
The user-space RCU API
This section describes the APIs implementing user-level RCU. Although the defaults work very well in most cases, the API allows the considerable control required for unusual situations. The aspects of the API are described in the following sections:
- URCU initialization/cleanup API
- URCU read-side API
- URCU update-side API
-
Thread control for
call_rcu() - But wait, there is more!!!
URCU initialization/cleanup API
The initialization/cleanup API is as follows:
-
void rcu_init(void): This function must be called at initialization time before any of the remaining functions are invoked. Because this function is marked as a constructor, it will be automatically invoked at startup. However, you can manually invoke it as well, for example if some other contructor needs to use RCU. It is legal to invokercu_init()repeatedly, as would naturally happen if userspace RCU was used by multiple libraries linked into a single application. -
void rcu_exit(void): This function should be called upon process exit in order to clean up. Because this function is marked as a destructor, it will be automatically invoked at process exit. However, you can manually invoke it as well, for example if you need to shut down RCU before exit. Again, it is legal to invokercu_exit()multiple times, as long as the application invokedrcu_init()at least that many times. -
void rcu_register_thread(void): For all RCU flavors other than bullet-proof RCU, each thread must invoke this function before its first call torcu_read_lock()orcall_rcu(). If a given thread never invokes any RCU read-side functions, it need not invokercu_register_thread(void). -
void rcu_unregister_thread(void): Every thread that callsrcu_register_thread()must invokercu_unregister_thread()before exiting, whether viapthread_exit()or by returning from its top-level function. -
void call_rcu_before_fork(void)
void call_rcu_after_fork_parent(void)
void call_rcu_after_fork_child(void): these functions are intended to be passed to thepthread_atfork()function, which allows URCU to reinitialize itself to handle the case of afork()that is not immediately followed by anexec(). This approach avoids problems that might otherwise occur if afork()system call was executed while some other thread held one of the URCU library's internal mutexes. Most multithreaded programs do not invokefork()without also immediately invokingexec(), so most programs will not need these three functions. The other reason that URCU does not invokepthread_atfork()itself is that there are sometimes dependencies among different atfork handlers, and resolving these dependencies can require that the developer control the order in which the various atfork handlers, including those of URCU, are invoked.Note that use of
pthread_atfork()itself is STRONGLY DISCOURAGED for any programs invoking the glibc memory allocator (e.g.,malloc()) from withincall_rcu()callbacks unless you like application hangs. Instead, applications that both usecall_rcu()and that invokefork()without an immediateexec()should directly call thevoid call_rcu_before_fork(void),void call_rcu_after_fork_parent(void), andvoid call_rcu_after_fork_child(void)functions before and after thefork(). See theREADMEfile in the source tree for more information on this issue.
URCU read-side API
The read-side API is as follows:-
void rcu_read_lock(void): Begin an RCU read-side critical section. Nesting is permitted. -
void rcu_read_unlock(void): End an RCU read-side critical section. -
T rcu_dereference(T): Load the specified pointer and return its value, but disabling any compiler or CPU code-motion optimizations that might otherwise cause readers to see pre-initialized values in the referenced data element. -
void rcu_quiescent_state(void): Report a quiescent state. Quiescent-state reports are needed only for QSBR, but are no-ops in the other flavors of RCU. -
void rcu_thread_offline(void): Report the beginning of an extended quiescent state, for example, prior to executing a system call that might block indefinitely. This is again only needed for QSBR, but is no-ops for the other flavors of RCU. Note that it is illegal to to invokercu_read_lock()andrcu_read_unlock()from within an extended quiescent state. -
void rcu_thread_online(void): Report the end of an extended quiescent state.
Quick Quiz 1:
Why do we need to use rcu_dereference() instead of just
using a simple assignment statement?
