
Leading items
Welcome to the LWN.net Weekly Edition for June 2, 2017
This edition contains the following feature content:
- The unexpected effectiveness of Python in science: this report from a PyCon keynote looks at how Python came to be successful in the scientific field, and how it can help to solve the reproducibility problem.
- Keeping Python competitive: what can be done to make Python performance competitive with that of other languages?
- Trio and the future of asynchronous execution in Python: a different approach to asynchronous execution and how it might influence the future direction of the language.
- Python ssl module update: the ongoing evolution of Python's ssl module.
- The "rare write" mechanism: a proposed kernel-hardening mechanism with some interesting implementation challenges.
- Toward non-blocking asynchronous I/O: asynchronous I/O in the kernel has never quite lived up to its name; this article describes some work to get a bit closer to that goal.
- What's new in gnuplot 5.2: the upcoming gnuplot release brings a number of interesting new features.
This week's edition also includes these inner pages:
- Brief items Brief news items from throughout the community.
- Announcements Newsletters, conferences, security updates, patches, and more.
Please enjoy this week's edition, and, as always, thank you for supporting LWN.net.
The unexpected effectiveness of Python in science
In a keynote on the first day of PyCon 2017, Jake VanderPlas looked at the relationship between Python and science. Over the last ten years or so, there has been a large rise in the amount of Python code being used—and released—by scientists. There are reasons for that, which VanderPlas described, but, perhaps more importantly, the growing practice of releasing all of this code can help solve one of the major problems facing science today: reproducibility.
VanderPlas said that it was his sixth PyCon; he started coming as "scruffy PhD. student" on a travel grant from the Python Software Foundation. In those days, he never imagined that he might some day be addressing the conference.
He likened PyCon to a mosaic; other conferences, like the SciPy conference or DjangoCon, give attendees a look at a specific slice of the Python community. At PyCon "you get it all". Each slice of the Python community has its own way of doing things, its own tools, and so on. In a conversation at PyCon, he once heard someone describe IPython as bloated and said that it promoted bad software practices, which was exactly the opposite of what he thought since he uses the tool regularly. That comment reflects that the other person uses Python for different reasons than he does. He suggested that attendees take the opportunity of the conference to talk to others who use Python in a different way; it might lead to new tools or insights.
He has worked on various projects, including SciPy, scikit-learn, and Astropy. He has a blog and has written several books on Python topics. His day job is at the University of Washington's eScience Institute, where he helps researchers "use computing more effectively", especially on large data sets.
Astronomy
Beyond all that, VanderPlas is an astronomer; he wanted to talk about how he uses Python as a scientist and astronomer. He put up a slide (Speaker Deck slides) showing Edwin Hubble at the eyepiece of a telescope in 1949, which is "a nice, romantic view of astronomy". But, he noted that in his ten years as an astronomer, he has never looked through a lens; these days, astronomers do database queries, he said.
![[Jake VanderPlas]](https://static.lwn.net/images/2017/pycon-vanderplas-sm.jpg "Jake VanderPlas")
He put up slides showing various kinds of telescopes that are being used today, as well as some of the visual output from them. Those interested will want to look at the slides and the YouTube video of the talk. He started with the Hubble Space Telescope; it has been in orbit since 1990 and one thing it has produced is an "ultra-deep field" image of a tiny section of the sky (roughly 1/10 of the full moon in size). That allowed astronomers to see galaxies that were up to 13 billion light years away. A complementary project was the Sloan Sky Survey that scanned the entire sky rather than at a single point. Spectrographic analysis of the data allows seeing the three-dimensional shape of the universe.
He then showed the artist's impression of the TRAPPIST-1 exoplanetary system from its Wikipedia entry. That is a system that has been determined to have seven rocky planets, some of which are in the habitable zone where liquid water can exist. In reality, the Kepler space telescope sees that system as four or so grayscale pixels; the wobbles and changes in brightness indicate when these planets pass in front of the star.
To extract information from that data requires "incredibly intricate statistical modeling of the system". That, in turn, means a complicated data-processing pipeline. That work is done in Python and the code is available on GitHub. It is one example of the scientific community "embracing the norms of the open-source community", VanderPlas said.
The James Webb Space Telescope is another instrument; it has a mirror that is three times the size of Hubble's. It is not as sensitive to visible light, but instead is tuned for infrared light. It might be able to actually image exoplanets but, more importantly, may be able to do spectroscopic measurement of light passing through the atmosphere of those planets. That is the "holy grail in exoplanet science", he said. It is a long shot, but it may detect oxygen or ozone in an atmosphere, which would be a sign of life since there is no geophysical way to produce those gases. Once again, the Python tools being used are available.
A project that he worked on as a graduate student, the Large Synoptic Survey Telescope (LSST), will really change every part of astronomy over the next ten years, he said. It has a three-gigapixel camera, which is the largest digital camera ever created. That requires a CCD that is the size of a person.
LSST will take two snapshots every thirty seconds for ten years, which will produce a ten-year time lapse of the full southern night sky from Chile. Each snapshot is the equivalent of around 1500 HDTV images and each night will require 15-30 terabytes of storage. By the end of the ten years, hundreds of petabytes will have been generated. There is a 600-page book that describes various things that can be done with the data and the processing code, in Python and C++, is available.
A graph of the mentions of programming languages in peer-reviewed papers in astronomy publications since 2000 shows Python making the "hockey stick" shape around 2011. Fortran, MATLAB, and IDL are all pretty flat since Python began that rise. IDL, which was the leader until 2015 or so, has actually shown a decline, which is good, he said, because it has a closed-source license.
Why Python?
