
LWN.net Weekly Edition for May 18, 2017
Welcome to the LWN.net Weekly Edition for May 18, 2017
This week's edition has a wide variety of feature articles:
- Entering the mosh pit: in which your editor finally gets around to playing with the Mosh shell.
- OpenStack faces the challenges of cloud backups: what do backups mean in the cloud environment, and how well are backup needs met by available free tools?
- Vulnerability hoarding and Wcry: a few observations on this week's malware mess.
- The end of the 4.12 merge window: a summary of the new features included in the final 1,000 changesets merged for the 4.12 development cycle.
- Randomizing structure layout: a look at the randstruct GCC plugin.
- Restricting pathname resolution with AT_NO_JUMPS: a proposed system-call enhancement that would help applications sandbox their filesystem accesses.
- IPv6 segment routing: a look at a new networking feature added during the 4.10 kernel development cycle.
Please enjoy this week's edition, and, as always, thank you for supporting LWN.net.
Entering the mosh pit
For some years now, your editor has heard glowing reviews of Mosh — the "mobile shell" — as a replacement for SSH. The Mosh developers make a number of claims about its reconnection ability, performance, and security; at least some of those are relatively easily testable. After a bit of moshing, a few clear conclusions have come to the fore.Mosh has been around since 2011 or so; the 1.3 release came out in March. It appears to be under active development and to be reasonably widely used. Mosh runs on just about any type of operating system one can imagine, and binary packages are readily available. Setup is nearly zero-effort, with one small exception noted below. In short, if Mosh meets your needs, there is little excuse for not using it.
Calling Mosh an "SSH replacement" (as the project's web site does) is not quite correct, though, for a couple of reasons. The first of those is that you still need SSH around to set up a Mosh connection. Mosh doesn't bother with little details like listening for new connections or authentication; it relies on SSH for those. Typing "mosh remote-host" will set up a connection but, behind the scenes, SSH will be used to make the initial connection to the remote host. Thus, one still has to go through the usual authentication dance — entering passwords, distributing public keys, etc. — before using Mosh. The good news being, of course, that one's existing SSH authentication setup will work unchanged with Mosh.
Once an SSH connection is established, though, the only thing Mosh uses it for is to start a mosh-server process at the remote end and to exchange keys with that process. Once that's going, the SSH link is closed and discarded; the client and server talk directly using a UDP-based protocol thereafter. That is one place where one can encounter minor setup difficulties. Installing Mosh itself can be an entirely unprivileged operation, but that may not be true of the task of ensuring that its UDP packets make it through any firewalls between the local and remote systems.
Each UDP packet is separately encrypted (using the OpenSSL AES implementation) before sending and authenticated on receipt; if all works well, that should make it impossible for an attacker to eavesdrop on the connection or inject packets into it. In theory, encryption at this level is more robust than the TCP-based encryption used by SSH; only the latter is subject to TCP reset attacks, for example. The protocol is designed with its own flow control that, among other things, is designed to avoid filling up network buffers along the path between the systems. Any longtime SSH user knows the annoyance that comes from interrupting a verbose command with ^C and having to sit through a long wait while all of the already-transmitted output makes its way across the link. Mosh claims to avoid that behavior — and your editor's tests suggest that the claim is warranted.
The actual protocol is called "state synchronization protocol" (SSP); it is built on the idea that the endpoints are maintaining copies of the same objects and communicating changes to the state of those objects. One object, maintained primarily on the client side, represents the keystrokes that the user has typed. The server end, instead, owns an object describing the state of the screen. The two ends exchange packets whenever the state of one of those objects changes, allowing the other end to update its idea of their state.
"TELNET
", the project's web site proclaims, "had some
good things going for it
". One of those was local echo. Users
typing over an SSH connection will not see their keystrokes until they are
echoed by the remote end; on a flaky connection, that can make typing
painful. Mosh, instead, has some tricky-seeming code in the client that
can anticipate the changes in the state of the screen object and echo
keystrokes ahead of the remote end. "Tricky" because the client has to
figure out when not to echo — when a screen-mode application is
running, say, or when a password is being typed. Your editor did not have
access to a network slow enough to exercise this feature; it will be
interesting to give it a try the next time it's necessary to try to get
some work done over an airplane WiFi network.
Since UDP is connectionless, packets can come from anywhere. Mosh uses this feature to implement its reconnection mechanism. The Mosh "connection" exists for as long as the mosh-server process is running; the client, meanwhile, can disappear and reappear at will. So, for example, one's laptop can switch from one wireless network to another, getting a new IP address in the process. The Mosh server will notice that packets are now coming from a different address; if those packets authenticate properly, the server will start sending its own packets to that address. So the Mosh connection will persist, uninterrupted, possibly without the user even noticing.
Your editor ran some tests of this feature, switching the laptop between a local network and tethering via a phone handset. The Mosh client puts up a notification when connectivity goes away (it seems to notice before the laptop itself figures out that its WiFi access point has vanished); once the network returns, the Mosh connection is back up and running. If an output-producing command is running while the change happens, none of the output will be lost (modulo one detail).
