
LWN.net Weekly Edition for December 15, 2016
Reworking Fedora release schedules
The Fedora distribution has had a habit of missing its release targets over the years, but has also tried to target releases at certain times of the year (early May and late October). That led to a rather short development cycle for Fedora 25 as its predecessor was substantially delayed. Fedora project leader Matthew Miller recently floated an idea on the fedora-devel mailing list that might plausibly help the chronic delayed-release problem and perhaps have other beneficial effects: move Fedora to an annual release cycle. There was more to it than just that, of course, and support for the idea was mixed at best, but the conversation makes it clear that Fedora is willing to look at fairly radical changes as it moves forward.
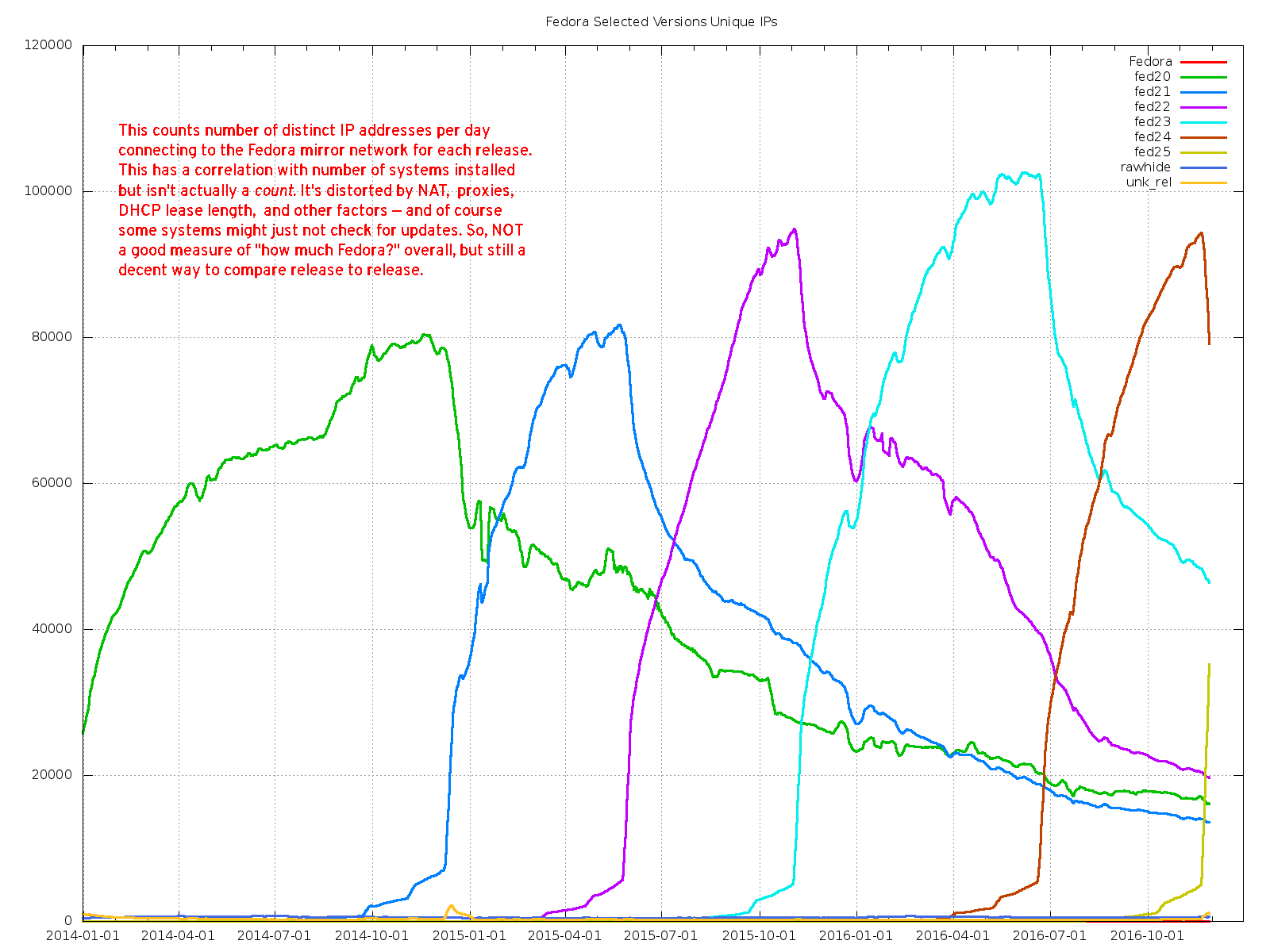
Miller's message started by noting a graph
of distinct IP addresses connecting to the Fedora mirror network for
updates, which shows Fedora 25 performing quite well compared to
earlier releases. The graph is
not a direct measure of the number of Fedora installations, by any means,
but does
provide some rough measure, especially when compared to previous Fedora
releases. "One week after the
release, we're at about the 40k mark, and previous releases going back
to F21 were at around 30k at that time.