When Guido van Rossum started Python, he never intended it to be the primary language for programmers. He targeted it as a teaching language and thought programs would be 10-50 lines long; a 500-line program would be near the top end. Obviously things have changed a bit since then. But, VanderPlas asked, what makes Python so effective for science?
Python's ability to interoperate with other languages is one key feature, he said. He paraphrased Isaac Newton: "If I have seen further, it is by importing from the code of giants." If you have to reinvent the wheel every time you extend the study, VanderPlas said, it will never happen.
David Beazley wrote a paper on "Scientific Computing with Python" back in 2000, which advocated the use of Python for science long before it was used much at all in those fields. Beazley mentioned all the different tools and data types that scientists have to deal with; it often takes a lot of effort to pull all of those things together.
Similarly, John Hunter, who created the Matplotlib plotting library for Python, described his previous work process in a SciPy 2012 keynote. He had Perl scripts that called C++ numerical programs, which generated data that got loaded in MATLAB or gnuplot. IPython creator Fernando Perez also described an awk/sed/bash environment for running C programs on supercomputers that he used as a graduate student. There was Perl, gnuplot, IDL, and Mathematica being used as well.
For science, "Python is glue", VanderPlas said. It allows scientists to use a high-level syntax to wrap C and Fortran programs and libraries, which is where most of the computation is actually done.
Another important feature is the "batteries included" philosophy of Python. That means there are all sorts of extras that come with the language; "compare that to C or C++ out of the box", he said. For those things that are not covered in the standard library, there is a huge ecosystem of third party libraries to fill in the gaps. People like Travis Oliphant, who created NumPy and SciPy, were able to add value by connecting low-level libraries to high-level APIs to make them easier to access and use.
The Python scientific stack has "ballooned over the last few years". There are multiple levels to that stack, starting with NumPy, IPython (and its successor, Jupyter), Cython, and others at the lowest level, moving through tools like Matplotlib, Pandas, and SciPy, etc., and then to libraries like scikit-learn, SymPy, StatsModels, and more. On top of those are various field-specific packages like Astropy, Biopython, SunPy, and beyond. If you have a problem you want to solve in Python, you will most likely find something available to help on GitHub, VanderPlas said.
The simple and dynamic nature of the language is another reason that Python fits well with science. He put up the classic "import antigravity" xkcd comic as something of an example. Python is fun to write and, for the most part, it is a matter of putting down what it is you want to happen. As Perry Greenfield put it at a PyAstro 2015 talk: Python is powerful for developers, but accessible to astronomers, which has a huge benefit that is not really being recognized or acknowledged.
Something that is often overlooked about scientific programming is that the speed of development is of primary importance, while the speed of execution is often a secondary consideration. Sometimes people are incredulous that petabytes of data are being processed using Python; they often ask "why don't you use C?" His half-joking response is: "Why don't you commute by airplane instead of by car? It is so much faster!"
Scientific programming is done in a non-linear fashion, generally. A scientist will take their data set and start playing around with it; there will be a lot of back and forth exploratory work that is done. For that, Jupyter notebooks are ideal, though they may not be a good fit for software development, VanderPlas said.
Impact on science
The "open ethos" of Python also makes it a good fit for science. Ten years ago, it was not the case that there were open repositories of code for telescopes, but over that time frame or longer science has been experiencing something of a replication crisis. The headlines of various publications are proclaiming that science is crumbling because peers are unable to reproduce published results.
Solving that problem is important and most who are looking at solving it are landing on the idea of "open science". That is starting to happen, he said. When the Laser Interferometer Gravitational-Wave Observatory (LIGO) detected the "incredible event" of "ripples in spacetime" caused by two black holes merging, part of what was released with the research was Jupyter notebooks with the data and analysis. "This is the way forward for science", he said.
He is also trying to "walk the walk" with two of his books. His Python Data Science Handbook and A Whirlwind Tour of Python are both available as Jupyter notebooks.
Python is really influencing science, he said. For example, the Astropy library is gaining popularity and a community. Astronomers are rallying around it, citing it in papers, and adding more tools to it.
The open-source community, and Python in particular, do things differently than academics and scientists have always done things. But "we've been able to learn" from open source and Python, VanderPlas said, and he hopes that leads to the downfall of the reproducibility problem. "The open-source ethos is such a good fit for science".
In conclusion, he returned to the idea of PyCon as a mosaic. He reiterated the idea that attendees should seek out those who do things differently than they do. Those communities have different approaches and tools; sitting in on talks from outside of your own communities can be highly beneficial. "You never know", it might just end up changing the way your field is done.
[I would like to thank the Linux Foundation for travel assistance to Portland for PyCon.]
Keeping Python competitive
Victor Stinner sees a need to improve Python performance in order to keep it competitive with other languages. He brought up some ideas for doing that in a 2017 Python Language Summit session. No solid conclusions were reached, but there is a seemingly growing segment of the core developers who are interested in pushing Python's performance much further, possibly breaking the existing C API in the process.
The "idea is to make Python faster", he said, but Python is not as easy to optimize as other languages. For one thing, the C API blocks progress in this area. PyPy has made great progress with its CPyExt API for C extensions, but it still has a few minor compatibility problems. PyPy tried to reimplement the NumPy extension a few years back, so that it would work with PyPy, but that effort failed. NumPy is one of the C extensions to Python that essentially must work for any alternative implementation. But the C API blocks CPython enhancements as well—Gilectomy, for example. It would be nice to find a way to change that, he said.
![[Victor Stinner]](https://static.lwn.net/images/2017/pls-stinner-sm.jpg "Victor Stinner")
A limited stable ABI has been defined for Python, but the full API, which is a superset of the ABI, can change between releases. The ABI is not tested, however; there is no tool to do so. Stinner said he knows of multiple regressions in the ABI, for example. The standard library is not restricted to only using the stable ABI; thus the default is the full API. All of that makes the ABI useless in practice. But Gilectomy needs to use a somewhat different C API to gain parallelism.
