
Optimizing Linker Load Times
Everyone wants their computer to start faster. Distribution maintainers are thus always looking for things to decrease boot time and program load time, using mechanisms such as readahead, boot reordering, even parallel init to more efficiently distribute CPU and disk I/O and get the user to the login screen faster.
One such tool used to decrease boot time and program load time is prelink [PDF], developed by Jakub Jelínek at Red Hat and discussed in an earlier LWN article. Prelinking is not the only way to improve start-up times, however; there are also a number of existing and developing optimizations the GNU linker can apply to give substantial gains. Besides existing GNU linker hash table optimizations, Michael Meeks has done substantial works on three separate optimizations in the GNU linker in a quest to make OpenOffice.org load quickly [PDF].
1.0 The -Wl,-O1 Linker Options
In typical operation, symbols are stored in hash tables in ELF binaries; these hash tables are kept small, and symbols that fall into the same bucket—hash to the same value—are compared by a simple string comparison. Unfortunately, symbols in the same bucket with the same prefix will need a long string comparison, which can be slow; if there are lots of symbols in the same bucket, then the dynamic linker has to string compare with each of them until it finds a match (Fig. 1.0-1).
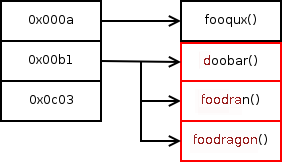
Fig. 1.0-1: A hash table of symbols in a library. The bucket 0x00b1 contains three symbols; the red characters will have to be tested against the symbol name before the symbol 'foodragon' is resolved.
It was recommended in a paper [PDF] by Ulrich Drepper to utilize a GNU linker optimization that focuses more on producing short hash chains than a small hash table size. Although the hash table may grow by a few kilobytes, the shortened length of hash chains means that symbol look-ups do not have to perform as many string comparisons. Further, the chances of symbols sharing long prefixes landing in the same bucket are greatly reduced, making walking the chains faster (Fig. 1.0-2).
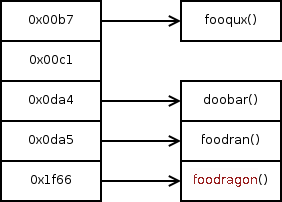
Fig. 1.0-2: A hash table of symbols in a library. This table is optimized, so symbols hash to buckets containing shorter hash chains; this reduces the number of string comparisons done. The table is a bit bigger, though.
This linker optimization can be activated by passing -Wl,-O1 to gcc at link time. This flag can also be passed during any compilation; however, optimizing hash tables can be slow, and there are no benefits to doing this when creating object files that are just going to be linked into a main executable or shared object.
Currently this linker optimization is used by GNOME in its official builds. It has also been discussed on the Gentoo forums; and is used by the Ubuntu distribution, to name a few. An old but good technique.
2.0 -Bdirect Linking
Michael Meeks also proposed an optimization to GNU binutils and glibc which functions similar to direct binding in Solaris. By passing -Bdirect at link time, the build process can cause many symbols to be directly linked, allowing the dynamic linker to severely decrease the search space during lookup.
Libraries have unresolved symbols when they use functions or global variables from other libraries; these symbols are resolved during dynamic linking. The dynamic linker locates every unresolved symbol each library needs by searching the symbol table of each loaded library in order from first loaded to last loaded. This can become quite time consuming, especially in cases such as GNOME or OpenOffice.org where 50-150 libraries are loaded and up to 200,000 symbols must be resolved.
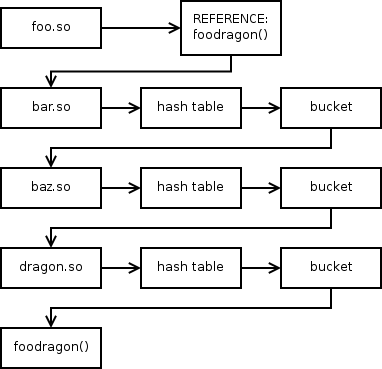
Fig. 2.0-1: Normal binding is done by checking through all libraries until the symbol is found.
