
LWN.net Weekly Edition for November 15, 2007
Google's phone initiative: Android
The media frenzy over Google's Android announcement has subsided, a bit, with actual details of the platform and strategy starting to emerge. Android is the long-rumored gPhone in a very different guise; instead of creating a phone, Google has created the Open Handset Alliance (OHA) – bringing together more than 30 different hardware and software companies – to develop a platform for mobile phones. That platform is Android, a Linux-based, Java-programmed framework for developing mobile applications. With this week's release of the Software Development Kit (SDK), we can now see some sample code as well as seeing how Google intends to attract developers to the platform.
Google has a stated intent to release "most of the components" of Android under the Apache v2 license, but the "early look" SDK has a much more stringent license. The license terms appear to give the OHA and Google some wiggle room regarding pieces of the software that they may not be willing or able to release under the Apache license, but a strict reading will worry free software folks. Some of the components of Android, Linux in particular, are released under other licenses, so the most charitable interpretation is that "most" is referring to those non-Apache-licensed components, but it will be a while before we know.
The SDK comes with lots of sample code for applications, but none for the tools that come with it; that will presumably come later. Probably the most interesting piece of Android is the Dalvik virtual machine (VM), which handles running the Java applications, but is not a Java virtual machine (JVM). Instead, Dalvik takes the .class and .jar files produced by the Java compiler and turns them into Dalvik executable (.dex) files.
![[ Android Emulator ]](https://static.lwn.net/images/android/android3_sm.png)
Dalvik is a register-based VM – unlike Java's stack-based implementation – that was created with a focus on minimizing the memory footprint. There may be optimizations possible with Dalvik's model that are not possible for JVM bytecode, but there may also be another motive for Android having its own VM: it is not subject to the Sun-controlled Java Community Process. Google is trying to leverage developer knowledge and understanding of the Java language and class libraries, without, necessarily, rigorously following the Java "standard".
Android uses the Apache Harmony class libraries to provide compatibility with Java Standard Edition (Java SE). There is an ongoing dispute between the Apache foundation and Sun regarding certification of the Harmony code as Java SE compatible, but that appears not to be much of a concern for Google and the OHA. It will be interesting to see if Sun's recent patent beliefs extend to implementations of Java SE that might infringe their patents.
Java Micro Edition (Java ME) runs on a large number of mobile phones today, but has been fragmented by the various phone vendors, breaking the (mostly illusory) "write once, run anywhere" promise that Java popularized. Though an Apache license won't prohibit that kind of fragmentation, the OHA requires its members to agree not to fragment the Android platform. That agreement has not been made public and likely lacks any teeth to punish violators, but it does serve as a statement of intent. It is clear that Google and the other OHA members have learned from the Java ME implementations in current phones and have something fairly different in mind.
The key to success of the Android platform will be in the applications that get built for it. If Android phones have enough unique and interesting tools, customers will seek it out – at least in theory. The early release of the SDK, long before real hardware is available, is part of the strategy to attract developers. Google has also put up $10 million for bounties as part of the Android Developer Challenge. Developers can enter their applications until March 3, with the best 50 receiving $25,000 each. Those winners will then be eligible for even larger, six-figure, awards after handsets are available in the second half of 2008.
![[ Android Emulator ]](https://static.lwn.net/images/android/android1_sm.png)
Money is certain to motivate some to write Android applications, but an easy-to-program interface based on an open platform will be enough for others. Android is definitely being touted as being easy to develop for, with one of the introductory videos showing a few sample programs that were claimed to be completed in a day. The SDK comes with an emulator that allows developing and debugging without access to phone hardware. Screenshots of different emulator "skins", which represent different hypothetical handset models, accompany this article.
The project community is, unsurprisingly, hosted at code.google.com. The site is already active, just a few days after the release, with an impressive amount of documentation available. The discussion group has quite a bit of traffic with questions, bug reports, and ideas for additional functionality. One recent poster had ported busybox to Android, making all of the normal UNIX command-line tools available in the emulator.
Android is a bold move that strikes at the heart of some entrenched interests, most notably Sun, but Apple (perhaps only recently entrenched) as well. Other mobile phone OS vendors, Symbian and Microsoft for example, could be hurt by widespread Android adoption as well. There is the ever-present threat of patent litigation getting in the way, but the backing of Google and the other OHA members should help to blunt that kind of attack. The real question is whether Android offers something compelling to both developers and users. The handset makers and cellular carriers will also need to do more than just join an alliance too; phones will need to be created and sold.
Unfortunately, the real losers in this could be OpenMoko and Qtopia. Both are free software platforms for mobile phones, but neither has been able to generate the publicity that Google has. At a fundamental level, Android takes a different approach, requiring all applications to run atop Dalvik, whereas OpenMoko and Qtopia both allow for native code, compiled from C or C++. Each allows the possibility of porting applications from other platforms, but it is likely that there are far more mobile phone Java applications than the others, which might give Android a leg up. It is certainly possible to run a Java VM (or even a Dalvik VM) on OpenMoko or Qtopia, which might open those platforms up to more applications, but the Android initiative has the appearance of a juggernaut – at least in the early going.
Java may offer some security advantages as well. Native code cannot be sandboxed easily so it will be easier to write malware for platforms that support it. The mobile phone malware "industry" is still in its infancy, but we can expect to see more of it as more sophisticated phones get into the hands of more security-unconscious users.
While iPhone users still wait for the ability to build applications for their phone, free software users have multiple choices of development platforms. The Neo 1973 hardware from OpenMoko is getting closer to availability for end users, with at least two software stacks available. It certainly wouldn't be too surprising to see Android ported to the Neo as well, though no official word has been heard as of yet. It is an exciting time for free software and for mobile phone users as we have just begun to see what the community can do in this space. With luck, there will be room for multiple free mobile platforms, avoiding a monoculture, as well.
Getting the (Share)Point About Document Formats
The OpenDocument Foundation was formed in 2005, with the mission "to provide a conduit for funding and support for individual contributors to participate in ODF development" at the standards body OASIS. So, at a time when backing for the ODF format seems to be gaining in strength around the world, eyebrows were naturally raised when Sam Hiser, the Foundation's Vice President and Director of Business Affairs, wrote on October 16 that it was no longer supporting ODF:
Microsoft's Jason Matusow naturally allowed himself a little Schadenfreude, Mary Jo Foley waxed apocalyptic, speculating that "the ODF camp might unravel before Microsoft's rival Office Open XML (OOXML) comes up for final international vote early next year," and IBM's Rob Weir provided a characteristically witty point-by-point criticism of the group's reasoning behind its move, dubbing the OpenDocument Foundation "two guys without a garage", in a nod to the "mythology of Silicon Valley" and its history of "two guys in a garage founding great enterprises."
Meanwhile, in an attempt to understand what was going on, standards expert Andy Updegrove tried applying Occam's Razor:
That seems a little hard to believe, though, given the years of hard work put in by Foundation members in support of ODF. For example, Hiser notes that he worked on the OpenOffice.org project "from 2001 through its 20-millionth download. I was OpenOffice.org's Marketing Project Lead...back when people said 'Open What?'" Moreover, if the Foundation had really wanted to wield a sharp stick, it could have done so far more effectively by announcing its break earlier. As Hiser points out: "I was supportive of ODF into the summer in order to avoid negative attention for ODF leading up to the September ISO vote on OOXML."
The roots of the Foundation's decision to abandon the ODF format in favour of the little-known Compound Document Formats (CDF) from the W3C go back to one of the most fraught and painful episodes in the history of open source and open standards: the attempt by the Commonwealth of Massachusetts to adopt the ODF format. Hiser was in the thick of it:
Sun's Chief Open Source Officer, Simon Phipps, begs to differ:
The main bone of contention between the OpenDocument Foundation and the rest of the community supporting ODF comes down to the issue of whether "100%", full-fidelity interoperability with Microsoft Office is achievable or even desirable. For example, Weir wrote:
The Foundation's position was explained by its President, Gary Edwards:
If however we could achieve full fidelity conversions of legacy Microsoft binary documents to ODF, and were able to guarantee the roundtrip process of these newly christened ODF documents in a mixed desktop environment, one comprised of ODF-enabled Microsoft Office, OpenOffice.org, Novell Office, WorkPlace, and KOffice, the existing MSOffice bound business processes could continue being used even as new ODF ready workstations were added to the workflow. Massachusetts could migrate to non-Microsoft Office software in manageable phases, restoring competition -- and sanity -- to the Commonwealth's software procurement program.
If on the other hand, there is no full fidelity conversion to ODF of legacy documents available at the head point of the migration -- Microsoft Office -- then the business process will break under the weight of users having to stop everything to fix and repair the artifacts of lossy file conversions. What Massachusetts discovered is that users will immediately revert to a Microsoft-only process wherever the business process system breaks down due to conversion fidelity problems. It is a productivity killer and a show stopper for migration to ODF-supporting software.
This line of thinking probably explains the widespread incomprehension that greeted the Foundation's decision to abandon ODF. Supporters of the latter believe that it is by far the best document format, one that provides numerous benefits to users, notably freedom from lock-in. Hiser couldn't agree more: "We don't want OOXML to ever see the light of day, and certainly we feel deeply that it needs to be rejected by ISO finally and conclusively." But he adds:
In companies running the Microsoft enterprise stack, those "sticky business processes" are defined and stored in a program that has a surprisingly low profile, but which may well turn out to be the biggest emerging threat to open source: Sharepoint. One perceptive observer, Alfresco's Matt Asay, had already spotted that threat 18 months ago, and is just as worried today:
Even worse, this same lock-in applies to any ODF documents the user might have. As Asay explains:
In other words, the lock-in occurs not at the document level - the one the ODF community is most focused on - but at the level of the workflow. If companies can't export their documents with ease and with perfect fidelity, the Foundation believes, they will simply opt for the default Microsoft solution - Sharepoint - and become trapped by workflow lock-in. This is why the Hiser and his colleagues have shifted their support away from ODF to CDF, which they think could allow companies to export Microsoft Office documents with perfect fidelity into other, truly open workflow systems. Asay's explains the difference with reference to his own company's product:
The Foundation believes that the ODF format could have addressed this issue had it added certain extensions to the standard to provide perfect interoperability with Microsoft's Office documents. Some, like Weir, doubt this:
Given the reluctance of the ODF community to take that route, the Foundation hopes to blunt the Sharepoint threat by combining the CDF format with some code it had already written for use with ODF files, called the "da Vinci" plugin. Hiser explains where the name came from:
It is the da Vinci plugin, the Foundation claims, that will allow perfect interoperability with Microsoft's Office files, which in turn will allow such documents to be taken out of the Microsoft ecosystem into open workflow software without users seeing any loss of fidelity. Partly because of the grand claims made for it, the plugin has been the cause of much of the skepticism surrounding the Foundation's ideas and future plans. As Weir wrote:
Hiser explains that in fact they had intended to release it as open source: "we actually agreed to open source it, and Massachusetts said, 'oh, great, OK'. And then the vendors that Louis [Gutierrez] asked to fund it walked away. When Louis resigned, we stopped doing work."
With the start of the CDF project, Hiser and Edwards have new priorities: "The reason for not opening sourcing it [now] is not because we're going to make a million dollars, although that's one of our goals too. We are business people: we need to fund the business that sells products, and we have to do that in about that magnitude to sustain our developing capabilities, and to feed our families." They will also be coming up with a new name for the now-defunct OpenDocument Foundation: "It takes time to do a total brand and corporate make-over," Hiser says, "but that's underway. I'm leaning toward 'Two Guys Without a Garage LLC'."
Whether or not CDF is the right format, whether the da Vinci plugin can provide 100% interoperability, and whether the new company of Hiser and Edwards will flourish, remains to be seen. In any case, the dramatic decision to break with the ODF community, and the attendant publicity it has garnered, may have already achieved something beneficial, for it has helped to direct attention towards the hitherto largely under-appreciated threat that Microsoft's Sharepoint represents for open source, open documents and open standards in the enterprise.
Asay has some thoughts on what must be done to meet that threat:
Weir agrees, and even sees an downside to Microsoft's huge installed base of Office users:
Clearly, then, now is a good time for two guys with - or even without - a garage to get coding, and found that great open source enterprise.
Glyn Moody writes about open source at opendotdotdot.
Memory part 8: Future technologies
[Editor's note: Here, at last, is the final segment of Ulrich Drepper's "What every programmer should know about memory." This eight-part series began back in September. The conclusion of this document looks at how future technologies may help to improve performance as the memory bottleneck continues to worsen.We would like to thank Ulrich one last time for giving LWN the opportunity to help shape this document and bring it to our readers. Ulrich plans to post the entire thing in PDF format sometime in the near future; we'll carry an announcement when that happens.]
8 Upcoming Technology
In the preceding sections about multi-processor handling we have seen that significant performance problems must be expected if the number of CPUs or cores is scaled up. But this scaling-up is exactly what has to be expected in the future. Processors will get more and more cores, and programs must be ever more parallel to take advantage of the increased potential of the CPU, since single-core performance will not rise as quickly as it used to.
8.1 The Problem with Atomic Operations
Synchronizing access to shared data structures is traditionally done in two ways:
- through mutual exclusion, usually by using functionality of the
system runtime to achieve just that;
- by using lock-free data structures.
The problem with lock-free data structures is that the processor has to provide primitives which can perform the entire operation atomically. This support is limited. On most architectures support is limited to atomically read and write a word. There are two basic ways to implement this (see Section 6.4.2):
- using atomic compare-and-exchange (CAS) operations;
- using a load lock/store conditional (LL/SC) pair.
It can be easily seen how a CAS operation can be implemented using LL/SC instructions. This makes CAS operations the building block for most atomic operations and lock free data structures.
Some processors, notably the x86 and x86-64 architectures, provide a far more elaborate set of atomic operations. Many of them are optimizations of the CAS operation for specific purposes. For instance, atomically adding a value to a memory location can be implemented using CAS and LL/SC operations, but the native support for atomic increments on x86/x86-64 processors is faster. It is important for programmers to know about these operations, and the intrinsics which make them available when programming, but that is nothing new.
The extraordinary extension of these two architectures is that they have double-word CAS (DCAS) operations. This is significant for some applications but not all (see [dcas]). As an example of how DCAS can be used, let us try to write a lock-free array-based stack/LIFO data structure. A first attempt using gcc's intrinsics can be seen in Figure 8.1.
struct elem { data_t d; struct elem *c; }; struct elem *top; void push(struct elem *n) { n->c = top; top = n; } struct elem *pop(void) { struct elem *res = top; if (res != NULL) top = res->c; return res; }Figure 8.1: Not Thread-Safe LIFO
This code is clearly not thread-safe. Concurrent accesses in different threads will modify the global variable top without consideration of other thread's modifications. Elements could be lost or removed elements can magically reappear. It is possible to use mutual exclusion but here we will try to use only atomic operations.
