
IPv6 segment routing
In November 2016, a new networking feature, IPv6 segment routing (also known as "IPv6 SR" or "SRv6"), was merged into net-next and subsequently included in Linux 4.10. In this article, we explain this new feature, describe key elements of its implementation, and present a few performance measurements.
Routing at the source
Segment routing is a modern source-routing architecture that is being developed within the IETF. Traditional IP routing uses destination-based hop-by-hop forwarding. Each intermediate router decides where to forward packets using its local routing table. This table is usually computed according to a shortest-path algorithm. As such, packets traverse networks following the shortest path toward their destination. This behavior is not always optimal, as the shortest path can have undesirable properties, such as congestion.
Existing traffic-engineering techniques enable coarse-grained control over a packet's path by tuning parameters, such as link weights, to adjust the shortest path algorithm. However, these techniques cannot control traffic on a per-flow basis. Segment routing, instead, can forward packets along non-shortest paths toward their destination by specifying a list of detours or waypoints called "segments". This list is specified within the packet itself. Packets are forwarded along the shortest path from the source to the first segment, then through the shortest path from the first segment to the second segment, and so on. The source of the packet can thus specify its path with an arbitrary precision. Segment routing defines two main types of segments representing topological instructions. A "node" segment is used to steer packets through a specific network node, while an "adjacency" segment steers packets through a particular link.
The segment routing architecture has been instantiated in two different data planes: Multiprotocol Label Switching (MPLS) and IPv6. The MPLS variant of SR is already implemented by network vendors and deployed by operators.
SRv6 is implemented with an IPv6 extension header, the routing header. The segment routing header (SRH) contains a list of segments, encoded as IPv6 addresses. A segment represents a topological instruction (node or link traversal) or any operator-defined instruction (e.g., a virtual function). An SRH can be used to steer packets through paths with given properties (e.g., bandwidth or latency) and through various network functions (such as a firewall). The list of segments present in the SRH thus specifies the network policy that applies to the packet. Each SRH contains at least a list of segments and a "segments left" pointer that references the current active segment (a value of zero refers to the last segment). In addition, an SRH can optionally include extended information encoded as type-length-value (TLV) fields. One example is the optional HMAC TLV, used for authenticity and integrity checks.
When a router must impose an SRH on a forwarded packet, the packet is encapsulated in an outer IPv6 header containing the SRH. The original packet is left unmodified as the payload. The router is called the "SR ingress node". The destination address of the outer IPv6 header is set to the first segment of the list and the packet is forwarded to the corresponding node following the shortest path. This node (called a "segment endpoint") then processes the packet by updating the destination address to the next segment. The last segment of the list is the "SR egress node". It decapsulates the inner packet and forwards it to its original destination.
Data-plane implementation
The core of the SRv6 implementation is the SRH processing capability. It enables a Linux node to act as both a segment endpoint and an SR egress node. When a segment endpoint receives an IPv6 packet containing an SRH, the destination address of the packet is local to the segment endpoint. To process this packet, a new ipv6_srh_rcv() function is called whenever the IPv6 input function encounters an SRH in the header chain. An SRH is defined by the following structure:
struct ipv6_sr_hdr {
__u8 nexthdr;
__u8 hdrlen;
__u8 type;
__u8 segments_left;
__u8 first_segment;
__u8 flags;
__u16 reserved;
struct in6_addr segments[0];
};
The ipv6_srh_rcv() function performs several operations. First, it checks that the node is allowed to act as a segment endpoint for SR-enabled packets coming from the ingress interface (skb->dev). This policy is configured through the sysctl boolean net.ipv6.conf.<interface>.seg6_enabled. If it is set to 0, then the packet is discarded. Otherwise, the processing continues.
