
LWN.net Weekly Edition for June 12, 2008
Google announces Gadgets for Linux
Google recently announced the release of their Gadgets for the Linux desktop, and, unlike some of their other desktop offerings, they released it under a free software license. While it is not earth-shattering technology, Gadgets does provide some interesting features and amusing diversions. It also generates some hope that Google is getting better at understanding what free software users are looking for, so perhaps things like the Google Desktop for Linux will be better integrated and more useful in the future.
Gadgets are a cross-platform way to create simple applications that can run on web pages and desktops. The gadget API provides a means to retrieve content from other sites and display it along with a user interface. Many kinds of applications can be created, from clocks and calendars to RSS-feedreaders and "picture of the day" viewers.
![[Gadget desktop]](https://static.lwn.net/images/gadgets/gadgetdesktop_sm.png)
There are numerous gadgets available, a semi-random collection on a KDE desktop can be seen at left. Google has created a handful of gadgets, but the vast majority are available from others in various categories including News, Sports, Finance, Fun and Games, Technology, and Communication. The gadget browser shown below, at right, allows easy access to an amazing number of choices, many of which are variations on a theme.
![[Gadget browser]](https://static.lwn.net/images/gadgets/gadgetbrowser_sm.png)
To get started with gadgets, it is first necessary to build the tool. Google does not yet provide .rpm or .deb files for various distributions. The "how to build" page was useful, but there was some difficulty in trying to translate the dependencies into Fedora 9 package names. A page in a language I don't know needed no translation, however. Linux commands, it seems, are multi-lingual.
Building from the Apache-licensed source tarball was straightforward after that. Gadgets for Linux comes in both GTK+ and Qt flavors which allows for integration with the two dominant Linux desktop environments. The screenshots accompanying this article are from the Qt version, but a bit of a look at the GTK+ version seemed roughly the same—though the Qt version lacks the sidebar dock.
This is a beta release, perhaps more of a beta than many Google releases, so there are still a fair number of glitches. Perhaps 20% of the gadgets tried had one problem or another, with some seeming not to function at all. Having no experience with gadgets on other platforms, it was not clear whether these were caused by bugs in the gadgets themselves or the desktop gadget program.
![[Moon image gadget]](https://static.lwn.net/images/gadgets/moongadget_sm.png)
The main benefit of the gadget API seems to be the cross-platform capabilities. Gadgets can run—largely unchanged—on Linux, Mac OS X, or Windows, but can also run in browsers on web pages at social networking sites or on other pages. If the API can deliver that wide of a range of platform choices, it could open up a much wider audience for folks that want to develop their gadgets on Linux.
Still missing is one of the tools recommended for developing gadgets, Gadget Designer, which is only available for Windows. The documentation for creating a gadget make it look like a tedious exercise in XML manipulation and Javascript programming, but there may be tools available or in development to make some of that easier.
Overall, gadgets look like an interesting project. There is really nothing new about the kinds of applications that can be built using the API, but there are few choices to build those kinds of programs in a truly cross-platform way. Google's choice to support Linux—and support it well—accompanied by the code under a free software license is, perhaps, the best news of all.
An interview with Jim Ready
Jim Ready has a long history in the embedded systems market. Most recently, he became the founder of MontaVista, now one of the most successful embedded Linux companies. A recent LWN article took issue with some of Jim's comments; it only seemed fair to give him the opportunity to present his side of the story. Thus, this interview. We asked several questions about MontaVista and its approach to Linux marketing, and Jim took quite a bit of time to answer them in detail. So, without further ado...You have been working in the embedded Linux market for some years. How has that market changed over that time? What do you think are the prospects for embedded Linux now?
Where do you think MontaVista's sweet spot is in that market?
As another example, our Carrier Grade Linux distribution is the core OS in deployed NEC systems which have established 99.9999% availability (that's no more than ~31.5 seconds of unscheduled downtime in a year, which is a DoCoMo requirement). Our Professional Edition is the OS for two different patient monitoring systems that have been through FDA certification. We're truly fortunate to have thousands of customers, both big and not-so-big.
Embedded systems vendors have, as a group, been criticized for their lack of participation in the free software development process. Are you happy with MontaVista's level of contribution? What, in your mind, are some of the highlights of MontaVista's community participation?
Your recent article in Military Embedded Systems was seized upon by a proprietary embedded vendor as proof that Linux is too expensive and difficult for embedded applications. Assuming you disagree with his conclusions, where do you think his reasoning went wrong?
That approach gets the customer out of the business of making their own distribution, maintaining and supporting it with all the accompanying costs. So we shield the customer from the complexity and change rate that they otherwise would be exposed to if they were on their own. They don't have to watch all the patches, monitor the newsgroups and otherwise be tied up, they can get on to building their product. Dan purposely ignored the fact that a commercial embedded Linux distribution makes it very easy to use Linux as an embedded OS. I suspect that's why he tried to hide it.
Your article suggests that an embedded systems manufacturer using Linux would start by assembling the kernel and development toolchain by hand. Why do you think they would do that? Even in the absence of vendors like MontaVista, there are numerous options which do not require assembling systems at such a low level; why would a vendor not use one of them?
Don't get me wrong, almost any Linux distribution can serve as a starting point, maybe 99.99% perfect, but our customers demand more than that. They want to be at the end of the Linux development cycle, not the beginning. For example, a Linux distribution we recently started working with had the following problems:
- The code explicitly ignored Linux coding standards by adding hardware
dependencies. That code would never be accepted into the upstream trees,
and this kind of fork creates debugging issues and additional maintenance
burden.
- The drivers were not SMP-safe, real-time safe nor did they support DPM, yet
the device was designed for applications where all three could well be
required. In order to take advantage of these advanced features, the
device driver would need to be re-written from scratch.
- The code contained numerous defects that caused the system to crash. Error returns were not checked and other problems indicating very poor coding practices. These are exactly the type of quality issues that should compel businesses to find a Linux commercialization partner.
We had the great pleasure of fixing all these problems as we assembled our distribution. Even with our standard practice of pushing back the changes, as you well know, there is no guarantee by the community that these changes make it back into the appropriate open source trees.
The fact is it is difficult for a prospective Linux developer to have any idea of the state of the Linux distribution they might select. A high quality, commercial distribution can give a developer some peace of mind about what they are getting. For example, MontaVista has a formal development process in place for each of its releases, with quantitative criteria that must be met for defects (0 critical defects for example with a sharply declining overall new defect detection curve.) before the distribution can ship. Our processes have been formally audited by a number of our largest customers in order to assure themselves of what they are getting from us. And as we mentioned above, the proven results from devices in the field speak to our abilities. As for other starting points, you'll have to ask them about their process.
There were some interesting numbers in that article. Where did the 5000 messages/day for kernel.org come from - which lists?
For example, the monitoring would include not only lkml, but also the lists for other significant parts of the software typically used for an embedded project, including the list maintained for the specific architecture used (MIPS, PPC ARM etc), the real-time list, networking, IPv6, security, advanced filesystems etc. By the way, the lkml list on May 21, 2008 contained ~500 messages, and gcc contained ~100, just for starters. So it wasn't just lkml at 5000 but a total set that can total up to 5000 per day. Does the fact that lkml is only ~500 a day (and "only" ~200-300 on weekends) make it any less daunting? I don't think so.
You say: "a recent security patch that took all of 13 lines of code to implement against an embedded Linux system would have taken more than 800k lines of source patches to implement if the previous trail of patches had been ignored." How was that number arrived at? Which security patch were you describing? How could it possibly require 800,000 lines of patches "to implement" this security fix?
They start with Linux 2.6.10 and base their device application software on this release. During testing, they notice a defect and find that the defect has been identified (the good news) and fixed in 2.6.13 (the bad news). So now they have a problem, moving up to 2.6.13, where the defect is fixed also introduces 846,233 new lines of code (the delta between 2.6.10 and 2.6.13).
This magnitude of change restarts their QA process, since so much code has changed in the underlying Linux kernel. Their other choice is to backport the fix, which in this particular case is 33 lines (we know because we did it), but now the developer has taken on maintenance of their own Linux, which was what they were trying to avoid in the first place. This drift between a Linux release you have baselined and the fact that defects are often fixed in newer releases presents a less than perfect set of choices for developers. Whether you wanted to or not, you're in the Linux maintenance business. This drift problem is true of many distributions, not just dealing with kernel.org.
If our customer found the same defect, we have the obligation to fix it in the release that they purchased from us; we don't force them to potentially destabilize their environment by sending them a newer kernel release where the defect was originally fixed. I guess it all depends how cavalier one is about changing your underlying operating system after you've developed and tested your application. In general our customers are very strict about minimizing changes, and so are we.
At least some of MontaVista's marketing would appear to focus on making Linux look scary. Are you not concerned that this approach might have the effect of making Linux in general look less attractive and, thus, playing into the hands of proprietary systems vendors?
We have seen over the past 8 years any number of projects that got into trouble by not understanding what to expect when they downloaded some Linux and started in by themselves. In fact one of our very earliest customers, back in 1999, had started off building their own Linux, and hit a hardware integration bug that stopped them dead in their tracks for weeks, putting their project in real trouble. Had we not been able to help them out, their alternative was Windows CE. Ugh!
Why shouldn't many millions of lines of complex operating system code that changes daily be a little scary, especially when your business is making devices, not operating systems? I think it is a mistake to "trivialize" the difficulty in owning large amounts of any software, including Linux. That's why I think it's important for folks to be well informed about what they are getting into, so they can make good decisions on how they will approach using Linux for their system, whether they do-it-themselves or go commercial. In either case we want them to succeed.
Is there anything else you would like to pass on to LWN's readers?
We would like to thank Jim for taking the time to answer our questions.
Implications of pure and constant functions
Introduction
Attributes and why you should use them
Free Software development is often a fun task for developers, and it is its low barrier to entry (on average) that makes it possible to have so much available software for so many different tasks. This low barrier to entry, though, is also probably the cause of the widely varying quality of the code of these projects.
Most of the time, the quality issues one can find are not related to developers' lack of skill, but rather to lack of knowledge of how the tools work, in particular, the compiler. For non-interpreted languages, the compiler is probably the most complex tool developers have to deal with. Because a lot of Free Software is written in C, GCC is often the compiler of choice.
Modern compilers are also supposed to do a great job at optimizing the code by taking code, often written with maintainability and readability in mind, and translating it into assembler code with a focus on performance. Code analysis for optimization (which is also used for warnings about the code) has the task of taking a semantic look at the code, rather than syntactic, and identifying various fragments of algorithms that can be replaced with faster code (or with code that uses a smaller memory footprint, if the user desires to do so).
This task is a pretty complex one and relies on the compiler knowing about the function called by the code. For instance, the compiler might know when to replace a call to a (local, static) function with its body (inlining) by looking at its size, the number of times it is called, and its content (loops, other calls, variables it uses). This is because the compiler can give a semantic value to the code for a function, and can thus assess the costs and benefits of a particular transformation at the time of its use.
I specified above that the compiler knows when to inline a function by looking at its content. Almost all optimizations related to function calls work this way: the compiler, knowing the body of a function, can decide when it's the case to replace a call with its body; when it is possible to completely avoid calling the function at all; and when it is possible to call it just once and thereby avoid multiple calls. This means, though, that these optimization can be applied only to functions that are defined in the same unit wherein they are used. These functions are usually limited to static functions (functions that are not defined as static can often be overridden both at link time and runtime, so the compiler cannot safely assume that what it finds in the unit is what the code will be calling).
As this is far from optimal, modern compilers like GCC provide a way for the developer to provide information about the semantics of a function, through the use of attributes attached to declarations of functions and other symbols. These attributes provide information to the compiler on what the function does, even though its body is not available. Consequently, the compiler can optimize at least some of its calls.
This article will focus on two particular attributes that GCC
makes available to C developers: pure and
const, which can declare a function as
either pure or
constant. The next section will provide a
definition of these two kinds of functions, and after that I'll
get into an analysis of some common optimizations that can be
performed on the calls of these functions.
