
LWN.net Weekly Edition for May 7, 2015
FontForge and moving forward
The annual Libre Graphics Meeting conference provides a regular update on the development of a number of free-software applications for visual graphics and design work. At this year's event in Toronto, one of the most talked-about sessions was Dave Crossland's take on the future of FontForge, the free-software font-editing tool.
Despite all of the progress that FontForge has made in the past few years, he said, recent developments have convinced him that the momentum lies elsewhere. In particular, newer projects started by dissatisfied FontForge users are likely to close the feature gap, and the type-design community seems more interested in engaging with those efforts. Perhaps predictably, that assessment of the current state of affairs sparked quite a bit of discussion—including a debate on the relative merits of desktop versus web-based applications.
Crossland began by recounting his personal experience with FontForge. He discovered the project while studying graphic design in college, and subsequently used it during his graduate work in the University of Reading's type-design program. Needless to say, virtually every other student used one of the proprietary, commercial font-design applications instead, and FontForge proved difficult to use in a number of ways.
![[Dave Crossland at LGM 2015]](https://static.lwn.net/images/2015/05-lwn-crossland-sm.jpg "Dave Crossland")
It was after that experience that Crossland got directly involved in FontForge's development. Working with Google's Web Fonts office (which exclusively uses open fonts and relies on an open-source toolchain) he was able to fund some contractors to improve FontForge. He personally underwrote additional development with his share of the proceeds from Crafting Type, a series of type-design workshops that he co-hosted.
The workshops used FontForge, and the development work that they prompted led to important bug fixes and new features (such as collaborative editing). They also led to a significantly improved packaging situation for Windows and Mac users. Nevertheless, even after several hundred students went through the workshops, only a tiny fraction of them stayed with FontForge (in the post-talk discussion, Crossland estimated the number was in the single digits).
FontForge's technical debt was clearly a problem. The application had been initially developed as a one-off project by a developer who later lost interest and left the project. Although it more or less worked, the code was not organized in a way that let new developers get involved, it contained a lot of hard-coded designs that were hard to change, and relied on a custom widget set that was difficult to maintain.
Crossland cited one example for reference: when users asked that a certain text-entry box be made elastic in size rather than fixed-width (so it could expand to fill the available horizontal space), implementing the change took more than three hours. That was far from an ideal situation, but, he said, it also shed light on a deeper problem: users would not stick with the project and help make FontForge better because contributing small design patches or even observational notes was difficult to impossible.
Freedom to compete
Meanwhile, a growing collection of new free-software font editors was cropping up, the vast majority of which are implemented as web applications. He cited four in particular: Typism, Fontclod, Prototypo, and Glyphr Studio. These web-based tools are not as full-featured as FontForge, he said, but they are developing at a rapid clip and, even more importantly, they are attracting considerable input and involvement from working type designers.
Thus, when Crossland got involved with the Metapolator project (a whole-font-interpolation program that can be used, for example, to rapidly generate multiple weights from one font), he pushed that team to adopt a similar model: build a web-based application, and solicit input from type designers. That strategy has been successful enough, he said, that he decided he cannot justify making further contributions to FontForge.
The latest round of FontForge development has given the application robust support for importing and exporting the Unified Font Object (UFO) interchange format. Soon, users will be able to create a basic font in FontForge, interpolate its weight and other properties in Metapolator, then perform any additional tweaks in FontForge.
But he expects Prototypo, Glyphr Studio, and other UFO editors to catch up to FontForge's functionality; that and the already existing ecosystem of open-source UFO scripts and utilities (most of which originate from users of other, proprietary font editors) may make FontForge irrelevant. "It seems like a lot of people want a free-software font editor and get so frustrated with FontForge that they leave and start their own," he said in summary. "Maybe we need to work on 'conservation' of FontForge rather than 'restoration' work trying to turn it into a modern editor."
Moreover, the web-based applications have demonstrated an ability to draw end users into the development and design process—something that desktop applications rarely, if ever, achieve. One of the ultimate goals of free software's "four freedoms" is to enable the user to participate in development, Crossland said. The newer, web-based font-development applications can do so in a way that FontForge has never been able to. JavaScript and CSS are easier to understand and tweak than are C and C++.
Feedback
At the end of the session, a number of audience members took issue with what they interpreted as advice from Crossland for developers to stop working on FontForge. For example, one audience member noted that he had looked at Glyphr Studio and found it to be far behind FontForge in terms of its supported features.
Another audience member suggested that if a shortage of contributors was holding FontForge back, then the project should figure out what it needs and run a public crowdfunding campaign to raise support. Crowdfunding is an approach that has been increasingly successful for free-software graphics applications of late, and Crossland had mentioned successful Kickstarter drives by the competing web-based font editors in his talk.
To those points, Crossland responded that the technical debt of FontForge is beyond what a crowdfunding campaign can raise to fix, and that the web-based editors may be behind today, but are catching up quickly. Furthermore, he added, C-based desktop applications still separate users and developers into disjoint classes. Type designers are required to learn CSS and JavaScript as part of their jobs, so they can easily get involved with web-application development. "The ideal cultural impact of software freedom is co-creation. We want a proactive culture of design and development, and I don't think traditional desktop software is the ideal way to create that."
Øyvind "Pippin" Kolås from GIMP then disagreed strongly with the notion that web-development languages could compete with C and C++. CSS and JavaScript user interfaces rely on levels of abstraction to keep things simple, he said; the core development underneath is just as complex in a "web stack" as it is in native code.
It is easy to get started writing something new (regardless of the development platform); but over time, he said, web applications will become just as complicated as native ones—if not worse, given the abstraction layers required. Thus, ditching FontForge in favor of partially completed web applications—just to solicit UI patches from type designers—is throwing the baby out with the bathwater. The community has something that works now, while the alternatives do not do much of anything by comparison.
Crossland replied that he was not trying to make a blanket statement about native development, much less telling anyone to stop working on GIMP, Scribus, or other desktop tools. He conceded Kolås's point about the underlying complexity of applications, regardless of the programming stack. He would also be happy to see others push FontForge development forward, he added; he just cannot justify it for himself. As time on the clock was running out, FontForge developer Frank Trampe cheerfully assured the crowd that he was continuing to contribute to the project, which got a round of applause.
Because the session was the last talk of the day, the discussion carried over into the evening event that followed. Ultimately, most people seemed to come away with a clearer understanding of the distinct points under debate, which were a bit conflated at the outset. The size and scope of the technical debt in FontForge is one issue; the broader competition between web-development and native application stacks is a separate one. Crossland later posted a FAQ entry on the Metapolator wiki to explain his concerns and Kolås's, together and in more detail.
The larger question about if or when a project accumulates too much technical debt to be manageable was one that resonated with a lot of attendees at the event. There were, in fact, several other web-based applications on display in the other sessions, some of which are taking on established free-software desktop application projects. Technical debt and support problems for aging code can plague any project; no one seems to have a silver bullet.
It was also noted in the discussion that web and desktop programming platforms have begun to overlap in a number of ways. GNOME Shell is scripted in JavaScript, for example, while GTK+3 and Qt's QML both rely on CSS-like styling. On the other hand, Mozilla and Google are both exploring approaches (such as asm.js and Native Client) that bring C and C++ to web applications. As hard as it may be to predict where FontForge and Glyphr Studio will be in a year's time, it is clear that the tug-of-war between desktop and web development is far from over.
A Libre Graphics Meeting showcase summary
Every year, there are a variety of talks at Libre Graphics Meeting that showcase entirely new work. While these new-project sessions frequently highlight still-in-development ideas or code that may not be quite ready for packaging and mass distribution, they are always a fascinating counterpoint to the progress reports from established application projects. At this year's event, the new projects showed off work designed to help crowdsource image collection, to do desktop publishing with HTML, and to transform 3D meshes into 2D images and back again.
The List
Matt Lee, technical lead at Creative Commons, introduced The List in a session on the first day of the event. The List is, in essence, a social-networking system in which users post public requests for images, and other users respond by posting matching images—images they have created from scratch, photographs they have taken, physical artwork they have scanned, and so forth. The project uses a free-software Android app as its interface, with an iOS app to follow shortly.
![[Matt Lee at LGM 2015]](https://static.lwn.net/images/2015/05-lgm-lee-sm.jpg "Matt Lee")
The crux of the problem that The List sets out to solve is that everyone needs images to communicate, but few people have the skills to create high-quality imagery (even among people for whom open content is a priority). The main example Lee discussed was contributions to Wikipedia; his talk was (not coincidentally) scheduled right after one from a Wikipedia volunteer who described that project's efforts to generate higher-quality SVG illustrations.
The app was developed with support from the Knight Foundation, and ultimately aims to be useful for a range of purposes, including collecting images for journalists, non-profits, and cultural institutions. The goal is a lofty one; harnessing the collective power of crowds to find obscure or out-of-print cultural works, for example, is arguably a higher calling than filling in missing photographs of buildings on Wikipedia. Creative Commons also plans to use The List app as a means to explain the values behind Creative Commons itself: at first startup, users are given a walkthrough of Creative Commons licenses before they are presented with the categorized list of requested images.
At the end of the talk, Lee outlined several of the challenges facing the project team. Internationalizing the requests for images is a hard problem, he said, relying as it does on human language and cultural context. There is also concern about whether or not the average smartphone camera will produce photos good enough to meet the needs of the people making image requests. The List's backend is not limited to smartphone photos, of course (all of the uploaded images are stored at The Internet Archive, which can handle essentially any file type). A web or application-based interface could easily allow the upload of other image types. The future of The List may include support for these other upload types—among other features, like enabling the device's geographic location to alert the user to nearby image-taking opportunities.
Finally, there is the question of image and request moderation. Balancing the desire for an open community with the Internet's tendencies for attracting trolls is a difficult challenge, to be sure. But it is one that Creative Commons, Wikipedia, and the Internet Archive have all worked at maintaining for several years now.
html2print
On the second day of the conference, Stéphanie Vilayphiou of Open Source Publishing (OSP) presented a talk about html2print, its tool for doing print-ready page layout using HTML and CSS. Printable web documents are not a new idea, of course, but many of the contemporary projects rely heavily on the HTML5 <canvas> element. That makes the resulting output more like a drawing than a text document: individual elements are not accessible through the document object model (DOM), and there is no separation between the code and the design.
![[Stéphanie Vilayphiou at LGM 2015]](https://static.lwn.net/images/2015/05-lgm-html2print-sm.jpg "Stéphanie Vilayphiou")
Html2print relies on some lightweight CSS tools (such as the preprocessor LessCSS). It defines page dimensions (including paper size and margins) as CSS properties, so that they can be adjusted and inspected easily, and allows the creation of re-flowable text elements using CSS Regions. It even allows the user to define CMYK spot colors as separate "inks" that can then be "mixed" in individual elements (e.g., 40% of chartreuse_1 and 15% eggshell_2). That feature is particularly useful for print work, because by default HTML and CSS only support RGB color at 8-bit-per-color granularity.
OSP likes to use collaborative editors like Etherpad for all of its projects, and html2print is designed to support that. It lets multiple users edit a large project simultaneously. It also supports what she called "responsive print" (a reference to responsive web design). She showed a demonstration using a booklet project: resizing the page-size parameters automatically adjusts other properties (like font size) to match. Large-format, book-like dimensions trigger a lot of text per page, while scaling the page dimensions down to pocket size proportionally scales the text so that its printed size will remain readable.