Mosh tries to provide the best terminal experience it can. It seems that quite a bit of effort has, for example, gone into proper handling of UTF-8 character sequences and escape sequences. But there is an implication of the state synchronization protocol that affects the terminal experience in a significant way. Since Mosh models the entire state of the screen, it wants to be in control of that state, with the result that it overrides and changes the behavior of the terminal emulator that one might be running Mosh within.
This aspect of Mosh is perhaps most visible when it comes to scrolling back through the terminal output. The Mosh model of the screen encompasses the screen itself, but not anything that has scrolled off the top. When using gnome-terminal and SSH, for example, the mouse wheel can be used to move back through the output; that does not work with Mosh. Instead, the wheel moves through the command history. The gnome-terminal scrollbar becomes inoperable while Mosh is running as well. The problem was first reported in 2011 — it is issue #2 — but it remains unfixed. The workaround is to use a utility like tmux or screen.
Mosh's focus on the terminal experience also ties into the other reason why it is not truly an SSH replacement. It can be used to run an interactive shell on a remote system. It can also be used to run a command non-interactively, but only if the user doesn't care about seeing the result after Mosh exits and resets the screen. But it cannot be used for tasks like port forwarding. Those of us who use SSH as a sort of poor hacker's VPN will need to continue doing so.
Mosh, thus, is aimed at a fairly specific use case: users who engage in interactive terminal sessions with remote hosts over variable and possibly flaky network connections. That is a description that, for example, fits many attendees of Linux-oriented conferences. But, if the truth be told, Mosh is not a tool that will make a day-to-day difference in your editor's life. In a world where many resources are local and the rest are accessed via higher-level protocols, many of us probably do not need a highly optimized, extra-robust remote terminal emulator. For those situations where it is useful, though, it would seem that, as your editor has heard for years, there is nothing better.
OpenStack faces the challenges of cloud backups
It seems that system administrators will never shake the need for backups, even when they shove everything into the cloud. At the OpenStack Summit in Boston last week, a session by Ghanshyam Mann and Abhinav Agrawal of NEC laid out the requirements for backing up data and metadata in OpenStack—with principles that apply to any virtualization or cloud deployment.
Many years ago, I backed up my workstation by inserting a cartridge tape each night into a drive conveniently included with the machine. A cron job ran during the wee hours of the night to shut down the machine and run a backup, either full or incremental, then bring up the machine. So far as I know, the servers at our company followed the same simple strategy.
Backups have gotten much more complicated over time. We no longer want to shut down any machine—we want five nines reliability (or the illusion of it) so people can connect to us at any time of the day or night. We want to checkpoint our backups so we don't have to restart them from the beginning in case of a network glitch or power failure. We want to restore files more easily, without waiting half an hour for the tape to fast-forward. And file backups don't always reflect the complexity of what we're trying to recover. Databases, for instance, are scattered among multiple files and depend just as much on the schema for the data as the raw data itself; they come with specialized backup commands.
Cloud computing takes this complexity to yet a new level. Mann listed the significant pieces of a cloud deployment: configuration files (contents of the /etc directory, in the case of OpenStack and other Unix-style utilities), log files, databases (all OpenStack services employ them), volumes, and virtual machines. Plain files can be saved through a file backup, and databases through their standard backup services such as mysqldump.
One basic question that the speakers skipped over is why one needs a backup when a robust virtualization architecture already includes redundancy. Even if a data center or an entire availability zone goes down, you should lose only a bit of recent data and be able to switch to another instance of your running service. The key to the answer is realizing that mere redundancy doesn't make it easy to recover a lost service. You still need an orderly way to restore everything to a running state. Perhaps we should spend more time discussing the recovery aspect of backup systems, rather than the backups themselves.
Agrawal laid out conventional reasons for backing up cloud instances: recovery from data loss, human error, power or hardware failure, upgrade problems, or natural disaster. He pointed out that a good backup and recovery system is a competitive advantage to those offering cloud services. Its presence may also be necessary for regulatory compliance.
A backup solution should save you from writing a bunch of manual scripts. It should guide you through the standard questions that govern backups: how often and when to do it, how many backups to keep, whether they should they be kept offsite, how frequently backups should be tested, etc. Mann described the essential features for a backup and restore system:
- The system should allow full, differential, incremental, and file-level backups.
- The system should support policy-driven backups, where the policies cover different data formats and retention strategies.
- Restore methods should include one-click restores, selective restores (for a single VM that goes down), and file-level restores.
- De-duplication is a valuable feature that reduces storage space and bandwidth costs. However, no system aimed at OpenStack currently does this.
- Data compression should be used, for the same reason as de-duplication.
- Security is clearly critical. Cloud backups have to recognize multi-tenant sites that run unrelated and potentially hostile clients on the same physical machine. It should be easy for each client to get all of its data and metadata, but impossible to get those of another client.
- The backup should be non-disruptive, allowing systems to stay up.
- Scalability is particularly important in the cloud, where a million nodes may need to be backed up.
- The backup should be sensitive to geographic location, so the user can decide whether to back up to a different availability zone for extra robustness, or store the backup locally to save money.
- A simple GUI or command-line interface should be offered.
Naturally, you have to allocate storage space, CPU time, and other resources to backups.
