
LWN.net Weekly Edition for June 8, 2023
Welcome to the LWN.net Weekly Edition for June 8, 2023
This edition contains the following feature content:
- Ethics in a machine-learning world: a PyCon keynote on the values we build into our machine-learning systems.
- Seeking the endgame for Debian's /usr merge: this transition has been ongoing for years, and isn't done yet.
- Special file descriptors in BPF: the BPF subsystem bans zero as a valid file-descriptor number.
- More LSFMM coverage:
- Supporting large block sizes: a discussion on what needs to be done to support block sizes larger than the page size.
- A decision on composefs: the proposed composefs read-only, integrity-protected filesystem was discussed along with alternatives to solve the same set of problems.
- An introduction to EROFS: an overview and discussion of the EROFS read-only filesystem.
- Memory-management documentation and development process: two brief discussions on documentation and development process.
This week's edition also includes these inner pages:
- Brief items: Brief news items from throughout the community.
- Announcements: Newsletters, conferences, security updates, patches, and more.
Please enjoy this week's edition, and, as always, thank you for supporting LWN.net.
Ethics in a machine-learning world
Margaret Mitchell, a researcher focused on the intersection of machine learning and ethics, was the morning keynote speaker on the third day of PyCon 2023. She spoke about her journey into machine learning and how the Python language has been instrumental in it. It was a timely and thought-provoking talk that looked beyond the machine-learning hype to consider the bigger picture.
Starting out
She began by noting that she had started programming on PCs in the early 1990s when she was in elementary school. Starting the computer was an exercise in waiting out a bunch of messages that she didn't much care about until, finally, she got to the goal: the "C:\> " prompt. A friend taught her about the CLS (clear screen) command, which was magical, and she learned about ECHO (print to the screen). This was before the internet was much of thing, she said, so she spent endless amounts of time printing silly things to the screen. It is what hooked her on computers.
![[Margaret Mitchell]](https://static.lwn.net/images/2023/pycon-mitchell-sm.png "Margaret Mitchell")
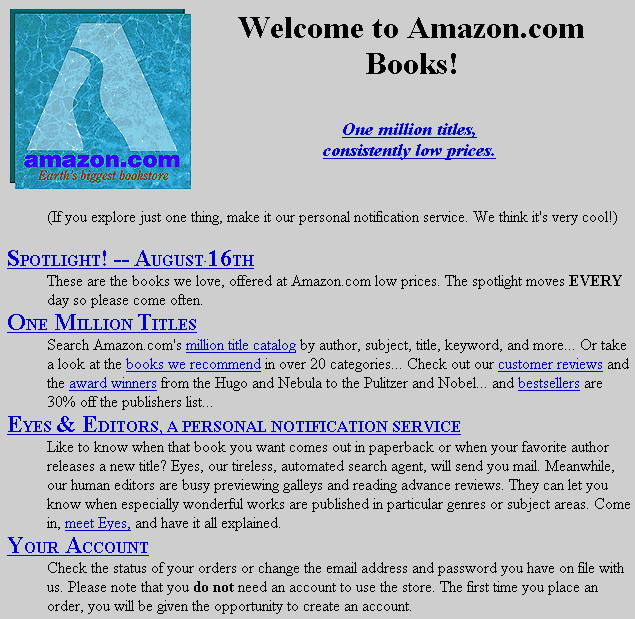
By the mid-1990s, the world-wide web had come along; she put up a slide with an early web site with all of its flashing, rotating, "32-bit glory". To "sort of place the time", she also put up an early, stark Amazon home page. Many people were interested in learning about HTML in order to create web pages with lots of colors and animations; she met "a lot of fellow nerds" on AOL, where they learned to program web sites together. Now, instead of printing silly messages just to her screen, she could put them on web sites for her friends to see.
{kind=link}
From there, she taught herself more about web-site design and object-oriented programming; her school did not have any classes of that sort, so she learned a lot from Webmonkey. She created interactive web sites, like "Ask Satan" that would give you your fortune; she also created little games that she gave as gifts to her friends, though she thinks it was probably a lot more fun for her than for them.
After that came compiled languages, starting with C++; once she mastered the basics of that, she immediately started writing games for her friends again. When she landed her first real job, the language she used there was Tcl, which is used in speech processing. Her job was writing software to diagnose whether someone might have mild cognitive impairment (a precursor to Alzheimer's disease) by processing their speech stream. She got quite familiar with Tcl and other scripting languages, as well as various Unix utilities, such as sed and Awk, which she still uses to this day, Mitchell said.
When she went to graduate school, she needed to decide which language she should use for her work. "This was a pretty straightforward decision for me." With a laugh she said that she was embarrassed to say that Tcl was her primary language, so she chose Python—"because Tcl sounds lame and Python sounds cool". That was her "reasoning", but she said that once she started using Python, she naturally took to it, found it intuitive, and was quickly off and running doing machine-learning tasks with it.
In 2011, she was part of a research team that used Python to create one of the first image-description systems, which is "somewhat relevant today" because generative-image and text-to-image models are becoming known to the public. It was niche research, since computer-vision systems did not work all that well at the time.
She finished graduate school, did post-doctoral research, and learned other languages and tools along the way. In jobs at Microsoft, Google, and now Hugging Face, the bulk of her work has been in Python, much of it learning new Python packages for various parts of her machine-learning work. The timeline she had presented was meant as a backdrop so that she could talk about some of the things she has found most important in computer science, machine learning, and artificial intelligence (AI). She did note that the AI term is seen by many in the machine-learning community as "a little bit 'roll your eyes'".
Image captioning
One of the big turning points in her life, which led to her work on ethics in machine learning, came about during her work at Microsoft. She was continuing to work on image description just as deep learning was successfully being applied to computer vision; meanwhile, recurrent neural networks on the language processing side were showing promise. So, using Python, she hooked up the output of convolutional neural networks for vision to recurrent neural networks for language to create an image-captioning system that "surpassed" (she used air quotes) human performance. That was measured using the output's BLEU score, which shows some of the problems with automatic metrics, she said, since they "don't actually quite capture what we want". That work led to a program called "Seeing AI" for blind people.
Along the way, she had wondered about why she was working on image-description systems: "what is the image-captioning task, who needs that?" One of the obvious answers that comes up when discussing the subject with other academics is that it is super-helpful for blind people. So she decided she would work with blind people and ask them; "it turned out: not helpful". The kinds of things that blind people needed "was fundamentally different than the kinds of things being optimized for in the image-captioning task".
That provided her with a wakeup call about the discrepancy between the academic tasks that are developed as a way to "play around with new models and new technology" and the real-world use cases. For example, someone who is blind does not need to know that they are holding a soda can—they know that already—but they do need to know which soda it is. They need to know if a tube is toothpaste—or a medicine like Preparation H that comes in a tube. Logo recognition and optical character recognition (OCR) are not really part of what the field of image captioning is working on. Beyond that, tasks like counting the number of stairs in a staircase are completely outside of what the field is working on, but are the kinds of things that blind people need and want.
Women in tech
Another aspect that she wanted to talk about was the difficulties that exist for women in tech. The work she did at Microsoft was not a particularly pleasant experience because the field was so new, so competitive, and so territorial. There were also lots of deep-learning competitions going on; she may have been the first woman to win one of those, but she does not know, "because people were super mean about it, people at Microsoft refused to share it". She did not see that happening to her male colleagues—or the men at other companies either.
To the other women in tech in the audience, she just wanted them to know that they are not alone. "If you feel like everybody hates you and isn't listening to you and is not respecting you similarly to your peers", it is a common experience for "so many women". Eventually you can get to a place where that is no longer true, but it takes an enormous amount of work—lots more than it takes for men, at least in her experience. She thanked the audience for a rousing round of applause to that.
Foresight
In her image-captioning work, the switch she made to working with people who are blind really changed her way of looking at research. Instead of focusing on the "tasks defined for some conference or some competition", she wants researchers to "think through what the technology you are working on now could look like" in five, ten, or 15 years "if it were to help people". How should it evolve to get to a "helping-people stage"?
She could see how image captioning might eventually be useful to blind people, but it needed to be fundamentally different than where it was headed. So she started from the endpoint of what was needed by blind people, and used that work out what she needed to be working on right then. It changed her approach to research so that she was looking at the long-term picture of the technology: "where is this going to go over time? who is it going to affect?"
Once people are working on their projects "from the perspective of foresight", they are already working in the realm of ethical AI, she said. A fundamental piece of ethical AI is being able to work through the use cases for the technology, how it can be used positively, and, importantly, how it can be used negatively, including by malicious actors. This use of foresight "is not prioritized in tech circles as much as it could be".
This experience made her want to always include those who would most likely benefit from a technology in its creation. As much as she can, she still does that to this day. Doing so helps shape the path of development and, she believes, leads to better outcomes.
Stories
In 2015, she started working on storytelling, where a program is fed a series of photographs and creates a story about the sequence. She and her colleagues discovered that the model had a problem, though: it thought that "everything was awesome". A series of four photos from her Thanksgiving gathering might generate: "Everyone was there. The food was awesome. The food was delicious. And it was awesome."