The first attempt to fix the problem uses CAS operations when installing or removing list elements. The resulting code looks like Figure 8.2.
#define CAS __sync_bool_compare_and_swap struct elem { data_t d; struct elem *c; }; struct elem *top; void push(struct elem *n) { do n->c = top; while (!CAS(&top, n->c, n)); } struct elem *pop(void) { struct elem *res; while ((res = top) != NULL) if (CAS(&top, res, res->c)) break; return res; }Figure 8.2: LIFO using CAS
At first glance this looks like a working solution. top is never modified unless it matches the element which was at the top of the LIFO when the operation started. But we have to take concurrency at all levels into account. It might be that another thread working on the data structure is scheduled at the worst possible moment. One such case here is the so-called ABA problem. Consider what happens if a second thread is scheduled right before the CAS operation in pop and it performs the following operation:
- l = pop()
- push(newelem)
- push(l)
The end effect of this operation is that the former top element of the LIFO is back at the top but the second element is different. Back in the first thread, because the top element is unchanged, the CAS operation will succeed. But the value res->c is not the right one. It is a pointer to the second element of the original LIFO and not newelem. The result is that this new element is lost.
In the literature [lockfree] you find suggestions to use a feature found on some processors to work around this problem. Specifically, this is about the ability of the x86 and x86-64 processors to perform DCAS operations. This is used in the third incarnation of the code in Figure 8.3.
#define CAS __sync_bool_compare_and_swap struct elem { data_t d; struct elem *c; }; struct lifo { struct elem *top; size_t gen; } l; void push(struct elem *n) { struct lifo old, new; do { old = l; new.top = n->c = old.top; new.gen = old.gen + 1; } while (!CAS(&l, old, new)); } struct elem *pop(void) { struct lifo old, new; do { old = l; if (old.top == NULL) return NULL; new.top = old.top->c; new.gen = old.gen + 1; } while (!CAS(&l, old, new)); return old.top; }Figure 8.3: LIFO using double-word CAS
Unlike the other two examples, this is (currently) pseudo-code since gcc does not grok the use of structures in the CAS intrinsics. Regardless, the example should be sufficient understand the approach. A generation counter is added to the pointer to the top of the LIFO. Since it is changed on every operation, push or pop, the ABA problem described above is no longer a problem. By the time the first thread is resuming its work by actually exchanging the top pointer, the generation counter has been incremented three times. The CAS operation will fail and, in the next round of the loop, the correct first and second element of the LIFO are determined and the LIFO is not corrupted. Voilà.
Is this really the solution? The authors of [lockfree] certainly make it sound like it and, to their credit, it should be mentioned that it is possible to construct data structures for the LIFO which would permit using the code above. But, in general, this approach is just as doomed as the previous one. We still have concurrency problems, just now in a different place. Let us assume a thread executes pop and is interrupted after the test for old.top == NULL. Now a second thread uses pop and receives ownership of the previous first element of the LIFO. It can do anything with it, including changing all values or, in case of dynamically allocated elements, freeing the memory.
Now the first thread resumes. The old variable is still filled with the previous top of the LIFO. More specifically, the top member points to the element popped by the second thread. In new.top = old.top->c the first thread dereferences a pointer in the element. But the element this pointer references might have been freed. That part of the address space might be inaccessible and the process could crash. This cannot be allowed for a generic data type implementation. Any fix for this problem is terribly expensive: memory must never be freed, or at least it must be verified that no thread is referencing the memory anymore before it is freed. Given that lock-free data structures are supposed to be faster and more concurrent, these additional requirements completely destroy any advantage. In languages which support it, memory handling through garbage collection can solve the problem, but this comes with its price.
The situation is often worse for more complex data structures. The same paper cited above also describes a FIFO implementation (with refinements in a successor paper). But this code has all the same problems. Because CAS operations on existing hardware (x86, x86-64) are limited to modifying two words which are consecutive in memory, they are no help at all in other common situations. For instance, atomically adding or removing elements anywhere in a double-linked list is not possible. {As a side note, the developers of the IA-64 did not include this feature. They allow comparing two words, but replacing only one.}
The problem is that more than one memory address is generally involved, and only if none of the values of these addresses is changed concurrently can the entire operation succeed. This is a well-known concept in database handling, and this is exactly where one of the most promising proposals to solve the dilemma comes from.
8.2 Transactional Memory
In their groundbreaking 1993 paper [transactmem] Herlihy and Moss propose to implement transactions for memory operations in hardware since software alone cannot deal with the problem efficiently. Digital Equipment Corporation, at that time, was already battling with scalability problems on their high-end hardware, which featured a few dozen processors. The principle is the same as for database transactions: the result of a transaction becomes visible all at once or the transaction is aborted and all the values remain unchanged.
This is where memory comes into play and why the previous section bothered to develop algorithms which use atomic operations. Transactional memory is meant as a replacement for—and extension of—atomic operations in many situations, especially for lock-free data structures. Integrating a transaction system into the processor sounds like a terribly complicated thing to do but, in fact, most processors, to some extent, already have something similar.
The LL/SC operations implemented by some processors form a transaction. The SC instruction aborts or commits the transaction based on whether the memory location was touched or not. Transactional memory is an extension of this concept. Now, instead of a simple pair of instructions, multiple instructions take part in the transaction. To understand how this can work, it is worthwhile to first see how LL/SC instructions can be implemented. {This does not mean it is actually implemented like this.}
8.2.1 Load Lock/Store Conditional Implementation
If the LL instruction is issued, the value of the memory location is loaded into a register. As part of that operation, the value is loaded into L1d. The SC instruction later can only succeed if this value has not been tampered with. How can the processor detect this? Looking back at the description of the MESI protocol in Figure 3.18 should make the answer obvious. If another processor changes the value of the memory location, the copy of the value in L1d of the first processor must be revoked. When the SC instruction is executed on the first processor, it will find it has to load the value again into L1d. This is something the processor must already detect.
There are a few more details to iron out with respect to context switches (possible modification on the same processor) and accidental reloading of the cache line after a write on another processor. This is nothing that policies (cache flush on context switch) and extra flags, or separate cache lines for LL/SC instructions, cannot fix. In general, the LL/SC implementation comes almost for free with the implementation of a cache coherence protocol like MESI.
8.2.2 Transactional Memory Operations
For transactional memory to be generally useful, a transaction must not be finished with the first store instruction. Instead, an implementation should allow a certain number of load and store operations; this means we need separate commit and abort instructions. In a bit we will see that we need one more instruction which allows checking on the current state of the transaction and whether it is already aborted or not.
There are three different memory operations to implement:
- Read memory
- Read memory which is written to later
- Write memory
When looking at the MESI protocol it should be clear how this special second type of read operation can be useful. The normal read can be satisfied by a cache line in the `E' and `S' state. The second type of read operation needs a cache line in state `E'. Exactly why the second type of memory read is necessary can be glimpsed from the following discussion, but, for a more complete description, the interested reader is referred to literature about transactional memory, starting with [transactmem].
In addition, we need transaction handling which mainly consists of the commit and abort operation we are already familiar with from database transaction handling. There is one more operation, though, which is optional in theory but required for writing robust programs using transactional memory. This instruction lets a thread test whether the transaction is still on track and can (perhaps) be committed later, or whether the transaction already failed and will in any case be aborted.
We will discuss how these operations actually interact with the CPU cache and how they match to bus operation. But before we do that we take a look at some actual code which uses transactional memory. This will hopefully make the remainder of this section easier to understand.
8.2.3 Example Code Using Transactional Memory
For the example we revisit our running example and show a LIFO implementation which uses transactional memory.
struct elem { data_t d; struct elem *c; }; struct elem *top; void push(struct elem *n) { while (1) { n->c = LTX(top); ST(&top, n); if (COMMIT()) return; ... delay ... } } struct elem *pop(void) { while (1) { struct elem *res = LTX(top); if (VALIDATE()) { if (res != NULL) ST(&top, res->c); if (COMMIT()) return res; } ... delay ... } }Figure 8.4: LIFO Using Transactional Memory
This code looks quite similar to the not-thread-safe code, which is an additional bonus as it makes writing code using transactional memory easier. The new parts of the code are the LTX, ST, COMMIT, and VALIDATE operations. These four operations are the way to request accesses to transactional memory. There is actually one more operation, LT, which is not used here. LT requests non-exclusive read access, LTX requests exclusive read access, and ST is a store into transactional memory. The VALIDATE operation is the operation which checks whether the transaction is still on track to be committed. It returns true if this transaction is still OK. If the transaction is already marked as aborting, it will be actually aborted and the next transactional memory instruction will start a new transaction. For this reason, the code uses a new if block in case the transaction is still going on.
The COMMIT operation finishes the transaction; if the transaction is finished successfully the operation returns true. This means that this part of the program is done and the thread can move on. If the operation returns a false value, this usually means the whole code sequence must be repeated. This is what the outer while loop is doing here. This is not absolutely necessary, though, in some cases giving up on the work is the right thing to do.
The interesting point about the LT, LTX, and ST operations is that they can fail without signaling this failure in any direct way. The way the program can request this information is through the VALIDATE or COMMIT operation. For the load operation, this can mean that the value actually loaded into the register might be bogus; that is why it is necessary in the example above to use VALIDATE before dereferencing the pointer. In the next section, we will see why this is a wise choice for an implementation. It might be that, once transactional memory is actually widely available, the processors will implement something different. The results from [transactmem] suggest what we describe here, though.
The push function can be summarized as this: the transaction is started by reading the pointer to the head of the list. The read requests exclusive ownership since, later in the function, this variable is written to. If another thread has already started a transaction, the load will fail and mark the still-born transaction as aborted; in this case, the value actually loaded might be garbage. This value is, regardless of its status, stored in the next field of the new list member. This is fine since this member is not yet in use, and it is accessed by exactly one thread. The pointer to the head of the list is then assigned the pointer to the new element. If the transaction is still OK, this write can succeed. This is the normal case, it can only fail if a thread uses some code other than the provided push and pop functions to access this pointer. If the transaction is already aborted at the time the ST is executed, nothing at all is done. Finally, the thread tries to commit the transaction. If this succeeds the work is done; other threads can now start their transactions. If the transaction fails, it must be repeated from the beginning. Before doing that, however, it is best to insert an delay. If this is not done the thread might run in a busy loop (wasting energy, overheating the CPU).
The pop function is slightly more complex. It also starts with reading the variable containing the head of the list, requesting exclusive ownership. The code then immediately checks whether the LTX operation succeeded or not. If not, nothing else is done in this round except delaying the next round. If the top pointer was read successfully, this means its state is good; we can now dereference the pointer. Remember, this was exactly the problem with the code using atomic operations; with transactional memory this case can be handled without any problem. The following ST operation is only performed when the LIFO is not empty, just as in the original, thread-unsafe code. Finally the transaction is committed. If this succeeds the function returns the old pointer to the head; otherwise we delay and retry. The one tricky part of this code is to remember that the VALIDATE operation aborts the transaction if it has already failed. The next transactional memory operation would start a new transaction and, therefore, we must skip over the rest of the code in the function.
How the delay code works will be something to see when implementations of transactional memory are available in hardware. If this is done badly system performance might suffer significantly.
8.2.4 Bus Protocol for Transactional Memory
Now that we have seen the basic principles behind transactional memory, we can dive into the details of the implementation. Note that this is not based on actual hardware. It is based on the original design of transactional memory and knowledge about the cache coherency protocol. Some details are omitted, but it still should be possible to get insight into the performance characteristics.
Transactional memory is not actually implemented as separate memory; that would not make any sense given that transactions on any location in a thread's address space are wanted. Instead, it is implemented at the first cache level. The implementation could, in theory, happen in the normal L1d but, as [transactmem] points out, this is not a good idea. We will more likely see the transaction cache implemented in parallel to L1d. All accesses will use the higher level cache in the same way they use L1d. The transaction cache is likely much smaller than L1d. If it is fully associative its size is determined by the number of operations a transaction can comprise. Implementations will likely have limits for the architecture and/or specific processor version. One could easily imagine a transaction cache with 16 elements or even less. In the above example we only needed one single memory location; algorithms with a larger transaction working sets get very complicated. It is possible that we will see processors which support more than one active transaction at any one time. The number of elements in the cache then multiplies, but it is still small enough to be fully associative.
The transaction cache and L1d are exclusive. That means a cache line is in, at most, one of the caches but never in both. Each slot in the transaction cache is in, at any one time, one of the four MESI protocol states. In addition to this, a slot has a transaction state. The states are as follows (names according to [transactmem]):
- EMPTY
- the cache slot contains no data. The MESI state is always 'I'.
- NORMAL
- the cache slot contains committed data. The data could as well exist in L1d. The MESI state can be 'M', 'E', and 'S'. The fact that the 'M' state is allowed means that transaction commits do not force the data to be written into the main memory (unless the memory region is declared as uncached or write-through). This can significantly help to increase performance.
- XABORT
- the cache slot contains data which is discarded on abort. This is obviously the opposite of XCOMMIT. All the data created during a transaction is kept in the transaction cache, nothing is written to main memory before a commit. This limits the maximum transaction size but it means that, beside the transaction cache, no other memory has to be aware of the XCOMMIT/XABORT duality for a single memory location. The possible MESI states are 'M', 'E', and 'S'.
- XCOMMIT
- the cache slot contains data which is discarded on commit. This is a possible optimization processors could implement. If a memory location is changed using a transaction operation, the old content cannot be just dropped: if the transaction fails the old content needs to be restored. The MESI states are the same as for XABORT. One difference with regard to XABORT is that, if the transaction cache is full, any XCOMMIT entries in the 'M' state could be written back to memory and then, for all states, discarded.
When an LT operation is started, the processor allocates two slots in the cache. Victims are chosen by first looking for NORMAL slots for the address of the operation, i.e., a cache hit. If such an entry is found, a second slot is located, the value copied, one entry is marked XABORT, and the other one is marked XCOMMIT.
If the address is not already cached, EMPTY cache slots are located. If none can be found, NORMAL slots are looked for. The old content must then be flushed to memory if the MESI state is 'M'. If no NORMAL slot is available either, it is possible to victimize XCOMMIT entries. This is likely going to be an implementation detail, though. The maximum size of a transaction is determined by the size of the transaction cache, and, since the number of slots which are needed for each operation in the transaction is fixed, the number of transactions can be capped before having to evict XCOMMIT entries.