Vilayphiou explained a few of the challenges that OSP had to tackle along the way, such as implementing a new zoom tool. Relying on the web browser's zoom function was a bad idea, she said, because zooming invariably triggers a re-render operation, which often causes difficult-to-fix artifacts. The zoom tool was more or less a solved problem, she said, but others have proven trickier—such as the inherent instability of the various browser engines. Two years ago, for instance, Chrome worked perfectly, but then the project dropped WebKit for its own Blink engine and discontinued support for CSS Regions.
Vilayphiou closed out the session by noting that html2print does not yet have a proper license attached, which she said was simply an accident. She encouraged anyone with interest in preparing print documents for publication to take a look and offer feedback, although at this stage new users might need to set time aside to learn their way around the tool.
Embedding 3D data in 2D images
![[Phil Langley at LGM 2015]](https://static.lwn.net/images/2015/05-lgm-langley-sm.jpg "Phil Langley")
Architect Phil Langley presented what he called a "digital steganography" project in his session on day three. Steganography is often associated with hiding information, he said, but the term originally just referred to embedding one message inside another. The most common example is encoding a string inside the least-significant bits of an RGB image, but Langley showed several other real-world techniques, such as an audio track embedded in a photograph, and concealing one text message within another. He also noted that depth-map images such as those produced by the Microsoft Kinect camera are actually encoding 3D data in a 2D form.
That final example leads into the project that Langley undertook. A course he teaches at the Sheffield School of Architecture involves advanced 3D modeling, and he recently set up a Twitter bot to send out status reports as the software progressed through its calculations. The trouble was that tweets are only 140 characters long, which is hardly enough to explain progress in detail. So the team set out to hack a solution that used a different feature instead. Twitter allows large images to be attached to Tweets, so the team looked for a way to encode their 3D meshes as 2D images.
The initial attempt was fairly straightforward. Each face of a typical 3D model is a triangle, and each vertex of that triangle includes three coordinates (x,y,z). They tried mapping the (x,y,z) triples to RGB values, thus using three pixels to represent each triangle. While this worked, it did not provide much resolution: 8-bit-per-channel graphics allowed just 256 units in each spatial dimension, which is quite coarse.
![[A 3D mesh and corresponding
2D PNG]](https://static.lwn.net/images/2015/05-lgm-3D-sm.png)
After further refinement, they settled on a plan that used the 24 bits of an RGB pixel to encode vertex coordinates more efficiently. The 3D model is first sliced into thin horizontal bands; each band has far fewer units in the z direction, so more resolution is available for the x and y coordinates. Furthermore, the resulting image somewhat resembles a 2D projection of the model.
This encoding scheme allowed the class's Twitter bot to generate and send PNG images that could quickly be converted into 3D models. The compression ratio was impressive, too: Langley showed a 6.7KB PNG image that represented a 156.8KB file in the STereoLithography (STL) format.
![[Mesh manipulated in GIMP]](https://static.lwn.net/images/2015/05-lgm-mesh-sm.png)
But that was not the end of the experimentation. Once the image-based format was working, Langley and the students started experimenting with altering the PNGs in GIMP and other image-editing tools. Some image transformations would have a predictable effect on the resulting 3D model (such as stretching or compressing), while others were more chaotic. There were practical uses to treating the models as 2D images, too—Langley showed a tool that graphed the changes in a model over time by plotting each step's 2D image together in a sequence.
These three sessions might not be described as a representative sample of LGM 2015, consisting, as they do, of such wildly different projects. But they do provide a glimpse into what makes the conference interesting every year. Html2print has clear application for those in the publication-design field, while Langley's 3D-to-2D object transformation is notably more experimental, and The List presents an interesting new take on consumer-grade content creation. Together, they are nothing if not thought-provoking.
Video editing and free software
Two talks at the 2015 Libre Graphics Meeting in Toronto came from video-editing projects. One was an update from Natron, a relatively young project that deals with video compositing, while the other was a reflection on ten years' worth of development on the general-purpose non-linear editor (NLE) Pitivi. Both are active projects, but they take two markedly different approaches: one aims to support an existing industry standard, while the other must build its core functionality from the ground up.
Natron
Alexandre Gauthier-Foichat gave the first report of the two, describing progress in the Natron visual effects (VFX) compositing application. Gauthier-Foichat began with a brief discussion of the project's background: it is developed at the French Institute for Research in Computer Science and Automation (INRIA), which means "it is funded by people's taxes," and the team consists of developers, a vision scientist, and several visual effects artists, among others.
![[Alexandre Gauthier-Foichat]](https://static.lwn.net/images/2015/05-lgm-natron-sm.jpg "Alexandre Gauthier-Foichat")
Natron's 1.0 release was made in December 2014, and the project has attracted considerable attention in recent months—presenting at SIGGRAPH and other conferences. In January, it won a "best innovation" award at the inaugural Paris Images Digital Summit. Gauthier-Foichat gave a preview of what has been happening on the development side—work that is expected to be released as Natron 2.0 by the end of May.
Natron provides a node-based editing environment in which users can visually construct a effects pipeline (by connecting processing nodes on a canvas) that is then used to process video. It implements an industry standard plugin interface called OpenFX that is supported by a wide variety of other VFX applications. That well-supported standard helps Natron gain acceptance, and not just through compatibility with other applications' plugins. The reality of large productions like television and movies requires small VFX studios to collaborate and exchange data, so many of the studios write their own scripts and tools to be compatible with OpenFX, too.
![[Node editing in Natron 2]](https://static.lwn.net/images/2015/05-lgm-natronnode-sm.png)
For the upcoming 2.0 release, the Natron team has reworked the user interface, in particular making the node-connection window easier to use. The team also spent a lot of time talking to VFX artists, who began bringing feature requests to the project as Natron grew in popularity. The number one request, he said, was for "interaction with 3D," but it took considerable research to narrow that request down into a specific feature set. Natron 2.0 will feature 3D support in the form of interaction with Blender, allowing users to place depth into the arrangement the images and clips that make up their scene, rather than treating all of the scene elements as flat pieces on the same plane.
It will also add new scripting features. Python scripting (using Python 3) will be supported, but not just for automating tasks. The new version will be the first to feature scriptable nodes—meaning that a video element can be manipulated by custom code in the middle of a processing pipeline. Natron's implementation will adhere to another widely used industry standard, SeExpr.
He showed several examples of SeExpr scripts in action, including an interactive lighting tool that lets users move illumination sources around the screen and immediately see updated results—without having to re-run the rendering process. Pixar offers a similar tool called LPics, he said, but Natron does the same thing in just a few lines of code. Still more work is yet to come, including G'MIC filter support and support for CUDA hardware acceleration.
Pitivi
Jean-François Fortin Tam presented the second of the talks, about the GTK+-based NLE Pitivi, which recently passed its tenth birthday.
![[Jean-François Fortin Tam]](https://static.lwn.net/images/2015/05-lgm-pitivi-sm.jpg "Jean-François Fortin Tam")
Ten years is a noteworthy milestone, Fortin Tam pointed out. Free-software NLE projects have a habit of starting strong then dying out; he showed a timeline graphic that depicted the rise and fall of many other free-software NLEs over the past decade. NLEs have developed their own form of the classic pick any two conundrum, he said: users can choose a subset of "soon," "cheap," and "complete" but they cannot have all three. "You can get something fairly usable, but if you want it in the next decade, you need to pay people to work on it."
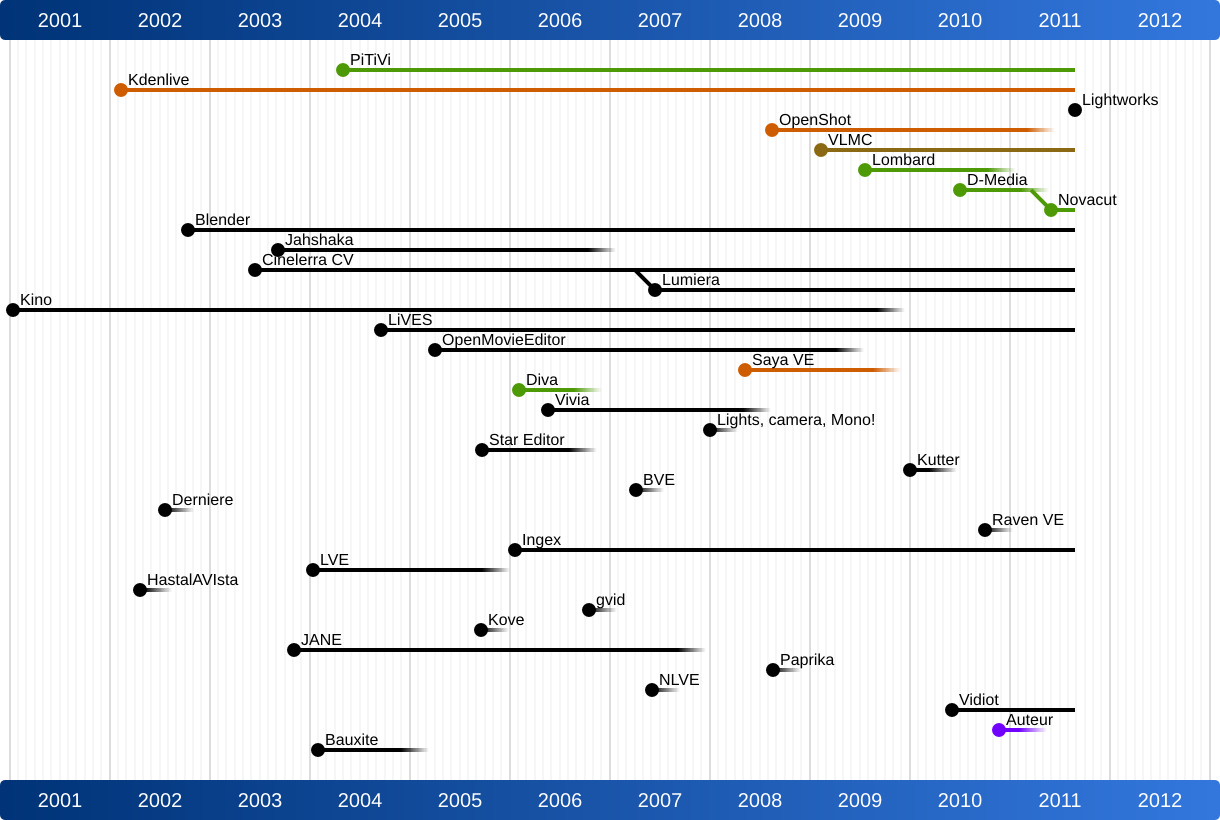{kind=link}
This is a problem, he said, because there is ultimately no business model that supports building a free-software NLE. Even a successful Kickstarter campaign can only generate enough funds to pay "a McDonald's salary" for three to six months. The reason is that less than one percent of computer users use Linux, and of those less than one percent use NLEs. As if one percent of one percent wasn't bad enough, he estimated only a fraction of that number would ever donate more than a dollar toward development.
