)
Posted Jun 6, 2024 22:05 UTC (Thu)
by Heretic_Blacksheep (guest, #169992)
[Link] (1 responses)
Posted Jun 6, 2024 22:10 UTC (Thu)
by willy (subscriber, #9762)
[Link]
Posted Jun 6, 2024 10:16 UTC (Thu)
by epa (subscriber, #39769)
[Link] (2 responses)
Maybe when there is a backlog of more than a certain number of pages to write back, any new write operations should switch to write-through?
Posted Jun 6, 2024 14:09 UTC (Thu)
by pj (subscriber, #4506)
[Link] (1 responses)
Posted Jun 6, 2024 15:12 UTC (Thu)
by Paf (subscriber, #91811)
[Link]
Posted Jun 6, 2024 15:10 UTC (Thu)
by Paf (subscriber, #91811)
[Link] (7 responses)
FWIW, the file system I work - Lustre - is moving towards a “hybrid” model where larger buffered IOs are redirected to do direct IO via an internal bounce buffer to solve the alignment requirement. Since there’s no cache, the required copy and allocation for that buffer can be multithreaded and the performance results are excellent - can hit 20 GiB/s from one user thread and scales when adding threads:
Posted Jun 6, 2024 16:04 UTC (Thu)
by Wol (subscriber, #4433)
[Link] (1 responses)
I don't know where I remember this from, but somebody did some tests on large file copies. By turning off the normal linux cache or something like that, I think the actual copy sped up by an order of magnitude. And system responsiveness during the copy didn't take anything like the usual hit, either.
Makes sense in a way - by disabling linux' habit of stashing everything in the cache, you're not thrashing the memory subsystem.
Cheers,
Posted Jun 6, 2024 16:08 UTC (Thu)
by Paf (subscriber, #91811)
[Link]
Posted Jun 6, 2024 17:02 UTC (Thu)
by joib (subscriber, #8541)
[Link] (1 responses)
Posted Jun 7, 2024 17:25 UTC (Fri)
by Paf (subscriber, #91811)
[Link]
Alignment means "byte N in this page of memory is byte N in a block on disk".
So let's say you want to do I/O from a 1 MiB malloc, and this 1 MiB buffer starts at 100 bytes into a page.
*Every* byte in the IO is 100 bytes off, and that means there's not a 1-to-1 mapping between pages in memory and page on disk. So you have to shift them *all*. Allocate a 1 MiB buffer and copy everything to it.
This is the same for the page cache, FWIW. It has to shift *everything*.
But since you can do the copying in parallel, it's still *really* fast.
Posted Jun 7, 2024 8:13 UTC (Fri)
by Homer512 (subscriber, #85295)
[Link] (2 responses)
If we could have this happen automatically, it would help so much. For example we could go back to using standard file formats without having to reimplement them. Right now I'm using a custom TIFF file writer for one application simply because there is no way of getting libtiff to do direct IO. Same for things like HDF5.
Heck, I can't even use cp or rsync for backups at the moment since for example rsync does not go faster than 800 MB/s on that server.
Posted Jun 7, 2024 9:57 UTC (Fri)
by Wol (subscriber, #4433)
[Link]
Exactly the use case - shifting a huge volume of data that is going to be written to disk and that's it. What you do NOT want is linux sticking it in the disk cache "just in case". And I think the speedup was (low) orders of magnitude.
I don't think it was even buffered i/o - if you can get linux to disable the disk cache on that machine, see what results you get with standard tiff, cp etc.
Cheers,
Posted Jun 7, 2024 17:29 UTC (Fri)
by Paf (subscriber, #91811)
[Link]
Some of the marketing folks at a Lustre vendor put together something showing improvements in PyTorch checkpointing, for example.
It's something that would presumably be useful in other file systems too, but Lustre is out of tree, so it'll stay within Lustre for now. (It's GPLv2, just out of tree.)
If someone working in upstream wants to copy the idea, I won't object. (Would like credit, of course!)