If the address is not found in the transactional cache, a T_READ request is issued on the bus. This is just like the normal READ bus request, but it indicates that this is for the transactional cache. Just like for the normal READ request, the caches in all other processors first get the chance to respond. If none does the value is read from the main memory. The MESI protocol determines whether the state of the new cache line is 'E' or 'S'. The difference between T_READ and READ comes into play when the cache line is currently in use by an active transaction on another processor or core. In this case the T_READ operation plainly fails, no data is transmitted. The transaction which generated the T_READ bus request is marked as failed and the value used in the operation (usually a simple register load) is undefined. Looking back to the example, we can see that this behavior does not cause problems if the transactional memory operations are used correctly. Before a value loaded in a transaction is used, it must be verified with VALIDATE. This is, in almost no cases, an extra burden. As we have seen in the attempts to create a FIFO implementation using atomic operations, the check which we added is the one missing feature which would make the lock-free code work.
The LTX operation is almost identical to LT. The one difference is that the bus operation is T_RFO instead of T_READ. T_RFO, like the normal RFO bus request, requests exclusive ownership of the cache line. The state of the resulting cache line is 'E'. Like the T_READ bus request, T_RFO can fail, in which case the used value is undefined, too. If the cache line is already in the local transaction cache with 'M' or 'E' state, nothing has to be done. If the state in the local transaction cache is 'S' the bus request has to go out to invalidate all other copies.
The ST operation is similar to LTX. The value is first made available exclusively in the local transaction cache. Then the ST operation makes a copy of the value into a second slot in the cache and marks the entry as XCOMMIT. Lastly, the other slot is marked as XABORT and the new value is written into it. If the transaction is already aborted, or is newly aborted because the implicit LTX fails, nothing is written.
Neither the VALIDATE nor COMMIT operations automatically and implicitly create bus operations. This is the huge advantage transactional memory has over atomic operations. With atomic operations, concurrency is made possible by writing changed values back into main memory. If you have read this document thus far, you should know how expensive this is. With transactional memory, no accesses to the main memory are forced. If the cache has no EMPTY slots, current content must be evicted, and for slots in the 'M' state, the content must be written to main memory. This is not different from regular caches, and the write-back can be performed without special atomicity guarantees. If the cache size is sufficient, the content can survive for a long time. If transactions are performed on the same memory location over and over again, the speed improvements can be astronomical since, in the one case, we have one or two main memory accesses in each round while, for transactional memory, all accesses hit the transactional cache, which is as fast as L1d.
All the VALIDATE and COMMIT operations do for an aborted transaction is to mark the cache slots marked XABORT as empty and mark the XCOMMIT slots as NORMAL. Similarly, when COMMIT successfully finishes a transaction, the XCOMMIT slots are marked empty and the XABORT slots are marked NORMAL. These are very fast operations on the transaction cache. No explicit notification to other processors which want to perform transactions happens; those processors just have to keep trying. Doing this efficiently is another matter. In the example code above we simply have ...delay... in the appropriate place. We might see actual processor support for delaying in a useful way.
To summarize, transactional memory operations cause bus operation only when a new transaction is started and when a new cache line, which is not already in the transaction cache, is added to a still-successful transaction. Operations in aborted transactions do not cause bus operations. There will be no cache line ping-pong due to multiple threads trying to use the same memory.
8.2.5 Other Considerations
In Section 6.4.2, we already discussed how the lock prefix, available on x86 and x86-64, can be used to avoid the coding of atomic operations in some situations. The proposed tricks falls short, though, when there are multiple threads in use which do not contend for the same memory. In this case, the atomic operations are used unnecessarily. With transactional memory this problem goes away. The expensive RFO bus requests are issued only if memory is used on different CPUs concurrently or in succession; this is only the case when they are needed. It is almost impossible to do any better.
The attentive reader might have wondered about delays. What is the expected worst case scenario? What if the thread with the active transaction is descheduled, or if it receives a signal and is possibly terminated, or decides to use siglongjmp to jump to an outer scope? The answer to this is: the transaction will be aborted. It is possible to abort a transaction whenever a thread makes a system call or receives a signal (i.e., a ring level change occurs). It might also be that aborting the transaction is part of the OS's duties when performing system calls or handling signals. We will have to wait until implementations become available to see what is actually done.
The final aspect of transactional memory which should be discussed here is something which people might want to think about even today. The transaction cache, like other caches, operates on cache lines. Since the transaction cache is an exclusive cache, using the same cache line for transactions and non-transaction operation will be a problem. It is therefore important to
- move non-transactional data off of the cache line
- have separate cache lines for data used in separate transactions
The first point is not new, the same effort will pay off for atomic operations today. The second is more problematic since today objects are hardly ever aligned to cache lines due to the associated high cost. If the data used, along with the words modified using atomic operations, is on the same cache line, one less cache line is needed. This does not apply to mutual exclusion (where the mutex object should always have its own cache line), but one can certainly make cases where atomic operations go together with other data. With transactional memory, using the cache line for two purposes will most likely be fatal. Every normal access to data {From the cache line in question. Access to arbitrary other cache lines does not influence the transaction.} would remove the cache line from the transactional cache, aborting the transaction in the process. Cache alignment of data objects will be in future not only a matter of performance but also of correctness.
It is possible that transactional memory implementations will use more precise accounting and will, as a result, not suffer from normal accesses to data on cache lines which are part of a transaction. This requires a lot more effort, though, since then the MESI protocol information is not sufficient anymore.
8.3 Increasing Latency
One thing about future development of memory technology is almost certain: latency will continue to creep up. We already discussed, in Section 2.2.4, that the upcoming DDR3 memory technology will have higher latency than the current DDR2 technology. FB-DRAM, if it should get deployed, also has potentially higher latency, especially when FB-DRAM modules are daisy-chained. Passing through the requests and results does not come for free.
The second source of latency is the increasing use of NUMA. AMD's Opterons are NUMA machines if they have more than one processor. There is some local memory attached to the CPU with its own memory controller but, on SMP motherboards, the rest of the memory has to be accessed through the Hypertransport bus. Intel's CSI technology will use almost the same technology. Due to per-processor bandwidth limitations and the requirement to keep (for instance) multiple 10Gb/s Ethernet ports busy, multi-socket motherboards will not vanish, even if the number of cores per socket increases.
A third source of latency are co-processors. We thought that we got rid of them after math co-processors for commodity processors were no longer necessary at the beginning of the 1990's, but they are making a comeback. Intel's Geneseo and AMD's Torrenza are extensions of the platform to allow third-party hardware developers to integrate their products into the motherboards. I.e., the co-processors will not have to sit on a PCIe card but, instead, are positioned much closer to the CPU. This gives them more bandwidth.
IBM went a different route (although extensions like Intel's and AMD's are still possible) with the Cell CPU. The Cell CPU consists, beside the PowerPC core, of 8 Synergistic Processing Units (SPUs) which are specialized processors mainly for floating-point computation.
What co-processors and SPUs have in common is that they, most likely, have even slower memory logic than the real processors. This is, in part, caused by the necessary simplification: all the cache handling, prefetching etc is complicated, especially when cache coherency is needed, too. High-performance programs will increasingly rely on co-processors since the performance differences can be dramatic. Theoretical peak performance for a Cell CPU is 210 GFLOPS, compared to 50-60 GFLOPS for a high-end CPU. The Graphics Processing Units (GPUs, processors on graphics cards) in use today achieve even higher numbers (north of 500 GFLOPS) and those could probably, with not too much effort, be integrated into the Geneseo/Torrenza systems.
As a result of all these developments, a programmer must conclude that prefetching will become ever more important. For co-processors it will be absolutely critical. For CPUs, especially with more and more cores, it is necessary to keep the FSB busy all the time instead of piling on the requests in batches. This requires giving the CPU as much insight into future traffic as possible through the efficient use of prefetching instructions.
8.4 Vector Operations
The multi-media extensions in today's mainstream processors implement vector operations only in a limited fashion. Vector instructions are characterized by large numbers of operations which are performed together. Compared with scalar operations, this can be said about the multi-media instructions, but it is a far cry from what vector computers like the Cray-1 or vector units for machines like the IBM 3090 did.
To compensate for the limited number of operations performed for one instruction (four float or two double operations on most machines) the surrounding loops have to be executed more often. The example in Section 9.1 shows this clearly, each cache line requires SM iterations.
With wider vector registers and operations, the number of loop iterations can be reduced. This results in more than just improvements in the instruction decoding etc.; here we are more interested in the memory effects. With a single instruction loading or storing more data, the processor has a better picture about the memory use of the application and does not have to try to piece together the information from the behavior of individual instructions. Furthermore, it becomes more useful to provide load or store instructions which do not affect the caches. With 16 byte wide loads of an SSE register in an x86 CPU, it is a bad idea to use uncached loads since later accesses to the same cache line have to load the data from memory again (in case of cache misses). If, on the other hand, the vector registers are wide enough to hold one or more cache lines, uncached loads or stores do not have negative impacts. It becomes more practical to perform operations on data sets which do not fit into the caches.
Having large vector registers does not necessarily mean the latency of the instructions is increased; vector instructions do not have to wait until all data is read or stored. The vector units could start with the data which has already been read if it can recognize the code flow. That means, if, for instance, a vector register is to be loaded and then all vector elements multiplied by a scalar, the CPU could start the multiplication operation as soon as the first part of the vector has been loaded. It is just a matter of sophistication of the vector unit. What this shows is that, in theory, the vector registers can grow really wide, and that programs could potentially be designed today with this in mind. In practice, there are limitations imposed on the vector register size by the fact that the processors are used in multi-process and multi-thread OSes. As a result, the context switch times, which include storing and loading register values, is important.
With wider vector registers there is the problem that the input and output data of the operations cannot be sequentially laid out in memory. This might be because a matrix is sparse, a matrix is accessed by columns instead of rows, and many other factors. Vector units provide, for this case, ways to access memory in non-sequential patterns. A single vector load or store can be parametrized and instructed to load data from many different places in the address space. Using today's multi-media instructions, this is not possible at all. The values would have to be explicitly loaded one by one and then painstakingly combined into one vector register.
The vector units of the old days had different modes to allow the most useful access patterns:
- using striding, the program can specify how big the gap
between two neighboring vector elements is. The gap between all
elements must be the same but this would, for instance, easily allow
to read the column of a matrix into a vector register in one
instruction instead of one instruction per row.
- using indirection, arbitrary access patterns can be created. The
load or store instruction would receive a pointer to an array which
contains addresses or offsets of the real memory locations which
have to be loaded.
It is unclear at this point whether we will see a revival of true vector operations in future versions of mainstream processors. Maybe this work will be relegated to co-processors. In any case, should we get access to vector operations, it is all the more important to correctly organize the code performing such operations. The code should be self-contained and replaceable, and the interface should be general enough to efficiently apply vector operations. For instance, interfaces should allow adding entire matrixes instead of operating on rows, columns, or even groups of elements. The larger the building blocks, the better the chance of using vector operations.
In [vectorops] the authors make a passionate plea for the revival of vector operations. They point out many advantages and try to debunk various myths. They paint an overly simplistic image, though. As mentioned above, large register sets mean high context switch times, which have to be avoided in general purpose OSes. See the problems of the IA-64 processor when it comes to context switch-intensive operations. The long execution time for vector operations is also a problem if interrupts are involved. If an interrupt is raised, the processor must stop its current work and start working on handling the interrupt. After that, it must resume executing the interrupted code. It is generally a big problem to interrupt an instruction in the middle of the work; it is not impossible, but it is complicated. For long running instructions this has to happen, or the instructions must be implemented in a restartable fashion, since otherwise the interrupt reaction time is too high. The latter is not acceptable.
Vector units also were forgiving as far as alignment of the memory access is concerned, which shaped the algorithms which were developed. Some of today's processors (especially RISC processors) require strict alignment so the extension to full vector operations is not trivial. There are big potential upsides to having vector operations, especially when striding and indirection are supported, so that we can hope to see this functionality in the future.
Appendices and bibliography
The appendices and bibliography page contains, among other things, the source code for a number of the benchmark programs used for this document, more information on oprofile, some discussion of memory types, an introduction to libNUMA, and the bibliography.
LWN comes early next week
Thursday, November 22 is the U.S. Thanksgiving holiday. As has become traditional, the LWN Weekly Edition will come out one day early next week so that your editors can focus on fasting in preparation for the Thanksgiving feast. After a few days of football, food, and avoidance of holiday shopping we'll return to our normal schedule on the 29th.
Security
Centralizing policy rules with PolicyKit
Linux security policy is very simple at its core: the root user can do anything, while all other users can do very little. Unfortunately, administrators want to be able to allow other users to do a limited subset of the things root is permitted to do. Various solutions have been implemented to try and solve this problem, with a recent one being PolicyKit.
Mounting removable filesystems, CDs, USB devices, and the like, is a classic example of a root-only task that some non-privileged users might be allowed to perform. In the past, various mechanisms using groups or mount options in /etc/fstab have been used with some success, but the mechanisms were specific to mounting and did not provide the flexibility that some administrators would like. Network configuration - particularly for wireless networking - is another common task that users might be allowed to do.
PolicyKit is an attempt to centralize these kinds of decisions into a single policy file that the administrator can use to set the kinds of access regular users should be allowed. Previous solutions required changing each utility to handle policy, each in its own unique format and file(s). PolicyKit is meant to avoid all of that, creating a single place, with a consistent syntax (the now ubiquitous XML), that details the policy rules for that system.
The PolicyKit philosophy decouples the "mechanism" of performing the privileged operation from the user interface used to request it. A GUI network configuration tool might allow a user to choose a different network to associate with, but would have no direct means to make that change. It would, instead, contact a privileged network management daemon through an interprocess communication mechanism (such as D-Bus). That daemon would use the PolicyKit API to determine whether to grant the request.
In order to make that decision, PolicyKit needs three pieces of information, the subject, object, and action. The subject is the user and process requesting the action, while the object is what entity the action is being requested on. In a network configuration example, the subject would be a uid, along with additional identifying information such as SELinux security context, the action would be to change the association, and the object would be the network device.
The mechanism code calls the PolicyKit library, passing the subject, object, and action, receiving back a decision. The decision could be a simple yes or no, or it could, instead, require that the user authenticate - either as themselves or as root - before allowing the operation. Re-authentication can be required on sensitive actions, such as those that malware or malicious users might want to perform, to provide an additional layer of security. All of this policy is governed by the entries in the PolicyKit configuration file. Once the decision has been rendered, it is up to the mechanism to enforce it. This may require coordination with the UI, especially if authentication is required.
