
Kernel development
Brief items
Kernel release status
The current development kernel is 3.17-rc1, released on August 16.Stable updates: 3.16.1, 3.15.10, 3.14.17, 3.10.53, and 3.4.103 were all released on August 14. The 3.15.10 update marks the end of support for the 3.15 kernels; users of that kernel should be thinking about moving on to 3.16.
An md/raid6 data corruption bug
Neil Brown, the MD maintainer, has sent out an alert for a bug which, in fairly abnormal conditions, can lead to data loss on an MD-hosted RAID6 array. "There is no risk to an optimal array or a singly-degraded array. There is also no risk on a doubly-degraded array which is not recovering a device or is not receiving write requests." RAID6 users will likely want to apply the patch, though, which is likely to show up in the next stable kernel update from distributors.
3.17 Merge window, part 3
Linus released 3.17-rc1 and closed the merge window for the 3.17 release on August 16. He had suggested that the merge window could be extended, but that's not how things turned out. Only a small number of changes made it into the mainline repository after last week's summary was written. User-visible changes merged in this time include:
- The xfs filesystem now requires a kernel built with 64-bit sector
numbers. There is also a sysfs directory for xfs now with a small
number of parameters mostly of use for filesystem testing.
- The NFS client now supports RCU-based lookups, speeding the task of
looking up files when the information is available in cache.
- New hardware support includes:
- Miscellaneous:
STi thermal controllers,
Allwinner A31 DMA controllers,
Renesas Type-AXI NBPF DMA controllers, and
TI DRA7xx PCIe controllers.
- Networking: APM X-Gene SoC-based Ethernet controllers.
- Miscellaneous:
STi thermal controllers,
Allwinner A31 DMA controllers,
Renesas Type-AXI NBPF DMA controllers, and
TI DRA7xx PCIe controllers.
In the end, 10,890 non-merge changesets found their way into the mainline repository during the 3.17 merge window. This cycle has now entered the stabilization phase; the final 3.17 release can be expected, if all goes well, sometime in early October.
Kernel development news
The 2014 Kernel Summit
The 2014 Kernel Summit was held on August 18-20 in Chicago, IL, USA. The format mirrored that of the last few years: a day of invitation-only discussion with a relatively small group, followed by a day of workshops. The final day consisted of relatively technical sessions open to all interested attendees.
Day 1
Discussions from the invitation-only day include:
- Error handling for I/O memory management
units: what do we do when DMA goes bad?
- Stable tree maintenance: what is the
condition of the stable tree and how can things be done better?
- The state of linux-next: how is the
kernel's integration tree doing and what could be improved?
- Kernel tinification: how can we make
the kernel work on the smallest of systems?
- What makes Linus happy (or not)?: this
year's guide to the care and feeding of the kernel's benevolent
dictator.
- Performance regressions: how is the
development community doing in the eternal battle against the
introduction of performance problems?
- Kernel self tests: creating a simple
set of self tests to quickly determine if a given kernel build runs
properly.
- Two sessions on review: how do we get
better review of new kernel ABIs? And, for that matter, how can we
get more reviewers in general?
- One year of Coverity work: using defect information from the Coverity scanner to improve the kernel.
And, of course, there is the obligatory group photo:
![[Group photo]](https://static.lwn.net/images/conf/2014/ks/group-sm.jpg)
Day 2
Unfortunately, LWN was unable to attend the workshop sessions. Attendees to various sessions have posted reports; we are collecting them here.
- Device model/driver
properties/ACPI_DSD session, posted by Darren Hart
- Testing by Paul McKenney. See also a followup by Shuah Khan.
- printk() (Paul McKenney)
- mount (Paul McKenney)
- Power management dependencies (Laurent
Pinchart).
- Power-aware scheduling (Morten Rasmussen).
Day 3
Many of the third-day sessions took the form of tutorials for tools like Coccinelle — valuable sessions, but difficult to write up in this format. Beyond that, though, this day also featured:
- The kernel.org update with an emphasis
on the new two-factor authentication system.
- The power-aware scheduling
miniconference; a report from Morten Rasmussen on the latest
developments in power-aware scheduling.
- A report from the networking miniconference; a whirlwind summary of what is happening in the networking subsystem.
Error handling for I/O memory management units
Traditionally the Kernel Summit focuses more on process-oriented issues than technical problems; the latter are usually deemed to be better addressed by smaller groups on the mailing lists. The 2014 Summit, however, started off with a purely technical topic: how to handle errors signaled by I/O memory management units (IOMMUs)?An IOMMU performs translations between memory addresses as seen by devices and those seen by the CPU. It can be used to present a simplified address space to peripherals, to make a physically scattered buffer look contiguous, or to restrict device access to a limited range of memory. Not all systems have IOMMUs in them, but there is a slow trend toward including them in a wider range of systems.
David Woodhouse started off by saying that, in the IOMMU context, there is
no generalized way of reporting errors. So drivers cannot easily be
notified if something goes wrong with an IOMMU. What does exist is
a certain amount of subsystem-specific infrastructure. The PowerPC
architecture has its "extended error handling" (EEH) structure that "only
![[David Woodhouse]](https://static.lwn.net/images/conf/2014/ks/DavidWoodhouse-sm.jpg "David Woodhouse") Ben Herrenschmidt understands," and the PCI subsystem has an error-handling
mechanism as well. But the kernel needs a coherent way to report errors
from an IOMMU to drivers regardless of how they are connected to the system.
There also needs to be a generalized mechanism by which an offending device
can be shut down to avoid crippling the system with interrupt storms.
Ben Herrenschmidt understands," and the PCI subsystem has an error-handling
mechanism as well. But the kernel needs a coherent way to report errors
from an IOMMU to drivers regardless of how they are connected to the system.
There also needs to be a generalized mechanism by which an offending device
can be shut down to avoid crippling the system with interrupt storms.
David presented a possible way forward, which was based on extending and generalizing the PCI error-handling infrastructure. It would need to be moved beyond PCI and given extra capabilities, such as the ability to provide information on exactly what went wrong and what the offending address was. He asked: does anybody have any strong opinions on the subject? This is the Kernel Summit, so, of course, opinions were on offer.
Ben started by saying that it is not always easy to get specific information about a fault to report. The response to errors — often wired into the hardware — is to isolate the entire group of devices behind a faulting IOMMU; at that point, there is no access to any information to pass on. Drivers do have the ability to ask for fault notification, and they can attempt to straighten out a confused device. In the absence of driver support, he said, the default response is to simulate unplug and replug events on the device.
David pointed out that with some devices, graphics adapters in particular, users do not want the device to stop even in the presence of an error. One command stream may fault and be stopped, but others running in parallel should be able to continue. So a more subtle response is often necessary.
Josh Triplett asked about what the response should be, in general, when something goes wrong. Should recovery paths do anything other than give up and reset the device fully? For most devices, a full reset seems like an entirely adequate response, though, as mentioned, graphics adapters are different. Networking devices, too, might need a gentler hand if error recovery is to be minimally disruptive. But David insisted that, almost all the time, full isolation and resetting of the device is good enough. The device, he said, "has misbehaved and is sitting on the naughty step."
Andi Kleen asked how this kind of error-handling code could be tested. In the absence of comprehensive testing, the code will almost certainly be broken. David responded that it's usually easy to make a device attempt DMA to a bad address, and faults can be injected as well. But Ben added that, even with these tools, EEH error handling breaks frequently anyway.
David asked: what about ARM? Will Deacon responded that there are no real standards outside of PCI; he has not seen anything in the ARM space that responds sanely to errors. He also pointed out that hypervisors can complicate the situation. An IOMMU can be used to provide limited DMA access to a guest, but that means exposing the guest to potential IOMMU errors. A guest may end up isolating an offending device, confusing the host which may not be expecting that.
Arnd Bergmann asked that any error-handling solution not be specific to PCI devices since, in the ARM world, there often is not a PCI bus involved. David suggested that the existing PCI error-handling infrastructure could be a good place to start if it could be made more generic. There are some PCI-specific concepts there that would have to be preserved (for PCI devices) somehow, but much of it could be moved up into struct device and generalized. After hearing no objections to that approach, David said he would go off and implement it. He will not, he noted dryly, be interested in hearing objections later on.
Next: Stable tree maintenance.
The stable tree
While much attention goes into the development of the mainline kernel, most users end up running something based on the stable tree, which incorporates important fixes after the mainline process has moved on. A session during the first day of the 2014 Kernel Summit, led by Greg Kroah-Hartman and Li Zefan, discussed the management of the stable tree and how things could be done better. In the end, it seems, there is little room for improvement at the moment.Greg started off by noting that, one year ago, he had asked developers to do a better job of ensuring that important patches make it to the stable tree. In that time, he said, things have gotten a lot better, to the point that he does not know of a single subsystem that is not doing it right. Important fixes from all over the kernel are now finding their way into the stable tree.
That said, he did note that he found it a bit strange that the 3.17-rc1
release had 200 patches marked for backporting to the stable tree. If the
patches are truly important fixes, they should not wait for -rc1; instead,
they should go into the mainline quickly. Dave Airlie suggested that the
problem is that "people are scared of Linus" and are holding their fixes
![[Li Zefan]](https://static.lwn.net/images/conf/2014/ks/Li-Zefan-sm.jpg "Li Zefan") for -rc1 whenever they are in doubt. Greg noted that some of those patches
are non-critical things like new device IDs, but others should perhaps be
tracked into the mainline more quickly.
for -rc1 whenever they are in doubt. Greg noted that some of those patches
are non-critical things like new device IDs, but others should perhaps be
tracked into the mainline more quickly.