Posted Jun 7, 2024 10:12 UTC (Fri)
by intgr (subscriber, #39733)
[Link] (20 responses)
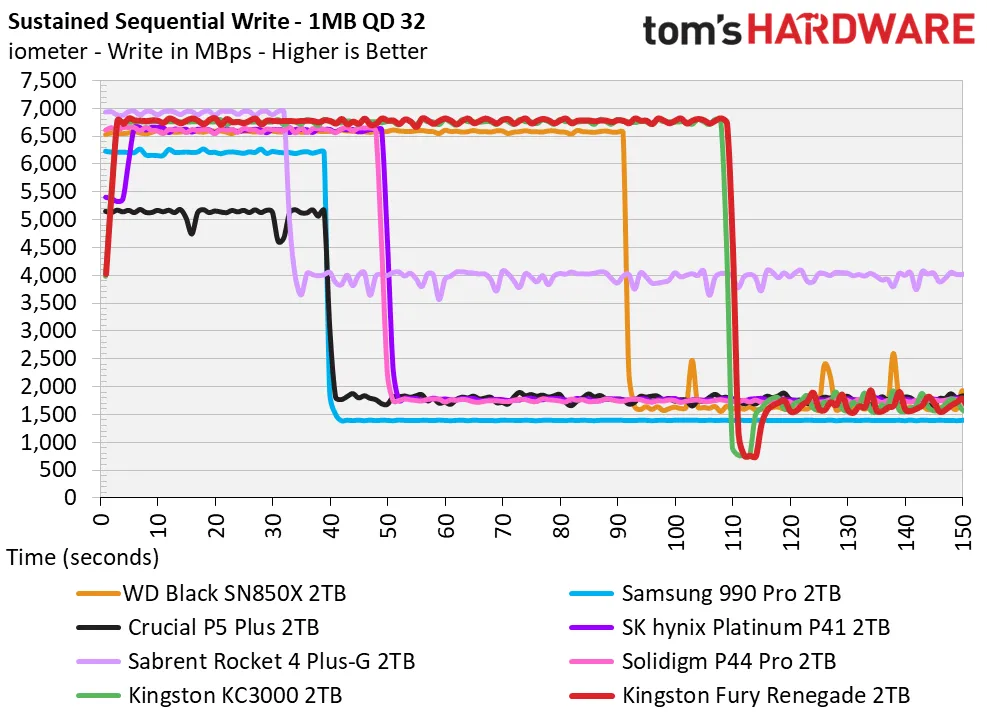
I recently upgraded to a new SSD: Intel 660p → Kingston KC3000 2TB. To my astonishment, after spending money and time migrating to the new disk, things did NOT get any faster. In the simplest possible sequential write tests, buffered writes capped out at ~700-800 MB/s! On an unencrypted ext4 file system. (Unless using O_DIRECT).
The hardware can do sustained 6.5 GB/s writes for 110s (https://cdn.mos.cms.futurecdn.net/YzH49txwAWv3EBB6jF7gge-...), but is limited to 3.5 GB/s for me because my system has PCIe 3.
And this isn't just my problem, there are lots of similar reports on the web:
After reformatting the drive from 512B -> 4kB sectors, things did get better (1.1 GB/s write), but still nowhere near the capabilities of the hardware. And it is software limited on read speeds too!
Results for buffered I/O: https://imgur.com/tsNQbmM (write capped out at 1.1 GB/s, reads 2.2 GB/s)
(Some more details in this forum post: https://bbs.archlinux.org/viewtopic.php?id=292078)
Posted Jun 7, 2024 11:24 UTC (Fri)
by intgr (subscriber, #39733)
[Link] (3 responses)
This is the first article I've seen covering the topic, but it makes it sound like the issue exists only for some high-end enterprise storage setups or obscure workloads.
I would expect to be able to copy files at close to the speed that my hardware allows.