"
{kind=link}
But he also noticed something of a trend:
So, first, putting together a release is a lot of work. If we're stepping on the toes of the previous releases, are we wasting some of that work?
Annual releases?
He noted there might be public relations advantages to having one big
release per year. Moreover, the Modularity and Generational
Core initiatives "give us an
opportunity to rethink how we are doing releases entirely
". Those
efforts are aimed at reworking how the distribution is put together, such
that it can better support "modules" that encapsulate kind of a "unit of
functionality" (e.g. a web server) with all of its dependencies. Modules
may have
different
lifecycles than other components of the operating system, which would be
built up using several different components (Base Runtime, System Runtime, and
Shared Components). All of those would be collected up into a "Generational
Core":
Unlike the Base Runtime and System Runtime, the Generational Core will be installable and very similar to the "minimal install" of previous releases of Fedora. It will be somewhat more stripped down even than those. For example, the Generational Core does not need to provide network management services, remote login capabilities or network storage connectivity. These features will be provided by additional modules and module stacks built atop the Generational Core.
That would certainly be a sweeping change for the distribution. But Miller's thoughts go even further:
He solicited input and listed a number of features that he would like to
see in any kind of plan going forward. The list included things like predictable
calendar dates for releases, increasing QA time and maintaining or
increasing the quality of the QA efforts, allowing the QA and release
engineering teams some time to "breathe
" and to work on
infrastructure, maximizing user growth, and so on. In some ways, it all
comes down to "not being on a hamster wheel which routinely bursts
into flame
".
Reaction
But Gerald B. Cox was not convinced by Miller's concern about newer releases stepping on the toes of older ones.
The recent cycle for Fedora 25 was planned for five months so it would, hopefully, land in late October, which was something that Miller pushed for. He now thinks that was a mistake and is questioning whether the frequency of Fedora releases is worth all of the effort that goes into them. But Michael Catanzaro is not so sure. He is concerned that Fedora would lose its place as the premier GNOME distribution if it moved to annual releases:
Miller is thinking that the ".1" update he proposed could incorporate even larger changes like a newer GNOME release, however. But the underlying Modularity initiative is also being questioned. Cox pointed to a comment by Kevin Kofler that was strongly critical of the idea, likening it to the "RPM hell" days. But Chris Murphy said that Modularity is not required in order to effect Miller's plan. There was some discussion of what the end-of-life strategy for the .0 and .1 pieces might be, but Miller seemed to agree that it was a workable scenario.
Another barrier to Miller's original idea is that Fedora release engineering is not prepared to handle all the parts and pieces. Dennis Gilmore pointed out that some significant work would need to be done to support it:
[...] There is a lot of pieces here that I suspect have not been considered because they are in the back of house and most people do not ever think of them. we would need to reconsider how upgrades work, or if we ship things as a rolling release. a big concern I have with any of it is making sure that we publish the matching sources for each binary deliverable.
More concrete
All of that led Miller to propose two
"more concrete
" options for ways to do an annual Fedora
release with one large update six months or so later. His proposal
did that without
"taking modularity into account in
any way; it's 'how we could do this with our current distro-building
process'
". In both cases,
Fedora 26 would be targeted
for a June a release, and 26.1 (or whatever it is called) would created
from that base.
The first
option would batch up all of the non-security updates starting in October and test them together "in
Some Handwavy Way for serious
problems and regressions
" before releasing the whole batch at the
end of the month.