The speakers ended with a list of solutions, most of them commercial. As mentioned earlier, no solution supports de-duplication yet. Nor do any of them checkpoint backups in case of a network failure. Anything that aborts the backup requires you to restart it from the beginning. One backup system, Freezer, is a free-software OpenStack project.
Freezer provides backup and restore as a service; it consists of four separate components, two for the client and two for the server side. It provides full and incremental backups for files and databases that can optionally be encrypted; the data can be stored locally, in the OpenStack Swift object storage facility, or on remote systems via SSH. Freezer's user interface is integrated with the OpenStack Horizon dashboard, as well. Freezer has had a few different releases over the past year or so and seems to be a fairly active project. However, Freezer does not appear on the list of commonly used OpenStack components in the April 2017 user survey. Its value to the community is therefore hard to gauge.
Automated backups are one of the first features sought by production facilities when they evaluate any system. Since OpenStack is part of our global computing infrastructure by now (it supports 5 million cores in 80 countries, according to the keynote by Jonathan Bryce, Executive Director of the OpenStack Foundation), the maturity of OpenStack is enhanced by the presence of multiple backup options, as well as by the inclusion of this talk at the summit.
Interested readers can view the video of the talk.
Vulnerability hoarding and Wcry
A virulent ransomware worm attacked a wide swath of Windows machines worldwide in mid-May. The malware, known as Wcry, Wanna, or WannaCry, infected a number of systems at high-profile organizations as well as striking at critical pieces of the infrastructure—like hospitals, banks, and train stations. While the threat seems to have largely abated—for now—the origin of some of its code, which is apparently the US National Security Agency (NSA), should give one pause.
At this point, 200,000 computers or more have been affected since Wcry started ramping up on May 12. So far, it is unknown how Wcry got its initial foothold on various systems, but it spreads to other computers using code derived from the EternalBlue remote code-execution exploit that is believed to have been developed by the NSA. EternalBlue exploits a bug in the Server Message Block (SMB) implementation in multiple versions of Windows; it was patched for still-supported Windows versions in March. EternalBlue was released as part of the Shadow Brokers trove of leaked NSA exploits in April; the timing of the Microsoft patches led some to wonder whether the company was tipped off about the upcoming leaks in time to fix them before the release. It is also possible that Microsoft was alerted by someone who saw exploits in the wild or that the company found them independently.
Once a system is infected, Wcry does what ransomware is known for: it encrypts the contents of the hard disk and requests a ransom in Bitcoin to decrypt them. The amount requested is fairly small (on the order of $300-600, at least if it was paid by May 15) but some $71,000 had been collected from more than 250 victims by that deadline. Somewhat ironically, a bug in Wcry allowed the payments to be tracked more easily—code to generate a Bitcoin wallet per victim suffered from a race condition, so a hardcoded set of three wallets was used by the malware.
Another flaw was the key to the downfall of the initial version of Wcry. The malware had an "kill switch" (which was probably inadvertent) that allowed a security researcher to register a domain that effectively stopped it from doing the encryption. It could simply be a bug in Wcry, but there is another possibility: in an attempt to avoid running its code in a sandboxed environment (where researchers can safely learn more about its inner workings), Wcry tries to connect to a (formerly) unregistered domain. In some sandboxed environments that are used to study malware, all domain names resolve to the sandbox's IP address; by checking a connection to a non-existent domain, the malware could avoid running in those environments. Luckily for the rest of us, registering the domain had the same effect—now all Wcry instances were running in a "sandbox".
There has been a fair amount of finger pointing about Wcry. One of the main targets of the malware has been Windows XP, which has been beyond its end of life since 2014. Given the ferocity and reach of the attack, however, Microsoft did put out a patch for XP and two other no-longer-supported versions (Windows 8 and Windows Server 2003). That led some to criticize the software giant for not doing so back in March. The company deflected the criticism in the direction of the NSA, which is, in truth, where much of the real problem lies.
Intelligence organizations like the NSA and countless other agencies throughout the world are extremely interested in vulnerabilities that can be used to gather data or are beneficial to their missions in other ways. However, those same exploits can be used in more mundane ways—shaking down businesses for Bitcoin, for instance. The agencies can only benefit from the vulnerabilities as long as they remain unpatched, which gives them plenty of reason to keep them secret. Though, as we have seen with Wcry, the existence of a two-month-old patch is hardly an insurmountable barrier for an exploit to overcome.
One might argue that as long as the agencies hold the vulnerability information close to the vest—and not bungle the security of their trove of "weaponized exploits" as the NSA evidently did—there should be little harm to those who are not targets. That is wishful thinking, however. The longer a vulnerability exists, the more people who know about it, maybe only in general terms, but that is often enough for skilled security researchers (of any colored hat) to figure out what it is. In particular, if a vulnerability is exploited in the wild, it is even more likely that it will be exposed to others. Exposure can happen in other ways, including the vulnerability being discovered, but not reported, long before the agency became aware of it. Gathering and hiding vulnerabilities is a kind of insecurity through obscurity; as a defense, it works about as well as its better known sibling.
If the companies that are responsible for the software—or, in the free-software world, the projects—are not getting any information about the vulnerabilities, it is hard to see how they can be blamed for not fixing them. Things become trickier for older, unsupported versions, though. By fixing XP this time, Microsoft may have set itself up for future calls to patch the 16-year-old system.