If Linux was only able to use 3 cores out of a 16-core CPU, Phoronix would be chucking out articles about it with the frequency of a machine gun. Are people taking poor I/O performance for granted so it isn't even being discussed? Or maybe it's a problem that affects only some specific combination of hardware? But the list of other similar reports I found seems to indicate that it's not that rare.
Posted Jun 7, 2024 12:03 UTC (Fri)
by malmedal (subscriber, #56172)
[Link] (2 responses)
Posted Jun 7, 2024 14:33 UTC (Fri)
by intgr (subscriber, #39733)
[Link] (1 responses)
nr_requests was already at 1023 by default and could not be increased. Reducing it decreased performance.
io_poll requires additional boot parameter (nvme.poll_queues), I will try it out later.
Did I miss any important tunables?
Posted Jun 7, 2024 15:40 UTC (Fri)
by malmedal (subscriber, #56172)
[Link]
Things keep changing, so it's good to try the options every now and then.
Posted Jun 7, 2024 12:16 UTC (Fri)
by adobriyan (subscriber, #30858)
[Link] (13 responses)
The answer in your case is probably different I/O scheduler + filesystem mount options, TRIM and as you've already discovered -- LBA size.
I want to comment on methodological traps and mistakes so to speak.
1) dd
dd is single threaded program. Comparing single threaded performance with report of CrystalMark "SEQ 1MiB (Q= 8, T= 1):" is not correct.
Internally SSDs are quite parallelised (imagine HDD with dozens of platters each having _independent_ actuator arm),
Don't use dd, don't use those pretty apps unless you traced then and know how they open descriptors and issue I/O.
Learn fio. It does O_DIRECT, maintains queue depth, can emulate dd(1)/cp(1) easily and have more config options than you can imagine.
Windows may do QD>1 copy, someone needs to check that. Naive POSIX read/write loop is not pinnacle of performance.
Again, it is easy to check: find block size with peak qd=1 seq write performance, anything past that must be qd>1.
1a) dd bs=1G is bad idea.
first you need to free 1 GiB by flushing everything else only to move big file through pagecache twice (not /dev/zero, lets say video).
If target file is unused afterwards, do "dd oflag=direct" and big-but-not-really-big bs= .
Internally, there is RAM buffer to keep the data, any write bigger than that has to be throttled!
2) manufacturers do _not_ use filesystems for benchmarks. ...
Internally they may have even more stripped down environments (think DPDK) to separate what hardware can do from what OS kernel developers can do afterwards.
So what happens, is some Gnome dev writes naive file copier and than users compare it with maximum possible number from real benchmarks which simulate maximum workload.
3) numbers are sensitive to what's called preconditioning
Manufacturers do preconditioning before benchmarks so that results aren't fudged. Those big enterprise buyers open devices with O_CONTRACT and reserve the right to reopen with O_LAWSUIT, so can't lie to them. Consumers benchmarks are crapshoot, of course.
Writing 2-3-4 capacities _before_ doing the run to get real numbers is a must if you want to know what hardware is capable of.
Posted Jun 7, 2024 14:02 UTC (Fri)
by intgr (subscriber, #39733)
[Link] (10 responses)
I guess I failed to put together a good narrative around my expectations, how it conflicted with reality, and what my benchmarks were supposed to illustrate.
As a user, I *only* care about performance of the buffered I/O path, which includes page cache. Workloads on my desktop/laptop compter don't use O_DIRECT, they are extremely simple and non-parallel: Copy some files, unpack some files, install packages, git operations, etc. I upgraded the SSD so that I could do these operations faster.
My expectation is that an operation as simple as copying a file should be able to mostly saturate the I/O bandwidth of my hardware. Not 100%, but I sure as hell wasn't expecting it to be ≤35%. I thought sequential I/O is simple. Is this a crazy expectation?