URCU update-side API
The update-side API is as follows:-
void synchronize_rcu(void): Wait for a grace period to elapse, in other words, wait for all pre-existing RCU read-side critical sections to complete. It should be clear that it is illegal to invokesynchronize_rcu()from within an RCU read-side critical section. See below for more information on this restriction. -
void call_rcu(struct rcu_head *head, void (*func)(struct rcu_head *head)): After the end of a subsequent grace period, invokefunc(head). A typical implementation offunc()is as follows:1 void func(struct rcu_head *head) 2 { 3 struct foo *p = caa_container_of(head, struct foo, rcu); 4 5 free(p); 6 }This assumes that
struct foocontains a field of typestruct rcu_headnamedrcu, allowingfunc()to be invoked as follows:call_rcu(&p->rcu, func);Note that
call_rcu()is the only update-side API member that may be invoked from within an RCU read-side critical section. This is becausecall_rcu()is guaranteed never to block waiting for a grace period. In addition,call_rcu()uses RCU read-side critical sections internally. Threads invokingcall_rcu()therefore must be registered readers and furthermore cannot be in an RCU extended quiescent state. -
void defer_rcu(void (*fct)(void *p), void *p): Similar tocall_rcu()in overall effect, but will sometimes block waiting for a grace period, and can also directly invoke the callbacks. This means thatdefer_rcu()cannot be called from an RCU read-side critical section, but also that it cannot be called holding any lock acquired by a callback function. In return,defer_rcu()is the most efficient of the three approaches (synchronize_rcu(),call_rcu(), anddefer_rcu()) from a real-fast viewpoint. -
rcu_assign_pointer(a, b): Similar to the assignment statementa=b, but also disables any compiler or CPU code-motion optimizations that might otherwise cause this assignment to be executed before any preceding statement. This disabling of optimizations is necessary for readers to correctly see newly inserted data. -
rcu_set_pointer(T **a, T *b): Similar torcu_assign_pointer, but implementable as a function, give or take the need for type genericity. This allowsrcu_set_pointer()to be implemented in terms of a dynamically linked function. In contrast,rcu_assign_pointer()is inherently a C-preprocessor macro. -
rcu_xchg_pointer(T **a, T *b): Atomically exchange the new valuebinto the pointer referenced bya, returning the old value referenced bya. This primitive can be used to provide extremely fast lockless updates to RCU-protected data structures. -
T rcu_cmpxchg_pointer(T *p, T old, T new): Atomically compare the data referenced bypwithold, and if they are equal, exchange it withnew. Either way, the old value referenced bypis returned. This primitive can be used to provide fast lockless and lock-free updates to RCU-protected data structures.
Quick Quiz 2: Thercu_xchg_pointer()andrcu_cmpxchg_pointer()functions don't look much different than ordinary garden-variety atomic-exchange and CAS. Why the special RCU variants?
Neither synchronize_rcu() nor defer_rcu()
may be invoked from within an RCU read-side critical section, but
the full constraint is more involved:
No RCU read-side critical section may contain any operation that waits
on the completion of an RCU grace period.
For example, an RCU read-side critical section must not acquire a lock
that is held across a call to either synchronize_rcu()
or defer_rcu().
There are any number of more ornate but broadly similar scenarios.
In the Linux kernel, the RCU callbacks registered by the
call_rcu() function are usually invoked in softirq
context on the same CPU that registered them.
Given that userspace does not have a softirq context, some other
approach is required.
The chosen approach is the use of special callback-invocation
threads that, strangely enough, invoke callbacks.
By default, there will be one such thread for each multithreaded
process, which will likely work quite well in almost all cases.
Thread control for call_rcu()
However, programs that register unusually large numbers of callbacks may need multiple callback-invocation threads. The following APIs allow some degree of control over how many such threads are created and how they are organized. Using these APIs, it is possible to assign a special callback-invocation thread to a specific application thread (or set of specific application threads) or to a specific CPU (or set of specific CPUs). However, if a single callback-invocation thread is sufficient for you, which it most likely will be, then you can skip the remainder of this document.