Of course, Microsoft is hardly alone in having a lot of its older software still running in the wild. Closer to home, Android is in some ways in a similar spot. There are huge numbers of Android devices out there with unpatched vulnerabilities; some of the vulnerabilities are already known, but there are undoubtedly others being hoarded by agencies and malicious players. Some kind of attack that threatened a huge swath of Android devices might well lead to calls for patches to age-old kernels.
Unfortunately, in the Android case, even patching the kernels may not be enough—updates in the embedded space are nowhere near as easy as they are for desktops. Even though they may be easier for desktops, though, that doesn't mean that updates get applied, sadly. Thus the need for better self protection in our software. Whacking moles as the sole means of protecting our systems is not tenable any more.
The real culprits in this matter are, of course, those who created Wcry and loosed it on the world. There has been speculation that North Korea have had a hand in it based on some of the code in early variants of Wcry. That code has been linked to the Lazarus Group, which in turn has been connected to the North Korean government. All of the evidence, which is fairly scant, is circumstantial at best; there are plenty of other groups, countries, and organizations that might have interest in a worldwide cyber attack. In the end, for the victims, it hardly matters who was behind it.
The end of the 4.12 merge window
Linus Torvalds released the 4.12-rc1 prepatch and closed the merge window on May 13 — a move that may have surprised maintainers who were waiting until the last day to get their final pull requests in. Let that be a lesson to all: one should not expect to have pull requests honored on Mother's Day. Below is a summary of the changes merged since the May 10 merge-window summary.In the end, 12,920 non-merge changesets found their way into the mainline during the merge window; about 1,000 since the previous summary was written. As expected, that was enough to make the 4.12 merge window the second-busiest ever. The most significant changes found in that last 1,000 changesets include:
- The TEE framework has been merged;
this mechanism allows the kernel to support trusted execution
environments on processors (such as ARM CPUs with TrustZone) with that
capability.
- Support for parallel NFS (pNFS) on top of object storage devices has
been removed; that support is unused and has been unmaintained for
some time.
- The building of the old Open Sound System audio drivers has been
disabled for the 4.12 release. In the absence of screaming, those
drivers will likely be removed in the relatively near future. They
are poorly maintained and nearly (if not completely) unused, but the
driving motivation behind this change at the moment is the desire to eliminate the many set_fs()
calls found in those drivers.
- New hardware support includes:
Mediatek MT6797 clocks,
HiSilicon Hi655x clocks,
Allwinner PRCM clock controllers,
Motorola CPCAP PMIC realtime clocks,
STMicroelectronics STM32 Quad SPI controllers,
Broadcom BCM2835 and BCM470xx thermal sensors,
Dialog Semiconductor DA9062/DA9061 thermal sensors,
Powers AXP20X battery power supplies, and
PlayStation 1/2 joypads via SPI interfaces.
- There is a
new set of macros that allow the marking of boot-time and module
parameters that modify hardware behavior. Numerous drivers have
been patched to make use of these macros. The intent is to disallow a
user from changing these parameters on systems where UEFI secure boot
is in use, but that mechanism has not yet been merged.
- Synchronous read-copy-update grace periods may now be used anywhere in the kernel's boot process; see this article for the details.
The time to test and stabilize the 4.12 kernel has begun; if all goes according to the usual schedule, the final release can be expected in early July.
Randomizing structure layout
Kees Cook is working on a series of patches for C structure randomization to improve security in the Linux kernel. This is an important part of obfuscating the internal binary layout of a running kernel, making kernel exploits harder. The randstruct plugin is a new GCC add-on that lets the compiler randomize the layout of C structures. When enabled, the plugin will scramble the layout of the kernel structures that are specifically designated for randomization.
The patches in question are part of the Kernel Self Protection Project (KSPP). The goal of KSPP is to harden the mainline Linux kernel. Currently, KSPP is primarily working on porting features from grsecurity/PaX to mainline Linux, and sending them incrementally to the Linux kernel mailing list. The structure randomization patches are part of that effort, and is a port of grsecurity's structure layout randomization plugin.
Structure randomization
Fields in a C structure are laid out by the compiler in order of their declaration. There may or may not be padding between the fields, depending on architecture alignment rules and whether the "packed" attribute is present. One technique for attacking the kernel is using memory bounds-checking flaws to overwrite specific fields of a structure with malicious values. When the order of fields in a structure is known, it is trivial to calculate the offsets where sensitive fields reside. A useful type of field for such exploitation is the function pointer, which an attacker can overwrite with a location containing malicious code that the kernel can be tricked into executing. Other sensitive data structures include security credentials, which can result in privilege-escalation vulnerabilities when overwritten.
The randstruct plugin randomly rearranges fields at compile time given a randomization seed. When potential attackers do not know the layout of a structure, it becomes much harder for them to overwrite specific fields in those structures. Thus, the barrier to exploitation is raised significantly, providing extra protection to the kernel from such attacks. Naturally, compiler support is necessary to get this feature to work. Since kernel 4.8, GCC's plugin infrastructure has been used by the kernel to implement such support for KSPP features.