(To put it anther way, I expected to reach 50% of SSD capability due to PCIe bandwidth limitation, but I got <20%)
Or if computers in 2024 are fundamentally unable to provide this, then it would be a fair argument that cp/tar/rsync implementations should all be rewritten with parallel I/O or O_DIRECT?
> dd is single threaded program.
And so are the workloads I am interested in. cp, tar and rsync are all single-threaded in the write I/O path, as far as I am aware. Not sure about git.
> Comparing single threaded performance with report of CrystalMark "SEQ 1MiB (Q= 8, T= 1):" is not correct.
I didn't compare to CrystalMark. Are you referring to the KDiskMark screenshots?
More importantly, if KDiskMark with buffered I/O gives me 1.1 GB/s and `dd` (from the forum post) gives 1.3 GB/s, they're both in the same ballpark and way below my expectation. The additional queue depth didn't seem to make any difference. I think it's valid to demonstrate that?
The reason for including the KDiskMark O_DIRECT results was to demonstrate that this is not a hardware limitation. To drive home the fact that Linux buffered I/O is the bottleneck.
> Learn fio. It does O_DIRECT, maintains queue depth, can emulate dd(1)/cp(1)
KDiskMark uses fio internally. I included the numbers for both O_DIRECT on and off. It's true that I didn't benchmark fio with QD=1, but as explaned above, it didn't make much difference and both highlight how much performance is left untapped compared to hardware capabilities.
> 1a) dd bs=1G is bad idea.
I didn't use `bs=1G`. In the forum post, I used `dd bs=1M`.
But again, it doesn't matter, I could also benchmark `cp` to copy a file from tmpfs to a real disk. The results are in the same ballpark and still a fraction of maximum I/O capacity.
> 2) manufacturers do _not_ use filesystems for benchmarks. ...
Yes, I didn't expect that they would. My complaint is not with manufacturers. My complaint is with Linux leaving so much hardware capability underutilized. And how nobody seems to be talking about this.
> some Gnome dev writes naive file copier and than users compare it with maximum possible number from real benchmarks which simulate maximum workload.
Exactly, this. Now we're getting somewhere. :D
Why is a simple buffered I/O writer limited to 35% or less of potential hardware throughput?
Posted Jun 7, 2024 14:53 UTC (Fri)
by pizza (subscriber, #46)
[Link] (6 responses)
The point is that that "SSD capability" (if not a completely theoretical maximum burst speed [1]) is, at best, derived from a synthetic multi-threaded benchmark that is all but guaranteed to bypass the I/O mechanisms available to real-world applications in real-world operating systems.
> Why is a simple buffered I/O writer limited to 35% or less of potential hardware throughput?
Due to fixed overhead (eg making system calls, I/O scheduling, copying data into/out of buffers, servicing interrupts, and latencies for all of these meaning that your bus duty cycle is well below the theoretical maximum) -- and the problem that optimizations that maximize throughput for a single thread can severely penalize other usage patterns. Case in point: the "bufferbloat" problem on wifi and ISP home routers.
[1] eg quoting max speeds as the theroetical maximum PCIe transfer speed; other stratageies include not including IOP transactional overhead, using transfers that can fit entirely within the SSD's cache, and/or preconditioning the SSD in some way. As the saying goes, "lies, damn lies, and benchmarks"
Posted Jun 7, 2024 15:30 UTC (Fri)
by Wol (subscriber, #4433)
[Link] (4 responses)
The point the other way, is that linux is caching a lot of disk i/o that is actually "write and forget". That cache is (a) expensive, and (b) pointless.
I get that knowing the difference between useful and useless caching is a very difficult problem, but there's a lot of evidence that caching is a prime example of "premature optimisation is the root of all evil". If on average half of that written data is then re-used, the implication is that the cost of caching it is more than the cost of reading it again from disk ... not a good trade-off.
I believe a lot of databases cache stuff they've read. Why is the disk caching it too? That's why I believe PostGRES uses direct i/o as a matter of course.