Greg announced that he will no longer be managing the 3.4 long-term stable kernel; that task has been passed over to Li.
Dmitry Torokhov asked if there weren't perhaps too many patches going into the stable trees. Might it make sense, he asked, to split stable into two trees, one of which would be only fixes while the other would handle new-device enablement. Greg responded that, when looked at individually, every patch going into stable seems to make sense when it is added. As a percentage of the total patch flow into the kernel, even hundreds of patches going into the stable tree are a drop in the bucket.
Eric Biederman said that, over time, the stable kernels really do get more stable. Chris Mason added that, at Facebook, they have not seen a single regression caused by a patch added to the 3.10 stable tree.
Rusty Russell asked if developers should be even more aggressive about sending patches to the stable tree. Perhaps fixes for performance regressions should go there as well? Greg responded that performance fixes are already accepted into the stable trees; they seem to be wanted, so he will take them. Mel Gorman added that there has been a determined effort to get important performance fixes into the stable kernels in an attempt to reduce the performance deltas between various kernel versions. In particular, it is not desirable that stable releases perform notably worse than distributor kernels, which tend to have those performance fixes mixed in.
The subject of the extended stable kernels maintained by developers at
Canonical came up. Greg said that, for the most part, those kernels could
be ignored; Canonical is doing its own thing there. Peter Anvin complained
about the use of the same numbering space for Canonical's kernels; that, he
said, can be confusing. He would like to see those kernels named in a way that makes it
![[Greg KH]](https://static.lwn.net/images/conf/2014/ks/Greg-Kroah-Hartman-sm.jpg "Greg Kroah-Hartman") clear that they are not "official" stable releases. In response to a
question about hosting those kernels on kernel.org, Greg noted that he will
hand a stable kernel space over to any community developer in good
standing. Canonical's developers, he said, are not that; they do not do
work within the community. Since he cannot trust their work, he doesn't
want their kernels on kernel.org.
clear that they are not "official" stable releases. In response to a
question about hosting those kernels on kernel.org, Greg noted that he will
hand a stable kernel space over to any community developer in good
standing. Canonical's developers, he said, are not that; they do not do
work within the community. Since he cannot trust their work, he doesn't
want their kernels on kernel.org.
Andy Lutomirski asked how he could mark a patch as applying only to the 3.16 kernel; the answer is to put "# v3.16+" in the patch tags. The use of the "Fixes:" tag can also help a lot, Greg said. But, he added, if a patch has a "Fixes: tag for an old bug, that patch should be directed toward the stable tree; apparently that does not always happen. Rusty asked about patches for theoretical bugs that have not been reported by actual users; Greg said they can be submitted, and he takes about a quarter of them.
What about the Long-Term Support Initiative kernels? Darren Hart noted that kernel developers tend to scoff at those kernels, but, from his experience, they tend to reduce duplicate backports and are thus useful. Greg said that they can be seen as an "embedded Linux enterprise kernel" and that, most of the time, it's better to just use a newer kernel. Christoph Hellwig complained about the addition of out-of-tree code to those kernels, but Greg said that LTTng is the only out-of-tree patch in LTSI, and that everybody in the embedded space needs it. Mark Brown said that the short merge window for LTSI is problematic; Greg responded that patches could be sent to him anytime and they would get into LTSI when the window opened.
Getting back to the long-term kernels maintained by Greg, Josh Triplett said that it would be nice to know which kernels will be receiving long-term support ahead of time. The problem with advance notification, Greg said, is that "then people merge a lot of crap" to get it into that release. It was suggested that the announcement could be made after the -rc1 release, making the premature merging of unready code impossible, but, in the end, a few weeks additional notice is not going to change things much. In the end, he said, distributors who are wondering about which kernel will get long-term support should just talk to him.
Linus, jumping in for the first time this day, let it be know that he dislikes developers who try to game the timing of long-term kernels. Rather than wait until code is ready or fix it on time, they rely on the stable kernels to get fixes out to users eventually. It is, he said, just not good development to do things that way.
The session wound down with a question: rather than use stable kernels, should companies put current mainline kernels into their products? Olof Johansson responded that he has tried that and "has some battle scars" to prove it. He has seen regressions with mainline kernels, especially on older hardware, which tends not to see much mainline testing. Ben Herrenschmidt added that subsystems like multipath I/O often regress; upgrades cause things to break. Linus said that that sort of attitude tends to perpetuate the problem. This unwillingness to risk problems with mainline kernels is unlikely to change, though, so the stable kernel series is going to prove useful for some time yet.
Next: The state of linux-next.
The state of linux-next
Once the discussion of the stable tree had completed, the group at the 2014 Kernel Summit turned its attention to the most unstable tree of all: linux-next. This tree holds code that, for the most part, is destined to go into the mainline during the next merge window; its contents can change wildly over the course of a development cycle as patches are added and removed. Linux-next maintainer Stephen Rothwell provided an update on how this tree is doing.In general, Stephen said, about 90% of the code that shows up in the mainline during the merge window was in linux-next prior to the opening of the window. Is that good enough? He left that for the group to decide. He also noted that there are currently more than 220 trees feeding into linux-next, and wondered if that might be too many. About 25 of those, he said, are dedicated to urgent fixes and are probably OK. He is not so sure about the "preparatory trees" that feed patches into another tree that is also pulled into linux-next. Many of those trees are not as stable as he would like; the code found there may not really be ready for mainline, so the trees get shuffled and rebased a lot.
Related to the preparatory trees are the "lead-in" trees run by
sub-subsystem maintainers. The wireless networking and Bluetooth trees
were held up as an example. These trees are "mostly OK," Stephen said,
though some of them run on their own schedules. The Bluetooth tree, he
noted, acquired a bunch of new work during the merge window, a practice
![[Stephen Rothwell]](https://static.lwn.net/images/conf/2014/ks/StephenRothwell-sm.jpg "Stephen Rothwell") that Stephen discourages. If new patches flow into linux-next during that
time, it complicates the task of figuring out what hasn't been merged into
the mainline yet.
that Stephen discourages. If new patches flow into linux-next during that
time, it complicates the task of figuring out what hasn't been merged into
the mainline yet.
A significant change to linux-next is the addition of build-test coverage for the ARM architecture; until recently, only x86 and PowerPC were tested. Stephen expressed some amazement at how often an "allmodconfig" build test fails; sometimes, developers are putting code into linux-next that clearly has never been compiled. That runs counter to the rule that all linux-next code should be ready for the mainline. While an occasional build failure for an architecture like PowerPC might be understandable, he said, there really is no excuse for failing to build on x86; that is a fundamental test that every developer should be running. Linus added that he gets grumpy when that kind of code is directed his way as well.
Josh Triplett suggested that, perhaps, all code should have to go through a public build test before being accepted into linux-next. The problem there is that linux-next is that build test, for all practical purposes. Additionally, Fengguang Wu's automatic test system should be finding build problems. We don't, Stephen said, need a more formal process; we just need developers to pay a bit more attention.
Rafael Wysocki said that, while he appreciated the merge conflict resolution work that Stephen does, he would rather fix conflicts in his trees himself. The problem, Stephen said, is that when he hits a conflict in the process of pulling trees into linux-next, he does not have the time to contact the appropriate maintainer and get a fix from them. It's faster and easier just to deal with it himself. And, in any case, the conflict may come from somewhere else anyway. In general, Stephen said, he gets four or five conflicts on a normal day, which is not that hard to deal with. Just before the merge window, when the tree is big and everybody is trying to get their code in place, things get much worse, though. That can lead to twelve-hour days, leading Ted Ts'o to wonder if the job isn't getting too big for one person to do.
There is, Stephen said, still too much rebasing of trees that feed into linux-next. Sometimes it's unavoidable, but a tree should normally be in a finished state before being put into linux-next.
A developer asked: what should be done about a patch that has found its way into linux-next and which turns out to be bad? Should the tree containing that patch be rewritten, causing the bad patch to disappear from the change history entirely? Or is it better to simply revert the patch at the head of the tree? Linus answered that dropping the patch (and rewriting the tree) is, essentially, a rebasing of the tree — and he tends not to respond well when asked to pull a just-rebased tree. There can be value in doing that; it makes the history cleaner. But it should not be done just before sending a pull request; at that point the patch should just be reverted. Having the patch and the revert in the history is embarrassing, he said, but in the end it's fine. Unless, he added, your tree has more reverts than commits, in which case there may be a problem.
While things can always be improved, it would appear from Stephen's report that the linux-next tree is working reasonably well. In the years that it has been operating, it has become a vital part of the kernel development process, helping the merge window (and the whole development cycle) to go more smoothly.
Next: Kernel tinification.
Kernel tinification
Josh Triplett started his 2014 Kernel Summit session with an assertion: saying that "Linux runs on everything from cellphones to supercomputers" is trite and uninformative. In 2014, he said, a smartphone is not an embedded system. He would like to convince kernel developers to pay a bit more attention to the needs of real embedded systems — those with only a few megabytes of flash and a tiny amount of memory. The Linux kernel, he says, has gotten far too big to run comfortably on such systems; he would like to build a consensus in favor of a "tinification" effort to shrink things back down.