But financing is not the only hurdle. There are "DevOps challenges" facing an NLE project, too. Regardless of whether they are paid or not, most teams are only one to three people, which is nothing compared to the hundreds employed by each proprietary NLE company. Furthermore, he said, technology making up the development platform keeps changing in front of you.
He then played a clip from the ending of Rambo III on which Pitivi-related dialog had been superimposed. In Fortin Tam's version of the scene, two protagonists on foot are congratulating each other on having completed a port to GStreamer Editing Services, only to be surprised by the arrivals of an ever-increasing horde of armed adversaries in tanks and helicopters—who are labeled "GTK+3," "GObject Introspection," "GStreamer 1.0," and so on—and demand that they "throw down their old libraries" in surrender. Keeping up with the pace of the desktop application stack, it seems, is not easy for Pitivi's small team. The code has undergone several rewrites in its ten-year history.
Then again, he continued, the video industry changes rapidly, too. Ten years ago, capturing video from external analog and digital sources was critical; today it is ancient history. High-definition has given way to 4K, 8K, and 3D video in rapid succession, and users get mad when their HD movies take more than five minutes to render. "When I was young," he said, "I was happy if it took less than a day." On the plus side, users "no longer have to take out a mortgage" to make a quality movie, and computing power has "gone through the roof."
The big question is how a project like Pitivi can make forward progress under such circumstances. Fortin Tam said that the project's strategy is to focus on enhancing the core, not the user interface. The next release will "finally kill off" GNonLin (the NLE library that originated in the GStreamer project) in favor of a new, integrated editing layer. Design flaws in GNonLin have held back the Pitivi core for years, and the project finally decided that fixing the library was not possible.
Moving forward, he said, Pitivi has to ignore legacy support issues (such as external capture), and focus solely on the modern video-editor workflow. It has to ignore the frequent calls for collaborative-editing features as well, he said. People often say they want it, but when one surveys working NLE users, no one uses collaboration features in other products.
The project also needs to focus on being a storytelling tool, he said, and not try to be every part of the production workflow from caption editor to VFX compositor to render farm. That means adjusting to the notion of being part of a "creative suite" of applications that the users will use, he said—like making sure Pitivi works with Natron. There are still technical features that need addressing, like color management and hardware acceleration, he said. But while the future may hold amazing new features, too ("3D video, holograms, and ponies," he said), focusing on letting users tell their stories is what will make Pitivi relevant for the next ten years.
One topic that Fortin Tam did not directly address in his talk was the influence that Blender has on the various efforts to develop an NLE. Like it or not, Blender has steadily expanded the scope of its built-in toolset, which has had the side effect of stealing away a large number of Linux NLE users. The talk schedule for the week included several sessions led by video artists describing their work; the vast majority use Blender for editing and exporting their output.
Video is a rapidly changing area for software developers. Natron has grown into a popular and stable application in a short amount of time (a bit less than two years). But it also has the advantage of sticking to the widely used OpenFX specification—so it gains a lot of functionality for free, so to speak—and it has a larger potential user base by virtue of being cross-platform. Pitivi does not have either luxury; after ten years and several under-the-hood rewrites, the project may finally have found a solid footing on which to build—but it will still be a challenge.
Security
SpamAssassin 3.4.1 released
One occasionally sees articles suggesting that the volume of spam on the net is in decline, but nobody would be foolish enough to argue that the spam problem has gone away. Industrial-strength spam-filtering tools are still a necessity for anybody whose email address is known by more than about two other people. For the minority of us who have not given in and moved to Gmail, SpamAssassin tends to be the spam-filtering tool of choice. In recent years it sometimes seems like the spammers are moving more quickly than the SpamAssassin project, so the announcement of the Apache SpamAssassin 3.4.1 release on April 30 — the first in over a year — is naturally of interest. A version-number bump from 3.4.0 to 3.4.1 would not seem to indicate major changes, but, in truth, the SpamAssassin developers have been busy.The "auto whitelist" (AWL) feature of SpamAssassin has long been one of that program's more annoying aspects. In theory it tracks the emails from each sender to get an overall sense of whether they are trustworthy; email from a trusted source will get a bonus score, while messages from apparent spammers will be penalized. The sad truth of the matter, in your editor's experience, is that a spammer need only get a small number of messages through to convince the AWL that everything else should be whitelisted. If SpamAssassin's other scoring mechanisms were perfect, this kind of AWL corruption would not be a problem — but then the AWL would not be needed at all. In a world where scoring is imperfect, the AWL often seems to make things worse.
In 3.4.1, the SpamAssassin developers have tried to address some of the problems with the AWL by replacing it with a new mechanism called TxRep. The basic idea remains the same: track each sender's activity and adjust the score of new messages toward the mean of what has been seen in the past. But a number of useful changes have been made in how this tracking is done, starting with an expansion of the set of data that is used. TxRep maintains reputation scores for the sending email address (as did the AWL), but also the sending domain name, the IP addresses of the originating system and the server that transferred the message, and the "HELO" string used by the last server. For any given message, each of these quantities is mixed in with its own (user-configurable, naturally) weight.
Another useful change is that the sa-learn utility (until now used only with the Bayesian filter) can be used to train TxRep, so the same command now works to update both filters. There is a "dilution" mechanism that causes newer messages to have more influence on a sender's score than older ones, making the system more responsive should, say, a spammer repent and start actually sending useful stuff (or should TxRep initially misjudge a sender). TxRep can be used to whitelist (or blacklist) senders or IP addresses outright — something that might be worth doing automatically for the most obvious of spam or for messages that have been explicitly classified by the recipient. There is also a mechanism to automatically whitelist the recipients of outgoing mail — though that could have undesired effects if one is prone to sending irate responses to spammers.
With these changes, TxRep should be able to avoid some of the worst AWL pitfalls, though the documentation still recommends against turning on auto-learning until SpamAssassin as a whole has been tuned well. But the whole thing still seems to be built around the idea that people can be spammers part of the time and senders of legitimate email at others. Perhaps your editor is an excessively unforgiving character, but it seems like the sender of known spam should not get off lightly with a gradual tweaking of a reputation score; once a spammer, always a spammer. Trust is hard to earn but easy to lose; the TxRep mechanism still doesn't quite reflect that fact.
The PDFInfo module, which has long existed outside of the SpamAssassin mainline, has now been merged; PDFInfo, as its name would suggests, looks for spammy PDF attachments. There is one other new module, URELocalBL, which allows blacklisting of spammy links using a local database.
SpamAssassin 3.4.1 can do a more thorough and careful job of normalizing all messages to the UTF-8 character set before applying rules. That should help to eliminate various tricks using strange character sets to get around the spam-checking rules.
An interesting addition to the Bayesian filter is the ability to hash MIME
attachments and use the result as a filter token. If it works well, it
should allow the filter to recognize often-repeated spam payloads as a
whole. But, as the manual
page notes, "not much experience has yet been gathered regarding
its usefulness
". It seems worth a try, in any case.
Beyond all of this work, of course, is the constant challenge of maintaining the rule base in the face of a changing spammer landscape. Spammers may now be more concerned with getting past Gmail's filters than SpamAssassin, but there are still signs that a subset of spam has been tested against SpamAssassin until the rules are unable to stop it. The Bayesian filter helps with that problem, but so does an ongoing effort to keep those rules current. It is thus unsurprising that a new SpamAssassin release contains a long list of rule changes that should help to keep its effectiveness up — until the spammers work around those as well.
Your editor has often heard the complaint that email is reaching a point of complete uselessness. Such claims overstate the reality — one need only watch how email keeps our development communities going to see that. But email has been under attack for many years, making life harder for both email users and those who are charged with running email systems. It is fair to say that SpamAssassin is one of a small set of tools that has helped email to survive the ongoing spammer onslaught, so it is good to see this tool continuing to evolve.
Brief items
Security quote of the week
On the other hand, plans to try use those sharp sticks and prods to try bully these sites into the https camp like cattle -- well, if you think the world has a mixed view of technologists now, if Mozilla gets its way we'll end up with a positive rating on par with politicians -- if we're lucky.
I very much want to see an Internet where all communications are securely encrypted, but only if it's done the right way, with sites and users treated as valued partners with a full understanding of their resource constraints and sensibilities -- and not as "losers" to be treated with what amounts fundamentally to arrogant contempt.
Unboxing Linux/Mumblehard: Muttering spam from your servers (WeLiveSecurity)
WeLiveSecurity reports that ESET researchers have revealed a family of Linux malware that stayed under the radar for more than 5 years. They are calling it Linux/Mumblehard. "There are two components in the Mumblehard malware family: a backdoor and a spamming daemon. They are both written in Perl and feature the same custom packer written in assembly language. The use of assembly language to produce ELF binaries so as to obfuscate the Perl source code shows a level of sophistication higher than average. Monitoring of the botnet suggests that the main purpose of Mumblehard seems to be to send spam messages by sheltering behind the reputation of the legitimate IP addresses of the infected machines."
Mozilla: Deprecating Non-Secure HTTP
The Mozilla community has declared its intent to phase out "non-secure" (not encrypted with TLS) web access. "Since the goal of this effort is to send a message to the web developer community that they need to be secure, our work here will be most effective if coordinated across the web community. We expect to be making some proposals to the W3C WebAppSec Working Group soon."