The packet then goes through an optional HMAC validation, controlled with the sysctl knob net.ipv6.conf.<interface>.seg6_hmac_require. This parameter can take three different values. If seg6_hmac_require is set to -1, the node accepts all SR packets, regardless of the status (absent/present, valid/invalid) of the HMAC TLV. When it is set to zero, the node must accept packets that contain an SRH and either present a valid HMAC TLV or do not include an HMAC TLV at all. Finally, a setting of 1 means that the node accepts only the SR packets that include a valid HMAC.
The next operations depend on the value of the "segments left" counter. If it is greater than zero, then the packet must be forwarded to the next segment. The field is decremented and the destination address of the packet is updated to the next segment. A route lookup is performed and the packet is forwarded.
If, instead, there are no segment left, the operation will depend on the next header. If it is another extension header or a final payload such as TCP or UDP, then the kernel assumes that the packet must be delivered to a local application. The packet processing then continues as normal. On the other hand, if the next header is another IPv6 header, then the kernel assumes that the packet is an encapsulation. The inner packet is then decapsulated and reinjected in the ingress interface using netif_rx().
Control plane implementation
To support SRH encapsulation, the SRv6 implementation uses the lightweight tunnels (LWT) infrastructure. LWTs can associate custom input and output function pointers (in struct dst_entry) to route objects. Those functions are called when a packet is forwarded by the kernel (input) and generated by a local application (output). A per-route stateful data structure (the "tunnel state") is also maintained.
For SRv6, the function pointers are set to seg6_input() and seg6_output(). Those functions encapsulate a packet within an outer IPv6 header that contains a pre-configured SRH. The SRH is stored as the tunnel state, along with a struct dst_cache. This structure stores the route associated with the first segment of the SRH. Indeed, all packets that receive an SRH will be immediately forwarded to their first segment. Using a cache thus prevents an unnecessary route lookup for each processed packet.
To configure the routes, the iproute2 tool has been extended. An SRv6 encapsulation route can be defined as follows:
# ip -6 route add fc42::/64 encap seg6 mode encap \
segs fc00::1,2001:db8::1,fc10::7 dev eth0
This command inserts a route for the prefix fc42::/64. Each matching packet receives an SRH with three segments. Note that it is mandatory to specify a non-loopback interface.
The routes configured by iproute2 are namespace-wide. To support finer-grained control of the SRH insertion, the SRv6 implementation also supports a per-socket interface, using the setsockopt() system call. This interface enables an application to specify its own per-socket SRH. The following piece of code shows how an application can use this feature:
struct ipv6_sr_hdr *srh;
int srh_len;
srh_len = build_srh(&srh);
fd = socket(AF_INET6, SOCK_STREAM, IPPROTO_TCP);
setsockopt(fd, IPPROTO_IPV6, IPV6_RTHDR, srh, srh_len);
HMAC
The authenticity and integrity of an SRH can be ensured using an HMAC TLV. This HMAC covers the source address of the packet and the full SRH (excluding TLVs). The HMAC TLV contains an opaque, operator-defined key ID. In the Linux SRv6 implementation, this identifier refers to a hashing algorithm (currently, SHA-1 and SHA-256 are supported) and to the HMAC secret.
The HMAC support is implemented using static per-CPU ring buffers to store the input data and pre-allocated, per-CPU algorithm descriptors to store the auxiliary buffer/context of the hashing algorithms. Pre-allocation prevents doing expensive dynamic memory allocation for each processed packet, and per-CPU data prevents lock contention.
To associate an HMAC with an SRv6 route, the iproute2 tool provides an hmac keyword. The command ip sr enables configuration of the hashing algorithm and secret associated with a given key ID.