"It turns out that this is a reflection of what people say when they are sharing photos." People tend to share photos of weddings, parties, and various fun gatherings; they also share beautiful scenery, like sunsets. People rarely share photos from sad events, such as funerals. Models that are trained on the kinds of photos that people share, and the captions and comments that go with them, have a distorted view of our world.
This really struck home for her when she fed the program three photos from an enormous explosion and fire in Hemel Hempstead, UK. "It looked at it and thought it was great". She realized that if we start making these systems autonomous, such that they can take actions based on their training, "then in the pursuit of beauty, and things that it mistakenly thinks are good, it could kill people". The model has learned that colors in the sky are beautiful, but it does not understand mortality nor does it understand all of the things that are not generally shared online.
When looking at the output, she could understand why it had made the mistakes it had, in determining that the explosion was fun, beautiful, and awesome. She tried to interest other researchers in these types of problems that she saw, without much success. She kind of looked around and realized that no one else really cared; "so if no one cares, I guess I have to, right? Someone has to". She started paying a lot more attention to the data that was going into the machine-learning pipeline with an eye toward what happens when the models get deployed in the real world.
Bias
Online text is the main source for training models, but that text is not reflective of the proportions of actions that occur in real life. For example, a study that looked at the counts of words in a corpus of web text found that "murdered" was far more frequent than "blinked", so murder would be learned to be much more common than blinking. Similarly, things like breathing or exhaling are generally not mentioned much in online text, though they are obviously always happening. But when a murder happens, it gets talked about a lot. This problem is known as "reporting bias" and is one of the many types of bias that can skew what a language model learns from its training.
The basic steps of the machine-learning pipeline are fairly well-known at this point, Mitchell said. It starts with gathering and annotating training data, then training and testing the model with that data. Then rankings, filters, and other post-processing steps can be added before the output is produced, which is what is seen by people using the model.
The data that is gathered for training "encodes a subset of human perspectives and a skewed set of human perspectives". What people choose to put into online text and how they describe those things looks quite a bit different than what actually occurs in our real-world interactions and lives. The idea that a data set could be "unbiased" is a misunderstanding of a what a data set is, she said; "a data set is a collection of bias". Where it is collected from, the time range that it covers, and the people that are part of it, all constitute a bias. It is not some kind of random sampling of everything that ever occurred in the universe, after all.
So the training data going into these models is not an actual representation of the world, it is, instead, "a biased, skewed snapshot of the world". Before the training data is even gathered, there is reporting bias, racism, sexism, underrepresentation of various viewpoints, stereotyping, and so on in the data that is being sampled. But then the data is annotated, which can add another layer of bias into the mix. How the annotation task is designed, who is doing the annotating, and what the compensation is for that task, all add bias into the training set.
So, those biases get injected into the model at the beginning of the pipeline and propagate through it. As the model is being trained, there are some additional types of bias that can be added in, including overfitting and underfitting, where the models are not actually representing the data well. There is also a tendency for researchers to default to "what people do, without really thinking through why [they] are making those choices". In general, choices that are made need to have a reason associated with them.
The post-processing stage has more opportunities for adding bias, including confirmation bias. She said that the current crop of chat bots (e.g. ChatGPT) are not actually particularly useful for search, despite what Microsoft and Google would have us believe; they are useful for other things, such as creative writing or learning English, but not search. Those companies are effectively paying for the models via their search tools, so they confirm their own beliefs even though it is not actually true, she said.
Once people see the output, a particularly pernicious bias kicks in: automation bias. People tend to agree with or believe the output of automated systems "even in light of evidence that what's going on isn't true". It comes out of this complicated system, where there is math involved, so there is a belief that the output is objective—and correct.
That output then affects what we do or what we say online. She gave an example of a recommendation model that listed tweets of interest; our choices of which tweets to engage with is perhaps altered by the automation bias. "This then can be swept up into a further machine-learning model further amplifying these sorts of effects", Mitchell said.
She has coined the term "bias laundering" to describe this. The underlying idea is that machine-learning development is not, and cannot be, value-neutral. If the developers decide not to think about values, it does not mean that there are not values encoded into the model. The input data set determines what is important in the model; if there are populations in the solution space that are not represented appropriately in the input, "then you are making the value judgment that some populations should receive worse performance".
Ethical tensions
There is no way "to have the most values" or "the ethical thing", because there are always tradeoffs involved. For example, an organization might want to release open data sets, which would help with advancing AI, benchmarking models, and reproducibility, but it comes with downsides as well. There may be a lack of consent for the data, privacy and licensing issues, as well as giving an incorrect impression that the data somehow represents all people well. Beyond that, there are issues with compensation and credit for those who created the data. She is not saying that it is all bad, just that there are tensions between different aspects of the data that has been gathered.
Another goal might be to have a data set that is diverse such that it has a reasonable representation of different populations, but that runs into tensions with stereotyping and exploitation. Her example targeted Google, which was accused of exploiting homeless black people for facial-recognition data. Since "Google was mean to me", she said with a chuckle, she likes to slide negative headlines about the company into her talks.
In this case, company researchers realized that the facial-unlock feature in Pixel 4 phones worked much better for light faces, as opposed to dark ones. In order to gather more dark-face data, some Google contractors visited homeless areas in Atlanta and paid $5 for photos without giving much information about what they were doing and why; effectively they were treating the people as faces, or simply facial images, rather than as people. "Yes, diversity, but also massive exploitation." This is the kind of tension that comes into play when people are trying to optimize for particular values without considering some of the others, she said.
The default state of data collection today has multiple problems in terms of the ethical challenges she has been talking about. "You all can change this." One tool to improve things is to be more structured in developing the data for these models. Even though data is at the heart of building these models, data development is often treated as an unexciting, unimportant, and even silly task.
She pointed to a paper she co-authored that describes a framework for doing ethical data-set development. The proper way to approach the problem is to have multiple roles, rather than today's norm of a single data scientist who gathers, culls, processes, and maintains the data set. "There should be a whole variety of people and steps that go into the project."
The framework describes multiple specifications, starting with the requirements for the data set; the foresight she had mentioned earlier is a key aspect to creating that specification. Much like with a large software project, there are design documents, implementation diaries, testing reports, and maintenance plans. These data sets have a lifecycle; various parts of the requirements and specifications may need to evolve over time.
Measuring
One of the ways that she has been working in this area, "in a way that lets me do Python, honestly", is the role of quantifying data sets. She calls the task "measuring data" (paper); the idea is that a data set can be quantified "along a whole bunch of different axes". It is strange in her mind that there is not a body of existing norms about what can be measured in a data set that is relevant to values, populations, and representation.
She has been working on an open-source tool at Hugging Face that can be used to do some of this kind of measurement. It has some basic measures, such as the number of languages in the data set, the number of web domains represented, copyright information, and licenses involved. In mid-April, The Washington Post had an article describing these statistics for the well-known C4 data set (a processed version of the web-crawl corpus from Common Crawl), which has been around since 2019. It took investigative journalism to get these simple measures for a popular data set, she said, which shows that data-set measurement is clearly not the norm in the industry. The work done by the journalist to gather the statistics used Python, she said: "Yay Python!"
The Hugging Face tool can do more advanced analysis as well. For example, natural languages are known to roughly follow a Zipfian distribution, so the tool can measure a data set to see how well it matches that, which will tell if the data "contains a lot of weird artifacts". There are a lot of wide-open areas for study and tools, including being able to measure constructs, such as the severity of hate language in a text.
She was clearly hoping that some in the audience would find this work as interesting as she does and contribute to the field (and the tool). One of her favorite measures is associations; to try to identify stereotypes, for example. You can make a list of terms that designate traits that might be used for stereotyping, such as gender words (man, woman), age words (young, old), and words denoting sexual orientation (gay, straight). Then you can count the words they co-occur with in the data set and do some simple calculations with those counts. "You're measuring bias, boom!" It is "so simple, such low-hanging fruit, nobody does this, someone please do this".
There are lots of more advanced association and correlation measures; "there's a whole world of math" in this area. Some measures that she uses easily highlight the stereotypes in a data set, so that they can be removed to make the data set better. Just as models are evaluated, data should be measured, she said, turning it into a logical relation: "evaluate : model :: measure : data".
Data should be documented as well. The sources, languages, curation rationale, methods of collection, and consent mechanisms are important pieces of metadata; they will allow researchers to compare data sets for characteristics that are important to their use case. She briefly mentioned The Stack, which is an experimental data set that Hugging Face created from code with permissive licenses in various programming languages collected from GitHub. Users can opt out of the data set if they desire; it is meant to be an experiment in creating a data set "where you try and make sure that people know that they are in it". The company is also working on opt-in data sets, but that is a much harder problem.
She is not part of an "ethics team" at Hugging Face, because that kind of organization can lead to problems; the team can be seen as a kind of "ethics police". She recommended that organizations that are trying to work on ethics in machine learning have ethics-minded people in various teams throughout the company. Those people can get together to compare notes; at Hugging Face, she is part of the ethics and society regulars, which operates that way.