As with all the other function attributes supported by GCC and
ICC, the pure and
const attributes should be attached to the
declarative prototype of the function, so that the compiler know
about them when it finds a call to the function even without its
definition. For static functions, the attribute can be attached
to the definition by putting it between the return type and the
name of the function:
int extern_pure_function([...])
__attribute__((pure));
int extern_const_function([...])
__attribute__((const));
int __attribute__((pure)) static_pure_function([...]) {
[...]
}
int __attribute__((const)) static_const_function([...]) {
[...]
}
Pure and Constant Functions
For what concerns the scope of this article, functions can be divided into three categories, from the smallest to the biggest: constant functions, pure functions and the remaining functions can be called normal functions.
As you can guess, constant functions are also pure functions,
but pure functions cannot be not all pure functions are constant
functions. In many ways, constant functions are a special case
of pure functions. It is, therefore, best to first define pure
functions and how they differ from all the rest of the
functions.
A pure function is a function with basically no side effect. This means that pure functions return a value that is calculated based on given parameters and global memory, but cannot affect the value of any other global variable. Pure functions cannot reasonably lack a return type (i.e. have a void return type).
GCC documentation provides strlen() as an
example of a pure function. Indeed, this function takes a pointer
as a parameter, and accesses it to find its length. This
function reads global memory (the memory pointed to by
parameters is not considered a parameter), but does not change
it, and the value returned derives from the global memory
accessed.
A counter-example of a non-pure function is the
strcpy() function. This function takes two
pointers as parameters. It accesses the latter to read the
source string, and the former to write to the destination
string. As I said, the memory areas pointed to by the parameters
are not parameters on their own, but are considered global
memory and, in that function, global memory is not only accessed for
reading, but also for writing. The return value derives directly
from the parameters (it is the same as the first parameter), but
global memory is affected by the side effect of
strcpy(), making it not pure.
Because the global memory state remains untouched, two calls to the same pure function with the same parameters will have to return the same value. As we'll see, it is a very important assumption that the compiler is allowed to make.
A special case of pure functions is constant functions. A pure function that does not access global memory, but only its parameters, is called a constant function. This is because the function, being unrelated to the state of global memory, will always return the same value when given the same parameters. The return value is thus derived directly and exclusively from the values of the parameters given.
The way a constant function "consumes" pointers is very different from the way other functions do: it can handle them as both parameter and return value only if they are never dereferenced, for accessing the memory they are referencing would be a global memory access, which breaks the requirements of constant functions.
Of course these requirements have to apply not only to the operations in the given function, but also recursively to all the functions it calls. One function can at best be of the same kind of the least restrictive kind of function it calls. So when it calls a normal function it can't be but a normal function itself, if it only calls pure functions it can be either pure or normal, but not constant, and if it only calls constant functions it can be constant.
As with inlining, the compiler will be able to decide if a function is pure or constant, in case no attribute is attached to it, only if the function is static (with the exception of special cases for freestanding code and other advanced options). When a function is not static, even if it's local, the compiler will assume that the function can be overridden at link- or run-time so it will not make any assumption based on the body for the definition it may find.
Optimizing Function Calls
Why should developers bother with marking functions pure or constant, though? As I said, these two attributes help the compiler to know some semantic meaning of a function call, so that it can apply higher optimization than to normal functions.
There are two main optimizations that can be applied to these kinds of functions: CSE (Common Sub-expression Elimination) and DCE (Dead Code Elimination). We'll soon see in detail, with the help of the compiler itself, what these two consist of. Their names, however, are already rather explicit: CSE is used to avoid duplicating the same code inside a function, usually factoring out the code before branching or storing the results of common operations in temporary variables (registers or stack), while DCE will remove code that would never be executed or that would be executed but never used.
These are both optimization that can be implemented in the source code, to an extent, reducing the usefulness of declaring functions pure or constant. On the other hand, as I'll demonstrate, doing so often reduces the readability of the code by obscuring the actual algorithm in favor of making it faster. This does not apply to all cases though, sometimes, doing the optimization "manually", directly in the source code, makes it more readable, and makes the code resemble the output of the compiler more.
About Assemblers and Examples
When talking about optimization, it's quite difficult to visualize the task of the compiler, and the way the code morphs from what you read in the C source code into what the CPU is really going to execute. For this reason, the best way to write about them is to use examples, showing what the compilers generates starting from the source code.
Given the way in which GCC works, this is actually quite
easy. You just need to enable optimization and append the
-S switch to the gcc
command line. This switch stops the compiler after the
transformation of C source code into assembly, before the
result is passed to the assembler program to produce the
object file.
Although I suspect a good fraction of the people reading this article would be comfortable reading IA-32 or x86-64 assembly code, I decided to use the Blackfin [1] assembly language, which should be readable for people who have never studied a particular assembly language.
The Blackfin assembler is more symbolic than IA-32: instead of
having operations named movl and
addq, the operations are identified by
their algebraic operators (=,
+), while the registers are merely called
R1, R2 and so on.
Calling conventions are also quite easy to understand: for all
the cases we'll look through in the article (at most four
parameters, integers or pointers), the parameters are passed
through the registers, starting in order from
R0. The return value of the function call
is also stored in the R0 register.
To clarify the examples which will appear later on, let's see how the following C source code is translated by GCC into Blackfin code:
int somefunction(int a, int b, int c);
void somestringfunction(char *pA, char *pB);
int globalvar;
void test() {
somestringfunction("foo", "bar");
globalvar = somefunction(11, 22, 33);
}
becomes:
.section .rodata
.align 4
L$LC$0:
.string "foo"
.align 4
L$LC$1:
.string "bar"
.text;
.align 4
.global _test;
.type _test, STT_FUNC;
_test:
LINK 12;
R0.H = L$LC$0; 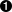 R0.L = L$LC$0;
R1.H = L$LC$1;
R1.L = L$LC$1;
call _somestringfunction;
R0.L = L$LC$0;
R1.H = L$LC$1;
R1.L = L$LC$1;
call _somestringfunction;  R0 = 11 (X);
R0 = 11 (X);  R1 = 22 (X);
R2 = 33 (X);
call _somefunction;
P2.H = _globalvar;
R1 = 22 (X);
R2 = 33 (X);
call _somefunction;
P2.H = _globalvar;  P2.L = _globalvar;
[P2] = R0;
P2.L = _globalvar;
[P2] = R0;  UNLINK;
rts;
UNLINK;
rts;  .size _test, .-_test
.size _test, .-_test
As the Blackfin does not have 32 bit immediate load, you
have to load high and low addresses separately (in
whichever order); the assembler will take care of properly
loading the high 16 bits of the label to the upper
part of the register, and the low 16 bits to the lower part.
Once the parameters are loaded, the function is called
almost identically to any other call
operation on other architectures; note the prefixed
underscore on symbols' names.
Integers, both constant or parameters and variables, are
also loaded for calls in the registers. Blackfin doesn't
have 32 bit immediate loading, but if the constant to load
fits into 16 bits, it can be loaded through sign extension
by appending the (X) suffix.
When accessing a global memory location, the
P2 pointer is set to the address of the
memory location...
... and then dereferenced to assign that memory
area. Being a RISC architecture, Blackfin does not have
direct memory operations.
The return value for a function is loaded into the
R0 register, and can be accessed from
there.
The rts command is the return from
subroutine, and usually indicates the end of the function,
but like the return statement in C,
it might appear in any place of the routine.
In the following examples, the preambles with declarations and data will be omitted whenever these are not useful to the discussion.
Concerning optimization levels, the code will almost always be compiled with at least the first optimization level enabled (-O1). This both because it makes the code cleaner to read (using register-register copy for parameters passing, instead of saving to the stack and then restoring from that) and because we need optimization enabled to see how they are applied.
Also, most of the times I'll refer to the
fastest alternative. Most of what I say,
though, applies also to the smaller
alternative when using the -Os optimization level. In any
case, the compiler always weighs the cost-to-benefit ratio
between the optimized and the unoptimized version, or between
different optimized versions. If you want to know the exact
route the compiler takes for your code, you can always use the
-S switch to find out.
DCE and Unused Variables
One area where DCE is useful is to avoid operations that result in unused data. It's not that uncommon that a variable is defined by an operation, complex or not, and is then never used by the code, either because it is intended for future expansion or because it's a remnant of older code that has been removed or replaced. While the best thing would be to get rid of the definition entirely, users expect the compiler to produce a good result with sloppy code too, and that operation should not be emitted.
The DCE pass can remove all the code that has no side effect, when its result is not used. This includes all mathematical operations and functions known to be pure or constant (as neither are allowed to change the global state of the variables). If a function call is not known to be at least pure, it may change the global state, and its call will not be eliminated, as shown in the following code:
int someimpurefunction(int a, int b);
int somepurefunction(int a, int b)
__attribute__((pure));
int testfunction(int a, int b, int c) {
int res1 = someimpurefunction(c, b);
int res2 = somepurefunction(b, c);
int res3 = a + b - c;
return a;
}
Which, once compiled with -O1,
[2]
produces the following Blackfin assembler:
_testfunction:
[--sp] = ( r7:7 );
LINK 12;
R7 = R0;
R0 = R2;
call _someimpurefunction;
R0 = R7;
UNLINK;
( r7:7 ) = [sp++];
rts;
As you can see, the call to the pure function has been
eliminated (the res2 variable was not being
used), together with the algebraic operation but, the impure
function, albeit having its return value discarded, is still
called. This is due to the fact that the compiler emits the
call, not knowing whether the latter function has side
effects on the global memory state or not.
This is equivalent to the following code (which produces the same assembler code):
int someimpurefunction(int a, int b);
int testfunction(int a, int b, int c) {
someimpurefunction(c, b);
return a;
}
The Dead Code Elimination optimization can be very helpful to reduce the overhead caused by code written to conform to C89 standard, where you couldn't mix variables (and constant) declarations with executable code.
In those sources, you had to declare variables at the top of the function, and then start to check for prerequisites. If you wanted to make it explicit that some variable had to keep its value, by making it constant, you would often have to fill them before the prerequisites could be checked.
Without discussing legacy code, it is also useful when
writing debug code, so that it doesn't look out of place from
the use of lots of #ifdef directives. Take
for instance the following code:
#ifdef NDEBUG
# define assert_se(x) (x)
#else
void assert_se(int boolean);
#endif
char *getsomestring(int i) __attribute__((pure));
int dosomethinginternal(void *ctx, int code, int val);
int dosomething(void *ctx, int code, int val) {
char *string = getsomestring(code);
// returning string might be a sub-string of "something"
// like "some" or "so"
assert_se(strncmp(string, "something", strlen(string)) == 0);
return dosomethinginternal(ctx, code, val);
}
The assert_se macro has different
behavior from the standard assert, as it
has side effects, which basically means that the code passed
to the assertion is called even though the compiler is told to
disable debugging. This is a somewhat common trick, although
its effects on readability are debatable.
With getsomestring() pure, when compiling
without debugging, the DCE will remove the calls to all three
functions: getsomestring(),
strncmp() and
strlen() (the latter two are usually
declared as pure by both the C library and by GCC's built-in
replacements). This because none of these functions have a
side effect, resulting in a very short function:
_dosomething:
LINK 0;
UNLINK;
jump.l _dosomethinginternal;
If our getsomestring() function weren't
pure, even though its return value is not going to be used,
the compiler would have to emit the call, resulting in rather
more complex (albeit still simple, compared with most
real-world functions) assembler code:
_dosomething:
[--sp] = ( r7:5 );
LINK 12;
R7 = R0;
R0 = R1;
R6 = R1;
R5 = R2;
call _getsomestring;
UNLINK;
R0 = R7;
R1 = R6;
R2 = R5;
( r7:5 ) = [sp++];
jump.l _dosomethinginternal;
Common Sub-expression Elimination
The Common Sub-expression Elimination optimization is one of the most important optimizations performed by the compiler, because it's the one that, for instance, replaces multiple indexed accesses to an array so that the actual memory address is calculated just once.