A different C API could perhaps provide a benefit that would act as a carrot for users to switch to using it, but he is not sure what should be offered. It is, in some ways, similar to the Python 2 to 3 transition, changing the API for performance or parallelism may not provide enough incentive for extension authors and users to port their existing code.
The C API is used both by the CPython core and C extensions. Beyond that, it used by low-level debuggers as well. But all of the header files for Python reside in the same directory, which makes it hard to determine what is meant to be exposed and what isn't. In the past, there have been some mistakes in adding to the API when that wasn't the intent. It might make sense to break out the headers that are meant to describe the API into their own directory, he suggested.
Python 3.7 is as fast as Python 2.7 on most benchmarks, but 2.7 was released in 2010. Users are now comparing Python performance to that of Rust or Go, which had only been recently announced in 2010. In his opinion, the Python core developers need to find a way to speed Python up by a factor of two in order for it to continue to be successful.
One way might be just-in-time (JIT) compilation, but various projects have been tried (e.g. Unladen Swallow, Pyston, and Pyjion) and none has been successful, at least yet. PyPy has made Python up to five times faster; "should we drop CPython and promote PyPy?". Many core developers like CPython and the C API, however. But, in his opinion, if Python is to be competitive in today's language mix, the project needs to look at JIT or moving to PyPy.
He had some other ideas to consider. Perhaps a new language could be created that is similar to Python but stricter, somewhat like Hack for PHP. He is not sure that would achieve his 2x goal, though. Compilation ahead of time (AoT) using guards that are checked at runtime, like Stinner's FAT Python project, might be a possibility to get a JIT without it needing a long warmup time. A multi-stage JIT, like the one for JavaScript, might provide the performance boost he is looking for.
Brett Cannon (who is one of the developers of Pyjion) noted that JIT projects are generally forks of CPython. That means the JIT developers are always playing catch-up with the mainline and that is hard to do. Pyjion is a C extension, but the other projects were not able to do that; the interfaces that Pyjion uses only went in for Python 3.6. He thought there might be room for consolidating some of the independent JIT work that has gone on, however.
But Mark Shannon pointed out that Pyjion and others are function-based JITs, while PyPy is tracing based. Beyond that, PyPy works, he said. Alex Gaynor, who is a PyPy developer, said that the PyPy project has changed the implementation of Python to make it more JIT friendly; that led to "a huge performance gain". He is skeptical that making small API changes to CPython will result in large performance gains from a JIT.
An attendee suggested Cython, which does AoT compilation, but its types are not Pythonic. He suggested that it might be possible to use the new type hints and Cython to create something more Pythonic. Cython outputs C, so the 2x performance factor seems possible.
Another audience member said that while it makes sense to make the ABI smaller, it is being used, so how is that going to change? It might be possible to stop it growing or growing in certain directions. One way to do that might be to require new C APIs to be implemented in PyPy before they can be merged. That might avoid the "horrible things" that some extensions (e.g. PyQt) have done. Stinner responded, "I did not say I have solutions, I only have problems", to some chuckles around the room.
PyPy has gotten its CPyExt extension API to work better, so NumPy now works for the most part, an attendee said. Problems can be fixed using the original rewrite. The long arc is to push more extension writers away from the C API and to the C Foreign Function Interface (CFFI). But Stinner is still concerned that the problem is bigger than just extensions; the C API is preventing some innovative changes to CPython.
[I would like to thank the Linux Foundation for travel assistance to Portland for the summit.]
Trio and the future of asynchronous execution in Python
At the 2017 Python Language Summit, Nathaniel Smith led a session on Trio—an asynchronous library he has recently been working on that uses the async and await keywords that have come about in recent Python releases. It is meant to be an alternative to the asyncio module. The session was targeted at relaying what Smith has learned in the process of writing Trio and to see where things might go from here.
![[Nathaniel Smith]](https://static.lwn.net/images/2017/pls-smith-sm.jpg "Nathaniel Smith")
He started out by describing why he was working on an asynchronous library when asyncio has already been adopted into the standard library. Guido van Rossum's hope was that other implementations would give up their event loop implementations in favor of the asyncio version, as he said in PEP 3156. In synchronous Python, the order that code will execute is clear, but in an asynchronous world that is no longer true. Twisted created a new, complicated Deferred object (and other data structures) to work with this departure from Python orthodoxy; asyncio standardized those data structures. Yury Selivanov then added async and a await to make them easier to use, Smith said.
But David Beazley pointed out that Python coroutines could now be used
directly; Future
and Deferred objects may not be needed.
Beazley's curio
project was meant to show one way to do so; it restores the causality that
was lost in code that uses Future or Deferred. At one
point, Van Rossum called
curio "a beacon of clarity compared to asyncio
", but cautioned
that the asyncio APIs need to be maintained. In that message, he suggested a
new PEP that proposed an API focused more on coroutines. That motivated
Smith to start working on Trio.
More background on Smith's ideas can be found in a blog post from November 2016. In particular, the section on causality fills in some of the missing context from his summit talk. The core developers present were likely up to speed on all of that as it was discussed on the python-dev mailing list.
Smith gave a brief overview of the approach taken by Trio. It uses async functions (i.e. async def) and await for calling those functions. There is a trio.run() that can be passed an asynchronous function to run in the Trio event loop. There is a new concept called a "nursery" that "holds children" he said with a grin; it allows multiple asynchronous functions to be run simultaneously. Trio also provides for cancellation of outstanding asynchronous functions. There are no Future objects or callbacks with Trio, he said, though that overstates things a bit as he admitted later.