She concluded with a quick recap. "Python is awesome", which was a theme throughout, Mitchell said. Machine-learning models mostly get their data from web-scraped data, which has a number of deficiencies, but that can be measured and controlled ("and we can use Python to do that"). Looking into the future five or ten years to see how these models could evolve to help is a useful tool to decide what to work on and how. In addition, data-set construction can be much more rigorous; it should also be measured and documented far better than it is today.
[I would like to thank LWN subscribers for supporting my travel to Salt Lake City for PyCon.]
Seeking the endgame for Debian's /usr merge
Like most other distributions, the Debian project decided to end the separation between the root and /usr filesystems years ago. Unlike most others, though, Debian is still working on the implementation of this decision. The upcoming Debian 12 ("bookworm") release will feature a merged /usr in most respects, but there are a couple of nagging issues that threaten to stretch this transition out for some time yet.At its core, the /usr merge is the project to move files out of root-level directories like /bin and /lib into the equivalent directories under /usr. Most distributors took a "rip the bandage off quickly" approach to this change, causing it to simply happen over the course of a single major-version upgrade. It was an abrupt change and not without problems but, for the most part, distributors got through it quickly.
Debian has taken a slower approach, spreading the transition over a few releases. If one looks closely at a fresh Debian install, either the current Debian 11 ("bullseye") or the upcoming "bookworm" release, one will see that directories like /bin and /lib exist only as symbolic links into their equivalent directories under /usr. It would seem that the merge process is complete.
There are some rough edges, though. If one looks into the packages installed on even a bookworm release, one will see that many of them are still installing into the top-level /bin and /lib directories. If the release is called anything but "Debian" (if it is a derivative distribution, for example), the dpkg package manager will emit a scary warning about how the system is broken. And, if one looks at the project's mailing lists, one will find ongoing discussions about the remaining problems with the transition, along with comments like this one from Bdale Garbee, who has in the past served as both Debian project leader and Technical Committee chair:
Merged-/usr seems to me to have brought great pain with no discernible benefit to Debian so far, and I at least have completely lost the thread on what the point of doing it was supposed to be.
All of this reflects a couple of fundamental problems that the project has not, as yet, figured out how to resolve.
dpkg and aliases
One of these problems is that much of this transition has been effected outside of dpkg, with the result that the Debian package manager lacks a complete understanding of how the system is structured. Specifically, the use of symbolic links to replace the top-level directories creates "aliases" — multiple paths to files — that dpkg does not properly understand. As a result, there is a scenario — involving renaming a file within a package, then moving that file to a different package — that can cause dpkg to delete files belonging to an installed package, thus corrupting the system when those packages are installed.
Problems like this are the inspiration behind the warning that dpkg prints on merged-/usr systems. The specific failure mode may seem obscure, but it is aggravated by a couple of factors. The first of those is that the end game for this whole transition involves moving files into their expected locations; rather than installing bash into /bin, the package would be changed to put it into /usr/bin instead. That is a lot of file moves; add to that the fact that moving files between packages is reasonably common in Debian, and the chances of steering users into this bug look fairly high.
Corrupted systems after an upgrade is just not part of the image that the Debian project has for itself, so this bug is a significant problem. It is the reason why the project has maintained a moratorium on the movement of files to their new locations under /usr — a moratorium that was recently renewed by the Technical Committee.
It is not uncommon to see project members blaming dpkg maintainer Guillem Jover for this problem. Jover has not hidden his disdain for how the transition has been handled, and is seen by many as preferring the addition of scary warnings over actually addressing the problem. But a careful reading of the lists can yield a more nuanced view. An attempt to have the Technical Committee force the complete removal of the warning from dpkg (for derivatives as well as for Debian itself) has not gone anywhere, and a number of developers feel that the substance (if not the wording) of the warning is appropriate. As Helmut Grohne put it:
The present discussion clearly shows that dpkg's support for how Debian deals with merged /usr is lacking. We are dealing with multiple file-loss scenarios (something we otherwise consider grave) and issuing a warning about such behaviour seems fine to me.
Meanwhile, developers continue to seek a way to fix this problem. Grohne
recently posted an extended
proposal on how dpkg could gain some new options to inform it
of the existence of directories. There has been a variety of
responses. Luca Boccassi said
that he intended to simply force-move everything after the bookworm
release, ending the aliasing as seen by dpkg and thus avoiding the
problem; "That should bring the matter to an end, without needing to
modify dpkg
". Simon McVittie, though, worried
that this sort of move was particularly likely to trigger the lost-file bug
rather than avoid it. Grohne tried to
adapt Boccassi's plan to avoid a number of problems that he found, but
eventually decided
that his approach, too, had too many problems. "The amount of
complexity we are piling up here becomes non-trivial
".
Jover, meanwhile, responded
to the proposal while avoiding the main development list; he described it
as "conceptually wrong
" and provided his reasoning in detail. Among
other things, informing dpkg of these links using separate
commands adds a "source of truth
" about the installed system that is
not found in any of the packages installed there. Jover did put some
effort, in that response, into thinking about how the situation might be
improved, but did not contribute thereafter.
The end result of all this is that the problems with dpkg remain, with more likely to be discovered, and there is still no clear picture of how they will be addressed. Until that issue is resolved, this transition will continue to loom over the Debian project.
Bootstrapping and interpreters
Most readers will be familiar with the "shebang" lines at the beginning of scripts that specify which interpreter a script should be fed to:
#!/bin/sh
It may be a bit more surprising to learn that natively compiled programs also specify an interpreter — specifically, the program that will load the executable into memory, link in dynamic libraries, and prepare it to run. This interpreter is stashed into the ELF program header as the PT_INTERP variable, and will normally be set to: /lib64/ld-linux-x86-64.so.2 on 64-bit Linux systems.
Regardless of whether one is trying to run a script or a compiled binary, little joy will result if the specified interpreter cannot be found. This creates a bit of a problem given that, in a merged-/usr system, these interpreters should be moved into /usr/bin and /usr/lib64, turning all of those interpreter strings into dangling references. Most of the time, the symbolic links added to the root directory paper over this problem, everything works, and nobody notices. But there is an exception.
The creation of a new root disk image containing a Debian installation is done with a bootstrap tool, usually either debootstrap or mmdebstrap. The bootstrap tools install the "essential set" of packages that every Debian system needs, then run their configuration scripts (in a chroot setting) to set up a basic, functioning installation. If, however, the packages in that essential set are changed to install their files under /usr, the programs needed to finish the setup will not find their interpreters and the installation will fail; that tends to lead to another round of calls to give up on this transition entirely.
In theory, all that one needs to do is to ensure that the appropriate
symbolic links are in place early in the bootstrap process. In practice,
it is far from so simple; among other things, the presence of those links
can, once again, confuse dpkg. At one point, Boccassi suggested
that Debian could be built with a modified PT_INTERP value and
changed shebang lines to sidestep the problem, but that led to a flurry of
complaints about breaking the Linux ABI, breaking compatibility with older
Debian releases, and losing the ability to compile
programs that would run on different distributions. As Russ Allbery put it:
"breaking the ABI is a Really Big Deal
". So that idea did not get
far.
Grohne took the time to put together a detailed look at the problem that should be required reading for anybody who is interested in the bootstrapping challenges. He outlined four different ways in which bootstrapping could be fixed and discussed the difficulties with each. His recommendation is to leave a handful of files in their old location for now while, in the long term, changing the way bootstrapping works to ensure that the requisite symbolic links are present from the beginning, and that they do not complicate the installation thereafter.
Now what?
As of this writing, neither problem has a definitive solution identified for it. A combination of avoiding file moves and keeping the interpreters at their old locations may be enough to get the bookworm release out the door successfully, but leaves a number of problems in place. The transition cannot be said, by any stretch, to be complete.
Some of the participants in the discussion evidently feel that the remaining problems are easily solved and that this transition is essentially done. Others clearly worry that, not only are the problems difficult, but that problems are still being discovered and that there are more to come. The latter view seems likely to be the more accurate one. As Technical Committee chair Sean Whitten said:
I am far from being an expert on the details of merged-/usr. But one thing I've noticed is that among the people who have spent the most time looking into it, the majority think that simple fixes are not going to be sufficient. Only a few people who have spent a lot of time on it still think that the fixes that are required are relatively simple ones.
LWN last looked at this transition just over one year ago; at that time, many of those involved were describing it as a social failure, and possibly a technical failure as well. Since then, progress has been made, and many Debian users are running on systems that are, for all practical purposes, fully merged. But the technical and social challenges remain as intransigent as ever.
Former Technical Committee member Gunnar Wolf described the
/usr merge as "the point we most came back to
" during his
time there. Perhaps a new spirit of cooperation and new technical insights
will bring this episode to a close during the upcoming "trixie" development
cycle. But it also seems plausible that the Technical Committee will find
itself hearing arguments about the /usr merge for a while yet; the
Debian community may well have more opportunities to wonder whether it
would have been better to just rip the bandage off and be done with it
years ago.