Direct binding shortens the path the linker has to take to resolve a symbol by drawing it straight from whatever ELF object needs the symbol to the ELF object containing the symbol. A section is added to the ELF header which associates each symbol with an entry in the DT_NEEDED table—the list of libraries needed by the ELF object. The linker uses this information to go straight to the library containing the symbol and search only there, instead of searching through each library sequentially.
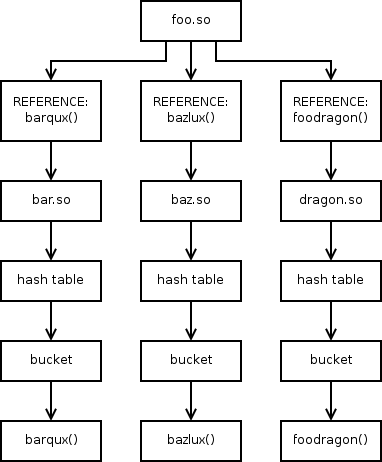
Fig. 2.0-2: Direct binding is done by checking the library that the symbol table says the binding is located in. This gives a much shorter path for any symbol lookup; three are shown above.
Meeks' -Bdirect linking method operates slightly differently from Solaris direct binding. With the Solaris linker, direct binding binds all symbols directly to the relevant libraries. With Michael Meeks' implementation of -Bdirect linking, vague symbols are detected and linked as normal. This is particularly important with C++, as vague C++ symbols are fairly common. It is not possible to guarantee that a vague symbol is linked to a specific library, so direct binding of vague symbols is not technically feasible.
-Bdirect binding can, to a degree, work with shared objects that are loaded with dlopen() rather than run-time linking; this is reported to greatly aid with OpenOffice.org and KDE start-up times. This is interesting because the performance improvements per library are comparable to but not quite as substantial as prelink, which does not affect libraries loaded in this manner.
The current implementation unfortunately has a few rough edges. Some areas could be better optimized; and there is an issue with certain libraries and programs breaking due to direct binding. Sometimes multiple libraries supply the same symbol, and the first loaded is the one used; this is called interposing, and is the reason why Meeks' -Bdirect linking patch does not optimize vague symbols. When direct binding is used, the symbol is chosen by the GNU linker at link time rather than by the dynamic linker at run time. This can be both a good and a bad thing, depending on the situation.
In most cases direct binding is a good thing, as it guarantees that libraries dependent on other libraries will always find the proper symbols, even if multiple libraries are loaded with the same symbols. Unfortunately, sometimes this very functionality also changes the way existing programs link, which just happen to work fine based on using the symbol from the first library supplying it. This is usually disastrous, as the symbol now used is typically a variable or function meant for a different purpose; the program no longer does what the programmer intended, and likely ends up simply crashing.
Not everybody believes that the use of interposing is the right thing to do. Still, getting things like this working would really require finding a work-around that does not break compatibility with existing code. Michael Meeks suggested during e-mail discussion a link-map extension to handle direct binding per symbol:
I would instead say: writing code that explicitely relies on interposing is not sensible. However - to make this work all that is needed is to implement an extension to link-maps (as done in the Solaris linker) to allow certain symbols to be marked as interposers (and hence not direct linked). That's most useful for (eg.) in glibc's use of pthreads - done by interposing.
This would allow direct binding to be used with libraries that currently fail with it, by only doing a long symbol search for vague symbols. Further, Meeks' finterpose tool can be used to find interposers between libraries; this not only shows where -Bdirect binding may fail, but also has exposed a few bugs in software such as GTK+ and gstreamer. The unfortunately large number of interposers presents a slight roadblock, but should not stop Meeks' -Bdirect linking from eventually becoming fully functional.
This optimization has an uncertain future, however. Relevant glibc code has so far been rejected by Ulrich Drepper. Despite this, -Bdirect linking has already found uses in Gentoo (with a portage overlay), Pardus Linux, and Solaris/OpenSolaris. The patch has also been committed to OpenSUSE, although it is uncertain if it will be used to build upcoming OpenSUSE releases.
3.0 dynsort
Another optimization posted by Michael Meeks adds the dynsort keyword to the GNU linker. By passing -zdynsort at link time, the .dynsym and .dynstr sections as well as relocations are all sorted by ELF hash and by the position where they land in the hash bucket.