![[Size chart]](https://static.lwn.net/images/conf/2014/ks/size-chart.jpg) He put up a chart showing the in-memory size of the smallest possible
kernel over time. That size, he said, has increased with almost every
release. It rarely goes down; about the only time was when developers figured
out how to configure out the TTY layer. A growing kernel makes it hard for
the people who are trying to build tiny systems, forcing them to go to a
proprietary real-time operating system instead. It should be possible to
use Linux on such systems, he said, but we have to make it possible to
build smaller kernels — perhaps as much as an order of magnitude smaller.
He put up a chart showing the in-memory size of the smallest possible
kernel over time. That size, he said, has increased with almost every
release. It rarely goes down; about the only time was when developers figured
out how to configure out the TTY layer. A growing kernel makes it hard for
the people who are trying to build tiny systems, forcing them to go to a
proprietary real-time operating system instead. It should be possible to
use Linux on such systems, he said, but we have to make it possible to
build smaller kernels — perhaps as much as an order of magnitude smaller.
Some people apparently suggest the use of 2.4 kernels for such use cases. The 2.4 kernel is indeed quite a bit smaller, but it still does not solve the problem. Just because somebody is using tiny hardware does not mean that they can do without (some of) the capabilities found in current kernels.
Some notes on building tiny kernels can be found at tiny.wiki.kernel.org.
Part of the problem, Josh said, is that the kernel is full of mandatory subsystems that cannot be configured out. If somebody wants to, say, build a kernel without support for signals, it should be possible for them to do so. We also suffer from a lack of good metrics on kernel size; most developers are blissfully unaware of how their changes affect the size of the kernel.
Ted Ts'o mentioned a related discussion on the ext4 development list. Tiny systems often run without a memory management unit (MMU), but most filesystems do not work in a kernel configured to operate without an MMU. Is it worth the trouble to make filesystems work on such systems? After all, the high-end filesystems are developed for large systems and scalability; they may not have much to offer for tiny systems. Others agreed, noting that tiny systems often do not even have the block layer built into them. Josh said that there may be value in ext4 support, though. Among other things, there is work afoot to use Linux as a bootloader on small systems; ext4 support is important there.
Grant Likely said that, while he is happy to see patches to enable the building of smaller kernels, he is worried about how all of the configuration options would work. We can't handle the complexity of the options we have now. Also, most kernel development is focused on the addition of new features. There is not a lot of pressure to make the kernel smaller, so nobody is working on it. The users who want this capability, he said, are not having a big impact on kernel development.
Peter Zijlstra agreed that more configuration options would not be welcome; we cannot, he said, even build-test all of the combinations of the current options. There was some talk of trying to hide many of the options and to instead use dependencies to select the right features when needed. But there are a number of practical difficulties here, especially in situations where a number of kernel subsystems could conceivably satisfy a given dependency.
Grant said, though, that to talk about configurations and dependency resolution was to get lost in side issues. People who are building tiny systems will have no choice but to get into the details of how their kernels are configured. What is needed are developers who are actively working on size issues. While other developers may have agreed with this point of view, the discussion quickly moved back to configuration issues and, in particular, the feared explosion of the size of the configuration space.
It was suggested that a user of a tiny system could provide the
configuration system with a list of the system calls that will actually be
used on the deployed system. The configuration code would then decide how
to create a minimal kernel that provides the needed capabilities. Ted said
![[Josh Triplett]](https://static.lwn.net/images/conf/2014/ks/JoshTriplett-sm.jpg "Josh Triplett") that this might be a good project for somebody to work on out of tree. In
the end, he said, kernel developers simply do not have the time to test
this kind of feature.
that this might be a good project for somebody to work on out of tree. In
the end, he said, kernel developers simply do not have the time to test
this kind of feature.
In general, Ted asked Josh, what would he like from the group? Josh answered that he would like developers to start seeing size increases as a regression and to be willing to accept reasonable patches to fix those regressions. Tejun Heo responded that this was not reasonable, given all of the other constraints that kernel developers must deal with. Worrying about size will just make the whole task even harder.
Tim Bird said that at least some of this task could be automated. There has been some research work on the elimination of unneeded code. In the more immediate future, he would like to see the link-time optimization (LTO) work merged into the kernel. Josh agreed that LTO is useful; among other things, it should enable the removal of a number of size-oriented configuration options. Andi Kleen, who has done the bulk of the LTO work so far, said that it can help, but that the code has to be designed correctly to get the most value from LTO. "Crazy callback dependencies," he said, will thwart LTO. Linus said that, for now, he does not trust the LTO implementation in the current toolchain, so he does not want to let the changes into the kernel. Toolchain bugs can create no end of obscure problems, and he does not want to see those in the kernel. Until that code stabilizes, LTO will remain outside.
It was also suggested that it would help to point to a real target or two for tiny kernels. As it is, developers have little understanding of the type of system that is being talked about. David Woodhouse suggested that the QEMU emulator could be set up as a reference target, but Grant asserted that a QEMU configuration is easy for developers to ignore. What is needed is a real hardware target.
Ted pointed out that "you get what you measure." What is needed, he said, is more information on kernel bloat and what is causing it. Andi responded that developers do not really care about this issue; size issues are simply not on their radar. Chris Mason suggested that Fengguang Wu's build system could start providing size-change information; that would put developers more in the position of intentionally choosing to make the kernel bigger. Andi agreed that size increases are usually done by accident; making them more visible might help.
As the session reached a close, Josh suggested that it would be useful to have a configuration option to turn absolutely everything off. It would not normally be possible to re-enable specific items, but developers working on tiny systems could apply a patch to get around that limitation. Once they have done that, though, the only way the development community would be interested in a problem report would be if it came accompanied with a patch to fix the problem.
What will come of this discussion remains to be seen. But, as Josh pointed out, if nothing else, developers are starting to talk about the problem, even if they are just scoffing. One has to start somewhere.
Next: What makes Linus happy (or not)?
What makes Linus happy (or not)?
Any self-respecting development community should be attentive to the needs of its benevolent dictator. To that end, a slot at the 2014 Kernel Summit was given to Linus Torvalds, who talked a bit about the things that make him happy — or not.He started by saying that, in general, he tries to avoid having the merge window be open while he is traveling. But, for the last three releases, that is exactly what has happened. In that situation, such as happened for the 3.17 merge window, he appreciates it even more than usual when subsystem maintainers are timely with their pull requests. Individual developers, he suggested, should also be happier when that happens. In general, he said, subsystem maintainers should be responsive to their contributors.
Linus said that he tries to respond quickly to pull requests. But, he
said, submissions that come in the form of patches in email tend to go to
the end of the queue. He still accepts patches — that is something that he
promised to do — but pull requests go in first. Partly that is because
pull requests are simply easier to find in his email stream; subsystem
![[Linus Torvalds]](https://static.lwn.net/images/conf/2014/ks/LinusTorvalds-sm.jpg "Linus Torvalds") maintainers, he said, should make a point of putting "pull" in their
subject lines somewhere to help make that happen. In any case, he said,
there is only one significant subsystem maintainer (Andrew Morton) who
still sends patches rather than pull requests.
maintainers, he said, should make a point of putting "pull" in their
subject lines somewhere to help make that happen. In any case, he said,
there is only one significant subsystem maintainer (Andrew Morton) who
still sends patches rather than pull requests.
Last year, he said, he complained about the lack of good changelog messages with merge commits. Since then, things have gotten a lot better. For 3.17, he pulled in about 500 merges done by others. Almost all of them looked good, with a proper message saying why the merge was done. So this problem appears to have mostly gone away.
One thing that makes him mad, he said, was being dismissive of regressions. If somebody responds to a regression report by telling the reporter to upgrade their user space, he will come down on them. He also has no tolerance of forged email messages. He recently got a patch submission consisting of messages with forged return addresses. The intent (to ensure proper credit for the author of each of the patches in the series) was good, but the technique used was reprehensible. The message was clear: do not send forged emails to Linus if you want to get a good response.
Mauro Carvalho Chehab asked whether pull requests should be GPG-signed. Linus answered that the emails containing the requests should not be signed. The signature, instead, should appear in the signed tag used to identify the branch to be pulled. The trust is in the Git source code management system, the kernel's web of trust, and in the management of kernel.org; signing email messages does not add much.
He complained a little bit about the problem of slow subsystem maintainers who cause their contributors to become frustrated. Those contributors will sometimes go directly to Linus with their own pull requests. That causes Linus to be caught in the middle, a position that he does not like. In any given case, the subsystem maintainer may be failing to process patches in a timely manner. But they might also have a good reason to delay the application of specific patches, in which case Linus does not want to get involved. Still, he said, some subsystems seem to have this kind of problem rather more often than others. Some of those subsystems might benefit from a switch to a multi-maintainer model like the one used for the x86 and arm-soc trees.
In general, though, Linus appeared to be reasonably content with the state of the development community and his role in it. There does not appear to be a need for much to change.
Next: Performance regressions.
Kernel performance regressions
Performance regressions are some of the nastiest problems that can afflict the Linux kernel. Often they go unnoticed when they are introduced. Some time — often years — later, some large user attempts to upgrade to a new kernel and notices that things have slowed down considerably. By then, the original problem (or series of problems) may be hard to track down. For this reason, performance regressions are a common Kernel Summit topic, and 2014 was no exception. What might be exceptional is that, it would appear, the kernel community is getting far better at avoiding the creation of new performance problems.Chris Mason started off the session by noting that, at his employer (Facebook), Linux is used anywhere that it is faster than FreeBSD — which, he said, is everywhere. Facebook tends to keep its working sets in RAM, so its workloads tend to be CPU-, memory-, or network-bound. Performance is an important concern there, so the company maintains extensive metrics of how its systems and applications are performing.