The other option he suggested was to branch the release a month or two
after its release; updates to Fedora 26 would be added to the 26.1
branch, which would get frozen and validated in much the same way as a
regular release (though without the Alpha stage). Fedora 26 would
continue on as usual until January when it would be switched over to use
the 26.1 repository.
While there was some discussion of the technical parts of the plan—the
second option had far more support than the first—much of
the thread concerned the justification for even looking at changing the
roughly six-month release cycle at all. Several participants seemed to
think that the reasons for even considering the change had not been
established. For example, "drago01" asked:
"Which problem are you trying to solve with those proposals?
"
In answer, Miller pointed back to the list of properties in his original email. But drago01 and others are skeptical that a sweeping change as he has suggested will actually preserve those properties. Peter Robinson was concerned that Miller's proposal might create more hamster wheels (flaming or otherwise) than it would actually eliminate. Adam Williamson was also unenthusiastic:
Overall, Miller's thoughts were a bit scattered, at least partly because he was posting in and around a conference he was attending. When he mentioned perhaps considering four-month cycles, Williamson was not seeing how that meshed at all:
When I mentioned shorter cycles, I wasn't suggesting we do all the same stuff we do now, only in a smaller space of time. That would be awful. I was honestly thinking more about far more automated and less significant 'release events'.
He also wondered why Modularity and Generational Core were not part of the picture given that is the direction Fedora seems to be heading. At that point, Langdon White spoke up to try to link those two initiatives into the picture:
If we can get to that point, then we can make "release" and "lifecycle" decisions purely based on the desire of "not code" reasons. In other words, we can decide how many versions of things are currently available based on the effort required to maintain them. We can also decide when a "release" makes sense based on marketing or other considerations and just "pull the trigger" on that day. Or we could allow users to decide for themselves by opting in to a "rolling release" style of deployment.
The problem, of course, is that the Modularity and Generational Core initiatives are still rather new and a lot is left to be done to get to the vision that White outlined. That may well mean that the 2017 releases of Fedora 26 and Fedora 27 proceed along the usual lines, with possibilities of larger changes sometime beyond that time frame. That is why Miller is trying to find a middle ground, though his justifications for that seem weak to several in the thread.
Some of these proposed changes are being driven by the new container-oriented world that is starting to change how packages and software stacks are delivered to users. Things are clearly changing in the world of distributions and it is not entirely clear what the "right" path forward is. One suspects we may see more of these kinds of discussions over time.
Adopting DNSSEC
The Domain Name System (DNS) is an amazing technological achievement, but it suffers from a historical excess of trust, which makes it possible for people who rely on it to be lied to. The DNS Security Extensions (formally DNSSEC-bis, more usually just DNSSEC) are a mechanism for including robust trust information within the DNS. Here we discuss briefly what DNSSEC does, how it does it, and how (and whether) you can use it to secure your domains.
The problem
DNS is the distributed system that maps domain names to IP addresses; it is one the largest distributed databases in the world. However, its design dates back to an earlier era when there was more trust around; specifically, information propagated by the DNS is often cached, while only being validated by checking the IP address of the supplier.
There are at least two problems with this. First, just because a DNS packet comes from the configured resolver is not necessarily a good reason to assume the content is trustworthy. And second, because much DNS information is propagated via UDP, which makes spoofing sender IP addresses trivial, a DNS packet claiming to be from the configured resolver's IP address may not actually come from that resolver.
The fascinating field of security research has unearthed many ingenious attacks against cryptographic protocols, such as power analysis, which are elegant and effective but unlikely to be seen in quantity in the wild anytime soon. DNS spoofing, though, is widespread; it's easy to do, and lots of people are doing it, for all sorts of reasons.
In March 2014, Turkey blocked access to Twitter after recordings damaging to the Turkish government were leaked there. The country did this by instructing Turkish ISPs to return wrong IP address information when twitter.com domains were resolved, so that DNS would instead return IP addresses that took users to a government web page announcing the block. Turks quickly discovered that setting their DNS servers to foreign recursing resolvers such as Google's would bypass the block, and some went a step further by spray-painting the IP addresses of Google's DNS servers on public buildings. Other governments engage in similar practices on a routine basis.