What this optimization does is to find common operations executed on the same operands (even when they are not known at compile-time), decide which ones are more expensive than saving the result in a temporary (register or stack), and then swapping the code around to take the cheapest course.
While its uses are quite varied, one of the easiest ways to
see the work of the CSE is to look at the
code generated when using the ternary if
operator. Let's take the following code:
int someimpurefunction(int a);
int somepurefunction(int a)
__attribute__((pure));
int testfunction(int a, int b, int c, int d) {
int res1 = someimpurefunction(a) ? someimpurefunction(a) : b;
int res2 = somepurefunction(a) ? somepurefunction(a) : c;
int res3 = a+b ? a+b : d;
return res1+res2+res3;
}
The compiler will optimize the code as:
_testfunction:
[--sp] = ( r7:4 );
LINK 12;
R7 = R0;
R5 = R1;
R4 = R2;
call _someimpurefunction;
cc =R0==0;
if !cc jump L$L$2;
R6 = R5;
jump.s L$L$4;
L$L$2:
R0 = R7;
call _someimpurefunction;
R6 = R0;
L$L$4:
R0 = R7;
call _somepurefunction;
R1 = R0;
cc =R0==0;
if cc R1 =R4; /* movsicc-1b */
R0 = R5 + R7;
cc =R0==0;
R2 = [FP+36];
if cc R0 =R2; /* movsicc-1b */
R1 = R1 + R6;
R0 = R1 + R0;
UNLINK;
( r7:4 ) = [sp++];
rts;
As you can see, the pure function is called just once, because the
two references inside the ternary operator are equivalent,
while the other one is called twice. This is because there was
no change to global memory known to the compiler between the
two calls of the pure function (the function itself couldn't
change it – note that the compiler will never take
multi-threading into account, even when asking for it
explicitly through the -pthread flag),
while the non-pure function is allowed to change global memory
or use I/O operations.
The equivalent code in C would be something along the following lines (it differs a bit because the compiler will use different registers):
int someimpurefunction(int a);
int somepurefunction(int a)
__attribute__((pure));
int testfunction(int a, int b, int c, int d) {
int res1 = someimpurefunction(a) ? someimpurefunction(a) : b;
const int tmp1 = somepurefunction(a);
int res2 = tmp1 ? tmp1 : c;
const int tmp2 = a+b;
int res3 = tmp2 ? tmp2 : d;
return res1+res2+res3;
}
The Common Sub-expression Elimination optimization is very useful when writing long and complex mathematical operations. The compiler can find common calculations even though they don't look common to the naked eye, and act on those.
Although sometimes you can get away with using multiple constants or variables to carry out temporary operations so that they can be re-used in the following calculations, leaving the formulae entirely explicit is usually more readable, as long as the formulae are not intended to change.
Like with other algorithms, there are some advantages to reducing the source code used to calculate the same thing; for instance you can easily make a change directly to the definition of a constant and get the change propagated to all the uses of that constant. On the other hand, this can be quite a problem if the meaning of two calculations is very different (and thus can vary in different ways with the evolution of the code), and just happen to be calculated in the same way at a given time.
Another rather useful place where the compiler can further optimize code with CSE, where it wouldn't be so nice or simple to do manually in the source code, is where you deal with static functions that are inlined by the compiler.
Let's examine the following code for instance:
extern int a;
extern int b;
static inline int somefunc1(int p) {
return (p * 16) + (3 << a);
}
static inline int somefunc2(int p) {
return (p * 16) + (4 << b);
}
extern int res1;
extern int res2;
extern int res3;
extern int res4;
void testfunc(int p1, int p2)
{
res1 = somefunc1(p1);
res2 = somefunc2(p1);
res3 = somefunc1(p2);
res4 = somefunc2(p2);
}
In this code, you can find four basic expressions:
(p1 * 16), (p2 *
16), (3 << a) and
(4 << b). Each of these four
expressions is used twice in the
somefunc() function. Thanks to the CSE,
though, the code will calculate each of them once, even
though they cross the function boundary, producing the
following code:
_testfunc:
[--sp] = ( r7:7 );
LINK 0;
R0 <<= 4;
R1 <<= 4;
P2.H = _a;
P2.L = _a;
R2 = [P2];
R7 = 3 (X);
R7 <<= R2;
P2.H = _b;
P2.L = _b;
R2 = [P2];
R3 = 4 (X);
R3 <<= R2;
R2 = R0 + R7;
P2.H = _res1;
P2.L = _res1;
[P2] = R2;
P2.H = _res2;
P2.L = _res2;
R0 = R0 + R3;
[P2] = R0;
R7 = R1 + R7;
P2.H = _res3;
P2.L = _res3;
[P2] = R7;
R1 = R1 + R3;
P2.H = _res4;
P2.L = _res4;
[P2] = R1;
UNLINK;
( r7:7 ) = [sp++];
rts;
As you can easily see (the assembly was modified a bit to
improve its readability, the compiler re-ordered loads of
registers to avoid pipeline stalls, making it harder to see the
point), the four expressions are calculated first, and stored
respectively in the registers R0,
R1, R7 and
R3.
These kinds of sub-expressions are usually harder to see in the code and also harder to implement. Sometimes they get factored out on their own parameter, but that can be more expensive during execution, depending on the calling conventions of the architecture.
Cheats
As I wrote above, there are some requirements that apply to functions that are declared pure and constant, related to not changing or accessing global memory; not executing I/O operations; and, of course, not calling further impure functions. The reason for this is that the compiler will accept what the user declares the function to be, whatever its body is (as it's usually unknown by the compiler at the call stage).
Sometimes, though, it's possible to fool the compiler so that it treats impure functions as pure or even constant functions. Although this is a risky endeavor, as it might truly cause bad code generation by the compiler, it can sometimes be used to force optimization for particular functions.
An example of this can be a lookup function that scans through a global table to return a value. While it is accessing global memory, you might want the compiler to promote it to a constant function, rather than simply to a pure one.
Let's take for instance the following code:
const struct {
const char *str;
int val;
} strings[] = {
{ "foo", 31 },
{ "bar", 34 },
{ "baz", -24 }
};
const char *lookup(int val) {
int i;
for(i = 0; i < sizeof(strings)/sizeof(*strings); i++)
if ( strings[i].val == val )
return strings[i].str;
return NULL;
}
void testfunction(int val, const char **str, unsigned long *len) {
if ( lookup(val) ) {
*str = lookup(val);
*len = strlen(lookup(val));
}
}
If the lookup() function is only
considered a pure function, as it is, adhering to the rules we
talked about at the start of the article, it will be called
three times in testfunction(), like this:
_testfunction:
[--sp] = ( r7:7, p5:4 );
LINK 12;
R7 = R0;
P5 = R1;
P4 = R2;
call _lookup;
cc =R0==0;
if cc jump L$L$17;
R0 = R7;
call _lookup;
[P5] = R0;
R0 = R7;
call _lookup;
call _strlen;
[P4] = R0;
L$L$17:
UNLINK;
( r7:7, p5:4 ) = [sp++];
rts;
Instead, we can trick the compiler by declaring the
lookup() function as constant (the data
it is reading is constant, after all, so at a given parameter
it will always return the same result). If we do that, the
three calls will have to return the same value, and the
compiler will be able to optimize them as a single call:
_testfunction:
[--sp] = ( p5:4 );
LINK 12;
P5 = R1;
P4 = R2;
call _lookup;
cc =R0==0;
if cc jump L$L$17;
[P5] = R0;
call _strlen;
[P4] = R0;
L$L$17:
UNLINK;
( p5:4 ) = [sp++];
rts;
In addition to lookup functions on constant tables, this trick is useful with functions which read data from files or other volatile data, and cache it in a memory variable.
Take for instance the following function that reads an environment variable:
char *get_testval() {
static char *cachedval = NULL;
if ( cachedval == NULL ) {
cachedval = getenv("TESTVAL");
if ( cachedval == NULL )
cachedval = "";
else
cachedval = strdup(cachedval);
}
return cachedval;
}
This is not truly a constant function, as its return value
depends on the environment. Even so, assuming that the
environment of the process is left untouched, its return value
will never change between calls. Even though it will affect
the global state of the program (as the
cachedval static variable will be filled in
the first time the function is called), it can be assumed to
always return the same value.
Tricking the compiler into thinking that a function is constant even though it has to load data through I/O operations, as I said, is risky, as the compiler will think there is no I/O operation going on; on the other hand, this trick might make a difference sometimes, as it allows the expression of functions in more semantic ways, leaving it up to the compiler to optimize the code with temporaries, where needed.
One example can be the following code:
char *get_testval() {
static char *cachedval = NULL;
if ( cachedval == NULL ) {
cachedval = getenv("TESTVAL");
if ( cachedval == NULL )
cachedval = "";
else
cachedval = strdup(cachedval);
}
return cachedval;
}
extern int a;
extern int b;
extern int c;
extern int d;
static int testfunc1() {
if ( strcmp(get_testval(), "FOO") == 0 )
return a;
else
return b;
}
static int testfunc2() {
if ( strcmp(get_testval(), "BAR") == 0 )
return c;
else
return d;
}
int testfunction() {
return testfunc1() + testfunc2();
}
Note:
To make sure that the compiler won't reduce the three
function calls to their return values right away, the static
sub-functions return values taken from global variables; the
meanings of those variables are not important.
Considering the above source code, if
get_testval() is impure, as the compiler
will automatically find it to be, it will be compiled into:
_testfunction:
[--sp] = ( r7:7 );
LINK 12;
call _get_testval;
R1.H = L$LC$2;
R1.L = L$LC$2;
call _strcmp;
cc =R0==0;
if !cc jump L$L$11 (bp);
P2.H = _a;
P2.L = _a;
R7 = [P2];
L$L$13:
call _get_testval;
R1.H = L$LC$3;
R1.L = L$LC$3;
call _strcmp;
cc =R0==0;
if !cc jump L$L$14 (bp);
P2.H = _c;
P2.L = _c;
R0 = [P2];
UNLINK;
R0 = R0 + R7;
( r7:7 ) = [sp++];
rts;
L$L$11:
P2.H = _b;
P2.L = _b;
R7 = [P2];
jump.s L$L$13;
L$L$14:
P2.H = _d;
P2.L = _d;
R0 = [P2];
UNLINK;
R0 = R0 + R7;
( r7:7 ) = [sp++];
rts;
As you can see, the get_testval() is
called twice, even though its result will be identical. If we
declare it constant, instead, the code of our test function
will be the following:
_testfunction:
[--sp] = ( r7:6 );
LINK 12;
call _get_testval;
R1.H = L$LC$2;
R1.L = L$LC$2;
R7 = R0;
call _strcmp;
cc =R0==0;
if !cc jump L$L$11 (bp);
P2.H = _a;
P2.L = _a;
R6 = [P2];
L$L$13:
R1.H = L$LC$3;
R0 = R7;
R1.L = L$LC$3;
call _strcmp;
cc =R0==0;
if !cc jump L$L$14 (bp);
P2.H = _c;
P2.L = _c;
R0 = [P2];
UNLINK;
R0 = R0 + R6;
( r7:6 ) = [sp++];
rts;
L$L$11:
P2.H = _b;
P2.L = _b;
R6 = [P2];
jump.s L$L$13;
L$L$14:
P2.H = _d;
P2.L = _d;
R0 = [P2];
UNLINK;
R0 = R0 + R6;
( r7:6 ) = [sp++];
rts;
The CSE pass combines the two calls to
get_testval with one. Again, this is one
of the optimizations that are harder to achieve by manually
changing the source code since the compiler can have a larger
view of the use of its value. A common way to handle this is
by using global variables, but that might require one more
load from the memory, while CSE can take care of keeping the
values in registers or on the stack.
Conclusions
After what you have read about pure and constant functions, you might have some concerns about the average use of them. Indeed, in a lot of cases, these two attributes allow the compiler to do something you can easily achieve by writing better code.