Most of the production systems at Facebook are currently running on 3.10-stable kernels with about 75 additional patches. There are systems running older kernels there, but the Facebook kernel group is slowly forcing them to move to more recent systems, mostly through the simple expedient of refusing to fix problems in older kernels.
When Facebook first moved to 3.10, its developers felt the usual concerns
about performance
regressions. As it turned out, this kernel had far fewer
problems than expected — but some problems still popped up. There was one
10% performance regression in the
![[Chris Mason]](https://static.lwn.net/images/conf/2014/ks/ChrisMason-sm.jpg "Chris Mason") IPv6 stack, but somebody else had already fixed it upstream before Chris
was able to track it down. Beyond that, there are some issues with CPU
frequency governors, which tend to choose lower-than-optimal frequencies
and create unwanted latencies. So Facebook is currently using the
ACPI-based CPU frequency governor while trying to figure out how to get the
newer intel_pstate code to do the right thing.
Another problem is contention for the futex bucket lock, which has
increased in newer kernels. Within Facebook, Chris has fixed this problem
by moving some significant work out of the critical section protected by
that lock. Rik van Riel suggest that increasing the number of buckets can
also help.
IPv6 stack, but somebody else had already fixed it upstream before Chris
was able to track it down. Beyond that, there are some issues with CPU
frequency governors, which tend to choose lower-than-optimal frequencies
and create unwanted latencies. So Facebook is currently using the
ACPI-based CPU frequency governor while trying to figure out how to get the
newer intel_pstate code to do the right thing.
Another problem is contention for the futex bucket lock, which has
increased in newer kernels. Within Facebook, Chris has fixed this problem
by moving some significant work out of the critical section protected by
that lock. Rik van Riel suggest that increasing the number of buckets can
also help.
So what happened when Chris tried running a Facebook workload on a 3.16 kernel? The numbers, he said, were "really good." The workload on that kernel gets 2.5% more queries per second and shows 5% lower latency. It does, however, also use about 4.5% more time in the kernel. That is after applying Chris's futex bucket lock fix; otherwise more than half of all the system time was spent contending for that lock and the system was unusable.
Going back to the company-wide 3.10 migration, Chris repeated a point from an earlier session: there have been zero regressions caused by patches from the stable tree. They have seen a few problems with the out-of-memory killer locking up the machine when killing POSIX-threads-based programs; that problem has been fixed upstream. There is also a case where combining direct and buffered I/O on a file can cause data corruption, leaving zero-filled pages in the page cache. Chris expressed surprise that existing tests did not find this problem, especially since it's not even caused by a race condition. He plans to look at the xfstests suite to figure out why this problem is not being caught.
But in general, he said, going to 3.10 was the easiest kernel move ever.
In a digression from the main topic, Arnd Bergmann asked about the additional patches that Facebook applies to its kernel. Chris responded that one of the more significant ones speeds the task of getting a thread's CPU usage by moving the relevant system calls into the VDSO area. That code, he said, should go upstream soon, but his forward port needs fixing up first; he "will not admit to having worked on it" in its current state. Another one allows the memory management system to avoid zeroing pages in memory-mapped regions during a page fault; he allowed as to how that one might be hard to send upstream. There is also a change to reduce the amount of IPv6 routing table information exported via /proc. The company runs its entire internal network on IPv6, so that routing tables are very large; it seems that Java programs have a tendency to query that information and slow everything down.
![[Jan Kara]](https://static.lwn.net/images/conf/2014/ks/JanKara-sm.jpg "Jan Kara") Getting back to performance issues, Jan Kara, who is working on
stabilizing 3.12 for the SLES 12 release, agreed that things have
gotten easier recently. His biggest concern seemed to be changes in
behavior that benefit some workloads at the expense of others. These
changes are not necessarily bad, unless, of course, you are one of the
people whose systems slow down. He pointed to changes in the CFQ I/O
scheduler and the NUMA balancing work as examples of this kind of change.
Getting back to performance issues, Jan Kara, who is working on
stabilizing 3.12 for the SLES 12 release, agreed that things have
gotten easier recently. His biggest concern seemed to be changes in
behavior that benefit some workloads at the expense of others. These
changes are not necessarily bad, unless, of course, you are one of the
people whose systems slow down. He pointed to changes in the CFQ I/O
scheduler and the NUMA balancing work as examples of this kind of change.
Andi Kleen asked why Chris thought that things were getting better. After all, the kernel process is certainly not slowing down. James Bottomley echoed that question, wondering why regressions are declining when we have not even been tracking them for the last few years. There appear to be a few aspects to the answer, but the most significant factor seems to be easy to identify: there is a lot more performance testing going on now than there was in the past. If a performance problem is introduced, it is far more likely to be caught and fixed long before it finds its way into a stable kernel release.
Chris added that both Red Hat and SUSE have recently gone through their enterprise distribution stabilization cycles; the extra focus on fixing problems certainly helped to stabilize things. Mel Gorman added that a number of hardware vendors have been introducing new hardware platforms. They put a lot of effort into making their systems go fast, but everybody benefited from the work. But that, he warned, might be a one-time boost that will not always be present.
Chris closed the session by noting that 3.10, in the end, is the fastest kernel ever run at Facebook. The developers in the room, who have perhaps grown used to being admonished over their tendency to introduce performance regressions, can only have been cheered by that news.
Next: Kernel self tests.
Kernel self tests
Shuah Khan started off her session at the 2014 Kernel Summit by noting that she has been helping with the process of testing stable kernel releases for some time. That testing is mostly of the build-and-boot variety, but it would be nice to be able to test kernels a bit more thoroughly than that. If there were a simple set of sanity tests that any developer could run, perhaps more regressions could be caught early, before they can affect users. The result of her work toward that goal is a new make target called "kselftest" in the kernel build system.There is a minimal set of tests there now; going forward, she would like to increase the set of tests that is run. We have lots of testing code out there, she said; it would be good to make more use of it. But she would like help in deciding which tests make sense to include with kselftest. The goal, she said, is to make things run quickly; it's a basic sanity test, not a full-scale stress test.
Ted Ts'o asked what the time budget is; what does "quickly" mean? Shuah
replied that she doesn't know; the current tests run in well under ten
minutes. That time could probably be increased, she said, but it should
not grow to the point that developers don't want to run the tests. Mel
![[Shuah Khan]](https://static.lwn.net/images/conf/2014/ks/ShuahKhan-sm.jpg "Shuah Khan") Gorman noted that his tests, if run fully, take about thirteen days —
probably a bit more than the budget allows. Paul McKenney added that the
full torture-test suite for the read-copy-update subsystem runs for more
than six hours. At this point, Shuah said that her goal is something
closer to 15-20 minutes.
Gorman noted that his tests, if run fully, take about thirteen days —
probably a bit more than the budget allows. Paul McKenney added that the
full torture-test suite for the read-copy-update subsystem runs for more
than six hours. At this point, Shuah said that her goal is something
closer to 15-20 minutes.
Josh Triplett expressed concerns about having the tests in the kernel tree itself. It could be hard to use bisection to find a test failure if the tests themselves are changing as well. Perhaps, he said, it would be better to fetch the tests from somewhere else. But Shuah said that would work against the goal of having the tests run quickly and would likely reduce the number of people running them.
Darren Hart asked if only functional tests were wanted, or if performance tests could be a part of the mix as well. Shuah responded that, at this point, there are no rules; if a test makes sense as a quick sanity check, it can go in. What about driver testing? That can be harder to do, but it might be possible to put together an emulator that simulates devices, bugs and all.
Grant Likely said that it would be nice to standardize the output format of the tests to make it easier to generate reports. There was a fair amount of discussion about testing frameworks and test harnesses. Rather than having the community try to choose one by consensus, it was suggested, Shuah should simply pick one. But Christoph Hellwig pointed out that the xfstests suite has no standards at all. Instead, the output of a test run is compared to a "golden" output, and the differences are called out. That makes it easy to bring in new tests and avoids the need to load a testing harness on a small system. Chris Mason agreed that this was "the only way" to do things.
The session closed with Shuah repeating that she would like more tests for the kselftest target, along with input about how this mechanism should work in general.
Next: Two sessions on review.
Two sessions on review
Like almost every other free software project out there, the kernel has a fundamental problem: not enough reviewers. Some areas of development need more review than others; at the top of the list must be the creation of binary interfaces for user space, since those interfaces must be maintained for a very long time. But the problem goes beyond ABI definition. Two sessions at the 2014 Kernel Summit looked at the issue of review and how it can be improved.
ABI changes
The first session, led by Michael Kerrisk and Andy Lutomirski, was concerned with the ABI issue in particular. Michael started by saying that, whenever he gets around to testing a new system call, he finds a bug 50% of the time. Christoph Hellwig remarked that the 50% number meant he wasn't looking hard enough. The point being made was that there is clearly not enough review and testing of code that is going out the door in a stable release. Indeed, sometimes there has been no testing at all. The recvmmsg() system call, Michael said, was implemented with a timeout value that cannot possibly have done anything sensible in the initial release.Sometimes we change ABIs as well, often without meaning to. For example, with the inotify interface, the IN_ONESHOT option in early kernels did not trigger the IN_IGNORED option; in later kernels that behavior has changed.