-
struct call_rcu_data *create_call_rcu_data(unsigned long flags, int cpu_affinity): Returns a handle that can be passed to the other functions in this list. Theflagsargument can be zero, or can beURCU_CALL_RCU_RTif the application threads associated with the new callback-invocation thread are to get real-time response fromcall_rcu()by avoiding the need to call into the kernel to wake up the callback-invocation thread. The argumentcpu_affinityspecifies a cpu on which the callback-invocation thread should be affinitied to. Ifcpu_affinityis negative, the thread is not affinitied to any CPU. -
struct call_rcu_data *get_default_call_rcu_data(void): Returns the handle of the default callback-invocation thread. If none of the functions in this list are invoked, the default callback-invocation thread is created the first time that the process invokescall_rcu(). -
struct call_rcu_data *get_call_rcu_data(void): Returns the handle for the current thread's callback-invocation thread, which is either, in decreasing order of preference: per-thread hard-assigned thread, per-cpu thread, or default thread. Theget_call_rcu_data()function should be called from registered RCU read-side threads. For the QSBR flavor, the caller must not be in an extended quiescent state. -
void call_rcu_data_free(struct call_rcu_data *crdp): Terminates a callback-invocation thread and frees its associated data. The caller must have ensured that this thread is no longer in use, for example, by passingNULLtoset_thread_call_rcu_data()andset_cpu_call_rcu_data()as required. -
struct call_rcu_data *get_cpu_call_rcu_data(int cpu): Returns the handle for the current cpu's callback-invocation thread, orNULLif the current CPU has no such thread currently assigned. The call to this function and use of the returned call_rcu_data must be protected byrcu_read_lock(). -
struct call_rcu_data *get_thread_call_rcu_data(void): Returns the handle for the current thread's hard-assigned callback-invocation thread, orNULLif the current thread is instead using a per-CPU or the default helper thread. -
pthread_t get_call_rcu_thread(struct call_rcu_data *crdp): Returns the callback-invocation thread's pthread identifier given a pointer to that thread'scall_rcu_datastructure. -
void set_thread_call_rcu_data(struct call_rcu_data *crdp): Sets the current thread's hard-assigned callback-invocation thread to the handle specified bycrdp. Note thatcrdpcan beNULLto disassociate this thread from its helper. Once a thread is disassociated from its helper, furthercall_rcu()invocations use the current CPU's callback-invocation thread if there is one and the default callback-invocation thread otherwise. -
int set_cpu_call_rcu_data(int cpu, struct call_rcu_data *crdp): Sets the specified CPU's callback-invocation thread to that corresponding to the handle specified bycrdp. Again,crdpcan beNULLto disassociate this CPU from its helper thread. Once a CPU has been disassociated from its helper, furthercall_rcu()invocations that would otherwise have used this CPU's helper will instead use the default helper. The caller must wait for a grace-period to pass between return fromset_cpu_call_rcu_data()and the call to thecall_rcu_data_free()that frees the returnedcall_rcu_datastructure. Returns nonzero and setserrnotoEINVALif an invalid CPU is specified, toENOMEMon allocation failure, and toEEXISTif the specified CPU already has a callback-invocation thread andcrdpis non-NULL. -
int create_all_cpu_call_rcu_data(unsigned long flags): Creates a separate callback-invocation thread for each CPU, with the value offlagsagain beingURCU_CALL_RCU_RTfor real-timecall_rcu()latencies. After this primitive is invoked, the global default callback-invocation thread will not be called. Theset_thread_call_rcu_data(),set_cpu_call_rcu_data(), andcreate_all_cpu_call_rcu_data()functions may be combined to set up pretty much any desired association between worker and callback-invocation threads. If a given executable callsonly call_rcu(), then that executable will have only the single global default callback-invocation thread. This will suffice in most cases. -
void free_all_cpu_call_rcu_data(void): Clean up all the per-CPU callback-invocation threads, whether created individually or en masse viacreate_all_cpu_call_rcu_data(). Note that this function invokessynchronize_rcu()internally, so the caller should be careful not to hold mutexes (or mutexes within a dependency chain) that are also taken within an RCU read-side critical section, or in a section where QSBR threads are online.
For example, if a multithreaded application with four threads
simply invoked call_rcu() without using any of the
functions on the above list, the result would be as shown below,
namely that all four threads would share the same callback-invocation
thread.
All four threads would enqueue concurrently onto that
callback-invocation thread's queue, which would wait for grace
periods and invoke them.