There are two objectives you have to keep in mind that are related to the use of these (and other) attributes. The first is code readability because sometimes the manually optimized functions are harder to read than what the compiler can produce. The second is allowing the compiler to optimize legacy or external code.
While you might not be too concerned with letting legacy code or code written by someone else get away with slower execution, a pragmatic view of the current Free Software world should take into consideration the fact that there are probably thousands lines of code of legacy code around. Some of that code, written with pre-C99 declarations, might be even using libraries that are being developed with their older interface, which could be improved by providing some extra semantic information to the compiler through use of attributes.
Also, it's unfortunately true that extensive use of these attributes might be seen by neophytes as an easy solution to let sloppy code run at a decent speed. On the other hand, the same attributes could be used to identify such sloppy code through analysis of the source code.
Although GCC does not issue warnings for all of these cases, it already warns for some of them, like unused variables, or statements without effect (both triggered by the DCE). In the future more warnings might be reported if pure and constant functions get misused.
In general, like with many other GCC function attributes, their use is tightly related to how programmers perceive their task. Most pragmatic programmers would probably like these tools, while purists will probably dislike the way these attributes help sloppy code to run almost as fast as properly written code.
My hopes are that in the future better tools will make good use of these and other attributes on different levels than compilers, like static and dynamic analyzers.
[1] The Blackfin architecture is a RISC architecture developed by Analog Devices, supported by both GCC and Binutils (and Linux, but I'm not interested in that here).
[2] I have chosen -O1 rather than -O2 because in the latter case the compiler performs extra optimization passes that I do not wish to discuss within the scope of this article.
Security
SCADA system vulnerabilities
Core Security released a security advisory on 11 June that details a fairly pedestrian stack-based buffer overflow vulnerability. This is similar to hundreds or thousands of this kind of flaw reported over the years except for one thing: it was found in large industrial control systems for things like power and water utility companies. That there is a vulnerability is not surprising—there are certainly many more—but it does give one pause about the dangers of connecting these systems to the internet.
The bug was found in a Supervisory Control and Data
Acquisition—better known as SCADA—system and could be
exploited to execute arbitrary code. Given that SCADA systems run much of
the world's infrastructure, an exploit of a vulnerable system could have
severe repercussions. The customers of Citect, the company that makes the
affected systems, include "organizations in the aerospace, food,
manufacturing, oil and gas, and public utilities industries.
"
Makers of SCADA systems nearly uniformly tell their customers to keep those
systems isolated from the internet. But as Core observes: "the
reality is that many organizations do have their process control networks
accessible from wireless and wired corporate data networks that are in turn
exposed to public networks such as the Internet.
" So, the potential
for a random internet bad guy to take control of these systems does exist.
None of that should be particularly surprising when you stop to think about it, but it is worrying. Many SCADA systems—along with various other control systems—were designed and developed long before the internet started reaching homes and offices everywhere. They were designed for "friendly" environments, with little or no change for the hostile environment that characterizes today's internet. Also, as we have seen, security rarely gets the attention it deserves until some kind of ugly incident occurs.
Even for systems that were designed recently, there are undoubtedly
vulnerabilities, so it is a bit hard to believe that they might be
internet-connected. According to the advisory, though, SCADA makers do not
necessarily require that the systems be physically isolated from the
network, instead customers can "utilize technologies including firewalls
to keep them protected from improper external communications.
"
Firewalls—along with other security techniques—do provide a measure of protection, but with the stakes so high, it would seem that more caution is required. It is probably convenient for SCADA users to be able to connect to other machines on the LAN, as well as to the internet, but with that convenience comes quite a risk. Even systems that are just locally connected could fall prey to a disgruntled employee exploiting a vulnerability to gain access to systems they normally wouldn't have.
One can envision all manner of havoc that could be wreaked by a malicious person (or government) who can take over the systems that control nuclear power plants, enormous gas pipelines, or some chunk of the power grid. Unfortunately, it will probably take an incident like that to force these industries into paying as much attention to their computer security as they do to their physical security.
New vulnerabilities
kernel: arbitrary code execution
| Package(s): | kernel | CVE #(s): | CVE-2008-1673 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | June 9, 2008 | Updated: | November 14, 2008 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | From the Debian advisory: Wei Wang from McAfee reported a potential heap overflow in the ASN.1 decode code that is used by the SNMP NAT and CIFS subsystem. Exploitation of this issue may lead to arbitrary code execution. This issue is not believed to be exploitable with the pre-built kernel images provided by Debian, but it might be an issue for custom images built from the Debian-provided source package. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
kernel: arbitrary code execution
| Package(s): | kernel | CVE #(s): | CVE-2008-2358 | ||||||||||||||||||||||||||||||||||||
| Created: | June 9, 2008 | Updated: | August 13, 2008 | ||||||||||||||||||||||||||||||||||||
| Description: | From the Debian advisory: Brandon Edwards of McAfee Avert labs discovered an issue in the DCCP subsystem. Due to missing feature length checks it is possible to cause an overflow they may result in remote arbitrary code execution. | ||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||
net-snmp: buffer overflow
| Package(s): | net-snmp | CVE #(s): | CVE-2008-2292 | ||||||||||||||||||||||||||||||||
| Created: | June 11, 2008 | Updated: | December 4, 2008 | ||||||||||||||||||||||||||||||||
| Description: | From the CVE entry: Buffer overflow in the __snprint_value function in snmp_get in Net-SNMP 5.1.4, 5.2.4, and 5.4.1, as used in SNMP.xs for Perl, allows remote attackers to cause a denial of service (crash) and possibly execute arbitrary code via a large OCTETSTRING in an attribute value pair (AVP). | ||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||
openoffice.org: integer overflow
| Package(s): | openoffice.org | CVE #(s): | CVE-2008-2152 | ||||||||||||||||||||||||||||||||||||||||||||
| Created: | June 11, 2008 | Updated: | September 10, 2008 | ||||||||||||||||||||||||||||||||||||||||||||
| Description: | OpenOffice.org has reported an integer overflow vulnerability in rtl_allocateMemory(). | ||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||
snort: detection rules bypass
| Package(s): | snort | CVE #(s): | CVE-2008-1804 | ||||||||||||||||||||
| Created: | June 6, 2008 | Updated: | December 11, 2009 | ||||||||||||||||||||
| Description: | From the CVE entry: preprocessors/spp_frag3.c in Sourcefire Snort before 2.8.1 does not properly identify packet fragments that have dissimilar TTL values, which allows remote attackers to bypass detection rules by using a different TTL for each fragment. | ||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||
tomcat: insufficient input sanitizing
| Package(s): | tomcat5.5 | CVE #(s): | CVE-2008-1947 | ||||||||||||||||||||||||||||||||||||||||||||
| Created: | June 10, 2008 | Updated: | February 17, 2009 | ||||||||||||||||||||||||||||||||||||||||||||
| Description: | From the Debian advisory: It was discovered that the Host Manager web application performed insufficient input sanitizing, which could lead to cross-site scripting. | ||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||
ucd-snmp: possible spoof
| Package(s): | ucd-snmp | CVE #(s): | CVE-2008-0960 | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | June 10, 2008 | Updated: | December 4, 2008 | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | From the Red Hat advisory: A flaw was found in the way ucd-snmp checked an SNMPv3 packet's Keyed-Hash Message Authentication Code (HMAC). An attacker could use this flaw to spoof an authenticated SNMPv3 packet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||
Page editor: Jake Edge
Kernel development
Brief items
Kernel release status
The current 2.6 development kernel is 2.6.26-rc5, released on June 4. As is usual
at this point in the release cycle, it is mostly bug fixes and the
like. There are a fair number of changes in the core kernel code, mostly
for scheduler issues, including some reverts for some performance
regressions. "Another week, another batch of mostly pretty small
fixes. Hopefully the regression list is shrinking, and we've fixed at least
a couple of the oopses on Arjan's list.
" See the long-format
changelog for
all the details. A 2.6.26-rc6 release is probably coming soon.
The current -mm tree is 2.6.26-rc5-mm2 which is a bug
fix for 2.6.26-rc5-mm1, also
released this week. The main additions are the unprivileged mounts tree
and a "large number of deep changes to memory management
".
The current stable 2.6 kernel is 2.6.25.6, released on June 9. It has a whole
pile of bugfixes, with none that are specifically called out as security
related. "It contains a number of assorted bugfixes all over the
tree. Users are encouraged to update.
" See the LWN announcement for some
discussion about potential security issues with this release. Also, note
that 2.6.25.5 was released on
June 7 with "one security bug fix. If you are using CIFS or SNMP NAT
you could be vulnerable and are encouraged to upgrade.
"
For older kernels: 2.4.36.6 was released on June
6. "It only fixes a vulnerability in the netfilter ip_nat_snmp_basic
module
(CVE-2008-1673). If you don't use it, you don't need to upgrade.
"
Kernel development news
A new kernel tree: linux-staging
There's a new kernel tree in town. The linux-staging tree was announced by Greg Kroah-Hartman on 10 June. It is meant to hold drivers and other kernel patches that are working their way toward the mainline, but still have a ways to go. The intention is to collect them all together in one tree to make access and testing easier for interested developers.
According to Kroah-Hartman, linux-staging (or -staging as it will
undoubtedly
be known) "is an outgrowth of the Linux Driver Project, and the fact
that
there have been some complaints that there is no place for individual
drivers to sit while they get cleaned up and into the proper shape for
merging.
" By collecting the patches in one place, it will increase
their visibility in the kernel community, potentially attracting more
developers to assist in fixing, reviewing, and testing them.
The intent is for -staging to house self-contained patches—Kroah-Hartman mentions drivers and filesystems—that should not affect anyone who is not using them. Because of that, he is hoping that -staging can get included in the linux-next tree. As he says to Stephen Rothwell, maintainer of -next, in the announcement:
The -next tree is meant for things that are headed for inclusion in the "N+1" kernel (where 2.6.N is the release under development), so including code not meant for that release is bending the rules a bit. As of this writing, Rothwell has not responded to the request to include -staging, but it would clearly benefit those patches to have a wider audience—with only a small impact on -next. There is no set timeline for patches to move from -staging into mainline, Kroah-Hartman says:
The -staging tree is seen as a great place for Kernel Janitors and others
who are interested in learning about kernel development to get their
start. The announcement notes: "The code in this tree
is in desperate need of cleanups and fixes that can be trivially
found using 'sparse' and 'scripts/checkpatch.pl'.
" In the
process of cleaning up the code, folks can learn how to create patches and
how to get them accepted into a tree. From there, the hope is that more
difficult tasks will be undertaken—with -staging or other kernel
code—leading to a new crop of kernel hackers.
The current status of -staging shows 17 patches, most of which are drivers from the Linux Driver Project. Kroah-Hartman is actively encouraging more code to be submitted for -staging, as long as it meets some criteria for the tree. The tree is not meant to be a dumping ground for drivers that are being "thrown over the wall" in hopes that someone else will deal with them. It is also not meant for code that is being actively worked on by a group of developers in another tree somewhere—the reiser4 filesystem is mentioned as an example—it is for code that would otherwise languish.
The reaction on linux-kernel has so far been favorable, with questions being asked about what kinds of patches are appropriate for the tree, in particular new architectures. The -staging tree fills a niche that has not yet been covered by other trees. It also serves multiple purposes, from giving new developers a starting point to providing additional reviewing and testing opportunities for new drivers and other code. With luck, that will hasten the arrival of new features—along with new developers.
A summary of 2.6.26 API changes
The 2.6.26 development cycle has stabilized to the point that it's possible to look at the internal API changes which have resulted. They include:
- At long last, support for the KGDB interactive debugger has been
added to the x86 architecture. There is a DocBook document in the
Documentation directory which provides an overview on how to use this
new facility. Some useful features (e.g. KGDB over Ethernet) are not
yet supported, but this is a good start.
- Page attribute table (PAT) support is also (again, at long last)
available for the x86 architecture. PATs allow for fine-grained
control of memory caching behavior with more flexibility than the
older MTRR feature. See Documentation/x86/pat.txt for more
information.