Administrators can modify the PolicyKit configuration by way of an XML file, usually PolicyKit.conf. The man page gives a few examples of entries like the following:
<match action="org.freedesktop.hal.storage.mount-fixed">
<match user="davidz">
<return result="yes"/>
</match>
<match user="freddy">
<return result="no"/>
</match>
</match>
As should be relatively easy to see, this configuration would allow the user
"davidz" to perform the action "mount-fixed" while disallowing the user
"freddy". Depending on the default value for that action, as specified in
the mechanism's configuration, users not listed could be denied,
allowed, or be required to authenticate.
Configuration for mechanisms, which lists the supported actions along with a default policy, is specified in a separate XML file. The mechanism could generate the file on startup and remove it on exit, completely removing the action from the system when it is inactive. Action configuration also includes the message strings that will be displayed by the UI when authenticating or denying users.
PolicyKit has been added to Fedora 8, but is, as yet, mostly unused. There are plans to integrate various GNOME configuration tools with PolicyKit for Fedora 9 and a GNOME API has been created to assist with that. One would guess that a KDE API is in the wings as well.
PolicyKit is not meant to replace SELinux or other security mechanisms, it is simply a means to allow users more privileges in a centralized, easily audited, way. PolicyKit works within the existing access control framework, using whatever privileges have been given to the mechanism. In the end, PolicyKit just provides advice to another program, it is up to that program to enforce the decision, while the OS can and does enforce its own rules upon that process.
New vulnerabilities
3proxy: denial of service
| Package(s): | 3proxy | CVE #(s): | CVE-2007-5622 | ||||
| Created: | November 9, 2007 | Updated: | November 14, 2007 | ||||
| Description: | Double-free vulnerability in the ftpprchild function in ftppr in 3proxy 0.5 through 0.5.3i allows remote attackers to cause a denial of service (daemon crash) via multiple OPEN commands to the FTP proxy. | ||||||
| Alerts: |
| ||||||
Django: denial of service
| Package(s): | Django | CVE #(s): | CVE-2007-5712 | ||||||||||||
| Created: | November 12, 2007 | Updated: | September 22, 2008 | ||||||||||||
| Description: | From the CVE notice: The internationalization (i18n) framework in Django 0.91, 0.95, 0.95.1, and 0.96, and as used in other products such as PyLucid, when the USE_I18N option and the i18n component are enabled, allows remote attackers to cause a denial of service (memory consumption) via many HTTP requests with large Accept-Language headers. | ||||||||||||||
| Alerts: |
| ||||||||||||||
emacs: command execution via local variables
| Package(s): | emacs | CVE #(s): | CVE-2007-5795 | ||||||||||||||||||||
| Created: | November 14, 2007 | Updated: | February 5, 2008 | ||||||||||||||||||||
| Description: | From the original Debian problem report: "In Debian's version of GNU Emacs 22.1+1-2, the `hack-local-variables' function does not behave correctly when `enable-local-variables' is set to :safe. The documentation of `enable-local-variables' states that the value :safe means to set only safe variables, as determined by `safe-local-variable-p' and `risky-local-variable-p' (and the data driving them), but Emacs ignores this and instead sets all the local variables." When this setting (which is not the default) is in effect, opening a hostile file could lead to the execution of arbitrary commands. | ||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||
gforge: multiple vulnerabilities
| Package(s): | gforge | CVE #(s): | CVE-2007-3921 | ||||
| Created: | November 8, 2007 | Updated: | November 14, 2007 | ||||
| Description: | The GForge collaborative development tool uses temp files in an insecure manner. Local users can use this to truncate files with the privileges of the gforge user, they can also use this to cause a denial of service. | ||||||
| Alerts: |
| ||||||
glib2: multiple vulnerabilities
| Package(s): | glib2 | CVE #(s): | |||||
| Created: | November 8, 2007 | Updated: | November 14, 2007 | ||||
| Description: | The glib2 library has multiple (currently unspecified) vulnerabilities in PCRE. | ||||||
| Alerts: |
| ||||||
horde3: multiple vulnerabilities
| Package(s): | horde3 | CVE #(s): | CVE-2006-3548 CVE-2006-3549 CVE-2006-4256 CVE-2007-1473 CVE-2007-1474 | ||||
| Created: | November 12, 2007 | Updated: | November 14, 2007 | ||||
| Description: | From the Debian advisory: Several remote vulnerabilities have been discovered in the Horde web application framework. The Common Vulnerabilities and Exposures project identifies the following problems: CVE-2006-3548: Moritz Naumann discovered that Horde allows remote attackers to inject arbitrary web script or HTML in the context of a logged in user (cross site scripting). CVE-2006-3549: Moritz Naumann discovered that Horde does not properly restrict its image proxy, allowing remote attackers to use the server as a proxy. CVE-2006-4256: Marc Ruef discovered that Horde allows remote attackers to include web pages from other sites, which could be useful for phishing attacks. CVE-2007-1473: Moritz Naumann discovered that Horde allows remote attackers to inject arbitrary web script or HTML in the context of a logged in user (cross site scripting). CVE-2007-1474: iDefense discovered that the cleanup cron script in Horde allows local users to delete arbitrary files. | ||||||
| Alerts: |
| ||||||
inotify-tools: arbitrary code execution
| Package(s): | inotify-tools | CVE #(s): | CVE-2007-5037 | ||||||||
| Created: | November 12, 2007 | Updated: | December 28, 2007 | ||||||||
| Description: | From the Fedora advisory: A vulnerability has been reported in inotify-tools, which can potentially be exploited by malicious users to compromise an application using the library. Successful exploitation may allow the execution of arbitrary code with privileges of the application using the affected library. NOTE: The programs shipped with inotify-tools are reportedly not affected. The vulnerability is reported in versions prior to 3.11. | ||||||||||
| Alerts: |
| ||||||||||
kernel: remote denial of service
| Package(s): | kernel | CVE #(s): | CVE-2006-6058 CVE-2007-4997 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | November 9, 2007 | Updated: | June 13, 2008 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | The Minix filesystem code in Linux kernel 2.6.x up to 2.6.18, and possibly
other versions, allows local users to cause a denial of service (hang) via
a malformed minix file stream that triggers an infinite loop in the
minix_bmap function. NOTE: this issue might be due to an integer overflow
or signedness error.
Integer underflow in the ieee80211_rx function in net/ieee80211/ieee80211_rx.c in the Linux kernel 2.6.x before 2.6.23 allows remote attackers to cause a denial of service (crash) via a crafted SKB length value in a runt IEEE 802.11 frame when the IEEE80211_STYPE_QOS_DATA flag is set, aka an "off-by-two error." | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
link-grammar: stack-based buffer overflow
| Package(s): | link-grammar | CVE #(s): | CVE-2007-5395 | ||||||||||||||||||||
| Created: | November 13, 2007 | Updated: | December 17, 2007 | ||||||||||||||||||||
| Description: | Stack-based buffer overflow in the separate_word function in tokenize.c in Link Grammar 4.1b and possibly other versions, as used in AbiWord Link Grammar 4.2.4, allows remote attackers to execute arbitrary code via a long word, as reachable through the separate_sentence function. | ||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||
madwifi: denial of service
| Package(s): | madwifi | CVE #(s): | CVE-2007-5448 | ||||||||
| Created: | November 8, 2007 | Updated: | January 11, 2008 | ||||||||
| Description: | The MadWifi driver for Atheros Wireless Lan cards does not process beacon frames correctly. This can be used by a remote attacker to cause a denial of service. | ||||||||||
| Alerts: |
| ||||||||||
openldap: denial of service
| Package(s): | openldap | CVE #(s): | CVE-2007-5707 | ||||||||||||||||||||||||||||||||||||||||
| Created: | November 8, 2007 | Updated: | April 9, 2008 | ||||||||||||||||||||||||||||||||||||||||
| Description: | The OpenLDAP Lightweight Directory Access Protocol suite has a problem with handling of malformed objectClasses LDAP attributes by the slapd daemon. Both local and remote attackers can use this to crash slapd, causing a denial of service. | ||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||
php: denial of service
| Package(s): | php | CVE #(s): | CVE-2007-4887 | ||||||||||||
| Created: | November 12, 2007 | Updated: | November 20, 2007 | ||||||||||||
| Description: | From the CVE entry: The dl function in PHP 5.2.4 and earlier allows context-dependent attackers to cause a denial of service (application crash) via a long string in the library parameter. NOTE: there are limited usage scenarios under which this would be a vulnerability. | ||||||||||||||
| Alerts: |
| ||||||||||||||
poppler and xpdf: multiple vulnerabilities
| Package(s): | poppler xpdf | CVE #(s): | CVE-2007-4352 CVE-2007-5392 CVE-2007-5393 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Created: | November 8, 2007 | Updated: | February 26, 2008 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description: | The xpdf and poppler PDF libraries contain several vulnerabilities which can lead to arbitrary command execution via hostile PDF files. Numerous other applications which use these libraries (PDF viewers, CUPS, etc.) will be affected by the vulnerabilities as well. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
tomboy: execution of arbitrary code
| Package(s): | tomboy | CVE #(s): | CVE-2005-4790 | ||||||||||||||||||||||||||||||||||||||||||||
| Created: | November 9, 2007 | Updated: | February 22, 2011 | ||||||||||||||||||||||||||||||||||||||||||||
| Description: | Jan Oravec reported that the "/usr/bin/tomboy" script sets the
"LD_LIBRARY_PATH" environment variable incorrectly, which might result
in the current working directory (.) to be included when searching for
dynamically linked libraries of the Mono Runtime application.
Note that the tomboy vulnerability was added in 2007. | ||||||||||||||||||||||||||||||||||||||||||||||
| Alerts: |
| ||||||||||||||||||||||||||||||||||||||||||||||
zope-cmfplone: arbitrary code execution
| Package(s): | zope-cmfplone | CVE #(s): | CVE-2007-5741 | ||||||||||||
| Created: | November 12, 2007 | Updated: | December 28, 2007 | ||||||||||||
| Description: | From the Debian advisory: It was discovered that Plone, a web content management system, allows remote attackers to execute arbitrary code via specially crafted web browser cookies. | ||||||||||||||
| Alerts: |
| ||||||||||||||
Page editor: Jake Edge
Kernel development
Brief items
Kernel release status
The current 2.6 prepatch remains 2.6.24-rc2. Quite a few patches have found their way into the mainline git repository since -rc2 was released; they are mostly fixes but there's also some ongoing CIFS ACL support work and the removal of a number of obsolete documents. Expect the -rc3 release sometime in the very near future.The current -mm tree is 2.6.24-rc2-mm1 - the first -mm release since 2.6.23-mm1 came out on October 11. Recent changes to -mm include a number of device mapper updates, a big driver tree update (which has broken a number of things), a lot of IDE updates, bidirectional SCSI support, a large set of SLUB fixes and other "mammary manglement" patches, 64-bit capability support, a number of ext4 enhancements, and the PCI hotplug development tree.
The -mm of the minute tree
In the introduction to 2.6.24-rc2-mm1 (the first -mm tree in some time), Andrew Morton noted that some people want something even more bleeding-edge. So he has created the -mm of the minute tree, which is updated a few times every day. "I will attempt to ensure that the patches in there actually apply, but they sure as heck won't all compile and run." The tree is exported as a patch series, so Quilt is needed to turn it into something which can be compiled. Have fun.
Kernel development news
Quotes of the week
LKML has 10-20x the traffic of linux-scsi and a much smaller signal to noise ratio. Having a specialist list where all the experts in the field hang out actually enhances our ability to fix bugs.
Various topics related to kernel quality
Discussions of kernel quality are not a new phenomenon on linux-kernel. It is, indeed, a topic which comes up with a certain regularity, more so than with many other free software projects. The size of the kernel, the rate at which its code changes, and the wide range of environments in which the kernel runs all lead to unique challenges; add in the fact that kernel bugs can lead to catastrophic system failures and you have the material for no end of debate.The latest round began when Natalie Protasevich, a Google developer who spends some time helping Andrew Morton track bugs, posted this list of a few dozen open bugs which seemed worthy of further attention. Andrew responded with his view of what was happening with those bug reports; that view was "no response from developers" in most cases:
A number of developers came back saying, in essence, that Andrew was employing an overly heavy hand and that his assertions were not always correct. Regardless of whether his claims are correct, Andrew has clearly touched a nerve.
He defended his posting by raising his often-expressed fear that the quality of the kernel is in decline. This is, he says, something which requires attention now:
But is the kernel deteriorating? That is a very hard question to answer for a number of reasons. There is no objective standard by which the quality of the kernel can be judged. Certain kinds of problems can be found by automated testing, but, in the kernel space, many bugs can only be found by running the kernel with specific workloads on specific combinations of hardware. A rising number of bug reports does not necessarily indicate decreasing quality when both the number of users and the size of the code base are increasing.
Along the same lines, as Ingo Molnar pointed out, a decreasing number of bug reports does not necessarily mean that quality is improving. It could, instead, indicate that testers are simply getting frustrated and dropping out of the development process - a worsening kernel could actually cause the reporting of fewer bugs. So Ingo says we need to treat our testers better, but we also need to work harder at actually measuring the quality of the kernel:
It is generally true that problems which can be measured and quantified tend to be addressed more quickly and effectively. The classic example is PowerTop, which makes power management problems obvious. Once developers could see where the trouble was and, more to the point, could see just how much their fixes improved the situation, vast numbers of problems went away over a short period of time. At the moment, the kernel developers can adopt any of a number of approaches to improving kernel quality, but they [PULL QUOTE: In the absence of objective measurements, developers trying to improve kernel quality are really just groping in the dark. END QUOTE] will not have any way of really knowing if that effort is helping the situation or not. In the absence of objective measurements, developers trying to improve kernel quality are really just groping in the dark.
As an example, consider the discussion of the "git bisect" feature. If one is trying to find a regression which happened between 2.6.23 and 2.6.24-rc1, one must conceivably look at several thousand patches to find the one which caused the problem - a task which most people tend to find just a little intimidating. Bisection helps the tester perform a binary search over a range of patches, eliminating half of them in each compile-and-boot cycle. Using bisect, a regression can be tracked down in a relatively automatic way with "only" a dozen or so kernel builds and reboots. At the end of the process, the guilty patch will have been identified in an unambiguous way.