Special file descriptors in BPF
Developers learning the Unix (or POSIX in general) system-call set will quickly encounter file descriptors, which are used to represent open files and more. Developers also tend to learn early on that the first three file descriptors are special, with file descriptor zero being the standard input stream, one being standard output, and two being standard error. The kernel, though, does not normally attach any specific meaning to a given descriptor number, so it was somewhat surprising when a recent BPF patch series attempted to attach a special meaning to zero when used as a file descriptor.BPF objects (maps and such) normally go away when they are closed, usually when the creating process exits. They may be "pinned", though, which gives them a name in the BPF filesystem (usually under /sys/fs/bpf) and allows them to outlive the creating process. The existing API for the pinning of BPF objects is path-based, meaning that the caller provides a string containing the full path name to be created for an object.
The series in question, posted by Andrii Nakryiko, adds a mechanism to pin BPF objects using an open file descriptor instead of a path name to identify the containing directory. The feature itself is widely seen as a useful addition and is not controversial, but one aspect of it was. The patch series expanded an anonymous structure in the impressively sprawling bpf_attr union to contain a new path_fd field that would be used to provide the file descriptor identifying the directory in which (or below which) to pin the object. If path_fd were provided as zero, though, it would be interpreted to mean the calling process's current working directory — the same as the AT_FDCWD argument to system calls like openat2().
The motivation behind these semantics is not that hard to understand. This new field will have a value of zero by default if the calling process does not provide it. Interpreting that zero as "start from the current working directory" allows for an easy, backward compatible expansion of the interface, since programs that do not provide that file descriptor will behave as they did before. But this interpretation also means that no process can use file descriptor zero as the starting directory for this system call, and that was seen as a source of concern.
Christian Brauner quickly questioned
this decision, calling it "very counterintuitive to userspace and
pretty much guaranteed to cause subtle bugs
". He also asked if similar
practices were to be found in other parts of the BPF subsystem. Nakryiko
answered
in the affirmative:
Yes, it's a very bpf()-specific convention we've settled on a while ago. It allows a cleaner and simpler backwards compatibility story without having to introduce new flags every single time. Most of BPF UAPI by now dictates that (otherwise valid) FD 0 can't be used to pass it to bpf() syscall.
He added that the libbpf library goes out of its way to hide this behavior by reopening file descriptors that would otherwise be returned as zero.
Brauner did not like this convention:
I personally find this extremely weird to treat fd 0 as anything other than a random fd number as it goes against any userspace assumptions and drastically deviates from basically every file descriptor interface we have. I mean, you're not just saying fd 0 is invalid you're even saying it means AT_FDCWD.
There was evidently
some sort of off-list conversation, and Nakryiko later posted an
updated patch set that introduces a new flag to indicate whether a file
descriptor has been provided rather than checking for a zero value. But it
seems clear that the BPF community is not entirely thrilled by this change,
and wants to continue to treat that value as special. Alexei Starovoitov
said
that the design of Unix includes two fundamental mistakes: allowing zero to
be a valid file-descriptor value, and assigning special meanings to the
first three descriptor values — a decision that he called "just
awful
". Those file descriptors, he said, are "taken
" and should
not be used for any other purpose; the BPF developers decided to implement
part of that approach themselves:
Because of that, several years ago, we've decided to fix unix mistake #1 when it comes to bpf objects and started reserving fd=0 as invalid. This patch is proposing to do the same for path_fd (normal vfs fd) when it is passed to bpf syscall. I think it's a good trade-off and fits the rest of bpf uapi.
Brauner reiterated that disallowing zero as a file descriptor seemed strange, but clarified his bigger complaint with the first version of the patch set: it didn't just disallow that file descriptor, but assigned a separate and incompatible meaning to it. If every kernel subsystem could attribute its own meaning to specific file-descriptor numbers, he said, the results would quickly spiral out of control.
Ted Ts'o wondered if there could be security problems inherent in the BPF approach and suggested that it should perhaps be changed even if ABI incompatibility resulted. Nobody else, though, has raised security concerns with regard to this practice.
Linus Torvalds was highly critical of any code that treats specific file descriptors specially:
But fd 0 is in absolutely no way special. Anything that thinks that a zero fd is invalid or in any way different from (say) fd 5 is completely and utterly buggy by definition. [...]If bpf thinks that 0 is not a file descriptor, then bpf is simply wrong. No ifs, buts or maybes about it. It's like saying "1 is not a number". It's nonsensical garbage.
Brauner acknowledged, though, that is is probably too late to change the BPF subsystem's practice of treating file descriptor zero as invalid. That policy has been baked into the code for years, so it would be surprising if no code in the wild depended on it. The patch assigning a more special meaning to that descriptor number was intercepted in time, though, and it doesn't appear that this practice exists anywhere else in the code. So programs interacting with BPF will be unable to use file descriptor zero as an ordinary descriptor, but neither will they be expected to use it as a special value.
Supporting large block sizes
At the 2023 Linux Storage, Filesystem, Memory-Management and BPF Summit, Luis Chamberlain led a plenary session on kernel support for block sizes larger than 4KB. There are assumptions in the current kernel that the block size used by a block-layer device is less than or equal to the system's page size—both are usually 4KB today. But there have been efforts over the years to remove that restriction; that work may be heading toward fruition, in part because of the folio efforts of late, though there are still lots of areas that need attention.
Originally, storage devices used 512-byte blocks, but over time that has grown to 4KB and beyond, Chamberlain said. Supporting block sizes greater than the page size has been desired for years; the first related patches were posted 16 years ago and the topic comes up at every LSFMM, he said. There is a wiki page about the project as well.
![[Luis Chamberlain]](https://static.lwn.net/images/2023/lsfmb-chamberlain-sm.png "Luis Chamberlain")
XFS has supported 64KB blocks for quite some time, but only on systems that have 64KB pages; he believes some PowerPC-based systems were shipped with XFS filesystems using 64KB blocks. But the original goal of the long-ago patch set is the same as today: to support 64KB blocks (and other power-of-two sizes) on systems with 4KB pages. To that end, he has added an experimental option to his kdevops tool that will create NVMe devices with larger block sizes. You can format the devices and boot a system, but if the devices are enabled, the system crashes. Trying to solve that problem is how he got involved in this work.
He has a Git tree for collecting patches of interest for the effort. Beyond just creating the large-block devices, he has also added ways to test modified kernels in kdevops. Currently development and testing is ongoing using XFS.
Chamberlain is tracking the effort using "objectives and key results" (OKRs) in a spreadsheet; he is aware that some hate OKRs, but he is simply using them as a tracking tool for himself, though others are welcome to use them as well. In various parts of the talk, he displayed the OKR lists, starting with the list for converting to the iomap support layer.
The previous session on buffer-head removal, which was led by Hannes Reinecke, did not really address the block-device (bdev) cache, Chamberlain said. The bdev cache is important because some filesystems use it for metadata, and it uses buffer heads. As Reinecke said in that session, though, there may never come a time when buffer heads will be fully removed from the kernel.
For filesystems that want to support large block sizes, the right path is to use iomap, Chamberlain said. It will take a while for iomap to be fully ready to support block sizes larger than the page size, but there is a path to get there, he believes. The block layer itself still requires some work in order to support the larger sizes, contrary to Matthew Wilcox's assertion that nothing more was needed, Chamberlain said. There is agreement now that only 0-order folios will be allowed for buffer heads, which removes one of the entries from his list.
Ted Ts'o wanted to understand the business case for supporting these larger block sizes; he went back to the email proposing the LSFMM topic, which seemed to indicate the push is coming from the storage vendors. He asked: what are the use cases where a 32KB or 64KB block size makes sense? If he is to ask his company for time to work on this support, he needs to be able to justify it and he felt that part was left out of the discussion.
James Bottomley pointed out that Ts'o had mentioned 16KB database blocks in his session the previous day, but Ts'o said that the atomic-write support was a path to being able to write 16KB blocks without tearing (i.e. partial writes). Atomic writes can come in a reasonable time frame, and do not require the large-block support, which is a more sprawling effort. Reinecke said that there was a simple answer to the objection from Ts'o: if he could not justify working on large-block-size support, "then don't".
Reinecke said that supporting these larger blocks is something of an experiment. There is a belief that it will lead to better performance, but the only way to find out is to try it. Ts'o said that it seems like a huge project, so he would need to be able to justify putting people to work on it. Josef Bacik said that the session was not aimed at making that justification, rather it is trying to see what the status and plans are for the project. He suggested that the group move back on track.
There are a bunch of ancient filesystems in the kernel, Chamberlain said, that are not going to be updated; some, such as ReiserFS, are already slated for removal. There are others that might be removed, but supported via FUSE. He thinks that there are some old filesystems lacking mkfs tools, which makes them hard to test, thus hard to support. He thought it would be good to put together a plan for what to do with various old, likely unmaintained, filesystems.
Supporting folios larger than order-0 (single page) in filesystems is needed, he said, but there are questions about what needs to be done for memory compaction. Wilcox said that the memory compaction code has not yet been converted from pages to folios, so that needs to happen. There is also a need to be able to migrate larger folios (not order-0) from one zone to another to try to ensure that higher-order allocations will not fail. Once the conversion to folios happens, he or someone else can dig more into the migration issue.
Chamberlain said that he has been working with Dave Chinner on rebasing Chinner's older patch set that added support for block sizes larger than the page size for XFS; the needed changes now just boil down to two patches. Testing is ongoing to ensure that those patches have not broken anything. Once that has been established, the next step would be to test XFS on a real device with a larger block size.