New vulnerabilities
ax25-tools: denial of service
| Package(s): | ax25-tools | CVE #(s): | |||||||||
| Created: | April 30, 2015 | Updated: | May 6, 2015 | ||||||||
| Description: | From the Fedora advisory:
Fixed crash when processing ROSE packets (by rose-fix patch) | ||||||||||
| Alerts: |
| ||||||||||
clamav: multiple vulnerabilities
| Package(s): | clamav | CVE #(s): | CVE-2015-2170 CVE-2015-2221 CVE-2015-2222 CVE-2015-2668 | ||||||||||||||||||||||||||||||||||||
| Created: | May 4, 2015 | Updated: | May 13, 2015 | ||||||||||||||||||||||||||||||||||||
| Description: | From the Arch Linux advisory:
CVE-2015-2170 (denial of service): A flaw has been found in the UPX decoder with crafted files. During unpacking there are two range checks which are implemented "manually". Those checks lack the detection of overflows which are considered by the CLI_ISCONTAINED() macro. CVE-2015-2221 (denial of service): Y0da cryptor / protector is a PE file encryptor - the executable file is decrypted on start up. Clamav is able to decrypt such files in order to scan them. As part of the decryptor there is an op code emulator. A special crafted file may contain a jump op code to a position that already has been interpreted - which leads to an endless loop. This leads to an endless loop in clamav itself. CVE-2015-2222 (denial of service): Petite is a tool for compressing PE files on windows. Clamav is a virus scanning tool which is able to unpack such files during scanning. Once the file has been identified as "petite" compressed before the decompressing process is started it is possible that a specially crafted file tells clamav to read more data than it allocated memory. On glibc it leads to SIGABRT on free() since glibc's malloc() recognizes this. CVE-2015-2668 (denial of service): A flaw has been discovered that is leading to an infinite loop condition on a crafted "xz" archive file. | ||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||
curl: information leak
| Package(s): | curl | CVE #(s): | CVE-2015-3153 | ||||||||||||||||
| Created: | April 30, 2015 | Updated: | May 28, 2015 | ||||||||||||||||
| Description: | From the Debian advisory:
It was discovered that cURL, an URL transfer library, if configured to use a proxy server with the HTTPS protocol, by default could send to the proxy the same HTTP headers it sends to the destination server, possibly leaking sensitive information. | ||||||||||||||||||
| Alerts: |
| ||||||||||||||||||
DirectFB: two vulnerabilities
| Package(s): | DirectFB | CVE #(s): | CVE-2014-2977 CVE-2014-2978 | ||||||||||||||||||||
| Created: | April 30, 2015 | Updated: | January 23, 2017 | ||||||||||||||||||||
| Description: | From the CVE entries:
Multiple integer signedness errors in the Dispatch_Write function in proxy/dispatcher/idirectfbsurface_dispatcher.c in DirectFB 1.4.13 allow remote attackers to cause a denial of service (crash) and possibly execute arbitrary code via the Voodoo interface, which triggers a stack-based buffer overflow. (CVE-2014-2977) The Dispatch_Write function in proxy/dispatcher/idirectfbsurface_dispatcher.c in DirectFB 1.4.4 allows remote attackers to cause a denial of service (crash) and possibly execute arbitrary code via the Voodoo interface, which triggers an out-of-bounds write. (CVE-2014-2978) | ||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||
dnsmasq: information disclosure
| Package(s): | dnsmasq | CVE #(s): | CVE-2015-3294 | ||||||||||||||||||||||||||||
| Created: | May 5, 2015 | Updated: | December 18, 2015 | ||||||||||||||||||||||||||||
| Description: | From the CVE entry:
The tcp_request function in Dnsmasq before 2.73rc4 does not properly handle the return value of the setup_reply function, which allows remote attackers to read process memory and cause a denial of service (out-of-bounds read and crash) via a malformed DNS request. | ||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||
elasticsearch: directory traversal
| Package(s): | elasticsearch | CVE #(s): | CVE-2015-3337 | ||||
| Created: | April 30, 2015 | Updated: | May 6, 2015 | ||||
| Description: | From the Debian advisory:
John Heasman discovered that the site plugin handling of the Elasticsearch search engine was susceptible to directory traversal. | ||||||
| Alerts: |
| ||||||
erlang: man-in-the-middle attack
| Package(s): | erlang | CVE #(s): | CVE-2015-2774 | ||||||||||||||||
| Created: | May 6, 2015 | Updated: | February 22, 2016 | ||||||||||||||||
| Description: | From the Mageia advisory:
Erlang's TLS-1.0 implementation failed to check padding bytes, leaving it vulnerable to an issue similar to POODLE. | ||||||||||||||||||
| Alerts: |
| ||||||||||||||||||
fcgi: denial of service
| Package(s): | fcgi | CVE #(s): | CVE-2012-6687 | ||||||||||||||||||||||||||||
| Created: | April 30, 2015 | Updated: | March 3, 2016 | ||||||||||||||||||||||||||||
| Description: | From the Red Hat bugzilla:
A stack-smashing bug for fcgi was reported to Ubuntu and subsequently patched in both Ubuntu and Debian. According to the bug report, if more than 1024 connections are received, a segfault can occur. A patch is provided with the bug reports: https://bugs.launchpad.net/ubuntu/+source/libfcgi/+bug/933417 and the report at debian: | ||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||
FlightGear: unspecified vulnerability
| Package(s): | FlightGear | CVE #(s): | |||||||||||||
| Created: | April 30, 2015 | Updated: | September 30, 2015 | ||||||||||||
| Description: | From the Fedora advisory:
This update provides a security fix related to the Nasal scripting language. From the Debian LTS advisory: It was discovered that flightgear, a Flight Gear Flight Simulator game, did not perform adequate filesystem validation checks in its fgValidatePath routine. | ||||||||||||||
| Alerts: |
| ||||||||||||||
ikiwiki: cross-site scripting
| Package(s): | ikiwiki | CVE #(s): | CVE-2015-2793 | ||||||||
| Created: | May 4, 2015 | Updated: | May 6, 2015 | ||||||||
| Description: | From the Red Hat bugzilla:
Cross-site scripting flaw in the handling of the openid_identifier parameter has been fixed in ikiwiki. | ||||||||||
| Alerts: |
| ||||||||||
libphp-snoopy: command execution
| Package(s): | libphp-snoopy | CVE #(s): | CVE-2014-5008 | ||||||||||||||||||||||||
| Created: | May 4, 2015 | Updated: | December 1, 2015 | ||||||||||||||||||||||||
| Description: | From the Debian advisory:
It was discovered that missing input sanitizing in Snoopy, a PHP class that simulates a web browser may result in the execution of arbitrary commands. | ||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||
openstack-glance: denial of service
| Package(s): | openstack-glance | CVE #(s): | CVE-2014-9684 CVE-2015-1881 | ||||
| Created: | May 6, 2015 | Updated: | May 6, 2015 | ||||
| Description: | From the CVE entries:
OpenStack Image Registry and Delivery Service (Glance) 2014.2 through 2014.2.2 does not properly remove images, which allows remote authenticated users to cause a denial of service (disk consumption) by creating a large number of images using the task v2 API and then deleting them before the uploads finish, a different vulnerability than CVE-2015-1881. (CVE-2014-9684) OpenStack Image Registry and Delivery Service (Glance) 2014.2 through 2014.2.2 does not properly remove images, which allows remote authenticated users to cause a denial of service (disk consumption) by creating a large number of images using the task v2 API and then deleting them, a different vulnerability than CVE-2014-9684. (CVE-2015-1881) | ||||||
| Alerts: |
| ||||||
owncloud: multiple vulnerabilities
| Package(s): | owncloud | CVE #(s): | CVE-2015-3011 CVE-2015-3012 CVE-2015-3013 | ||||
| Created: | May 4, 2015 | Updated: | May 6, 2015 | ||||
| Description: | From the Debian advisory:
CVE-2015-3011: Hugh Davenport discovered that the "contacts" application shipped with ownCloud is vulnerable to multiple stored cross-site scripting attacks. This vulnerability is effectively exploitable in any browser. CVE-2015-3012: Roy Jansen discovered that the "documents" application shipped with ownCloud is vulnerable to multiple stored cross-site scripting attacks. This vulnerability is not exploitable in browsers that support the current CSP standard. CVE-2015-3013: Lukas Reschke discovered a blacklist bypass vulnerability, allowing authenticated remote attackers to bypass the file blacklist and upload files such as the .htaccess files. An attacker could leverage this bypass by uploading a .htaccess and execute arbitrary PHP code if the /data/ directory is stored inside the web root and a web server that interprets .htaccess files is used. On default Debian installations the data directory is outside of the web root and thus this vulnerability is not exploitable by default. | ||||||
| Alerts: |
| ||||||
perl-xml-libxml: information disclosure
| Package(s): | perl-xml-libxml | CVE #(s): | CVE-2015-3451 | ||||||||||||||||||||||||||||||||||||
| Created: | May 1, 2015 | Updated: | September 8, 2015 | ||||||||||||||||||||||||||||||||||||
| Description: | From the Arch Linux advisory:
Unpreserved unset options after a _clone() call (e.g: in load_xml()) leads to not preserved expand_entities. Therefore it leads to a XML-External-Entity Vulnerability. This vulnerability may lead to the disclosure of confidential data, denial of service, port scanning from the perspective of the machine where the parser is located, and other system impacts. | ||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||
quassel: SQL injection
| Package(s): | quassel | CVE #(s): | CVE-2015-3427 | ||||||||||||
| Created: | May 1, 2015 | Updated: | May 6, 2015 | ||||||||||||
| Description: | From the Mageia advisory:
Quassel is vulnerable to SQL injection through its use of Qt's postgres driver. If the PostgreSQL server is restarted or the connection is lost at any point, other IRC users may be able to trick the Quassel core into executing SQL queries upon reconnection. | ||||||||||||||
| Alerts: |
| ||||||||||||||
squid: certificate validation bypass
| Package(s): | squid | CVE #(s): | CVE-2015-3455 | ||||||||||||||||||||||||||||||||||||||||
| Created: | May 4, 2015 | Updated: | December 22, 2015 | ||||||||||||||||||||||||||||||||||||||||
| Description: | From the Arch Linux advisory:
The flaw allows remote servers to bypass client certificate validation. Some attackers may also be able to use valid certificates for one domain signed by a global Certificate Authority to abuse an unrelated domain. However, the bug is exploitable only if you have configured Squid to perform SSL Bumping with the "client-first" or "bump" mode of operation. Sites that do not use SSL-Bump are not vulnerable. A remote attacker is able to bypass client certificate validation, as a result malicious server responses can wrongly be presented through the proxy to clients as secure authenticated HTTPS responses. | ||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||
xen: information leak
| Package(s): | xen | CVE #(s): | CVE-2015-3340 | ||||||||||||||||||||||||||||||||||||||||||||
| Created: | May 4, 2015 | Updated: | May 6, 2015 | ||||||||||||||||||||||||||||||||||||||||||||
| Description: | From the CVE entry:
Xen 4.2.x through 4.5.x does not initialize certain fields, which allows certain remote service domains to obtain sensitive information from memory via a (1) XEN_DOMCTL_gettscinfo or (2) XEN_SYSCTL_getdomaininfolist request. | ||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||
xorg-server: denial of service
| Package(s): | xorg-server | CVE #(s): | CVE-2015-3418 | ||||||||||||
| Created: | May 4, 2015 | Updated: | May 6, 2015 | ||||||||||||
| Description: | From the Debian LTS advisory:
This issue (CVE-2015-3418) is a regression which got introduced by fixing CVE-2014-8092. The above referenced version of xorg-server in Debian squeeze-lts fixes this regression in the following way: The length checking code validates PutImage height and byte width by making sure that byte-width >= INT32_MAX / height. If height is zero, this generates a divide by zero exception. Allow zero height requests explicitly, bypassing the INT32_MAX check (in dix/dispatch.c). | ||||||||||||||
| Alerts: |
| ||||||||||||||
Page editor: Jake Edge
Kernel development
Brief items
Kernel release status
The current development kernel is 4.1-rc2, released on May 3. "As usual, it's a mixture of driver fixes, arch updates (with s390 really standing out due to that one prng commit), and some filesystem and networking."
Stable updates: none have been released in the last week. The 4.0.2, 3.19.7, 3.14.41, and 3.10.77 updates are in the review process as of this writing. They were originally expected on May 4, but have been held up due to some problems caused by the inclusion of some ill-advised patches.
Quotes of the week
Many people suggested over the years that it needs a major cleanup, and some time ago I went "what the heck" and started doing it step by step to see where it leads - it cannot be that hard!