Bisection works so well that developers will often ask a tester to use it to track down a problem they are reporting. Some people see this practice as a way for lazy kernel developers to dump the work of tracking down their bugs on the users who are bitten by those bugs. Building and testing a dozen kernels is, they say, too much to ask of a tester. Mark Lord, for example, asserts that most bugs are relatively easy to find when a developer actually looks at the code; the whole bisect process is often unnecessary:
On the other hand, some developers see bisection as a powerful tool which has made it easier for testers to actively help the process. David Miller says:
Returning to original bug list: another issue which came up was the use of mailing lists other than linux-kernel. Some of the bugs had not been addressed because they had never been reported to the mailing list dedicated to the affected subsystem. Other bugs, marked by Andrew as having had no response, had, in fact, been discussed (and sometimes fixed) on subsystem-specific lists. In both situations, the problem is a lack of communication between subsystem lists and the larger community.
In response, some developers have, once again, called for a reduction in the use of subsystem-specific lists. We are, they say, all working on a single kernel, and we are all interested in what happens with that kernel. Discussing kernel subsystems in isolation is likely to result in a lower-quality kernel. Ingo Molnar expresses it this way:
Moving discussions back onto linux-kernel seems like a very hard sell, though. Most subsystem-specific lists feature much lower traffic, a friendlier atmosphere, and more focused conversation. Many subscribers of such lists are unlikely to feel that moving back to linux-kernel would improve their lives. So, perhaps, the best that can be hoped for is that more developers would subscribe to both lists and make a point of ensuring that relevant information flows in both directions.
David Miller pointed out another reason why some bug reports don't see a lot of responses: developers have to choose which bugs to try to address. Problems which affect a lot of users, and which can be readily reproduced, have a much higher chance of getting quick developer attention. Bug reports which end up at the bottom of the prioritized list ("chaff"), instead, tend to languish. The system, says David, tends to work reasonably well:
Given that there are unlikely to ever be enough developers to respond to every single kernel bug report, the real problem comes down to prioritization. Andrew Morton has a clear idea of which reports should be handled first: regressions from previous releases.
Attention to regressions has improved significantly over the last couple of years or so. They tend to be much more actively tracked, and the list of known regressions is consulted before kernel releases are made. The real problem, according to Andrew, is that any regressions which are still there after a release tend to fall off the list. Better attention to those problems would help to ensure that the quality of the kernel improved over time.
Better per-CPU variables
One of the great advantages of multiprocessor computers is the fact that main memory is available to all processors on the system. This ability to share data gives programmers a great deal of flexibility. One of the first things those programmers learn (or should learn), however, is that actually sharing data between processors is to be avoided whenever possible. The sharing of data - especially data which changes - causes all kinds of bad cache behavior and greatly reduced performance. The recently-concluded What every programmer should know about memory series covers these problems in great detail.Over the years, kernel developers have made increasing use of per-CPU data in an effort to minimize memory contention and its associated performance penalties. As a simple example, consider the disk operation statistics maintained by the block layer. Incrementing a global counter for every disk operation would cause the associated cache line to bounce continually between processors; disk operations are frequent enough that the performance cost would be measurable. So each CPU maintains its own set of counters locally; it never has to contend with any other CPU to increment one of those counters. When a total count is needed, all of the per-CPU counters are added up. Given that the counters are queried far more rarely than they are modified, storing them in per-CPU form yields a significant performance improvement.
In current kernels, most of these per-CPU variables are managed with an array of pointers. So, for example, the kmem_cache structure (as implemented by the SLUB allocator) contains this field:
struct kmem_cache_cpu *cpu_slab[NR_CPUS];
![[percpu array]](https://static.lwn.net/images/ns/kernel/percpu-array.png) Note that the array is dimensioned to hold one pointer for every possible
CPU in the system. Most deployed computers have fewer than the maximum
number of processors, though, so there is, in general, no point in
allocating NR_CPUS objects for that array. Instead, only the
entries in the array which correspond to existing processors are populated;
for each of those processors, the requisite object is allocated using
kmalloc() and stored into the array. The end result is an array
that looks something like the diagram on the right. In this case, per-CPU
objects have been allocated for four processors, with the remaining entries
in the array being unallocated.
Note that the array is dimensioned to hold one pointer for every possible
CPU in the system. Most deployed computers have fewer than the maximum
number of processors, though, so there is, in general, no point in
allocating NR_CPUS objects for that array. Instead, only the
entries in the array which correspond to existing processors are populated;
for each of those processors, the requisite object is allocated using
kmalloc() and stored into the array. The end result is an array
that looks something like the diagram on the right. In this case, per-CPU
objects have been allocated for four processors, with the remaining entries
in the array being unallocated.
A quick look at the diagram immediately shows one potential problem with this scheme: each of these per-CPU arrays is likely to have some wasted space at the end. NR_CPUS is a configuration-time constant; most general-purpose kernels (e.g. those shipped by distributors) tend to have NR_CPUS set high enough to work on most or all systems which might reasonably be encountered. In short, NR_CPUS is likely to be quite a bit larger than the number of processors actually present, with the result that there will be a significant amount of wasted space at the end of each per-CPU array.
In fact, Christoph Lameter noticed that are more problems than that; in response, he has posted a patch series for a new per-CPU allocator. The deficiencies addressed by Christoph's patch (beyond the wasted space in each per-CPU array) include:
- If one of these per-CPU arrays is embedded within a larger data
structure, it may separate the other variables in that structure,
causing them to occupy more cache lines than they otherwise would.
- Each CPU uses exactly one pointer from that array (most of the time);
that pointer will reside in the processor's data cache while it is
being used. Cache lines hold quite a bit more than one pointer,
though; in this case, the rest of the cache line is almost certain to
hold the pointers for the other CPUs. Thus, scarce cache space is
being wasted on completely useless data.
- Accessing the object requires two pointer lookups - one to get the object pointer from the array, and one to get to the object itself.
Christoph's solution is quite simple in concept: turn all of those little
per-CPU arrays into one big per-CPU array. With this scheme, each
processor is allocated a dedicated range of memory at system initialization
time. These ranges are all contiguous in the kernel's virtual address
![[New percpu structure]](https://static.lwn.net/images/ns/kernel/percpu-noarray.png) space, so, given a pointer to the per-CPU area for CPU 0, the area for
any other processor is just a pointer addition away.
space, so, given a pointer to the per-CPU area for CPU 0, the area for
any other processor is just a pointer addition away.
When a per-CPU object is allocated, each CPU gets a copy obtained from its own per-CPU area. Crucially, the offset into each CPU's area is the same, so the address of any CPU's object is trivially calculated from the address of the first object. So the array of pointers can go away, replaced by a single pointer to the object in the area reserved for CPU 0. The resulting organization looks (with the application of sufficient imagination) something like the diagram to the right. For a given object, there is only a single pointer; all of the other versions of that object are found by applying a constant offset to that pointer.
The interface for the new allocator is relatively straightforward. A new per-CPU variable is created with:
#include <linux/cpu_alloc.h>
void *per_cpu_var = CPU_ALLOC(type, gfp_flags);
This call will allocate a set of per-CPU variables of the given type, using the usual gfp_flags to control how the allocation is performed. A pointer to a specific CPU's version of the variable can be had with:
void *CPU_PTR(per_cpu_var, unsigned int cpu);
void *THIS_CPU(per_cpu_var);
The THIS_CPU() form, as might be expected, returns a pointer to the version of the variable allocated for the current CPU. There is a CPU_FREE() macro for returning a per-CPU object to the system. Christoph's patch converts all users of the existing per-CPU interface and ends by removing that API altogether.
There are a number of advantages to this approach. There's one less pointer operation for each access to a per-CPU variable. The same pointer is used on all processors, resulting in smaller data structures and better cache line utilization. Per-CPU variables for a given processor are grouped together in memory, which, again, should lead to better cache use. All of the memory wasted in the old pointer arrays has been reclaimed. Christoph also claims that this mechanism, by making it easier to keep track of per-CPU memory, makes the support of CPU hotplugging easier.
The amount of discussion inspired by this patch set has been relatively low. There were complaints about the UPPER CASE NAMES used by the macros. The biggest complaint, though, has to do with the way the static per-CPU areas bloat the kernel's data space. On some architectures it makes the kernel too large to boot, and it's a real cost on all architectures. Just how this issue will be resolved is not yet clear. If a solution can be found, the new per-CPU code has a good chance of getting into the mainline when the 2.6.25 merge window opens.
The Ceph filesystem
Ceph is a distributed filesystem that is described as scaling from gigabytes to petabytes of data with excellent performance and reliability. The project is LGPL-licensed, with plans to move from a FUSE-based client into the kernel. This led Sage Weil to post a message to linux-kernel describing the project and looking for filesystem developers who might be willing to help. There are quite a few interesting features in Ceph which might make it a nice addition to Linux.
Weil outlines why he thinks Ceph might be of interest to kernel hackers:
The filesystem is well described in a paper from the 2006 USENIX Operating Systems Design and Implementation conference. The project's homepage has the expected mailing list, wiki, and source code repository along with a detailed overview of the feature set.
Ceph is designed to be extremely scalable, from both the storage and retrieval perspectives. One of its main innovations is splitting up operations on metadata from those on file data. With Ceph, there are two kinds of storage nodes, metadata servers (MDSs) and object storage devices (OSDs), with clients contacting the type appropriate for the kind of operation they are performing. The MDSs cache the metadata for files and directories, journaling any changes, and periodically writing the metadata as a data object to the OSDs.
Data objects are distributed throughout the available OSDs using a hash-like function that allows all entities (clients, MDSs, and OSDs) to independently calculate the locations of an object. Coupled with an infrequently changing OSD cluster map, all the participants can figure out where the data is stored or where to store it.
Both the OSDs and MDSs rebalance themselves to accommodate changing conditions and usage patterns. The MDS cluster distributes the cached metadata throughout, possibly replicating metadata of frequently used subtrees of the filesystem in multiple nodes of the cluster. This is done to keep the workload evenly balanced throughout the MDS cluster. For similar reasons, the OSDs automatically migrate data objects onto storage devices that have been newly added to the OSD cluster; thus distributing the workload by not allowing new devices to sit idle.
Ceph does N-way replication of its data, spread throughout the cluster. When an OSD fails, the data is automatically re-replicated throughout the remaining OSDs. Recovery of the replicas can be parallelized because both the source and destination are spread over multiple disks. Unlike some other cluster filesystems, Ceph starts from the assumption that disk failure will be a regular occurrence. It does not require OSDs to have RAID or other reliable disk systems, which allows the use of commodity hardware for the OSD nodes.
In his linux-kernel posting, Weil describes the current status of Ceph:
In addition to creating an in-kernel filesystem for the clients (OSDs and MDSs run as userspace processes), there are several other features – notably snapshots and security – listed as needing work.
Originally the topic of Weil's PhD. thesis, Ceph is also something that he hopes to eventually use at a web hosting company he helped start before graduate school:
Unlike other projects, especially those springing from academic backgrounds, Ceph has some financial backing that could help it get to a polished state more quickly. Weil is looking to hire kernel and filesystem hackers to get Ceph to a point where it can be used reliably in production systems. Currently, he is sponsoring the work through his web hosting company, though an independent foundation or other organization to foster Ceph is a possibility down the road.
Other filesystems with similar feature sets are available for Linux, but Ceph takes a fundamentally different approach to most of them. For those interested in filesystem hacking or just looking for a reliable solution scalable to multiple petabytes, Ceph is worth a look.
Patches and updates
Kernel trees
Architecture-specific
Build system
Development tools
Device drivers
Documentation
Filesystems and block I/O
Memory management
Networking
Security-related
Virtualization and containers
Miscellaneous
Page editor: Jonathan Corbet
Distributions
News and Editorials
Development Gentoo for developers
The Grumpy Editor didn't have enough experience with Gentoo Linux to cover it in his review of development distributions, so the time is nigh. A few commenters on the review also said they'd hoped it was about the best distributions to develop with, so I'll show you here what makes developing with Gentoo Linux a pleasure.
Many of you know Gentoo is a moving target. You may not know, however, that despite that, it's divided into two main chunks: stable and testing. All packages go through a phase in testing (a.k.a. ~arch, with the tilde designating testing status) before they go stable. Stable resembles the testing level of Debian, and Gentoo's ~arch resembles Debian Sid. Developers often want to use the latest and greatest development tools and libraries to develop against, and running Gentoo ~arch (like any good development distribution) allows you to keep all these tools and libraries under package management. First, we'll cover the same points as our Grumpy Editor's review, then we'll move into using Gentoo for development.
Stability
Although complaints about Gentoo's stability and breakages are fairly common, many of those complaints involve compile-time rather than run-time failures. Perhaps the largest complaint about run-time issues with Gentoo involves shared-library version bumps. Since you, rather than an upstream provider, are doing all the building, you need to run a program called revdep-rebuild to track down and rebuild packages that broke from a shared-library version change. While you're waiting for the rebuilds, packages using the bumped library may or may not break, depending on its maintainer's choice. Fortunately this will change in Portage 2.2, planned for release by the end of the year, with the addition of a global setting to always save the old libraries.
Tracking ~arch is possible with the --changelog and --pretend options to emerge. The --changelog option, when used in combination with a --pretend merge (which simply shows which packages would be installed or updated), displays the ChangeLog entries made since adding the new package . Other than that, the new Gentoo packages site has an Atom feed with all version bumps. There is no mailing list, however, dedicated to ~arch users. Instead, one would hope people encountering bugs would report them, and others could search Gentoo's Bugzilla for bugs filed in the past few days. Advance warnings are fairly scarce, but that may change as Portage 2.2 releases late this year with support for distributing news announcements. Last-minute warnings now show up as messages printed just before or after installing the update (and saved for later reading), but sometimes this is too late. Here's a look at --changelog output:
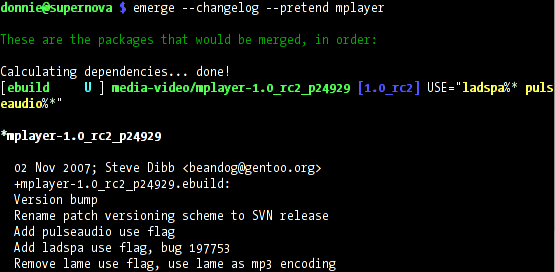
Package management and updates
LWN covered in July the basics of Gentoo's package management. The basic thrust is that Gentoo has three competing low-level package managers: portage (the official one), paludis and pkgcore. Since much of package management in Gentoo is done on the command line, the CLIs are very colorful and featureful: emerge --help --verbose produces 334 lines of options and descriptions. Here's an example of colorful, verbose emerge output:
Development of GUI package-management tools has increased lately, with portato and himerge giving strong showings as fairly full-featured GUIs. Other GUIs exist for more specific purposes, for example configuration-file updating and USE flag (compilation feature) editing. One of the biggest problems with Gentoo is choosing which of the many tools you like best. For example, there are at least 5 different packages that allow you to do a package search.