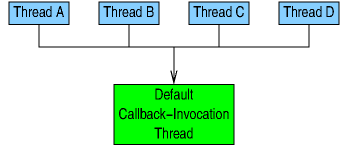
This arrangement works extremely well in the common case with low callback-invocation rates.
If the application were to then invoke
create_all_cpu_call_rcu_data(0),
the result would be as shown below, assuming that Threads A and B
are running on CPU 0 and Threads C and D are running on
CPU 1.
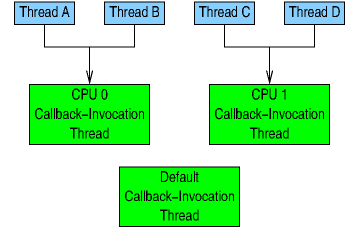
As you can see, none of the threads are using the default callback-invocation thread because the per-CPU callback-invocation threads take precedence.
Quick Quiz 3: But suppose that Thread B is migrated to CPU 1 just as it is registering a callback. Can't that result in failures due to a thread running on CPU 1 accessing CPU 0's data structures?Quick Quiz 4: Suppose that there is a callback-invocation thread for each CPU, and suppose that one of the threads invoking
call_rcu()is affinitied to a particular CPU. Can interactions between that thread and its RCU callbacks be free of synchronization operations, relying instead on the fact that the callbacks will be running on the same CPU as the thread that registered them?
If Thread D were then to execute the following statements:
1 crdp = create_call_rcu_data(URCU_CALL_RCU_RT, -1); 2 set_thread_call_rcu_data(crdp);
Then the result would be as shown on the following diagram.
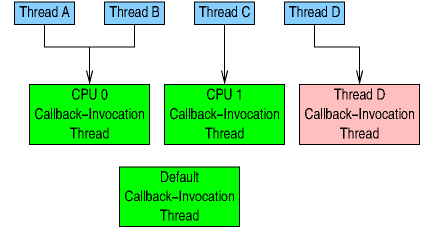
Thread D now has its own callback-invocation thread, which,
thanks to URCU_CALL_RCU_RT, is
set up to provide Thread D real-time response to its invocations
of call_rcu().
This means that Thread D need not wake up its callback-invocation
thread, which must instead periodically poll for callbacks.
This real-time response comes at the expense of energy efficiency,
because Thread D's callback-invocation thread will wake up every
ten milliseconds to check to see if Thread D has registered any
callbacks.
In contrast, the other callback-invocation threads will block indefinitely
on a futex operation if their application threads have no callbacks.
Therefore, Thread D's callback-invocation thread is colored red
and the rest are colored green.
Quick Quiz 5: Now that Thread D has its own callback-invocation thread, can interactions between those two threads be omitted?Quick Quiz 6: Is there any situation where a
URCU_CALL_RCU_RTcallback-invocation thread can be more energy-efficient than a normal callback-invocation thread, where a normal callback-invocation thread is created with0rather thanURCU_CALL_RCU_RT?
The -1 passed as the final parameter to
create_call_rcu_data() specifies that the callback-invocation
thread will not be bound to any particular CPU, but will instead be
free to migrate as the scheduler sees fit.
Suppose that the application now executes the following:
crdp = get_cpu_call_rcu_data(1); set_cpu_call_rcu_data(1, NULL); synchronize_rcu(); call_rcu_data_free(crdp);
This will disassociate CPU 1's callback-invocation thread, wait for any possible uses of it to complete, and then free it, resulting in the situation shown in the following diagram:
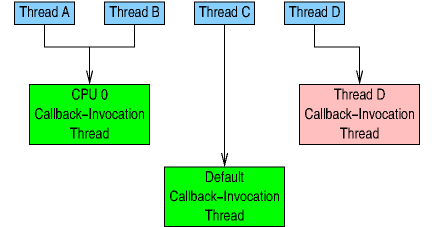
Here, Thread C is once again using the default callback-invocation thread. Note that any callbacks that were still pending on CPU 1's callback-invocation thread are moved to the default callback-invocation thread.