There is, he said, no specification for new ABIs, a fact which makes them
hard to review and test. The lack of a specification also leads to subtle
implementation problems. Again citing inotify as an example, Michael
talked about the difficulties involved in tracking files that move between
![[Michael and Andy]](https://static.lwn.net/images/conf/2014/ks/Michael+Andy-sm.jpg "Michael Kerrisk, Andy Lutomirski") directories; see this article for details.
There are no man pages for most new system calls and not enough reviewers,
with the result that questionable designs get through. The
O_TMPFILE option serves as a good example, Michael said; beyond
its other problems, there should also have
been consideration given to
implementing that functionality as a separate system call.
directories; see this article for details.
There are no man pages for most new system calls and not enough reviewers,
with the result that questionable designs get through. The
O_TMPFILE option serves as a good example, Michael said; beyond
its other problems, there should also have
been consideration given to
implementing that functionality as a separate system call.
Andy added that a specification is good, but a unit test for a new ABI is also a good thing to have. At this point, Peter Zijlstra asked if maybe the Linux Test Project would be a better place than the kernel tree for unit tests. But LTP is concerned with testing more than just system calls, and many kernel developers see the LTP system as a big extra thing that they would have to install.
Ted Ts'o observed that developers must have tests for the new features they have. Otherwise they would not be exercising the expected level of diligence in their work. Dave Airlie added that it would be good to have those tests in the kernel tree. He also suggested that, perhaps, the community should insist on the existence of a man page for any new system call before it could be added to the mainline. Michael responded that this has been tried before, without much success. But, it was pointed out, all four new system calls added in 3.17 came with manual pages.
Ben Herrenschmidt pointed out that system calls are just the tip of the iceberg. The kernel's ABI includes other aspects, such as ioctl() calls, sysfs, netlink, and more.
A topic that came up repeatedly is that any patch changing the kernel ABI should be copied to the linux-api mailing list. Perhaps, it was suggested, it should be the subsystem maintainers' duty to ensure that this copying happens when needed. Josh Triplett suggested that the get_maintainer script could be modified to make that happen, but that idea was not received all that warmly. That script tends to add lots of unrelated recipients to patch mailings and is not universally popular among kernel developers.
Peter Anvin made the claim that the linux-api list simply is not working. Perhaps it would be better, he said, to just merge the man pages into the kernel tree so that the code and documentation could be patched together. Michael responded that this idea has come up before. There are advantages and disadvantages to it. On the down side, there is a lot of material in the man pages that does not describe the kernel interface. The man pages are documentation for application developers, not for kernel developers, so they cover a lot of glibc interfaces, wrappers around system calls, and more.
The discussion wound down with some repeated suggestions that maintainers should insist on man pages before accepting new system calls into the kernel. The plea to copy the linux-api list for changes affecting the kernel ABI was also repeated. For a while, at least, kernel developers may try to do better, but no true solution to the problem was found at this session.
Getting more reviewers
James Bottomley stepped up to run a more general discussion on the problem of patch review. How, he asked, can we increase the amount of review that code going into the mainline gets? Are there any new ideas out there on how the kernel's review process can be improved? No answers resulted, but the session did cover some of the mechanics of how review is performed.
Peter Zijlstra said that he has been getting patches with bogus
Reviewed-by tags. "Bogus," in this case, means that no in-depth
review of the code has actually happened. Often, these tags come from
![[James Bottomley]](https://static.lwn.net/images/conf/2014/ks/JamesBottomley-sm.jpg "James Bottomley") other developers working for the same company as the patch author, but not
always. James said that he ignores Reviewed-by tags unless they
are offered in an email that has substantive comments in it.
other developers working for the same company as the patch author, but not
always. James said that he ignores Reviewed-by tags unless they
are offered in an email that has substantive comments in it.
Darren Hart said, though, that these tags can be the result of internal review that happens before patches are posted on a public list. In some companies, at least, this review process is serious and rigorous; it makes sense to document those reviews in the patch. Dave asked why the process has to be done internally; why not expose the whole process on the public lists? Darren answered that, with almost any project, it is natural to go for "small-group consensus" before facing the wider world.
James added that he is often suspicious of same-vendor reviews, but they are not necessarily invalid. It is really a matter of how much one trusts the specific reviewers involved.
He went on to ask a general process question: how much can a patch change before a Reviewed-by tag needs to be reviewed? A white-space change probably should not bring about a need for a new review, but substantial changes to how the patch works should. There were some differences of opinion in the room about just where the line should be drawn; in the end it seems to come down to common sense and the subsystem maintainer's opinion on the matter.
The session ended with Linus jumping in and saying that, in the end, the Reviewed-by, Acked-by, and Cc tags all mean the same thing: the person named in the tag will be copied on the report if the patch turns out to be buggy. Some developers use one tag, while others use a different one, but there is no real difference between them. The session closed with some general disagreement over the meanings of the different tags — and no new ideas on how to get more review of kernel code.
Next: One year of Coverity work.
One year of Coverity work
For the last year, Dave Jones has been working with the Coverity scanner to identify and fix possible bugs in the kernel. Like many developers, he worried that things could get worse over time; with all the code that is going into the kernel, there must be a lot of defects coming in as well. But the actual news turns out to be a bit better than that.What Dave feeds to Coverity is a "kitchen-sink build" with almost everything enabled. Where there is a configuration choice to be made, he tries to choose like a distributor would. The end result is that the kernel he builds has some 6,955 options selected. Running the scanner on this kernel takes several hours. Indeed, Dave has been keeping Coverity busy enough that the company eventually set up a dedicated server for kernel runs, enabling him to do two or three runs each day.
When Dave ran a scan of the 3.11 kernel, he ended up with a "defect density" of 0.68 per thousand lines of code — somewhat above the company's "open-source average" of 0.59. The results since then look like this:
Kernel Defect
density3.11 0.68 3.12 0.62 3.13 0.59 3.14 0.55 3.15 0.55 3.16 0.53
The current defect density, after the closing of the 3.17 merge window, is 0.52. So things have consistently gotten better over time.
He has put together a ranking of the areas in the kernel with the most defects. At the top of the list is the staging tree. That, he said, is good; if any other subsystem were worse than staging, that would indicate a real problem. Most of the other entries in the list were in the driver tree, which is not surprising; that is where most of the code is.
The biggest single issue raised by Coverity, he said, was dead code. Sometimes the warning makes sense, but it is not always correct. Some code will be unreachable due to configuration choices, for example. Second on the list was a failure to check return values; that, too, may or may not be a real bug, depending on the situation. The third item on the list — checking for a null pointer after the pointer has already been dereferenced — is clearly bad news and needs to be fixed.
Also scary are the static buffer overrun errors. These can be "nasty," and
there are too many of them, though the situation is getting better. These,
too, are not always bugs; the networking layer, for example, performs
![[Dave Jones]](https://static.lwn.net/images/conf/2014/ks/DaveJones-sm.jpg "Dave Jones") tricks with its skb data structures that look like buffer overruns
but in reality are not. Coverity also flags a large number of resource
leaks; unsurprisingly, these are usually found in error paths.
tricks with its skb data structures that look like buffer overruns
but in reality are not. Coverity also flags a large number of resource
leaks; unsurprisingly, these are usually found in error paths.
There are numerous other classes of potential errors. Some of them, such as "statement with no effect," tend to be harmless and may well be intentional. For example, assigning a variable to itself has no effect, but it was evidently an effective way of shutting down "possibly uninitialized" warnings from the compiler in the past. Others, like unchecked use of data from user space, can be more serious; in this case, most of the offending uses are behind capability checks and are thus not immediately exploitable.
The good news, Dave said, is that there are now less than 50 use-after-free errors flagged in the kernel. Various other classes of "dumb" errors have been nearly eliminated from the kernel as well. Dave said he keeps a close eye on those; when one pops up in a new kernel, he tries to get it fixed quickly.
Ted Ts'o asked how many of the issues flagged by Coverity are real bugs. Dave's feeling is that only a small minority of the reports indicate serious bugs. If one is interested in security issues, he said, the Trinity fuzz tester has found more of them than Coverity has.
What about ARM coverage? The commercial Coverity product has it, but the free version for the open source community does not. In truth, Dave said, if the code can be made to compile on an x86 compiler, Coverity will scan it. So he has pondered approaches like commenting out all of the inline assembly in the ARM tree and scanning the result. That is a project for the future, though.
Other developers can have a look at the Coverity results if they want to help to fix the reported problems. It's a matter of going to scan.coverity.com and signing up for the "Linux" project. Then drop a note to Dave, and he will approve access to the results. As is usually the case, more eyes on these results should lead to a better kernel in the long run.
Axiomatic validation of memory barriers and atomic instructions
Although memory barriers and atomic instructions are less obscure than
they once were, they can still be rather confusing.
The need for atomic instructions is easy to see: if multiple CPUs execute
a++ simultaneously, some increments could be lost.
For example, if the initial value of a was zero, then all
(say) eight CPUs might concurrently load zero, add one to it, and then all
store the value one, rather than the correct value of eight.
In contrast, atomic_inc(&a) would faithfully record each
and every increment to a.