Back in the day, Pick/MultiValue databases never cached data, because they could retrieve it from disk so fast (and I've seen them drive disks like that!) (That was with disks and ram measured in megabytes. Or even less.)
What's needed is a - probably by device - toggle to turn direct/buffered/cached i/o on and off. That guy doing streaming to disk - if the disks were unbuffered all the normal utilities would work. Databases with a dedicated storage partition - they can control their own caching if they wish. Even normal users with a normal /home - do they really need caching? How often do they re-read the same file in normal usage? Probably pretty much never ...
Buffered/cached i/o is an anachronism that probably doesn't make sense in a lot of workloads ...
Cheers,
Posted Jun 7, 2024 15:42 UTC (Fri)
by adobriyan (subscriber, #30858)
[Link]
Devs need pagecache, all of it!
# from cold cache, top end consumer NVMe SSD
# from pagecache
rg(1) is multithreaded.
Posted Jun 8, 2024 18:46 UTC (Sat)
by jkl (subscriber, #95256)
[Link]
It does not. It was just introduced as an optional experimental/dev only feature in PostgreSQL 16. https://wiki.postgresql.org/wiki/AIO.
Posted Jun 17, 2024 17:03 UTC (Mon)
by fest3er (guest, #60379)
[Link] (1 responses)
IMO, normal users benefit from disk cache, just as they benefit from having at least 4 CPU cores (GUI, disk IO, local program, other activity).
Some years ago, I experimented to see the difference between Linux's disk caching and ramdisk. The system had 16GiB RAM and 8 or 16 CPU cores. I was working on a custom Linux system at the time. The whole build required about 13GiB, using as many CPU cores as any pkg could (GCC and Linux would use all allowed cores for minutes). First, I built it on spinning disk (after having dropped the cache). It took X minutes. Then I cleared it, loaded the tree into a 14GiB ramdisk formatted with some filesystem and built again. This build took X - (time to read files from spinning drive) minutes. My conclusion 10 years ago was that Linux's disk caching was quite efficient; reads weren't really noticeable and writes vanished into unused CPU cycles. But perhaps this isn't 'normal use'.
Once upon a time, I noticed that EXT4 filesystems would 'lock' or 'hang' the system for some seconds while data were being flushed to disk, something I didn't see on other FSen (ReiserFS). But I haven't seen that happen for prolly 10 years now. (Maybe I had enabled something on that particular EXT4 FS and forgot I'd done did it.)
Posted Jun 18, 2024 11:29 UTC (Tue)
by Wol (subscriber, #4433)
[Link]
So you were doing a build. What exactly do you mean?
If you're talking a compile-and-link, dev-type stuff, you're doing a lot of "write then read", and yes, and cache is useful. But how typical is that sort of behaviour for a normal user?
> Then I cleared it, loaded the tree into a 14GiB ramdisk formatted with some filesystem and built again. This build took X - (time to read files from spinning drive) minutes.
So you're now measuring "time for first read from spinning rust". And how exactly is caching going to improve THAT figure? It's not! It'll make a big difference to "time to read it again", or "time to retrieve what I just wrote", but how much does that figure into a NORMAL USER'S workflow. If I'm working on a document, I'll read it ONCE, then it'll sit in ram til I'm finished with it. Cache saves me nothing.
> Once upon a time, I noticed that EXT4 filesystems would 'lock' or 'hang' the system for some seconds while data were being flushed to disk, something I didn't see on other FSen (ReiserFS).
And that's background writes, again nothing to do with caching. Except that there's a LOT of evidence that leaving all that i/o behind in cache is damaging to performance.
I'm an analyst. My whole job is to analyse performance. I'm looking at all this and thinking "where are the performance gains coming from?". All the evidence in front of me says that caching has a very measurable performance cost. And when I try and work out where the offsetting gains are going to come from, there are some obvious places - development work for example. A "make" cycle will certainly benefit. But there are also places where I struggle to find any benefit - YOUR TYPICAL USER - for example.