Selivanov said that nurseries could be implemented on top of asyncio, which would be beneficial because that would allow them to use libuv and other parts of the asyncio ecosystem. There are two separate pieces of asyncio: the low-level piece that consists of the event loop with callbacks that has objects, like Future, Task, and so on, built on top. The second part could be replaced with something else, perhaps Trio or something derived from it, Selivanov said.
Van Rossum acknowledged that asyncio has some weak points; cancellation should be handled by the library, for example. But he is not convinced that Trio itself "is the future" as Smith seems to think. Some future version of asyncio could borrow APIs from Trio without losing compatibility with existing code.
Instead of creating a competing library, Van Rossum suggested that Smith "write a PEP and give us a way out". But Smith said that he couldn't write a PEP without creating a competing library as part of that process. Van Rossum was adamant, though: "take what you learned and write a PEP".
Smith moved on to another topic: multiple exceptions generated by separate asynchronous coroutines. Those could be thrown away, which is how some frameworks handle them, but he didn't want to lose that information. So Trio uses a container for exceptions, called MultiError, that collects a set of exceptions into one object. A related issue is that there is a need for being able to mutate traceback objects in order to hide or annotate parts of the traceback for easier debugging. It is not just Trio that needs that ability, Jinja2 would like that ability and the new import framework could use it as well. Van Rossum once again suggested a PEP.
MultiError is a fundamental change in the exception semantics that other libraries (e.g. IPython) are not prepared to deal with, Smith said; that is kind of awkward. There are also some tricky semantics that need to be worked out. But it may be that the need to catch multiple exceptions is less of a problem in practice, so it may not really need to be addressed.
[I would like to thank the Linux Foundation for travel assistance to Portland for the summit.]
Python ssl module update
In something of a follow-on to his session
(with Cory Benfield) at the 2016 Python Language Summit, Christian Heimes
gave an update on the state of the Python ssl module.
In it, he covered some changes that have been made in the last year as well
as some changes that are being proposed. Heimes and Benfield are the
co-maintainers is a co-maintainer of the ssl module.
Heimes started with a bit of a detour to the hashlib module. The SHA-1 hash algorithm is dead, he said, due to various breakthroughs over the last few years. So, in Python 3.6, the hashlib module has added support for SHA-3 and BLAKE2. The security community has been happy to see that, he said. But Alex Gaynor pointed out that SHA-1 is still allowed as the hash in X.509 certificates; Heimes acknowledged that, but said that it is needed to support some versions of TLS.
![[Christian Heimes]](https://static.lwn.net/images/2017/pls-heimes-sm.jpg "Christian Heimes")
The default cipher suites were next up. In the past, the ssl module needed to choose its own cipher suites because the choices made by OpenSSL were extremely poor. But OpenSSL has gotten much better recently and Python's override actually re-enables some insecure ciphers (e.g. 3DES). Heimes is proposing that ssl start using the OpenSSL HIGH default and explicitly exclude the known insecure ciphers. That way ssl will benefit from OpenSSL's updates to its choices and will hopefully mean that there will be no need to backport changes to the ssl module for cipher suite changes in the future.
Version 1.3 of the TLS protocol will be supported in OpenSSL version 1.1.1, which is supposed to be released mid-year. New cipher suites will need to be added to support TLS 1.3. Older Python versions (2.7, 3.5, and 3.6) will use a new flag to indicate that they do not support the new protocol.
There are a large number of bugs associated with matching hostnames against those found in TLS certificates. In Python 3.2, ssl.match_hostname() was added (and backported to 2.7.9) to do so. Since that time, there has been a steady stream of hostname-matching bugs, some of which remain unfixed. His proposed solution is to let OpenSSL perform the hostname verification step. That requires a recent version of OpenSSL (1.0.2 or higher) or LibreSSL (version 2.5 or higher).
He would also like to drop support for older versions of OpenSSL, at least for Python 3.7. OpenSSL 1.0.2 is available in RHEL 7.4, Debian 8 ("Jessie"), and Ubuntu 16.04; it has also been backported to Debian stable. OpenSSL 1.0.1 is no longer supported upstream, so he would like to drop support for that.
LibreSSL is a BSD fork of OpenSSL 1.0.1 that has picked up the new features in OpenSSL 1.0.2, so it is mostly compatible though it has removed multiple features. He would like to keep ssl only using those features provided by LibreSSL so that it is supported. In answer to a question from the audience, Heimes said that LibreSSL support is important for the BSDs as well as for Alpine Linux, which is popular for use in containers.
As Heimes started running out of time, he went through a few more things rather quickly. He pointed out that PEP 543, which proposes a unified TLS API, still needs a BDFL delegate to determine whether it will be adopted or not. There are some upcoming deprecations of broken parts of the ssl API. In addition, there are plans for various improvements to the module, including better hostname checking and support for international domain names encoded using IDNA.
[I would like to thank the Linux Foundation for travel assistance to Portland for the summit.]
The "rare write" mechanism
One of the ways to harden the kernel is by tightening permissions on memory to write-protect as much run-time data as possible. This means the kernel makes some data structures read-only to prevent malicious or accidental corruption. However, inevitably, most data structures need read/write access at some point. Because of this, a blanket read-only policy for these structures wouldn't work. Therefore, we need a mechanism that keeps sensitive data structures read-only when "at rest", but allows writes when the need arises.
Kees Cook proposed such a mechanism based on similar functionality that exists in the PaX/grsecurity patch set. Cook calls it "rare write", but that is a bit of misnomer considering that write access to some of the target data structures is not always rare. The resulting discussion on the Linux kernel mailing list fleshed out how the mechanism could be implemented, from a standpoint of both architecture-neutrality and performance.
