
Google's RE2 regular expression library
At Google, we use regular expressions as part of the interface to many external and internal systems, including Code Search, Sawzall, and Bigtable. Those systems process large amounts of data; exponential run time would be a serious problem. On a more practical note, these are multithreaded C++ programs with fixed-size stacks: the unbounded stack usage in typical regular expression implementations leads to stack overflows and server crashes. To solve both problems, we've built a new regular expression engine, called RE2, which is based on automata theory and guarantees that searches complete in linear time with respect to the size of the input and in a fixed amount of stack space." More information can be found on the RE2 project page.
Posted Mar 12, 2010 15:40 UTC (Fri)
by coriordan (guest, #7544)
[Link] (2 responses)
Posted Mar 12, 2010 17:07 UTC (Fri)
by robla (subscriber, #424)
[Link] (1 responses)
Posted Mar 12, 2010 17:15 UTC (Fri)
by southey (guest, #9466)
[Link]
Posted Mar 12, 2010 15:57 UTC (Fri)
by epa (subscriber, #39769)
[Link] (6 responses)
However it would be nice if the library could have two modes: a safe, regular-expression-only mode, and an unsafe mode where it will also accept backreferences and other funky Perl-like features, at the cost of fewer guarantees on run time. It might then be more widely adopted.
Posted Mar 12, 2010 17:51 UTC (Fri)
by rriggs (guest, #11598)
[Link]
Posted Mar 12, 2010 18:18 UTC (Fri)
by vonbrand (subscriber, #4458)
[Link] (4 responses)
There are regular expressions that require an exponentially large deterministic automaton to recognize (alternatively, if they simulate a nondeterministic one directly, an exponentially large set of states to remember), so they'll cut it short somewhere.
Posted Mar 12, 2010 18:42 UTC (Fri)
by ballombe (subscriber, #9523)
[Link]
Posted Mar 12, 2010 19:13 UTC (Fri)
by Pc5Y9sbv (guest, #41328)
[Link] (1 responses)
If I remember way back from school, in practice, many human-comprehensible non-determinstic REs can be emulated in closer to linear time. Running a set of DFAs, growing on each non-deterministic branch point, doesn't grow as wildly as it could in theory, because so many of the DFAs are culled relatively soon on dead-end input transitions. Is that no longer considered a valid heuristic strategy?
Posted Mar 14, 2010 10:50 UTC (Sun)
by ballombe (subscriber, #9523)
[Link]
This is much much worse. Languages defined with general back-references are undecidable, and even the simplest kind of back reference can cause languages not to be algebraic, for example ([ab]*)\1 and (a*)(b*)\1\2 are not.
Now, all true regular expressions can be matched in linear time and bounded memory. However both the memory bound and the setup time (before starting the match) are in the worse case exponential in the size of the expression.
Posted Mar 13, 2010 4:29 UTC (Sat)
by greenfie (subscriber, #6488)
[Link]
Posted Mar 12, 2010 16:19 UTC (Fri)
by HelloWorld (guest, #56129)
[Link]
Posted Mar 12, 2010 18:34 UTC (Fri)
by robert_s (subscriber, #42402)
[Link] (8 responses)
Wonder why that's never happened.
Posted Mar 12, 2010 19:17 UTC (Fri)
by ajross (guest, #4563)
[Link]
Posted Mar 12, 2010 22:57 UTC (Fri)
by tzafrir (subscriber, #11501)
[Link] (3 responses)
Posted Mar 13, 2010 19:24 UTC (Sat)
by tkil (guest, #1787)
[Link] (2 responses)
Not really;
This is still a win, since the regex object creation step is often the most
expensive part of using a regex: it involves interpolation, compilation to
opcodes, and various optimizations. Doing that only once vs. every time
through a loop is a huge help.
Being able to compile down to machine instruction (with all the
optimizations along the way) is just going further along the scale of "more
effort up front" vs. "better speed on each match". When you're working
with long-lived C++ apps and the regexes are static, it makes perfect sense
to try to compile them down as far as possible; when working with short-
lived dynamic scripts, it isn't always a win.
Posted Mar 14, 2010 10:02 UTC (Sun)
by tzafrir (subscriber, #11501)
[Link] (1 responses)
If the VM has the code half-compiled, there are probably many other optimizations to do under the cover.
Posted Mar 15, 2010 2:37 UTC (Mon)
by tkil (guest, #1787)
[Link]
What's so special about a regex, then? If the VM has the code half-compiled, there are probably many other
optimizations to do under the cover. That's pretty much the reason: it's a tradeoff between upfront regex
parsing / compilation / optimizing, and the ongoing cost of matching
against that regular expression. If you are only going to match against a regex once or twice, then
there's no point in spending a huge amount of time optimizing that regex
(and certainly not in doing it every time it's seen!). If, on the other
hand, you are going to match many things against that regex, it makes sense
to spend more time up front so that each match is a bit faster. It's a continuum: on the one end, the regex engine can just parse the
regex text as it goes, and do no compilation or optimization whatsoever
(this would be analogous to a true interpreter). As the next step, the
interpreter could process the regex into some internal representation, but
not do any optimizations. A step further, that internal representation
could be optimized in various ways. Finally, the optimized internal
representation could be compiled down to machine code (with possible
further optimizations applied). Each of those steps takes longer up front,
though, so you have to amortize the up-front regex processing time across
the number of matches.