Performance
An evaluation shows that the SRH encapsulation performance is within 12% of plain IPv6 forwarding. The following figure summarizes the results, performed on Xeon X3440 machines with Intel 82599 10 Gbps interface cards:
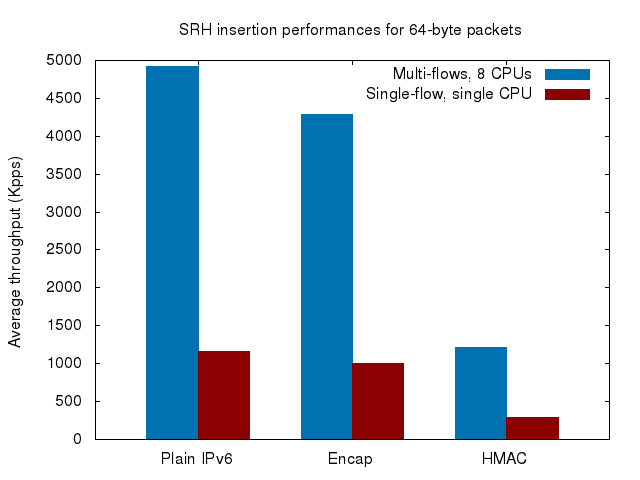
In red is shown the performance for a single flow, processed by a single CPU. The blue bars show the performance for an arbitrarily large number of flows, with the receive-side scaling feature enabled (i.e., the flows are evenly processed by all the CPUs). With the multi-flow measurements, plain IPv6 forwarding peaks at about 4.9Mpps, while SRv6 encapsulation reaches 4.3Mpps. The HMAC computation (using the SHA-256 algorithm) performance reaches only 1.2Mpps. Profiling shows that most of the CPU cycles are used in the sha256_transform() function, which is the main processing function for the hashing algorithm.
The multi-flows measurements are about four times better than the single-flow measurements. This is explained by the fact that the test machine actually has four physical cores with HyperThreading enabled. Considering this, the SRv6 encapsulation performance seems to scale linearly with respect to the available CPU power.
SRv6 is a promising new source-routing technique. For obvious security
reasons, it is intended to run within the bounds of an administrative
domain. As such, it provides network operators with a powerful traffic
engineering and flow management tool. With the help of a central
controller, segment routing can implement a software-defined network
paradigm, providing an alternative to OpenFlow-based networks.
Currently, multiple service providers are exploring the potential of
SRv6. Enterprise networks may also benefit from this technique, as IPv6
deployments increase in this kind of environment.
| Index entries for this article | |
|---|---|
| Kernel | Networking/IPv6 |
| GuestArticles | Lebrun, David |
Posted May 18, 2017 6:51 UTC (Thu)
by flussence (guest, #85566)
[Link] (4 responses)
Posted May 18, 2017 7:12 UTC (Thu)
by dalebrun (subscriber, #105802)
[Link]
Posted May 18, 2017 18:44 UTC (Thu)
by raven667 (subscriber, #5198)
[Link] (2 responses)
Posted May 20, 2017 7:44 UTC (Sat)
by obonaventure (guest, #108715)
[Link]
Posted May 23, 2017 6:23 UTC (Tue)
by gdt (subscriber, #6284)
[Link]
Actually this is really useful for cross-boundary applications. You can't use MPLS for that effectively, as implementations usually carry too much access into the interior forwarding plane of the neighbour, and MPLS ACLing is next to non-existent. So you end up having to signal per-flow information using the DSCP markings, which you then flick into a particular MPLS tag at your network edge. There's simply not enough QoS tags to ennumerate features beyond simplistic features like "worst effort". What SRH allows is the user's application to select routing features for each flow. You can them impose a further SRH on that to fully enumerate the route within your network, or flip them into a MPLS virtual router, or select a different routing table, etc. This allows ISPs to move towards per-application routing, which is an attractive place to be for CDNs (which are currently hacked-up using DNS resolver addresses to determine the CDN node to use). As noted, the HMAC can be used for access control, although in the CDN case, only being able to reach particular CDN nodes is probably punishment enough to limit abuse.
Posted May 18, 2017 15:06 UTC (Thu)
by ballombe (subscriber, #9523)
[Link] (1 responses)
Posted May 22, 2017 11:56 UTC (Mon)
by niner (subscriber, #26151)
[Link]
Posted May 19, 2017 18:50 UTC (Fri)
by excors (subscriber, #95769)
[Link] (8 responses)
Not particularly relevant but it might be worth noting that that only really applies within smallish networks, not across the global internet or very large intranets that use BGP.