When symbols are looked up in an ELF object, a hash table has to be searched. Hash collisions are effectively stored as a linked list, which then has to be walked to find the appropriate entry. With dynsort, the symbols that have to be examined while walking a bucket are all adjacent to each other. This reduces the number of L1 and L2 cache misses, allowing the CPU to utilize its facilities much more efficiently during dynamic linking.
The dynsort optimization has gotten a good bit of attention since it was unveiled. Meeks is working on improving it in various ways, such as moving data for undefined symbols away from the rest of the data. It was this patch that got Meeks offered a branch in binutils cvs, although as of this writing one hasn't been set up. It can be used in Gentoo with an overlay, but may soon be available everywhere via the --hash-style option.
4.0 Precomputed Hash Values
A few weeks after the dynsort patch, Meeks posted another optimization the binutils mailing list. This one adds pre-computed ELF hash values to the elf header when the -hashvals switch is given. Normally the dynamic linker has to compute a hash value of a symbol and then use that to find the index in the symbol tables of the other libraries. The -hashvals optimization pre-computes these, removing a series of cache misses and mathematical computations from the process.
The visible effect of the -hashvals switch is a large speedup in symbol look-up; Meeks measured dlopen() on libsvx as requiring 40% less time, and in some places a 51% reduction was realized. This is due not only to avoiding the calculation of symbol hash values; but also to much more efficient L2 cache utilization. Only a single 32-bit value is accessed for each symbol, rather than a long string; and locality is increased, since only the .hashvals section is accessed instead of both .dynsym and .dynstr, which reduces L2 cache misses.
This patch has a very favorable future; it almost immediately gained support for inclusion in upstream binutils. Several months later, a rewrite done by Ulrich Drepper and Jakub Jelínek was posted, implementing sorting and precomputed hashvals via --hash-style. And of course, Gentoo users have had access to it for a while with various portage overlays.
Conclusion
There are a lot of optimizations possible to reduce dynamic linking time, creating substantial gains in application load time. Future versions of the GNU linker and glibc may allow distributions to boot and load programs much faster, getting users to the desktop and on their applications in substantially less time.
| Index entries for this article | |
|---|---|
| GuestArticles | Moser, John Richard |
Posted Jul 27, 2006 2:05 UTC (Thu)
by martinfick (subscriber, #4455)
[Link] (3 responses)
Posted Jul 27, 2006 3:14 UTC (Thu)
by jreiser (subscriber, #11027)
[Link]
Posted Jul 27, 2006 3:49 UTC (Thu)
by bluefoxicy (guest, #25366)
[Link]
I actually proposed filling hash buckets with Patricia Tries, but never wrote and tested it. I like to put my ideas out there but keep in mind I'm not an expert on this stuff by far ;) (guys feel free to point out reasons this won't work)
A Patricia trie would basically let you find a bucket; locate the first character of the symbol; and then from there the string only goes as far as ALL symbols in that bucket go with a common prefix. Then it would fork towards each different symbol.
In other words you'd have this:
The first is a list, the second is a Patricia Trie. The difference is that to find 'appliance' you have to compare 'apple', 'apple', 'appliance\0' with a list (if it's in that exact order); whereas with the Patricia Trie you would compare 'appl\0', 'e', 'iance\0'. 'brick' would be 'a' 'a' 'a' 'brick\0' vs 'a' 'brick\0'.
The size of the storage would be smaller and the data locality would thus be tighter. You would avoid problems with similar prefixes (hello C++ crap) and the trie could be implemented to give these guarantees fairly easily as long as they were kept small (i.e. big tries might have a pointer forward to the next segment a few pages ahead; so I said to stick them in hash buckets to keep them small and reduce the number of forks).
The data would be stored at each branch of the trie. So 'appl' would resolve, it would just resolve to "there is no value here"; and 'e' would store the dynsym entry for 'apple'; etc.
This could be done without breaking the ELF standard by using a different section and letting the dynamic linker use it instead of the typical sections.
The problem isn't so simple though. This would help with the case of "there's 3 symbols in every bucket that start with some 400 character string and we're wasting tons of cycles doing millions of character comparisons on load;" but overall it's not going to become instant look-up. You still have to walk through all loaded libraries; this is what -Bdirect linking takes care of for you.