Cook's proposed series of eleven patches for the rare_write() infrastructure consists of sample implementations for x86 and ARM, plus usage examples. Two new kernel configuration options, HAVE_ARCH_RARE_WRITE and HAVE_ARCH_RARE_WRITE_MEMCPY, were added to let architectures define whether or not they have implemented the new mechanism. Cook's implementation contains architecture-specific code that relies on CPU features on x86 and ARM that selectively enable and disable write access to areas of memory. Thus, the data write routines cannot be preemptible, as interrupting the kernel after it enables writing on read-only memory would result in leaving a window of vulnerability open. Cook noted that his code is inlined to discourage return-oriented programming attacks on the write-enable routines, which would otherwise be a juicy target for such attacks.
The architecture-specific nature of the code became a point of contention in the resulting discussion on the linux-kernel and kernel-hardening mailing lists. But first, let's look at how Cook's proposed mechanism works.
The kernel stores data in different ELF sections depending on how that data will be accessed: .data or .bss for normal, read-write data, in .rodata for read-only data, or in .data..ro_after_init for data that will become read-only after initialization. Cook's newly introduced __wr_rare annotation, which for now is just a #define alias for __ro_after_init, would be used to mark data structures to be converted to read-only. Write access would be enabled via a new rare_write() macro, or in a critical section protected by rare_write_begin() and rare_write_end() macros. Cook gave a simple example of the usage of the single rare_write() call by converting a function in net/core/sock_diag.c from:
sock_diag_handlers[family] = NULL;
To:
rare_write(sock_diag_handlers[family], NULL);
There are also helper functions to deal with linked lists that utilize the rare_write_begin() and rare_write_end() macro pair internally.
Implementation
On x86 CPUs, read-only data is mapped onto pages marked with the read-only bit set in their page-table entries. CR0 is a control register on the x86 CPUs, and toggling the write-protect bit (bit 16) of CR0 allows this read-only protection to be either enabled or disabled. When the write-protect bit has been cleared on a CPU, any data, regardless of the page-table permissions, can be written by the kernel when running on that CPU. After some back and forth discussion, Cook's implementation of the rare write functions on x86 became the following:
static __always_inline unsigned long __arch_rare_write_begin(void)
{
unsigned long cr0;
cr0 = read_cr0() ^ X86_CR0_WP;
BUG_ON(cr0 & X86_CR0_WP);
write_cr0(cr0);
return cr0 ^ X86_CR0_WP;
}
static __always_inline unsigned long __arch_rare_write_end(void)
{
unsigned long cr0;
cr0 = read_cr0() ^ X86_CR0_WP;
BUG_ON(!(cr0 & X86_CR0_WP));
write_cr0(cr0);
return cr0 ^ X86_CR0_WP;
}
Mathias Krause raised a
concern that non-maskable interrupts would still be able to interrupt
the CPU inside the critical section, and questioned if PaX's implementation
that Cook's patch was based on whether the implementation was
indeed correct. Thomas Gleixner suggested
that the proper way to handle writing to a read-only memory location
is to create a writable shadow mapping to that physical memory location, and
update the value of the data in that location through the shadow map. This
approach
would not require clearing the CR0 write-protect bit which, he suggested, is
too dangerous to ever do. Gleixner provided this
piece of pseudocode to illustrate his idea:
write_rare(ptr, val)
{
mp = map_shadow_rw(ptr);
*mp = val;
unmap_shadow_rw(mp);
}
He added:
map_shadow_rw() is essentially the same thing as we do in the highmem case where the kernel creates a shadow mapping of the user space pages via kmap_atomic().
It's valid (at least on x86) to have a shadow map with the same page attributes but write enabled. That does not require any fixups of CR0 and just works.
After subsequent discussions on which method would be better with regard to performance, Andy Lutomirski suggested setting up a separate mm_struct that had a writable alias of the target read-only data and using use_mm() to access it. Lutomirski argued this was more architecture-neutral and, if anyone was inclined to test its performance, they could do so against the CR0-toggle method. While Mark Rutland agreed with this approach, Gleixner wasn't too sure if this was efficient. Cook replied that there was a need for performance and efficiency, as this mechanism will be used for data structures that need extra protection, and not just those are are written to rarely:
I probably chose the wrong name for this feature (write rarely). That's _usually_ true, but "sensitive_write()" was getting rather long. The things that we need to protect with this are certainly stuff that doesn't get much writing, but some things are just plain sensitive (like page tables) and we should still try to be as fast as possible with them.
PaX Team responded that the weakness of the use_mm() approach is that it wouldn't scale, and that you couldn't use the approach inside use_mm() and switch_mm() themselves. These limitations also concerned Cook:
Lutomirski replied
that page table writes aren't rare, so there may need to be "multiple
levels of rareness
" to accommodate this.
Cook also included an implementation for ARM-based CPUs. The ARM architecture organizes memory into regions called "domains", and each domain can have different access permissions. Cook created a domain called DOMAIN_WR_RARE to store read-only data; whenever rare_write() is invoked on ARM, the code will modify the domain permissions of DOMAIN_WR_RARE to enable writes, and disable them again after it is done.
Conclusion
After the various comments that were posted on the mailing list, Cook is working on another iteration of his patch set. An open question is how something like this can be implemented on architectures that do not have architecture support for enabling or disabling writing to read-only memory. Earlier, in his first RFC series on the kernel-hardening list, Cook stated that he isn't sure how to handle other architectures that do not have the requisite hardware support, but he does plan to get a "viable interface" for the architectures that do. Perhaps the way forward is to use the suggested method of writing to read-only data sections via shadow mappings, which can be implemented with kmap_atomic() as proposed by Gleixner.