Posted Mar 13, 2010 2:26 UTC (Sat)
by emk (subscriber, #1128)
[Link]
In any case, you might not need all of LLVMthat kind of simplified control
Posted Mar 13, 2010 17:10 UTC (Sat)
by andikleen (guest, #39006)
[Link] (1 responses)
You don't really need all the infrastructure in a full compiler like LLVM
One old style version (non JIT) is re2c that simply compiles regexprs to C.
Posted Mar 16, 2010 16:21 UTC (Tue)
by wahern (subscriber, #37304)
[Link]
http://www.complang.org/ragel/
Posted Mar 13, 2010 10:23 UTC (Sat)
by PO8 (guest, #41661)
[Link] (6 responses)
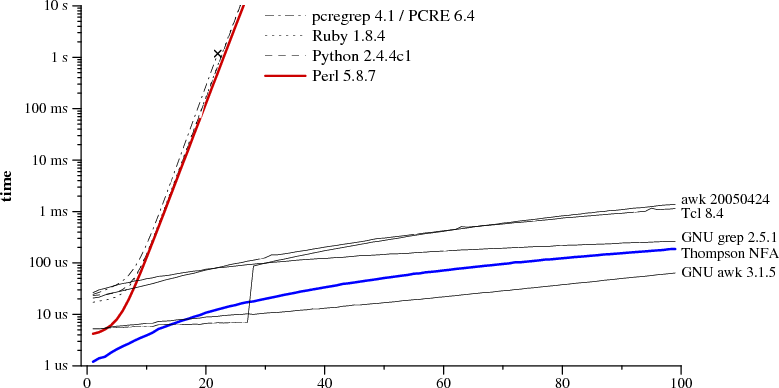
This all seems a little weird to me. The things chosen as reference points are mostly strange; most were never particularly touted as examples of speed. GNU grep is pretty fast, though; indeed, if you look at their own graph you might wonder why they cut it off where they did—grep certainly looks like it's almost constant-time in this example, and about to cross the y axis. Anyhow, the RE and target given in that second paper are a lousy benchmark for normal use; they are only intended to illustrate the thesis that backtracking loses on some REs and targets. In short, I'm not sure why backtracking matchers are any more than a strawman when building a fast modern RE engine. The benchmarking in the first paper is only against PCRE. It doesn't appear that any kind of Boyer-Moore is being used; this can be a major performance penalty for fixed strings. If I recall correctly, one can do Boyer-Moore-like things with general REs these days also. This is a performance no-brainer as far as I know. I'd be willing to wager a small amount of money that ripping Mike Haertel's RE engine out of GNU grep and clipping out the backreference support (which wouldn't be very hard) would give a much faster engine than re2, with an equally good memory footprint. The problem with this approach for Google, I suspect, is the GPL. Reimplementing a more sophisticated DFA-based RE engine doesn't seem that hard either, though. Certainly one could pay Mike to do it on a contract basis. Here's some stories about Mike and grep and RE matching: (1) (and note the comments), (2).
Posted Mar 14, 2010 10:05 UTC (Sun)
by tzafrir (subscriber, #11501)
[Link]
Posted Mar 14, 2010 19:38 UTC (Sun)
by droundy (subscriber, #4559)
[Link] (3 responses)
Admittedly, it seems like pretty weird regular expressions are needed in
Posted Mar 15, 2010 9:47 UTC (Mon)
by PO8 (guest, #41661)
[Link] (2 responses)
Just grabbed the source code and stared at it for a bit. It's big; 14K lines of C++ code, really well commented. It does do lazy DFA compilation with a state cache, which is nice. Couldn't find any evidence of Boyer-Moore, though. This is really a major omission if performance is an issue.
Don't really have time right now to do more benchmarking of this code. There's some benchmarks there already, but I haven't figured out how to play with them yet. More if and when I get some time.
Posted Mar 15, 2010 17:31 UTC (Mon)
by droundy (subscriber, #4559)
[Link]
Posted Mar 17, 2010 21:39 UTC (Wed)
by dthurston (guest, #4603)
[Link]
Posted Mar 19, 2010 12:16 UTC (Fri)
by walles (guest, #954)
[Link]
This performance issue is one that I'd really like to see fixed, so if somebody would step up to fix it that would be great!
Posted Mar 13, 2010 14:38 UTC (Sat)
by intgr (subscriber, #39733)
[Link] (4 responses)
Posted Mar 14, 2010 16:01 UTC (Sun)
by zlynx (guest, #2285)
[Link] (2 responses)
The main problem is that UTF encodings are variable length, so you never really know where the characters are until you go there and look.