Chamberlain wondered if other filesystems were interested in supporting larger block sizes. Bacik said that Btrfs already handles metadata in 16KB blocks, so he would like to make that work on larger-block devices. He would love to do it for data too, but work on that will not happen until after the iomap conversion for Btrfs data is done.
Bottomley said that Chinner's original patch set was much larger than two patches, so he wondered whether that was due to the folio conversion that had already gone into XFS. If so, what looks like a huge amount of work for supporting large block sizes may turn out to be relatively straightforward. Chamberlain confirmed that; for filesystems that want to support larger block sizes, it is much easier once the folio conversion has been done.
Handling metadata for those filesystems that are still using buffer heads may still be an issue, however. From afar, Darrick Wong noted that XFS has its own buffer cache internally, so its metadata handling can already use block sizes larger than the page size—"at least until memory fragmentation kills you". The part that does not work right now is that iomap is lacking a way to tell the memory-management subsystem that XFS needs multi-page folios that are at least of a certain size.
After some discussion of memory fragmentation issues, Wong suggested that someone should simply set up a modified XFS using 8KB blocks (and 4KB pages) in order to run MySQL on a system without much memory. The idea would be to see if it falls over any faster than a regular XFS with 4KB blocks. Chamberlain said that the issue of how to test these changes is one that needs to addressed; a test plan with specifics about how to measure the impacts (good or bad) of the changes is needed.
A decision on composefs
At the end of our February article about the debate around the composefs read-only, integrity-protected filesystem, it was predicted that the topic would come up at the 2023 Linux Storage, Filesystem, Memory-Management and BPF Summit. That happened on the second day of the summit when Alexander Larsson led a session on composefs. While the mailing-list discussion was somewhat contentious, the session was less so, since overlayfs can be made to fit the needs of the composefs use cases. It turns out that an entirely new filesystem is not really needed.
Larsson began by looking at the use case that spurred the creation of composefs. At Red Hat, image-based Linux systems are created using OSTree/libostree; they are not the typical physical block-device images, however, as they are more like "virtual images". There is a content-addressed store (CAS) that contains all of the file content for all of the images. In order to build a directory hierarchy for the virtual image, a branch gets checked out from the OSTree repository, which contains the metadata and directory information for the image; OSTree then builds the directory structure using hard links to the CAS entities.
![[Alexander Larsson]](https://static.lwn.net/images/2023/lsfmb-larsson-sm.png "Alexander Larsson")
A system created this way "is very lean", because it is flexible and easy to update, so the Red Hat developers want to use OSTree-based images for containers and other types of systems. But there is a missing feature that they would like to have: some kind of tampering prevention as with dm-verity. There are two main reasons that a tamper-proof filesystem is desired: security, to provide a trusted boot, for example, and safety, such as protecting the data used by a self-driving car. Fs-verity provides much of what they are looking for, but it does not go far enough; it is concerned only with protecting the file contents, not the file metadata or the directory structure.
So, back in November, he and Giuseppe Scrivano posted composefs, which is like a combination of a read-only filesystem, such as SquashFS or EROFS, with overlayfs. Composefs just contains the metadata and the directory structure; it gets mounted as the equivalent of the overlayfs upper layer, with the CAS as the lower layer. So referencing a file by its name actually resolves to the entry in the CAS.
If all of the files in the CAS have fs-verity enabled for them, those digest values can be used in the creation of the image for the composefs metadata, which itself is protected with fs-verity. When composefs is mounted, the expected digest for the metadata image is passed to the mount command, so that it can be verified; the Merkle tree of digests for the CAS is part of that image, so everything is protected against any kind of change (be it malicious or cosmic-ray induced).
In the "sometimes heated discussions about this", it turns out that there are already features in overlayfs "that sort of make this possible". Files can have extended attributes (xattrs) that specify that the metadata is separate from the file data (overlay.metacopy) and that the names are different in the layers (overlay.redirect). The idea would be to create an overlayfs with two filesystems: the CAS is the lowest layer and a read-only EROFS loopback image would be above that with its xattrs pointing into the CAS.
There are some missing features, though. In order to support fs-verity on the file contents, there needs to be a overlay.verity xattr to tell overlayfs to verify the file contents based on the digest in the xattr. There also needs to be a mount option to specify that every file must have a digest. There are pending patches to add those features to overlayfs.
There were some performance measurements ("of dubious quality") that were done using ls -lR which showed some lookup amplification in overlayfs. For no real reason, overlayfs was looking up the underlying CAS file; Amir Goldstein called overlayfs "too eager" and has posted patches to support lazy lookups, so that the lower-layer file is not looked up until it is actually needed. An overlay filesystem is a union filesystem, which combines the entries of all of the layers, but that is not needed for this use case, Larsson said. You could use overlay whiteouts to hide the underlying CAS files, but Goldstein's lazy-lookup patches also add data-only layers, which do not have the file names from their filesystems visible in the combined overlayfs.
The basic question for the room, Larsson said, was what the approach should be to getting something upstream to solve his (and others') use cases. "This where the talk gets kind of short because I think most people are leaning toward using the existing code in overlayfs", rather than add a new filesystem. It is less code to maintain, which is always beneficial, but also the features that would be added to overlayfs are useful in their own right.
There are a few cons, but "I think they're pretty minor"; he does not like loopback mounts because they are global and are not namespaced. In addition, the performance of the overlayfs version is roughly the same as composefs (after the lazy lookup is added), but having two filesystems does double the number of inodes and directory entries (dentries) that are in use. He wondered if anyone thought that a custom filesystem was the right approach.
If you ask a room full of kernel developers if a new filesystem is needed, "the answer is almost always going to be 'no'", Josef Bacik said to laughter; "you made our argument for us" since an existing filesystem can cover the needed features. Larsson agreed that he would rather not have to maintain a filesystem; "I have enough code to maintain".
Larsson was asked about the problems with loopback mounts. He said that there are people working on solutions, but a container must have a loopback device available. The loopback device is global, however, so it can see all of the loopback mounts in the entire system. Christian Brauner said that he has working patches for doing proper namespacing for global system devices like loopback; there are iSCSI people who are interested in it as well. He hopes that it is just a matter of time before that problem is solved.
There are two facets to the problem of global devices; they appear as device nodes in the /dev tree but are also sysfs entries, Brauner said. He did not want to do a "half-assed namespacing" where he only dealt with the device nodes and did not handle the sysfs entries, but he had to step carefully in order to avoid breaking backward compatibility.
Other mechanisms for handling the integrity and/or trust level of container images were discussed, some of which overlapped the FUSE passthrough discussion the previous day or the session on mounting filesystems in user namespaces coming later in the day. Allowing unprivileged users to mount random images from, say, DockerHub, is not something that will ever be supported, Brauner said. Goldstein agreed, noting that something like a BPF verifier for filesystem images would be needed to ensure that they would not crash the kernel. James Bottomley thought there was a class of simple filesystem images that the kernel could verify before mounting, even for unprivileged users. But Bottomley's idea was not entirely well-received in the room.
An introduction to EROFS
Gao Xiang gave an overview of the Extended Read-Only File System (EROFS) in a filesystem session at the 2023 Linux Storage, Filesystem, Memory-Management and BPF Summit. EROFS was added to Linux 5.4 in 2019 and has been increasingly used in places beyond its roots as a filesystem for Android and embedded devices. Container images based on EROFS are being used in many places these days, for example.
Unfortunately, this session was quite difficult for me to follow, so the report below is fragmentary and incomplete. There is a YouTube video of the session, but it suffers from nearly inaudible audio, though perhaps that will be addressed before long. The slides from the session are also available.
EROFS is a block-based, read-only filesystem with a "very simple" format, Xiang began. The earlier read-only filesystems had many limitations, such as not supporting compression, which is part of why EROFS was developed. EROFS stores its data in a block-aligned fashion, which is page-cache friendly; that alignment also allows direct I/O and DAX filesystem access.
![[Gao Xiang]](https://static.lwn.net/images/2023/lsfmb-xiang-sm.png "Gao Xiang")
SquashFS is another read-only filesystem, but it does not store its compressed data in a block-aligned fashion, which increases the I/O overhead. EROFS does its compression into fixed 4KB blocks in the filesystem, while SquashFS uses fixed-sized blocks of uncompressed data. In addition, SquashFS does not allow random-access in its directories, unlike EROFS; that means SquashFS requires linear searches for directory entries.
Replacing tar or cpio archives with a filesystem is a potential use case for EROFS. There has been a proposal from the confidential-computing community for a kernel tarfs filesystem, which would allow guest VMs to efficiently mount a tar file directly. But EROFS would be a better choice, he said. There is a proof-of-concept patch set that allows directly mounting a downloaded tar file using EROFS that performs better than unpacking the tarball to ext4, then mounting it in the guest using overlayfs.
There are still problems with this approach, including a lack of sharing in the page cache between guests that are using the same tar archive. Aleksa Sarai agreed that there was a problem with that, but thought that eliminating tar archives as the underlying format would go a long toward fixing it—along with a bunch of other problems. He also said that the EROFS approach is better than what's being done today, but believes that replacing the tar format in container images is needed.