- ioremap() on the x86 architecture will now always return an
uncached mapping. Previously, it had taken a more relaxed approach,
leaving the caching as the BIOS had set it up. The practical result
was to almost always create uncached mappings, but with
occasional exceptions. Drivers which depend on a cached mapping will
now break; they will need to use ioremap_cache() instead.
See this article for
more information on this change and caching in general.
- The generic semaphores
patch has been merged. The semaphore code also has new
down_killable() and down_timeout() functions.
- The final users of struct class_device have been converted to
use struct device instead. The class_device
structure, along with its associated infrastructure, has been
removed.
- The nopage() virtual memory area operation has been removed;
all in-tree code is now using fault() instead.
- The object debugging
infrastructure has been merged.
- Two new functions (inode_getsecid() and
ipc_getsecid()), added to support security modules and the
audit code, provide general access to security IDs associated with
inodes and IPC objects. A number of superblock-related LSM callbacks
now take a struct path pointer instead of struct
nameidata. There is also a new set of hooks providing
generic audit support in the security module framework.
- The now-unused ieee80211 software MAC layer has been removed; all of
the drivers which needed it have been converted to mac80211. Also
removed are the sk98lin network driver (in favor of skge) and bcm43xx
(replaced by b43 and b43legacy).
- The ata_port_operations structure used by libata drivers now
supports a simple sort of operation inheritance, making it easier to
write drivers which are "almost like" existing code, but with small
differences.
- A new function (ns_to_ktime()) converts a time value in
nanoseconds to ktime_t.
- Greg Kroah-Hartman is no longer the PCI subsystem maintainer, having
passed that responsibility on to Jesse Barnes.
- The seq_file code now accepts a return value of SEQ_SKIP from
the show() callback; that value causes any accumulated output
from that call to be discarded.
- The Video4Linux2 API now defines a set of controls for camera devices;
they allow user space to work with parameters like exposure type, tilt
and pan, focus, and more.
- On the x86 architecture, there is a new configuration parameter which
allows gcc to make its own decisions about the inlining of functions,
even when functions are declared inline. In some cases, this
option can reduce the size of the kernel's text segment by over 2%.
- The legacy IDE layer has gone through a lot of internal changes which
will break any remaining out-of-tree IDE drivers.
- A condition which triggers a warning from WARN_ON will now
also taint the kernel.
- The get_info() interface for /proc files has been
removed. There is also a new function for creating /proc
files:
struct proc_dir_entry *proc_create_data(const char *name, mode_t mode, struct proc_dir_entry *parent, const struct file_operations *proc_fops, void *data);This version adds the data pointer, ensuring that it will be set in the resulting proc_dir_entry structure before user space can try to access it.
- The klist type now has the usual-form macros for declaration and
initialization: DEFINE_KLIST() and KLIST_INIT().
Two new functions (klist_add_after() and
klist_add_before()) can be used to add entries to a klist in
a specific position.
- kmap_atomic_to_page() is no longer exported to modules.
- There are some new generic functions for performing 64-bit integer
division in the kernel:
u64 div_u64(u64 dividend, u32 divisor); u64 div_u64_rem(u64 dividend, u32 divisor, u32 *remainder); s64 div_s64(s64 dividend, s32 divisor) s64 div_s64_rem(s64 dividend, s32 divisor, s32 *remainder);Unlike do_div(), these functions are explicit about whether signed or unsigned math is being done. The x86-specific div_long_long_rem() has been removed in favor of these new functions. - There is a new string function:
bool sysfs_streq(const char *s1, const char *s2);It compares the two strings while ignoring an optional trailing newline.
- The prototype for i2c probe() methods has changed:
int (*probe)(struct i2c_client *client, const struct i2c_device_id *id);The new id argument supports i2c device name aliasing.
One change which did not happen in the end was the change to 4K kernel stacks by default on the x86 architecture. This is still a desired long-term goal, but it is hard to say when the developers might have enough confidence to make this change.
Andrew Morton on kernel development
Andrew Morton is well-known in the kernel community for doing a wide variety of different tasks: maintaining the -mm tree for patches that may be on their way to the mainline, reviewing lots of patches, giving presentations about working with the community, and, in general, handling lots of important and visible kernel development chores. Things are changing in the way he does things, though, so we asked him a few questions by email. He responded at length about the -mm tree and how that is changing with the advent of linux-next, kernel quality, and what folks can do to help make the kernel better.Years ago, there was a great deal of worry about the possibility of burning out Linus. Life seems to have gotten easier for him since then; now instead, I've heard concerns about burning out Andrew. It seems that you do a lot; how do you keep the pace and how long can we expect you to stay at it?
I'm still keeping up with the reviewing and merging but the -mm release periods are now far too long.
There are of course many things which I should do but which I do not.
Over the years my role has fortunately decreased - more maintainers are running their own trees and the introduction of the linux-next tree (operated by Stephen Rothwell) has helped a lot.
The linux-next tree means that 85% of the code which I used to redistribute for external testing is now being redistributed by Stephen. Some time in the next month or two I will dive into my scripts and will find a way to get the sufficiently-stable parts of the -mm tree into linux-next and then I will hopefully be able to stop doing -mm releases altogether.
So. The work level is ramping down, and others are taking things on.
What can we do to help?
Secondly: it would help if people's patches were less buggy. I still have to fix a stupidly large number of compile warnings and compilation errors and each -mm release requires me to perform probably three or four separate bisection searches to weed out bad patches.
Thirdly: testing, testing, testing.
Fourthly: it's stupid how often I end up being the primary responder on bug reports. I'll typically read the linux-kernel list in 1000-email batches once every few days and each time I will come across multiple bug reports which are one to three days old and which nobody has done anything about! And sometimes I know that the person who is responsible for that part of the kernel has read the report. grr.
Is it your opinion that the quality of the kernel is in decline? Most developers seem to be pretty sanguine about the overall quality problem. Assuming there's a difference of opinion here, where do you think it comes from? How can we resolve it?
When I'm out and about I will very often hear from people whose machines we broke in ways which I'd never heard about before. I ask them to send a bug report (expecting that nothing will end up being done about it) but they rarely do.
So I don't know where we are and I don't know what to do. All I can do is to encourage testers to report bugs and to be persistent with them, and I continue to stick my thumb in developers' ribs to get something done about them.
I do think that it would be nice to have a bugfix-only kernel release. One which is loudly publicised and during which we encourage everyone to send us their bug reports and we'll spend a couple of months doing nothing else but try to fix them. I haven't pushed this much at all, but it would be interesting to try it once. If it is beneficial, we can do it again some other time.
There have been a number of kernel security problems disclosed recently. Is any particular effort being put into the prevention and repair of security holes? What do you think we should be doing in this area?
But a security hole is just a bug - it is just a particular type of bug, so one way in which we can reduce the incidence rate is to write less bugs. See above. More careful coding, more careful review, etc.
Now, is there any special pattern to a security-affecting bug? One which would allow us to focus more resources on preventing that type of bug than we do upon preventing "average" bugs? Well, perhaps. If someone were to sit down and go through the past five years' worth of kernel security bugs and pull together an overall picture of what our commonly-made security-affecting bugs are, then that information could perhaps be used to guide code-reviewers' efforts and code-checking tools.
That being said, I have the impression that most of our "security holes" are bugs in ancient crufty old code, mainly drivers, which nobody runs and which nobody even loads. So most metrics and measurements on kernel security holes are, I believe, misleading and unuseful.
Those security-affecting bugs in the core kernel which affect all kernel users are rare, simply because so much attention and work gets devoted to the core kernel. This is why the recent splice bug was such a surprise and head-slapper.
I have sensed that there is a bit of confusion about the difference between -mm and linux-next. How would you describe the purpose of these two trees? Which one should interested people be testing?
The -mm tree used to consist of the following:
- 80-odd subsystem maintainer trees (git and quilt), eg: scsi, usb, net.
- various patches which I picked up which should be in a subsystem maintainer's tree, but which for one of various reasons didn't get merged there. I spend a lot of time acting as backup for leaky maintainers.
- patches which are mastered in the -mm tree. These are now organised as subsystems too, and I count about 100 such subsystems which are mastered in -mm. eg: fbdev, signals, uml, procfs. And memory management.
- more speculative things which aren't intended for mainline in the short-term, such as new filesystems (eg reiser4).
- debugging patches which I never intend to go upstream.
The 80-odd subsystem trees in fact account for 85% of the changes which go into Linux. Pretty much all of the remaining 15% are the only-in-mm patches.
Right now (at 2.6.26-rc4 in "kernel time"), the 80-odd subsystem trees are in linux-next. I now merge linux-next into -mm rather than the 80-odd separate trees.
As mentioned previously, I plan to move more of -mm into linux-next - the 100-odd little subsystem trees.
Once that has happened, there isn't really much left in -mm. Just
- the patches which subsystem maintainers leaked. I send these to the subsystem maintainers.
- the speculative not-for-next-release features
- the not-to-be-merged debugging patches.
Do you have any specific goals for the development of the kernel over the next year or so? What would they be?
I keep on hoping that kernel development in general will start to ramp down. There cannot be an infinite number of new features out there! Eventually we should get into more of a maintenance mode where we just fix bugs, tweak performance and add new drivers. Famous last words.
And it's just vaguely possible that we're starting to see that happening now. I do get a sense that there are less "big" changes coming in. When I sent my usual 1000-patch stream at Linus for 2.6.26 I actually received an email from him asking (paraphrased) "hey, where's all the scary stuff?"
In the early-May discussions, Linus said a couple of times that he does not think code review helps much. Do you agree with that point of view?
How would you describe the real role of code review in the kernel development process?
It also increases the number of people who have an understanding of the new code - both the reviewer(s) and those who closely followed the review are now better able to support that code.
Also, I expect that the prospect of receiving a close review will keep the originators on their toes - make them take more care over their work.
There clearly must be quite a bit of communication between you and Linus, but much of it, it seems, is out of the public view. Could you describe how the two of you work together? How are decisions (such as when to release) made?
We each know how the other works and I hope we find each other predictable and that we have no particular issues with the other's actions. There just doesn't seem to be much to say, really.
Is there anything else you would like to say to LWN's readers?
Nothing special is needed - just install it on as many machines as you dare and use them in your normal day-to-day activities.
If you do hit a bug (and you will) then please be persistent in getting us to fix it. Don't let us release a kernel with your bug in it! Shout at us if that's what it takes. Just don't let us break your machines.
Our testers are our greatest resource - the whole kernel project would grind to a complete halt without them. I profusely thank them at every opportunity I get :)
We would like to thank Andrew for taking time to answer our questions.
Patches and updates
Kernel trees
Architecture-specific
Core kernel code
Development tools
Device drivers
Documentation
Filesystems and block I/O
Memory management
Virtualization and containers
Page editor: Jake Edge
Distributions
News and Editorials
openSUSE merges forums ahead of 11.0 release
The openSUSE project announced this week it has merged its three largest English-language community support forums under one big green umbrella and relaunched it as the openSUSE Forums. According to data supplied by openSUSE, the combined number of suseforums.net, suselinuxsupport.de, and openSUSE Novell support forum members was in the tens of thousands — a number expected to rise with the upcoming release of openSUSE 11.0.
Even though the new forums are already up and running smoothly, the team has no intention of resting on its laurels. They're already working on implementing similar changes with forums in other languages and better integration with the rest of the site.
Project Manager Rupert Horstkötter says there are also plans for a "user-rating for the whole openSUSE community, integrated with forums.opensuse.org, and all other openSUSE services. Besides all of that, we hope to be able to attract more independent forum communities for the official openSUSE forums."
Keith Kastorff, the site admin for suseforums.net says the idea began to take shape during an openSUSE project meeting back in 2007. "A big topic was the need for an 'official' openSUSE forum, and the duplication of effort, expertise, and resources we had in play," he recalls. "I volunteered to reach out to some of the independent SUSE focused forums to see if I could generate any interest in a merge." Then he contacted people involved with Novell and suselinuxsupport.de and "things moved forward from there."