Configuration-file updating is superb in Gentoo compared to many other distributions. This may be in part because Gentoo assumes some level of familiarity with the command line and with config-file editing. Again, there are a few tools: etc-update and dispatch-conf on the CLI side and etcproposals on the GUI side, among others. After each installation, Gentoo tells you how many configuration files you have to update, and the various tools help you merge the old and new configurations. Some of them even have true version control.
Package selection
Gentoo has 12,037 packages in its main repository as of this writing, which puts it among the largest package collections. A quick check of my Fedora CVS checkout revealed roughly 5,200 packages, to put this in perspective. Since the state of ~arch has no relationship to Gentoo's releases, there are no freezes and packages are never artificially forced to become out of date. There are also many more packages available via overlays, additional package repositories that are easy to find using layman, which provides a centralized list of pointers to repositories and manages them for you, and easy to search (even without downloading them) with eix, which can download a pregenerated cache of information from all repositories. Here's an example of the additional repositories on my system:
Since Gentoo is a pragmatic distribution, it doesn't force any particular ideology upon users so it's easy to use patent-encumbered formats. Whether this is a good or bad thing philosophically remains open to question, but Gentoo is a tool; it tries to get out of your way to let you do what you want. For those more interested in freedom, Portage 2.2 will add license restrictions—you can refuse to install any packages with nonfree licenses. Other Gentoo package managers already allow this.
Why develop with Gentoo?
Gentoo provides a powerful set of tools for a development machine. Since it's a source-based distribution, it comes by default with the full toolchain and related tools (autotools, flex, bison, etc). Furthermore, the packages are not split up, so if you have a package installed, you have all of that package: no searching around for -devel, -headers, -debuginfo, or whatever else.
Two extremely powerful tools to speed up development are ccache and distcc, both of which Gentoo has quite well-integrated and documented. CCache is the compiler cache, which can significantly speed up compile times by caching the object files. DistCC is the distributed C/C++ compiler, which distributes parallel compilations among multiple hosts and is really handy for anything that can build in parallel and takes a while, such as a kernel.
To set up a decent development system, you often want to install debugging versions of a lot of libraries and maybe even install the source code too. Gentoo provides for that with a couple of FEATURES settings: splitdebug and installsources. The splitdebug feature installs separate debuginfo files that are automatically found by gdb, and installsources will do what it sounds like. Combined with an addition of -g or similar to to your CFLAGS setting in /etc/make.conf, that will get you off and running.
On a lower level, you might want to make sure your code compiles on a wide variety of compilers before shipping or releasing it. Gentoo's gcc-config lets you dynamically switch between multiple installed compilers, and you can even use non-GCC compilers for Gentoo packages by simply setting CC in /etc/make.conf or the environment. Here's all of the GCCs installed on my system, including cross-compiling toolchains:
Gentoo supports cross-compiling quite nicely with a tool called crossdev that integrates with Portage to make building cross-compiling toolchains completely trivial. All you have to do is pass crossdev the target and it takes care of the rest. You may want to cross-compile with distcc, too, and Gentoo also supports that. There's a draft version of the Gentoo Embedded Handbook that goes into detail on creating and using cross-compilers, but remember that it is just a draft.
Another feature that makes Gentoo excellent for development is its ability to install packages into a chroot with the variable ROOT. This makes it easy to test things independent of your development system without getting into virtualization. It also helps a lot for embedded development (when coupled with crossdev) and netbooting (when exporting the client / over NFS).
The last, most advanced and possibly most useful aspect of Gentoo for development is the ease of packaging your code. Writing ebuilds is just writing bash shell scripts. If you can build it by hand, you can make an ebuild for it. Here's an example of a simple ebuild, to wrap things up:
New Releases
Announcing the release of Fedora 8
The Fedora 8 distribution "Werewolf" has been announced, in a rather poetic manner. "It's close to midnight and something cool is coming through the "tubes" It's looking real tight, a distro for the experts and the n00bs With Live CDs* so you can try it out before installing Or DVDs so you can have the packages you choose No way to lose 'Cause it's Fedora, Fedora 8 We'd love to have you join us and together we'll be great Using Fedora, Fedora 8 Just click the link and rescue your computer's future today".
Fedora 8 Games spin released
Looking for a Monday morning productivity enhancer? The Games spin for Fedora 8 may be exactly what you are looking for. It contains more than a hundred different free software games in an installable Live DVD format. More information and a link to download it are available on the Fedora project wiki.
Distribution News
Fedora
After Fedora 8 comes Fedora 9!
Fedora 9 development is underway and the rawhide branch is filled with package builds that target Fedora 9. "This will be a bumpy ride at first as we start to see where all these builds gets us. In the next couple of weeks we the project will work on setting a schedule for Fedora 9, start reviewing proposed Features, and come up with an overall idea of what we'd like to accomplish this time around."
ATrpms for Fedora 8; EOL for Fedora Core 6
ATrpms has officially launched Fedora 8 support for i386, x86_64 and PPC. Support for Fedora Core 6 will be dropped on December 7, 2007.rpm.livna.org repositories for Fedora 8 (Werewolf) now available
The Livna repository has Fedora 8 packages available for i386, x86_64 and PPC architectures. "Using the Livna repository gives your Werewolf the ability to play all kinds of audio such as MP3 files and plays DVDs. Additionally Livna offers the ATI and Nvidia closed-source drivers in a Fedora-compatible rpm package for the Fedora users whose videocards are not yet fully supported with the stock open source drivers."
Fedora Unity releases Fedora 8 CD Sets
The Fedora Unity Project has CD ISOs based on the Fedora 8 DVD ISOs. The ISO images are available for i386 and x86_64 architectures via jigdo.Unofficial Fedora FAQ Updated for Fedora 8!
The Unofficial Fedora FAQ has been updated for Fedora 8. "Keep checking in for the next few days, too--new FAQs may be added, current FAQs may be changed! The FAQ always says in the top right corner when it was last updated, and there's a little "updated" notice next to questions (with a date that shows when I change them) whenever I update them."
EOL for FedoraNEWS.ORG
The FedoraNEWS.ORG domain has retired. "As of this morning, index page has been redirected to Fedora Project Wiki. Old contents are still available but no new content will be posted."
SUSE Linux and openSUSE
The first openSUSE board
Novell has created the openSUSE board to provide overall leadership for the project. Initial members are Pascal Bleser, Francis Giannaros, Andreas Jaeger, Stephan Kulow, and Federico Mena-Quintero. "The initial board has been appointed by Novell -- in the future, the board members will be elected by the community and the chair person appointed by Novell."
openSUSE Guiding Principles take effect
The openSUSE project now has Guiding Principles. "The Guiding Principles are a framework for the project and give everyone a clear view of who we are, what we stand for, what the project wants and how it works. The Guiding Principles document was created by the openSUSE community and is embraced by Novell - the founder and largest sponsor of the openSUSE project."
New Distributions
paldo
paldo stands for "pure adaptable linux distribution". It is a Upkg driven GNU/Linux distribution and it's a mix of a source and a binary distribution. Even though it builds packages like a source distribution it provides binary packages. The current version of paldo is 1.12, released November 5, 2007. Linux Titans has an interview with Jürg Billeter, creator of paldo.
Distribution Newsletters
Fedora Weekly News Issue 109
The Fedora Weekly News for the week of November 5, 2007 is out. "In Announcements, we have 'Announcing the release of Fedora 8 (Werewolf)', 'Fedora Unity releases Fedora 8 CD Sets', 'rpm.livna.org repositories for Fedora 8 (Werewolf) now available', 'ATrpms for Fedora 8; EOL for Fedora Core 6' and 'Unofficial Fedora FAQ Updated for Fedora 8!' In Planet Fedora, we have 'Lesser-Known Fedora Contributors', 'Part 1-6, Report: LTSP Hackfest 2007', 'motd-File for your machine', 'Fedora Electronic Lab 8 - Stable release', 'Fedora Unity Spin Report', 'Fedora 8 Games Spin - Feedback Requested', 'Fedora Media Labels Howto', and 'I am a Broken Record'"
Ubuntu Weekly News: Issue #65
The Ubuntu Weekly Newsletter for November 10, 2007 covers the UbuntuWire Community Network, a Christmas marketing campaign, the Michigan Packaging Jam, and much more.DistroWatch Weekly, Issue 228
The DistroWatch Weekly for November 12, 2007 is out. "The Fedora project has once again risen the bar of desktop usability, especially in the area of hardware support, but what do the users think? Find out in our exclusive review of Fedora 8 by Simon Hildenbrand. In the news section, openSUSE announces the creation of openSUSE Board, Mandriva continues to fight the Nigerian Classmate PC deal, Fedora unveils the feature list for version 9, and LinuxTitans.com interviews creator of paldo GNU/Linux Jürg Billeter. Also in this issue, two sets of statistical analyses in the never-ending quest to find out which is the most popular distribution."
Distribution meetings
Worldwide 2008 Mandriva Linux Installfest
Mandriva is organizing a worldwide Installfest on November 17, 2007. "Installations of Mandriva Linux One will take place all around the world, thanks to the Linux community. Major participating locations will include the Ecuador, China, Poland, Russia and France. Last year, Mandriva install fests gathered more than 2000 participants in more than 80 cities in 20 countries. This major event was covered on TV, radio and in the press."
Newsletters and articles of interest
Distribution reviews
gOS: The Little Desktop Linux that Came Out of the Blue (DesktopLinux)
DesktopLinux takes a look at gOS. "The operating system is based, like so many desktop Linuxes such as Mint, on Ubuntu. In gOS' case, it's built on top of the newly released Ubuntu 7.10 Linux. It includes the usual array of open-source software that users have learned to expect from a Linux desktop such as popular applications from Firefox, Skype and OpenOffice.org. The one difference that Linux users will notice immediately about it is that it uses the Enlightenment E17 desktop interface with a Google-centric theme instead of the far more common KDE or GNOME desktops."
Red Hat's Fedora 8 hope: An all-purpose Linux foundation (c|net)
c|net reviews the recently released Fedora 8. "Over the years, Red Hat's Fedora has made a name for itself as a version of Linux for enthusiasts, developers, and those who want to try the latest thing in open-source software. But a curious feature of the new version 8, released Thursday, is the ability to strip out the Fedora identity altogether. The reason: Red Hat wants Fedora to be a foundation for those who want to build their own Linux products on a Fedora foundation. With Fedora 8, that's easier, because all the Fedora-specific elements are wrapped up into one neatly optional package, said project leader Max Spevack."
Page editor: Rebecca Sobol
Development
Download and Watch Videos with Miro 1.0
The Miro project, which was formerly known as Democracy Player, (reviewed on LWN.net in 2006) has just announced the release of Miro version 1.0. Unlike simple video player applications, the focus of Miro is on downloading and managing video collections. Miro is classified as an Internet TV viewer. Miro is the main product from the non-profit Worcester, MA Participatory Culture Foundation:
![[Miro]](https://static.lwn.net/images/ns/Mirologo.png)
Miro's feature list includes the following capabilities:
- Miro is cross-platform, open-source software.
- The software has been translated to over 40 languages.
- Miro has the normal video motion controls.
- There are keyboard shortcuts for easy playback control.
- Miro supports fullscreen viewing of HD video.
- The MPEG, Quicktime, AVI, H.264, Divx, Windows Media and Flash Video formats are supported.
- It is possible to play sequential videos via playlists.
- Video downloading capabilities are built-in.
- RSS-based video channels are supported.
- It is possible to auto-download videos.
- Miro can download via BitTorrent feeds.
- Downloaded video expires after a number of days in order to free up disk space.
- The Miro Guide provides an online catalog of RSS video feeds.
- There are various search options for locating particular videos.
- There are many library features for organizing video collections.
- Miro supports the movement of library data across media.
- Miro has built-in disk space management.
- Pushbuttons are provided for sharing channels and videos with others.
Installation of Miro on a recently installed Ubuntu 7.10 "Gutsy Gibbon" machine was trivial. The Miro download site has detailed instructions on adding the appropriate software repository and installing the various required packages. As a test, your author ran Miro on a .mov file that was created on a Nikon S10 digital camera. The video played, but had a tendency to pause briefly every few seconds. On the same machine, the video played without pauses when viewed with the simpler MPlayer application. Perhaps the relatively old Athlon 1700 system with a non-accelerated video card is not quite up to the task.
The real power of Miro can be seen by downloading videos from the net. A few example videos were downloaded and played via the Miro Guide, fortunately there was no evidence of the jerky playback here. It is possible to select a number of videos, then download them in parallel for later playback. Downloads can be paused and aborted if necessary. Miro marks the downloaded videos as UNWATCHED so that the user knows what has not yet been viewed. Once playback is started, the videos are shown in the sequence that they were downloaded. This makes viewing much more a TV-like experience when compared to watching videos from a web browser.
Creating a playlist is trivial, one simply clicks on the video in the New window and drags it to the desired playlist label. Playback is started by clicking the play button on the first video, videos are played sequentially until they are all finished.
Miro greatly improves the experience of downloading and viewing online videos. The designers should be congratulated for making this big step forward. Give Miro a spin, you won't be disappointed.
System Applications
Backup Software
GPB Backup Solution: first release (SourceForge)
The initial release of Geek Power Backup has been announced. "GPB (Geek Power Backup) is a powerful backup solution that uses Bash Shell Scripting, rsync and SSH to create incremental backups of your data. GPB is intended for system administrators that need a powerful, open source, reliable backup solution."
Database Software
Postgres Weekly News
The November 11, 2007 edition of the Postgres Weekly News is online with the latest PostgreSQL DBMS articles and resources.
Embedded Systems
BusyBox 1.8.1 released
Version 1.8.1 of BusyBox , a collection of command line tools for embedded systems, is out. "This is a bugfix-only release, with fixes to login (PAM), modprobe, syslogd, telnetd, unzip."
Web Site Development
One month of Django tips
James Bennett has announced a blog series that will involve a daily article on the Django web platform through the month of November, 2007. "Ive been reminded today by Maura that November is National Blog Posting Month, when in theory bloggers the world over try to keep up a pace of one entry every day. I dont know how well this is going to go, but Id like to give it a try. And, inspired by Drew McLellans excellent 24 ways advent calendars of web-design tips, Im going to give it a theme: one Django tip every day during the month of November. Kicking off the series, Id like to focus today on the deceptively-simple task of template loading and rendering."