There is currently a lot of effort that goes into optimizing image layout that is all needed solely due to the tar format; "in my mind, this is insanity", Sarai said. The community needs to stop expending so much energy working around the limitations of the tar format. There may be 500 instances of Bash in the guests on a system, but they cannot share the same inode in a tar-based format, so they are treated as distinct files. But the tar format is going to continue to need to be supported, Xiang said, so a compatible solution is needed.
He continued with features of EROFS, including the ability to do chunk-based deduplication of file data. The typical use case is for systems using EROFS with Nydus. EROFS optionally supports per-file compression with LZ4/LZMA, but uses smaller compression block sizes, which reduces the memory amplification that occurs with SquashFS. The data is decompressed in-place in order to reduce extra copies.
Recent use cases for EROFS take three basic forms. The first is an EROFS full image; those are used in compressed form for space saving at the cost of some performance, or uncompressed and shared among guests with DAX or FS-Cache. The second is to have an EROFS metadata-only image with an external source for the file data, such as a tar archive or other binary format. The third is to use EROFS with overlayfs as described in the previous session on composefs.
Using EROFS could potentially increase performance for machine-learning data sets, Gao said. These data sets often have millions of small files in a single directory; the training process will read the entire directory and choose files randomly from the list. Because of its compact layout, EROFS is potentially twice as fast as ext4 for those kinds of operations.
The session wound down with some discussion about using the clone-file-range ioctl() operation to do an overlayfs copy_up on files. A copy_up is performed when the lower-layer file is accessed for write; the file gets copied to the upper layer before it can be modified. If the layers are loopback-mounted files from the same filesystem, a copy-on-write operation could be done instead. Amir Goldstein seemed to think that something like that is possible and would be useful, but there is work needed to get there.
Memory-management documentation and development process
As the 2023 Linux Storage, Filesystem, Memory-Management and BPF Summit neared its conclusion, two sessions were held in the memory-management track on process-oriented topics. Mike Rapoport ran a session on memory-management documentation (or the lack thereof), while Andrew Morton talked about the state of the subsystem's development process in general. Both sessions were relatively brief and did not foreshadow substantial changes to come.
Documentation
Rapoport started by saying that documentation has become an annual topic. There has been some big progress since last year's session, he said: Matthew Wilcox had added a table of contents to the memory-management documentation and Rapoport had contributed "a half chapter". This major step forward was greeted with applause from the group. Taking a more serious tone, Rapoport asked for ideas that might lead to a better progress report next year.
Your editor felt the need to point out that, despite the existence of thousands of kernel developers who are paid to contribute code, there is not a single person paid to contribute to the documentation. Many developers try, and a fair amount of documentation work gets done, but it almost always has to be wedged in around the "real" work that people are paid to do. As long as that situation persists, it is going to be hard to see major improvements to the documentation. Matthew Wilcox commented that this is an example of the sort of "endemic corporate brokenness" that we see every day.
Steve Rostedt suggested refusing to accept patches that do not come with documentation; Rapoport answered that this approach would not help with the large amount of documentation debt the community has now. Rostedt said that some sort of "we'll take this patch after you document that" policy could be tried, but Pasha Tatashin pointed out that not everybody is a good writer, and the results from such a policy might not be to the community's liking.
Lorenzo Stoakes said that writers also have to be engineers to do the job properly. Vlastimil Babka pointed out that companies like to have nice technical blogs, and that perhaps some of the energy that goes in that direction could be put into creating documentation. SeongJae Park suggested using ChatGPT. But nobody seemed to have any ideas that would substantially improve the situation.
As the session came to its end, Rapoport was asked where the documentation is most in need of improvement; he answered that potential contributors should find an interesting empty spot in the current table of contents and fill it in.
Since the end of the conference, Stoakes, who is working on a book about Linux memory management, has offered to contribute parts of it to the kernel's documentation. That discussion has just begun, but it may well lead to some significant contributions in the near future.
![[Andrew Morton]](https://static.lwn.net/images/conf/2023/lsfmm/AndrewMorton-sm.png "Andrew Morton")
The state of the community
The final scheduled session in the memory-management track was the traditional discussion with maintainer Andrew Morton about the state of the community as a whole. He didn't have much to say. Everything that he proposed last year, including a move to using Git and changing how patches are handled on their way to the mainline, is working as intended. The mm-stable subtree, perhaps, is the least successful part, just because patches take a long time to stabilize. In response, he is becoming more active about hurrying people along. He has also started putting some of the less-finished patches into mm-stable to give them more stability.
When asked if he planned to kill mm-stable, the answer was "no", but he'll try to move stuff out of the unstable tree more quickly. There is a lot that goes into the stable tree during the last week of the development cycle, which is not ideal, he said.
Michal Hocko said that he likes how the process has changed over the last
year. It is much more transparent and a step in the right direction.
Nobody else had much to add, so the session came to a close after just a
few minutes.
Brief items
Security
Security quotes of the week
Surveillance ads require a massive, multi-billion-dollar surveillance dragnet, one that tracks you as you physically move through the world, and digitally, as you move through the web. Your apps, your phone and your browser are constantly gathering data on your activities to feed the ad-tech industry.— Cory DoctorowThis data is incredibly dangerous. There's so much of it, and it's so loosely regulated, that every spy, cop, griefer, stalker, harasser, and identity thief can get it for pennies and use it however they see fit. The ad-tech industry poses a risk to protesters, to people seeking reproductive care, to union organizers, and to vulnerable people targeted by scammers.
Ad-tech maintains the laughable pretense that all this spying is consensual, because you clicked "I agree" on some garbage-novella of impenetrable legalese that no one – not even the ad-tech companies' lawyers – has ever read from start to finish. But when people are given a real choice to opt out of digital spying, they do. Apple gave Ios users a one-click opt-out of in-app tracking and 96% of users clicked it (the other 4% must have been confused – or on Facebook's payroll). The decision cost Facebook $10b in the first year.
Until about now, most of the text online was written by humans. But this text has been used to train GPT3(.5) and GPT4, and these have popped up as writing assistants in our editing tools. So more and more of the text will be written by large language models (LLMs). Where does it all lead? What will happen to GPT-{n} once LLMs contribute most of the language found online?— Ross AndersonAnd it's not just text. If you train a music model on Mozart, you can expect output that's a bit like Mozart but without the sparkle – let's call it 'Salieri'. And if Salieri now trains the next generation, and so on, what will the fifth or sixth generation sound like?
[...] So there we have it. LLMs are like fire – a useful tool, but one that pollutes the environment. How will we cope with it?
The government didn't do its part, though. Despite the public outcry, investigations by Congress, pronouncements by President Obama, and federal court rulings. I don't think much has changed. The NSA canceled a program here and a program there, and it is now more public about defense. But I don't think it is any less aggressive about either bulk or targeted surveillance. Certainly its government authorities haven't been restricted in any way. And surveillance capitalism is still the business model of the Internet.— Bruce Schneier reflects on "Snowden Ten Years Later" (worth reading in its entirety)
Kernel development
Kernel release status
The current development kernel is 6.4-rc5, released on June 4. Linus said:
Nothing particularly strange here, most notable is probably just the quick revert of the module loading trial that caused problems for people in rc4 depending on just random timing luck (or rather, lack there-of). So if you tried rc4, and some devices randomly didn't work for you, that was likely the issue.
Stable updates: 6.3.6, 6.1.32, 5.15.115, 5.10.182, and 5.4.245 were released on June 5.
Distributions
NixOS 23.05 released
A new version of NixOS, which is a Linux distribution based on the Nix package manager, has been released: NixOS 23.05 is now available. The release notes list numerous updates, including Nix 2.13, Linux 6.1, glibc 2.37, Cinnamon 5.6, GNOME 44, and KDE Plasma 5.27.The 23.05 release was made possible due to the efforts of 1867 contributors, who authored 36566 commits since the previous release. Our thanks go the contributors who also take care of the continued stability and security of our stable release.NixOS is already known as the most up to date distribution while also being the distribution with the most packages. This release saw 16240 new packages and 13524 updated packages in Nixpkgs. We also removed 13466 packages in an effort to keep the package set maintainable and secure. In addition to packages the NixOS distribution also features modules and tests that make it what it is. This release brought 282 new modules and removed 183. In that process we added 2882 options and removed 728.
openSUSE Leap 15.5 released
Version 15.5 of the openSUSE Leap distribution has been released. This is not intended as a feature release, but brings updated versions of many packages. The project has also announced that there will be one more 15.x release before that series ends and users have to migrate to whatever its successor will be.Red Hat dropping support for LibreOffice
Red Hat's Matthias Clasen has let it be known that LibreOffice will be dropped from a future Red Hat Enterprise Linux release, and the future of its support in Fedora is unclear as well.