All I'm asking is "is caching worth the cost?". For servers, "it depends". Do they do their own caching, do they rely on the OS? For a development workstation, almost certainly, reading and writing the same files over and over will obviously benefit. But for a typical user PC? Caching will *interfere* with a normal work-pattern. And for a backup server? All the evidence is that caching is actually a major hindrance. I've very recently seen someone complaining about NVME performance - the difference in speed between cached and uncached i/o is about three HUNDRED percent.
The ability to switch it on and off by volume is probably very useful.
Cheers,
Posted Jun 11, 2024 17:44 UTC (Tue)
by anton (subscriber, #25547)
[Link]
Let's assume that this performs a standard copy rather than a reflink. Then inside the kernel a bunch of blocks (including some metadata blocks) are marked as dirty and will be written at some later time. If you do a lot of such copies, a lot of dirty pages accumulate, and when the kernel decides to write this data, it can do that with as many threads as is appropriate. If it uses too few, that's an optimization opportunity for the kernel.
However, for the kind of usage that intgr mentions, as long as the data fits into RAM, it does not matter when the kernel starts and finishes writing the data to the disk, and what the bandwidth of that is. So for this kind of usage the write bandwidth to the buffer cache is what counts, and it's no wonder that he does not see a speedup from switching to a faster SSD: In this setting the limit is RAM bandwidth, not bandwidth to the SSD.
There is a catch: People who argue with the term O_PONIES for file systems with bad crash consistency guarantees tell us that the applications need to sync at some points, and that syncs mean that the application waits every time until the data resides on the disk. Unfortunately, last I looked, the only Linux file system with a good crash consistency guarantee is NILFS2. So if applications sync frequently, write bandwidth to the SSDs would become the limiter. The cp invocation I straced does not call anything that has "sync" in its name.
My guess is that writing from buffered I/O to SSDs has not been optimized because it has not hurt kernel developers much. In the usual case git performance is plenty fast (or maybe my repos are just too small to notice problems:-).
Posted Jun 7, 2024 18:10 UTC (Fri)
by Tobu (subscriber, #24111)
[Link]
I would guess most of the reason why rsync and tar don't do multithreaded writes is that C makes concurrency hard and risky (with bad consequences for corruption in the write path; maybe it's not worth the risk of silently corrupted backups).
Anyway, Rust makes correct and highly concurrent tools feasible, quite a few are best in their class. Try cpz and rmz. Also look at gitoxide, not full featured (currently targetting use cases where it's embedded inside another app) but it can git checkout the kernel much faster. Or fclones and ripgrep for more read-heavy use cases.
Posted Jun 9, 2024 12:22 UTC (Sun)
by malmedal (subscriber, #56172)
[Link] (1 responses)
Posted Jun 12, 2024 12:40 UTC (Wed)
by intgr (subscriber, #39733)
[Link]
Posted Jun 8, 2024 18:44 UTC (Sat)
by dcoutts (guest, #5387)
[Link]
I think this is far from obvious. The crucial observation is that SSDs are highly parallel (with e.g. a 20x factor between serial (Q1) and parallel (QD32) use).
Certainly, one can expect to achieve best I/O throughput and lowest CPU use by using nice modern async I/O APIs like io_uring, with O_DIRECT, and submitting I/O from multiple cores. That allows one to fully take advantage of the SSDs parallelism.
But how can older programs written using classic serial I/O APIs take advantage of parallel I/O capabilities of SSDs? Or are all these programs condemned to poor serial performance or rewrites using new (non-portable) APIs? One potential answer is the page cache!
The page cache allows a program using serial I/O APIs to quickly move data into the page cache, from where it should _in principle_ be possible to write it to disk in parallel. And similarly for reading data via readahead. The kernel readahead could use parallel I/O to get data from the SSD and put it into the page cache, while the application still uses serial I/O APIs to copy that data from the page cache.