To see the need for memory barriers, keep in mind that both the compiler
and the CPU can cause memory-reference instructions to be reordered.
It is important to remember that even strongly ordered systems such
as x86 and the IBM Mainframe still do some reordering, namely, allowing
prior stores to be executed after subsequent loads.
For example, consider the following x86 litmus test, with x
and y both initially zero:
CPU 0 CPU 1
----- -----
mov [x],$1 mov [y],$1
mov eax,[y] mov eax,[x]
It is possible for both CPUs' eax registers to be equal
to zero at the end of this test, because both of the loads can be executed
before either of the stores. (In fact, this outcome could occur even if
just one of the loads was executed before both stores.)
To prevent this reordering,
we can insert mfence instructions as follows:
CPU 0 CPU 1
----- -----
mov [x],$1 mov [y],$1
mfence mfence
mov eax,[y] mov eax,[x]
These added mfence instructions ensure that at least one
of the CPUs will end up with a non-zero eax register.
But this leads to the question: “Exactly where do I need to place memory-barrier instructions?” For most developers, even Linux kernel hackers, the answer is “Nowhere.” The reason for this reassuring answer is that most synchronization primitives already contain the needed memory barriers. Therefore, if you use locks, sequence counters, atomic operations, or read-copy-update (RCU) in the intended manner, you don't need to add any explicit memory-barrier instructions. Instead, the required memory-barrier instructions are included in these synchronization primitives.
Of course, if you are writing tricky code (in which case, you should
think twice) or if you are writing your own synchronization primitive
(in which case you should also think twice), you will need to add your
own memory barriers and atomic instructions.
One indispensable source of help is the documentation in
Documentation/atomic_ops.txt and
Documentation/memory-barriers.txt.
You most definitely need to read and understand these documents
before using atomic operations or explicit memory-barrier instructions.
armmem/ppcmem tool
Once you have read this documentation, another source of help is the
armmem/ppcmem
tool discussed in an
LWN article
that appeared in 2011.
This tool has been extremely helpful for validating short sequences of
critical code for the Linux kernel and elsewhere; however, it can be
a bit slow.
For example, consider the “independent reads of independent writes”
(IRIW) litmus test, in which one thread (call it “P0”)
writes the value 1 to variable x, another thread
(P1) writes the value 1 to variable y,
a third thread (P2) reads x then y separated
by a full barrier, and a fourth thread (P3) reads these two variables
in the opposite order.
Both x and y are initially zero.
The corresponding PowerPC litmus test is as follows:
1 PPC IRIW.litmus
2 ""
3 (* Traditional IRIW. *)
4 {
5 0:r1=1; 0:r2=x;
6 1:r1=1; 1:r4=y;
7 2:r2=x; 2:r4=y;
8 3:r2=x; 3:r4=y;
9 }
10 P0 | P1 | P2 | P3 ;
11 stw r1,0(r2) | stw r1,0(r4) | lwz r3,0(r2) | lwz r3,0(r4) ;
12 | | sync | sync ;
13 | | lwz r5,0(r4) | lwz r5,0(r2) ;
14
15 exists
16 (2:r3=1 /\ 2:r5=0 /\ 3:r3=1 /\ 3:r5=0)
Line 1 identifies this as a PowerPC litmus file, and gives it the name “IRIW.litmus”. An ARM litmus file would, of course, substitute “ARM” for the above “PPC”. Line 2 provides a place for an alternative name for the test, which you will usually want to leave blank as shown. Comments may be inserted at this point, as shown on line 3, using the OCaml (or Pascal) syntax of “(* *)”. These comments can span multiple lines if desired.
Lines 4-9 provide initial values for the machine registers,
and are of the form “P:R=V”,
where “P” is the process identifier,
“R” is the register identifier, and “V” is the
value.
For example,
Process P0's register r1 initially contains the value 1,
and its register r2 initially contains the address of
variable x.
Uninitialized variables default to the value zero, so that,
in the example,
x and y are both initially zero.
If desired, x and y can be initialized as well,
for example, adding a “x=1; y=2;” after line 4
would initialize x to the value one and y to
the value two.
Line 10 provides identifiers for the four processes, and must be of the form “PN” numbered consecutively starting from zero. Strict, perhaps, but it does help avoid confusion.
Lines 11-13 contain the code, so that P0 and P1 do their
respective stores, and P2 and P3 do their loads in opposite orders,
separated by a full memory barrier in the form of a sync
instruction.
Finally, lines 15 and 16 contain the assertion, which in this case will trigger if P2 and P3 see the two stores from P0 and P1 happening in different orders.
Running this example using the full state-space search tool ppcmem gives the correct answer, namely that the assertion cannot fire. Automatic computation of this result is a great improvement over the alternative of poring over manuals and, in fact, armmem/ppcmem has been an invaluable aid in tracking down several Linux kernel issues over the past few years. However, armmem/ppcmem does take about 14 CPU hours to compute this result, and also requires about 10GB of main memory to hold the state space. Of course, 14 hours is a great improvement over the weeks or months required by manual methods, but these two kernel hackers are impatient and prize quicker answers to hard questions.
herd tool
Jade Alglave and Luc Maranget, who were members of the
original group
behind ppcmem, were joined by Michael Tautschnig in some
recent work [PDF]
that replaces the full state-space search with an
axiomatic, event-based approach.
This axiomatic approach can greatly reduce the time required to analyze a
particular code fragment because its use of partially ordered relations
means that it does not need to examine large numbers of equivalent,
totally ordered sequences of states.
Instead, the axiomatic approach constructs the set of possible candidate
executions, rejecting those that do not meet the constraints of the
underlying memory model.
In herd, a candidate execution consists of little more
than a mapping giving, for each load, the store that provided the
memory value that was read.
This compact representation results in a much smaller number
of candidate executions than are considered by the full-state-space
approach used by armmem/ppcmem, which should allow herd
to run somewhat faster.
Running herd
(as in “herd -model ppc.cat IRIW.litmus -o /tmp”
after downloading from
here or via
https://github.com/herd/herdtools)
on the IRIW litmus test file gives the following
output, which, like ppcmem, confirms that the assertion can never fire
(note the second-to-last line beginning with “Observation”):
Test IRIW Allowed States 15 2:r3=0; 2:r5=0; 3:r3=0; 3:r5=0; 2:r3=0; 2:r5=0; 3:r3=0; 3:r5=1; 2:r3=0; 2:r5=0; 3:r3=1; 3:r5=0; 2:r3=0; 2:r5=0; 3:r3=1; 3:r5=1; 2:r3=0; 2:r5=1; 3:r3=0; 3:r5=0; 2:r3=0; 2:r5=1; 3:r3=0; 3:r5=1; 2:r3=0; 2:r5=1; 3:r3=1; 3:r5=0; 2:r3=0; 2:r5=1; 3:r3=1; 3:r5=1; 2:r3=1; 2:r5=0; 3:r3=0; 3:r5=0; 2:r3=1; 2:r5=0; 3:r3=0; 3:r5=1; 2:r3=1; 2:r5=0; 3:r3=1; 3:r5=1; 2:r3=1; 2:r5=1; 3:r3=0; 3:r5=0; 2:r3=1; 2:r5=1; 3:r3=0; 3:r5=1; 2:r3=1; 2:r5=1; 3:r3=1; 3:r5=0; 2:r3=1; 2:r5=1; 3:r3=1; 3:r5=1; No Witnesses Positive: 0 Negative: 15 Condition exists (2:r3=1 /\ 2:r5=0 /\ 3:r3=1 /\ 3:r5=0) Observation IRIW Never 0 15 Hash=41423414f4e33c57cc1c9f17cd585c4d
However, instead of taking 14 hours to compute this result,
herd completes in about 16 milliseconds,
representing a speedup in excess of 3,000,000x, which is something
that you do not see every day.
(The
herd paper
claims only a 45,000x speedup.)
However, it is only fair to add that ppcmem/armmem was implemented in a
deliberately straightforward way, without performance optimizations,
in order to increase the probability that it was in fact implementing the
intended memory model, a point that is also called out on pages 3
and 61 of the herd paper.
The tool also reports assertion violations.
For example, substituting the lightweight-barrier
lwsync instruction for the full-barrier sync
instruction gives the following output:
Test IRIW Allowed States 16 2:r3=0; 2:r5=0; 3:r3=0; 3:r5=0; 2:r3=0; 2:r5=0; 3:r3=0; 3:r5=1; 2:r3=0; 2:r5=0; 3:r3=1; 3:r5=0; 2:r3=0; 2:r5=0; 3:r3=1; 3:r5=1; 2:r3=0; 2:r5=1; 3:r3=0; 3:r5=0; 2:r3=0; 2:r5=1; 3:r3=0; 3:r5=1; 2:r3=0; 2:r5=1; 3:r3=1; 3:r5=0; 2:r3=0; 2:r5=1; 3:r3=1; 3:r5=1; 2:r3=1; 2:r5=0; 3:r3=0; 3:r5=0; 2:r3=1; 2:r5=0; 3:r3=0; 3:r5=1; 2:r3=1; 2:r5=0; 3:r3=1; 3:r5=0; 2:r3=1; 2:r5=0; 3:r3=1; 3:r5=1; 2:r3=1; 2:r5=1; 3:r3=0; 3:r5=0; 2:r3=1; 2:r5=1; 3:r3=0; 3:r5=1; 2:r3=1; 2:r5=1; 3:r3=1; 3:r5=0; 2:r3=1; 2:r5=1; 3:r3=1; 3:r5=1; Ok Witnesses Positive: 1 Negative: 15 Condition exists (2:r3=1 /\ 2:r5=0 /\ 3:r3=1 /\ 3:r5=0) Observation IRIW Sometimes 1 15 Hash=a886ed63a2b5bddbf5ddc43195a85db7
This confirms that full barriers are required in order to prevent
the assertion from firing: Compare the “Sometimes” on
the second-to-last line of the output for lwsync to the
“Never” on that same line in the previous output.