To get structure randomization working in the kernel, a few things need to be done to ensure that it works smoothly without breaking anything. Once enabled, the randstruct plugin will do its magic provided a few conditions are met. First, structures marked for randomization need to be tagged with the __randomize_layout annotation. However, structures consisting entirely of function pointers are automatically randomized. Structures that only contain function pointers are a big target for attackers and reordering them is unlikely to cause problems elsewhere. This behavior can be overridden with the __no_randomize_layout annotation, when such randomization is undesirable. Therefore, if enabled, structure randomization is opt-in, except for structures that only contain function pointers, in which case it becomes opt-out. An example of a situation where __no_randomize_layout is needed is this patch from Cook, in which some paravirtualization structures (consisting entirely of function pointers) are used outside the kernel, hence should not be auto-randomized.
Structures to be randomized need to be initialized with designated initializers. A designated initializer is a C99 feature where the members of a C structure are initialized in any order explicitly by member name instead of anonymously by order of declaration. Also, structure pointers should not be cast to other pointer types for randomized structures. Cook has sent a number of patches to convert a few sensitive structures to use designated initializers, but their use has been standard practice in the kernel for some time now, so the kernel is pretty much ready for that feature. Structures that explicitly require designated initializers can be tagged with __designated_init; that will trigger a warning if a designated initializer is not used when initializing them.
Randomization of task_struct
This is a change that affects the source code in many places, so careful consideration is required when reordering some structure's internals as there are special cases that need to be handled. The task_struct structure is a prime example of a structure that benefits from field randomization. Inside task_struct are sensitive fields such as process credentials, flags for enabling or disabling process auditing, and pointers to other task_struct structures. Those fields, among others, are juicy targets for potential attackers to overwrite. However, we can't just randomize the entirety of task_struct, as some fields on the very top and very bottom of the structure need to be where they are.
The top of task_struct is as follows:
struct task_struct {
#ifdef CONFIG_THREAD_INFO_IN_TASK
/*
* For reasons of header soup (see current_thread_info()), this
* must be the first element of task_struct.
*/
struct thread_info thread_info;
#endif
To make it easy for current_thread_info() to get to the thread_info structure of the current running thread, it is possible to just use a struct thread_info pointer to the first element of the task_struct without having to actually include the file that defines it. This is to avoid circular header dependencies that arise from such an inclusion. Therefore, thread_info needs to be at that fixed location for the pointer access to work.
The bottom of task_struct has a similar position-locked structure:
/* CPU-specific state of this task: */
struct thread_struct thread;
/*
* WARNING: on x86, 'thread_struct' contains a variable-sized
* structure. It *MUST* be at the end of 'task_struct'.
*
* Do not put anything below here!
*/
};
From here we can see that the implementation of thread_struct is architecture-specific, can be variable in size and sensitive to alignment. Thus it needs to be placed at the very end, and cannot be shifted around.
Linus Torvalds weighed in on task_struct randomization:
Thus, the solution in Cook's patch is to introduce another sub-structure that encompasses the middle of task_struct, just after the first fields and just before the last one, and to mark that as randomizable. Any other fields that need to be position-locked can be carved out with more sub-structures without the __randomize_layout annotation; two such fields are blocked and saved_sigmask (both sigset_t). These fields are directly copied to user space and are expected to be adjacent and in that order.
More caveats
There is one major caveat to structure randomization: to build third party or out-of-tree kernel modules against a kernel with randomized structures, the randomization seed is required. Therefore, those distributing kernel binaries (such as Linux distributions) will need a way to expose the randomization seed to users that install the kernel headers or other kernel development package; attackers can use that to defeat the randomization. Since the same seed will be used across all instances of that particular distribution (as the seed needs to be chosen at compile time), any successful attack on a distribution kernel would work for all installations of that distribution kernel version. Nevertheless, compile-time randomization remains useful for custom private kernel builds, where the seed need not be exposed. Cook explains:
Nevertheless, Torvalds is unimpressed by structure randomization, calling it
security theater. The fact that distributions need to publish the
randomization seeds for module-building meant it did not provide as big of
a security feature as advertised. Torvalds however did add:
"So it's imnsho a pretty questionable security thing. It's likely most
useful for one-off 'special secure installations' than mass productions.
"
To which, Cook replied:
"Well, Facebook and Google don't publish their kernel builds. :)
"
There is a good argument to be made that large production servers running custom kernels do benefit from additional security protections such as structure randomization, so it is a worthwhile addition to the mainline.
Restricting pathname resolution with AT_NO_JUMPS
On April 29, Al Viro posted a patch on the linux-api mailing list adding a new flag to be used in conjunction with the ...at() family of system calls. The flag is for containing pathname resolution to the same filesystem and subtree as the given starting point. This is a useful feature to have for implementing file I/O in programs that accept pathnames as untrusted user input. The ensuing discussion made it clear that there were multiple use cases for such a feature, especially if the granularity of its restrictions could be increased.
As an example use case, consider a web server that accepts requests for documents along with a relative path to said documents from the root of the server data directory. It is imperative that the user-supplied pathname sent to a web server is not allowed to name files outside of the web-server subtree. If the web server could use file I/O system calls that guaranteed that any given path will never break out of a certain subdirectory tree, it would give an additional layer of security to the server.