Of course this will have a substantially higher CPU overhead than using io_uring with O_DIRECT, but it should still be possible to achieve the full I/O throughput at least for current generation SSDs (e.g. in the 1M IOPS range).
So in summary, the problem is how to mediate between parallel SSDs and (older) serial applications, and the page cache _should_ be the solution.
Posted Jun 11, 2024 20:56 UTC (Tue)
by willy (subscriber, #9762)
[Link]
That's an exceptionally stupid thing to say. It's a cache. Its entire purpose is to make things faster. If what you meant was "for an uncachable workload it can only make things slower", well, I disagree with that too. It decouples the application from the characteristics of the underlying storage, allowing write() of a single byte to succeed, no matter the block size of the underlying device.
Posted Jun 7, 2024 18:13 UTC (Fri)
by Paf (subscriber, #91811)
[Link] (1 responses)
But this whole thing - buffered IO sucks but real apps don’t use direct IO - is why I’ve implemented something called hybrid IO for the Lustre parallel file system. Starting from the observation that the main cost of using the page cache is locking and setup - not memory allocation and copying - it adds unaligned direct IO support by creating bounce buffers in the kernel, copying (in parallel) to those, and then doing DIO from those buffers. Then this is used to bypass the page cache for larger IO sizes. It can get up to about 20 GiB/s from one thread doing “buffered” IO if the IO size is large. (Not having the cache for larger IO works out because it’s very, very rare to do a *large* write followed shortly by reading that data back.)
This is something it would probably make sense to put in more file systems, but Lustre is out of tree (GPLv2, but out of tree), so that would fall to someone else.
Some conference slides here:
Posted Jun 9, 2024 15:51 UTC (Sun)
by intgr (subscriber, #39733)
[Link]
Interesting. Thanks for pointing that out. I ran a bunch of tests with multiple file systems on Linux kernel 6.9.3.
XFS achieves roughly double the sequential write throughput and also has a significant lead in read throughput, compared to all the others (ext4, btrfs, bcachefs).
Results from `dd if=/dev/zero of=./tempfile bs=1M count=8192 conv=fdatasync`: XFS 3.1 GB/s, btrfs 1.5 GB/s, bcachefs 1.5 GB/s, ext4 1.3 GB/s.
The dd result of 3.1 GB/s is close enough to theoretical 3.5 that I'm happy with it.
According to KDiskMark (fio) with buffered I/O, sequential write of XFS goes up to 1900 MB/s, compared to 900-1000 MB/s. Not sure where the measured discrepancy between dd vs fio comes from, but the uplift is consistent in both results.
KDiskMark screenshots here: https://imgur.com/a/wJKKLZk
Posted Jul 4, 2024 19:18 UTC (Thu)
by gaowayne1 (guest, #172310)
[Link]
root@salab-bncbeta02:~/wayne/FlameGraph# uname -a
when I test XFS, I can see even direct=0, fio can reach more than 14GB/s flush kworker CPU is only 20%. no issue at all.
Real customer
Real customer
Real customer
Write-through
Write-through
Write-through
BIO vs DIO
https://www.depts.ttu.edu/hpcc/events/LUG24/slides/Day2/L...
BIO vs DIO
Wol
BIO vs DIO
BIO vs DIO
BIO vs DIO
BIO vs DIO
BIO vs DIO
Wol
BIO vs DIO
Not even close to saturating consumer NVMe disks
* https://askubuntu.com/questions/1277708/why-are-writes-on...
* https://askubuntu.com/questions/1005396/ssd-slow-write-sp...
* https://askubuntu.com/questions/1300444/slow-nvme-perform...
* https://askubuntu.com/questions/1434255/nvme-slow-write-s...