The solution
It's been slow in coming, but DNSSEC is now pretty much here. It enables cryptographic signatures to be distributed in the DNS alongside existing information, so that resolvers that care about such things can ask for it; they can also rely upon the answers they get. This is done by defining a few new DNS Resource Record (RR) types:
- RRSIG: This one's the workhorse; it's a signature for an RR, made with the appropriate key pair. To verify the authenticity of some RR that has just been queried, whether it was an A record, an MX, a CNAME, or some other record, the accompanying RRSIG is the starting point.
- DNSKEY: This asserts one of the keys (yes, plural, we'll come to that) for a particular zone or subzone. This is something given out to the world for your own zone(s), much like an SSH server announcing its own public key on connection.
- DS: This is how trust is distributed. It's a fingerprint for the primary DNSKEY record, generated by the zone's parent (usually, the registrar) and distributed as part of the glue. Like any other RR, it also comes with an RRSIG record, also generated by the zone's parent. This is how people can trust your DNSKEY records when you return them in response to a query. Its existence also functions as a flag that DNSSEC extensions should be checked by a capable resolver for queries in the zone in question.
- NSEC3: It is as important to sign your negative responses as your positive ones, otherwise any attacker could simply sit there returning faked NXDOMAIN responses for queries about all your hostnames. NSEC3 provably says that no such RR exists, in such a way as to cover a range of possible name queries without enabling a brute-force search of the namespace.
Can I use it? Should I? How do I?
Not all top-level domains (TLDs) currently implement DNSSEC. Wikipedia's list of TLDs includes information on which do and do not support DNSSEC, but it's pretty widely supported, and if you're not doing registration in some obscure country-code TLD just to get a cute domain name, you probably can deploy DNSSEC.The following shows how I enabled DNSSEC on teaparty.me.uk by following a procedure which was developed from NLNetLabs' excellent HOWTO, to whose authors I am grateful. You will need to be using a BIND implementation that is DNSSEC-capable, but I'm using BIND 9.8.2 on CentOS 6, which is pretty old, and it works fine.
First, you have to generate your zone keys. Second, you have to include your keys in your zone file and sign your zone. Finally, you have to generate your DS record, and propagate it through your registrar.
So, first off, generate the keys. They come in two types: a key-signing key (KSK), which is used only to sign other keys, and a zone-signing key (ZSK), which is used to sign all the other RRs. These do not have to be different keys, but best practice is to use a different KSK and ZSK. Key lengths and algorithm choices are a matter for you to decide. Also, the choice between /dev/random and /dev/urandom is yours to make; my server has a hardware random-number generator (RNG) attached, without which this process might have taken some time. Note also that I do this in the parent of the directory that holds the zone files themselves, as I find it convenient to keep the keys there.
[root@lory dns]# dnssec-keygen -r/dev/random -f KSK -a RSASHA1 -b 2048 teaparty.me.uk
Generating key pair...............................+++ ..........................+++
Kteaparty.me.uk.+005+02104
[root@lory dns]# dnssec-keygen -r/dev/random -a RSASHA1 -b 2048 teaparty.me.uk
Generating key pair.....+++ .................+++
Kteaparty.me.uk.+005+60996
Here, the -b chooses the key length and the -a is used to
choose the cryptographic algorithm to be used.
The last line of the output in each case is the base name of the
key files, one ending .key and the other ending in
.private, which have just been created in the working
directory. The filename includes the zone name, the algorithm type (005=RSA/SHA-1),
and a five-digit random key identifier
which helps detect key rollovers (about which more
may be found here). Now, let's extract the meat, that being the
new keys, from those .key files we just created:
[root@lory dns]# grep DNSKEY *teaparty.me.uk*.key
Kteaparty.me.uk.+005+02104.key:teaparty.me.uk. IN DNSKEY 257 3 5 AwEAAdCM/LeSga8...
Kteaparty.me.uk.+005+60996.key:teaparty.me.uk. IN DNSKEY 256 3 5 AwEAAcQxmpGFwWw...
The keys in the above output have been truncated to avoid filling
your screen with gibberish. Note the leading 256 and 257 in the
DNSKEY RRs: an even number indicates a ZSK and an odd number,
a KSK. Your KSK is your zone's primary key, from which we will later
derive your DS record.