The ...at() family of system calls (such as openat(), fstatat(), mknodat(), etc.) are a relatively new series of POSIX filesystem interfaces, similar to open(), fstat(), mknod(), and friends, but allowing the start point for relative pathnames to be something other than the current working directory. For example, the openat() system call's prototype is:
int openat(int dirfd, const char *pathname, int flags);
A call to openat() will try to open the file specified by the pathname. If the pathname is a relative path, such as ../home/user1, openat() will try and walk the directory structure relative to the directory bound to the file descriptor dirfd, instead of the current working directory (which is what open() does). The behavior of this and other calls in the same family can be further altered with the flags parameter.
Viro's proposed flag (initially called AT_NO_JUMPS) for the ..at() calls would restrict the directory traversal of those calls to the same subtree as the starting point and, in any case, within the same filesystem. When the flag is set, the ...at() call affected would fail with -ELOOP upon encountering an absolute pathname, an absolute symbolic link, a procfs-style symbolic link, a pathname that results in the traversal of a mount point, or any relative path that starts with "..". This flag thus confines pathname lookups to subdirectories of the starting point that are contained within the same mount point, while allowing the traversal of relative symbolic links that do not violate the aforementioned rules. The error code -ELOOP is used by Unix-like operating systems to tell the user that too many symbolic links were encountered during pathname lookup, but it is used here as a placeholder. The patch only implements AT_NO_JUMPS for fstatat() and friends, but the proposal is for it to be extended to all the ...at() calls.
Jann Horn commented that this proposal is somewhat similar to the O_BENEATH functionality that was sent to the Linux kernel list by David Drysdale in November 2014, but was ultimately not merged. The O_BENEATH flag is a port of a feature from Capsicum, a project that seeks to provide the ability to use capabilities to let applications sandbox themselves with a high degree of control. Horn noted that, while the functionality is similar, the intended use case for O_BENEATH is application sandboxing, whereas the AT_NO_JUMPS flag is to enable user programs to limit their own filesystem access. Viro commented that, unlike O_BENEATH, AT_NO_JUMPS does allow relative symbolic links, which he thinks is the saner option:
Andy Lutomirski suggested
splitting the flag into two, "one to prevent moving between mounts
and one for everything else
". This is because web servers and the
like will probably be fine with mount-point traversal; they only need the
directory containment feature. Horn concurred
with Lutomirski about the usefulness of the split.
Viro agreed that the no-mount-point-crossing policy from AT_NO_JUMPS could be split out into a separate flag. He proposed AT_XDEV for preventing mount point crossing, and the original flag be renamed to AT_BENEATH to match the functionality of O_BENEATH, which does allow crossing mount points. The returned error for crossing mount points when AT_XDEV is enabled could be the obvious -EXDEV, while the error for AT_BENEATH would still be -ELOOP (which Viro isn't too satisfied with, but nothing else has been suggested thus far).
Linus Torvalds liked the split, but wanted to go even further:
As mentioned last time, at least for the git usage, even relative symlinks are a no-no - not because they'd escape, but simply because git wants to see the *unique* name, and resolve relative symlinks to either the symlink, or to the actual file it points to. So I think that we'd want an additional flag that says "no symlinks at all". And I think the "no mountpoint" traversal might be splittable too.
Torvalds went on to say that, sometimes, the use case is just to guarantee that pathname resolution does not go above a certain point in the directory tree, regardless of whether the directory walk crosses mount points. However this should only be the case of non-bind mount points. Bind mount points are basically views of directories (or files) that are mounted in another place in the directory tree. Since bind mounts can be used to break the directory containment, they should not be allowed. However from the system's point of view, there is no difference between a mounted filesystem and a bind-mounted directory, and thus Torvalds is not sure if it a mount point can be tested if it is a bind mount or not. Viro agreed that it wasn't testable, and thus cannot be handled as a special case.
Viro then proposed that the flags become AT_BENEATH, AT_XDEV, and AT_NO_SYMLINKS, which is the flag used when no symbolic links are allowed at all. This proposal raises a few questions on how to handle some of the combinations of these three flags. Viro asked what AT_XDEV should do with absolute symbolic links. Torvalds replied that, while it might be more consistent to allow an absolute symbolic link to be traversed with AT_XDEV (but without AT_BENEATH) as long as the root directory is on the same mount point as the starting point, it would be more straightforward to just return -EXDEV on all absolute symbolic links.
Next, if the apparently conflicting flags AT_BENEATH (which allows symbolic links) and AT_NO_SYMLINKS (which disallows all symbolic links) are invoked simultaneously, Viro suggested that AT_NO_SYMLINKS take precedence since it was convenient to implement, to which Torvalds agreed.
Finally, Viro asked what should happen when the final component of a pathname is a symbolic link when AT_NO_SYMLINKS is applied. Torvalds thinks it should be an error if the symbolic link is followed, except if paired with AT_SYMLINK_NOFOLLOW, which indicates that the user is fine with a "dangling symlink" at the end, which will not be followed.