Toward non-blocking asynchronous I/O
The Linux asynchronous I/O (AIO) layer tends to have many critics and few defenders, but most people at least expect it to actually be asynchronous. In truth, an AIO operation can block in the kernel for a number of reasons, making AIO difficult to use in situations where the calling thread truly cannot afford to block. A longstanding patch set aiming to improve this situation would appear to be nearing completion, but it is more of a step in the right direction than a true solution to the problem.To perform AIO, a program must set up an I/O context with io_setup(), fill in one or more iocb structures describing the operation(s) to be performed, then submit those structures with io_submit(). A call to io_getevents() can be made to learn about the status of outstanding I/O operations and, optionally, wait for them. All of those system calls should, with the exception of the last, be non-blocking. In the real world, things are more complicated. Memory allocations or lock contention can cause any AIO operation to block before it starts to move any data at all. And, even in the best-supported case (direct file I/O), the operation itself can block in a number of places.
The no-wait AIO patch set from Goldwyn Rodrigues seeks to improve this situation in a number of ways. It does not make AIO any more asynchronous, but it will cause AIO operations to fail with EAGAIN errors rather than block in a number of situations. If a program is prepared for such errors, it can opportunistically try to submit I/O in its main thread; it will then only need to fall back to a separate submission thread in cases where the operation would block.
If a program is designed to use no-wait AIO, it must indicate the fact by setting the new IOCB_RW_FLAG_NOWAIT flag in the iocb structure. That structure has a field (aio_flags) that is meant to hold just this type of flag, but there is a problem: the kernel does not currently check for unknown flags in that field. That makes it impossible to add a new flag, since a calling program can never know whether the kernel it is running on supports that flag or not. Fortunately, that structure contains a couple of reserved fields that are checked in current kernels; the field formerly known as aio_reserved1 is changed to aio_rw_flags in this patch set and used for the new flag.
One of the places where an I/O request can block is if the operation will trigger a writeback operation; in that case, the request will be held up until the writeback completes. This wait happens early in the submission process; in particular, it can happen before io_submit() completes its work and returns. Setting IOCB_RW_FLAG_NOWAIT will cause submission to fail with EAGAIN in this case.
Another common blocking point is I/O submission at the block level, where, in particular, a request can be stalled because the underlying block device is too busy. Avoiding that involves the creation of a new REQ_NOWAIT flag that can be set in the BIO structure used to describe block I/O requests. When that flag is present, I/O submission will, once again, fail with an EAGAIN error rather than block waiting for the level of block-device congestion to fall.
Support is also needed at the filesystem level; each filesystem has its own places where execution can block on the way to submitting a request. The patch set includes support for Btrfs, ext4, and XFS. In each case, situations like the inability to obtain a lock on the relevant inode will cause a request to fail.
All of this work can make AIO better, but only for a limited set of use cases. It only improves direct I/O, for example. Buffered I/O, which has always been a sort of second-class citizen in the AIO layer, is unchanged; there are simply too many places where things can block to try to deal with them all. Similarly, there is no support for network filesystems or for filesystems on MD or LVM volumes — though Rodrigues plans to fill some of those gaps at some future point.
In other words, AIO seems likely to remain useful only for the handful of applications that perform direct I/O to files. There have been a number of attempts to improve the situation in the past, including fibrils, threadlets, syslets, acall, and an AIO reimplementation based on kernel threads done by the original AIO author. None of those have ever reached the point of being seriously considered for merging into the mainline, though. There are a lot of tricky details to be handled to implement a complete solution, and nobody has ever found the goal to be important enough to justify the considerable work required to come up with a better solution to the problem. So the kernel will almost certainly continue to crawl forward with incremental improvements to AIO.
What's new in gnuplot 5.2
This article is a tour of some of the newest features in the gnuplot plotting utility. Some of these features are already present in the 5.0 release, and some are planned for the next official release, which will be gnuplot 5.2. Highlights in the upcoming release include hypertext labels, more control over axes, a long-awaited ability to add labels to contours, better lighting effects, and more; read on for the details.
Most of the examples in this article should work as-is in the 5.2 alpha release when it is available; they should also work with latest development version, the source for which can be downloaded from the repository and compiled. There is also a new stable branch for 5.2 that was established as this article was written; this may be the best choice for users who want the latest features and don't mind compiling themselves.
For an introduction to gnuplot — what it is, where it comes from, how to compile and install, and how to get started using it — please refer to our earlier article.
Why gnuplot?
Gnuplot is no longer the only open-source graphing system available. During the 30 years of its existence, several other programs and libraries have become popular, including the widely-used Matplotlib library for Python. Those who rely on gnuplot for their graphing needs, including this author, do so for a number of reasons. Its self-contained, language-agnostic nature — and the ability to be used with any programming language through a socket interface — make collaboration easier. Its ability to work intimately with LaTeX makes for good-looking papers. It makes easy tasks easy (plot sin(x): done); and complex tasks manageable. It is infinitely customizable. It can handle a large variety of plot types, and it's fast and stable when dealing with huge data files.
The reason for gnuplot's large repertoire is the responsiveness of its developers to the needs of its users. Gnuplot is developed by a core group of about 30 contributors from around the world. Ethan Merritt, a professor in the Department of Biochemistry of the University of Washington, serves as the unofficial project coordinator. He was kind enough to share some anecdotes that explain the origins of some of gnuplot's special plotting styles, and its wide diversity of applications. It turns out that quite a few plot types were added to gnuplot in response to various bug reports by users. These "bug reports" were actually feature requests in disguise, as the submitters were under the impression that gnuplot should be able to produce the plots they had in mind, but that some bug was preventing it from working.