Next up is to put the two DNSKEY RRs into your zone file, then sign it with the keys you have just created. Signing is accomplished with the dnssec-signzone command:
[root@lory ~]# cd /var/named/chroot/var/dns/primary/
[root@lory primary]# /usr/sbin/dnssec-signzone -o teaparty.me.uk \
-f teaparty.me.uk.signed -K .. -k Kteaparty.me.uk.+005+02104.key \
-e +3024000 -N unixtime teaparty.me.uk Kteaparty.me.uk.+005+60996.key
dnssec-signzone: warning: teaparty.me.uk:8: no TTL specified; using SOA MINTTL instead
Verifying the zone using the following algorithms: RSASHA1.
Zone signing complete:
Algorithm: RSASHA1: KSKs: 1 active, 0 stand-by, 0 revoked
ZSKs: 1 active, 0 stand-by, 0 revoked
teaparty.me.uk.signed
First, I changed into the directory where the zone file is (in whose
parent, you will recall, the keys are kept). Then I signed the zone;
important flags include:
- -o specifies the zone origin (domain name); this can be inferred from the filename, but I prefer to keep it explicit.
- -f specifies the file that will contain the signed zone; I will need to alter my named.conf file so that the zone is taken from this signed file in future.
- -K specifies where to find key files.
- -k specifies the file containing the KSK.
- -e specifies the date until which I wish the signatures to remain valid. +3024000s is now + 35 days, which is designed to let me automate this signing with cron on the first of every month without the signatures ever expiring, even if the leap second people at the IERS decide to put quite a lot of extra seconds onto the end of any given month.
- -N specifies that the zone serial number (SN) in the new, signed zone file will be Unix time. I could use -N keep to preserve the SN from the input unsigned, zone file, but I prefer this.
The last step is to generate your DS record from your KSK. This has already been done by signing the zone; you will notice in the zone file directory a file called, in my case, dsset-teaparty.me.uk.. This contains a couple of potential DS records that differ only in the digest type being used ("1" versus "2") and thus also in the digest of the key itself:
[root@lory primary]# cat dsset-teaparty.me.uk.
teaparty.me.uk. IN DS 2104 5 1 1E8AB98D...
teaparty.me.uk. IN DS 2104 5 2 440A7FA1... 6F8640BE
This can also be done manually with the dnssec-dsfromkey
command, which can be fed either the zone file or the KSK file.
Although RFC 4034
says that having a DS record with digest type 1 (SHA-1) is
mandatory, RFC
4509 defines the digest type 2 (SHA256) digest, and specifies that
digest type 1 should be ignored if type 2 is present, in keeping with
the move away from SHA-1. Most people seem to publish only the SHA-256
(digest type 2) record, and this works well for me.
So I will give the digest type 2 record to my registrar through whatever mechanism it has decided is appropriate. For registrations in .uk I do it through Nominet's website, being a registrar myself; alternatively, one would go through one's registrar. For .com/.net/.org domains, which I register through an old friend, I email the DS record to him under cover of PGP, and he passes it up the chain of registrars until it gets to someone who can put it into the proper TLD zone file.
And is it working?
You can check for DNSSEC capability in your normal resolution chain by using dig +trace. Try:
$ dig +trace www.google.com
If you
see a bunch of RRSIG and DS records being returned in
the chain along with the more usual A and NS records,
you're DNSSEC-capable. If your normal resolution chain isn't capable,
try:
$ dig +trace www.google.com @8.8.8.8
That will show whether your
client is
capable and so configured. You'll need a DNSSEC-capable resolver to go
any further.
If I take a DNSSEC-capable resolver, such as Fedora 24's, using a capable resolution chain such as Google's public servers, and I ask for explicit signature checks, I should get confirmation that all is well:
$ dig +sigchase test.teaparty.me.uk @8.8.8.8
...
;; Ok this DNSKEY is a Trusted Key, DNSSEC validation is ok: SUCCESS
If I alter the RRSIG on my A record by one byte,
increment the zone's SN, reload the zone, and repeat the test, I should
get indication of a problem, ending with:
;; Impossible to verify the Non-existence, the NSEC RRset can't be validated: FAILED
The usual sources of error are cut-and-paste failings, publishing a DS record without a signed zone (recall that the presence of the record is the indicator that a zone should be signed), or major clock skew in your DNS server. The latter can cause problems because TTLs in DNSSEC RRs are absolute timestamps, unlike the relative TTLs of pre-DNSSEC RRs; if clocks are badly wrong, RRs that are already out-of-date can be propagated, and these will fail to validate.