If Viro's proposed changes are picked up in the mainline kernel, we should see more robust directory containment options in the Linux API, which application writers can in turn use for file I/O. Since the pathname traversal protection mechanism will be in the kernel, there will no longer be a need for each user program to do its own pathname checking. This should be a welcome feature for anyone writing applications that work with file and directory names as user input.
IPv6 segment routing
In November 2016, a new networking feature, IPv6 segment routing (also known as "IPv6 SR" or "SRv6"), was merged into net-next and subsequently included in Linux 4.10. In this article, we explain this new feature, describe key elements of its implementation, and present a few performance measurements.
Routing at the source
Segment routing is a modern source-routing architecture that is being developed within the IETF. Traditional IP routing uses destination-based hop-by-hop forwarding. Each intermediate router decides where to forward packets using its local routing table. This table is usually computed according to a shortest-path algorithm. As such, packets traverse networks following the shortest path toward their destination. This behavior is not always optimal, as the shortest path can have undesirable properties, such as congestion.
Existing traffic-engineering techniques enable coarse-grained control over a packet's path by tuning parameters, such as link weights, to adjust the shortest path algorithm. However, these techniques cannot control traffic on a per-flow basis. Segment routing, instead, can forward packets along non-shortest paths toward their destination by specifying a list of detours or waypoints called "segments". This list is specified within the packet itself. Packets are forwarded along the shortest path from the source to the first segment, then through the shortest path from the first segment to the second segment, and so on. The source of the packet can thus specify its path with an arbitrary precision. Segment routing defines two main types of segments representing topological instructions. A "node" segment is used to steer packets through a specific network node, while an "adjacency" segment steers packets through a particular link.
The segment routing architecture has been instantiated in two different data planes: Multiprotocol Label Switching (MPLS) and IPv6. The MPLS variant of SR is already implemented by network vendors and deployed by operators.
SRv6 is implemented with an IPv6 extension header, the routing header. The segment routing header (SRH) contains a list of segments, encoded as IPv6 addresses. A segment represents a topological instruction (node or link traversal) or any operator-defined instruction (e.g., a virtual function). An SRH can be used to steer packets through paths with given properties (e.g., bandwidth or latency) and through various network functions (such as a firewall). The list of segments present in the SRH thus specifies the network policy that applies to the packet. Each SRH contains at least a list of segments and a "segments left" pointer that references the current active segment (a value of zero refers to the last segment). In addition, an SRH can optionally include extended information encoded as type-length-value (TLV) fields. One example is the optional HMAC TLV, used for authenticity and integrity checks.
When a router must impose an SRH on a forwarded packet, the packet is encapsulated in an outer IPv6 header containing the SRH. The original packet is left unmodified as the payload. The router is called the "SR ingress node". The destination address of the outer IPv6 header is set to the first segment of the list and the packet is forwarded to the corresponding node following the shortest path. This node (called a "segment endpoint") then processes the packet by updating the destination address to the next segment. The last segment of the list is the "SR egress node". It decapsulates the inner packet and forwards it to its original destination.
Data-plane implementation
The core of the SRv6 implementation is the SRH processing capability. It enables a Linux node to act as both a segment endpoint and an SR egress node. When a segment endpoint receives an IPv6 packet containing an SRH, the destination address of the packet is local to the segment endpoint. To process this packet, a new ipv6_srh_rcv() function is called whenever the IPv6 input function encounters an SRH in the header chain. An SRH is defined by the following structure:
struct ipv6_sr_hdr {
__u8 nexthdr;
__u8 hdrlen;
__u8 type;
__u8 segments_left;
__u8 first_segment;
__u8 flags;
__u16 reserved;
struct in6_addr segments[0];
};
The ipv6_srh_rcv() function performs several operations. First, it checks that the node is allowed to act as a segment endpoint for SR-enabled packets coming from the ingress interface (skb->dev). This policy is configured through the sysctl boolean net.ipv6.conf.<interface>.seg6_enabled. If it is set to 0, then the packet is discarded. Otherwise, the processing continues.
The packet then goes through an optional HMAC validation, controlled with the sysctl knob net.ipv6.conf.<interface>.seg6_hmac_require. This parameter can take three different values. If seg6_hmac_require is set to -1, the node accepts all SR packets, regardless of the status (absent/present, valid/invalid) of the HMAC TLV. When it is set to zero, the node must accept packets that contain an SRH and either present a valid HMAC TLV or do not include an HMAC TLV at all. Finally, a setting of 1 means that the node accepts only the SR packets that include a valid HMAC.
The next operations depend on the value of the "segments left" counter. If it is greater than zero, then the packet must be forwarded to the next segment. The field is decremented and the destination address of the packet is updated to the next segment. A route lookup is performed and the packet is forwarded.
If, instead, there are no segment left, the operation will depend on the next header. If it is another extension header or a final payload such as TCP or UDP, then the kernel assumes that the packet must be delivered to a local application. The packet processing then continues as normal. On the other hand, if the next header is another IPv6 header, then the kernel assumes that the packet is an encapsulation. The inner packet is then decapsulated and reinjected in the ingress interface using netif_rx().