If I remember correctly, BGP's primary consideration when choosing routes is simply to avoid loops; its secondary considerations are often commercial and only locally optimal, e.g. it's usually best to send traffic to your customers (who are paying you for traffic) if they'll accept it, else to peers (who you've agreed to exchange traffic with for free), and only to providers (who you have to pay) if unavoidable, without caring how far the traffic goes once it's off your own network. It's also common to prefer or filter routes based on arbitrary tags set by your neighbours to get all kinds of complicated behaviour, e.g. only advertising routes to peers in a particular continent.
Once BGP has done all that (and more) and still has no preference between two or more possible routes, then it finally bothers to look at which path is 'shortest' (based on number of ASes it passes through; of course people often put their AS into the route's AS list multiple times to make it 'longer' and less preferred, which is okay until so many people do it that the list length reaches 256 and some routers treat it as a fatal error and disconnect from their neighbours and the internet breaks).
One consequence of not simply computing shortest paths is that shortest-path algorithms don't work. BGP tries to use one anyway, so you can break the algorithm and get instability or get permanently stuck in incorrect states if you're unlucky, which is fun.
Source routing seems to fundamentally rely on the source being trusted by the network operators that the route crosses (because you don't want to accept a packet that asks to be sent back and forth across the Atlantic a hundred times) so I guess it's never going to work across the internet. But it's useful within a trusted network, since most of your routers can use a simple dumb routing algorithm and don't need a million-entry IP forwarding table, and the complex policy is only needed at the edges. (I think this is what large networks have always done, using MPLS; Segment Routing sounds like basically a better (and more IPv6-friendly) way of assigning MPLS labels, and the SRH sounds like basically an alternative to MPLS for forwarding.)
Posted May 19, 2017 19:31 UTC (Fri)
by Cyberax (✭ supporter ✭, #52523)
[Link] (6 responses)
Posted May 20, 2017 9:22 UTC (Sat)
by paulj (subscriber, #341)
[Link] (5 responses)
The rest of the network can't stay stateless though. In order for the transmitting node to specify exactly the route it wants, it needs to have have a lot of information on the state network (there's not much source routing to do otherwise). The state of the network must be gathered and communicated around, by the network - which requires holding state. The network can never abstract that information either, if source routing is to be useful, so the bigger the network the worse this scales.
Source routing is powerful, but it comes with its own set of problems. As is often the case in networking and computer systems, we tend to oscillate back and forth and re-visit things. What is old becomes hot again. Distributed routing! Centralised! Next-hop routing! Source-routing! This has been going on for many decades... ;)
Posted Dec 21, 2017 3:16 UTC (Thu)
by immibis (subscriber, #105511)
[Link] (4 responses)
Posted Dec 18, 2020 12:20 UTC (Fri)
by paulj (subscriber, #341)
[Link] (3 responses)
Posted Dec 18, 2020 20:38 UTC (Fri)
by Cyberax (✭ supporter ✭, #52523)
[Link] (2 responses)
You can literally encode all the route information in labels that are interpreted like this: "send the packet to port 8, pop label, send the packet to port 2, pop label, ...". And all this encoding can be done on the edge router so the inner routers don't have to know anything.
As you said, the problem is that "port 2" might not actually be working, so all the traffic is going to be blackholed. This is typically solved by having a separate control plane network that is used to communicate the state of individual routers. It can physically run on top of the same media, just with special labels that instruct the routers to do something like "decapsulate packet, and punt it to the CPU". The CPU then runs a classic IS-IS/OSPF stack and marks the outgoing packets with the same "decapsulate and punt" label.
One large cloud provider has a fully separate network for the control plane, it's not even using the same physical hardware to avoid any possibility of interference of customer data flows with the control plane.