So in summary, DNSSEC isn't complex; honestly, it's not. It's fiddly, to be sure; many small parts have to be assembled in the right order. But once this is done, it just works, to the net benefit of all. If you are in charge of any DNS infrastructure, and you haven't come to grips with this already, now might be a good time for you to tackle DNSSEC.
AMD's Display Core difficulties
Back in 2007, the announcement that AMD intended to reverse its longstanding position and create an upstream driver for its graphics processors was joyfully received by Linux users worldwide. As 2017 approaches, an attempt by AMD to merge a driver for an upcoming graphics chip has been rejected by the kernel's graphics subsystem maintainer — a decision that engendered rather less joy. A look at this discussion reveals a pattern seen many times before; the positions and decisions taken can seem arbitrary to the wider world but they are not without their reasons and will, hopefully, lead to a better kernel in the long run.
A quick timeline
Back in February, Harry Wentland posted a patch
set adding the new "DAL display driver" to the AMD GPU subsystem; this
driver, he said, would "allow us going forward to bring display
features on the open amdgpu driver (mostly) on par with the Catalyst
driver.
" It was not a small patch, adding 279 new source files
containing nearly 94,000 lines of code. That code saw little public
discussion and was never merged, though it has become clear that some
private discussion took place.
In March, Alex Deucher proposed that DAL should
be merged, saying that it was to be the core of the new display stack;
his goal was to get it into the 4.7 release. Graphics maintainer Dave
Airlie made it clear that this was not
going to happen, saying that: "I think people are focusing on the
minor comments and concerns and possibly deliberately ignoring the bigger
concern that this code base is pretty much unmergeable as-is.
"
His biggest complaint had to do with the overall design, which involved a
lot of abstraction code that tried to hide the details of working with the
kernel from the rest of the code.
Others echoed his concerns and, indeed, the code was not merged for 4.7 or
any other kernel released since then.
The current chapter began on December 7, when Wentland posted an RFC note saying that this code (now going
by the name "display core") was needed to support the next generation GPU
coming out of AMD. The company, he said, has based all of its efforts on
the display core code,
using it as the foundation for all of its quality-assurance work, its OEM
preloads, and more. And, he noted: "DC behavior mirrors what we do
for other OSes
". That last point is important; the display core
code helps the company maintain the driver across multiple operating
systems by hiding a lot of system-specific interfaces.
This time, Daniel Vetter complained about the abstraction layers in the code and described why they were not acceptable in the mainline kernel. Airlie responded more strongly, saying that this code would not be merged in its current form:
As one might expect, a certain amount of back-and-forth resulted; the AMD developers were not pleased by this response. It can only have felt like a slap to a group of developers who were trying to do the right thing by getting support for their hardware into the mainline kernel. Even so, they stayed with the discussion, which remained almost entirely civil, and which, in the end, seems to be leading to a viable path forward.
The trouble with midlayers
There are a number of complaints with the AMD driver code; it is not often that tens of thousands of lines of new code are free of problems. But the biggest issue has to do with the midlayer architecture. A midlayer, as its name suggests, sits between two other layers of code, typically with the purpose of hiding those outer layers from each other. In this case, for example, the display core code tries to hide the details of low-level hardware access, allowing the upper-layer driver to run on any operating system.
The kernel community has a long experience with midlayers, and that experience is generally seen as being bad. For an extensive discussion of the midlayer pattern in the kernel, this 2009 article from Neil Brown is recommended reading. A midlayer architecture can bring a whole raft of long-term maintainability issues in general; the graphics developers are also concerned about some more specific issues.