In short, the reasons we haven't used binary tries are:
Posted Jul 27, 2006 10:04 UTC (Thu)
by nix (subscriber, #2304)
[Link]
Posted Jul 27, 2006 5:14 UTC (Thu)
by smurf (subscriber, #17840)
[Link] (1 responses)
Please fix.
Posted Jul 27, 2006 5:57 UTC (Thu)
by dvrabel (subscriber, #9500)
[Link]
Posted Jul 27, 2006 7:13 UTC (Thu)
by Felix.Braun (guest, #3032)
[Link]
Posted Jul 27, 2006 8:14 UTC (Thu)
by kevinliao (guest, #17895)
[Link] (1 responses)
Posted Jul 27, 2006 22:13 UTC (Thu)
by bluefoxicy (guest, #25366)
[Link]
It applies to the created object. So if you link glibc or GTK+ with -Wl,-O1, any program that uses glibc or GTK+ will benefit.
As for whether you can build applications with -Wl,-O1, this is absolutely possible. Applications have a .dynsym section and do export symbols. Most symbols are undefined in the executable and must get resolved to a shared library; but there are a few that are straight exported. Looking at gaim:
The list goes on. With some applications this is useful; you can dlopen() a library (i.e. a plug-in) and have its undefined symbols resolve to symbols in the main executable. This of course means that this symbol table gets searched too; so if you don't want to parse 'gaim_' over and over again 5-10 times in whatever bucket you land in, build the gaim executable with -Wl,-O1 and make sure only say 1-3 fall in the same bucket.
In short, yes, it's both safe, sane, and purposeful to use this everywhere.
Posted Jul 27, 2006 10:34 UTC (Thu)
by jarel (guest, #4109)
[Link]
Posted Jul 27, 2006 14:38 UTC (Thu)
by sdalley (subscriber, #18550)
[Link] (2 responses)
Posted Jul 27, 2006 16:53 UTC (Thu)
by bluefoxicy (guest, #25366)
[Link] (1 responses)
It'd be awesome to start moving into -fvisibility=hidden build systems and using the visibility attribute; but it's not something you're going to drop in today and have working in 10 hours after rebuilding Gentoo on an AMD64 build server. Everything I listed, however, would just be "Oh this option is here *enable*" and reap the benefits.
A separate article on -fvisibility and the visibility attribute WRT writing good shared libraries may be nice; if you place it somewhere visible like LWN you'll get a lot of developers looking at it, for example all of Debian ;) It's not that useful stuff is out there; it's that people know about it.
Unfortunately I don't know much about the visibility attribute besides that it makes sure the final module doesn't export hidden symbols, but lets other objects in that module use the symbols; as opposed to static, which statically links the symbol in that object so other objects in the module can't reach it. There's not much I can say beyond one or two paragraphs and some extra peripheral information. Maybe someone else should write something about this? :)
Posted Aug 7, 2006 21:39 UTC (Mon)
by aleXXX (subscriber, #2742)
[Link]
Posted Jul 27, 2006 18:47 UTC (Thu)
by NAR (subscriber, #1313)
[Link] (1 responses)
Posted Jul 27, 2006 21:56 UTC (Thu)
by bluefoxicy (guest, #25366)
[Link]
These are all linker options, so 'gcc -O99' won't do it. It'd be more like 'gcc -Wl,-O1,-Bdirect,-z,dynsort,-hashvals' or (since hashvals and dynsort are getting merged as --hash-style) 'gcc -Wl,-O1,-Bdirect,--hash-style=both'.
To that end, you'd see something like LDFLAGS="-Wl,-O1,-Bdirect,--hash-style=both" either as an argument to make or in the environment. The Makefile will adapt, at least with automake; if it won't, then the distro maintainers will patch it to accept LDFLAGS properly.
Posted Aug 6, 2006 8:59 UTC (Sun)
by renox (guest, #23785)
[Link] (1 responses)
Do the time measurements take into account the 'loading from the disk' part? Or are the object files already in memory?