Three weeks and 200+ patches later I think I have to admit that I seriously underestimated the magnitude of the project! ;-)
Kernel development news
System call conversion for year 2038
There are now less than 23 years remaining until that fateful day in January 2038 when signed 32-bit time_t values — used to represent time values in Unix-like systems — run out of bits and overflow. As that date approaches, 32-bit systems can be expected to fail in all kinds of entertaining ways and current LWN readers can look forward to being called out of retirement in a heroic (and lucrative) effort to stave off the approaching apocalypse. Or that would be the case if it weren't for a group of spoilsport developers who are trying to solve the year-2038 problem now and ruin the whole thing. The shape of that effort has come a bit more into focus with the posting by Arnd Bergmann of a new patch set (later updated) showing the expected migration path for time-related system calls.Current Linux system calls use a number of different data types to represent times, from the simple time_t value through the timeval and timespec structures and others. Each, though, has one thing in common: an integer value counting the number of seconds since the beginning of 1970 (or from the current time in places where a relative time value is needed). On 32-bit systems, that count is a signed 32-bit value; it clearly needs to gain more bits to function in a world where post-2038 dates need to be represented.
Time representations
One possibility is to simply create 64-bit versions of these time-related structures and use them. But if an incompatible change is to be made, it might be worthwhile thinking a bit more broadly; to that end, Thomas Gleixner recently suggested the creation of a new set of (Linux-specific) system calls that would use a signed, 64-bit nanosecond counter instead. This counter would mirror the ktime_t type (defined in <include/linux/ktime.h>) used to represent times within the kernel:
union ktime {
s64 tv64;
};
typedef union ktime ktime_t; /* Kill this */
(Incidentally, the "kill this" comment was added by Andrew Morton in 2007; nobody has killed it yet.)
Having user space work with values that mirror those used within the kernel has a certain appeal; a lot of time-conversion operations could be eliminated. But Arnd Bergmann pointed out a number of difficulties with this approach, including the fact that it makes a complicated changeover even more so. The fatal flaw, though, turns up in this survey of time-related system calls posted by Arnd shortly thereafter: system calls that deal with file timestamps need to be able to represent times prior to 1970. They also need to be able to express a wider range of times than is possible with a 64-bit ktime_t. So some variant of time_t must be used with them, at least. (The need to represent times before 1970 also precludes the use of an unsigned value to extend the forward range of a 32-bit time_t value).
So universal use of signed nanosecond time values does not appear to be in the cards, at least not as part of the year-2038 disaster-prevention effort. Still, there is room for some simplification. The current plan is to use the 64-bit version of struct timespec (called, appropriately, struct timespec64 in the kernel, though user space will still see it as simply struct timespec) for almost all time values passed into or out of the kernel. The various system calls that use the other (older) time formats can generally be emulated in user space. So, for example, a call to gettimeofday() (which uses struct timeval) will be turned into a call to clock_gettime() before entry into the kernel. That reduces the number of system calls for which compatibility must be handled in kernel space.
Thus, in the future, a 32-bit system that is prepared to survive 2038 will use struct timespec64 for all time values exchanged with the kernel. That just leaves the minor problem of how to get there with a minimal amount of application breakage. The current plan can be seen in Arnd's patch set, which includes a number of steps to move the kernel closer to a year-2038-safe mode of operation.
Getting to a year-2038-safe system
The first of those steps is to prepare to support 32-bit applications while moving the kernel's internal time-handling code to 64-bit times in all situations. The internal kernel work has been underway for a while, but the user-space interfaces still need work, starting with the implementation of a set of routines that will convert between 32-bit and 64-bit values at the system-call boundary. The good news is that these routines already exist in the form of the "compatibility" system calls used by 32-bit applications running on a 64-bit kernel. In the future, all kernels will be 64-bit when it comes to time handling, so the compatibility functions are just what is needed (modulo a few spots where other data types must be converted differently). So the patch set causes the compatibility system calls to be built into 32-bit kernels as well as 64-bit kernels. These compatibility functions are ready for use, but will not be wired up until the end of the patch series.
The next step is the conversion of the kernel's native time-handling system calls to use 64-bit values exclusively. This process is done in two broad sub-steps, the first of which is to define a new set of types describing the format of native time values in user space. For example, system calls that currently accept struct timespec as a parameter will be changed to take struct __kernel_timespec instead. By default, the two structures are (nearly) the same, so the change has no effect on the built kernel. If the new CONFIG_COMPAT_TIME configuration symbol is set, though, struct __kernel_timespec will look like struct timespec64 instead.
The various __kernel_ types are used at the system-call boundary, but not much beyond that point. Instead, they are immediately converted to 64-bit types on all machines; on 64-bit machines, obviously, there is little conversion to do. Once each of the time-related system calls is converted in this manner, it will use 64-bit time values internally, even if user space is still dealing in 32-bit time values. Any time values returned to user space are converted back to the __kernel_ form before the system call returns. There is still no change visible to user space, though.
The final step is to enable the use of 64-bit time values on 32-bit systems without breaking existing 32-bit binaries. There are three things that must all be done together to make that happen:
- The CONFIG_COMPAT_TIME symbol is set, causing all of the
__kernel_ data structures to switch to their 64-bit versions.
- All of the existing time-related system calls are replaced with the
32-bit compatibility versions. So, for example, on the ARM
architecture, clock_gettime() is system call number 263.
After this change, applications invoking system call 263 will get
compat_sys_clock_gettime() instead. If the compatibility
functions have been done correctly, binary applications will not
notice the change.
- The native 64-bit versions of the system calls are given new system call numbers; clock_gettime() becomes system call 388, for example. Thus, only newly compiled code that is prepared to deal with 64-bit time values will see the 64-bit versions of these calls.
And that is about as far as the kernel can take things. Existing 32-bit binaries will call the compatibility versions of the time-related system calls and will continue to work — until 2038 comes around, of course.
That leaves a fair amount of work to be done in user space, of course. In a simplified view of the situation, the C libraries can be changed to use the 64-bit data structures and invoke the new versions of the relevant system calls. Applications can then be recompiled against the new library, perhaps with some user-space fixes required as well; after that, they will no longer participate in the year 2038 debacle. In practice, all of the libraries in a system and all applications may need to be rebuilt together to ensure that they have a coherent idea of how times are represented. The GNU C library uses symbol versioning, so it can be made to work with both time formats simultaneously, but many other libraries lack that flexibility. So converting a full distribution is likely to be an interesting challenge even once the work on the kernel side is complete.
Finishing the job
Even on the kernel side, though, there are a few pieces of the puzzle that have not yet been addressed. One significant problem is ioctl() calls; of the thousands of them supported by the kernel, a few deal in time_t values. They will have to be located and fixed one-by-one, a process that could take some time. The ext4 filesystem stores timestamps as 32-bit time_t values, though some variants of the on-disk format extend those fields to 34 bits. Ext3 does not support 34-bit timestamps, though, so the solution there is likely to be to drop it entirely in favor of ext4. NFSv3 has a similar problem, and may meet a similar fate; XFS also has some challenges to deal with. The filesystem issues, notably, affect 64-bit systems as well. There are, undoubtedly, many other surprises like this lurking in both the kernel and user space, so the task of making a system ready for 2038 goes well beyond migrating to 64-bit time values in system calls. Still, fixing the system calls is a start.
Once the remaining problems have been addressed, there is a final patch that can be applied. It makes CONFIG_COMPAT_TIME optional, but in a way that leaves the 64-bit paths in place while removing the 32-bit compatibility system calls. If this option is turned off, any binary using the older system calls will fail to run. This is thus a useful setting for testing year-2038 conversions or deploying long-lived systems that must survive past that date. As Arnd put it:
Presumably somebody will be paying attention and will remember to carry out this removal twenty years from now (if they are feeling truly inspired, they might just kill ktime_t while they are at it). At that point, they will likely be grateful to the developers who put their time into dealing with this problem before it became an outright emergency. The rest of us, instead, will just have to find some other way to fund our retirement.
(Thanks to Arnd Bergmann for his helpful comments and suggestions on an earlier draft of this article.)
The OrangeFS distributed filesystem
There is no shortage of parallel, distributed filesystems available in Linux today. Each have their strengths and weaknesses, as well as their advocates and use cases. Orange File System (or OrangeFS) is another; it is targeted at providing high I/O performance on systems with up to several thousand multicore storage nodes, but the project is planning to support millions of cores eventually. The OrangeFS client code was proposed for the Linux kernel back in January. Walt Ligon, one of the principals behind the filesystem, gave a talk about OrangeFS at the Vault conference back in March.
At the beginning of the talk, Ligon noted that OrangeFS was similar "in some ways" to GlusterFS, which was the subject of an earlier Vault presentation. But OrangeFS grew out of a research project from 1993 called Parallel Virtual File System (PVFS). That filesystem (now in version 2, called PVFS2) is in use today by various commercial organizations as well as by universities. In 2008, the PVFS project was renamed to OrangeFS as part of changing its focus to a more general filesystem for "big data".
Overview
At its core, OrangeFS has a client-server architecture, most of which runs in user space. All of the code is available under the LGPL. There are multiple ways for client systems to use the PVFS protocol to access data on the servers. That includes libpvfs2 for low-level access, MPI-IO, Filesystem in Userspace (FUSE), web-related mechanisms (e.g. WebDAV, REST), and a Linux virtual filesystem (VFS) client implementation for mounting OrangeFS like any other filesystem in Linux. The latter is what is being proposed for upstream inclusion.
OrangeFS servers handle objects, called dataspaces, that can have both byte-stream and key-value components. The "Trove" subsystem determines how to store those components. Currently, the byte streams are stored as files on the underlying filesystem, while the key-value data is mostly stored in Berkeley DB files, though there is starting to be some use of LMDB.
![[File structure diagram]](https://static.lwn.net/images/2015/vault-orangefs-diag-sm.png) As seen in the diagram at right, files are stored as a collection of
objects: a metadata object and one or
more distributed file ("Dfile") objects. Those are accessed from directory
objects that include a metadata object. Each of those point to various DirData
objects, which contain Dirent (directory entry) objects that point
to the metadata object
of a file.
As seen in the diagram at right, files are stored as a collection of
objects: a metadata object and one or
more distributed file ("Dfile") objects. Those are accessed from directory
objects that include a metadata object. Each of those point to various DirData
objects, which contain Dirent (directory entry) objects that point
to the metadata object
of a file.
Instead of blocks, OrangeFS is all about objects and leaves the block mapping to the underlying filesystems. There are no metadata servers, as all servers can handle all kinds of requests. It is possible to configure an OrangeFS filesystem to store its metadata separate from its data using parameters that govern how the objects should be distributed. Files are typically striped across multiple servers to facilitate parallel access.
OrangeFS provides a unified namespace, so that all files are accessible from a single mount point. It has a client protocol that supports lots of parallel clients and servers. That provides "high aggregate throughput", Ligon said.
In the past, users wanted MPI-IO access to files, but that has changed. Now, POSIX access is "what everyone wants to use". They want to be able to write Python scripts to access their data. But the POSIX API "can be a real limiting factor" because it doesn't understand parallel files, striping, and so on.
Another of the goals for OrangeFS is to "enable the future" by being flexible about the underlying technologies it uses. It wants to provide ways to swap in new redundancy, availability, and stability techniques. For example, OrangeFS is designed to allow users to use their own distribution equation, which is used to find and store data. That equation allows the system to determine which servers go with each object.