The idea behind AMD's midlayer is to abstract out the Linux-specific details in the driver. That may be desirable for somebody trying to maintain a cross-platform driver; it also helps the AMD developers get the Linux driver working before the hardware engineers move on to the next product and stop answering questions. But code structured in this way is painful for people trying to maintain the Linux kernel. Understanding higher-level code becomes harder when that code does not follow the normal patterns used by graphics drivers; that can be hard for maintenance in general, but it can become a severe impediment to any sort of refactoring work. As Airlie put it:
A hardware abstraction layer must be maintained to meet the needs of code for other operating systems — code that the Linux kernel developers cannot see (and probably don't want to). In effect, that means that nobody outside of the originating company can touch the midlayer code, making community maintenance impossible. If members of the community do try to patch the midlayer — often to remove code that, from the kernel's perspective, is redundant — they will run afoul of the driver maintainers, who may well try to block the work. If they are successful in doing so, the result is code in the community kernel that is essentially off-limits for community developers.
Functionality placed in a midlayer, rather than in common code, has a high likelihood of developing its own behavioral quirks. As a result, drivers using the midlayer will behave differently from other drivers for similar hardware, often in subtle ways. That creates pain for application developers, who no longer have a single driver interface to work with.
A midlayer will also tend to isolate its developers from the common core code. The midlayer will be fixed and improved, often to work around shortcomings in the common layer, rather than improving the common layer itself. Kernel developers would rather see that effort going into the common code, where it benefits all users rather than one driver in particular. Developers who work on this support code have a say in the direction it takes, while developers who work on a midlayer generally do not. So things tend to diverge further over time, with the driver developers feeling that the core is not developed with their needs in mind.
Finally, midlayer-based code has a certain tendency to get stuck on older
kernel versions; indeed, the current display core code is still based on
4.7. That makes it hard to maintain as the kernel goes forward. In this
case, Vetter summarized this aspect of the
problem by saying: "I think you don't just need to demidlayer DAL/DC,
you also need to demidlayer your development process.
" Code
intended for the mainline needs to be developed and tested against the
current mainline, or it will inevitably fall behind.
The way forward
Regardless of how one views the odds of seeing the Year of the Linux Desktop in the near future, it seems certain that those odds can only be worse in the lack of AMD GPU drivers. The blocking of such a driver — otherwise on track to be in mainline before the hardware ships — thus looks like a step backward for a subsystem that has already struggled to gain support for current hardware.
Chances are, though, that this standoff will be resolved more quickly than people might expect. The AMD developers were not unaware of the problems and, it seems, not unwilling to fix them. Deucher said:
Some work has indeed been done since the early posting of this patch set; and, it is said, about one-third of the midlayer code is gone. Vetter made it clear that this work had been seen and appreciated:
The code that had been removed so far is,
naturally enough, the easiest third to take care of; getting rid of the
rest of the midlayer will require some significant refactoring of the
code. Vetter provided a roadmap for how
that work could be done; Wentland and AMD
developer Tony Cheng agreed that the path
seemed workable. Wentland acknowledged that things could have been done
better at AMD, saying: "We
really should've started DC development in public and probably would do
that if we had to start anew.
"
Actually getting all that work done may take a while; it must
compete with other small tasks
like making the driver actually work for existing and upcoming hardware.
One might conclude that what we are really seeing here is a negotiation over just how much of this work must be done before the code is deemed good enough that the rest of the fixes can be done in the mainline. Maintainers tend to worry about giving way in such situations because, once they have merged the code, they have given up their strongest leverage and can find that the developers become surprisingly unmotivated to finish the job. Arguably, that is a relatively unlikely outcome here; AMD has been trying to improve its upstream development for nearly a decade and its developers know what the rules are.
The most likely outcome, thus, is that this driver is delayed for perhaps a few more development cycles while the worst problems are taken care of and some sort of convincing story exists for the rest. Then it will be welcomed into the kernel as a welcome addition to mainline support for current hardware, and users worldwide will have something to celebrate. The Year of the Linux Desktop, unfortunately, may be a little slower in coming.
Page editor: Jonathan Corbet
Inside this week's LWN.net Weekly Edition
- Security: ModSecurity for web-application firewalls; New vulnerabilities in jasper, kernel, mozilla, roundcube, ...
- Kernel: 4.10 Merge window; A way forward for BFQ; LPC Android microconference.
- Distributions: Debian considering automated upgrades; CentOS, KDE Neon LTS, OLPC, ...
- Development: An update on the Linux Test Project; Krita, LLVM, Nextcloud, ...
- Announcements: KDE e.V. Community Report, ...