Posted Mar 15, 2010 2:45 UTC (Mon)
by tkil (guest, #1787)
[Link] (1 responses)
It's easy enough if you convert internally while reading the data into
UCS-2 or 4. The main problem is that UTF encodings are variable length, so you never
really know where the characters are until you go there and look. I believe that all you really need is: Granted, going to UCS-4 solves the latter issue, but incurs a pretty
hefty memory cost. The canonicalization is required regardless. Unicode-compliant regex
engines will be slower than 8-bit regex engines, no matter what: all the
character
classes are larger, implying longer time to read in from disk, and more
cache hit when in use. Also, their size tends to remove the capability to
use simple table lookups like we could for 8-bit datasets, forcing the
engine to use fancier (and likely slower) techniques such as tries,
etc.
Posted Mar 15, 2010 6:34 UTC (Mon)
by dlang (guest, #313)
[Link]
on the other hand, many programs copy strings around a lot, but don't actually manipulate them much.
and for many things, the data being used really is almost entirely ASCII.
in these cases it is far better to leave things in UTF-8 variable length encoding and just walk the string when needed.
in the case of regex matching, if you are going to start at the beginning of the string and walk though it looking for matches, then you may as well leave it in UTF-8, you aren't doing anything that would benifit from knowing ahead of time where a particular character position starts, and the fact that the string is almost always going to be smaller is a win.
Posted Mar 20, 2010 0:38 UTC (Sat)
by rsc (guest, #64555)
[Link]
You're looking at it. http://code.google.com/p/re2/
3-clause BSD
3-clause BSD
it was "BSD", but the anal retentive side of me couldn't bring myself to
call it "BSD" when neither the abbreviation "BSD" nor even the word
"Berkeley" appear in the license.
Try 'New BSD License'
is linked it to the www.opensource.org for details.
The project page notes that
It handles only regular expressions, while Perl regexps give more
Unlike most automata-based engines, RE2 implements almost all the common Perl and PCRE features and syntactic sugars. It also finds the leftmost-first match, the same match that Perl would, and can return submatch information. The one significant exception is that RE2 drops support for backreferences and generalized zero-width assertions, because they cannot be implemented efficiently.
This is quite correct. Once you allow backreferences, you no longer have a regular language but some more powerful class of language, which can't make the same runtime guarantees.
It handles only regular expressions, while Perl regexps give more
Full regular expressions?
Full regular expressions?
Full regular expressions?
Full regular expressions?
Full regular expressions?
limitations, but during matching (when it builds up its DFA) it has bounded
memory. It'll just run slower on perverse regexes.
Google's RE2 regular expression library
Google's RE2 regular expression library
Mostly because constant factor execution speed (not the algorithmic stuff the
linked article is talking about) doesn't matter for regexes. Anything doing
performance critical work on text data in the modern world is going to be I/O
bound at some level (even if it's only DRAM latency). Cycle counting doesn't
help in that regime.
Google's RE2 regular expression library
Google's RE2 regular expression library
Google's RE2 regular expression library
Something like perl's
qr// operator?qr// simply lets the programmer control when the
double-quotish regex string is turned into a regex object. It's more like
generating an opcode tree for the regex, as opposed to compiling it down to
bytecode or machine instructions.
Google's RE2 regular expression library
Google's RE2 regular expression library
Google's RE2 regular expression library
which is basically Microsoft's closest approximation of LLVM?
flow can occasionally be handled quite nicely by specialized code generators.
Google's RE2 regular expression library
for it either, regular expressions are rather simple.
Then the V8 java script engine in google chrome which uses an own compiler for their JS regexprs. Undoubtedly there are others too. e.g. in a language with built in compiler like Common Lisp it's rather easy to do.
Google's RE2 regular expression library
Google's RE2 regular expression library
Google's RE2 regular expression library
Google's RE2 regular expression library
ruby and pcre is irrelevant. True, they are slow, but regexp matching is
supposed to be one of their strengths (esp of perl). And most people think
of them as being only maybe 10 or 1000 times slower than C, precisely when
the computation is dominated by library calls such as regular expression
matching, not 1e6 times slower than C. Of course, the point is that the
algorithm is at issue, not the language.
order to trigger this exponential behavior. But then again, taking a minute
to match a 29 character string with a 29 character regular expression does
seem pretty excessive...
Google's RE2 regular expression library
Google's RE2 regular expression library
implementations in common use than the claim of a drastically new and better
implementations, and the choice of a pathological regular expression made
sense as such, since the point is that such a beast exists with backtracking
implementations, and doesn't exist with good implementations.
Google's RE2 regular expression library
GNU Grep has its bad days
http://bugs.debian.org/cgi-bin/bugreport.cgi?bug=445215
Google's RE2 regular expression library
Google's RE2 regular expression library
Google's RE2 regular expression library
Google's RE2 regular expression library
Google's RE2 regular expression library
> 5x slowdown when used with a UTF-8 locale.
{kind=link}