Another goal is to make OrangeFS grow to "exascale". One
way to keep increasing storage is to add more disks to the computer, but
that will eventually hit a wall. There is not enough bandwidth and compute
![[Walt Ligon]](https://static.lwn.net/images/2015/vault-ligon-sm.jpg "Walt Ligon") power within a system to access all that data with reasonable performance;
the solution to that
problem is to add more computers into the mix.
power within a system to access all that data with reasonable performance;
the solution to that
problem is to add more computers into the mix.
That dramatically increases the number of cores accessing the data, but you can only increase the amount of storage per server to a certain point. Just as with the single computer system above, various limits will be hit, so a better solution is to add more servers with more network connections, but that can get costly. In an attempt to build a lower-cost alternative, Ligon has a new project to create, say, 500 storage servers, each using a Raspberry Pi with a disk. It will be much cheaper, but he thinks it will also be faster—though he still needs to prove that.
There are a number of planned OrangeFS attributes that are missing from the discussion so far, he said. For example, with a large enough number of servers and disks, there will be failures every day. Even if there are no failures, systems will need to be taken down to update the operating system or other software, so there is a need for features that provide availability.
Security is a "major issue" that has mostly been dealt with using "chewing gum and string", Ligon said. Data integrity is another important attribute, as the stored data must be periodically checked and repaired. There is also a need for ways to redistribute files and objects for load or space reasons, as well as a need for monitoring and administration tools.
OrangeFS V3
Some of the "core values" for the next major version of OrangeFS (3.0 or V3) are directly targeted at solving those problems. At the top of that list is "parallelism"; the filesystem should allow parallel access to files, directories, and metadata, while providing scalability through adding servers. The filesystem should also recognize that things are going to fail regularly. If a copy goes bad, throw it away and recreate it; if a node fails, simply discard and replace it.
OrangeFS V3 will minimize the dependencies between servers by not sharing state between them. That will allow servers to be added and removed as needed. Avoiding locks is key to providing better performance, which may require relaxing the semantics of some operations. Finally, 3.0 will target flexible site-customization policies for things like object placement, replication, migration, and so forth.
In order to do all of that, OrangeFS will change the PVFS handle that has been used to identify objects. It is a 64-bit value that encodes both the object and the server it lives on. That scheme has a number of limitations. Objects cannot migrate or be replicated and the collection of servers is static. That works well up to around 128 static servers, he said, but it won't work for OrangeFS V3.
The new handles will contain both an object ID and one or more server IDs, both of which will be 128-bit values. The number of server IDs will typically be somewhere between two and four that will be set when the filesystem is created; it can change, but in practice rarely will. These handles are internal-only, typically stored in metadata objects. By making this change, OrangeFS V3 will be able to do replication and migration.
This will allow all of the filesystem structure to be replicated, as well as the file data. A set of back references is also created, so that maintenance operations can find other copies of the structures. Each of those pieces and copies could be stored on different servers if that was desired. Another possibility is to use "file stuffing", which places the first data object on the same server as its metadata object.
Reads can be done from any server that has a copy of the object, while writes are done to the primary object. Its server then initiates the copy (or copies) needed for replication. The write will only complete and return to the client after a certain number of copies have completed. This is known as the "write confidence" required. For example, if one copy is sent to a much slower archive device, the write could complete after all or some of the non-archive copies have completed.
V3 adds a server ID database, rather than a fixed set of servers. That allows dynamic addition of servers with site-defined attributes (e.g. number, building, rack, etc.). A client doesn't have to know about all the servers, only the set it is using. Servers maintain a partial list of other servers that they tend to work with and there is a server resolution protocol to find others as needed.
The security model is already present in OrangeFS 2.9 (which is the current version of the filesystem). The model is based around capabilities that get returned based on the credentials presented when a metadata object is accessed. That capability is then passed when accessing the data objects. Certificates and public/private key pairs are used to authenticate clients and their credentials.
The final OrangeFS feature that Ligon described was the "parallel background jobs" (PBJs) that are used for maintenance and data integrity. They can be run to check the integrity of the data stored and to repair problems that are found. They can also handle tasks like rebalancing where data is stored to avoid access hotspots and the like.
As he said at the outset, Ligon's talk provided a high-level overview of the filesystem. It seems to not be a particularly well known filesystem, but one that has some interesting attributes. Beyond just handling large data sets for parallel computation, it is also targeted as a research platform that can be used to test ideas for enhancements or broad restructuring. The kernel patches did not receive any comments, but they are also fairly small (less than 10,000 lines of code), so it seems plausible that we will see an OrangeFS client land in the mainline sometime in the future.
[I would like to thank the Linux Foundation for travel support to Boston for Vault.]
Improving kernel string handling
The handling and parsing of string data has long been acknowledged as a fertile breeding ground for bugs and security issues; that is doubly true when the C language — whose string model leaves a bit to be desired — is in use. Various attempts have been made to improve C string handling, both in the kernel and in user space, but few think that the problem has been solved. A couple of current projects may improve the situation on the kernel side, though.
String copying
The venerable strcpy() family of functions has long been seen as error-prone and best avoided. In most settings, they are replaced with functions like strncpy() or strlcpy(). The last time your editor wrote about criticisms of strlcpy(), he was treated to a long series of incendiary emails from one of its supporters. So, for the purposes of this article, suffice to say that not all developers are fond of those functions. Even so, the kernel contains implementations of both, and there are over 1,000 call sites for each.
That doesn't mean that there isn't room for improvement, though. Chris Metcalf thinks he has an improvement in the form of the proposed strscpy() API, which provides two new functions:
ssize_t strscpy(char *dest, const char *src, size_t count);
ssize_t strscpy_truncate(char *dest, const char *src, size_t count);
As with similar functions, strscpy() will copy a maximum of count bytes from src to dest, but it differs in the details. The return value in this case is the number of bytes copied, unless the source string is longer than count bytes; in that case, the return value will be -E2BIG instead. Another difference is that, in the overflow case, dest will be set to the empty string rather than a truncated version of src.
This behavior is designed to make overflows as obvious as possible and to prevent code from blithely proceeding with a truncated string. When questioned on this behavior, Chris justified it this way:
2. Programmers are fond of ignoring error returns. My experience with truncated strings is that in too many cases, truncation causes program errors down the line. It's better to ensure that no partial string is returned in this case.
In a perfect world, all error returns would be checked, and there would be no need for this, but we definitely don't live in that world :-)
For cases where the code can handle a truncated string, strscpy_truncate() can be used. Its return value convention is the same, but it will fit as much of the string as possible (null-terminated) in dest.
Integer parsing
The kernel must often turn strings into integer values; the interpretation of numbers written to sysfs files or found on the kernel command line are a couple of obvious examples. This parsing can be done with functions like simple_strtoul() (which decodes a string to an unsigned long), but they were marked as being obsolete in 2011. The checkpatch script complains about their use, but there are still about 1,000 call sites in the kernel. Current advice is to use kstrtoul() and the better part of a dozen variants, also added in 2011. There are almost 2,000 uses of these functions in the kernel, but Alexey Dobriyan thinks we can do better.
Alexey has a few complaints about the current APIs. One of the reasons for moving beyond the simple_strto*() functions was that they would silently stop conversion at a non-digit character — "123abc" would be successfully converted to 123. That is the sort of behavior for which PHP is roundly criticized, but, Alexey says, there are times when it is useful. He gives the parsing of device numbers (usually given in the "major:minor" format) as an example. The kstrto*() family cannot easily be used for that kind of parsing, but there are plenty of reasons to not go back to simple_strto*() for that kind of work.
His suggestion is the addition of a new function:
int parse_integer(const char *s, unsigned int base, <type> *val);
In truth, parse_integer() is not a function; it is instead a rather unsightly macro that arranges to do the right thing for a wide variety of types for val. So, if val is an unsigned short, the decoding will be done on an unsigned basis and will be checked to ensure that the resulting value does not exceed the range of a short.
A successful decoding will cause the result to be placed in val; the number of characters decoded will come back as the return value. If it is expected that the entire string will be decoded, a quick check to see whether s[return_value] is a null byte can verify that. Otherwise, parsing of the string can continue from the indicated point. If the base is ORed with the undocumented value PARSE_INTEGER_NEWLINE, a final newline character will be skipped over — useful for parsing input to sysfs files. If no characters at all are converted, the return value will be -EINVAL; an overflow will return -ERANGE instead.
Alexey's patch set turns the kstrto*() functions into calls to parse_integer(); it also converts a number of simple_strto*() calls to direct parse_integer() calls. The end result is an apparent simplification of the code and net reduction in lines of code.
Whether either of these patch sets will find its way into the kernel is not entirely clear; kernel developers do not, in general, tend to get too excited about string-parsing functions. In both cases, though, the potential exists for improvements to the massive amounts of parsing code found in the kernel while simultaneously making it simpler. In the end, most developers will find it hard to argue against something like that.
Patches and updates
Kernel trees
Architecture-specific
Core kernel code
Development tools
Device drivers
Device driver infrastructure
Filesystems and block I/O
Memory management
Networking
Security-related
Virtualization and containers
Miscellaneous
Page editor: Jonathan Corbet
Distributions
Packaging QtWebEngine
There is always some tension between the goals of upstream projects and those of distributions. We see that playing out in a recent discussion of packaging the QtWebEngine component for Debian and Fedora that took place on the kde-core-devel mailing list. The whole intent of QtWebEngine is to use the Chromium browser code base as a tool for other applications, but that brings with it all of the packaging problems—library bundling, mostly—that come with that browser.
Lisandro Damián Nicanor Pérez Meyer raised the issue, noting that the KDE personal information management (KDE PIM) packages now depend on QtWebEngine. That package is difficult for distributions to handle because it depends on Chromium, which in turn depends on various other packages.
If Chromium simply depended on those other packages, there wouldn't be so much of a problem. Instead, however, Chromium bundles modified versions of those packages in such a way that distributions have to take the binaries they are given by the project, make a huge number of distribution-specific patches, or live without. In fact, these problems are why Chromium is not available in Fedora.
The immediate responses from KDE board member Albert Astals Cid were less than entirely helpful. He indicated that he thought the distribution policies were simply out of line. He did note that the maintenance window provided for QtWebEngine by the Qt Project might not meet distributions' requirements, but that was really a problem for the distributions:
While that response was not realistically addressing the problem, it does underscore the differences that exist between some upstream projects and distributions. It is not exactly clear how Astals expects KDE to get into the hands of users if it weren't for distributions—it would seem that he thinks that all of the upstream projects should simply dictate what the distributions ship. It is not an uncommon attitude, at least for larger projects, but it is a bit hard to see it as much of a cooperative stance.
Others on the list saw things a bit differently, however. Luigi Toscano noted that the distributions have their rules
for a reason: "The rules are there not because someone wants to have unhappy users; think
about the rule about untangling tons of embedded libraries and patching
issues.
" Sune Vuorela envisioned an all-too-plausible scenario where
adopting a new version of QtWebEngine led to an enormous cascade of other
dependencies
that needed updating due to the change.
That led Thomas Lübking to conclude that
"the Linux SW stack is crap
", but the problem is not so cut
and dried. As Matthias Klumpp pointed out,
there are lots of different upstream projects with lots of different
priorities. The job of
a distribution is to navigate that landscape and to produce something sane
for its users:
Astals had suggested that distributions that choose not to ship certain applications because of dependencies that "broke rules" would simply cause their users to go elsewhere. But Vuorela explained that the problem affects both distributions and KDE equally:
We (as KDE) need to understand that if we don't have our software in distributions, it is just as likely that people will switch applications, as it is that they will switch distributions.