Kastorff says getting the project underway was slow going at first and admits that some members were wary of Novell's involvement. "The open source community is sometimes skeptical of commercial players, but we found nothing but tremendous support from Novell," he says.
It's not surprising there were a number of technical hurdles to overcome in bringing the three forums together. One of the main issues included an inability to merge the member databases and it was eventually decided to simply archive them within a section of the new forum. "Like any project, we had to make compromises to achieve the end goal," says Kastorff. "We knew going in we had different cultures in play, and there were times the dialogs between the various merging staffs got intense, but the team's strong commitment to bettering the openSUSE community kept us focused on the prize."
Indeed, it was a team effort. More than 30 people worked behind the scenes to import the help sections of the separate forums and archive over 400,000 posts prior to launching forums.opensusue.org. In order for the project to work, the various groups — each with their own goals and ideas — needed to work together and trust in the end goal.
Horstkötter says it was "a lot of work to combine different cultures into one big forum for the openSUSE community, but it was a great time. I feel like I met some new friends during the project."
"We had three teams — one from Novell, two from different grassroots projects that had sprung up to serve the community and had developed their own style and ways of working together," recalls openSUSE Product Manager Michael Löffler "To merge the three, the staff for each forum had to be comfortable putting all their eggs in one basket (Novell hosting the forums) and agreeing on a common set of rules, moderation guidelines, etc. It took some time and effort to work everything out, but I think that the three teams are working quite well together now."
Just as important as teams working together is the impact that merged forums will have on the openSUSE community overall. "Having a unified forum means that all interested users can converse and support one another in one location — so you don't have the duplication of effort." says Löffler. "I'm really glad [they] launched in time for 11.0 — I expect that a lot of new users are going to be interested in openSUSE with this release, and I am very happy we have the forums to help support them."
New Releases
64 Studio 2.1 'A Minha Menina' released!
The latest version of 64 Studio, 2.1 'A Minha Menina', has been released. "Version 2.1 is the first update to the second stable release of 64 Studio. It is named after a song by Jorge Ben, recorded by Os Mutantes and covered by The Bees." 64 Studio is a remix of Debian 4.0 'Etch', focused on digital content creation, including audio, video, graphics and publishing tools.
Debian Installer lenny beta 2 released
The second beta of the Debian lenny installer is available for testing. Click below for a look at the improvements and known issues in this release.Mandriva Flash 2008 Spring released
Mandriva has announced the release of Mandriva Flash 2008 Spring, the new release of its bootable distribution on a USB key. "Mandriva Flash 2008 Spring is based on the new release of Mandriva Linux. It doubles the capacity of the key from 4GB for the previous version to 8GB, and comes in an attractive white casing. Flash 2008 Spring's new installation feature lets you install Mandriva Linux 2008 Spring permanently onto any system with just a few clicks." It's available now from the Mandriva Store.
openSUSE Build Service 1.0 RC 1 released
The openSUSE Project has released the first release candidate of the openSUSE Build Service 1.0. "With the release candidate, all the features are now in place to support external collaboration with the community to build openSUSE in the open. Developers can now submit contributions to openSUSE directly at build.opensuse.org/."
Distribution News
Fedora
Fedora Board Recap 2008-JUN-03
Here's a look at the June 3, 2008 meeting of the Fedora board. Topics include Codeina, Fedora 9 Postmortem, and Fedora Organizational Structure.
Gentoo Linux
Nominations open for the Gentoo Council 2008/2009
Nominations for the Gentoo Council 2008/2009 are open now and will be open for the next two weeks. Only Gentoo developers may be nominated and only Gentoo developers may vote.
Mandriva Linux
Celebrating 10 years of Mandriva
Mandriva just celebrated its Tenth Anniversary, both as a company and as a distribution. "The Mandriva community celebrated in style over the last weekend in May, with a party in the Eiffel Tower in Paris attended by many staff, former staff, community members and partners. There was also an - indoor - picnic, and the now-traditional Dance Dance Revolution party."
Other distributions
FreeBSD supported branches update
FreeBSD has announced an end-of-life for FreeBSD 5.5, FreeBSD 6.1, and FreeBSD 6.2. "Users of these releases are advised to upgrade promptly to FreeBSD 6.3 or FreeBSD 7.0, either by downloading an updated source tree and building updates manually, or (for i386 and amd64 systems) using the FreeBSD Update utility as described in the FreeBSD 6.3 and FreeBSD 7.0 release announcements."
Distribution Newsletters
Ubuntu Weekly Newsletter #94
The Ubuntu Weekly Newsletter for June 7, 2008 covers Ubuntu Global Bug Jam, New Members, Newly Approved LoCos, Canonical Showcases Ubuntu Netbook Remix at Computex, Kubuntu Specs in Full, Ubuntu at OSCON, Ubuntu Server receives positive reviews, Mobile devices driving Ubuntu-Shuttleworth, Ubuntu UK podcast #7, Acer bets big on Linux, and much more.Fedora Weekly News Issue 130
The Fedora Weekly News for June 8, 2008 looks at an interview with Jim Whitehurst, Ubuntu 8.04 vs Fedora 9, LinuxTag Reports, Fedora Open Day 2008, and much more.DistroWatch Weekly, Issue 256
The DistroWatch Weekly for June 9, 2008 is out. "Ever since the launch of ASUS Linux Eee PC late last year, the ultra-portable computer market has turned into a major battleground of operating systems. Who will win? Microsoft with its thick wallet and pressure tactics or Linux with its low cost and open development model? Last week's Computex in Taipei revealed surprising differences between the ways hardware manufacturers embrace this exciting market. In the news section, Debian announces upcoming freeze of "Lenny", Mandriva celebrates its 10-year birthday, Canonical releases Ubuntu Netbook Remix, and FreeBSD updates the End-of-Life dates for its current and past releases. Also in this week's issue, a good collection of search resources for CentOS and RHEL users, and a list of valuable third-party repositories for openSUSE 11.0. Finally, with the annual package database update on DistroWatch, do let us know which new packages you want us to include in the tracking process."
Distribution meetings
Recordings of Linuxtag '08
Recordings from talks that took place at the openSUSE day at Linuxtag are available online. Almost all are in German.
Page editor: Rebecca Sobol
Development
Detect and record video movement with Motion
Motion is a video application that monitors a video4linux device such as a USB camera and records movement within the image:
An installation of Motion was performed on a machine with a 3Ghz Athlon 64 processor running Ubuntu 7.04 (Feisty Fawn). The most recent version of Motion (v 3.2.10.1) was downloaded, the file was uncompressed and untared. The normal configure, make and make install steps were performed. If one wishes to record mpeg movies, the libavcodec and libavformat libraries must be installed prior to running configure.
The make install step needed a bit of manual intervention, it was necessary to create the /var/run/motion directory and copy the motion-dist.conf configuration file to /usr/local/etc/motion.conf. The config file was modified to define a USB camera, the camera's default resolution was defined and the destination directory for images was set. The framerate parameter was changed to 2 seconds to slow down the rate of accumulation of image files.
A Kensington Model 67015 VideoCAM VGA USB camera was plugged into the computer. It is a good idea to run a real-time video monitoring application such as xawtv or EffecTV (in DumbTV mode) to adjust the camera's focus, brightness and contrast settings. Running Motion was simply a matter of typing "motion" on the command line. The program takes about 25 seconds to start recording movement, presumably most of this time is spent learning the contents of the video. After this delay, the software would output a line of text and create one .jpg file for each movement it detected. The images were inspected with the Mirage image viewer and a changing sequence of static images was observed.
Motion has a wide variety of capabilities and configurable parameters. The Motion Guide and Config File Options are a good place to read about the various capabilities and the FAQ gives answers to common questions.
One can imagine a number of uses for Motion, cube farm denizens could find out what is causing their pens to disappear at night, people in high crime areas could use it to catch vandals and thieves in the act. The on_picture_save configuration directive can execute a script on motion detection, this could be used to copy captured images to a distant web server for remote monitoring. This feature was tested by adding a line like this: on_picture_save scp %f remote-host:/directory-path to the config file, the operation worked as expected.
It should be noted that inexpensive USB cameras may only work in a very limited set of lighting conditions. Serious surveillance would require an NTSC or PAL video input adapter and a better camera, or a high resolution webcam.
Apparently, no major releases of Motion have been released in a long time, but the developers' mail archive shows that recent work has been done on the project. A new point release just showed up this week, it added a fix for a security bug.
If you are looking for a way to do automated video surveillance, Motion is an excellent tool for the job.
System Applications
Database Software
MySQL 5.1.25-rc has been released
Version 5.1.25-rc of the MySQL DBMS has been announced. "We are proud to present to you the MySQL Server 5.1.25-rc release, a new "release candidate" version of the popular open source database. Bear in mind that this is still a "candidate" release, and as with any other pre-production release, caution should be taken when installing on production level systems or systems with critical data."
pgAdmin III v1.8.4 released
Version 1.8.4 of pgAdmin III has been announced. "The pgAdmin Development Team are pleased to announce the release of pgAdmin 1.8.3, the Open Source graphical PostgreSQL administration tool for Windows, Linux, FreeBSD, Mac OS X and Solaris, now available for download in source and a variety of binary formats from: http://www.pgadmin.org/download/. v1.8.4 is primarily a bug fix release".
Embedded Systems
BusyBox 1.10.3 released
Version 1.10.3 of BusyBox, a collection of command line utilities for embedded systems, has been announced. "Bugfix-only release for 1.10.x branch. It contains fixes for dnsd, fuser, hush, ip, mdev and syslogd."
Web Site Development
About Django and the importance of releases (Technobabble)
Christian Joergensen notes the lack of recent releases of the Django web platform. "My favorite Python web framework, Django, has not been updated for a long time. The most current release, 0.96, was released in March 2007. This is a very long time, when you're in the market of web frameworks. This doesn't seem to bother a lot of people, as the common answer in the django community seems to be just to run the trunk version (development version). I for one do[]n't like that solution. And here are some of the reasons why."
Desktop Applications
Animation Software
Synfig Irregular News
The June 5, 2008 edition of the Synfig Irregular News covers the latest news from the Synfig 2D vector animation studio project.
Audio Applications
JVoiceXML: Release 0.6 (SourceForge)
Version 0.6 of JVoiceXML has been announced, several new capabilities have been added. "VoiceXML is designed for creating audio dialogs that feature synthesized speech, digitized audio, recognition of spoken and DTMF key input, recording of spoken input, telephony, and mixed initiative conversations. Major goal is to have a platform independent implementation that can be used for free."
Business Applications
OrangeHRM: Releases Version 2.3 (SourceForge)
Version 2.3 of OrangeHRM has been announced. "OrangeHRM developed by OrangeHRM Inc is an Open Source HR Information Systems(HRIS) that covers Personnel Information Management, Employee Self Service, Leave, Time & Attendance, and Benefits. Recruitment, and Performance Appraisal are in development. New version - a result of OrangeHRM and its user community collaboration - brings in the introduction of the comprehensive Benefit Module".
Desktop Environments
GNOME 2.23.3 released
Version 2.23.3 of the GNOME desktop has been announced. "Okay, the big thing in this release is that we fixed many bugs! Hrm, you're used to this too... But does all this mean this release is boring? Of course not, it just means we don't realize how much good work we're constantly doing :-) So just think about it and hug a GNOME contributor!"
GARNOME 2.23.3 released
Version 2.23.3 of GARNOME, the bleeding-edge GNOME distribution, has been announced. "Next one. Unstable again this time. After lots of smoke-testing the last 3 days, re-building lots of stuff over and over again, pestering maintainers to fix their code and upload brown paper bag tarballs..."