Desktop Applications
Desktop Environments
GNOME Software Announcements
The following new GNOME software has been announced this week:- Accerciser 1.1.2 (bug fix and translation work)
- cairomm 1.4.6 (bug fixes)
- Dasher 4.7.0 (new development series)
- Deskbar-Applet 2.21.2 (bug fixes and translation work)
- Empathy 0.21.2 (bug fixes and translation work)
- gcalctool 5.21.2 (bug fixes and translation work)
- Gnome Applets 2.21.1 (new features, bug fixes and translation work)
- gnome-control-center 2.21.2 (new features, bug fixes and translation work)
- gnome-games 2.21.2 (new features, bug fixes and translation work)
- GNOME Power Manager 2.20.1 (bug fixes and translation work)
- Gnome-schedule 1.2.0 (new features, bug fixes and translation work)
- Gnumeric 1.7.14 b2 (new features and bug fixes)
- Gossip 0.28 (bug fixes and translation work)
- Gypsy 0.5 (unspecified)
- JSON-GLib 0.4.0 (new features and bug fixes)
- kiwi 1.9.19 (bug fixes)
- metacity 2.21.1 (new features, bug fixes and translation work)
- Orca v2.21.2 (bug fixes and translation work)
- PyPoppler 0.6.0 (first public release)
- Rhythmbox 0.11.3 (new features, bug fixes and documentation work)
- Simplexifier 0.1 (initial release)
- Tinymail pre-release 0.0.4 (new features, bug fixes and documentation work)
- TMut 1.0.0 (initial release)
- Tomboy 0.9.1 (bug fixes)
KDE Commit-Digest (KDE.News)
The November 11, 2007 edition of the KDE Commit-Digest has been announced. The content summary says: "Resurgent development work on KDevelop 4, with work on code parsing, code completion and the user interface. Support for converting the KVTML XML-based format to HTML in KDE-Edu. Support for the much-wanted feature of multiple album root paths in Digikam. Various continued developments in Amarok 2. Multiple additional comic sources for the Plasma Comic applet. Support for Kopete plugins written in Python, Ruby, JavaScript and other supported languages through the Kross scripting framework. A simple command-line application for playing media supported by Phonon..."
KDE Software Announcements
The following new KDE software has been announced this week:- AmaKode 1.3 (new feature)
- amarok Livestream with Icecast2 0.1 (initial release)
- Beesoft Commander 4.0.05.beta (new features)
- digiKam 0.9.3-beta2 (new feature and bug fixes)
- gambas 2 2.0 RC1 (new features and bug fixes)
- GenTube 1.5.3 (new features and translation work)
- indywikia 0.9.1 (unspecified)
- Jukebox3D 0.5.0 (complete rewrite)
- K Menu Gnome 0.6.9 (new features)
- KAlarm 1.4.19 / 1.9.9beta (new feature and bug fixes)
- Katesort plugin 1.0 (unspecified)
- kdesvn 0.14.1 (bug fix and translation work)
- Krsync 0.3-Alpha (new features)
- kuftp 0.9.0 (unspecified)
- Perl Audio Converter 4.0.0 (new features, bug fixes and translation work)
- PokerTH 0.6-beta3 (new feature and bug fixes)
- PokerTH 0.6-beta4 (bug fixes)
- QtiPlot 0.9.1 (new features and bug fixes)
- Qtractor 0.0.8.762 (new features and bug fixes)
- rkward 0.4.8a (new feature and bug fixes)
- WebMonX 0.3.0 (complete rewrite)
Electronics
UsbPicProg v0.2 released (SourceForge)
Version 0.2 of the UsbPicProg hardware project has been announced. "UsbPicProg is a Microchip PIC programmer with simple hardware (one PIC18f2550 and some small components). It works together with Piklab. Usbpicprog consists of 3 components: *Hardware (a pcb design) *Embedded software *A plugin for Piklab / Piklab-prog".
Interoperability
Wine 0.9.49 released
Version 0.9.49 of Wine has been announced. "What's new in this release: Many copy protection fixes. GLSL is now the default for Direct3D. Lots of memory errors fixed thanks to Valgrind. Support for TOPMOST windows. Beginnings of an inetcomm dll implementation. Lots of bug fixes."
Medical Applications
Stratos viewer: first demo version online (SourceForge)
The Stratos viewer project now has an online demo. "Stratos viewer is a web based utility to examine DICOM medical images through a web browser"
Office Applications
Task Coach 0.66.1 available (SourceForge)
Version 0.66.1 of Task Coach is available. "Task Coach is a simple open source todo manager to manage personal tasks and todo lists. Often, tasks and other things todo consist of several activities. Task Coach is designed to deal with composite tasks. This release fixes a number of minor bugs."
Digital Photography
UFRaw 0.13 released
Version 0.13 of UFRaw, a utility that can read and manipulate raw images from digital cameras, has been announced. "UFRaw-0.13 was just released, supporting all the latest and greatest digital cameras (thanks to dcraw). From the long list of changes the one that stands out is the option to save images in PNG format. PNG format supports 8 and 16 bit depth, embedding the original EXIF data and attaching an ICC profile. To top it all it gives an efficient lossless compression."
Science
SAGE 2.8.12 has been released
Version 2.8.12 of SAGE has been released. "Use SAGE for studying a huge range of mathematics, including algebra, calculus, elementary to very advanced number theory, cryptography, numerical computation, commutative algebra, group theory, combinatorics, graph theory, and exact linear algebra." See the release announcement for more information on this version.
Video Applications
Schrodinger 0.9.0 released
Version 0.9.0 of Schrodinger, an implementation of the BBC Dirac codec, has been announced. "After a lot of heavy hacking from David Schleef Schrodinger 0.9.0 is now available for download. The jump in version number is meant to demonstrate that Schrodinger is getting close to its first major release. This release is very close to the current bitstream specification, but since the bitstream specification is not 100% frozen yet files created with this version of Schrodinger are likely not to play in future bitstream compliant decoders including future versions of Schrodinger."
Web Browsers
Mozilla Links Newsletter
The November 1, 2007 edition of the Mozilla Links Newsletter is online, take a look for the latest news about the Mozilla browser and related projects.
Miscellaneous
Hotwire 0.600 is available
Version 0.600 of Hotwire is out with a number of new features and bug fixes. "Hotwire is not a terminal emulator, nor is it something you can set as your Unix "login shell"; instead, Hotwire unifies the concepts of shell and terminal and can natively do about 80-90% of what one would normally do in a terminal+shell; for the rest, Hotwire can embed VTE. Practically speaking, Hotwire provides a modern command interface for developers and system administrators to interact with the computer."
SDict Viewer 0.5.2 released (SourceForge)
Version 0.5.2 of SDict Viewer has been announced. "SDict Viewer is a viewer for dictionaries in open format developed by AXMASoft (free dictionaries are available for download at http://sdict.com). Primary goal of the project is to provide usable dictionary app for Nokia 770 and N800 running Maemo. This is a bug fix release."
Languages and Tools
BASIC
Release announcement for Gambas 2.0 RC1 (GnomeDesktop)
The first release candidate of Gambas 2 has been announced. "We're making this announcement now in hopes of attracting more testers users to the project during the release candidate cycle, to help us find any bugs we might have missed. Gambas is a full-featured object language and development environment based on a BASIC interpreter. It is released under the GNU General Public Licence. Its architecture is very inspired by Java: a Gambas executable is an archive of compiled classes and data files that is executed by a custom interpreter."
C
Sparse 0.4.1 released
Version 0.4.1 of Sparse is out with bug fixes that apply to recent kernels. "Sparse, the semantic parser, provides a compiler frontend capable of parsing most of ANSI C as well as many GCC extensions, and a collection of sample compiler backends, including a static analyzer also called "sparse". Sparse provides a set of annotations designed to convey semantic information about types, such as what address space pointers point to, or what locks a function acquires or releases."
Caml
Caml Weekly News
The November 13, 2007 edition of the Caml Weekly News is out with new articles about the Caml language.
Haskell
Haskell Weekly News
The November 11, 2007 edition of the Haskell Weekly News is online. This week sees the release of GHC 6.8.1, to rave reviews. There have been many reports of large performance improvements for Haskell programs, from small to large production systems. Congratulations to the GHC team for such a great release! (Thanks to Don Stewart).
PHP
PHP 5.2.5 released
Version 5.2.5 of PHP has been announced. "This release focuses on improving the stability of the PHP 5.2.x branch with over 60 bug fixes, several of which are security related. All users of PHP are encouraged to upgrade to this release."
Python
Python-URL! - weekly Python news and links
The November 12, 2007 edition of the Python-URL! is online with a new collection of Python article links.
Tcl/Tk
Tcl-URL! - weekly Tcl news and links
The November 10, 2007 edition of the Tcl-URL! is online with new Tcl/Tk articles and resources.Tcl-URL! - weekly Tcl news and links
The November 14, 2007 edition of the Tcl-URL! is online with new Tcl/Tk articles and resources.
Libraries
libfishsound 0.8.1 released
Version 0.8.1 of libfishsound, an interface for decoding and encoding audio data using the Xiph.Org Vorbis and Speex codecs, is out. "This is a maintenance release, fixing a build error when libfishsound is configured with encoding disabled."
Page editor: Forrest Cook
Linux in the news
Recommended Reading
Open Document Foundation closes up shop (Linux-Watch)
At Linux-Watch, Steven J. Vaughan-Nichols has a wrap-up of the rather bizarre Open Document Foundation tale. The Foundation came about to promote Open Document Format, but gradually became disenchanted with it, eventually switching to a W3C format on its way to shutting down. The article quotes from Andy Updegrove, ODF supporter and standards process watcher: "'What I think that Gary, Sam and Marbux are missing is that standards are, by definition, consensus tools. No one has to adopt them, so they have to work well enough for enough people that enough vendors actually implement them. Gary and company didn't get what they wanted, and decided to back another standard instead. There's nothing inappropriate about that, but there is something very unrealistic, as I doubt anyone sees CDF the way they do. Standards are one string that you can't push, unless you've got monopoly power--and needless to say, that they don't have.'"
Can a small business afford not to run Linux? (iTWire)
Stan Beer of iTWire offers a counterpoint to the plethora of "Why Linux won't make it on the desktop" articles. He looks at small business owner complaints as well as his own experiences trying to get reasonable performance from Windows. "'As a small business owner I can afford the cost of Microsoft, I just can't afford the time anymore. I've had the host running QB go down, get new hardware installed, only to not be able to 'activate' Windows. Can't run a business that way! I don't mind paying for Windows, I just can't have it prevent me from doing my business. I'm switching everything to SuSE Linux. I'm pushing all my clients that way too!'"
Trade Shows and Conferences
Report: KDE at The Italian Linux Day 2007 in Rome (KDE.News)
KDE.News has a report from KDE Italia on the Italian Linux Day. "For the people that have never attended to these kind of events, it is important to remember that the Italian Linux Day is a day dedicated to spreading Free and Open Source Software and specially the GNU/Linux Operating System and its software components such as KDE. The talks for the day were at different levels of difficulty and you could find widely accessible talks or talks for an expert audience with more technical and specific topics."
The SCO Problem
SCO found guilty of lying about Unix code in Linux in Germany (Linux-Watch)
Linux-Watch reports that SCO Group GmbH, SCO's Germany branch has been found guilty of lying about Linux containing stolen Unix code. "In the first case, reported on by Heise Online, the pro-Linux German companies, Tarent GmbH and Univention found that SCO was once more making claims that Linux contained Unix IP (intellectual property). Specifically, SCO GmbH made the familiar claims that "As we have progressed in our discovery related to this action, SCO has found compelling evidence that the Linux operating system contains unauthorized SCO UNIX intellectual property (IP)." This was followed by the usual threat "If a customer refuses to compensate SCO for its UNIX intellectual property found in Linux by purchasing a license, then SCO may consider litigation.""
Companies
Dalvik: how Google routed around Sun's IP-based licensing restrictions on Java ME (Betaversion)
The Betaversion blog has an interesting discussion on Dalvik, the not-a-Java-VM which will run on Google's Android platform. "So, Android uses the syntax of the Java platform (the Java 'language', if you wish, which is enough to make java programmers feel at home and IDEs to support the editing smoothly) and the java SE class library but not the Java bytecode or the Java virtual machine to execute it on the phone (and, note, Android's implementation of the Java SE class library is, indeed, Apache Harmony's!)"
Red Hat and Amazon make RHEL available online (Linux-Watch)
Linux-Watch reports on Red Hat's release of a beta version of Red Hat Enterprise Linux that supports Amazon's Elastic Compute Cloud (EC2). "EC2 is a Web service that provides resizable server capacity in the cloud. This collaboration makes all the capabilities of RHEL 5.1, including the Red Hat Network management service, technical support and over 3,400 certified applications, available to customers on Amazon's network infrastructure and data centers. Together, RHEL and Amazon EC2 enable customers to pay only for the infrastructure software services and capacity that they actually use. RHEL on Amazon EC2 enables customers to increase or decrease capacity within minutes, removing the need to over-buy software and hardware capacity as a set of resources to handle periodic spikes in demand."
Red Hat announces ISV appliance platform (Linux-Watch)
Linux-Watch covers Red Hat's announcement of a new appliance version Red Hat Enterprise Linux 5.1: Red Hat Appliance Operating System. "With RHAOS, and its associated SDK (software developer kit), ISVs will be able to minimize their development and support costs by writing once for RHEL and then being able to run the application on any physical, virtual, appliance or cloud version of RHEL. The company claims that this will allow applications that are certified on RHEL to be deployed as software appliances on the broadest range of servers in the industry. With RHAOS as a virtual machine, these RHEL-certified applications will also be able to run on VMware ESX and Microsoft Windows Viridian platforms."
Fedora 8 sees strong adoption in first week (Ars Technica)
Ars Technica reports that Fedora 8 is off to strong start. "The latest version of Fedora--codenamed Werewolf--was released last week. According to statistics released this morning by Red Hat, Fedora 8 has been already been installed over 54,000 times in only four days."
Linux at Work
Nigeria Favors Mandriva Over Microsoft Once More (PCWorld)
PCWorld reports that Nigeria now plans to keep Mandriva on its Classmate PCs. "Now, however, a government agency funding 11,000 of the PCs has overruled the supplier: Nigeria's Universal Service Provision Fund (USPF) wants to keep Mandriva Linux on the Classmate PCs, said an official who identified himself as the program manager for USPF's Classmate PCs project. "We are sticking with that platform," said the official, who would not give his name."