So, all in all, if everyone takes a hard stance, everyone will lose.
Let's find a way so we all can win.
The problem isn't limited to Linux, either. Vadim Zhukov had similar complaints about QtWebEngine for OpenBSD.
While there were some advocating finding solutions, there were few actual solutions to be found in the thread. QtWebKit, which is based on WebKit rather than Chromium, might be an alternative, but it is deprecated in Qt or will be before too long. Trying to avoid hard dependencies on QtWebEngine is another possibility, but makes it hard for KDE applications that want to use the web.
This is a problem we have seen in various guises over the years and will certainly see again. Resolving the tension between the needs of upstream projects and users (as embodied by the distributions they choose) is not easy. Perhaps some radical experiments in the distribution space are indicated.
Brief items
Distribution quotes of the week
Instead, my waggish friends, the winsome W on which we wish will be… the “wily werewolf”.
OpenBSD 5.7
OpenBSD 5.7 has been released. This version includes improved hardware support, network stack improvements, installer improvements, security and bug fixes, and more. OpenSSH 6.8, LibreSSL, and other packages have also seen improvements and bug fixes.
Distribution News
Debian GNU/Linux
Debian GNU/Hurd 2015 released
Debian GNU/Hurd 2015 has been released. "This is a snapshot of Debian "sid" at the time of the stable Debian "jessie" release (April 2015), so it is mostly based on the same sources. It is not an official Debian release, but it is an official Debian GNU/Hurd port release."
Qt4's status and Qt4's webkit removal in Stretch
Lisandro Damián Nicanor Pérez Meyer has a reminder that Qt4 is deprecated and code should be ported to Qt5 during the "Stretch" development period. "We plan to start filing wishlist bugs soon. Once we get most of KDE stuff running with Qt5's webkit we will start raising the severities."
Fedora
Fedora 22 Beta for aarch64 and POWER platforms
Fedora 22 beta is available for aarch64 and POWER secondary architectures.
Red Hat Enterprise Linux
Red Hat Enterprise Linux 6.7 beta
Red Hat has announced the release of Red Hat Enterprise Linux 6.7 beta. "The beta release of Red Hat Enterprise Linux 6.7 includes a number of new and updated features to help organizations preserve investments in existing infrastructure, bolster security, stability, and systems management/monitoring capabilities, and embrace the latest Linux innovations." See the release notes for details.
Ubuntu family
Wily Werewolf (15.10) now open for development
Ubuntu 15.10 "Wily Werewolf" is open for development. "Very little has changed in the opening base system and toolchain, however do note that due to jessie releasing only a couple of days after vivid, many Debian developers have awoken from hibernation and auto-syncs and merges should be full of new shiny to look at."
Ubuntu 10.04 (Lucid Lynx) End of Life
Ubuntu 10.04 LTS reached its end of support on April 30. The supported upgrade path from Ubuntu 10.04 is via Ubuntu 12.04.
Newsletters and articles of interest
Distribution newsletters
- Last few days in CentOS (May 5)
- DistroWatch Weekly, Issue 608 (May 4)
- 5 things in Fedora this week (May 1)
- Tumbleweed - Review of the week (May 2)
- Ubuntu Weekly Newsletter, Issue 415 (May 3)
FreeBSD quarterly status report
The FreeBSD project has released a quarterly status report for the period between January and March 2015. "The first quarter of 2015 was another productive quarter for the FreeBSD project and community. FreeBSD is being used in research projects, and those projects are making their way back into FreeBSD as new and exciting features, bringing improved network performance and security features to the system. Work continues to improve support for more architectures and architecture features, including progress towards the goal of making ARM (32- and 64-bit) a Tier 1 platform in FreeBSD 11. The toolchain is receiving updates, with new versions of clang/LLVM in place, migrations to ELF Tool Chain tools, and updates to the LLDB and gdb debuggers. Work by ports teams and kernel developers is maintaining and improving the state of FreeBSD as a desktop operating system. The pkg team is continuing to make binary packages easier to use and upgrade."
Hoogland: Introducing the Moksha Desktop
Jeff Hoogland has announced that the Bodhi Linux project is forking Enlightenment 17. The new fork is the Moksha Desktop. "On top of the performance issues, E19 did not allow for me personally to have the same workflow I enjoyed under E17 due to features it no longer had. Because of this I had changed to using the E17 on all of my Bodhi 3 computers – even my high end ones. This got me to thinking how many of our existing Bodhi users felt the same way, so I opened a discussion about it on our user forums. I found many felt similar to how I did. So that left only one question: What was to be done about it? After much reflection, I came to the same conclusion others had before me that lead to the creation of the Mate and Trinity desktops – fork it."
Debian 8: Linux’s most reliable distro (Ars Technica)
Ars Technica has a review of Debian 8 "Jessie". "Debian Stable is designed to be, well, stable. The foundation of Debian is built upon long development cycles and a conservative approach to application updates. So as a general rule, Debian Stable lags behind pretty much every other distro on the market when it comes to package updates. If you want the latest and greatest, Debian Stable simply isn't the distro for you. While Debian 8 may bring a ton of new stuff to Debian, it has almost nothing the rest of the Linux world hasn't been using for, in some cases, years. What's more, many things in Debian 8 are still not going to be the latest available versions."
Ubuntu 15.04 review: Beauty or “boring” is in the eye of the beholder (Ars Technica)
Ars Technica also reviewed Ubuntu 15.04 "Vivid Vervet". "Snow melts and trees blossom, but nothing really says spring around the Ars Orbital HQ like the arrival of a new version of Ubuntu Linux. Right on schedule, Canonical has recently released Ubuntu 15.04, also known as Vivid Vervet. Ubuntu 15.04 arrived in late April and has, judging by other reviews, largely underwhelmed. According to the popular storyline, there's not much new in 15.04. Of course, a slew of changes and unforeseen features in 15.04 could have just as easily earned a negative reaction, probably from the same people calling the actual release boring. The top of the Linux mountain is a lonely, criticism-strewn place."
When Official Debian Support Ends, Who Will Save You? (Linux Journal)
Linux Journal takes a look at the Debian LTS effort. "The Debian Long Term Support (LTS) project has been providing support for Debian version 6 (Squeeze) and will continue to do so until early next year. LTS announced that it will be supporting later editions too. The project provides security patches and bug fixes for the core components of the Debian system, in addition to the most popular packages. The team would like to expand the range of packages covered, but it will require additional support to make that happen."
Page editor: Rebecca Sobol
Development
Opposition to Python type hints
Type hints for Python seem to be a feature that is on the fast track. These optional hints provide information that would allow static type-checking. But a recent discussion on the python-dev mailing list shows that not everyone is on-board with the idea of adding the annotations inline—they would rather see the hints be "hidden" in separate files. Others seem opposed to the idea of type hints at all, fearing that the feature will change the character of the language entirely.
We first looked at the type hints back in December, though the discussion started in August 2014. The feature has been championed by Python's benevolent dictator for life (BDFL), Guido van Rossum, who also described the feature in a Python Language Summit session (and PyCon keynote) in April. It is targeted for the Python 3.5 release that is slated for September. The idea of static typing for Python goes back much further, however, at least as far as a December 2004 blog post from Van Rossum.
Self-described "mediocre programmer" Harry Percival posted his reaction to the type hints. He argued that type hints are "ugly" and will make the language harder to understand, especially for beginners. He didn't buy the argument that the type annotations for functions will truly be optional, suggesting that over time there will be a strong uptake of the feature. He didn't suggest doing away with type hints entirely, just that there be a recommendation to put those annotations into stub files.
The idea of stub files is already part of the type hints proposal, largely to support C extensions where there may be no Python code to annotate. There are other situations where they will be needed, including for modules that must support both Python 2 and 3. The syntax used by the annotations is only available in Python 3. Stub files have the same syntax as regular Python files—just containing function signatures with "pass" for the function body—but use a .pyi extension
There are some problems with always using stub files, however. For one thing, the way things are currently implemented, the stub files for a module would only be consulted for code that uses that module. The module itself would not have the benefit of the annotations, so its code could not be type-checked. Also, the annotations from stubs are not accessible for introspection from within Python code as inline annotations are.
Percival's post garnered a fair amount of support. To many, type hints are not particularly "Pythonic" and they will make Python code harder to read. By far the strongest condemnation came from Jack Diederich (who is evidently still smarting from a suggestion Van Rossum made in 2003). Some of his complaints are based on misunderstandings of the plans moving forward, but those misconceptions are shared by a fair number of others in what turned into a monster thread. But the core of his complaint can be found at the end of the message:
There are many fine languages that have sophisticated type systems. And many bondage & discipline languages that make you type things three times to make really really sure you meant to type that. If you find those other languages appealing I invite you to go use them instead.
Adding type declarations to a dynamically typed language seems to be the crux of the problem for Diederich and others. It fundamentally changes what Python is. But Gregory P. Smith noted that the PEP is really targeted at creating a common way for projects using types (and type-checking) for Python to annotate code, not at all for a wholesale change in existing code:
We will not be putting type annotations anywhere in the stdlib or expecting anyone else to maintain them there. That would never happen until tools that are convincing enough in their utility for developers to _want_ to use are available and accepted. That'll be a developer workflow thing we could address with a later PEP. IF it happens at all.
A more practical complaint about the annotations came from Requests developer Cory Benfield, who tried to annotate some parts of that library. For certain parameters, he got incredibly complicated annotations that still didn't fully restrict the parameter types. He summarized the problems, as follows:
After Chris Angelico suggested that
Benfield might "want to just stop caring about the exact
type
", Benfield pointed to exactly
that as
part of the problem:
Another complaint, voiced by Arnaud
Delobelle, is that type hints are a
threat to duck
typing. The concern is that if the tools start complaining about
interfaces that use duck typing, it will cause programmers to shy away from
that longstanding Python type convention. That "could encourage a very
significant
cultural change in the way Python code is written towards a less flexible
mindset
". But Van Rossum has not
forgotten about duck typing:
The hope is that once 3.5 is out (with PEP 484's typing.py included *provisional* mode) we can start working on the duck typing specification. The alternative would have been to wait until 3.6, but we didn't think that there would be much of an advantage to postponing the more basic type hinting syntax (it would be like refusing to include "import" until you've sorted out packages). During the run of 3.5 we'll hopefully get feedback on where duck typing is most needed and how to specify it -- valuable input that would be much harder to obtain of *no* part of the type hints notation were standardized.
The roughly one and a half to two years that fall between each major Python release were clearly part of Van Rossum's thinking. He chose to implement something that could be done before 3.5 hit its feature freeze, but to keep the feature in a provisional state so that it could still be changed during the 3.6 development cycle. Several things may get addressed during that cycle, including support for duck typing and, possibly, adding new syntax for variable type declarations (instead of the comment-based annotations that are part of PEP 484). That all assumes that the PEP is accepted for 3.5, which seems likely unless Van Rossum has a change of heart.