GNOME Software Announcements
The following new GNOME software has been announced this week:- Clutter 0.6.4 (bug fixes)
- Conduit 0.3.11.2 (bug fixes)
- CrunchyFrog 0.2.1 (new features, bug fixes and translation work)
- GENIUS 1.0.3 (new features, bug fixes, documentation and translation work)
- gnome-control-center 2.23.3 (code cleanup, bug fixes and translation work)
- gnome-settings-daemon 2.23.3 (bug fixes and translation work)
- GVFS 0.99.1 (new features, bug fixes and translation work)
- Vala 0.3.3 (new features and bug fixes)
KDE Commit-Digest (KDE.News)
The May 11, 2008 edition of the KDE Commit-Digest has been announced. The content summary says: "In this week's KDE Commit-Digest: A wordprocessor-like ruler for repositioning and resizing the Plasma panel. Scripting support re-enabled in KRunner. More developments in the NetworkManager Plasma applet. Initial work to allow closer interaction of Plasma with KNotify's popups. Work on theming, Magnatune membership support, and the ClassicView in Amarok 2.0. Work on adding support for plugins to Marble. General work across KDE games..."
KDE Software Announcements
The following new KDE software has been announced this week:- cb2Bib 1.0.0 (new features and bug fixes)
- cb2Bib 1.0.0.1 (new features and bug fixes)
- CoverPrint 1. (improved text fitting)
- eric4 4.1.5 (bug fixes)
- eXaro rc 8 (new name, new features and bug fixes)
- first4 1.4-beta3 (new features, bug fixes and translation work)
- Foxkit 0.0.1 (initial release)
- KGtk 0.9.5 (bug fixes and translation work)
- Kopete Antispam Plugin 0.2 (unspecified)
- KrcStat 0.3 (new features)
- LilyKDE 0.6.0 (new features and bug fixes)
- Mailody 1.5.0-alfa1 (unspecified)
- QjackCtl 0.3.3 (new features and bug fixes)
- qtsolartron 0.1.3 (unspecified)
- Sudoku Generator 1.3 (unspecified)
- Transcogg 2.3 (new feature)
- Yakuake 2.9.3 for KDE 4 (new features and bug fixes)
X.Org security advisory june 2008 - Multiple vulnerabilities
A June, 2008 X.Org security advisory has been issued. "Several vulnerabilities have been found in the server-side code of some extensions in the X Window System. Improper validation of client-provided data can cause data corruption."
Xorg Software Announcements
The following new Xorg software has been announced this week:- libpciaccess 0.10.3 (bug fixes)
- pixman 0.11.2 (new features and bug fixes)
- pixman 0.11.4 (bug fix)
- rgb 1.0.2 (bug fixes and documentation work)
- rgb 1.0.3 (documentation work)
- xf86-input-elographics 1.2.2 (bug fix)
- xf86-input-evdev 1.99.3 (new features and bug fixes)
- xf86-input-evdev 1.99.4 (bug fix)
- xorg-server 1.4.1 (security and bug fixes)
- xorg-server 1.4.2 (security fixes)
Desktop Publishing
LyX version 1.6.0 (beta 3) is released
Version 1.6.0 beta 3 of LyX, a GUI front-end to the TeX typesetter, has been announced. "Compared with the latest stable release, this is the culmination of one year of hard work, and we sincerely hope you will enjoy the results."
pdfposter 0.4.2 released
Version 0.4.2 of pdfposter, a tool for scaling and tiling PDF images to print on multiple pages, has been announced. "This version fixes a view minor bugs - some media-/poster-sizes (eg. Letter) have not bee[n] recogni[z]ed - some PDF files crashed the tool."
Imaging Applications
Gimp UserFilter: plug-in v0.9.6 released (SourceForge)
Version 0.9.6 of Gimp User Filter has been announced. "Gimp User Filter is a plugin for The Gimp (http://www.gimp.org/), originally written by Jens Restemeier back in 1997. This project is about maintaining the plugin, keeping it compatible with current versions of Gimp, and eventually extending its features. This is a bugfix release of the plug-in. It fixes a couple of issues in the configuration and compilation process."
Interoperability
Wine 1.0-rc4 released
Version 1.0-rc4 of Wine has been announced. Changes include: Bug fixes only, we are in code freeze.
Multimedia
ScaleTempo: gst-scaletempo Release 1 (SourceForge)
Release 1 of ScaleTempo has been announced. The application is a: "Variable speed playback for major open source media players (MPlayer, GStreamer, Xine, VLC, Totem, RhythmBox, Amorak, Miro, etc.) Scaletempo plays audio and video faster or slower than the recorded speed without changing pitch (i.e. no chipmunk effect)."
Office Suites
OpenOffice 2.4.1 released
Version 2.4.1 of OpenOffice.org has been released. "The OpenOffice.org Community is pleased to announce the release of OpenOffice.org 2.4.1, a minor update of OpenOffice.org 2.4 released in March 2008."
Video Applications
Dirac Beta version (0.10.0) released
Beta version 0.10.0 of the Dirac video codec has been announced. Changes include new support for ultra high definition video, improved compression performance, bug fixes and more.
Web Browsers
Mozilla Firefox 3 Release Candidate 2 Available (MozillaZine)
MozillaZine has announced the availability of Firefox 3 RC 2. "The second candidate build for Mozilla's next generation Firefox browser is now available for testing. Firefox 3 Release Candidate 2 can be downloaded from the Firefox Release Candidates page. The Firefox 3 Release Candidate 2 Release Notes have more details."
Miscellaneous
Souzou: Version 0.1.0 Released (SourceForge)
The initial release of Souzou has been announced. "Souzou is a cross-platform drawing board application written in C++. It is intended to be used with homemade Wiimote smartboards, and allows the interactive whiteboard to be used like a normal whiteboard, and allows you to save captures of the content."
Languages and Tools
C
GCC 4.3.1 released
Version 4.3.1 of GCC, the GNU Compiler Collection, has been announced. See the changes document for details.
Caml
Caml Weekly News
The June 10, 2008 edition of the Caml Weekly News is out with new articles about the Caml language.
Haskell
Haskell Communities and Activities Report
The May, 2008 edition of the Haskell Communities and Activities Report has been published. "This is the 14th edition of the Haskell Communities and Activities Report. There has been a transition in editorship which went very smoothly, also thanks to the many responsive contributors who where as helpful to the new editor as they have been to Andres during the last years."
Java
GNU Classpath 0.97.2 released
Version 0.97.2 of GNU Classpath, the essential libraries for Java, has been announced. "This is the second of a new series of bugfix releases that follow a major (0.x) release. A 0.x.y release will only contain minor bug fixes. It will not cause major changes in the functionality of GNU Classpath, either for better or for worse."
Qt Jambi 4.4 has been released (KDE.News)
KDE.News takes a look at Qt Jambi 4.4. "Trolltech today announced the launch of Qt Jambi 4.4 the latest version of its application framework for Java development. Qt Jambi is based on the recently-launched Qt 4.4, and brings its benefits to Java developers: including the ability to develop web and multimedia enriched applications across desktop operating systems."
Perl
This Week on perl5-porters (use Perl)
The May 25-31, 2008 edition of This Week on perl5-porters is out with the latest Perl 5 news.
Python
Practical threaded programming with Python (IBM developerWorks)
Noah Gift discusses threaded programming with Python on IBM developerWorks. "Threaded programming in Python can be done with a minimal amount of complexity by combining threads with Queues. This article explores using threads and queues together to create simple yet effective patterns for solving problems that require concurrency."
Python-URL! - weekly Python news and links
The June 11, 2008 edition of the Python-URL! is online with a new collection of Python article links.
Tcl/Tk
Tcl-URL! - weekly Tcl news and links
The June 8, 2008 edition of the Tcl-URL! is online with new Tcl/Tk articles and resources.
UML
UMLet: 9.01 Released (SourceForge)
Version 9.01 of UMLet has been announced. "UMLet is an open-source Java tool for rapidly drawing UML diagrams, with a focus on a sound and pop-up-free user interface. Its homepage is http://www.umlet.com. UMLet 9.01 is available at http://www.umlet.com. Changes: CPU load issue on Linux resolved."
Page editor: Forrest Cook
Linux in the news
Recommended Reading
Stallman attacks Oyster's 'unethical' use of Linux (ZDNet)
Richard Stallman is not known for pulling punches, as he demonstrates in an attack on the Oyster payment system for the London Underground railway. ZDNet has the coverage of his complaints, which are based on very real privacy concerns that have little or nothing to do with Linux. "Online payments cannot be made anonymously, so anyone paying online or linking their Oyster card to a credit card for automatic top-ups is handing their travel information to the government, Stallman argued. He also warned that the RFID chip on the card might be read at other times, allowing information to be gathered besides details of Tube and bus travel."
Trade Shows and Conferences
KDE at LinuxTag 2008 in Berlin (KDE.News)
KDE.News covers the KDE presence at LinuxTag, which was held recently in Berlin. There were two booths, one for KDE and another for Amarok, plus multiple talks in the KDE track. "Both main booths were well manned and even better visited. The interested crowd asked zillions of questions and was very eager to see the latest features, goodies and eyecandy of KDE 4.1 which we showed on all computers at the booth, on Linux, Mac OS X and Windows. Other visitors came by to share ideas or suggestions, and altogether they gave wonderful feedback."
Companies
Acer likes Linux for laptops (c|net)
c|net looks at Acer's shift toward Linux-based laptops. "In an interview with VNUNet.com, Acer Vice President of Marketing Gianpiero Morbello said his Taiwanese PC maker has big plans to develop the market for Linux, not only on its low-cost ultraportable, but on the company's laptops as well. The Acer Aspire One is just the beginning of Acer's foray into the Linux world, according to a company exec. The reason is because of the cost and operation of Microsoft's operating system over open-source Linux. "We have shifted towards Linux because of Microsoft," said Morbello. "Microsoft has a lot of power and it is going to be difficult, but we will be working hard to develop the Linux market.""
Google Gadgets for Linux appears (ZDNet)
ZDNet reports on the availability of Google Gadgets for Linux, a set of mini-applications for the desktop. "Zhuang invited developers to view the source code for the entire project. "For Gadgets for Linux, we don't just want to simply release the final offering, but we also want to give everyone a chance to tinker with the code powering the gadgets," Zhuang wrote. "For this project, fostering a transparent and lively developer community is just as important as serving our users." Google Gadgets for Linux are compatible with those written for Google Desktop for Windows and the "Universal Gadgets" on iGoogle. Therefore, according to the company, "a large library of existing gadgets [is] immediately available to Linux users, [and] gadget developers will benefit from a much larger potential user base without having to learn a new API"."
Resources
Add multitouch gesture support to a TouchPad-equipped laptop (developerWorks)
IBM's developerWorks has an article describing how to detect multitouch gestures using a Synaptics TouchPad on Linux. "This article provides tools and code needed to add some of this new gesture support on older Linux®-enabled hardware. Building on the output of the synclient program, the Perl code presented here allows you to assign specific application functions to 'Three-Finger Swipe,' as well as open- and close-pinch gestures."
Reviews
KDE 4 Progress: New plasmoids, Akonadi, KRunner and more (polishlinux.org)
PolishLinux.org looks at a KDE 4.1 snapshot. "In spite of fragmentary information about changes, that I've published since my last insight (like the Amarok 2 visual changelog), I've decided after all to gather them all in one place. Hence, I invite you to the next insight of KDE 4. The revision of the day is 811150." (Found on KDE.News)
Linux captures the 'green' flag, beats Windows 2008 power-saving measures (Network World)
Network World takes a look at power consumption by comparing Red Hat Enterprise Linux 5.1, SUSE Enterprise Linux 10 SP1, and Windows Server 2008 on four different servers. "The results showed that while Windows Server 2008 drew slightly less power in a few test cases when it had its maximum power saving settings turned on, it was RHEL that did the best job of keeping the power draw in check across the board."
Page editor: Forrest Cook
Announcements
Non-Commercial announcements
Ardour participates in Summer Code Finland
The Ardour multi-track audio workstation project has announced the participation by Sakari Bergen in the Summer Code Finland. "We were lucky to discover that Sakari Bergen, an open source enthusiast and student at the Helsinki University of Technology, was chosen to be a part of the Summer Code Finland program. Sakari will be working on Ardour for three months this summer, improving export functionality and adding meta data support."