The Red Hat Display Systems team (the team behind most of Red Hat’s desktop efforts) has maintained the LibreOffice packages in Fedora for years as part of our work to support LibreOffice for Red Hat Enterprise Linux. We are adjusting our engineering priorities for RHEL for Workstations and focusing on gaps in Wayland, building out HDR support, building out what’s needed for color-sensitive work, and a host of other refinements required by Workstation users. This is work that will improve the workstation experience for Fedora as well as RHEL users, and which, we hope, will be positively received by the entire Linux community.The tradeoff is that we are pivoting away from work we had been doing on desktop applications and will cease shipping LibreOffice as part of RHEL starting in a future RHEL version. This also limits our ability to maintain it in future versions of Fedora.
Distributions quote of the week
There are different degrees of badness. E.g. Epiphany, which I maintain, has a [Flatpak] sandbox hole that allows it to read and write your Downloads directory, and another hole that allows it to talk to Geoclue. These are both unacceptable, but certainly not as bad as allowing read/write access to the user's home directory or root filesystem, which many apps actually do.— Michael CatanzaroFlatpak could be pretty darn secure, but only if we stop allowing this, and I fear that would likely result in applications abandoning the platform. This is a major threat IMO.
Development
Rust 1.70.0 released
Version 1.70.0 of the Rust language is out. Changes include enabling the "sparse" protocol for Cargo, a couple of new types for the initialization of shared data, and more. "You should see substantially improved performance when fetching information from the crates.io index."
Page editor: Jake Edge
Announcements
Newsletters
Distributions and system administration
Development
Meeting minutes
Miscellaneous
Calls for Presentations
CFP Deadlines: June 8, 2023 to August 7, 2023
The following listing of CFP deadlines is taken from the LWN.net CFP Calendar.
| Deadline | Event Dates | Event | Location |
|---|---|---|---|
| June 12 | October 3 October 5 |
PGConf NYC | New York, US |
| June 16 | September 17 September 18 |
Tracing Summit | Bilbao, Spain |
| July 2 | November 3 November 5 |
Ubuntu Summit | Riga, Latvia |
| July 7 | September 13 September 14 |
All Systems Go! 2023 | Berlin, Germany |
| July 17 | October 17 October 19 |
X.Org Developers Conference 2023 | A Coruña, Spain |
| July 21 | September 13 | eBPF Summit 2023 | online |
| July 29 | September 8 September 9 |
OLF Conference 2023 | Columbus, OH, US |
| July 31 | October 7 October 8 |
LibreOffice - Ubuntu Conference Asia 2023 | Surakarta, Indonesia |
| July 31 | November 7 November 9 |
Open Source Monitoring Conference | Berlin, Germany |
| July 31 | November 27 November 29 |
Deutsche Open Stack Tage | Berlin, Germany |
| August 6 | November 13 November 15 |
Linux Plumbers Conference | Richmond, VA, US |
If the CFP deadline for your event does not appear here, please tell us about it.
Upcoming Events
Events: June 8, 2023 to August 7, 2023
The following event listing is taken from the LWN.net Calendar.
| Date(s) | Event | Location |
|---|---|---|
| June 13 June 15 |
Open Infrastructure Summit | Vancouver, Canada |
| June 13 June 15 |
Beam Summit 2023 | New York City, US |
| June 14 | Ceph Days Korea 2023 | Seoul, South Korea |
| June 14 June 15 |
KVM Forum 2023 | Brno, Czech Republic |
| June 15 | Ceph Days Vancounver | Vancouver, Canada |
| June 15 June 17 |
Open Source Festival Africa | Lagos, Nigeria |
| June 16 June 18 |
Devconf.CZ 2023 | Brno, Czech Republic |
| June 20 June 22 |
SUSECON München 2023 | München, Germany |
| June 27 | PostgreSQL Conference Germany | Essen, Germany |
| June 28 June 30 |
Embedded Open Source Summit | Prague, Czech Republic |
| July 13 July 16 |
Free and Open Source Yearly | Portland OR, US |
| July 15 July 21 |
aKademy 2023 | Thessaloniki, Greece |
| July 26 July 31 |
GUADEC | Riga, Latvia |
| August 2 August 4 |
Flock to Fedora | Cork, Ireland |
| August 5 August 6 |
FrOSCon 18 | Hochschule Bonn-Rhein-Sieg, Germany |
If your event does not appear here, please tell us about it.
Security updates
Alert summary June 1, 2023 to June 7, 2023
| Dist. | ID | Release | Package | Date |
|---|---|---|---|---|
| Debian | DSA-5419-1 | stable | c-ares | 2023-06-07 |
| Debian | DSA-5418-1 | stable | chromium | 2023-06-03 |
| Debian | DLA-3445-1 | LTS | cpio | 2023-06-04 |
| Debian | DLA-3440-1 | LTS | cups | 2023-06-01 |
| Debian | DLA-3439-1 | LTS | libwebp | 2023-05-31 |
| Debian | DLA-3446-1 | LTS | linux-5.10 | 2023-06-05 |
| Debian | DLA-3444-1 | LTS | mariadb-10.3 | 2023-06-03 |
| Debian | DLA-3444-1 | LTS | mariadb-10.3 | 2023-06-03 |
| Debian | DLA-3442-1 | LTS | nbconvert | 2023-06-03 |
| Debian | DLA-3426-2 | LTS | netatalk | 2023-06-01 |
| Debian | DSA-5417-1 | stable | openssl | 2023-05-31 |
| Debian | DLA-3441-1 | LTS | sofia-sip | 2023-06-02 |
| Debian | DLA-3436-2 | LTS | sssd | 2023-05-31 |
| Debian | DLA-3427-2 | LTS | texlive-bin | 2023-05-31 |
| Debian | DLA-3443-1 | LTS | wireshark | 2023-06-03 |
| Fedora | FEDORA-2023-d53831b69d | F38 | ImageMagick | 2023-06-03 |
| Fedora | FEDORA-2023-3317c9b824 | F37 | bitcoin-core | 2023-06-01 |
| Fedora | FEDORA-2023-1bae6b7751 | F38 | bitcoin-core | 2023-05-31 |
| Fedora | FEDORA-2023-37eac50e9b | F38 | curl | 2023-06-07 |
| Fedora | FEDORA-2023-6e5d4757df | F37 | editorconfig | 2023-06-01 |
| Fedora | FEDORA-2023-ca393d660a | F37 | edk2 | 2023-06-01 |
| Fedora | FEDORA-2023-af4cfc9c3c | F38 | firefox | 2023-06-07 |
| Fedora | FEDORA-2023-f3824383be | F38 | mingw-python-requests | 2023-06-04 |
| Fedora | FEDORA-2023-b534ca7056 | F38 | mod_auth_openidc | 2023-05-31 |
| Fedora | FEDORA-2023-964eb00fc6 | F37 | openssl | 2023-06-04 |
| Fedora | FEDORA-2023-026c8ba371 | F38 | openssl | 2023-06-03 |
| Fedora | FEDORA-2023-690e150a39 | F38 | pypy | 2023-05-31 |
| Fedora | FEDORA-2023-81bb8e3b99 | F38 | pypy3.9 | 2023-05-31 |
| Fedora | FEDORA-2023-994ecd7dbc | F38 | python3.10 | 2023-05-31 |
| Fedora | FEDORA-2023-56cefa23df | F37 | python3.6 | 2023-06-04 |
| Fedora | FEDORA-2023-d8b0003ecd | F38 | python3.8 | 2023-05-31 |
| Fedora | FEDORA-2023-d261122726 | F37 | texlive-base | 2023-06-04 |
| Fedora | FEDORA-2023-23cc337543 | F37 | webkitgtk | 2023-06-03 |
| Fedora | FEDORA-2023-9e75e38b47 | F38 | webkitgtk | 2023-06-03 |