The concerns about the standard library getting annotations are largely
based on misunderstandings—there are no plans afoot to add them en
masse either inline or as stubs. In fact, changes of that sort to
"modernize" the
standard library are frowned upon, Van Rossum said, because they often cause subtle
regressions "in dark corners
". Adding stub files for the
standard library in 3.6 is a possibility, PEP co-author Łukasz Langa said. Additions to the standard library might include inline annotations, if
the author is a fan of type hints, but
that is going to be a ways out, according to
Van Rossum.
The standard library is often seen as a place to look at "good" Python code, but that isn't really the case. It is a shared community code base, as Nick Coghlan described it but, as Van Rossum pointed out, it is not the epitome of Python coding style:
The debate got a bit testy at times but, as is generally the case in the Python world, it never got really out of hand. That community has found a way to moderate its communication, generally by way of fairly gentle reminders about respecting others' views. In the end, any change of this magnitude is going to cause some to be worried about the impacts—as they should. Contrary to some of the less temperate reactions (evidently Twitter was especially bad), this hardly seems like a change that "breaks" the language. It would not be hugely surprising to see it as quite a popular feature in, say, five years, once all the kinks have been worked out.
Brief items
Quotes of the week
Apache SpamAssassin 3.4.1 released
The Apache SpamAssassin 3.4.1 release is out. "Highlights include: Improved automation to help combat spammers that are abusing new top level domains; Tweaks to the SPF support to block more spoofed emails; Increased character set normalization to make rules easier to develop, block more international spam and stop spammers from using alternate character sets to bypass tests; Continued refinement to the native IPv6 support; and Improved Bayesian classification with better debugging and attachment hashing."
Jython 2.7.0 released
Version 2.7 of Jython, the Python implementation for Java, has been released. As the version number suggests, this update provides language and runtime compatibility with CPython 2.7.
GNU moe 1.7 released
Version 1.7 of the GNU moe console text editor has been released. This update includes a number of fixes for translating text data to and from UTF-8, adds a function for encoding as ASCII, and incorporates several fixes to search/replace functionality.
Git v2.4.0 released
Git 2.4.0 has been released. LWN took a look at version 2.4.0 in April. Little seems to have changed since the release-candidate builds, but users are advised to give the release notes a close read nonetheless.
PyTables 3.2.0 released
PyTables version 3.2.0 has been released. The update "is the result of more than a year of accumulated patches, but most specially it fixes a couple of nasty problem with indexed queries not returning the correct results in some scenarios.
" The release notes contain considerably more detail.
Git code hosting beta (launchpadblog)
Early support for hosting Git repositories directly on Launchpad has been announced. "This has been by far the single most commonly requested feature from Launchpad code hosting for a long time; we’ve been working hard on it for several months now, and we’re very happy to be able to release it for general use. This is distinct from the facility to import code from Git (and some other systems) into Bazaar that Launchpad has included for many years."
Newsletters and articles
Development newsletters from the past week
- What's cooking in git.git (April 30)
- What's cooking in git.git (May 4)
- What's cooking in git.git (May 6)
- LLVM Weekly (May 4)
- OCaml Weekly News (May 5)
- OpenStack Community Weekly Newsletter (May 1)
- Perl Weekly (May 4)
- PostgreSQL Weekly News (May 3)
- Python Weekly (April 30)
- Ruby Weekly (April 30)
- This Week in Rust (May 5)
- Tor Weekly News (April 29)
- Tor Weekly News (May 6)
- TUGboat (April)
- Wikimedia Tech News (May 4)
App Container spec gains new support as a community-led effort
CoreOS looks at community adoption of the App Container spec (appc). "In order to ensure the specification remains a community-led effort, the appc project has established a governance policy and elected several new community maintainers unaffiliated with CoreOS: initially, Vincent Batts of Red Hat, Tim Hockins of Google and Charles Aylward of Twitter. This new set of maintainers brings each of their own unique points of view and allows appc to be a true collaborative effort. Two of the initial developers of the spec from CoreOS, Brandon Philips and Jonathan Boulle, remain as maintainers, but now are proud to have the collective help of others to make the spec what it is intended to be: open, well-specified and developed by a community."
Page editor: Nathan Willis
Announcements
Brief items
International Day Against DRM
This year the International Day Against DRM will be held on May 6. The Free Software Foundation focuses on community with a wide variety of community groups, activist organizations, and businesses all taking part in the ninth International Day Against DRM.
The FSF's DefectiveByDesign campaign looks at how DRM
affects people with disabilities. "DRM is especially bad for those of us that face additional
hurdles using computers. It's beastly for blind people, who are
dependent on an audiobook market heavily laden with DRM.
"
Articles of interest
Free Software Supporter - Issue 85, May 2015
The Free Software Foundation's monthly newsletter for May covers the International Day Against DRM, the Licensing and Compliance Lab interviews Matt Lee, DMCA exemption commenting process broken beyond repair, thousands of Spaniards leave Twitter for GNU social, GNU Mailman 3.0 released, GCC 5 release series update, and several other topics.FSFE Newsletter - May 2015
The Free Software Foundation Europe newsletter looks at a secret Free Software action plan by the European Commission, interpretation of law restricting Free Software in Switzerland, Document Freedom Day, and much more.
Calls for Presentations
PGConf Silicon Valley CfP Now Open
PGConf Silicon Valley will be held November 17-18 in San Francisco, CA. The call for papers closes 15.CFP Deadlines: May 7, 2015 to July 6, 2015
The following listing of CFP deadlines is taken from the LWN.net CFP Calendar.
| Deadline | Event Dates | Event | Location |
|---|---|---|---|
| May 8 | July 31 August 4 |
PyCon Australia 2015 | Brisbane, Australia |
| May 15 | September 28 September 30 |
OpenMP Conference | Aachen, Germany |
| May 17 | September 16 September 18 |
PostgresOpen 2015 | Dallas, TX, USA |
| May 17 | August 13 August 17 |
Chaos Communication Camp 2015 | Mildenberg (Berlin), Germany |
| May 23 | August 22 August 23 |
Free and Open Source Software Conference | Sankt Augustin, Germany |
| May 23 | May 23 May 25 |
Wikimedia/MediaWiki European Hackathon | Lyon, France |
| May 31 | October 2 October 4 |
PyCon India 2015 | Bangalore, India |
| June 1 | November 18 November 22 |
Build Stuff 2015 | Vilnius, Lithuania |
| June 1 | July 3 July 5 |
SteelCon | Sheffield, UK |
| June 5 | August 20 August 21 |
Linux Security Summit 2015 | Seattle, WA, USA |
| June 6 | September 29 September 30 |
Open Source Backup Conference 2015 | Cologne, Germany |
| June 11 | June 25 June 28 |
Linux Vacation Eastern Europe 2015 | Grodno, Belarus |
| June 15 | August 15 August 22 |
DebConf15 | Heidelberg, Germany |
| June 15 | September 24 | PostgreSQL Session 7 | Paris, France |
| June 15 | November 17 November 18 |
PGConf Silicon Valley | San Francisco, CA, USA |
| June 17 | October 5 October 7 |
LinuxCon Europe | Dublin, Ireland |
| June 17 | October 5 October 7 |
Embedded Linux Conference Europe | Dublin, Ireland |
| June 19 | August 20 | Tracing Summit | Seattle, WA, USA |
| June 28 | August 28 September 3 |
ownCloud Contributor Conference | Berlin, Germany |
| June 28 | November 11 November 13 |
LDAP Conference 2015 | Edinburgh, UK |
| June 30 | November 16 November 19 |
Open Source Monitoring Conference 2015 | Nuremberg, Germany |
| July 5 | October 27 October 29 |
Open Source Developers' Conference | Hobart, Tasmania |
If the CFP deadline for your event does not appear here, please tell us about it.
Upcoming Events
EuroPython 2015
EuroPython will take place July 20-26 in Bilbao, Spain. You may now vote for talks and apply for financial aid. Talk voting will be open until May 15.Events: May 7, 2015 to July 6, 2015
The following event listing is taken from the LWN.net Calendar.
| Date(s) | Event | Location |
|---|---|---|
| May 6 May 8 |
German Perl Workshop 2015 | Dresden, Germany |
| May 7 May 9 |
Linuxwochen Wien 2015 | Wien, Austria |
| May 8 May 10 |
Open Source Developers' Conference Nordic | Oslo, Norway |
| May 12 May 13 |
PyCon Sweden 2015 | Stockholm, Sweden |
| May 12 May 14 |
Protocols Plugfest Europe 2015 | Zaragoza, Spain |
| May 13 May 15 |
GeeCON 2015 | Cracow, Poland |
| May 14 May 15 |
SREcon15 Europe | Dublin, Ireland |
| May 16 May 17 |
11th Intl. Conf. on Open Source Systems | Florence, Italy |
| May 16 May 17 |
MiniDebConf Bucharest 2015 | Bucharest, Romania |
| May 18 May 22 |
OpenStack Summit | Vancouver, BC, Canada |
| May 18 May 20 |
Croatian Linux User Conference | Zagreb, Croatia |
| May 19 May 21 |
SAMBA eXPerience 2015 | Goettingen, Germany |
| May 20 May 22 |
SciPy Latin America 2015 | Posadas, Misiones, Argentina |
| May 21 May 22 |
ScilabTEC 2015 | Paris, France |
| May 23 May 24 |
Debian/Ubuntu Community Conference Italia - 2015 | Milan, Italy |
| May 23 May 25 |
Wikimedia/MediaWiki European Hackathon | Lyon, France |
| May 30 May 31 |
Linuxwochen Linz 2015 | Linz, Austria |
| June 1 June 2 |
Automotive Linux Summit | Tokyo, Japan |
| June 3 June 5 |
LinuxCon Japan | Tokyo, Japan |
| June 3 June 6 |
Latin American Akademy | Salvador, Brazil |
| June 5 June 7 |
PyCon APAC 2015 | Taipei, Taiwan |
| June 8 June 10 |
Yet Another Perl Conference 2015 | Salt Lake City, UT, USA |
| June 10 June 13 |
BSDCan | Ottawa, Canada |
| June 11 June 12 |
infoShare 2015 | Gdańsk, Poland |
| June 12 June 14 |
Southeast Linux Fest | Charlotte, NC, USA |
| June 16 June 20 |
PGCon | Ottawa, Canada |
| June 22 June 23 |
DockerCon15 | San Francisco, CA, USA |
| June 23 June 26 |
Open Source Bridge | Portland, Oregon, USA |
| June 23 June 25 |
Solid Conference | San Francisco, CA, USA |
| June 23 June 26 |
Red Hat Summit | Boston, MA, USA |
| June 25 June 26 |
Swiss PostgreSQL Conference | Rapperswil, Switzerland |
| June 25 June 28 |
Linux Vacation Eastern Europe 2015 | Grodno, Belarus |
| June 26 June 27 |
Hong Kong Open Source Conference 2015 | Hong Kong, Hong Kong |
| June 26 June 28 |
FUDCon Pune 2015 | Pune, India |
| July 3 July 5 |
SteelCon | Sheffield, UK |
| July 4 July 10 |
Rencontres Mondiales du Logiciel Libre | Beauvais, France |
If your event does not appear here, please tell us about it.
Page editor: Rebecca Sobol