Posted Dec 18, 2020 22:43 UTC (Fri)
by paulj (subscriber, #341)
[Link] (1 responses)
How do you build a distributed control-plane for it that can allow the 'core' to be dumb and at least scale well (i.e., the state grows at a less-than-linear rate, relative to growth in the number of nodes), if not stateless (which to my thinking, implies constant state at each node, regardless of the size of the node).
OSPF/IS-IS don't scale up arbitrarily. They need O(N . LogN + M) entries in each flooding domain, for N nodes with M links, and a further O(N.logN) amount of state for vectored destinations outside of flooding domains. RSVP-TE scales much worse again.
If you know how to make source-routing scale well, you should write a Ph.D. on it - or start a company.
Posted Dec 18, 2020 23:04 UTC (Fri)
by Cyberax (✭ supporter ✭, #52523)
[Link]
> OSPF/IS-IS don't scale up arbitrarily. They need O(N . LogN + M) entries in each flooding domain, for N nodes with M links, and a further O(N.logN) amount of state for vectored destinations outside of flooding domains. RSVP-TE scales much worse again.
You also don't need to do that in hardware (so no worries about TCAM capacity), purely software routing is fine.
> If you know how to make source-routing scale well, you should write a Ph.D. on it - or start a company.
Posted May 20, 2017 7:48 UTC (Sat)
by obonaventure (guest, #108715)
[Link]
The recent SRv6 programming draft also provide additional use cases and benefits for IPv6 SR that cannot easily be realised with MPLS
Posted May 24, 2017 9:34 UTC (Wed)
by stevenc (guest, #114573)
[Link]
IPv6 segment routing
IPv6 segment routing
IPv6 segment routing
IPv6 segment routing
IPv6 segment routing
IPv6 segment routing
IPv6 segment routing
IPv6 segment routing
The usual problem with BGP is that it only has the distance information. So if you have something like this:IPv6 segment routing
AS0 - AS1 - AS2 - AS3 (1GBps) - AS7 (1GBps) - AS4
|- AS5 - AS6 (1kbps) ----------------|
Then there's no way for AS0 to prefer the first route to the second one (without administrative intervention). And this is OK with global Internet - you are not administrative authority for AS1 and you shouldn't be able influence it (directly).
However, you can have similar problems within one organization and you should be able to solve them. OSPF and IS-IS allow you to do weighted paths but that's not always enough in the current world.
For example, you might want to have different networks paths for low-latency traffic and high-bandwidth flows. Managing two topologies on top of OSPF is... challenging.
And in some situations you might also want to send out traffic across all your links, not just the lowest cost ones. But this can easily lead to routing loops with distance-based protocols. So you really need to have an "eagle eye" view of the topology for that, you can't make it work with routing decisions based only on local connectivity information.
You still can kinda make it work by using the regular source-based routing by uploading decision tables into every router on the path, but this just doesn't scale.
MPLS (and ipv6sr) allows to work around that - you can have a central "route planning" system that uploads the full routing information into your edge routers and they basically encode it in every packet and the rest of the network can stay dumb and stateless.
IPv6 segment routing
MPLS (and ipv6sr) allows to work around that - you can have a central "route planning" system that uploads the full routing information into your edge routers and they basically encode it in every packet and the rest of the network can stay dumb and stateless.
IPv6 segment routing
IPv6 segment routing
IPv6 segment routing
IPv6 segment routing
IPv6 segment routing
Individual data-plane routers just need a handful of rules (in the extreme, equal to the number of ports).
You need OSPF/ISIS only for the control plane nodes, and you don't need many of them. Perhaps tens of thousands even for the extremely large networks (e.g. an Amazon AWS region). This amount of state can be easily managed through OSPF/ISIS flooding over gigabit-range links.
I did look into it, but it's hard. You might have maybe several dozens of very large potential customers and it's a very hard market to get into. Every customer will require a lot of custom integration with their system, and for a startup it's just not feasible.
IPv6 segment routing
https://tools.ietf.org/html/draft-filsfils-spring-srv6-ne...
IPv6 segment routing