One interesting example recounted by Merritt comes from the astronomy field. If you are familiar with observational astronomy, you may be aware that star charts sometimes use something called a "horizontal coordinate system" (or the "alt-az system"). This is a kind of polar coordinate system, but violates some of the assumptions that were built in to gnuplot's idea of a polar plot: for example, the radial axis is reversed. Consequently, when a certain user attempted to make such a plot, problems ensued. The resulting "bug report" caused the developers to learn about this type of coordinate system, and now gnuplot can handle it.
Similar stories are behind several of the new plot types slated for the next release. Let's now take a brief tour of some of these useful new features.
Hypertext labels
Gnuplot already had the ability to plot labels, with their positions, sizes, text, and colors taken from the data in a file. A new feature, intended for use on web pages, reveals the label text when the reader hovers over it with the mouse pointer. Gnuplot calls this the "hypertext" label style. It works with SVG files and the HTML canvas element; our example will use the former. SVG coverage is quite good now in browsers, so you should be able to see and interact with the image unless you happen to be using an unusual browser.
The following gnuplot script is an example of how to use the hypertext style:
set term svg mouse standalone
set out "file.svg"
set datafile separator comma
set xlabel '% eligible entering 1st grade' font ",16"
set ylabel '% youth literacy' font ",16"
unset key
set yr [50:110]
set xr [10:110]
set style fill solid 0.5
plot "< sort -t, -k4 -gr htxt.dat" using 2:3:1:(log($4/100000)) \
with labels hypertext point pt 7 ps var lc rgb "violet", \
"" using 2:3:(log($4/100000)) with points pt 6 lc "red" ps var notitle
The first line instructs gnuplot to include, inline with the XML that makes up the SVG output, some JavaScript code that handles the mouse integration. The rest of it is familiar gnuplot code, with the exception of the hypertext keyword, which creates the hidden labels. The output looks like:
As you hover over the data points, the titles should appear (note that you need to have JavaScript enabled). In addition, a click inside the image frame will toggle tracking of the mouse pointer with a display of the mouse coordinates.
The reason for reverse sorting the data file by its last column, which determines the point size, is to place smaller points on top of larger ones, so that all the labels can be revealed. The file direction syntax can be used to pipe files through any external command (here, the linux sort command), in case there is no convenient built-in gnuplot command that does what we need.
Linked axes
Gnuplot now allows the two y-axes, or the two x-axes, to be related by any mathematical transformation. You do this by using the set link command, which requires you to spell out the inverse transformation as well. We'll align the grid with the y2 axis and plot some random data with this script:
unset key
set title "Radius and area of observed circles" font ",16"
set xlabel "Circle number" font ",14"
set ylab "Circle radius" font ",14"
set y2lab "Circle area" font ",14"
set link y2 via pi*y**2 inverse sqrt(y/pi)
set samples 11
set xtic 1
set ytic .1 nomirror font ",10"
set y2tic .2 font ",10"
set xr [0:10]
set yr [0:1]
set grid noy y2 x lw 1 lt -1
plot "+" u 1:(rand(0)) with linespoints lw 3 ps 2 pt 9
The resulting plot looks like:
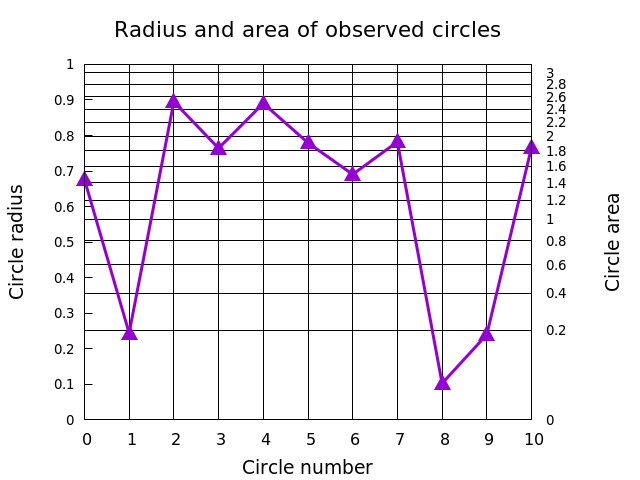
Parallel-axis plots
Starting with version 5, gnuplot has gained the ability to make an entirely new type of plot. The parallel-axis or parallel coordinate plot is a way to visualize a multidimensional data set that can help in the discovery of patterns and relationships. For example, we'll use a table of physical properties of the elements and these gnuplot commands:
unset key
unset colorbox
set border 0
unset ytics
set datafile separator comma
set paxis 1 range [-1:41]
set paxis 1 tics 2 tc rgb "#666666"
set paxis 2 range [-1:100]
set paxis 2 tics 10 tc rgb "#666666"
set paxis 3 range [0:5200]
set paxis 3 tics 0,200,5200 tc rgb "#666666"
set paxis 4 range [0:5200]
set paxis 4 tics 0,200,5200 tc rgb "#666666"
set paxis 5 range [0:500]
set paxis 5 tics 20 tc rgb "#666666"
set xtics ("At. #" 1, "At. Wt" 2, "Melt" 3, "Boil" 4, "Therm" 5) nomirror
set xtics ("At. #" 1, "At. Wt" 2, "Melt" 3, "Boil" 4, "Therm" 5)
plot "elements" u 3:4:6:7:15:3 every ::1::40 w parallel lc pal lw 2
Running this script on the elements data yields this plot:
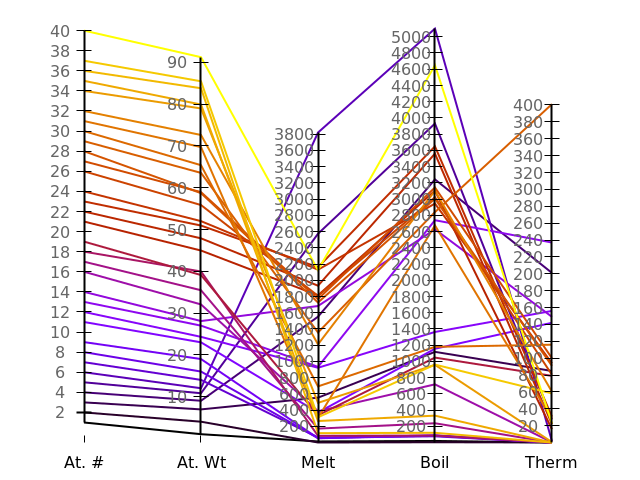
As you can see, it is possible to set the ranges and tics for each axis independently. We've used this flexibility to ensure that the scales for melting and boiling temperature are aligned. Colors for the data lines can be set based on one of the data columns, or on a palette, as we've done here; the colors should be chosen to make the data relationships apparent to the eye.