Control plane implementation
To support SRH encapsulation, the SRv6 implementation uses the lightweight tunnels (LWT) infrastructure. LWTs can associate custom input and output function pointers (in struct dst_entry) to route objects. Those functions are called when a packet is forwarded by the kernel (input) and generated by a local application (output). A per-route stateful data structure (the "tunnel state") is also maintained.
For SRv6, the function pointers are set to seg6_input() and seg6_output(). Those functions encapsulate a packet within an outer IPv6 header that contains a pre-configured SRH. The SRH is stored as the tunnel state, along with a struct dst_cache. This structure stores the route associated with the first segment of the SRH. Indeed, all packets that receive an SRH will be immediately forwarded to their first segment. Using a cache thus prevents an unnecessary route lookup for each processed packet.
To configure the routes, the iproute2 tool has been extended. An SRv6 encapsulation route can be defined as follows:
# ip -6 route add fc42::/64 encap seg6 mode encap \
segs fc00::1,2001:db8::1,fc10::7 dev eth0
This command inserts a route for the prefix fc42::/64. Each matching packet receives an SRH with three segments. Note that it is mandatory to specify a non-loopback interface.
The routes configured by iproute2 are namespace-wide. To support finer-grained control of the SRH insertion, the SRv6 implementation also supports a per-socket interface, using the setsockopt() system call. This interface enables an application to specify its own per-socket SRH. The following piece of code shows how an application can use this feature:
struct ipv6_sr_hdr *srh;
int srh_len;
srh_len = build_srh(&srh);
fd = socket(AF_INET6, SOCK_STREAM, IPPROTO_TCP);
setsockopt(fd, IPPROTO_IPV6, IPV6_RTHDR, srh, srh_len);
HMAC
The authenticity and integrity of an SRH can be ensured using an HMAC TLV. This HMAC covers the source address of the packet and the full SRH (excluding TLVs). The HMAC TLV contains an opaque, operator-defined key ID. In the Linux SRv6 implementation, this identifier refers to a hashing algorithm (currently, SHA-1 and SHA-256 are supported) and to the HMAC secret.
The HMAC support is implemented using static per-CPU ring buffers to store the input data and pre-allocated, per-CPU algorithm descriptors to store the auxiliary buffer/context of the hashing algorithms. Pre-allocation prevents doing expensive dynamic memory allocation for each processed packet, and per-CPU data prevents lock contention.
To associate an HMAC with an SRv6 route, the iproute2 tool provides an hmac keyword. The command ip sr enables configuration of the hashing algorithm and secret associated with a given key ID.
Performance
An evaluation shows that the SRH encapsulation performance is within 12% of plain IPv6 forwarding. The following figure summarizes the results, performed on Xeon X3440 machines with Intel 82599 10 Gbps interface cards:
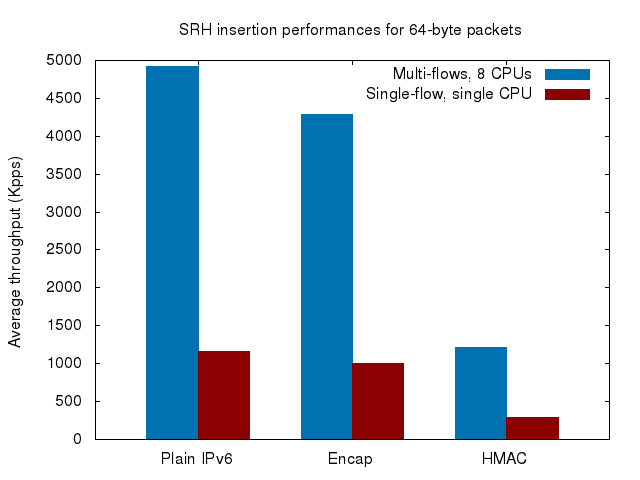
In red is shown the performance for a single flow, processed by a single CPU. The blue bars show the performance for an arbitrarily large number of flows, with the receive-side scaling feature enabled (i.e., the flows are evenly processed by all the CPUs). With the multi-flow measurements, plain IPv6 forwarding peaks at about 4.9Mpps, while SRv6 encapsulation reaches 4.3Mpps. The HMAC computation (using the SHA-256 algorithm) performance reaches only 1.2Mpps. Profiling shows that most of the CPU cycles are used in the sha256_transform() function, which is the main processing function for the hashing algorithm.
The multi-flows measurements are about four times better than the single-flow measurements. This is explained by the fact that the test machine actually has four physical cores with HyperThreading enabled. Considering this, the SRv6 encapsulation performance seems to scale linearly with respect to the available CPU power.
SRv6 is a promising new source-routing technique. For obvious security reasons, it is intended to run within the bounds of an administrative domain. As such, it provides network operators with a powerful traffic engineering and flow management tool. With the help of a central controller, segment routing can implement a software-defined network paradigm, providing an alternative to OpenFlow-based networks. Currently, multiple service providers are exploring the potential of SRv6. Enterprise networks may also benefit from this technique, as IPv6 deployments increase in this kind of environment.
Page editor: Jonathan Corbet
Inside this week's LWN.net Weekly Edition
- Briefs: Brief news from across the development community.
- Announcements: Newsletters, Calls for Presentations, Events, Security updates, Kernel patches.