Posted Aug 25, 2006 0:29 UTC (Fri)
by bluefoxicy (guest, #25366)
[Link]
This is a gain because the stuff winds up in adjacent memory and then CPU cache handles it much more gracefully. We also have a LOT less running back and forth to do so we don't have to read massive amounts of memory over and over and over again. (read Drepper's paper and take note of i.e. C++ common prefixes).
Maybe someone with a clue could explain to me why library symbol lookup is Optimizing Linker Load Times
not a perfect candidate for a binary tree? Afterall, lookup times are
what need to be optimized, not inserts (they only happen during compile
right?) Who cares if libraries take longer to compile but runtimes are
substantially sped up? Is it simply a matter of not breaking the ELF
standard?
I dare you to produce the code, and the measurements. :-)Optimizing Linker Load Times
Optimizing Linker Load Times
apple
applecore
appliance
brick
appl--e--core
|-ianc
brick
Binary trees generally have awful cache locality. Note that most of the speedups from the DT_GNU_HASH patch came from considering the impact of code on the dcache: even things like starting hash chains with a tiny bitmap showing which elements were in use was useful to avoid the cache misses involved in scanning the rest of the chain.Optimizing Linker Load Times
They are usually known as "weak" symbols."vague" symbols? Ouch!
See the section on vague linkage in the GCC manual.
"vague" symbols? Ouch!
This was an excelent and unusually informative article (even by LWN's high standards), thank you!Optimizing Linker Load Times
Does the fisrt method (-Wl,-O1) only apply to shared library? Or it can also be used for normal applications? Thanks a lot.Optimizing Linker Load Times
Optimizing Linker Load Times
bluefox@icebox:~$ readelf -s /usr/bin/gaim|grep -v UND
Symbol table '.dynsym' contains 2669 entries:
Num: Value Size Type Bind Vis Ndx Name
3: 0806ef4d 131 FUNC GLOBAL DEFAULT 14 gaim_account_supports_off
4: 080aa128 163 FUNC GLOBAL DEFAULT 14 gaim_markup_get_tag_name
6: 08091136 49 FUNC GLOBAL DEFAULT 14 gaim_plugin_pref_get_name
7: 080b5db8 141 FUNC GLOBAL DEFAULT 14 gaim_whiteboard_destroy
8: 080a5336 162 FUNC GLOBAL DEFAULT 14 gaim_ssl_read
Great article - thanks.Optimizing Linker Load Times
Another recent change was the gcc -fvisibility option which reduces the number of exported symbols that the loader has to slosh around in in the first place - http://gcc.gnu.org/wiki/Visibility . It would be interesting to know whether OO, KDE etc are now taking advantage of this.Optimizing Linker Load Times
This is of course an excellent idea; but it requires code changes as well. I was mostly writing about drop-and-go speed hacks.Optimizing Linker Load Times
-fvisibility is used by KDE for gcc > 4.1, both KDE 3.5 and KDE 4. Optimizing Linker Load Times
Alex
If I understood correctly, these optimizations are enabled by "magic" options (e.g. -Bdirect, -zdynsort), i.e. application developers need to put these options into their Makefiles to enable them. Of course, first they need to find these options and understand them. However, I'm afraid most application developers doesn't have a clue about these delicate details of runtime linking, so will there be a --make-as-fast-as-possible option for the mere mortals? Or will -O<high> turn these options on?
Options
Actually most Makefiles allow the build system to accept variables from the environment or command line; portage puts CFLAGS and LDFLAGS in the environment, and dpkg-buildpackage tends to put them on the make command line.Options
I'm a bit surprised that precomputing hash values is a gain: after all these precomputed value increase (a little) the size of the object files, so the gain of the lookup must be balanced against the increased time loading for the disk the object files.About precomputing hash values
yeah the increase is 1-2 pages (4-8KiB) and the kernel does read-ahead caching and the read time when doing a linear read is nothing. Seek time is what kills you really; if you try to read 1 byte at a time over and over, versus read in 512 byte blocks, you'll find it takes hours to do byte by byte what takes 3 seconds to do 512 at a time (in DOS; Linux has some kind of cool read-ahead algorithm that prefetches the next few sectors).About precomputing hash values