Results with O_DIRECT: https://imgur.com/hnWPDaF (reaches 3.5 GB/s)
Not even close to saturating consumer NVMe disks
Not even close to saturating consumer NVMe disks
Not even close to saturating consumer NVMe disks
Not even close to saturating consumer NVMe disks
Not even close to saturating consumer NVMe disks
Q=8 means "queue depth 8" which means 8 NVMe commands in flight not 1.
so queue depth 1 is worst case performance for SSD. CrystalMark report have measly "130.946 MB/s" qd1, 4 KiB random ream, that's SSDs for you.
ioengine=libaio, iodepth=N. ioengine=psync to emulate dd/file copy routines.
... because it only makes things slower, not faster, because they can't control host OS kernel, application, mount options, SCSI/NVMe stack and so on.
It's takes time and eats block erase count but it is necessary.
Not even close to saturating consumer NVMe disks
Not even close to saturating consumer NVMe disks
Not even close to saturating consumer NVMe disks
Wol
Not even close to saturating consumer NVMe disks
$ time rg -e 'page->private' -w -n
real 0m1.498s
real 0m0.093s
Not even close to saturating consumer NVMe disks
Not even close to saturating consumer NVMe disks
Not even close to saturating consumer NVMe disks
Wol
Not even close to saturating consumer NVMe disks
Due to fixed overhead (eg making system calls, I/O scheduling, copying data into/out of buffers, servicing interrupts, and latencies for all of these meaning that your bus duty cycle is well below the theoretical maximum) -- and the problem that optimizations that maximize throughput for a single thread can severely penalize other usage patterns.
I don't see these issues as fundamentally limiting buffered I/O bandwidth, especially for the kinds of applications that intgr mentions. I did
strace cp lp_solve_2.2.tar.gz xxx
cp performs 101 system calls, most of them startup stuff. The actual work seems to be:
openat(AT_FDCWD, "xxx", O_RDONLY|O_PATH|O_DIRECTORY) = -1 ENOENT (No such file or directory)
newfstatat(AT_FDCWD, "lp_solve_2.2.tar.gz", {st_mode=S_IFREG|0644, st_size=87030, ...}, 0) = 0
openat(AT_FDCWD, "lp_solve_2.2.tar.gz", O_RDONLY) = 3
newfstatat(3, "", {st_mode=S_IFREG|0644, st_size=87030, ...}, AT_EMPTY_PATH) = 0
openat(AT_FDCWD, "xxx", O_WRONLY|O_CREAT|O_EXCL, 0644) = 4
ioctl(4, BTRFS_IOC_CLONE or FICLONE, 3) = -1 EOPNOTSUPP (Operation not supported)
newfstatat(4, "", {st_mode=S_IFREG|0644, st_size=0, ...}, AT_EMPTY_PATH) = 0
fadvise64(3, 0, 0, POSIX_FADV_SEQUENTIAL) = 0
copy_file_range(3, NULL, 4, NULL, 9223372035781033984, 0) = 87030
copy_file_range(3, NULL, 4, NULL, 9223372035781033984, 0) = 0
close(4) = 0
close(3) = 0
If cp used direct I/O, the number of system calls would not be less, so system calls are not the issue.
Not even close to saturating consumer NVMe disks
Not even close to saturating consumer NVMe disks
Not even close to saturating consumer NVMe disks
Not even close to saturating consumer NVMe disks
Not even close to saturating consumer NVMe disks
Not even close to saturating consumer NVMe disks
https://www.depts.ttu.edu/hpcc/events/LUG24/slides/Day2/L...
Not even close to saturating consumer NVMe disks
my test with gen5 CPU and raid0 two gen5 NVMe SSD
I tested with latest fio, gen5 CPU, gen5 NVMe SSD with kernel version, I raid0 two gen5 SSD, it can reach 15GB/s
Linux salab-bncbeta02 6.8.5-301.fc40.x86_64 #1 SMP PREEMPT_DYNAMIC Thu Apr 11 20:00:10 UTC 2024 x86_64 GNU/Linux
when I test ext4, I can reproduce this problem, flush kworker is 100% CPU.
may I know what is difference and root cause for this? I got the perf flame svg for both ext4 and xfs, if anyone need, please reach me.
{kind=link}