This means that in
the version of this litmus test using the sync instruction,
the assertion can “Never” happen, while in the version
using the lwsync instruction, it
“Sometimes” can.
Although this is nice to know, it would be even nicer to understand how the
lwsync barriers allow this result to happen.
Such understanding can be used to drive an interactive
ppcmem/armmem session, providing a useful cross-check of herd's
results.
(And performance is not an issue when you are interactively studying
a single path of execution rather than conducting a full state-space
search.)
And that is what the “-graph cluster -show prop”
arguments to the herd command are for.
This generates a
graphviz dot
file as follows:
![[Graphvis output]](https://static.lwn.net/images/2014/barriers/IRIW-lwsync-f.png)
This diagram shows that while the lwsync instructions
enforce the order of the individual reads, they do not force the
writes to be propagated in the same order to Thread 2 and Thread 3.
This may not be a surprise, but it is still nice
to see it in diagram form.
The labels on the arrows are defined as follows:
Answer
- fr: From read, which connects earlier loads to later
stores at the same address, for example, from Thread 3's
read of
xto Thread 0's later write to this same variable. - GHB: Global happens before, which is based on the
effects of memory-barrier instructions and dataflow dependencies,
illustrating
the limited transitivity (aka “cumulativity”)
of the
lwsyncinstruction. - po: Program order, for example, between the pairs of reads.
- propbase: Base store-propagation relationship that
the
herdtool uses to construct the full set of store-propagation relationships. - rf: Read from, for example from the store to
xto the load that returns the value written by that store.
Answer
The herd tool handles PowerPC and a few variants of
ARM, as well as x86, a fragment of the C++ language (including its memory
model), and several generations of NVIDIA GPUs,
with the C++11 and GPU models having been supplied by
Jade Alglave, Mark Batty, Luc Maranget, Daniel Poetzl, Tyler Sorensen
and John Wickerson.
In fact, one of the strengths of the herd tool is that
it uses a very compact description of memory models, so that the
ppc.cat file describing the PowerPC memory model is 67
lines long, and the x86tso.cat file describing the
x86 memory model is only 23 lines long.
An example x86 litmus test follows, which was discussed on LKML in November 2013:
1 X86 LockRelease
2 ""
3 {
4 x=0; y=0; z=0;
5 }
6 P0 | P1 | P2 ;
7 MOV [x],$1 | MOV EAX,[z] | MOV [y],$1 ;
8 MOV [z],$1 | MOV EBX,[y] | MFENCE ;
9 | | MOV EAX,[x] ;
10 exists (1:EAX=1 /\ 1:EBX=0 /\ 2:EAX=0)
The incantation “./herd -model x86tso.cat x86-lock-barrier.litmus -o ~/tmp”
gives the following output:
Answer
Test LockRelease Allowed States 7 1:EAX=0; 1:EBX=0; 2:EAX=0; 1:EAX=0; 1:EBX=0; 2:EAX=1; 1:EAX=0; 1:EBX=1; 2:EAX=0; 1:EAX=0; 1:EBX=1; 2:EAX=1; 1:EAX=1; 1:EBX=0; 2:EAX=1; 1:EAX=1; 1:EBX=1; 2:EAX=0; 1:EAX=1; 1:EBX=1; 2:EAX=1; No Witnesses Positive: 0 Negative: 7 Condition exists (1:EAX=1 /\ 1:EBX=0 /\ 2:EAX=0) Observation LockRelease Never 0 7 Hash=98f5658ae7325da4775b1358920d466a
This is in agreement with the
verdict
from Intel's CPU architects—and herd delivered this
verdict after a delay that extended for a full eleven milliseconds.
Linked data structures
It turns out that both ppcmem/armmem and herd can
handle simple linked data structures, namely a singly linked list
with no data.
This makes it possible for these tools to validate some simple
uses of RCU, for example, the 3-light scenario in the
LWN article on the RCU-barrier menagerie:
1 PPC RCU-3-tmp
2 ""
3 (* https://lwn.net/Articles/573497/ Scenario 3-light for Power.
4 Also adds a temporary. *)
5 {
6 0:r0=1; 0:r3=x; 0:r4=y; 0:r5=z;
7 1:r0=1; 1:r3=x; 1:r4=y; 1:r5=z;
8 }
9 P0 | P1 ;
10 lwz r6,0(r3) | stw r0,0(r4) ;
11 cmpwi r6,0 | lwsync ;
12 beq Fail | stw r4,0(r3) ;
13 stw r6,0(r5) | ;
14 lwz r8,0(r5) | ;
15 lwz r7,0(r8) | ;
16 Fail: | ;
17
18 exists
19 (0:r6=y /\ 0:r7=0)
Processor P1
initializes the new node (which is variable y) on line 10
and
does an rcu_assign_pointer() into the list header
(which is variable x) on lines 11 and 12.
Variable x now contains a pointer to
variable y, which in turn contains the value one.
Meanwhile, processor P0
does an rcu_dereference() (line 10),
checks for a NULL pointer (lines 11 and 12),
stores the resulting non-NULL pointer to a temporary
(line 13),
loads the pointer back from the temporary (line 14), and finally
loads the contents of the first element in the list.
If the value returned from rcu_dereference() is a pointer
to y, but dereferencing that pointer returns a value of
zero, we are in trouble.
Therefore, the condition on line 19 should never happen.
And, fortunately, both tools agree that it never does:
Test RCU-3-tmp Allowed States 2 0:r6=0; 0:r7=0; 0:r6=y; 0:r7=1; No Witnesses Positive: 0 Negative: 2 Condition exists (0:r6=y /\ 0:r7=0) Observation RCU-3-tmp Never 0 2 Hash=413c6e17f142bfa3835ed993c8ebf814
There is some work in progress to handle more complex data structures — though, in the words of one of the researchers: “Don't hold your breath!” Nevertheless, the above litmus test shows that even this limited ability to handle single-member data structures can be quite useful.
Scalability
We already saw that herd is blindingly fast, but it is still
interesting to look at its scalability.
Two tests will demonstrate this, the first being an extension of the
IRIW litmus test discussed above.
This test is augmented so that the writing processors do additional
(useless) writes, so that the five-writes-per-processor litmus test
appears as follows:
1 PPC IRIW5.litmus
2 ""
3 (* Traditional IRIW, but with five stores instead of just one. *)
4 {
5 0:r1=1; 0:r2=x;
6 1:r1=1; 1:r4=y;
7 2:r2=x; 2:r4=y;
8 3:r2=x; 3:r4=y;
9 }
10 P0 | P1 | P2 | P3 ;
11 stw r1,0(r2) | stw r1,0(r4) | lwz r3,0(r2) | lwz r3,0(r4) ;
12 addi r1,r1,1 | addi r1,r1,1 | sync | sync ;
13 stw r1,0(r2) | stw r1,0(r4) | lwz r5,0(r4) | lwz r5,0(r2) ;
14 addi r1,r1,1 | addi r1,r1,1 | | ;
15 stw r1,0(r2) | stw r1,0(r4) | | ;
16 addi r1,r1,1 | addi r1,r1,1 | | ;
17 stw r1,0(r2) | stw r1,0(r4) | | ;
18 addi r1,r1,1 | addi r1,r1,1 | | ;
19 stw r1,0(r2) | stw r1,0(r4) | | ;
20
21 exists
22 (2:r3=1 /\ 2:r5=0 /\ 3:r3=1 /\ 3:r5=0)
The time required as a function of the number of per-thread writes is as follows:
Writes
Per
ProcessorTime (s) Relative
SlowdownSlowdown
vs.
1 Write1 0.017 2 0.152 8.9x 8.9x 3 1.940 12.8x 114.1x 4 25.182 13.0x 1,481.3x 5 984.798 39.1x 57,929.3x
So although herd is quite fast compared to full-state-space
search, it is still most emphatically exponential.
However, one of the reasons for the slowness is that
“./herd -model ppc.cat”
calculates all possible coherence orders (orders of writes to a given
single variable), even those that do not matter to
the reads.
However, herd provides an alternative memory model that
computes only the subset of the coherence order that actually matters
to readers.
Substituting this alternative “prettycat.cat”
model for
“ppc.cat” runs the five-write-per-processor
litmus test in 3.888 seconds, which is a few orders of magnitude faster
than the 984.798 seconds that ppc.cat manages.
Of course, as with other software tools, adding optimization adds risk!
The second test chains the WWC+lwsyncs litmus test,
but instead of extending the number of writes per processor, extends
the number of processors.