| Oracle | ELSA-2023-3425 | OL8 | cups-filters | 2023-06-06 |
| Oracle | ELSA-2023-3423 | OL9 | cups-filters | 2023-06-06 |
| Oracle | ELSA-2023-3349 | OL8 | kernel | 2023-06-06 |
| Oracle | ELSA-2023-3433 | OL8 | webkit2gtk3 | 2023-06-06 |
| Oracle | ELSA-2023-3432 | OL9 | webkit2gtk3 | 2023-06-06 |
| Red Hat | RHSA-2023:3380-01 | EL8.2 | apr-util | 2023-06-03 |
| Red Hat | RHSA-2023:3360-01 | EL8.4 | apr-util | 2023-06-03 |
| Red Hat | RHSA-2023:3425-01 | EL8 | cups-filters | 2023-06-06 |
| Red Hat | RHSA-2023:3429-02 | EL8.1 | cups-filters | 2023-06-06 |
| Red Hat | RHSA-2023:3428-01 | EL8.2 | cups-filters | 2023-06-06 |
| Red Hat | RHSA-2023:3427-02 | EL8.4 | cups-filters | 2023-06-05 |
| Red Hat | RHSA-2023:3426-01 | EL8.6 | cups-filters | 2023-06-06 |
| Red Hat | RHSA-2023:3423-01 | EL9 | cups-filters | 2023-06-06 |
| Red Hat | RHSA-2023:3424-02 | EL9.0 | cups-filters | 2023-06-05 |
| Red Hat | RHSA-2023:3460-01 | EL8.4 | curl | 2023-06-06 |
| Red Hat | RHSA-2023:3481-01 | EL7 | emacs | 2023-06-06 |
| Red Hat | RHSA-2023:3382-01 | EL8.2 | git | 2023-06-03 |
| Red Hat | RHSA-2023:3361-01 | EL8.6 | gnutls | 2023-06-03 |
| Red Hat | RHSA-2023:3349-01 | EL8 | kernel | 2023-06-03 |
| Red Hat | RHSA-2023:3461-01 | EL8.4 | kernel | 2023-06-06 |
| Red Hat | RHSA-2023:3388-01 | EL8.6 | kernel | 2023-05-31 |
| Red Hat | RHSA-2023:3465-01 | EL9.0 | kernel | 2023-06-06 |
| Red Hat | RHSA-2023:3350-01 | EL8 | kernel-rt | 2023-06-03 |
| Red Hat | RHSA-2023:3462-01 | EL8.4 | kernel-rt | 2023-06-06 |
| Red Hat | RHSA-2023:3470-01 | EL9.0 | kernel-rt | 2023-06-06 |
| Red Hat | RHSA-2023:3351-01 | EL8 | kpatch-patch | 2023-06-03 |
| Red Hat | RHSA-2023:3517-01 | EL8.4 | kpatch-patch | 2023-06-06 |
| Red Hat | RHSA-2023:3431-01 | EL8.6 | kpatch-patch | 2023-06-06 |
| Red Hat | RHSA-2023:3490-01 | EL9.0 | kpatch-patch | 2023-06-06 |
| Red Hat | RHSA-2023:3408-01 | EL8.6 | openssl | 2023-06-01 |
| Red Hat | RHSA-2023:3403-01 | EL8.6 | pcs | 2023-05-31 |
| Red Hat | RHSA-2023:3394-01 | EL8.6 | pki-core:10.6 | 2023-05-31 |
| Red Hat | RHSA-2023:3397-01 | EL8.6 | qatzip | 2023-05-31 |
| Red Hat | RHSA-2023:3433-01 | EL8 | webkit2gtk3 | 2023-06-06 |
| Red Hat | RHSA-2023:3432-01 | EL9 | webkit2gtk3 | 2023-06-06 |
| Slackware | SSA:2023-153-01 | cups | 2023-06-02 | |
| Slackware | SSA:2023-157-01 | mozilla | 2023-06-06 | |
| Slackware | SSA:2023-153-02 | ntp | 2023-06-02 | |
| SUSE | SUSE-SU-2023:2344-1 | MP4.3 SLE15 oS15.4 oS15.5 | ImageMagick | 2023-06-01 |
| SUSE | SUSE-SU-2023:2345-1 | SLE12 | ImageMagick | 2023-06-01 |
| SUSE | SUSE-SU-2023:2357-1 | SLE15 oS15.4 | ImageMagick | 2023-06-02 |
| SUSE | SUSE-SU-2023:2390-1 | MP4.3 SLE15 SES7 SES7.1 oS15.4 oS15.5 | apache-commons-fileupload | 2023-06-06 |
| SUSE | openSUSE-SU-2023:0117-1 | osB15 | chromium | 2023-05-31 |
| SUSE | SUSE-SU-2023:2347-1 | MP4.2 MP4.3 SLE15 SLE-m5.2 SLE-m5.3 SLE-m5.4 SES7 SES7.1 oS15.4 oS15.5 osM5.3 | cups | 2023-06-01 |
| SUSE | SUSE-SU-2023:2346-1 | OS9 SLE12 | cups | 2023-06-01 |
| SUSE | SUSE-SU-2023:2351-1 | SLE-m5.2 | installation-images | 2023-06-01 |
| SUSE | SUSE-SU-2023:0796 | MP4.3 SLE15 SLE-m5.3 SLE-m5.4 oS15.4 osM5.3 | kernel | 2023-06-06 |
| SUSE | SUSE-SU-2023:0749 | SLE15 SLE-m5.3 SLE-m5.4 oS15.4 osM5.3 | kernel | 2023-06-06 |
| SUSE | SUSE-SU-2023:2356-1 | MP4.3 SLE15 SLE-m5.3 SLE-m5.4 oS15.4 osM5.3 | libvirt | 2023-06-02 |
| SUSE | SUSE-SU-2023:0305 | MP4.3 SLE15 SES7 SES7.1 oS15.4 | openssl-1_0_0 | 2023-06-06 |
| SUSE | SUSE-SU-2023:2343-1 | MP4.2 SLE15 SLE-m5.1 SLE-m5.2 SES7 SES7.1 | openssl-1_1 | 2023-06-01 |
| SUSE | SUSE-SU-2023:2342-1 | MP4.3 SLE15 SLE-m5.3 SLE-m5.4 oS15.4 osM5.3 | openssl-1_1 | 2023-06-01 |
| SUSE | SUSE-SU-2023:2378-1 | OS9 SLE12 | openstack-heat, openstack-swift, python-Werkzeug | 2023-06-05 |
| SUSE | SUSE-SU-2023:2379-1 | OS8 SLE12 | openstack-heat, python-Werkzeug | 2023-06-05 |
| SUSE | SUSE-SU-2023:2360-1 | OS9 SLE12 | openvswitch | 2023-06-02 |
| SUSE | SUSE-SU-2023:2358-1 | SLE12 | qemu | 2023-06-02 |
| SUSE | SUSE-SU-2023:2334-1 | MP4.3 SLE15 SLE-m5.2 SLE-m5.3 SLE-m5.4 oS15.4 oS15.5 osM5.3 | tiff | 2023-05-31 |
| Ubuntu | USN-6129-1 | 20.04 22.04 22.10 23.04 | avahi | 2023-06-01 |
| Ubuntu | USN-6128-2 | 16.04 | cups | 2023-06-01 |
| Ubuntu | USN-6128-1 | 18.04 20.04 22.04 22.10 23.04 | cups | 2023-06-01 |
| Ubuntu | USN-6143-1 | 20.04 | firefox | 2023-06-07 |
| Ubuntu | USN-6136-1 | 22.04 22.10 23.04 | frr | 2023-06-05 |
| Ubuntu | USN-6140-1 | 22.10 23.04 | go | 2023-06-06 |
| Ubuntu | USN-6137-1 | 20.04 22.04 22.10 23.04 | libraw | 2023-06-05 |
| Ubuntu | USN-6144-1 | 20.04 22.04 | libreoffice | 2023-06-07 |
| Ubuntu | USN-6138-1 | 20.04 22.04 22.10 23.04 | libssh | 2023-06-05 |
| Ubuntu | USN-6126-1 | 22.04 22.10 23.04 | libvirt | 2023-05-31 |
| Ubuntu | USN-6127-1 | 20.04 22.04 22.10 | linux, linux-aws, linux-aws-5.15, linux-azure, linux-azure-5.15, linux-gcp, linux-gcp-5.15, linux-gke, linux-gke-5.15, linux-gkeop, linux-hwe-5.15, linux-hwe-5.19, linux-ibm, linux-kvm, linux-lowlatency, linux-lowlatency-hwe-5.15, linux-oracle, linux-oracle-5.15, linux-raspi | 2023-05-31 |
| Ubuntu | USN-6130-1 | 14.04 16.04 18.04 | linux, linux-aws, linux-aws-hwe, linux-azure, linux-azure-4.15, linux-gcp, linux-gcp-4.15, linux-hwe, linux-kvm, linux-oracle, linux-snapdragon | 2023-06-01 |
| Ubuntu | USN-6131-1 | 18.04 20.04 | linux, linux-aws, linux-azure, linux-azure-5.4, linux-gcp, linux-gcp-5.4, linux-gke, linux-gkeop, linux-hwe-5.4, linux-ibm, linux-ibm-5.4, linux-kvm, linux-oracle, linux-oracle-5.4 | 2023-06-01 |
| Ubuntu | USN-6132-1 | 18.04 20.04 | linux-aws-5.4, linux-bluefield | 2023-06-01 |
| Ubuntu | USN-6135-1 | 20.04 22.04 | linux-azure-fde, linux-azure-fde-5.15 | 2023-06-02 |
| Ubuntu | USN-6133-1 | 22.04 | linux-intel-iotg | 2023-06-01 |
| Ubuntu | USN-6134-1 | 20.04 | linux-intel-iotg-5.15 | 2023-06-01 |
| Ubuntu | USN-6142-1 | 16.04 18.04 20.04 | nghttp2 | 2023-06-06 |
| Ubuntu | USN-6112-2 | 20.04 22.04 22.10 23.04 | perl | 2023-06-05 |
| Ubuntu | USN-6139-1 | 14.04 16.04 18.04 20.04 22.04 22.10 23.04 | python2.7, python3.10, python3.11, python3.5, python3.6, python3.8 | 2023-06-05 |
| Ubuntu | USN-6141-1 | 22.04 22.10 | xfce4-settings | 2023-06-06 |
Kernel patches of interest
Kernel releases
Architecture-specific
Core kernel
Device drivers
Device-driver infrastructure
Documentation
Filesystems and block layer
Memory management
Networking
Security-related
Virtualization and containers
Miscellaneous
Page editor: Jonathan Corbet