The plot includes the atomic numbers from 1 to 40; the several gaps are where one of the data columns is missing a value; in that case gnuplot apparently omits the entire line.
Contour labels
One feature that has been missing from gnuplot for the past 30 years, an omission conspicuous to its scientific users in particular, is the ability to attach labels to contours. Many of its devotees, including this author, have devised various hacks to label contours in gnuplot, but now the feature is built-in. Here's an example script:
set contour
unset surface
set view map
set samp 500
set iso 100
set xr[-24:-9]
set yr [2:4.5]
unset key
set cntrlabel start 2 interval 900 font ",11"
splot lgamma(x)*cos(y)**2 lw 3, lgamma(x)*cos(y)**2 with labels
The cntrlabel setting controls how many labels are put on each contour line, and where on the line they start. Getting the labels on the contours requires two plot commands, one to draw the lines and one to apply the text. The output looks like:

Fancy lighting
Gnuplot has a longstanding ability to color 3D surfaces based on any information that the user chooses, usually the value of the function or data represented by the height of the surface. This can be a great aid to visualization. Simulating the effects of an external light source, modeling the surface as if it were a physical object reflecting light to the viewer's eyes, enhances the 3D perspective illusion, and can help even more in perceiving the shape of complex surfaces.
Gnuplot can now do this. There is a new command to add both diffuse, ambient light and specular highlights, with adjustable intensities. The sample script to show this feature is:
unset key
set yr [0:10]
set xr [0:10]
set samp 100
set iso 100
set view 45,45
set pm3d lighting primary .5 specular .4
splot besj0(y)*x**2 with pm3d
And the resulting output is:

This effect is best viewed in interactive mode, though, where the plot can be rotated with the mouse and the lighting effect responds accordingly.
Jitter
Often, data is gathered in a way that causes one or more variables to be "quantized," rather than to be smoothly distributed. For example, some observation may be recorded every hour or day, which would cause the observations to be clustered on the time axis. This will cause the data points to overlap on a scatterplot, for example, which would obscure some of the data. One way to overcome this is to add a small displacement, random or otherwise, to the plotted points, in order to spread them out and make them visible. Gnuplot now has an automated, configurable mechanism for doing just this, using the new jitter command. We'll show how it works using some artificial data. Here is a straightforward scatterplot script:
unset key
set xtic format ""
set ytic format ""
set grid lt -1
seed = rand(17)
plot sample [i = 0 : 99] "+" u (int(i)%10):(int(rand(0)*99)%10)\
pt 6 ps 3 lw 3
It yields this plot:

This just puts some points randomly on a grid. It also happens to demonstrate one use of another new gnuplot command, the sample keyword, which creates a set of equally spaced points within the specified interval.
Jitter can be added to this plot with these commands:
set jitter spread .2
seed = rand(17)
replot
After running the above, we can see that some locations that appeared to be occupied by a single data point were actually hosting more than one:

The spread parameter specifies how much to displace the overlapping points, in coordinate units, and is one of several ways to customize its behavior.
More
There are many more new features and improvements. Here we'll try to summarize a few of the ones that stand out as particularly useful.
Gnuplot has a new data type: arrays. Simply make a declaration like:
array a[20]
to create and initialize an array. Gnuplot arrays can contain
heterogeneous data, so a[1] = 4 and
a[2] = "Graph 1" are possible (the array
index starts at one). Veteran gnuplot
scripters have devised all kinds of hacks for packing data into strings;
this is a welcome addition that will make all that unnecessary.
The sequence of colors that gnuplot uses by default for plot elements has been refined: it is now more useful for people with partial color blindness.
The dot-dash line pattern can be set independently of other line properties, and it can be set visually. For example:
plot f(x) dt "--..-"
There is a new geographic coordinate system, which can convert decimal degrees into tic labels formatted with latitude and longitude expressed as degrees, minutes, and seconds.
Gnuplot now supports an interesting new output device called DomTerm. This is a terminal that supports embedded graphics, allowing the user to interleave commands with gnuplot's output. The experience is somewhat like using the imaxima Emacs interface or Sage notebooks, both of which were described in this article.
The symbol used for plotting with points can be controlled by the value of the data, just as color and size could before.
An experimental feature performs automatic binning of data for histogram or other plots. Up to now this had to be done externally or manually in the script.
Polar plots have been improved, with support for tics and labels around the perimeter, a circular border, the astronomer's horizontal coordinate system (see the Introduction), labeling the radial axis, and assigning the location of θ = 0.
Finally, there are a few new features that make scripting more convenient. For example, you can store data in a named block for reuse, there is a new import command that lets you name a function provided by an external shared object, there are continue and break statements, and you can now pass arguments to gnuplot scripts.
Acknowledgement
Thanks to Ethan Merritt for explaining gnuplot's versioning conventions and sharing information about the development process.
Page editor: Jonathan Corbet
Next page:
Brief items>>