EFF Asks Judge to Block Unmasking of MySpace User
The Electronic Frontier Foundation has announced an effort to protect an anonymous MySpace poster. "Cook County, IL - The Electronic Frontier Foundation (EFF) asked a judge in Illinois Wednesday to reject an attempt to identify an anonymous MySpace user who allegedly posted fake profiles of an Illinois official because the request would violate both the First Amendment and federal statute."
Leading Intellectual Property Attorney Joins EFF
Michael Kwun has joined the Electronic Frontier Foundation as a Senior Intellectual Property Staff Attorney. "Kwun comes to EFF from Google. As the company's Managing Counsel, Litigation, he was responsible for defending Google in copyright cases about YouTube, Google Book Search, and Google Image Search; trademark cases about Google AdWords; and patent cases in connection with a wide variety of Google products."
Firefox 3 Release and Mozilla 10th Anniversary Parties (MozillaZine)
MozillaZine has announced upcoming Firefox 3 and Mozilla parties. "Gervase Markham has posted a note on his weblog announcing that mozillaparty.com is now open for booking parties to celebrate the release of Firefox 3 and also Mozilla's 10th anniversary. At this time, there are over 200 parties registered, and over 900 people signed up to attend."
SFLC Files Another Round of GPL Violation Lawsuits on Behalf of BusyBox Developers
The Software Freedom Law Center (SFLC) has announced that it has filed two more copyright infringement lawsuits, on behalf of two principal developers of BusyBox, alleging violation of the GNU General Public License (GPL). The defendants in this new round of lawsuits are Bell Microproducts, Inc. and Super Micro Computer, Inc.
Commercial announcements
IGEL introduces 9 new Citrix XenDesktopT Appliances
IGEL has announced the availability of 9 new thin clients. "IGEL Technology, the world's third largest thin client vendor, today announced the broadest range of Linux-based thin client models supporting the important Citrix XenDesktop(tm) Appliance standard. The standard, published by Citrix in Q1 2008, ensures that any compliant access device connected to Citrix XenDesktop behaves exactly like a normal PC. IGEL's latest firmware upgrade allows all Linux-based IGEL thin clients to be switched, with just one mouse click, from a traditional IGEL Universal Desktop to a tightly defined virtual PC using ICA to access Citrix XenDesktop."
Novell joins Microsoft server virtualization validation program
Novell, Inc. has announced the joining of Microsoft's Server Virtualization Validation Program. "As a result of Novell's participation in this program, customers will be able to confidently run Windows Server 2008 as a virtualized guest on top of the Xen hypervisor in SUSE(R) Linux Enterprise 10 and receive cooperative support from either company. Novell is currently running the tests required by the validation process in the Server Virtualization Validation Program, and expects the tests to be completed by August 2008."
Customers, Partners Run Top Supercomputers on SUSE Linux Enterprise Server for High Performance Computing
Novell has a press release about the TOP500 supercomputers that are running SUSE Linux Enterprise. "According to TOP500, a project that tracks and detects trends in high-performance computing, SUSE Linux Enterprise is the Linux* of choice on the world's largest HPC supercomputers today. Of the top 50 supercomputers worldwide, 40 percent are running on SUSE Linux Enterprise, including the top three -- IBM* eServer Blue Gene at the Lawrence Livermore National Laboratory, IBM eServer BlueGene/P (JUGENE) at the Juelich Research Center and SGI* Altix 8200 at the New Mexico Computing Applications Center."
Pentaho releases Pentaho Business Intelligence Platform under GPL
Pentaho has announced the release of the Pentaho Business Intelligence Platform under the GPLv2. "Pentaho Corp., the commercial open source alternative for business intelligence (BI), today announced that its current version 2 alpha release of the Pentaho BI Platform, as well as future versions, will be distributed under the terms of the GNU General Public License Version 2 (GPLv2)."
Terra Soft Launches Quad-Core 'YDL PowerStation'
Here's the official announcement for the YDL PowerStation. "Available exclusively from Terra Soft Solutions, the YDL PowerStation offers four 2.5GHz IBM 970MP cores, up to 32GB RAM, dual Gigabit ethernet, four USB 2.0 ports, integrated ultra-fast SAS with 4 hot-swap bays, both PCI-E and PCI-X slots, and support for x86 architecture graphics cards."
Virtual Bridges announces major update of Win4Lin
Virtual Bridges has announced Win4Lin Desktop 5 with support for Ubuntu 8.04. "Version 5 of Win4Lin Desktop is very fast. Virtualized desktops are very convenient and do not require a user to either reboot or use a second personal computer to run their remaining PC applications (often Intuit Quicken or QuickBooks) but users often complain theyre just too slow. Users make this comment whether theyre running Windows virtualized on Linux, OS X or Solaris and regardless of which vendor has developed the virtualized desktop. Win4Lin Desktop 5 answers this concern with blazing speed. Based on a massively modernized code base, Win4Lin Desktop 5 makes it possible to eliminate the need for rebooting or for maintaining a second PC box."
YDL PowerStation - coming soon
We are jumping the gun just a bit with this announcement, but with all the small Linux laptops on the market here's a larger box that will be available next week. TerraSoft Solutions will be announcing the commercial incarnation of a prototype previously demonstrated at recent OLS and LCA events. It may be the most robust and "open" PPC64 box available designed with Linux developers in mind. This box has a Quad-core PPC64, with up to 32GB RAM. It also features IBM's Slimline Open Firmware, which is available for download (registration required) and Yellow Dog Linux. The TerraSoft Solutions YDL PowerStation will be available June 10, 2008. (Thanks to Robert MacFarlan)
New Books
Valgrind - Advanced Debugging and Profiling for GNU/Linux applications
Network Theory Ltd has published the book Valgrind - Advanced Debugging and Profiling for GNU/Linux applications by J. Seward, N. Nethercote, J. Weidendorfer and the Valgrind Development Team.
Resources
ODBMS.org publishes panel discusson
ODBMS.org has published a panel discussion entitled "ODBMS: Quo Vadis?". "ODBMS.ORG, a vendor-independent non-profit group of high-profile software experts lead by Prof. Roberto Zicari, today announced a new panel discussion "Object Database Systems: Quo vadis?" with responses from the ODBMS.ORG experts Mike Card, Jim Paterson, and Kazimierz Subieta, on their views on on some critical questions related to Object Databases".
Meeting Minutes
Perl 6 Design Minutes for 28 May, 2008
The minutes from the May 28, 2008 Perl 6 Design Meeting have been published. "The Perl 6 design team met by phone on 28 May 2008. Larry, Allison, Patrick, Jerry, and chromatic attended."
Minutes from the Ubuntu Technical Board meeting
The minutes from the June 3, 2008 Ubuntu Technical Board meeting have been posted. "Present: Matt Zimmerman (chair) Scott James Remnant (board member) Till Kamppeter Jamie Strandboge Martin Pitt Stephan Hermann Soren Hansen Kees Cook Chuck Short Mathias Gug"
Calls for Presentations
FOMS2009 Call for Participation
A call for participation has gone out for the Foundations of Open Media Software Developer Workshop. The event takes place in Hobart, Tasmania, Australia on January 15-16, 2008. The submission deadline is August 15.OpenOffice.org annual conference update
A call for papers has gone out for the OpenOffice.org annual conference, the event will be held in Beijing, China on November 5-7, 2008. "Potential speakers: there is still time to submit your proposals for a paper at OOoCon 2008. Following a replan by the organisers, you now have until 18th July to submit your proposal."
PyOhio Call for Proposals deadline extended to June 15
The PyOhio Call for Proposals deadline has been extended to June 15. "PyOhio, the first annual Python programming mini-conference for Ohio and surrounding areas will take place Saturday, July 26, in Columbus, Ohio. The conference is free of change and will include scheduled presentations, Lighting Talks and unconference-style Open Spaces."
Upcoming Events
SciPy 2008 Conference
The SciPy 2008 Conference will take place on August 19-24, 2008 at Caltech in Pasadena, CA. "Exciting things are happening in the Python community, and the SciPy 2008 Conference is an excellent opportunity to exchange ideas, learn techniques, contribute code and affect the direction of scientific computing (or just to learn what all the fuss is about). We'll be announcing the Keynote Speaker and providing a detailed schedule in the coming weeks."
Events: June 19, 2008 to August 18, 2008
The following event listing is taken from the LWN.net Calendar.
| Date(s) | Event | Location |
|---|---|---|
| June 17 June 22 |
Liverpool Open Source City | Liverpool, England |
| June 18 June 20 |
Red Hat Summit 2008 | Boston, MA, USA |
| June 18 June 20 |
National Computer and Information Security Conference ACIS 2008 | Bogota, Columbia |
| June 19 June 21 |
Fedora Users and Developers Conference | Boston, MA, USA |
| June 22 June 27 |
2008 USENIX Annual Technical Conference | Boston, MA, USA |
| June 23 June 24 |
O'Reilly Velocity Conference | San Francisco, CA, USA |
| June 28 June 29 |
Rockbox Euro Devcon 2008 | Berlin, Germany |
| July 1 July 5 |
Libre Software Meeting 2008 | Mont-de-Marsan, France |
| July 3 July 4 |
SyScan08 Singapore | Novotel Clarke Quay, Singapore |
| July 3 | Penguin in a Box 2008: Embedded Linux Seminar | Herzelia, Israel |
| July 5 | Open Tech 2008 | London, England |
| July 7 July 12 |
EuroPython 2008 | Vilnius, Lithuania |
| July 7 July 12 |
GUADEC 2008 | Istanbul, Turkey |
| July 14 July 18 |
PHP 5 & PostgreSQL Bootcamp at the Big Nerd Ranch | Atlanta, USA |
| July 18 July 20 |
RubyFringe | Canada, Toronto |
| July 19 | Firebird Developers Day | Piracicaba-SP, Brazil |
| July 19 July 25 |
Ruby & Ruby on Rails Bootcamp at the Big Nerd Ranch | Atlanta, USA |
| July 19 July 20 |
LugRadio Live 2008 - UK | Wolverhampton, United Kingdom |
| July 20 | OSCON PDXPUG Day | Portland, OR, USA |
| July 21 July 25 |
O'Reilly Open Source Convention | Portland, OR, USA |
| July 21 July 22 |
Ubuntu Live - cancelled | Portland, Oregon, USA |
| July 23 July 26 |
Ottawa Linux Symposium | Ottawa, Canada |
| July 26 | PyOhio 2008 | Columbus, OH, USA |
| July 26 July 27 |
EuroSciPy2008 | Leipzig, Germany |
| August 1 | LLVM Developers' Meeting | Cupertino, CA, USA |
| August 3 August 9 |
DebCamp 2008 | Mar del Plata, Argentina |
| August 4 August 7 |
LinuxWorld Conference & Expo | San Francisco, CA, USA |
| August 9 August 16 |
Akademy 2008 | Sint-Katelijne-Waver, Belgium |
| August 9 August 17 |
Linuxbierwanderung (Linux Beer Hike) | Samnaun/Compatsch, Switzerland |
| August 10 August 16 |
Debian Conference 2008 | Mar del Plata, Argentina |
| August 11 August 15 |
SAGE-AU'2008 | Adelaide, Australia |
| August 12 August 14 |
Flash Memory Summit | Santa Clara, CA, USA |
| August 13 August 15 |
YAPC::Europe 2008 | Copenhagen, Denmark |
If your event does not appear here, please tell us about it.
Audio and Video programs
French KDE Day Conference Videos available (KDE.News)
KDE.News has announced the availability of videos from a recent French KDE event. "To celebrate the release of KDE 4, the KDE French contributors and the Toulibre LUG organised a two-day event on January 25th and 26th 2008 in Toulouse, France. On the 25th, Kévin Ottens made a general presentation of KDE 4, and on the 26th there was a day of technical conferences featuring speakers such as David Faure, Laurent Montel, Alexis Ménard, Kévin Ottens, Aurélien Gâteau and Anne-Marie Mahfouf. The videos of all these talks, in French, are now available for download."
Page editor: Forrest Cook