Interviews
Interview with Linux-VServer Project Leader (MontanaLinux.org)
Scott Dowdle talks with Linux-VServer project leader Herbert Pötzl (Bertl). "ML: How long have you been working on Linux-VServer and how did you get started? Bertl: I started as an simple user back when the project was called 'Linux Security Contexts', maintained by Jacques Gelinas. Everything back then was very rough and edgy, many possible exploits, no resource management, no SMP support. But I liked the idea of the Project and soon I had a bunch of patches sitting on my desk, improving this behavior or adding that feature."
10+1 Questions on Innovation to Bjarne Stroustrup (ODBMS Industry Watch)
Roberto V. Zicari asks Bjarne Stroustrup some questions about innovation. "One of the main driving force which influenced the introduction of new generation database systems, such as ODBMS, was Object Oriented Programming (OOP). C++ is notably one of the most important. I had the pleasure to interview Bjarne Stroustrup who invented C++."
Resources
Introduction to Amazon S3 with Java and REST (O'ReillyNet)
O'Reilly has published an introduction to S3. "S3 is a file storage and serving service offered by Amazon. In this article, Eric Heuveneers demonstrates how to use Amazon S3 via its simple REST API to store and serve your own documents, potentially offloading bandwidth from your own application."
Reviews
Google Calling: Inside Android, the gPhone SDK (O'ReillyNet)
Brian DeLacey has an in-depth look at the newly released Android SDK, over at O'ReillyNet. He looks at the Open Handset Alliance, the SDK itself, application development for the platform, and the $10 million Developer Challenge. "Consistent with the design goal of making the platform as open as possible, all Android code is being released under the Apache license. Anyone who wants to can extend, modify, or enhance the platform. (One adoption-accelerating consequence of using the Apache license is that handset manufacturers can write their own device-level drivers or make other customizations without being forced to release this intellectual property to competitors. In addition, third party developers can extend the object oriented user interface and add in their own suite of applications without running the risk of license infractions.)"
Low-cost board runs Linux, Google Apps (LinuxDevices)
LinuxDevices reviews an inexpensive Linux-compatible motherboard from Everex. "For $60, developers and Linux hackers can now buy the guts of the recently unveiled $200 Everex TC2502 Linux PC. The compact, ultra-efficient, x86-compatible "gOS Dev Board" comes with "gOS," a lightweight Linux-based OS meant for use with Google Apps. The gOS operating system was initially created for use in Everex's TC2502, a $200 Linux-based PC available for $200 at Walmart.com and at select Walmart locations. The gOS Developer Board product lets developers and Linux hackers buy just the TC2502's motherboard, along with a CD of the gOS distribution."
Miscellaneous
Top-10 gift ideas for the Linux Gadget Geek (LinuxDevices)
There are rumors of a gift-giving holiday in the not-too-distant future, so LinuxDevices has a list of Linux gadgets that might fit someone on your list. "Got a Linux Gadget Geek on your shopping list? You can't fail with a gift from this guide to the ten hottest Linux-powered devices gleaned from LinuxDevices.com's news throughout 2007. There's something for everyone, at prices from $150 to $1,000, organized from least to most expensive."
CCHIT begins next phase of EHR testing: LAIKA (LinuxMedNews)
LinuxMedNews reports on the CCHIT testing of LAIKA. "The Certification Commission for Healthcare Information Technology has entered into the next phase of building software capable of testing the Interoperability capabilities of electronic health record systems, officials reported today. CCHIT is collaborating with the MITRE Corp. on an open source, software-testing framework called, LAIKA, which will make it possible for vendors to test and verify whether their products meet CCHIT certification."
Page editor: Forrest Cook
Announcements
Non-Commercial announcements
Certified Open: Welcome to life after ICT lock-in
The Free Software Foundation Europe has announced an open trial period for Certified Open. "Today sees the launch of the trial period for Certified Open, a programme to evaluate the technical and commercial lock-in of ICT solutions. Certified Open promotes fair and effective competition in the delivery of software, hardware and services. Certified Open is a joint venture between OpenForum Europe (OFE) and Free Software Foundation Europe (FSFE). The programme originated in UK local government and European Commission eTen projects and was further developed with industry, community and user engagement."
Nominations for X.Org Foundation Board of Directors are OPEN
The X.Org Foundation has announced that nominations for its board of directors are open. "All X.Org Foundation members are eligible for election to the board. Nominations for the 2007 election are now open and will remain open until 23.59 GMT on Saturday 1 December 2007. The Board consists of Directors elected from the membership. Each Director is elected to serve a two-year term. Each year, an election is held to bring the total number of Directors to eight."
Commercial announcements
3DLABS introduces Linux 2.6.21 developer kit for DMS-02 applications processor
3DLABS Semiconductor has announced a Linux 2.6.21 Software Development Kit for its DMS-02 applications processor. "The kit brings the latest open source innovations to developers and device makers using 3DLABS' DMS-02 processor to deliver unrivalled application and media processing performance within low power environments. The SDK provides a suite of development tools and production ready applications, CODECs and libraries that take full advantage of the underlying features and performance of the DMS processor".
ACCESS Brings Thousands of Garnet OS Applications to Nokia Internet Tablets
ACCESS CO., LTD. has announced that it will make available a beta version of a Garnet(TM) VM software for Nokia N770, N800 and N810 Internet Tablets. Garnet VM is expected to be available by the end of the year free of charge as a download from the ACCESS website.BitNami announces Trac and Redmine software stacks
BitNami has announced packaged versions of its Trac and Redmine software stacks. "The BitNami Stacks combine each application with all of the other software it requires in fast, easy to use installer. In less than 5 minutes, you can have Trac or Redmine installed and configured with Subversion, Apache, and all other required software. The Trac and Redmine Stacks are currently available for Linux, with Windows, Mac OS X and Solaris coming soon."
The 2007 JCP Executive Committees election results
The Java Community Process Program has announced the final results of the 2007 JCP Executive Committees elections. "After two ballot rounds -- for ratified and elected seats -- the winners are: Apache Software Foundation, Eclipse Foundation, Inc., Google Inc., Nortel and Red Hat Middleware LLC for the Java SE/EE EC and Intel Corporation, Orange France SA, Research In Motion, LTD (RIM), Samsung Electronics Corporation and Time Warner Cable Inc. for the Java ME EC. For an overview of the JCP EC elections process including detailed descriptions of the ratified seats and elected seats selection processes you can visit http://jcp.org/en/whatsnew/elections."
Microsoft and Novell Celebrate Year of Interoperability, Expand Collaboration Agreement
Microsoft Corp. has announced the first year of collaboration with Novell. "One year after signing a landmark agreement to build a bridge between open source and proprietary software, Novell Inc. and Microsoft Corp. today unveiled continued strong momentum behind the agreement. Having exceeded their original business targets, the companies continue to see strong demand for interoperability and intellectual property (IP) peace of mind. In addition, Novell and Microsoft announced an expansion of their technical collaboration to create a cross-platform accessibility model that links together the existing Windows and Linux frameworks used to build assistive technology products that enable people with disabilities to interact with computers."
Oracle: "Unbreakable Linux" going great
Oracle has sent out a press release saying that its "Unbreakable Linux" offering has been selling better than expected with over 1500 paying customers. "The Oracle Unbreakable Linux support program has also helped Oracle drive growth and advancements in Linux as bug fixes are provided back to the Linux community, in addition to the company's on-going new features and functionality contributions."
Skype 2.0 Beta for Linux, the Great Revolution
Skype has announced a beta release of the Skype 2.0 teleconferencing application for Linux.Y-Film Delivers Tools for Professional VFX Production Shops
Terra Soft has announced the debut of the Y-Film VFX management and productivity tools at the Supercomputing 07 conference. "Y-Film leverages two decades experience in the Hollywood VFX industry through the integration of a robust Asset Manager, a Workflow Pipeline, an Artist Productivity Tool suite, and an end-to-end Color Management System."
YDL v6.0 for IBM QS21 Cell Blade
Terra Soft Solutions has announced the availability of Yellow Dog Linux v6.0 for the IBM BladeCenter QS21. "This evolutionary addition to the growing family of Terra Soft's operating system for the Power architecture offers QS21 end-users an advanced, robust, fully tested RPM-based Linux OS. Coupled with professional support from Terra Soft, YDL v6.0 with integrated IBM SDK v3.0 enables end-users to rapidly install, deploy, and immediately use QS21 compute nodes."
New Books
Absolute FreeBSD, 2nd Edition--New from No Starch Press
No Starch Press has published the book Absolute FreeBSD, 2nd Edition by Michael W. Lucas.
Contests and Awards
KDE 4.0 Release Event Contest winners announced (KDE.News)
KDE.News has announced the winners of the KDE 4.0 Release Event contest. "On October 4, 2007 we announced a contest regarding the KDE 4.0 Release Event at Mountain View, California on January 17-19, 2008. Participants were asked to answer the question: "Why should you be at the KDE 4.0 Release Event?" with the winner being flown out to the Release Event itself. We received many great submissions from community members with very different backgrounds from around the globe. Everyone captured the spirit of the contest with enthusiastic responses; some humorous and some serious, some brief and some reaching the submission limit on length. In the end, with generous approval from KDE e.V. Vice President and Treasurer Cornelius Schumacher, we have decided to fly out two contestants".
Patrick Michaud awarded Perl 6 Development Grant (use Perl)
use Perl reports that Patrick Michaud has been awarded a Perl 6 Development Grant. "It is with great pleasure that The Perl Foundation and Mozilla Foundation announce a major new Perl 6 Development Grant. The recipient of the grant is Patrick Michaud, the Perl 6 compiler pumpking and lead programmer of a Perl 6 implementation based on Parrot and on his own work on the Perl 6 compiler and grammar. The grant will provide Patrick with four months of support for this work beginning November 1, 2007. Patrick will receive US$15,000 over this time, with $10,000 of the funding coming from Mozilla Foundation and $5,000 from The Perl Foundation."
Education and Certification
LPI joins with IT Leaders to form Industry Council
The Linux Professional Institute has announced the formation of the Information Technology Certification Council (ITCC). "The ITCC is a collaborative effort between such leading IT corporations as HP, IBM, Microsoft, Novell and Sun; test development and delivery vendors Pearson Vue and Prometric; certification organizations the Computing Technology Industry Association (CompTIA) and the Linux Professional Institute (LPI); and education provider Kaplan. "LPI applauds this initiative and recognizes the importance of participating in a constructive effort to continually enhance the value of IT certification."
Calls for Presentations
CanSecWest 2008 CFP
A call for papers has gone out for CanSecWest 2008. The conference takes place on March 26-28, 2008 in Vancouver, Canada. The submission deadline is November 30.The Python Papers Monograph Series: Call for Proposals
A call for proposals has gone out for The Python Papers Monograph Series. "The Python Papers Monograph Series (ISSN under application) is a sub-publication of The Python Papers (ISSN 1834-3147). This monograph series provides a refereed format for publication of monograph-length reports including dissertations, conference proceedings, case studies, advanced-level lectures, and similar material of theoretical or empirical importance."
Upcoming Events
Akademy-es 2007 in Zaragoza, Spain (KDE.News)
KDE.News has an announcement for the Akademy-es conference. "Our conference in Spain, Akademy-es, will be held in Zaragoza this year on the 17th and 18th November. We have a very interesting schedule with talks about CMake, KOffice, KDE programming, KDE 4 among other interesting topics. Of course, entry to the talks is free, only limited by physical space. We are planning to have a dinner on saturday night, if you are interested in attending mail sent us a mail to cena-akademy2007-at-ereslibre.es."
The second Django worldwide sprint
The second Django worldwide sprint has been announced. "We'll hold the sprint Saturday, December 1st here in Lawrence, KS, and virtually around the world. We'll run things much the same as we did last time around. We plan to devote at least 24 hours of focused work to get some of this done in an organized fashion, and also to encourage new people to contribute. If all goes well on Saturday, we'll probably continue to Sunday. Anybody can participate and contribute, and there's no obligation or expectation. If you've never contributed to Django before, this is the perfect chance for you to chip in."
Announcing the sponsors of FOSS.IN/2007
The sponsors of FOSS.IN/2007 have been announced. "We all know that an international event like FOSS.IN simply cannot happen without the generous support from sponsors. And this is even more so this year, where the event is bigger than ever! As always, our sponsors have been extremely supportive, and it gives me great pleasure to introduce them to you..."
Events: November 22, 2007 to January 21, 2008
The following event listing is taken from the LWN.net Calendar.
| Date(s) | Event | Location |
|---|---|---|
| November 20 November 23 |
DeepSec ISDC 2007 | Vienna, Austria |
| November 22 November 23 |
Conferencia Rails Hispana | Madrid, Spain |
| November 24 | LinuxDay in Vorarlberg (Deutschland, Schweiz, Liechtenstein und Österreich) | Dornbirn, Austria |
| November 26 November 29 |
Open Source Developers' Conference | Brisbane, Australia |
| November 28 November 30 |
Mono Summit 2007 | Madrid, Spain |
| November 29 November 30 |
PacSec 2007 | Tokyo, Japan |
| December 1 | Django Worldwide Sprint | Online, World |
| December 1 | London Perl Workshop 2007 | London, UK |
| December 4 December 8 |
FOSS.IN 2007 | Bangalore, India |
| December 7 December 8 |
Free Software Conference Scandinavia | Gotherburg, Sweden |
| December 7 December 8 |
PGCon Brazil | Sao Paulo, Brazil |
| December 10 | Paris on Rails (2nd Edition) | Paris, France |
| December 11 December 12 |
3rd DoD Open Conference: Deployment of Open Technologies and Architectures within Military Systems | Vienna, VA, USA |
| December 15 December 22 |
Unix Meeting 2007 | IRC, Worldwide |
| December 27 December 30 |
24th Chaos Communication Congress | Berlin, Germany |
| December 31 | Israeli Perl Workshop | Ramat Efal, Israel |
| January 11 January 13 |
FUDCon Raleigh 2008 | Raleigh, NC, USA |
| January 16 January 17 |
QualiPSo Conference 2008 | Rome, Italy |
| January 17 January 19 |
KDE 4 release event | Mountain View, CA, USA |
If your event does not appear here, please tell us about it.
Mailing Lists
New GNOME mailing list: academia-list
A new GNOME academia-list mailing list has been announced. "The purpose of this list is to establish a bond between the GNOME community and academia."
Page editor: Forrest Cook