Here is the base-level three-processor version:
1 PPC WWC+lwsyncs
2 "Rfe LwSyncdRW Rfe LwSyncdRW Wse"
3 Cycle=Rfe LwSyncdRW Rfe LwSyncdRW Wse
4 {
5 0:r2=x;
6 1:r2=x; 1:r4=y;
7 2:r2=y; 2:r4=x;
8 }
9 P0 | P1 | P2 ;
10 li r1,2 | lwz r1,0(r2) | lwz r1,0(r2) ;
11 stw r1,0(r2) | lwsync | lwsync ;
12 | li r3,1 | li r3,1 ;
13 | stw r3,0(r4) | stw r3,0(r4) ;
14 exists
15 (x=2 /\ 1:r1=2 /\ 2:r1=1)
In C, this looks something like the following (but in real life, don't forget the ACCESS_ONCE() calls!):
(The assertion is intended to run after all the parallel code has finished.)1 CPU 0 CPU 1 CPU 2 2 ----- ----- ----- 3 x = 2; r1 = x; r2 = y; 4 lwsync(); lwsync(); 5 y = 1; x = 1; 6 7 assert(!(x==2 && r1==2 && r2==1));
This can be extended to add a fourth processor as follows:
1 PPC WWC4+lwsyncs
2 "Rfe LwSyncdRW Rfe LwSyncdRW Wse"
3 Cycle=Rfe LwSyncdRW Rfe LwSyncdRW Wse
4 {
5 0:r2=x;
6 1:r2=x; 1:r4=y;
7 2:r2=y; 2:r4=z;
8 3:r2=z; 3:r4=x;
9 }
10 P0 | P1 | P2 | P3 ;
11 li r1,2 | lwz r1,0(r2) | lwz r1,0(r2) | lwz r1,0(r2) ;
12 stw r1,0(r2) | lwsync | lwsync | lwsync ;
13 | li r3,1 | li r3,1 | li r3,1 ;
14 | stw r3,0(r4) | stw r3,0(r4) | stw r3,0(r4) ;
15 exists
16 (x=2 /\ 1:r1=2 /\ 2:r1=1 /\ 3:r1=1)
Which looks something like the following in C:
1 CPU 0 CPU 1 CPU 2 CPU 3 2 ----- ----- ----- ----- 3 x = 2; r1 = x; r2 = y; r3 = z; 4 lwsync(); lwsync(); lwsync(); 5 y = 1; z = 1; x = 1; 6 7 assert(!(x==2 && r1==2 && r2==1 && r3 == 1));
This test continues adding processors up through 12 processors, resulting
in
this monstrosity, which is best viewed
in full-screen mode.
Surprisingly, herd deals just fine with twelve threads.
And although herd still shows exponential behavior, the
slowdowns are considerably milder than for the previous augmented
IRIW example:
Threads Time (s) Relative
SlowdownSlowdown vs.
3 Processors3 0.017 4 0.023 1.4x 1.4x 5 0.049 2.1x 2.9x 6 0.107 2.2x 6.3x 7 0.255 2.4x 15.0x 8 0.613 2.4x 36.1x 9 1.471 2.4x 86.5x 10 3.444 2.3x 202.6x 11 7.938 2.3x 466.9x 12 17.711 2.2x 1,041.8x
In short, herd appears to be able to handle most reasonably
sized litmus tests with eminently reasonable runtime.
Perhaps surprisingly, herd seems happier with multiple
processors than with multiple writes to the same memory location.
Limitations and summary
However, it is important to consider some
intrinsic limitations of the herd tool, which are
similar to
those
of ppcmem/armmem:
- These tools do not constitute official statements by ARM, IBM, or Intel on their respective CPU architectures. For example, all three corporations reserve the right to report a bug at any time against any version of any of these tools. These tools are therefore not a substitute for careful stress testing on real hardware. Moreover, both the tools and the model that they are based on are under active development and might change at any time.
- Contrariwise, at least one counterexample (observed on real hardware) to the results reported by the tools has been recognized by the official architects as demonstrating a silicon bug. The processors are also under active development.
- ppcmem/armmem on the one hand and
herdon the other do not always agree. These tools do give the same results for each litmus test in a suite of more than 8,000 such tests; however, there are a couple of examples where they differ. One example is Figure 37 of the herd paper, and Alan found a smaller example. Both examples are quite obscure. But there is a formal result in one direction; Section 7.3 of the paper (pages 45-49) contains a proof that whenever ppcmem/armmem believes an assertion can be triggered,herdwill report the same. In other words,herdis more conservative: it may indicate that a litmus test contains a synchronization error even though ppcmem/armmem thinks the test is okay. Nevertheless, when either one reports a possible assertion violation, it is wise to use the tools' reporting and visualization capabilities to help understand the reason for the violation. - The
herdtool is still exponential in nature, though much much faster than its predecessors. - Neither armmem/ppcmem nor
herdis much good for complex data structures, although you can create and traverse super-simple linked lists using initialization statements of the form “x=y; y=z; z=42;”. - Neither armmem/ppcmem nor
herdhandles memory-mapped I/O or device registers. Although there might come a time when we have formal models not only of normal memory, but of I/O devices as well, now is not yet that time. - The tools will detect only those problems for which you code an assertion. This weakness is common to all formal methods, and is yet another reason why testing remains important. In the immortal words of Donald Knuth: “Beware of bugs in the above code; I have only proved it correct, not tried it.”
On the other hand, one nice thing about tools such as
ppcmem/armmem and herd is that they are designed to model
the full range of behaviors permitted by the architecture.
This full range includes behaviors that current hardware does
not exhibit, but which future hardware might.
Use of these tools is thus one good way to future-proof your code.
All that said, it is best to design your code to be easily
partitioned and to use higher-level synchronization primitives such as locks,
sequence counters, atomic operations, and RCU.
But for those of us who design and implement these synchronization primitives,
ppcmem/armmem and herd are likely to be quite helpful.
Acknowledgments
We owe thanks to H. Peter Anvin (and the anonymous Intel CPU architects) who validated the x86 litmus test, and to Richard Grisenthwaite and Derek Williams for many helpful discussions of the ARM and the Power architectures, respectively. We are all indebted to Luc Maranget, Jade Alglave, Peter Sewell, and Susmit Sarkar for their review of an early draft of this article. We are grateful to Jim Wasko for his support of this effort.
Answers to Quick Quizzes
Quick Quiz 1: Why can't the CPU designers simply make their hardware do things in order???
Answer: Because full ordering destroys performance and scalability. This reordering of earlier stores against later loads allows the hardware to buffer stores, so that a long series of stores need not force the hardware to stall while waiting for ownership of the corresponding cache lines to make its way to the CPU doing the stores. In fact, thread-local reordering is just the beginning: compilers can also eliminate and introduce memory accesses, and in the Power and ARM architectures different writes by a given processor can propagate to the other processors in different orders.
Quick Quiz 2: But the diagram has a cycle involving the two fr arrows! How can that possibly happen? Do these computer systems have some sort of built-in time machine???
Answer: The hardware uses exactly the same time machine that we all use, namely the one that propels us into the future at a rate of one second per second. To see how that cycle can happen, imagine a system where Thread 0 and Thread 2 are close to each other, for example, they might be a pair of hardware threads running in the same CPU core. Imagine that Thread 1 and Thread 3 are similarly close to each other. This could cause Thread 2's loads to become aware of Thread 0's store much more quickly than Thread 3's loads do, as shown in the following diagram, with time advancing from top to bottom.
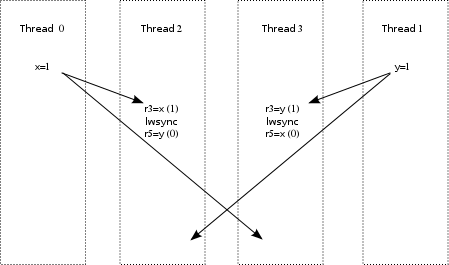
As you can see, this “counter-intuitive” result can be
explained by simple propagation delay.
The question of how sync instructions manage to
prevent executions like this one is left as an open exercise for
advanced students.
Quick Quiz 3: How could anyone possibly describe something as complex as a memory model in only 23 lines of text?
Answer: By using high-level notation, for example as follows for x86:
"X86 TSO" (* Uniproc check *) let com = rf | fr | co acyclic po-loc | com (* Atomic *) empty atom & (fre;coe) (* GHB *) #ppo let po_ghb = WW(po) | RM(po) #implied barriers let poWR = WR(po) let i1 = PA(poWR) let i2 = AP(poWR) let implied = i1 | i2 let GHB = mfence | implied | po_ghb | rfe | fr | co show mfence show implied acyclic GHB
This might serve as a useful reminder that “concise” and “easy to read” are orthogonal concepts. On the other hand, the 23 lines include both blank lines and comments. The notation is explained in the herd paper.
Quick Quiz 4: What kind of locking primitive gets away without using atomic instructions, anyway???
Answer: High-contention handoff of a queued locking primitive.
Now, the initial acquisition of a queued lock does in fact use atomic instructions, as it must to handle the possibility of multiple CPUs concurrently attempting to acquire the lock at a time when no CPU holds it. However, the high-contention handoff is from the CPU holding the lock to the CPU that is first in line to acquire it. Because there are only two CPUs involved, atomic instructions are not needed.
This should come as no surprise, as the classic single-producer/single-consumer array-based FIFO implementation also needs no atomic instructions, and for the same reason.
Patches and updates
Kernel trees
Architecture-specific
Core kernel code
Development tools
Device drivers
Device driver infrastructure
Filesystems and block I/O
Memory management
Virtualization and containers
Miscellaneous
Page editor: Jonathan Corbet
Next page:
Distributions>>