In short, although the APIs controlling the callback-invocation threads should be needed only rarely, they provide a high degree of control over how RCU callbacks are processed.
But wait, there is more!!!
This API overview covered the underlying RCU API, but URCU also includes RCU-protected data structures. These data structures are covered in separate articles on hash tables, queues and stacks, and lists.
Answers to Quick Quizzes
Quick Quiz 1:
Why do we need to use rcu_dereference() instead of just
using a simple assignment statement?
Answer: If we were to use a simple assignment statement, both the compiler and the CPU would be within their rights to:
- Guess the value of the pointer.
- Use this guess to execute the subsequent pointer dereferences.
- Check the guess against the current value of the pointer.
- If the guess was wrong, repeat from the beginning.
This can break RCU if the initial guess was wrong, but if after doing
the dereferences, some other thread changed the pointer so that it now
matched the guess.
This is not a theoretical possibility, given that
there has been work on profile-directed feedback optimizations
that would guess data values (in addition to the traditional use for
guessing branch targets).
In addition,
DEC Alpha
also behaves this way
due to the fact that it does not respect dependency ordering.
Using a simple assignment statement instead of
rcu_dereference() invites additional compiler
misbehavior of the types described
here.
Quick Quiz 2:
The rcu_xchg_pointer() and rcu_cmpxchg_pointer()
functions don't look much different than ordinary garden-variety
atomic-exchange and
CAS.
Why the special RCU variants?
Answer: The RCU variants of these APIs provide type checking, ensuring that the values being exchanged match those referenced by the pointer. In addition, these variants open the door to later validation features similar to the Linux kernel's lockdep-RCU.
Quick Quiz 3: But suppose that Thread B is migrated to CPU 1 just as it is registering a callback. Can't that result in failures due to a thread running on CPU 1 accessing CPU 0's data structures?
Answer: Although it can result in momentary performance loss, it will not result in failure. The callback-invocation threads are set up to handle concurrent registry of callbacks from any and all CPUs. Associating a callback-invocation thread with each CPU is thus merely a performance optimization.
Quick Quiz 4:
Suppose that there is a callback-invocation thread for each CPU,
and suppose that one of the threads invoking call_rcu()
is affinitied to a particular CPU.
Can interactions between that thread and its RCU callbacks be free
of synchronization operations, relying instead on the fact that
the callbacks will be running on the same CPU as the thread that
registered them?
Answer: No, for several reasons:
- Unless the callback-invocation thread is also affinitied to that same CPU, it might well be running on some other CPU.
- In some situations, for example, if the CPU that the threads are affinitied to is taken offline, the scheduler might choose to run the thread somewhere else.
- Even if the thread and its callback-invocation thread really do execute on the same CPU, preemption can cause execution to be interleaved.
In short, any interactions between a given thread and its callback-invocation thread must be properly synchronized.
Quick Quiz 5: Now that Thread D has its own callback-invocation thread, can interactions between those two threads be omitted?
Answer: No, and for the same reasons as noted earlier:
- Unless both threads are affinitied to the same CPU, they might well be running on different CPUs.
- In some situations, for example, if the CPU that the threads are affinitied to is taken offline, the scheduler might choose to run the thread somewhere else.
- Even if the thread and its callback-invocation thread really do execute on the same CPU, preemption can cause execution to be interleaved.
In short, any interactions between a given thread and its callback-invocation thread must be properly synchronized—regardless of how those two threads are related and where they run.
Quick Quiz 6:
Is there any situation where a URCU_CALL_RCU_RT
callback-invocation thread can be more energy-efficient than a
normal callback-invocation thread, where a normal callback-invocation
thread is created with 0 rather than
URCU_CALL_RCU_RT?
Answer:
No, or at least not by much.
Even if a normal callback-invocation thread's application threads collectively
register a callback every (say) millisecond, the fact that the
callback-invocation thread blocks for ten milliseconds after being awakened
means that it will throttle the number of wakeups it receives to roughly
that of a URCU_CALL_RCU_RT callback-invocation thread.
This policy might need modification in the future should applications start exhibiting extremely high callback-registration rates.